TL;DR#
Current image generation methods lack precise instance control, resulting in attribute leakage and limiting user-directed creation. Even state-of-the-art models like FLUX and 3DIS face challenges in maintaining attribute fidelity across multiple instances.
To tackle these issues, DreamRenderer, a plug-and-play controller built upon the FLUX model, is introduced. This training-free approach grants users fine-grained control over each region/instance using bounding boxes/masks, preserving visual harmony. Key innovations include Bridge Image Tokens for hard text attribute binding and Hard Image Attribute Binding applied to vital layers.
Key Takeaways#
Why does it matter?#
This paper introduces DreamRenderer, an innovative approach to control image generation, holding promise for content creation. It enhances existing layout-to-image models, offering new avenues for visual synthesis and controllable AI research.
Visual Insights#

🔼 Figure 1 illustrates the architecture and functionality of DreamRenderer. Panel (a) presents a schematic overview of the DreamRenderer pipeline, showing how depth or canny maps, along with text prompts for individual instances and a global caption, are processed to generate an image. The process involves encoding via a Variational Autoencoder (VAE) and the T5 text encoder, followed by joint attention mechanisms. Panel (b) details the attention mechanisms within the joint attention module. It highlights three key aspects: Hard Text Attribute Binding, Hard Image Attribute Binding, and Soft Image Attribute Binding. Different patterns visually distinguish between image, text, and bridge image tokens in the attention maps. Color-coding further differentiates tokens originating from different instances (e.g., an ice cat, a fire dog, or global context).
read the caption
Figure 1: The overview of DreamRenderer. (§ 3.3) (a) The pipeline of DreamRenderer. (b) Attention maps in Joint Attention, which includes 1) Hard Text Attribute Binding (§ 3.5), 2) Hard Image Attribute Binding (§ 3.6), and 3) Soft Image Attribute Binding (§ 3.6). In the attention maps shown in (b), rows represent queries and columns represent keys. We use different patterns to distinguish between image tokens , text tokens , and bridge image tokens , while different colors ( for an ice cat, for a fire dog and for the global text tokens and background image tokens) represent tokens from different instances.
| Method | SR (%) | ISR (%) | MIoU (%) | AP (%) | CLIP |
| FLUX∗ | 16.38 | 64.95 | 59.71 | 31.88 | 19.03 |
| 3DIS∗ | 18.07 | 68.78 | 62.97 | 31.36 | 19.46 |
| Ours∗ | 23.28 | 74.61 | 66.95 | 37.00 | 20.03 |
| FLUX† | 44.83 | 85.13 | 76.86 | 50.72 | 19.82 |
| 3DIS† | 53.88 | 90.33 | 81.26 | 54.26 | 20.23 |
| Ours† | 62.50 | 94.51 | 84.36 | 58.95 | 20.74 |
🔼 This table presents a quantitative comparison of different methods on the COCO-POS benchmark. The COCO-POS benchmark evaluates the ability of models to generate images based on depth or canny maps (edge detection) and corresponding layouts. The table compares the performance of FLUX (a baseline model) and 3DIS (another state-of-the-art model) against the proposed DreamRenderer method, showing the success ratio for the entire image (SR), the success ratio for individual instances (ISR), mean intersection over union (MIoU) indicating the accuracy of instance localization, and average precision (AP) reflecting the overall quality of generated instances. Results are broken down for both canny-guided and depth-guided generation scenarios.
read the caption
Table 1: Quantitative results on COCO-POS benchmark (§ 4.2). SR: Success Ratio of the Entire Image, ISR: Instance Success Ratio, MIoU: Mean Intersection over Union, AP: Average Precision. ∗*∗: canny-guided. ††\dagger†: depth-guided.
In-depth insights#
Text Binding Core#
Text Binding Core focuses on effectively linking textual descriptions with visual elements in image generation, particularly when dealing with multiple instances or regions. A key challenge is ensuring that the text embeddings accurately capture and convey the desired attributes for each instance, preventing attribute leakage or confusion. The goal is to achieve granular control over the generated content, allowing users to specify the characteristics of individual elements within a scene while maintaining overall visual harmony. Techniques include manipulating attention mechanisms to guide the model in associating text tokens with the correct visual tokens, potentially using intermediate ‘bridge’ tokens or selectively applying constraints in different layers of the model to balance precise control with image quality.
Layer Sensitivity#
While not explicitly addressed under the heading “Layer Sensitivity”, the paper implicitly explores this concept through its analysis of the FLUX model’s layers. The decision to apply Hard Image Attribute Binding only in the intermediate layers while using Soft Image Attribute Binding elsewhere demonstrates an understanding of varying roles within the network. Specifically, the paper observes that layers near the input and output encode global information, while the middle layers are responsible for rendering individual instances. This indicates a deliberate sensitivity to each layer, aiming to leverage each layer strength for multi-instance generation. By selectively applying Hard Image Attribute Binding where it is most effective, DreamRenderer ensures precise instance control without sacrificing overall image coherence.
Instance Control#
Instance control in text-to-image generation aims to provide users with precise control over individual objects or regions within an image. This is crucial for creating complex scenes where each element needs specific attributes and spatial arrangements. Challenges arise from attribute leakage where properties intended for one instance bleed into another, and maintaining overall visual harmony while enforcing instance-specific constraints. Effective instance control requires mechanisms to ensure that the generated content for each instance accurately reflects the user’s input, while also integrating seamlessly with the surrounding context. Techniques include manipulating attention mechanisms to focus on relevant image regions, and using specialized modules to ensure each instance’s attributes are rendered correctly. Evaluating instance control involves assessing both the accuracy of individual instance generation and the overall coherence of the generated scene. Methods that can effectively balance these two aspects offer more robust and user-friendly image generation capabilities.
Flux Enhancement#
While the provided document doesn’t explicitly contain a section titled ‘Flux Enhancement,’ we can infer its potential meaning in the context of image generation. It likely refers to techniques aimed at improving the flow and integration of information within the FLUX model or similar architectures. This could involve strategies to strengthen the relationship between text and image embeddings, ensuring visual outputs accurately reflect textual prompts. ‘Flux Enhancement’ might address challenges related to attention mechanisms, optimizing them to prevent attribute leakage and maintain visual harmony. The paper mentions addressing challenges related to text embeddings lacking intrinsic visual information. Thus, flux enhancement could involve better incorporation of visual data into text embeddings during joint attention. Furthermore, considering the paper’s focus on instance control, ‘Flux Enhancement’ could encompass methods to enhance the flow of information specific to each controlled instance or region, allowing for more precise and consistent generation. Enhancing flux might also involve improving the model’s ability to process conditional inputs like depth or canny maps, leading to better adherence to structural guidance during image synthesis. In essence, the term likely represents an ongoing effort to optimize information processing within generative models for improved visual fidelity and controllable image synthesis by better information flow which is described using the word flux. Finally, achieving the precise attribute control with minimal trade-off in image quality falls under flux enhancement.
Plug-and-Play#
Plug-and-Play methods offer a compelling paradigm for image generation by enabling modular control without retraining. These approaches usually involve a pre-trained model which is then used with additional modules or constraints that guide the generation process. The advantage lies in the ability to control specific aspects like object attributes or scene layout. The challenge is to maintain high image quality while ensuring that the injected controls are faithfully reflected in the output without introducing artifacts. DreamRenderer exemplifies this by focusing on instance-level control, a notoriously difficult area where attributes often ‘bleed’ between instances. Ensuring both fidelity to individual instance descriptions and overall image coherence demands careful attention to how controls are integrated.
More visual insights#
More on figures

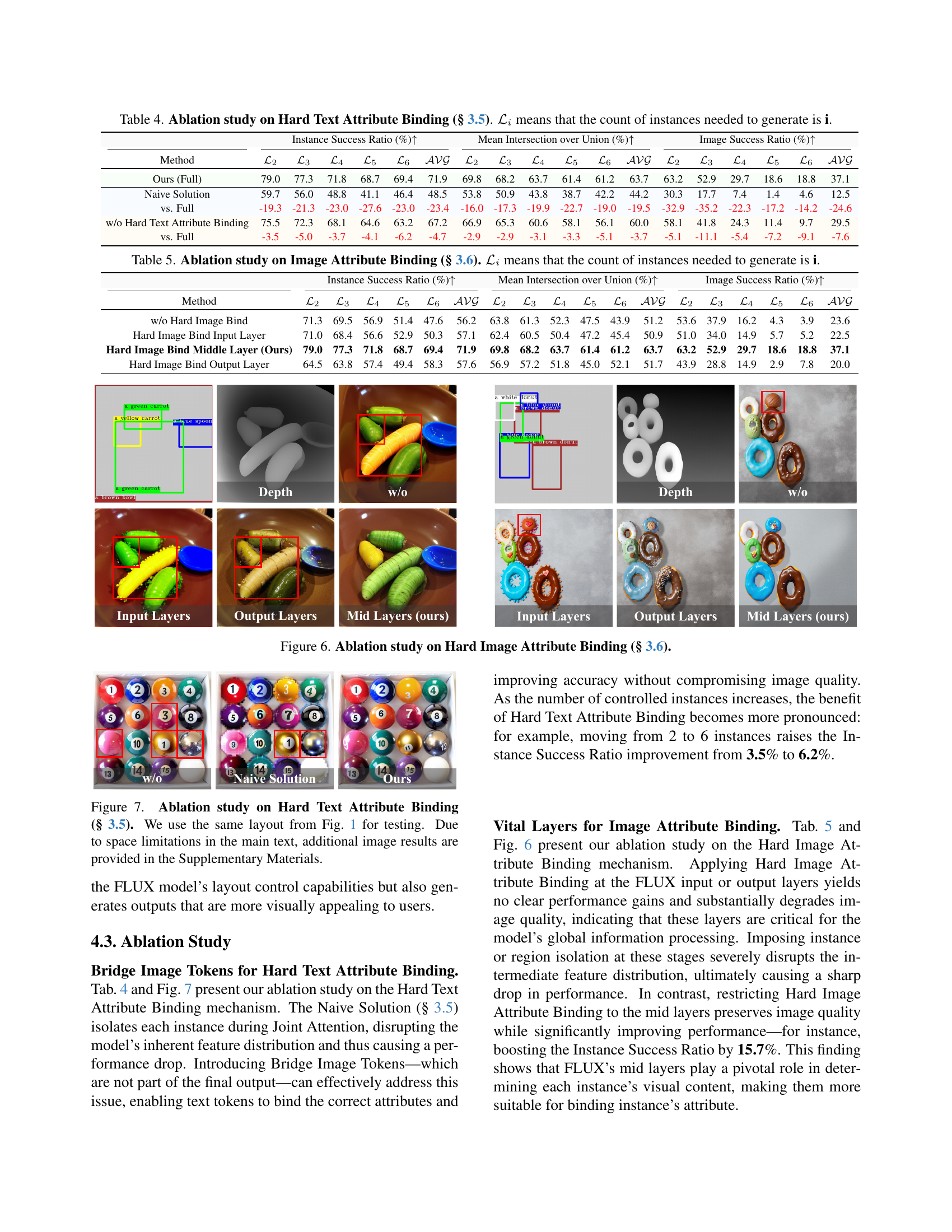
🔼 This figure displays the results of an experiment to determine the optimal layer within the FLUX model to apply Hard Image Attribute Binding. Hard Image Attribute Binding is a technique used to improve the accuracy of generating images by ensuring that each instance’s image tokens only attend to themselves, preventing attribute leakage between instances. The experiment involved applying this technique layer by layer within the FLUX model, and the results show that applying it to the input or output layers actually decreased performance. However, applying it to the middle layers resulted in performance improvements. This highlights the importance of selecting the right layer for this binding technique for optimal image generation.
read the caption
Figure 2: Vital Binding Layer Search (§ 3.6). We apply Hard Image Attribute Binding layer by layer and observe that applying it in the FLUX model’s input or output layers degrades performance, whereas applying it in the middle layers yields improvements.

🔼 Figure 4 shows a qualitative comparison of the results obtained using FLUX and 3DIS, compared to the results from the proposed method, DreamRenderer, on the COCO-POS benchmark. The figure visually demonstrates the effectiveness of DreamRenderer in generating images that adhere more closely to the specified depth map and layout than the existing methods (FLUX and 3DIS). Each row presents a sample image, with the top row showing depth and layout, and the bottom row showing the generated results using FLUX, 3DIS and DreamRenderer respectively. The figure illustrates DreamRenderer’s enhanced ability to control multiple instances (e.g., different objects) within a single image, and achieve better alignment with both depth and layout, resulting in better quality generation.
read the caption
Figure 3: Qualitative Comparison on the COCO-POS benchmark (§ 4.2).

🔼 Figure 4 shows a qualitative comparison of the results obtained using the DreamRenderer method on the COCO-MIG benchmark. The COCO-MIG benchmark assesses the model’s capacity to generate images matching specified layouts and instance attributes. The figure visually compares the images generated by different methods, including GLIGEN, InstanceDiffusion, MIGC, and 3DIS, both with and without DreamRenderer integrated. This comparison highlights DreamRenderer’s ability to improve the accuracy of instance attributes and enhance the overall image quality when combined with these state-of-the-art layout-to-image models.
read the caption
Figure 4: Qualitative comparison on the COCO-MIG benchmark (§ 4.2).

🔼 This ablation study analyzes the impact of applying Hard Image Attribute Binding at different layers of the FLUX model. It compares the performance using Hard Image Attribute Binding applied to input, middle, and output layers, against a baseline without Hard Image Attribute Binding. The results are shown across various metrics, including instance success ratio, mean intersection over union, and image success ratio, for different numbers of instances. The study aims to identify the optimal layer(s) for applying this technique to balance the accuracy of individual instance rendering with the overall image coherence.
read the caption
Figure 5: Ablation study on Hard Image Attribute Binding (§ 3.6).

🔼 Figure 6 shows the results of an ablation study on the Hard Text Attribute Binding method (section 3.5). The study uses the same layout as Figure 1 to compare different versions of the method. The images demonstrate the effect of the Hard Text Attribute Binding, showing how it improves the accuracy of generating multiple instances within the image. Due to space constraints, only a subset of the images from the ablation study are shown in the main paper; more examples are available in the supplementary materials.
read the caption
Figure 6: Ablation study on Hard Text Attribute Binding (§ 3.5). We use the same layout from Fig. LABEL:fig:teaser for testing. Due to space limitations in the main text, additional image results are provided in the Supplementary Materials.
More on tables
| Instance Success Ratio (%) | Mean Intersection over Union (%) | Image Success Ratio (%) | ||||||||||||||||
| Method | ||||||||||||||||||
| GLIGEN [CVPR23] | 41.6 | 31.6 | 27.0 | 28.3 | 27.7 | 29.7 | 37.1 | 29.2 | 25.1 | 26.7 | 25.5 | 27.5 | 16.8 | 4.6 | 0.0 | 0.0 | 0.0 | 4.4 |
| +Ours | 75.5 | 73.6 | 67.9 | 62.6 | 66.2 | 67.8 | 64.3 | 63.5 | 58.1 | 54.2 | 56.6 | 58.2 | 57.4 | 45.1 | 27.0 | 11.4 | 13.0 | 31.2 |
| vs. GLIGEN | +33.9 | +42.0 | +40.9 | +34.3 | +38.5 | +38.1 | +27.2 | +34.3 | +33.0 | +27.5 | +31.1 | +30.7 | +40.6 | +40.5 | +27.0 | +11.4 | +13.0 | +26.8 |
| InstanceDiff [CVPR24] | 58.4 | 51.9 | 55.1 | 49.1 | 47.7 | 51.3 | 53.0 | 47.4 | 49.2 | 43.7 | 42.6 | 46.0 | 37.4 | 15.0 | 11.5 | 5.0 | 2.6 | 14.5 |
| +Ours | 77.4 | 75.4 | 72.5 | 65.3 | 67.2 | 70.1 | 68.8 | 66.4 | 63.0 | 57.8 | 57.5 | 61.2 | 58.7 | 45.8 | 34.5 | 13.6 | 17.5 | 34.4 |
| vs. InstanceDiff | +19.0 | +23.5 | +17.4 | +16.2 | +19.5 | +18.8 | +15.8 | +19.0 | +13.8 | +14.1 | +14.9 | +15.2 | +21.3 | +30.8 | +23.0 | +8.6 | +14.9 | +19.9 |
| MIGC [CVPR24] | 74.8 | 66.2 | 67.2 | 65.3 | 66.1 | 67.1 | 64.5 | 56.9 | 57.0 | 55.5 | 57.3 | 57.5 | 54.8 | 32.7 | 22.3 | 12.9 | 17.5 | 28.4 |
| +Ours | 79.7 | 76.3 | 70.6 | 67.7 | 69.4 | 71.4 | 68.8 | 65.0 | 60.3 | 57.6 | 59.3 | 61.0 | 64.5 | 47.7 | 30.4 | 18.6 | 20.1 | 36.7 |
| vs. MIGC | +4.9 | +10.1 | +3.4 | +2.4 | +3.3 | +4.3 | +4.3 | +8.1 | +3.3 | +2.1 | +2.0 | +3.5 | +9.7 | +15.0 | +8.1 | +5.7 | +2.6 | +8.3 |
| 3DIS [ICLR25] | 76.5 | 68.4 | 63.3 | 58.1 | 58.9 | 62.9 | 67.3 | 61.2 | 56.4 | 52.3 | 52.7 | 56.2 | 61.3 | 36.0 | 25.0 | 12.9 | 11.7 | 29.7 |
| +Ours | 79.0 | 77.3 | 71.8 | 68.7 | 69.4 | 71.9 | 69.8 | 68.2 | 63.7 | 61.4 | 61.2 | 63.7 | 63.2 | 52.9 | 29.7 | 18.6 | 18.8 | 37.1 |
| vs. 3DIS | +2.5 | +8.9 | +8.5 | +10.6 | +10.5 | +9.0 | +2.5 | +7.0 | +7.3 | +9.1 | +8.5 | +7.5 | +1.9 | +16.9 | +4.7 | +5.7 | +7.1 | +7.4 |
🔼 Table 2 presents a quantitative analysis of the COCO-MIG benchmark results. The benchmark evaluates the performance of different methods in generating images with multiple instances (regions) according to given specifications. The table shows the performance metrics for several methods, including the proposed approach, across different numbers of instances (indicated by Li, where i is the number of instances). Metrics include instance success rate (ISR), mean intersection over union (mIoU), and image success rate (SR). Higher values indicate better performance.
read the caption
Table 2: Quantitative results on COCO-MIG benchmark (§ 4.2). ℒisubscriptℒ𝑖\mathcal{L}_{i}caligraphic_L start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT means that the count of instances needed to generate is i.
| Method | Layout Accuracy | Visual Quality |
| FLUX | 3.51 | 3.26 |
| 3DIS | 3.63 | 3.31 |
| Ours | 4.04 | 3.80 |
🔼 This table presents the results of a user study evaluating the perceptual quality of images generated by three different methods: FLUX, 3DIS, and the proposed DreamRenderer. Thirty-one participants rated the layout accuracy and overall visual quality of images generated by each method on a 1-5 scale (1 being the lowest and 5 being the highest). The scores provide a subjective assessment of the models’ performance in terms of how well they generate images that both adhere to the input layout and look visually appealing.
read the caption
Table 3: User study results with 31 participants (1-5 scale)(§ 4.2).
| Instance Success Ratio (%) | Mean Intersection over Union (%) | Image Success Ratio (%) | ||||||||||||||||
| Method | ||||||||||||||||||
| Ours (Full) | 79.0 | 77.3 | 71.8 | 68.7 | 69.4 | 71.9 | 69.8 | 68.2 | 63.7 | 61.4 | 61.2 | 63.7 | 63.2 | 52.9 | 29.7 | 18.6 | 18.8 | 37.1 |
| Naive Solution | 59.7 | 56.0 | 48.8 | 41.1 | 46.4 | 48.5 | 53.8 | 50.9 | 43.8 | 38.7 | 42.2 | 44.2 | 30.3 | 17.7 | 7.4 | 1.4 | 4.6 | 12.5 |
| vs. Full | -19.3 | -21.3 | -23.0 | -27.6 | -23.0 | -23.4 | -16.0 | -17.3 | -19.9 | -22.7 | -19.0 | -19.5 | -32.9 | -35.2 | -22.3 | -17.2 | -14.2 | -24.6 |
| w/o Hard Text Attribute Binding | 75.5 | 72.3 | 68.1 | 64.6 | 63.2 | 67.2 | 66.9 | 65.3 | 60.6 | 58.1 | 56.1 | 60.0 | 58.1 | 41.8 | 24.3 | 11.4 | 9.7 | 29.5 |
| vs. Full | -3.5 | -5.0 | -3.7 | -4.1 | -6.2 | -4.7 | -2.9 | -2.9 | -3.1 | -3.3 | -5.1 | -3.7 | -5.1 | -11.1 | -5.4 | -7.2 | -9.1 | -7.6 |
🔼 This ablation study analyzes the impact of the Hard Text Attribute Binding method introduced in section 3.5. The table shows the performance of the model (measured by Instance Success Ratio, Mean Intersection over Union, and Image Success Ratio) when generating images with varying numbers of instances (from 2 to 6). Different configurations are evaluated: the full model with Hard Text Attribute Binding, a naive solution without any binding, and variations to explore different binding strategies. The results demonstrate the effectiveness of the proposed Hard Text Attribute Binding in improving the model’s accuracy and overall image quality.
read the caption
Table 4: Ablation study on Hard Text Attribute Binding (§ 3.5). ℒisubscriptℒ𝑖\mathcal{L}_{i}caligraphic_L start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT means that the count of instances needed to generate is i.
| Instance Success Ratio (%) | Mean Intersection over Union (%) | Image Success Ratio (%) | ||||||||||||||||
| Method | ||||||||||||||||||
| w/o Hard Image Bind | 71.3 | 69.5 | 56.9 | 51.4 | 47.6 | 56.2 | 63.8 | 61.3 | 52.3 | 47.5 | 43.9 | 51.2 | 53.6 | 37.9 | 16.2 | 4.3 | 3.9 | 23.6 |
| Hard Image Bind Input Layer | 71.0 | 68.4 | 56.6 | 52.9 | 50.3 | 57.1 | 62.4 | 60.5 | 50.4 | 47.2 | 45.4 | 50.9 | 51.0 | 34.0 | 14.9 | 5.7 | 5.2 | 22.5 |
| Hard Image Bind Middle Layer (Ours) | 79.0 | 77.3 | 71.8 | 68.7 | 69.4 | 71.9 | 69.8 | 68.2 | 63.7 | 61.4 | 61.2 | 63.7 | 63.2 | 52.9 | 29.7 | 18.6 | 18.8 | 37.1 |
| Hard Image Bind Output Layer | 64.5 | 63.8 | 57.4 | 49.4 | 58.3 | 57.6 | 56.9 | 57.2 | 51.8 | 45.0 | 52.1 | 51.7 | 43.9 | 28.8 | 14.9 | 2.9 | 7.8 | 20.0 |
🔼 This ablation study investigates the impact of applying Hard Image Attribute Binding at different layers of the FLUX model on the performance of multi-instance image generation. It evaluates the effect of applying this binding to input, middle, and output layers separately, as well as a condition without Hard Image Attribute Binding. The results are measured in terms of Instance Success Ratio (ISR), Mean Intersection over Union (MIoU), and Image Success Ratio across varying numbers of instances (L2, L3, L4, L5, and L6, representing 2, 3, 4, 5, and 6 instances respectively). This analysis aims to identify the optimal layer(s) for applying Hard Image Attribute Binding to achieve the best balance between accuracy of instance attributes and overall image quality.
read the caption
Table 5: Ablation study on Image Attribute Binding (§ 3.6). ℒisubscriptℒ𝑖\mathcal{L}_{i}caligraphic_L start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT means that the count of instances needed to generate is i.
Full paper#