TL;DR#
Existing video customization approaches struggle with identity degradation & limited dynamics due to reliance on self-reconstruction with static images. These methods fail to maintain consistent identity over extended video and reduce natural motion. The core issue lies in the domain shift between static reference images & dynamic video sequences, hindering performance during inference.
To solve this, MagicID is introduced, a framework promoting identity-consistent, dynamic-rich videos via hybrid preference optimization. It uses pairwise preference video data with identity & dynamic rewards for learning. A hybrid sampling strategy leverages static videos for identity & enhances motion. Extensive experiments show MagicID achieves identity & natural dynamics, surpassing existing methods.
Key Takeaways#
Why does it matter?#
This research on personalized video generation offers valuable tools & techniques for researchers, driving future advancements in content creation and personalized media experiences. The hybrid approach enhances identity fidelity & dynamic preservation, setting a new benchmark for quality and realism.
Visual Insights#

🔼 This figure showcases the results of the MagicID model. The model takes a small number of reference images of a person as input and generates a series of short video clips depicting that person in various actions and settings. The generated videos demonstrate that the MagicID model is able to create highly realistic and personalized videos while maintaining a consistent identity (i.e., the person’s appearance remains the same throughout the video clips) and showcasing dynamic, natural-looking movement.
read the caption
Figure 1: Results of MagicID. Given a few reference images, our method is capable of generating highly realistic and personalized videos that maintain consistent identity features while exhibiting natural and visually appealing motion dynamics.
| Method | Face Sim. () | Dyna. Deg. () | T. Cons. () | CLIP-T () | CLIP-I () | FVD () |
|---|---|---|---|---|---|---|
| DreamBooth [30] | 0.276 | 5.690 | 0.9922 | 25.83 | 46.55 | 1423.55 |
| MagicMe [27] | 0.322 | 5.332 | 0.9924 | 25.42 | 62.45 | 1438.66 |
| IDAnimator [11] | 0.433 | 10.33 | 0.9938 | 25.21 | 49.33 | 1558.33 |
| ConsisID [42] | 0.482 | 9.26 | 0.9811 | 26.12 | 63.88 | 1633.21 |
| MagicID | 0.600 | 14.42 | 0.9933 | 26.28 | 78.83 | 1228.33 |
🔼 Table 1 presents a quantitative comparison of MagicID against several other state-of-the-art methods for video customization. The comparison is based on six key metrics: Face Similarity (how well the generated video’s face matches the reference image), Dynamic Degree (how much motion is present in the video), Temporal Consistency (how consistent the identity is across the video sequence), CLIP-T (how well the generated video aligns with the text prompt), CLIP-I (how well the generated video’s identity matches the reference image, using image embeddings from CLIP), and FVD (Fréchet Video Distance, which measures the overall visual difference between generated and real videos). Higher scores are better for Face Similarity, Dynamic Degree, Temporal Consistency, CLIP-T, and CLIP-I; a lower score is better for FVD.
read the caption
Table 1: Quantitative comparison. We conduct a comprehensive comparison including the ability to achieve high ID fidelity (i.e., Face Similarity and CLIP-I), dynamic degree, temporal consistency, text alignment (i.e., CLIP-T), and distribution distance (i.e., FVD).
In-depth insights#
Hybrid Pref. Opt.#
Hybrid Preference Optimization presents a sophisticated approach to training generative models by leveraging pairwise comparisons instead of relying solely on reconstruction losses. This technique is particularly useful in scenarios like personalized video creation, where maintaining both identity and dynamic fidelity is crucial. Instead of directly reconstructing a target, the model learns to discriminate between preferable and less desirable outputs, guided by explicitly defined rewards for identity consistency and dynamic realism. The hybrid aspect suggests a strategy that likely combines different types of preference data or rewards, addressing the inherent challenges of balancing competing objectives and data scarcity in customization tasks. This might involve multi-stage training or adaptive weighting of different preference signals, contributing to more robust and nuanced results. Furthermore, this pref. optimization has the potential to improve the overall quality and human satisfaction with the generated content.
ID Consistency++#
ID Consistency is paramount in personalized video generation, ensuring the generated content accurately reflects the identity of the person depicted in the reference images. A robust ‘ID Consistency++’ would involve maintaining identity across varying poses, lighting conditions, and even stylistic changes. It also extends to preserving subtle nuances of the individual’s appearance, such as facial expressions and unique physical characteristics. The enhancement is to preserve ID across video frames, even in fast-paced scenes or complex camera movements. Furthermore, a successful ‘ID Consistency++’ method should be resilient to potential artifacts or distortions that can arise during the video generation process. The goal is to have a system with minimal manual intervention, which allows for more personalized video creation. Another important element is to have is benchmark tools to evaluate video generation.
Dynamic Reward#
A dynamic reward mechanism is crucial for fostering motion in video generation. It goes beyond static image reconstruction, incentivizing the model to generate sequences with varied movements. A well-designed dynamic reward should consider factors like optical flow, motion intensity, and the naturalness of movements. Balancing dynamic rewards with identity preservation is key, as excessive emphasis on motion might compromise the consistency of identity features. The dynamic reward fosters visually interesting and realistic video content by guiding the model towards outputs that reflect real-world motion patterns, moving beyond the limitations of static image-based self-reconstruction. However, the computation must be precise, which is one of the challenging aspect.
T2V Customization#
Text-to-Video (T2V) customization is more complex than Text-to-Image (T2I) due to the temporal dynamics inherent in videos. Current studies in this area are limited, with methods like MagicMe extending Textual Inversion but facing issues in generalization. ID-Animator and ConsisID use face adapters, requiring extensive high-quality video datasets for fine-tuning, adding to the costs. T2V requires not only preserving identity but also maintaining dynamic motion, making the task significantly more challenging. Many current techniques fail to address both, either degrading ID or reducing dynamics. Furthermore, self-reconstruction from still reference images causes the model to prioritize static features, resulting in diminished motion quality in generated videos.
Motion & Identity#
Motion and identity in video generation are intertwined, posing a complex challenge. Preserving identity across frames while ensuring natural dynamics is crucial. Current methods often falter, leading to either identity degradation or reduced dynamic range. The key is balancing these two aspects; excessive focus on one can detrimentally impact the other. A successful approach must prioritize both, perhaps through a hybrid strategy that first establishes a strong identity foundation and then enhances motion. A novel approach should incorporate identity and dynamic rewards to achieve results that better align with desired outcomes.
More visual insights#
More on figures

🔼 This figure shows the impact of video length on identity consistency. The x-axis represents the length of generated videos, and the y-axis represents a metric measuring the consistency of the identity. Different methods are plotted, demonstrating how their performance changes as the video length increases. It highlights the challenge of preserving identity over longer videos.
read the caption
(a) ID Consistency for longer video.

🔼 The figure shows a graph that illustrates how the dynamic quality of videos generated by different methods changes over the course of training. It demonstrates that traditional approaches show a significant reduction in dynamic quality (motion) as the training steps increase. In contrast, the proposed method (Ours) maintains consistently high dynamic quality throughout the training process.
read the caption
(b) Dynamic Degree for more steps.

🔼 This figure analyzes the effects of video length and training duration on identity consistency and dynamic quality in video generation. In part (a), it shows that as the length of the generated videos increases, traditional methods experience a decline in identity consistency, while the proposed MagicID method consistently maintains a high level of identity preservation. Part (b) demonstrates that traditional methods show a reduction in dynamic quality over time, whereas MagicID preserves the original motion dynamics throughout the training process.
read the caption
Figure 2: Analysis of identity degratation and dynamic reduction. (a) We compute the mean identity similarity with the reference images for generated videos of different lengths. As shown, traditional approaches suffer from diminished identity consistency as video length increases. In contrast, our method maintains strong identity robustness throughout prolonged video generations. (b) We calculate the dynamic degree for different training steps. As the customization progresses, traditional methods experience a gradual loss of motion dynamic during customization, whereas our method preserves original video dynamics across the entire training.

🔼 Figure 3 illustrates the process of creating training data for a video generation model. First, a repository of videos is built using videos generated by both a fine-tuned and an initial Text-to-Video (T2V) model, as well as static images derived from the user’s reference images. Next, each video in the repository is evaluated based on three criteria: identity consistency (using an ID Encoder), dynamic degree (using optical flow), and prompt adherence (using a Vision-Language Model). Finally, video pairs are selected for training using a two-step hybrid approach. The first step prioritizes identity preservation by choosing pairs with significantly different identity scores while maintaining acceptable dynamic scores. The second step focuses on enhancing video dynamics by selecting pairs with a balance of both identity and dynamic scores.
read the caption
Figure 3: Overview of pairwise preference video data construction. In Step 1, we construct a preference video repository using videos generated by fine-tuned and Initial T2V models, along with static videos derived from reference images. In Step 2, we evaluate each video sequentially based on ID consistency using ID Encoder [6], dynamic degree using optical flow [13], and prompt following using VLM[2]. In Step 3, we perform Hybrid Pair Selection, first selecting pairs based on ID consistency differences with a pre-defined dynamic threshold to address identity inconsistency, then selecting pairs based on both dynamic and identity to mitigate the dynamic reduction.

🔼 Figure 4 presents a qualitative comparison of video generation results between MagicID and two other methods: DreamBooth and MagicMe. DreamBooth and MagicMe both utilize fine-tuning approaches, which, according to the study, negatively impact the generated videos by causing a degradation of identity consistency over longer videos and a reduction in dynamic motion elements. In contrast, Figure 4 visually demonstrates how MagicID overcomes these shortcomings, creating videos with significantly better maintenance of consistent identity (ID fidelity) and significantly more natural and dynamic movement.
read the caption
Figure 4: Qualitative comparison with tuning-based methods. As observed, both Dreambooth and MagicMe suffer from inferior ID fidelity, while our method maintains consistent identity and natural dynamics.

🔼 Figure 5 presents a qualitative comparison of video generation results between MagicID and three other methods: ID-Animator, ConsisID, and two tuning-based methods (DreamBooth and MagicMe). The figure visually demonstrates that ID-Animator fails to produce videos with consistent identity and good quality. While ConsisID shows some improvement in identity consistency, it suffers from severe ‘copy-paste’ artifacts, resulting in unnatural motion and misalignment with the text prompts, particularly noticeable in the last example (a video of a person wearing a helmet). In contrast, MagicID generates high-quality videos with consistent identity, natural motion, and accurate text alignment, surpassing the other methods.
read the caption
Figure 5: Qualitative comparison with tuning-based methods. As shown, ID-Animator suffers from poor identity consistency and video quality. While ConsisID improves identity fidelity to some extent, it exhibits severe copy-paste artifacts, demonstrating unnatural motion dynamics and text alignment, as seen in the last example with the helmet. In contrast, our method achieves strong performance in identity consistency, motion dynamics, and text alignment, significantly outperforming the baseline approaches.

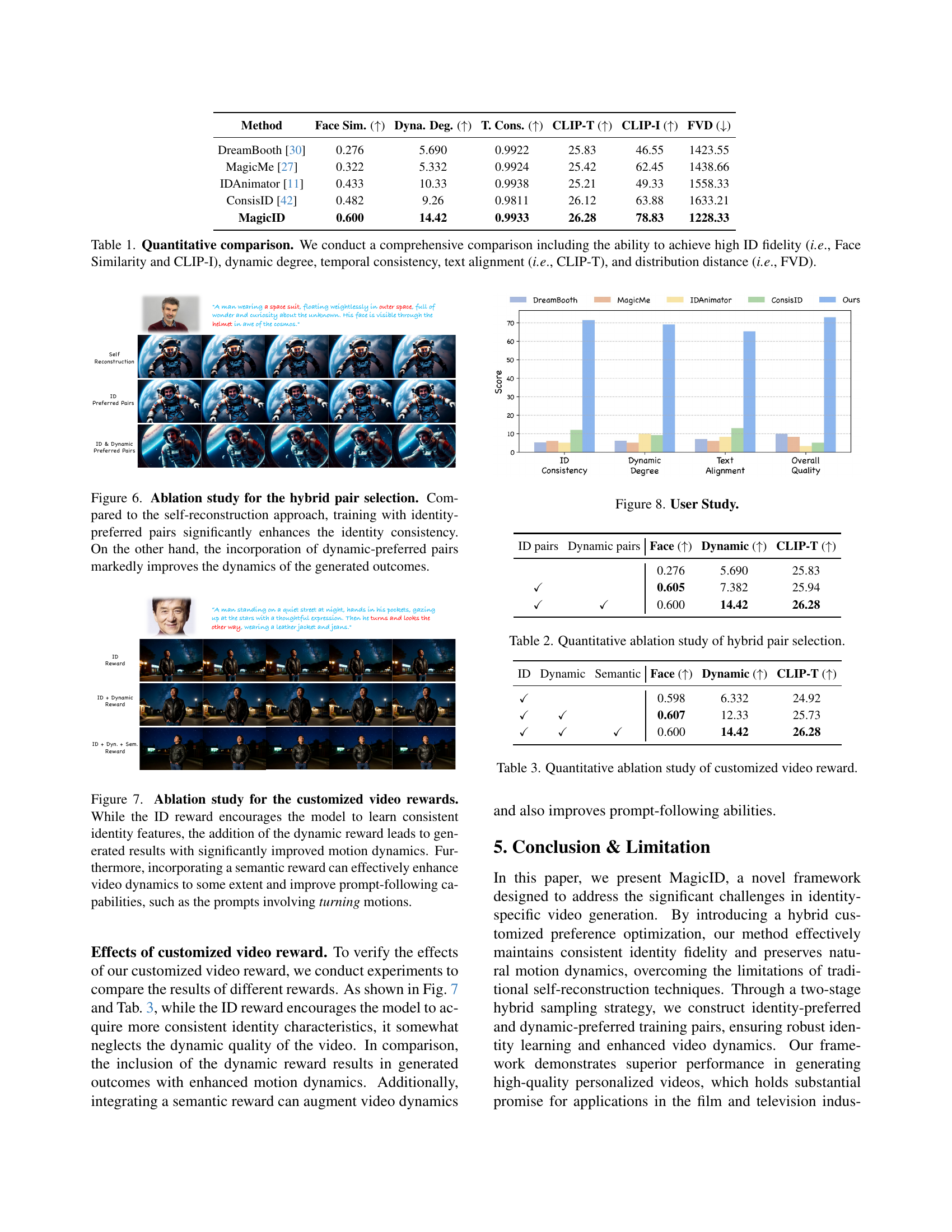
🔼 This ablation study investigates the impact of using different types of video pairs for training a video generation model. The study compares three training strategies: (1) Self-reconstruction (using only a single image for reconstruction); (2) Identity-preferred pairs (prioritizing pairs with significant differences in identity consistency, while allowing some dynamic variability); and (3) Hybrid pairs (combining both identity-preferred and dynamic-preferred pairs to balance identity and motion quality). The results show that using identity-preferred pairs significantly improves identity consistency, while the hybrid approach achieves the best overall results, offering the best balance between consistent identity and natural dynamic motion.
read the caption
Figure 6: Ablation study for the hybrid pair selection. Compared to the self-reconstruction approach, training with identity-preferred pairs significantly enhances the identity consistency. On the other hand, the incorporation of dynamic-preferred pairs markedly improves the dynamics of the generated outcomes.

🔼 This ablation study analyzes the impact of different reward components on video generation quality. The baseline uses only an identity consistency reward, which prioritizes maintaining the subject’s identity across frames. Adding a dynamic reward significantly improves the motion in the generated videos, making them more fluid and natural. Finally, including a semantic reward further enhances the dynamics and improves how well the generated videos match the text prompt, particularly noticeable in actions like turning.
read the caption
Figure 7: Ablation study for the customized video rewards. While the ID reward encourages the model to learn consistent identity features, the addition of the dynamic reward leads to generated results with significantly improved motion dynamics. Furthermore, incorporating a semantic reward can effectively enhance video dynamics to some extent and improve prompt-following capabilities, such as the prompts involving turning motions.

🔼 This figure presents the results of a user study comparing MagicID against other methods in terms of identity consistency, dynamic quality, text alignment, and overall quality. The study involved 25 evaluators assessing 40 video sets generated using the different methods and reference images. The results visually show MagicID’s superior performance across all evaluation criteria.
read the caption
Figure 8: User Study.

🔼 This figure displays further results generated by the MagicID model, showcasing its ability to produce high-fidelity videos that maintain consistent identity and exhibit significant dynamics based on user-provided reference images. Multiple examples of diverse scenarios are presented, highlighting the model’s ability to generate realistic and personalized videos across various contexts. Each example shows a series of video frames resulting from the same prompt and reference images.
read the caption
Figure 9: More results of MagicID.

🔼 This figure showcases additional results generated by the MagicID model. It demonstrates the model’s ability to generate high-fidelity videos that maintain consistent identity and exhibit natural dynamics across various scenes and actions. The example shows a man in a tactical stealth suit on a rooftop at night, highlighting the model’s capacity to render detailed textures and realistic lighting conditions.
read the caption
Figure 10: More results of MagicID.

🔼 This figure showcases additional results generated by the MagicID model. It presents a series of short video clips demonstrating the model’s ability to generate realistic and dynamically consistent videos of a tribal warrior in a jungle setting, maintaining a consistent identity based on the input reference images while exhibiting natural motion.
read the caption
Figure 11: More results of MagicID.
More on tables
| ID pairs | Dynamic pairs | Face () | Dynamic () | CLIP-T () |
|---|---|---|---|---|
| 0.276 | 5.690 | 25.83 | ||
| ✓ | 0.605 | 7.382 | 25.94 | |
| ✓ | ✓ | 0.600 | 14.42 | 26.28 |
🔼 This table presents a quantitative analysis of the impact of different hybrid pair selection strategies on the performance of the MagicID model. It shows the effects of using only identity-preferred pairs, only dynamic-preferred pairs, and a combination of both on key metrics: Face similarity (measuring identity preservation), Dynamic degree (measuring motion intensity), and CLIP-T (measuring alignment with text prompts). The results demonstrate the benefit of the hybrid approach in achieving a balance between consistent identity and dynamic motion.
read the caption
Table 2: Quantitative ablation study of hybrid pair selection.
| ID | Dynamic | Semantic | Face () | Dynamic () | CLIP-T () |
|---|---|---|---|---|---|
| ✓ | 0.598 | 6.332 | 24.92 | ||
| ✓ | ✓ | 0.607 | 12.33 | 25.73 | |
| ✓ | ✓ | ✓ | 0.600 | 14.42 | 26.28 |
🔼 This table presents the results of an ablation study investigating the impact of different reward functions on the performance of the MagicID model. It shows the effects of using only an identity reward, an identity and dynamic reward, and finally all three rewards (identity, dynamic, and semantic). The metrics used to evaluate model performance are face similarity, dynamic degree, and text alignment, reflecting the model’s ability to maintain identity consistency, generate dynamic videos, and adhere to the text prompt, respectively. The study’s goal was to determine the optimal combination of reward functions to achieve the best overall performance in generating high-quality, consistent, and dynamic videos.
read the caption
Table 3: Quantitative ablation study of customized video reward.
Full paper#