TL;DR#
Current Large Multi-modal Models (LMMs) are primarily focused on offline video understanding. Streaming video poses challenges to recent models due to its time-sensitive and interactive characteristics. The paper aims to extend streaming video understanding and proposes Visual Instruction Feedback, in which models understand visual content and extract instructions. This greatly enhances user-agent interactions.
The study defines key subtasks and collects ViSpeak-Instruct dataset for training and ViSpeak-Bench for evaluation. The paper proposes the ViSpeak model, a SOTA streaming video understanding LMM with GPT-4o-level performance. After fine-tuning, ViSpeak gains basic visual instruction feedback ability, serving as a solid baseline.
Key Takeaways#
Why does it matter?#
This paper introduces a novel task and benchmark that addresses the growing need for models that can understand and respond to visual instructions in streaming videos, mirroring real-time human interactions. By addressing the gap in current models that primarily focus on offline video understanding, this research opens up new possibilities for creating more interactive and responsive AI systems in various applications.
Visual Insights#

🔼 This figure showcases examples of human-computer interaction using body language as instructions in the Visual Instruction Feedback task. It illustrates four key subtasks: Visual Wake-Up (initiating interaction), Visual Reference (indicating an object), Visual Interruption (stopping the agent), and Visual Termination (ending the interaction). The image displays screen captures of a video stream at different time points, each showing a distinct body language cue. The text in parentheses indicates the action performed via body language instead of verbal communication.
read the caption
Figure 1: Examples of some actions in Visual Instruction Feedback task, which are Visual Wake-Up, Visual Reference, Visual Interruption, and Visual Termination in order. The content in parentheses is displayed by body language instead of text or speech.
| Benchmark | #Videos | #QA Pairs | Time | Streaming | PO | Visual Instruct | Anno |
| ActivityNet-QA [60] | 800 | 8,000 | ✗ | ✗ | ✗ | ✗ | Manual |
| NExT-QA [50] | 1,000 | 8,564 | ✗ | ✗ | ✗ | ✗ | Auto |
| MVBench [25] | 3,641 | 4,000 | ✗ | ✗ | ✗ | ✗ | Auto |
| Video-MME [15] | 900 | 2,700 | ✗ | ✗ | ✗ | ✗ | Manual |
| ET-Bench [32] | 7,002 | 7,289 | ✓ | ✗ | ✗ | ✗ | Manual |
| StreamingBench [29] | 900 | 4,500 | ✓ | ✓ | ✓ | ✗ | Mixed |
| ViSpeak-Bench | 1,000 | 1,000 | ✓ | ✓ | ✓ | ✓ | Mixed |
🔼 This table compares ViSpeak-Bench with other video benchmarks across several key features. It highlights whether each benchmark is time-sensitive (meaning the order of events matters) and whether it includes tasks to evaluate a model’s ability to proactively provide output (i.e., generate responses without explicit user prompting). The table also lists the number of videos and QA pairs (Question-Answer pairs) for each benchmark.
read the caption
Table 1: Comparison between ViSpeak-Bench and other video benchmarks. ‘Time’ means the dataset is time-sensitive. ‘PO’ denotes the dataset to evaluate the proactive output ability.
In-depth insights#
Visual Feedback#
Visual feedback in AI, especially for streaming videos, introduces a novel human-agent interaction. It requires agents to be aware of visual cues, like gestures, and react accordingly. The core idea is to provide real-time assistance and responses based on visual input, enhancing user experience. The task includes subtasks like wake-up via body language, anomaly warnings, gesture understanding, visual referencing, interruption handling, humor reactions, and ending conversations. Such a system uses visual input for conversational AI. This interaction improves human-agent relationships by allowing for in-time, effective exchanges and feedback. Understanding visual cues greatly improves overall experience.
Streaming LMMs#
Streaming Large Multimodal Models (LMMs) present unique challenges compared to offline models, primarily due to their time-sensitive, omni-modal and interactive nature. Unlike offline processing where the entire video context is available, streaming LMMs must make decisions based on continually arriving data. This necessitates prompt responses to questions, and effective integration of streaming audio. The interactive characteristic further distinguishes streaming LMMs, encompassing non-awakening interaction, interruption, and proactive output. This interactive aspect is often overlooked, requiring models to respond to user actions at any time, handle interruptions smoothly, and express their mind proactively. These factors make streaming LMMs a complex but important area for enhancing human-agent interactions in real-time visual settings.
ViSpeak Model#
The ViSpeak model is designed as an omni-modal LMM (Large Multi-modal Model) to tackle the Visual Instruction Feedback task. It uses an image encoder, an audio encoder, and a large language model to process visual and audio cues. A key innovation is the two-stream chat template, which allows the model to process user inputs and generate outputs concurrently, facilitating real-time interaction. To handle visual interruptions, the model can output a “↓ Stop!” token. The model also has an informative head to proactively generate visual outputs. This head helps predict when to speak, addressing a crucial aspect of streaming video processing. A weighted sum of the two streams is used to combine user input and system output, with a linear layer predicting weights. Finally, the streaming inputs from users are segmented into multiple fragments and organized in chronological order.
Three-Stage Tune#
Three-stage tuning is vital for refining large models. Initially, aligning the model’s template ensures it adapts to specific input formats while retaining core understanding. Subsequent tuning focuses on enhancing task-specific abilities, like question answering, using relevant datasets. Finally, fine-tuning on a targeted dataset optimizes performance for the desired task. This layered approach allows for both broad adaptation and specialized expertise, improving model efficiency.
ViSpeak-Bench#
The paper introduces ViSpeak-Bench, a benchmark to evaluate models on Visual Instruction Feedback in streaming videos. It seems designed to test how well models understand and respond to visual cues, gestures, and actions without explicit text instructions. The benchmark includes diverse subtasks which address important aspects of human-agent interaction. This task aims to facilitate in-time interaction and assistance effectively. By restricting the feedback in the conversational scenarios, ViSpeak-Bench becomes a valuable resource for developing more intuitive and responsive video understanding systems, specifically concerning the integration of visual cues into interactive dialogues. The benchmark appears to be comprehensive, which requires the model to respond actively to visual contents. As a result, it can enhance human-agent interactions and advance research in this domain.
More visual insights#
More on figures

🔼 The ViSpeak model architecture is shown. It’s a large multimodal model (LMM) designed for streaming video understanding. It uses separate encoders for audio, video, and text inputs. Notably, it accepts two input streams: one for user inputs (e.g., questions, commands) and another for the model’s own previously generated outputs. These two streams are combined before being fed into a large language model (LLM). A key feature is the inclusion of an ‘informative head’, which enables the model to proactively generate visual outputs, such as initiating conversation based on observed actions in the video stream.
read the caption
Figure 2: ViSpeak is an omni-modality LMM with multiple encoders and a LLM. To support streaming video analysis, ViSpeak takes two input streams as inputs, one for user inputs and one for self-generated outputs. Two streams will be combined into a single one before sending to LLM. An informative head is trained for visual proactive output.

🔼 The figure shows a breakdown of the demographics of the participants involved in recording videos for the ViSpeak-Bench and ViSpeak-Instruct datasets. The data is presented as two charts: a pie chart displaying the gender distribution (approximately equal numbers of males and females), and a bar chart illustrating the age distribution, ranging from 10 to 70 years old.
read the caption
Figure 3: Statistics on participants who recorded videos. The participants comprised nearly equal numbers of males and females, with ages ranging from 10 to 70 years.

🔼 This figure shows a sequence of images from the ViSpeak-Bench dataset that depicts a person performing a visual wake-up gesture. The person is making a sequence of hand gestures, and the figure displays timestamps for each gesture. Below the images, there are annotations showing the corresponding text prompt and the ViSpeak model’s response to that visual input. The response demonstrates the model’s ability to recognize the visual wake-up cue and start a conversation accordingly. This example illustrates the type of data used for the Visual Instruction Feedback task.
read the caption
Figure 4: Examples of Visual Wake-Up in ViSpeak-Bench and the corresponding output by ViSpeak.

🔼 This figure showcases an example from the ViSpeak-Bench dataset illustrating the ‘Visual Termination’ subtask. It displays a video sequence where a user signals the end of a conversation using a nonverbal cue (body language). The annotation details the conversation’s timing and the user’s action. It also shows the corresponding output generated by the ViSpeak model, demonstrating its ability to understand the visual signal and appropriately terminate the interaction. The first round of conversation is included as context for the model’s response.
read the caption
Figure 5: Examples of Visual Termination in ViSpeak-Bench and the corresponding output by ViSpeak. The first round conversation is used as context.

🔼 This figure showcases examples from the ViSpeak-Bench dataset where a visual interruption occurs. The top panel displays a sequence of video frames depicting the interruption, showing the user visually signaling a halt in the conversation. The bottom panel presents the original conversation prompt from the dataset, the model’s initial response before interruption, the user’s visual interruption signal (denoted as ‘(Stop)’), and finally, the model’s concise response to the interruption. This illustrates the model’s ability to recognize and respond appropriately to this non-verbal form of user feedback in real-time.
read the caption
Figure 6: Examples of Visual Interruption in ViSpeak-Bench and the corresponding output by ViSpeak. The first round conversation is used as context.

🔼 This figure showcases examples from the ViSpeak-Bench dataset demonstrating the Gesture Understanding subtask. It visually presents a sequence of frames from a video showing a person making a gesture (a finger heart). Accompanying the video frames is a transcript of the human-agent conversation. The first part of the conversation serves as context for the gesture. The figure then shows the model’s (ViSpeak) response to the gesture, highlighting the model’s ability to understand and interpret the visual cue within the conversational context.
read the caption
Figure 7: Examples of Gesture Understanding in ViSpeak-Bench and the corresponding output by ViSpeak. The first round conversation is used as context.

🔼 This figure showcases two examples from the ViSpeak-Bench dataset demonstrating the ‘Anomaly Warning’ subtask. Each example shows a short video clip depicting an anomalous event (a person falling on a trampoline). The figure displays the corresponding ground truth caption of the video, the response generated by the GPT-4 model, and finally the response generated by the ViSpeak model. The comparison highlights the different abilities of GPT-4 and ViSpeak in handling anomaly detection and generating appropriate warnings.
read the caption
Figure 8: Examples of Anomaly Warning in ViSpeak-Bench and the corresponding output by ViSpeak.

🔼 Figure 9 shows two examples of the Humor Reaction subtask from the ViSpeak-Bench dataset. Each example displays a short video clip with a humorous scene, followed by the ground truth annotation and ViSpeak’s generated response. The annotations provide context and describe the humorous aspects of the video. ViSpeak’s response attempts to capture the humor in a conversational and engaging way, demonstrating its ability to understand and generate appropriate responses to humorous visual content.
read the caption
Figure 9: Examples of Humor Reaction in ViSpeak-Bench and the corresponding output by ViSpeak.

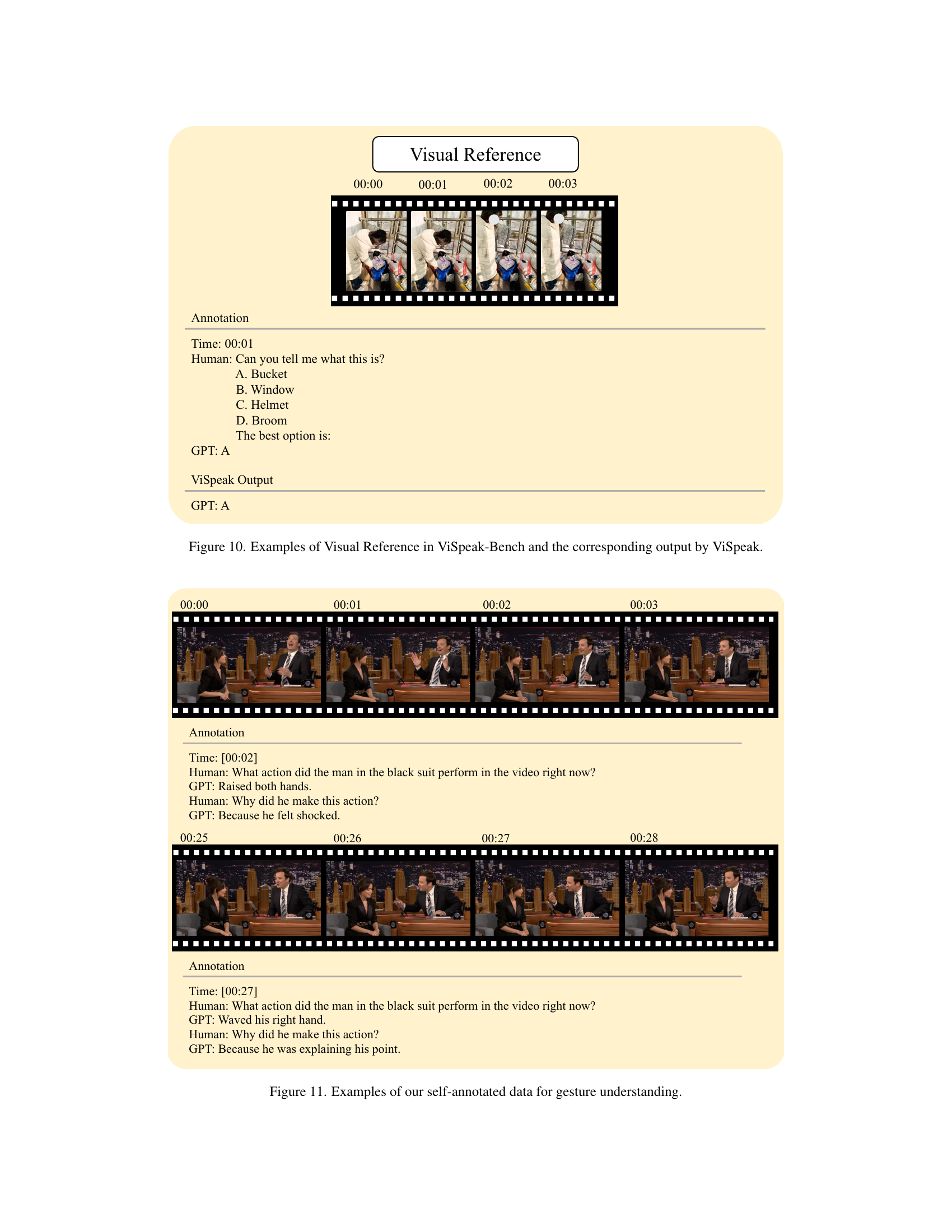
🔼 This figure showcases examples from the ViSpeak-Bench dataset, specifically focusing on the Visual Reference subtask. It presents several short video clips where a user points to an object, and the corresponding response from the ViSpeak model. The goal of the subtask is to test the model’s capability to understand visual references within videos. The figure highlights the accuracy of ViSpeak in correctly identifying the referenced object based on the user’s visual cue, demonstrating its ability to process visual information and respond accordingly within the context of the video.
read the caption
Figure 10: Examples of Visual Reference in ViSpeak-Bench and the corresponding output by ViSpeak.

🔼 This figure showcases examples from the self-annotated dataset used for gesture understanding. It displays video segments with annotations showing both the gesture itself and the intended meaning or context of that gesture within a conversation. The annotations help train the model to accurately interpret and respond appropriately to various gestures. These examples illustrate the diversity of gestures and their accompanying explanations present in the dataset.
read the caption
Figure 11: Examples of our self-annotated data for gesture understanding.

🔼 Figure 12 showcases three instances where the ViSpeak model’s responses were inaccurate. The first example, ‘Time Mistake,’ illustrates a situation where the model generates a response at an inappropriate moment in the video, unrelated to the on-screen activity. The second example, ‘Content Mistake,’ demonstrates a failure to correctly understand the visual content of the video. The model’s response misinterprets what is happening in the video. The third example, ‘Context Mistake,’ highlights the model’s inability to grasp the context of the conversation, leading to an irrelevant and inaccurate response.
read the caption
Figure 12: Examples of failure cases. The ‘Time Mistake’ denotes the model responds at an improper time. The ‘Content Mistake’ denotes the model fails to understand the visual content in the video. The ‘Context Mistake’ means the model is unaware of the context of the conversation.
More on tables
| Subtask | #Videos | #QA Pairs | QA Type |
| Visual Wake-Up | 100 | 100 | Open-Ended |
| Anomaly Warning | 200 | 200 | Open-Ended |
| Gesture Understanding | 200 | 200 | Open-Ended |
| Visual Reference | 200 | 200 | Multi-Choice |
| Visual Interruption | 100 | 100 | Open-Ended |
| Humor Reaction | 100 | 100 | Open-Ended |
| Visual Termination | 100 | 100 | Open-Ended |
| ViSpeak-Bench | 1,000 | 1,000 |
🔼 ViSpeak-Bench is a benchmark dataset designed for evaluating models’ ability to perform Visual Instruction Feedback. It contains 1000 videos and 1000 question-answer pairs across seven subtasks: Visual Wake-Up, Anomaly Warning, Gesture Understanding, Visual Reference, Visual Interruption, Humor Reaction, and Visual Termination. Each subtask focuses on a specific aspect of visual instruction understanding in streaming video, encompassing various interactive scenarios.
read the caption
Table 2: ViSpeak-Bench benchmark statistics. ViSpeak-Bench contains 7 subtasks with 1,000 videos and 1,000 QA pairs.
| Subtask | Data Source | Data Type | #Samples | Ratio |
| Visual Wake-Up | self-collected data | online | 1k | 0.03 |
| Anomaly Warning | OOPS [13] | online | 3k | 0.09 |
| HIVAU [63] | online | 3k | 0.09 | |
| Gesture Understanding | Jester [35] | online | 4k | 0.12 |
| self-collected data | online | 4k | 0.12 | |
| Social-IQ [61] | offline | 2k | 0.06 | |
| IntentQA [24] | offline | 5k | 0.15 | |
| SocialIQA [41] | offline | 0.5k | 0.02 | |
| self-collected data | offline | 1k | 0.03 | |
| Visual Reference | self-collected data | online | 5k | 0.15 |
| Visual Interruption | self-collected data | online | 1k | 0.03 |
| Humor Reaction | FunQA [51] | online | 2k | 0.06 |
| SMILE [20] | offline | 1k | 0.03 | |
| Visual Termination | self-collected data | online | 1k | 0.03 |
| ViSpeak-Instruct | 34k | 1 |
🔼 This table details the distribution of samples across different subtasks within the ViSpeak-Instruct dataset. It shows how many samples are dedicated to each of the seven subtasks (Visual Wake-Up, Anomaly Warning, Gesture Understanding, Visual Reference, Visual Interruption, Humor Reaction, and Visual Termination) and indicates whether the data source is self-collected or from other online/offline datasets. The ratio of samples for each subtask relative to the overall dataset is also provided. This information is crucial for understanding the composition and balance of the dataset used to train and evaluate the ViSpeak model.
read the caption
Table 3: Task and sample distribution in ViSpeak-Instruct.
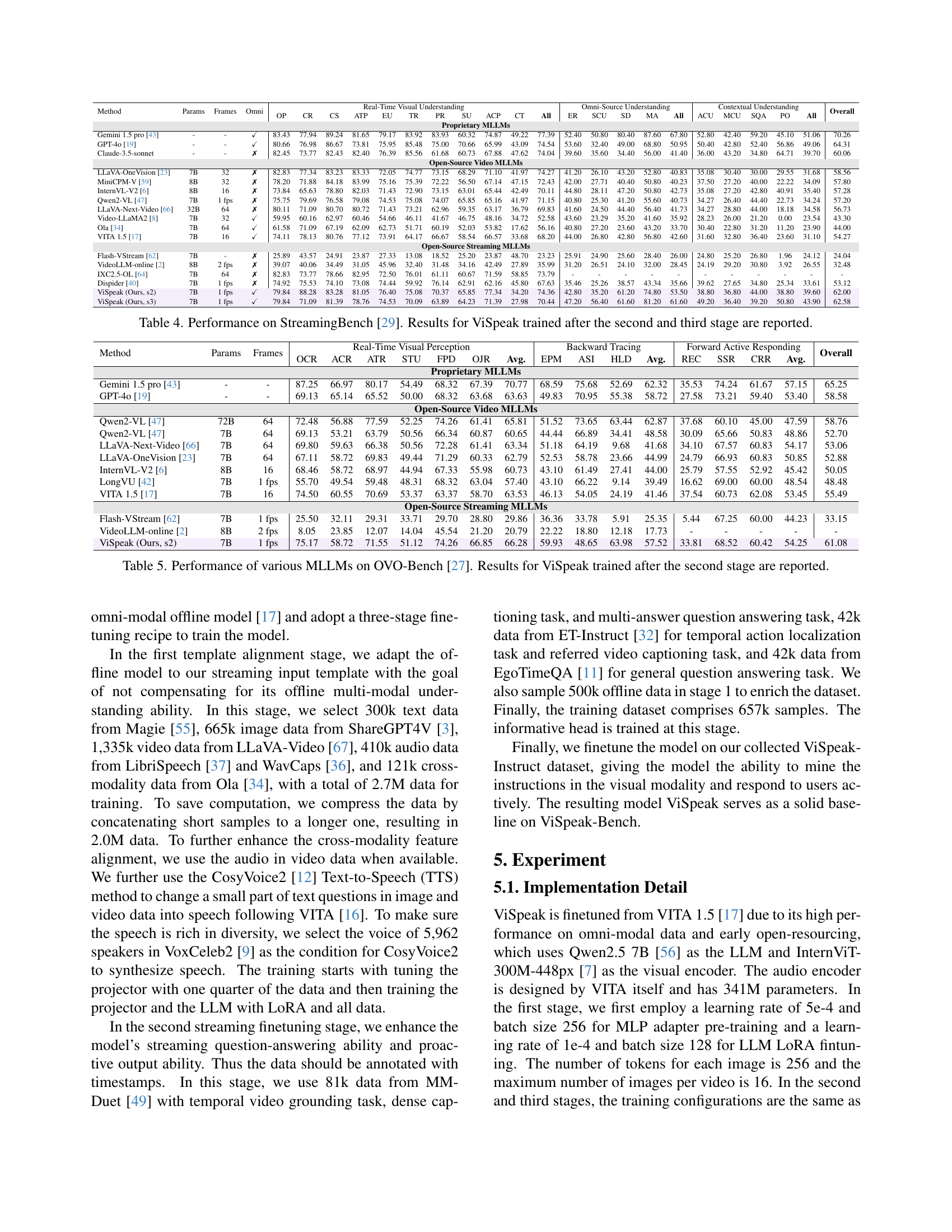
| Method | Params | Frames | Omni | Real-Time Visual Understanding | Omni-Source Understanding | Contextual Understanding | Overall | ||||||||||||||||||
| OP | CR | CS | ATP | EU | TR | PR | SU | ACP | CT | All | ER | SCU | SD | MA | All | ACU | MCU | SQA | PO | All | |||||
| Proprietary MLLMs | |||||||||||||||||||||||||
| Gemini 1.5 pro [43] | - | - | ✓ | 83.43 | 77.94 | 89.24 | 81.65 | 79.17 | 83.92 | 83.93 | 60.32 | 74.87 | 49.22 | 77.39 | 52.40 | 50.80 | 80.40 | 87.60 | 67.80 | 52.80 | 42.40 | 59.20 | 45.10 | 51.06 | 70.26 |
| GPT-4o [19] | - | - | ✓ | 80.66 | 76.98 | 86.67 | 73.81 | 75.95 | 85.48 | 75.00 | 70.66 | 65.99 | 43.09 | 74.54 | 53.60 | 32.40 | 49.00 | 68.80 | 50.95 | 50.40 | 42.80 | 52.40 | 56.86 | 49.06 | 64.31 |
| Claude-3.5-sonnet | - | - | ✗ | 82.45 | 73.77 | 82.43 | 82.40 | 76.39 | 85.56 | 61.68 | 60.73 | 67.88 | 47.62 | 74.04 | 39.60 | 35.60 | 34.40 | 56.00 | 41.40 | 36.00 | 43.20 | 34.80 | 64.71 | 39.70 | 60.06 |
| Open-Source Video MLLMs | |||||||||||||||||||||||||
| LLaVA-OneVision [23] | 7B | 32 | ✗ | 82.83 | 77.34 | 83.23 | 83.33 | 72.05 | 74.77 | 73.15 | 68.29 | 71.10 | 41.97 | 74.27 | 41.20 | 26.10 | 43.20 | 52.80 | 40.83 | 35.08 | 30.40 | 30.00 | 29.55 | 31.68 | 58.56 |
| MiniCPM-V [59] | 8B | 32 | ✗ | 78.20 | 71.88 | 84.18 | 83.99 | 75.16 | 75.39 | 72.22 | 56.50 | 67.14 | 47.15 | 72.43 | 42.00 | 27.71 | 40.40 | 50.80 | 40.23 | 37.50 | 27.20 | 40.00 | 22.22 | 34.09 | 57.80 |
| InternVL-V2 [6] | 8B | 16 | ✗ | 73.84 | 65.63 | 78.80 | 82.03 | 71.43 | 72.90 | 73.15 | 63.01 | 65.44 | 42.49 | 70.11 | 44.80 | 28.11 | 47.20 | 50.80 | 42.73 | 35.08 | 27.20 | 42.80 | 40.91 | 35.40 | 57.28 |
| Qwen2-VL [47] | 7B | 1 fps | ✗ | 75.75 | 79.69 | 76.58 | 79.08 | 74.53 | 75.08 | 74.07 | 65.85 | 65.16 | 41.97 | 71.15 | 40.80 | 25.30 | 41.20 | 55.60 | 40.73 | 34.27 | 26.40 | 44.40 | 22.73 | 34.24 | 57.20 |
| LLaVA-Next-Video [66] | 32B | 64 | ✗ | 80.11 | 71.09 | 80.70 | 80.72 | 71.43 | 73.21 | 62.96 | 59.35 | 63.17 | 36.79 | 69.83 | 41.60 | 24.50 | 44.40 | 56.40 | 41.73 | 34.27 | 28.80 | 44.00 | 18.18 | 34.58 | 56.73 |
| Video-LLaMA2 [8] | 7B | 32 | ✓ | 59.95 | 60.16 | 62.97 | 60.46 | 54.66 | 46.11 | 41.67 | 46.75 | 48.16 | 34.72 | 52.58 | 43.60 | 23.29 | 35.20 | 41.60 | 35.92 | 28.23 | 26.00 | 21.20 | 0.00 | 23.54 | 43.30 |
| Ola [34] | 7B | 64 | ✓ | 61.58 | 71.09 | 67.19 | 62.09 | 62.73 | 51.71 | 60.19 | 52.03 | 53.82 | 17.62 | 56.16 | 40.80 | 27.20 | 23.60 | 43.20 | 33.70 | 30.40 | 22.80 | 31.20 | 11.20 | 23.90 | 44.00 |
| VITA 1.5 [17] | 7B | 16 | ✓ | 74.11 | 78.13 | 80.76 | 77.12 | 73.91 | 64.17 | 66.67 | 58.54 | 66.57 | 33.68 | 68.20 | 44.00 | 26.80 | 42.80 | 56.80 | 42.60 | 31.60 | 32.80 | 36.40 | 23.60 | 31.10 | 54.27 |
| Open-Source Streaming MLLMs | |||||||||||||||||||||||||
| Flash-VStream [62] | 7B | - | ✗ | 25.89 | 43.57 | 24.91 | 23.87 | 27.33 | 13.08 | 18.52 | 25.20 | 23.87 | 48.70 | 23.23 | 25.91 | 24.90 | 25.60 | 28.40 | 26.00 | 24.80 | 25.20 | 26.80 | 1.96 | 24.12 | 24.04 |
| VideoLLM-online [2] | 8B | 2 fps | ✗ | 39.07 | 40.06 | 34.49 | 31.05 | 45.96 | 32.40 | 31.48 | 34.16 | 42.49 | 27.89 | 35.99 | 31.20 | 26.51 | 24.10 | 32.00 | 28.45 | 24.19 | 29.20 | 30.80 | 3.92 | 26.55 | 32.48 |
| IXC2.5-OL [64] | 7B | 64 | ✗ | 82.83 | 73.77 | 78.66 | 82.95 | 72.50 | 76.01 | 61.11 | 60.67 | 71.59 | 58.85 | 73.79 | - | - | - | - | - | - | - | - | - | - | - |
| Dispider [40] | 7B | 1 fps | ✗ | 74.92 | 75.53 | 74.10 | 73.08 | 74.44 | 59.92 | 76.14 | 62.91 | 62.16 | 45.80 | 67.63 | 35.46 | 25.26 | 38.57 | 43.34 | 35.66 | 39.62 | 27.65 | 34.80 | 25.34 | 33.61 | 53.12 |
| ViSpeak (Ours, s2) | 7B | 1 fps | ✓ | 79.84 | 88.28 | 83.28 | 81.05 | 76.40 | 75.08 | 70.37 | 65.85 | 77.34 | 34.20 | 74.36 | 42.80 | 35.20 | 61.20 | 74.80 | 53.50 | 38.80 | 36.80 | 44.00 | 38.80 | 39.60 | 62.00 |
| ViSpeak (Ours, s3) | 7B | 1 fps | ✓ | 79.84 | 71.09 | 81.39 | 78.76 | 74.53 | 70.09 | 63.89 | 64.23 | 71.39 | 27.98 | 70.44 | 47.20 | 56.40 | 61.60 | 81.20 | 61.60 | 49.20 | 36.40 | 39.20 | 50.80 | 43.90 | 62.58 |
🔼 This table presents the performance of the ViSpeak model on the StreamingBench benchmark [29], a widely used evaluation set for assessing real-time visual understanding capabilities. The results shown are specifically for the ViSpeak model after undergoing both the second and third stages of fine-tuning. This allows for a comparison of the model’s performance at different stages of training and highlights improvements gained through subsequent training phases. The table enables an assessment of ViSpeak’s performance relative to other models on various subtasks within the StreamingBench, including aspects of omni-source understanding and contextual understanding.
read the caption
Table 4: Performance on StreamingBench [29]. Results for ViSpeak trained after the second and third stage are reported.
| Method | Params | Frames | Real-Time Visual Perception | Backward Tracing | Forward Active Responding | Overall | ||||||||||||
| OCR | ACR | ATR | STU | FPD | OJR | Avg. | EPM | ASI | HLD | Avg. | REC | SSR | CRR | Avg. | ||||
| Proprietary MLLMs | ||||||||||||||||||
| Gemini 1.5 pro [43] | - | - | 87.25 | 66.97 | 80.17 | 54.49 | 68.32 | 67.39 | 70.77 | 68.59 | 75.68 | 52.69 | 62.32 | 35.53 | 74.24 | 61.67 | 57.15 | 65.25 |
| GPT-4o [19] | - | - | 69.13 | 65.14 | 65.52 | 50.00 | 68.32 | 63.68 | 63.63 | 49.83 | 70.95 | 55.38 | 58.72 | 27.58 | 73.21 | 59.40 | 53.40 | 58.58 |
| Open-Source Video MLLMs | ||||||||||||||||||
| Qwen2-VL [47] | 72B | 64 | 72.48 | 56.88 | 77.59 | 52.25 | 74.26 | 61.41 | 65.81 | 51.52 | 73.65 | 63.44 | 62.87 | 37.68 | 60.10 | 45.00 | 47.59 | 58.76 |
| Qwen2-VL [47] | 7B | 64 | 69.13 | 53.21 | 63.79 | 50.56 | 66.34 | 60.87 | 60.65 | 44.44 | 66.89 | 34.41 | 48.58 | 30.09 | 65.66 | 50.83 | 48.86 | 52.70 |
| LLaVA-Next-Video [66] | 7B | 64 | 69.80 | 59.63 | 66.38 | 50.56 | 72.28 | 61.41 | 63.34 | 51.18 | 64.19 | 9.68 | 41.68 | 34.10 | 67.57 | 60.83 | 54.17 | 53.06 |
| LLaVA-OneVision [23] | 7B | 64 | 67.11 | 58.72 | 69.83 | 49.44 | 71.29 | 60.33 | 62.79 | 52.53 | 58.78 | 23.66 | 44.99 | 24.79 | 66.93 | 60.83 | 50.85 | 52.88 |
| InternVL-V2 [6] | 8B | 16 | 68.46 | 58.72 | 68.97 | 44.94 | 67.33 | 55.98 | 60.73 | 43.10 | 61.49 | 27.41 | 44.00 | 25.79 | 57.55 | 52.92 | 45.42 | 50.05 |
| LongVU [42] | 7B | 1 fps | 55.70 | 49.54 | 59.48 | 48.31 | 68.32 | 63.04 | 57.40 | 43.10 | 66.22 | 9.14 | 39.49 | 16.62 | 69.00 | 60.00 | 48.54 | 48.48 |
| VITA 1.5 [17] | 7B | 16 | 74.50 | 60.55 | 70.69 | 53.37 | 63.37 | 58.70 | 63.53 | 46.13 | 54.05 | 24.19 | 41.46 | 37.54 | 60.73 | 62.08 | 53.45 | 55.49 |
| Open-Source Streaming MLLMs | ||||||||||||||||||
| Flash-VStream [62] | 7B | 1 fps | 25.50 | 32.11 | 29.31 | 33.71 | 29.70 | 28.80 | 29.86 | 36.36 | 33.78 | 5.91 | 25.35 | 5.44 | 67.25 | 60.00 | 44.23 | 33.15 |
| VideoLLM-online [2] | 8B | 2 fps | 8.05 | 23.85 | 12.07 | 14.04 | 45.54 | 21.20 | 20.79 | 22.22 | 18.80 | 12.18 | 17.73 | - | - | - | - | - |
| ViSpeak (Ours, s2) | 7B | 1 fps | 75.17 | 58.72 | 71.55 | 51.12 | 74.26 | 66.85 | 66.28 | 59.93 | 48.65 | 63.98 | 57.52 | 33.81 | 68.52 | 60.42 | 54.25 | 61.08 |
🔼 This table presents a comparison of the performance of various large multi-modal language models (MLLMs) on the OVO-Bench benchmark [27]. OVO-Bench assesses streaming video understanding capabilities focusing on backward tracing, real-time visual perception, and forward active responding. The table highlights key performance metrics for each model, with a focus on ViSpeak’s results after the second stage of its three-stage fine-tuning process. This allows for evaluation of ViSpeak’s performance compared to other state-of-the-art models in terms of its streaming video understanding capabilities.
read the caption
Table 5: Performance of various MLLMs on OVO-Bench [27]. Results for ViSpeak trained after the second stage are reported.
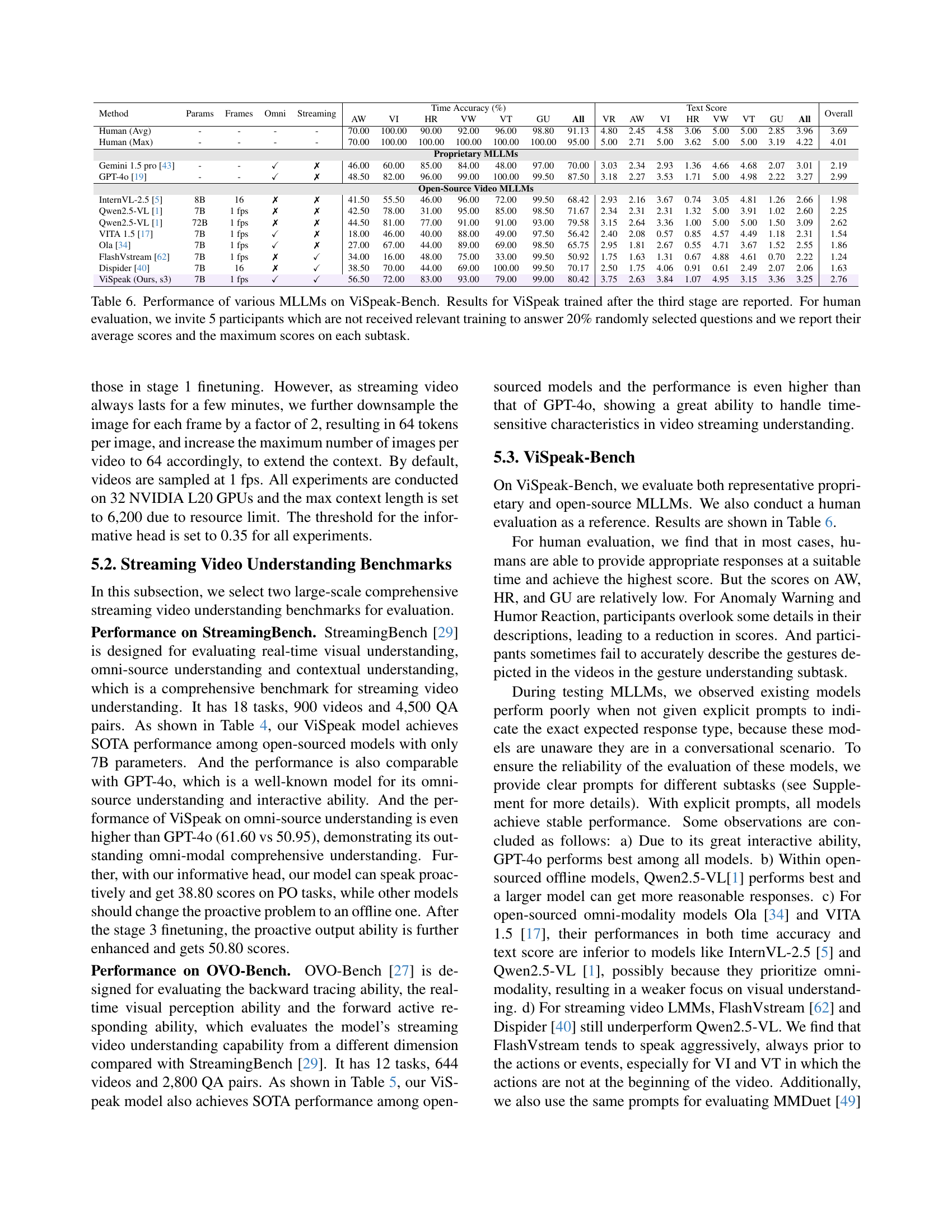
| Method | Params | Frames | Omni | Streaming | Time Accuracy (%) | Text Score | Overall | |||||||||||||
| AW | VI | HR | VW | VT | GU | All | VR | AW | VI | HR | VW | VT | GU | All | ||||||
| Human (Avg) | - | - | - | - | 70.00 | 100.00 | 90.00 | 92.00 | 96.00 | 98.80 | 91.13 | 4.80 | 2.45 | 4.58 | 3.06 | 5.00 | 5.00 | 2.85 | 3.96 | 3.69 |
| Human (Max) | - | - | - | - | 70.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 95.00 | 5.00 | 2.71 | 5.00 | 3.62 | 5.00 | 5.00 | 3.19 | 4.22 | 4.01 |
| Proprietary MLLMs | ||||||||||||||||||||
| Gemini 1.5 pro [43] | - | - | ✓ | ✗ | 46.00 | 60.00 | 85.00 | 84.00 | 48.00 | 97.00 | 70.00 | 3.03 | 2.34 | 2.93 | 1.36 | 4.66 | 4.68 | 2.07 | 3.01 | 2.19 |
| GPT-4o [19] | - | - | ✓ | ✗ | 48.50 | 82.00 | 96.00 | 99.00 | 100.00 | 99.50 | 87.50 | 3.18 | 2.27 | 3.53 | 1.71 | 5.00 | 4.98 | 2.22 | 3.27 | 2.99 |
| Open-Source Video MLLMs | ||||||||||||||||||||
| InternVL-2.5 [5] | 8B | 16 | ✗ | ✗ | 41.50 | 55.50 | 46.00 | 96.00 | 72.00 | 99.50 | 68.42 | 2.93 | 2.16 | 3.67 | 0.74 | 3.05 | 4.81 | 1.26 | 2.66 | 1.98 |
| Qwen2.5-VL [1] | 7B | 1 fps | ✗ | ✗ | 42.50 | 78.00 | 31.00 | 95.00 | 85.00 | 98.50 | 71.67 | 2.34 | 2.31 | 2.31 | 1.32 | 5.00 | 3.91 | 1.02 | 2.60 | 2.25 |
| Qwen2.5-VL [1] | 72B | 1 fps | ✗ | ✗ | 44.50 | 81.00 | 77.00 | 91.00 | 91.00 | 93.00 | 79.58 | 3.15 | 2.64 | 3.36 | 1.00 | 5.00 | 5.00 | 1.50 | 3.09 | 2.62 |
| VITA 1.5 [17] | 7B | 1 fps | ✓ | ✗ | 18.00 | 46.00 | 40.00 | 88.00 | 49.00 | 97.50 | 56.42 | 2.40 | 2.08 | 0.57 | 0.85 | 4.57 | 4.49 | 1.18 | 2.31 | 1.54 |
| Ola [34] | 7B | 1 fps | ✓ | ✗ | 27.00 | 67.00 | 44.00 | 89.00 | 69.00 | 98.50 | 65.75 | 2.95 | 1.81 | 2.67 | 0.55 | 4.71 | 3.67 | 1.52 | 2.55 | 1.86 |
| FlashVstream [62] | 7B | 1 fps | ✗ | ✓ | 34.00 | 16.00 | 48.00 | 75.00 | 33.00 | 99.50 | 50.92 | 1.75 | 1.63 | 1.31 | 0.67 | 4.88 | 4.61 | 0.70 | 2.22 | 1.24 |
| Dispider [40] | 7B | 16 | ✗ | ✓ | 38.50 | 70.00 | 44.00 | 69.00 | 100.00 | 99.50 | 70.17 | 2.50 | 1.75 | 4.06 | 0.91 | 0.61 | 2.49 | 2.07 | 2.06 | 1.63 |
| ViSpeak (Ours, s3) | 7B | 1 fps | ✓ | ✓ | 56.50 | 72.00 | 83.00 | 93.00 | 79.00 | 99.00 | 80.42 | 3.75 | 2.63 | 3.84 | 1.07 | 4.95 | 3.15 | 3.36 | 3.25 | 2.76 |
🔼 Table 6 presents a comprehensive comparison of various large multimodal language models (MLLMs) on the ViSpeak-Bench benchmark. The table showcases the performance of different models across seven distinct subtasks of the Visual Instruction Feedback task, including Visual Wake-up, Anomaly Warning, Gesture Understanding, Visual Reference, Visual Interruption, Humor Reaction, and Visual Termination. The results displayed are for the ViSpeak model after completing its third and final fine-tuning stage, representing a state-of-the-art (SOTA) performance on the benchmark. To establish a baseline for comparison, human evaluation is also included. Five participants, without prior training on the dataset, answered 20% of the questions randomly selected from ViSpeak-Bench. Both the average and maximum scores from these human evaluators are reported for each subtask, providing a direct comparison to the MLLM results and highlighting the challenges inherent in the visual instruction feedback task.
read the caption
Table 6: Performance of various MLLMs on ViSpeak-Bench. Results for ViSpeak trained after the third stage are reported. For human evaluation, we invite 5 participants which are not received relevant training to answer 20% randomly selected questions and we report their average scores and the maximum scores on each subtask.
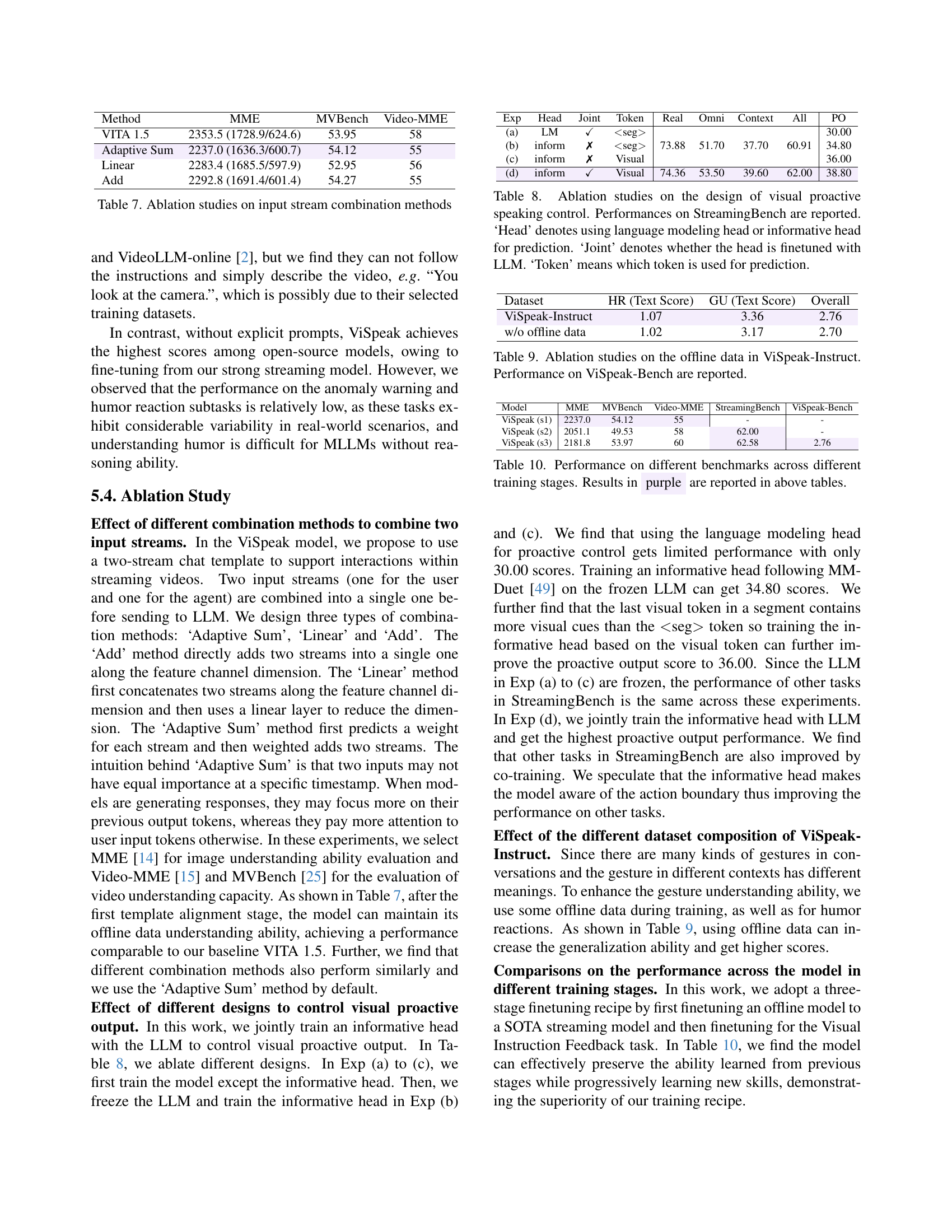
| Method | MME | MVBench | Video-MME |
| VITA 1.5 | 2353.5 (1728.9/624.6) | 53.95 | 58 |
| Adaptive Sum | 2237.0 (1636.3/600.7) | 54.12 | 55 |
| Linear | 2283.4 (1685.5/597.9) | 52.95 | 56 |
| Add | 2292.8 (1691.4/601.4) | 54.27 | 55 |
🔼 This ablation study investigates the impact of different methods for combining user input and model-generated output streams in a streaming video understanding model. It compares three approaches: Adaptive Sum (weighted averaging), Linear (concatenation followed by linear transformation), and Add (direct addition). The results, measured by metrics such as MME (Multi-Modal Evaluation) and scores on MVBench and Video-MME benchmarks, help determine the optimal strategy for integrating dual streams effectively to enhance model performance.
read the caption
Table 7: Ablation studies on input stream combination methods
| Exp | Head | Joint | Token | Real | Omni | Context | All | PO |
| (a) | LM | ✓ | seg | 73.88 | 51.70 | 37.70 | 60.91 | 30.00 |
| (b) | inform | ✗ | seg | 34.80 | ||||
| (c) | inform | ✗ | Visual | 36.00 | ||||
| (d) | inform | ✓ | Visual | 74.36 | 53.50 | 39.60 | 62.00 | 38.80 |
🔼 This ablation study investigates the design of visual proactive speaking control within a streaming video understanding model. The table presents results from experiments on the StreamingBench benchmark, comparing different approaches to controlling when the model speaks based on visual cues. Specifically, it analyzes the impact of using a language modeling head versus an informative head for prediction, whether the head is jointly fine-tuned with the large language model (LLM), and which token (e.g., visual segment token, end-of-segment token) serves as input for the prediction mechanism. The metrics reported likely include performance scores across various sub-tasks within the StreamingBench.
read the caption
Table 8: Ablation studies on the design of visual proactive speaking control. Performances on StreamingBench are reported. ‘Head’ denotes using language modeling head or informative head for prediction. ‘Joint’ denotes whether the head is finetuned with LLM. ‘Token’ means which token is used for prediction.
| Dataset | HR (Text Score) | GU (Text Score) | Overall |
| ViSpeak-Instruct | 1.07 | 3.36 | 2.76 |
| w/o offline data | 1.02 | 3.17 | 2.70 |
🔼 This table presents the results of ablation studies conducted to evaluate the impact of offline data on the ViSpeak-Instruct dataset. Specifically, it shows how the performance of the ViSpeak model changes on the ViSpeak-Bench benchmark when trained with and without offline data. The metrics reported likely include scores for various subtasks within the ViSpeak-Bench (such as gesture understanding, anomaly warning, etc.). Comparing these scores reveals the contribution of offline data to the model’s overall performance, particularly highlighting any improvement or decline in specific areas.
read the caption
Table 9: Ablation studies on the offline data in ViSpeak-Instruct. Performance on ViSpeak-Bench are reported.
| Model | MME | MVBench | Video-MME | StreamingBench | ViSpeak-Bench |
| ViSpeak (s1) | 2237.0 | 54.12 | 55 | - | - |
| ViSpeak (s2) | 2051.1 | 49.53 | 58 | 62.00 | - |
| ViSpeak (s3) | 2181.8 | 53.97 | 60 | 62.58 | 2.76 |
🔼 This table presents a comparison of the ViSpeak model’s performance across three training stages on various benchmarks. It shows the model’s performance on StreamingBench, MVBench, Video-MME, and ViSpeak-Bench, highlighting how performance improves with each subsequent training stage. The results for ViSpeak in the second and third training stages are directly compared to the performance of the model in the first training stage as well as other models mentioned in the paper.
read the caption
Table 10: Performance on different benchmarks across different training stages. Results in purple are reported in above tables.
| Datasets | License |
| OOPS [13] | CC BY-NC-SA 4.0 |
| FunQA [51] | CC BY-NC-SA 4.0 |
| SocialIQA [41] | MIT |
| HIVAU [63] | MIT |
| Social-IQ [61] | MIT |
| IntentQA [24] | N/A |
| Jester [35] | N/A |
| SMILE [20] | N/A |
🔼 This table lists the licenses associated with the source datasets used in the creation of the ViSpeak-Bench and ViSpeak-Instruct datasets. It clarifies the usage rights for each dataset, indicating whether they are licensed under Creative Commons (CC BY-NC-SA 4.0), MIT License, or have no specified license (N/A). This information is crucial for understanding the permissible uses and restrictions of the data included in the ViSpeak project.
read the caption
Table 11: License of source datasets in ViSpeak-Bench and ViSpeak-Instruct.
Full paper#