TL;DR#
Current Multimodal Large Language Models (MLLMs) struggle to integrate reasoning into visual perception, often providing direct responses without deeper analysis. To address this, the paper introduces knowledge-intensive visual grounding (KVG), a new visual grounding task demanding both fine-grained perception and the integration of domain-specific knowledge. The benchmark includes 10 domains with 1.3K curated test cases, highlighting current MLLMs’ limitations in cognitive visual perception.
To overcome these challenges, the paper presents a method that enhances MLLMs with cognitive visual perception capabilities. This approach utilizes (1) an automated data synthesis pipeline for generating high-quality, knowledge-aligned samples, and (2) a two-stage training framework combining supervised fine-tuning and reinforcement learning. Experimental results demonstrate significant improvements in accuracy and generalization compared to direct fine-tuning, achieving state-of-the-art performance on the new benchmark. The approach substantially advances the state-of-the-art in cognitive visual perception.
Key Takeaways#
Why does it matter?#
This paper introduces a novel approach to enhance MLLMs’ cognitive visual perception, addressing limitations in integrating reasoning with visual analysis. It is important because it sets a new benchmark for human-like visual perception and opens new directions for multimodal reasoning research with broad applications.
Visual Insights#

🔼 Figure 1 shows a comparison of DeepPerception and a baseline model’s performance on a visual grounding task. Panel (a) illustrates the difference in their reasoning processes: DeepPerception uses knowledge-driven reasoning to arrive at an answer, while the baseline model provides a direct response without any cognitive steps. Panel (b) presents quantitative results, showing that DeepPerception significantly outperforms the baseline model, demonstrating enhanced cognitive visual perception capabilities that cannot be obtained simply through zero-shot chain-of-thought prompting of the foundational model.
read the caption
Figure 1: (a) DeepPerception employs knowledge-driven reasoning to derive answers, while the baseline model directly outputs predictions without cognitive processing. (b) DeepPerception demonstrates superior cognitive visual perception capabilities that cannot be elicited in the foundation model through simplistic zero-shot CoT prompting.
| Models | Seen Categories | Unseen categories | Avg. | ||||||||||
| Air. | Car | Rep. | Bird | Food | Avg. | Dog | Mol. | Mam. | Flwr. | Ldmk. | Avg. | ||
| Human Evaluation | |||||||||||||
| Human | 59.33 | 66.67 | 50.84 | 44.17 | 65.33 | 57.27 | 48.33 | 45.33 | 51.67 | 64.45 | 68.00 | 55.56 | 56.41 |
| Human + search | 81.33 | 85.56 | 68.00 | 74.17 | 86.67 | 78.03 | 78.89 | 74.00 | 74.17 | 84.44 | 86.67 | 79.63 | 78.83 |
| 70B-Scale MLLMs | |||||||||||||
| InternVL2-76B [6] | 62.50 | 74.04 | 60.00 | 41.04 | 76.43 | 59.22 | 78.40 | 51.11 | 56.25 | 43.82 | 55.42 | 57.90 | 58.68 |
| Qwen2-VL-72B [36] | 63.16 | 75.96 | 59.31 | 40.24 | 77.14 | 59.34 | 80.80 | 42.96 | 59.82 | 65.17 | 66.27 | 62.32 | 60.55 |
| Specialist Grounding Models | |||||||||||||
| YOLO-World [7] | 41.45 | 28.85 | 8.28 | 14.74 | 30.71 | 23.36 | 50.40 | 2.22 | 24.11 | 1.12 | 3.61 | 17.83 | 21.11 |
| G-DINO-1.6-Pro [34] | 39.47 | 41.35 | 48.97 | 23.11 | 24.29 | 33.59 | 44.00 | 40.00 | 39.29 | 32.58 | 27.71 | 37.68 | 35.25 |
| DINO-X [31] | 43.42 | 49.04 | 42.76 | 28.29 | 41.43 | 38.89 | 62.40 | 35.56 | 48.21 | 31.46 | 49.40 | 45.77 | 41.69 |
| 7B-Scale MLLMs | |||||||||||||
| Shikra-7B [3] | 20.39 | 25.96 | 15.17 | 16.33 | 28.57 | 20.33 | 51.20 | 19.26 | 25.00 | 16.85 | 22.89 | 27.94 | 23.43 |
| CogVLM-G [37] | 46.71 | 64.42 | 49.66 | 34.26 | 63.57 | 48.61 | 79.20 | 31.11 | 54.46 | 56.18 | 66.27 | 56.43 | 51.80 |
| DeepSeek-VL2 [40] | 51.32 | 60.57 | 53.10 | 29.08 | 63.57 | 47.98 | 62.40 | 35.56 | 50.89 | 44.94 | 39.76 | 47.06 | 47.60 |
| InternVL2-8B [6] | 46.05 | 52.88 | 40.69 | 26.29 | 50.71 | 40.53 | 64.80 | 34.81 | 45.54 | 41.57 | 25.30 | 43.57 | 41.77 |
| Qwen2-VL-7B [36] | 48.03 | 74.04 | 51.30 | 33.07 | 65.71 | 50.38 | 76.00 | 33.33 | 54.46 | 57.30 | 59.04 | 55.33 | 52.40 |
| Qwen2-VL-7B (SFT) | 53.95 | 79.81 | 53.10 | 31.87 | 67.86 | 52.65 | 84.80 | 34.81 | 54.46 | 40.45 | 53.01 | 56.25 | 54.12 |
| DeepPerception | 69.08 | 86.54 | 64.14 | 41.04 | 77.86 | 63.13 | 85.60 | 40.74 | 58.04 | 59.55 | 61.45 | 60.85 | 62.20 |
🔼 This table presents a quantitative comparison of DeepPerception’s performance against various baseline models on the Knowledge-Intensive Visual Grounding (KVG) task. It shows the accuracy of each model across different categories within the KVG-Bench dataset, both for seen and unseen categories. This allows for an assessment of DeepPerception’s overall performance, its ability to generalize to new categories, and a comparison against other approaches, including both large language models and specialist grounding models.
read the caption
Table 1: KVG results of DeepPerception and baseline models.
In-depth insights#
Cognitive Vision#
Cognitive vision represents a significant leap beyond traditional computer vision, aiming to imbue machines with human-like visual understanding. It’s not just about recognizing objects, but also about comprehending the relationships between them, inferring context, and reasoning about visual information. This involves integrating perception with higher-level cognitive processes such as memory, knowledge, and reasoning. A key aspect is the ability to handle ambiguity and uncertainty, drawing on prior knowledge to make informed interpretations of visual scenes. Cognitive vision systems should be capable of learning and adapting, improving their understanding over time through experience. Applications range from autonomous navigation and robotics to medical image analysis and intelligent surveillance, offering more robust and reliable visual understanding compared to traditional methods. The challenge lies in effectively modeling and implementing these complex cognitive processes within artificial systems, bridging the gap between raw visual data and meaningful semantic understanding.
KVG Benchmark#
The research introduces KVG-Bench, a novel benchmark designed to evaluate cognitive visual perception in MLLMs. KVG-Bench emphasizes fine-grained visual discrimination and domain-specific knowledge integration, challenging MLLMs to move beyond superficial pattern recognition. The benchmark encompasses 10 diverse domains, providing a comprehensive evaluation across various knowledge areas. KVG-Bench is manually curated with 1.3K test cases, ensuring high-quality and reliable assessment. The rigorous construction and manual validation sets a new standard for evaluating cognitive visual perception in multimodal systems, highlighting its meaningful role for advancing research and model capabilities.
DeepPerception#
DeepPerception addresses the limitation of current MLLMs that struggle to integrate reasoning into visual perception, leading to direct responses without deeper analysis. It enhances MLLMs with cognitive visual perception capabilities, consisting of an automated data synthesis pipeline for high-quality, knowledge-aligned training samples and a two-stage training framework. The approach combines supervised fine-tuning for cognitive reasoning and reinforcement learning to optimize perception-cognition synergy. This integration bridges the gap between the inherent cognitive capabilities of MLLMs and human-like visual perception, showing significant performance gains and superior cross-domain generalization compared to direct fine-tuning methods. DeepPerception offers a way to emulate human-like visual perception with structured knowledge integration.
RL for Perception#
Reinforcement Learning (RL) offers a compelling framework for training perception systems, moving beyond traditional supervised learning. The core idea is to train agents to interact with an environment and learn perceptual representations that are useful for decision-making. This is especially valuable when ground truth labels for perception are scarce or expensive to obtain. RL can learn directly from raw sensory inputs (e.g., images, audio), optimizing perceptual features that maximize task performance. The reward function in RL acts as a form of implicit supervision, guiding the learning of relevant perceptual attributes. For instance, an RL agent learning to navigate would develop visual features sensitive to obstacles and landmarks. Furthermore, RL enables learning of active perception strategies, where the agent controls its sensors to gather the most informative data. This contrasts with passive perception systems that simply process whatever input they receive. Challenges in applying RL to perception include designing effective reward functions, handling partial observability, and ensuring generalization to novel environments. Despite these challenges, RL for perception holds immense potential for creating robust, adaptable, and task-driven perceptual systems.
Domain Expertise#
Domain expertise is paramount for fine-grained visual tasks. The paper reveals that current MLLMs struggle to integrate domain knowledge into visual perception, often producing direct answers without deeper analysis. Human experts excel due to their ability to leverage domain knowledge to refine perceptual features. The KVG task highlights this gap, requiring both fine-grained perception and domain-specific knowledge integration. The results show a significant performance elevation in the Open-Book Setting, which validates the importance of the synergistic integration of expert-level knowledge and fine-grained visual comparison for advancing cognitive visual perception in MLLMs. Data augmentation is key.
More visual insights#
More on figures

🔼 Figure 2 shows two aspects of the KVG-Bench dataset. (a) Illustrates that KVG-Bench images contain multiple entities of the same subordinate category. The example given shows various Boeing aircraft models (777, 767, 757, 747, 737, 727, 717, 707) within a single image. This highlights the fine-grained nature of the dataset and the need for a model to distinguish between visually similar objects. (b) Demonstrates the high diversity across categories and entities in KVG-Bench. This ensures the dataset is comprehensive in terms of the range of visual concepts represented.
read the caption
Figure 2: (a) KVG-Bench images contain multiple subordinate-category entities (e.g., Boeing 777, 767, 757, 747, 737, 727, 717, 707 from top to bottom in the left image); (b) KVG-Bench exhibits high diversity across categories and entities.

🔼 This figure illustrates the DeepPerception model’s architecture, which consists of a data engine and a two-stage training framework. The data engine automatically synthesizes high-quality training data by leveraging existing fine-grained visual recognition datasets, addressing the scarcity of suitable data for knowledge-intensive visual grounding. The two-stage training framework first employs supervised fine-tuning with chain-of-thought prompting to establish foundational cognitive capabilities, followed by reinforcement learning to optimize perception-cognition synergy. The figure visually depicts the data flow and processing steps in both the data generation and model training phases.
read the caption
Figure 3: Overview of the proposed data engine and two-stage training framework.

🔼 This figure presents a bar chart analysis comparing the performance of DeepPerception and a baseline model on a knowledge evaluation task. The x-axis represents different domains (both known and unknown to the model), while the y-axis indicates accuracy. The bars show that DeepPerception consistently outperforms the baseline model across all domains, particularly exhibiting a much larger improvement in domains where the model already possesses some knowledge. The significant performance difference, especially noticeable in known domains, highlights the effectiveness of DeepPerception’s structured knowledge integration in visual perception. This suggests that DeepPerception’s improvements stem from cognitive processes that leverage knowledge rather than solely relying on superficial visual feature recognition.
read the caption
Figure 4: Knowledge evaluation results. DeepPerception exhibits greater improvement on known entities across domains, evidencing cognitive visual perception with structured knowledge integration rather than superficial perceptual improvements.

🔼 This figure displays the KL divergence between the probability distributions of response tokens generated by stage-2 models (trained with either CoT-SFT or GRPO) and the stage-1 model. The KL divergence is broken down into two parts: one measuring the difference in the reasoning process (CoT) and another measuring the difference in the final answers. The results show that CoT-SFT primarily improves the reasoning aspect (higher CoT divergence), while GRPO mainly refines the perceptual precision (higher answer divergence). This suggests a synergistic relationship between the two training stages, with CoT-SFT establishing cognitive abilities and GRPO enhancing perception-cognition alignment.
read the caption
Figure 5: KL Divergence analysis between the probability distribution of response tokens from stage-2 models and the stage-1 model reveals complementary specialization: CoT-SFT focuses on knowledge-guided reasoning process (higher CoT divergence) while GRPO optimizes perceptual precision (elevated answer divergence), synergistically bridging cognitive processing and perception refinement.

🔼 This figure presents a comparative case study of DeepPerception and Qwen2-VL-7B on two distinct tasks: Knowledge-Intensive Visual Grounding (KVG) and Fine-grained Visual Recognition (FGVR). The top half showcases KVG examples, highlighting DeepPerception’s superior ability to use reasoning and visual analysis to accurately identify objects, even amidst similar-looking distractors. It contrasts this with Qwen2-VL-7B’s less accurate responses. The bottom half illustrates FGVR examples. It again demonstrates DeepPerception’s enhanced performance in distinguishing between closely related objects, due to its cognitive reasoning capabilities. This contrasts with Qwen2-VL-7B which has a lower success rate in this challenging fine-grained visual categorization task.
read the caption
Figure 6: Case study comparing DeepPerception and Qwen2-VL-7B on KVG-Bench (top) and FGVR (bottom).

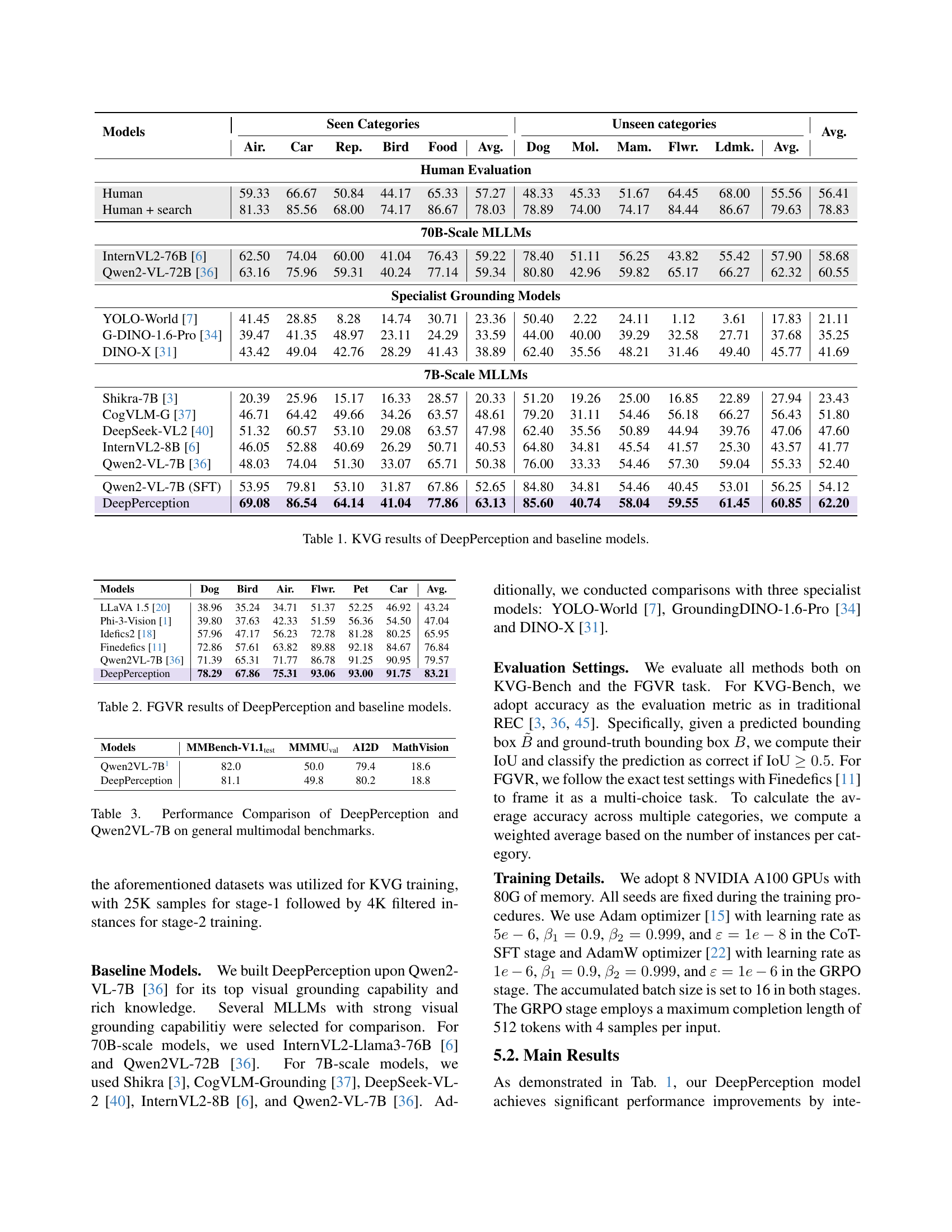
🔼 This figure displays an example of Chain-of-Thought (CoT) reasoning generated by the Qwen2-VL-72B model. The CoT outlines the steps the model took to identify a specific bird in an image. It begins with a planning phase, which lays out the steps involved in the identification process. This is followed by a visual analysis step, detailing the visual characteristics of the target bird and other birds present in the image. A comparison phase then differentiates the target bird based on the visual features described. Finally, the CoT concludes by identifying the specific bird based on its distinguishing characteristics compared to others in the image.
read the caption
Figure 7: Example of Chain-of-Thought data generated by Qwen2-VL-72B.
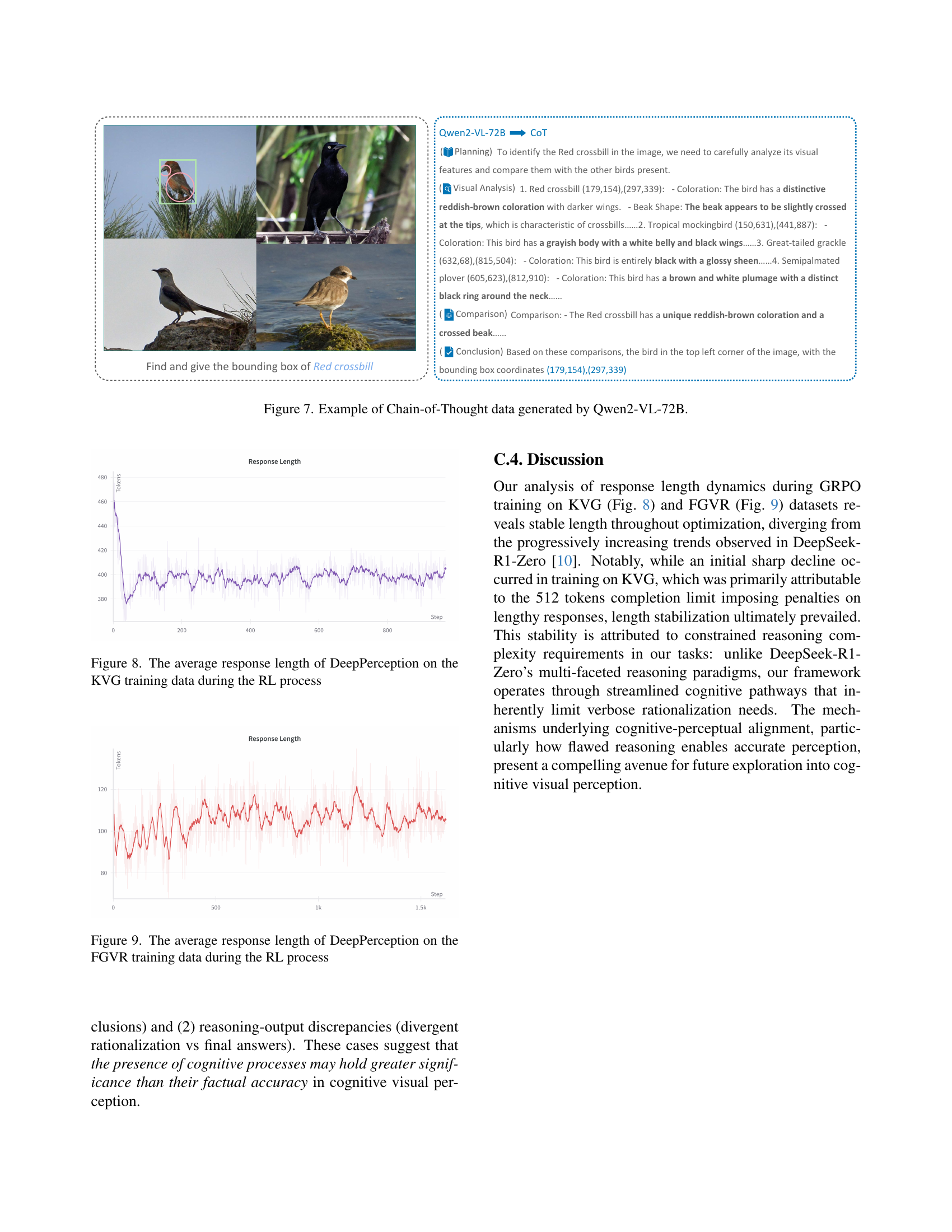
🔼 This figure shows a line graph illustrating the average length of responses generated by the DeepPerception model during the reinforcement learning (RL) phase of its training on the Knowledge-Intensive Visual Grounding (KVG) dataset. The x-axis represents the training step, while the y-axis indicates the average number of tokens in the model’s responses. The graph reveals a trend of decreasing response length during initial training, followed by stabilization to a consistent length. This trend suggests the model learns efficient reasoning strategies during RL training, avoiding excessive or unnecessary verbosity in its responses. The consistent length may also reflect the limited complexity inherent to the KVG task which does not require prolonged or extensive deliberation for accurate perception.
read the caption
Figure 8: The average response length of DeepPerception on the KVG training data during the RL process

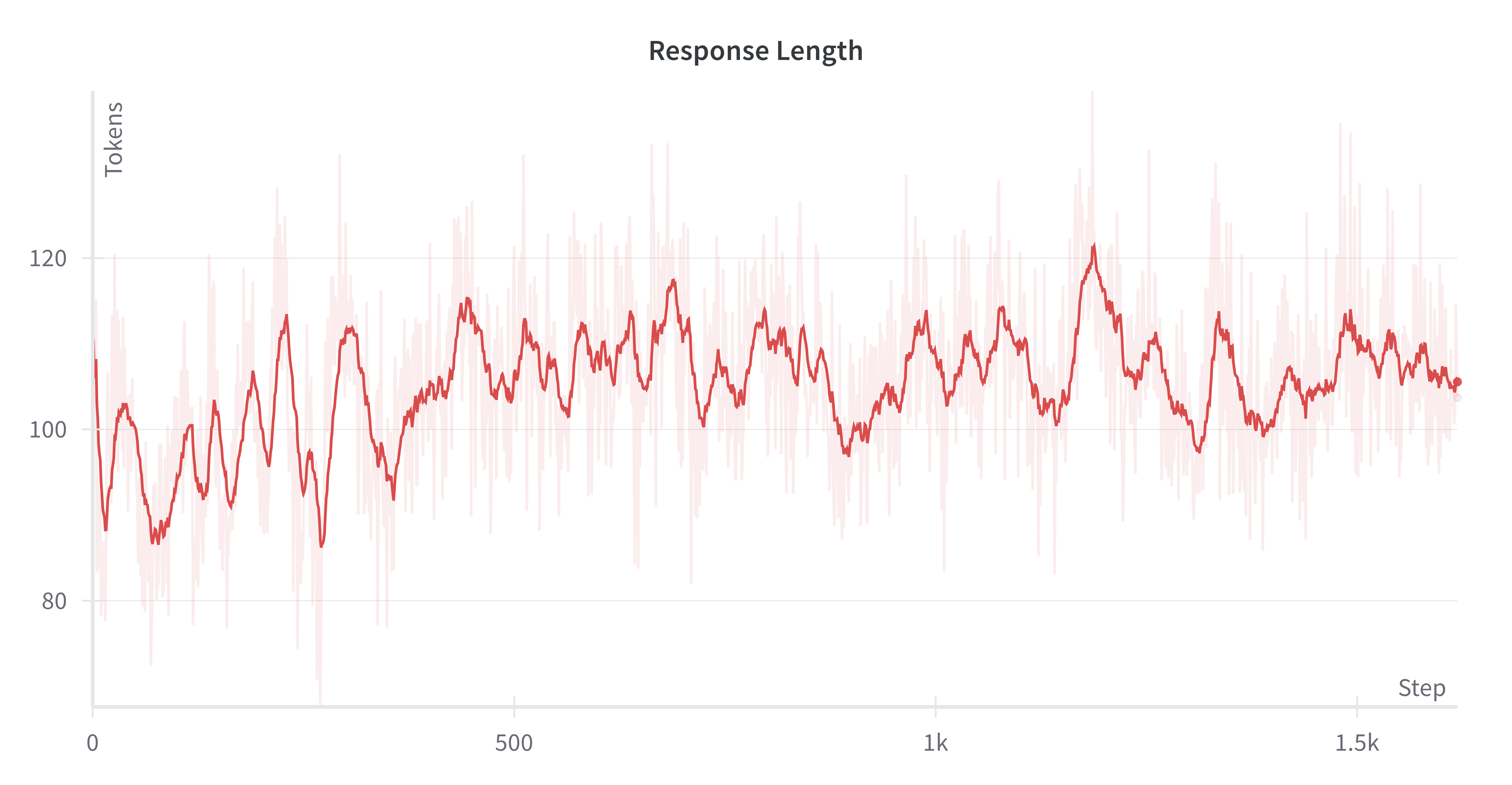
🔼 This figure shows a line graph illustrating the average response length of the DeepPerception model during the reinforcement learning (RL) process on the Fine-grained Visual Recognition (FGVR) training dataset. The x-axis represents the training steps, while the y-axis indicates the average response length in terms of the number of tokens. The graph displays the trend of response length over the RL process, offering insights into the model’s behavior and performance.
read the caption
Figure 9: The average response length of DeepPerception on the FGVR training data during the RL process

🔼 This figure showcases a comparative case study between DeepPerception and Qwen2-VL-7B on the KVG-Bench dataset. It presents several example queries and highlights how DeepPerception leverages cognitive visual perception to successfully identify and locate objects in images, while Qwen2-VL-7B struggles with accurate grounding, particularly for complex queries requiring in-depth visual analysis and domain knowledge. Each example includes the query, the model’s response (including reasoning chains if available for DeepPerception), and a visual indication (✓ or ✗) of correctness. The differences highlight DeepPerception’s superior performance on knowledge-intensive visual grounding.
read the caption
Figure 10: Case study comparing DeepPerception and Qwen2-VL-7B on KVG-Bench

🔼 Figure 11 presents a comparative case study showcasing DeepPerception and Qwen2-VL-7B’s performance on Fine-grained Visual Recognition (FGVR) tasks. The figure highlights several examples where each model is asked to identify specific entities within images. For each example, the visual analysis, comparison process, and conclusion drawn by each model are displayed. This visual comparison demonstrates DeepPerception’s superior ability to leverage visual clues and incorporate knowledge to arrive at precise answers, contrasting with Qwen2-VL-7B which sometimes makes less accurate or even completely incorrect identifications.
read the caption
Figure 11: Case study comparing DeepPerception and Qwen2-VL-7B on FGVR
More on tables
| Models | Dog | Bird | Air. | Flwr. | Pet | Car | Avg. |
|---|---|---|---|---|---|---|---|
| LLaVA 1.5 [20] | 38.96 | 35.24 | 34.71 | 51.37 | 52.25 | 46.92 | 43.24 |
| Phi-3-Vision [1] | 39.80 | 37.63 | 42.33 | 51.59 | 56.36 | 54.50 | 47.04 |
| Idefics2 [18] | 57.96 | 47.17 | 56.23 | 72.78 | 81.28 | 80.25 | 65.95 |
| Finedefics [11] | 72.86 | 57.61 | 63.82 | 89.88 | 92.18 | 84.67 | 76.84 |
| Qwen2VL-7B [36] | 71.39 | 65.31 | 71.77 | 86.78 | 91.25 | 90.95 | 79.57 |
| DeepPerception | 78.29 | 67.86 | 75.31 | 93.06 | 93.00 | 91.75 | 83.21 |
🔼 This table presents a comparison of the performance of DeepPerception against several baseline models on fine-grained visual recognition (FGVR) tasks. It shows the accuracy achieved by each model on several FGVR datasets, providing a quantitative assessment of DeepPerception’s effectiveness in this challenging visual perception domain compared to existing methods.
read the caption
Table 2: FGVR results of DeepPerception and baseline models.
| Models | MMBench-V1.1test | MMMUval | AI2D | MathVision |
|---|---|---|---|---|
| Qwen2VL-7B111reproduced using VLMEvalKit | 82.0 | 50.0 | 79.4 | 18.6 |
| DeepPerception | 81.1 | 49.8 | 80.2 | 18.8 |
🔼 This table presents a quantitative comparison of DeepPerception and Qwen2VL-7B’s performance across various general-purpose multimodal benchmarks. It allows for a direct assessment of DeepPerception’s capabilities beyond the specialized knowledge-intensive visual grounding task (KVG) for which it was primarily designed. The benchmarks likely assess a range of skills such as reasoning, knowledge retrieval, and visual understanding. By comparing DeepPerception against Qwen2VL-7B, the table helps gauge the extent to which DeepPerception’s architectural enhancements improve generalized multimodal performance, rather than just performance on a narrowly defined KVG task.
read the caption
Table 3: Performance Comparison of DeepPerception and Qwen2VL-7B on general multimodal benchmarks.
| Stage | Method | In Domain | Out of Domain | Overall |
|---|---|---|---|---|
| 1 | SFT | 52.65 | 56.25 | 54.12 |
| CoT-SFT | 56.82 | 56.80 | 56.81 | |
| 2 | CoT-SFT | 56.94 | 56.99 | 56.96 |
| GRPO | 63.13 | 60.85 | 62.20 |
🔼 This ablation study analyzes the contribution of each stage in the proposed two-stage training framework for DeepPerception. It compares the model’s performance on the in-domain and out-of-domain categories of the KVG benchmark across different training stages: (1) Supervised Fine-Tuning (SFT), (2) Chain-of-Thought Supervised Fine-Tuning (COT-SFT), and (3) Reinforcement Learning with Group Relative Policy Optimization (GRPO). The results highlight how each stage impacts the overall performance and, specifically, the model’s ability to generalize across different domains.
read the caption
Table 4: Ablation study on the effectiveness of the proposed two-stage cognitive training framework.
Full paper#