TL;DR#
Aligning generated images with text prompts and human preferences is a core challenge in AIGC. Reward-enhanced diffusion distillation is promising for boosting text-to-image models. However, rewards become dominant with stronger conditions, overshadowing diffusion losses. Rewards become the dominant force in generation while diffusion losses become regularization.
To validate, the paper introduces R0, a conditional generation approach via regularized reward maximization. Treating image generation as an optimization in data space, it searches for images with high compositional rewards. State-of-the-art few-step models are trained with R0, demonstrating the rewards play a dominant role in complex conditions and challenge the conventional diffusion post-training.
Key Takeaways#
Why does it matter?#
This paper presents a paradigm shift in conditional image generation, offering a new perspective via regularized reward maximization, eliminating reliance on complex diffusion losses and opening doors for efficient, high-quality AIGC.
Visual Insights#

🔼 Figure 1 shows examples of image generation from Diff-Instruct++ and RG-LCM, highlighting common artifacts like repeated text or objects in the background. These artifacts are hypothesized to result from reward hacking, where the model exploits reward mechanisms to produce images that are not truly aligned with the intended prompt but maximize the reward score.
read the caption
Figure 1: Samples are taken from the corresponding papers of Diff-Instruct++ and RG-LCM. It can be observed that there exist certain artifacts in samples, e.g., repeated text/objects in the background. We hypothesize this comes from reward hacking.
| Model | Backbone | Steps | HPS | Aes | CS | FID | Image Reward | |
| Base Model (Realistic-vision) | SD-v1.5 | 25 | 30.19 | 5.87 | 34.28 | 29.11 | 0.81 | |
| Hyper-SD (Ren et al., 2024) | SD-v1.5 | 4 | 30.24 | 5.78 | 31.49 | 30.32 | 0.90 | |
| RG-LCM (Li et al., 2024a) | SD-v1.5 | 4 | 31.44 | 6.12 | 29.14 | 52.01 | 0.67 | |
| DI++ (Luo, 2024) | SD-v1.5 | 4 | 31.83 | 6.09 | 29.22 | 55.52 | 0.72 | |
| R0 (Ours) | SD-v1.5 | 4 | 33.70 | 6.11 | 32.13 | 33.79 | 1.22 | |
| R0+ (Ours) | SD-v1.5 | 4 | 34.37 | 6.20 | 32.97 | 37.53 | 1.27 | |
| Base Model | SD3-Medium | 28 | 31.37 | 5.84 | 34.13 | 28.72 | 1.07 | |
| R0 (Ours) | SD3-Medium | 4 | 34.04 | 6.27 | 33.89 | 31.97 | 1.13 |
🔼 Table 1 presents a quantitative comparison of several state-of-the-art text-to-image generation models, focusing on their performance in terms of speed and image quality. The models are evaluated using four metrics: HPS (Human Preference Score) assessing user preference; Aesthetic Score (AeS) measuring visual quality; CLIP Score (CS) evaluating image-text alignment; and FID (Fréchet Inception Distance) quantifying the similarity of generated images to real images. The table highlights the best-performing models among those capable of fast generation (few sampling steps), using the COCO-5k dataset as the benchmark for FID.
read the caption
Table 1: Comparison of machine metrics on text-to-image generation across state-of-the-art methods. We highlight the best among fast sampling methods. The FID is measured based on COCO-5k dataset.
In-depth insights#
Reward Dominance#
Reward dominance in generative models signifies a paradigm shift where reward signals, rather than the diffusion process itself, become the primary driver of image creation. This emerges especially when dealing with complex conditions or preferences. Instead of relying heavily on diffusion losses for regularization, the focus shifts towards maximizing reward functions that reflect desired image attributes. The success of this approach hinges on effectively parameterizing the generator and applying appropriate regularization techniques to prevent reward hacking and ensure the generated images align with the intended goals. The concept involves strategically searching valid image points within data space that yield high compositional rewards. Shifting our attention to the reward functions could result in more effective models and potentially reduce the need for heavy regularization or complex processes. It allows for a more direct control over image generation by allowing us to target specific desired qualities. This approach allows more human-centric generative paradigms across the broader field of AIGC.
R0: Reward-Driven#
The shift towards reward-driven approaches signifies a move from directly modeling data distributions to optimizing for desired outcomes. Rewards, when strong, can guide the generation process more effectively than diffusion losses acting as regularization. This necessitates rethinking conditional generation, prioritizing reward maximization while diffusion losses serve as regularization. It enables surprisingly good few-step generation, even without relying on image data or complex diffusion distillation losses. This reward-centric view may involve reformulating generation as an optimization problem, searching for images that maximize multiple reward functions. The generator parameterization and regularization techniques are critical for achieving high-quality results. It is a shift toward recognizing that rewards play a more vital role in scenarios involving complex conditions, potentially leading to more effective and efficient text-to-image generation systems.
Beyond Distillation#
Beyond the conventional wisdom of relying on distillation techniques for efficient generative modeling, a new paradigm emerges where rewards play a dominant role. Instead of painstakingly transferring knowledge from a pre-trained diffusion model, the focus shifts to directly optimizing for desired attributes, guided by reward signals. This transition signals a move from density estimation to regularized reward maximization, where the goal is to find images that simultaneously satisfy multiple reward functions. By carefully designing generator parameterization and regularization techniques, it is possible to achieve high-quality results without the complexities of distillation. The success of this approach suggests that diffusion losses, previously seen as essential, might primarily serve as a form of regularization, becoming less critical as reward signals strengthen. This perspective has potential to facilitate faster development and improve the controllability in AIGC by reducing dependence on computationally intensive distillation.
Regularization Key#
Regularization is a critical aspect of training generative models, particularly in scenarios with strong conditional guidance like text-to-image synthesis. Without proper regularization, models can easily overfit to the reward function, leading to reward hacking where the generated images exhibit artifacts or repeated patterns, ultimately deviating from the desired image manifold. The paper explores different regularization techniques, notably weight regularization, which penalizes deviations from pre-trained diffusion model weights, and random noise sampling, which introduces diversity in the generator’s output. The results highlight the importance of carefully balancing reward maximization with regularization to achieve high-quality, diverse, and semantically accurate image generation. Effective regularization is key to preventing the model from exploiting weaknesses in the reward function and ensuring that it learns to generate images that are both high-reward and visually plausible.
High-Res Guidance#
Generating high-resolution images from text is difficult because reward functions used to guide the process are typically trained on low-resolution images. When directly applied to high-resolution synthesis, fine-grained details can be lost. One strategy is to train a dedicated high-resolution classifier to guide the generation process. The high-resolution classifier acts as a complementary signal, explicitly encouraging perceptual quality in the high-resolution outputs. This can be implemented by using a high-resolution classifier as a Bayesian rule, which involves combining the information from both high and low-resolution classifiers. The high-resolution information can be used for fine-tuning, and it is important to prioritize perceptual quality in high-resolution outputs. This approach is promising because it allows the model to focus on generating realistic details, even when the primary reward function is not well-suited for high-resolution images.
More visual insights#
More on figures

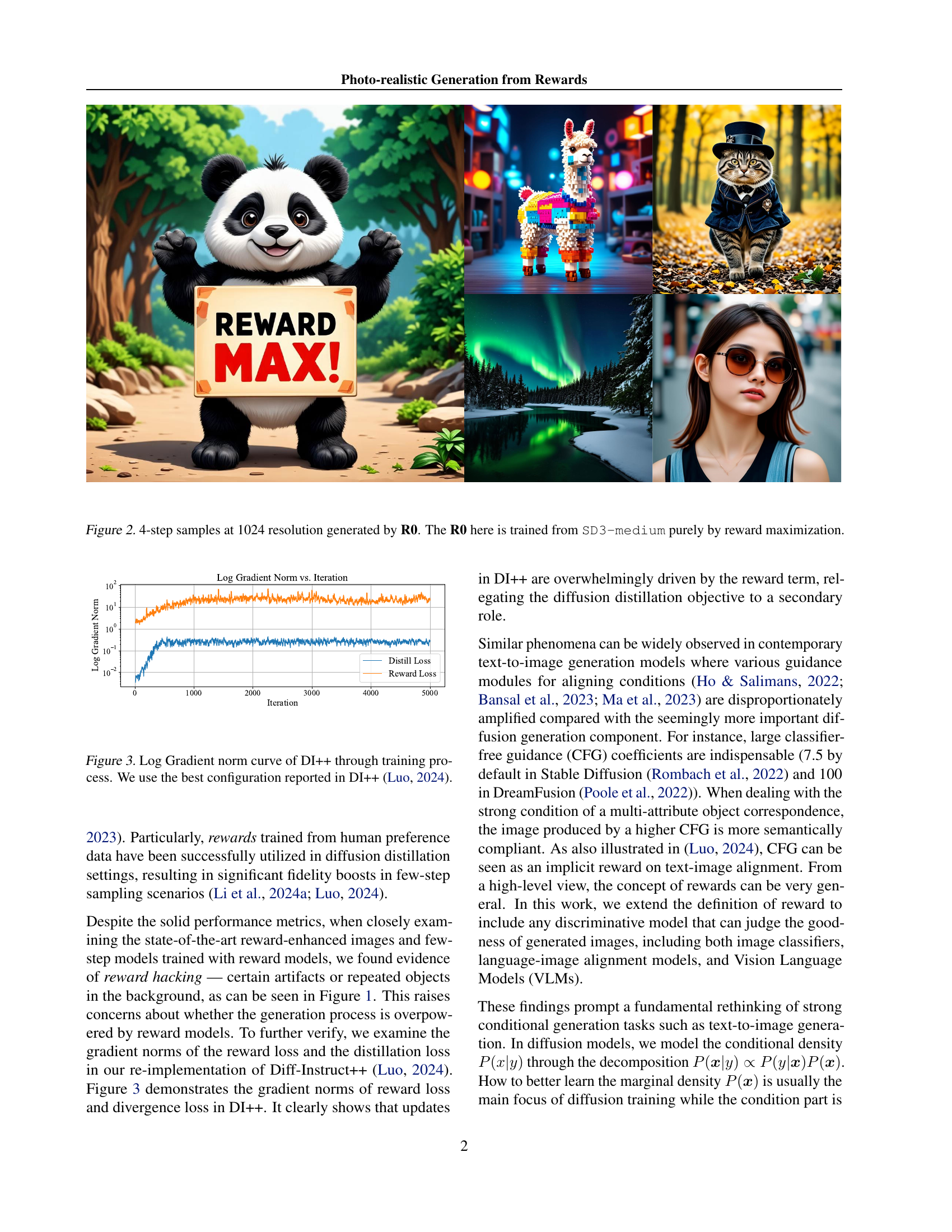
🔼 This figure displays images generated using the R0 model. The model was trained solely on reward maximization without using any diffusion loss, highlighting the effectiveness of rewards in image generation. Four steps of the generation process are shown for each of the images, and all images are at a 1024x1024 resolution.
read the caption
Figure 2: 4-step samples at 1024 resolution generated by R0. The R0 here is trained from SD3-medium purely by reward maximization.

🔼 This figure shows the log gradient norms of both the distillation loss and the reward loss during the training process of the DI++ model. The x-axis represents the training iteration, and the y-axis shows the log of the gradient norm. This visualization helps to illustrate the relative dominance of the reward loss compared to the distillation loss as training progresses, suggesting that reward signals become the dominant force in guiding the model’s learning process, particularly in scenarios with complex generation conditions. The use of the best configuration from the DI++ model (as reported in Luo, 2024) ensures a fair comparison.
read the caption
Figure 3: Log Gradient norm curve of DI++ through training process. We use the best configuration reported in DI++ (Luo, 2024).

🔼 This figure compares the image generation quality of the proposed method (R0) against the baseline method, Referee can play (Liu et al., 2024). The images shown are examples generated by each method for the same prompts. The comparison highlights the superior visual quality achieved by R0, showing more detail, realism, and overall better adherence to the prompt compared to the baseline method.
read the caption
Figure 4: Comparison with Referee can play (Liu et al., 2024). The baseline samples are taken from their paper. It can be seen that our method has significantly better visual quality.

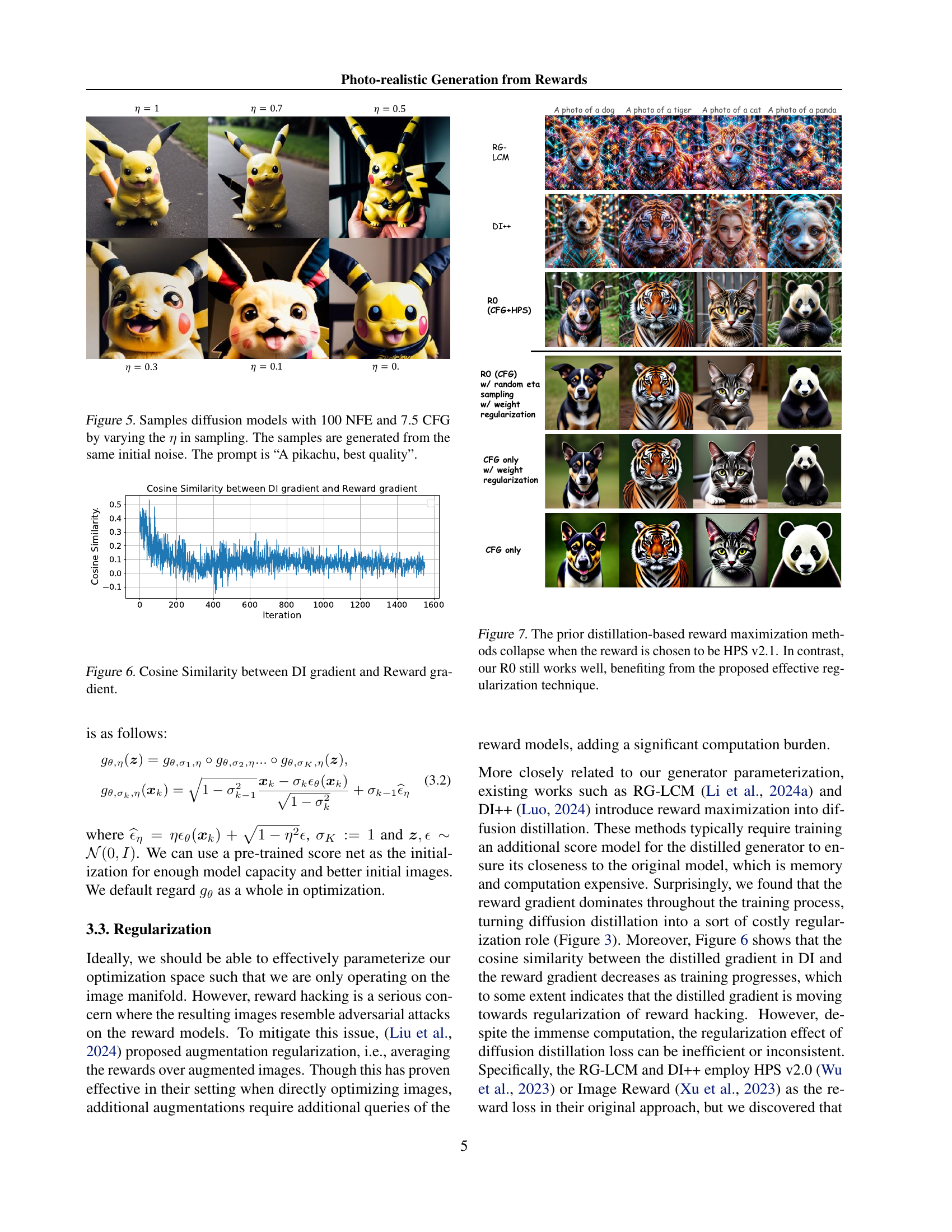
🔼 This figure displays the results of an experiment using diffusion models to generate images of a Pikachu. The models were run with 100 noise-removing steps (NFE) and a classifier-free guidance (CFG) scale of 7.5. The key variable manipulated was η (eta), a parameter controlling the sampling process during image generation. The images shown are all generated from the same starting point (the same initial noise), allowing a clear visualization of how different eta values impact the final output. The prompt used for all generations was: “A Pikachu, best quality”. This illustrates the effect of this hyperparameter on the generated image.
read the caption
Figure 5: Samples diffusion models with 100 NFE and 7.5 CFG by varying the η𝜂\etaitalic_η in sampling. The samples are generated from the same initial noise. The prompt is “A pikachu, best quality”.

🔼 This figure displays the cosine similarity between the gradients of the distillation loss and the reward loss during the training process of the Diff-Instruct++ model. The x-axis represents the training iteration, and the y-axis shows the cosine similarity. A high cosine similarity indicates that the updates from the distillation loss and reward loss are aligned, while a low similarity implies that the updates are pulling the model in different directions. This graph helps to visually illustrate the dominance of reward loss gradient over distillation loss gradient during the training process, as discussed in the paper.
read the caption
Figure 6: Cosine Similarity between DI gradient and Reward gradient.

🔼 This figure compares the performance of prior distillation-based reward maximization methods (like RG-LCM and DI++) and the proposed R0 method when using HPS v2.1 as the reward. The prior methods fail to generate reasonable images, indicated by a ‘collapse’ in their performance. In contrast, R0, due to its effective regularization techniques, is robust and produces satisfactory results even with this challenging reward function. This illustrates the robustness and effectiveness of R0’s regularization strategies.
read the caption
Figure 7: The prior distillation-based reward maximization methods collapse when the reward is chosen to be HPS v2.1. In contrast, our R0 still works well, benefiting from the proposed effective regularization technique.

🔼 This figure displays the training progress curves for various metrics, specifically focusing on the HPS (Human Preference Score) benchmark. The curves illustrate how different metrics change over a series of training iterations (50 iterations are shown on the x-axis). It highlights that using normalized gradients leads to better performance during the training process compared to unnormalized gradients. The evaluation is conducted on 1000 prompts from the HPS benchmark, providing a robust assessment of the model’s performance.
read the caption
Figure 8: Training progress of various metrics over iterations. It can be seen that the normalized gradient shows better performance. This is evaluated on 1k prompts from HPS benchmark.

🔼 This figure showcases a series of images generated by the R0 model after 4 steps. Each image corresponds to a different number of reward signals used during the generation process. The purpose is to illustrate how the visual quality of the generated image improves as more reward signals are integrated into the R0 model, indicating a monotonic relationship between the number of rewards and image quality. The improvement in image quality suggests that the use of multiple reward functions enhances the overall result.
read the caption
Figure 9: Four-step samples generated by R0. We observed that the quality of the image monotonically increases with the gradual increment of the reward count.

🔼 This figure demonstrates that combining multiple reward signals during training leads to better image generation compared to using a single reward. It showcases the complementary effect of using HPS, Image Reward, and Clip Score rewards, resulting in improved image quality and a closer alignment between the generated image and the text prompt. The experiment was conducted without the use of random η sampling and with minimal weight regularization to highlight the benefits of combining rewards.
read the caption
Figure 10: The complementary effect of different reward. We do not use random η𝜂\etaitalic_η sampling and set small weight regularization in training here to highlight the complementary effect between rewards.

🔼 This figure demonstrates the impact of the regularization loss on image generation using the R0 model. It showcases multiple images generated from the same initial noise, with and without the regularization loss applied. The differences in image quality and features illustrate how the regularization term influences the output and helps prevent issues like reward hacking, ensuring the generator stays within a desirable distribution and produces images of better quality.
read the caption
Figure 11: The effect of regularization loss. Images are from the same initial noise.
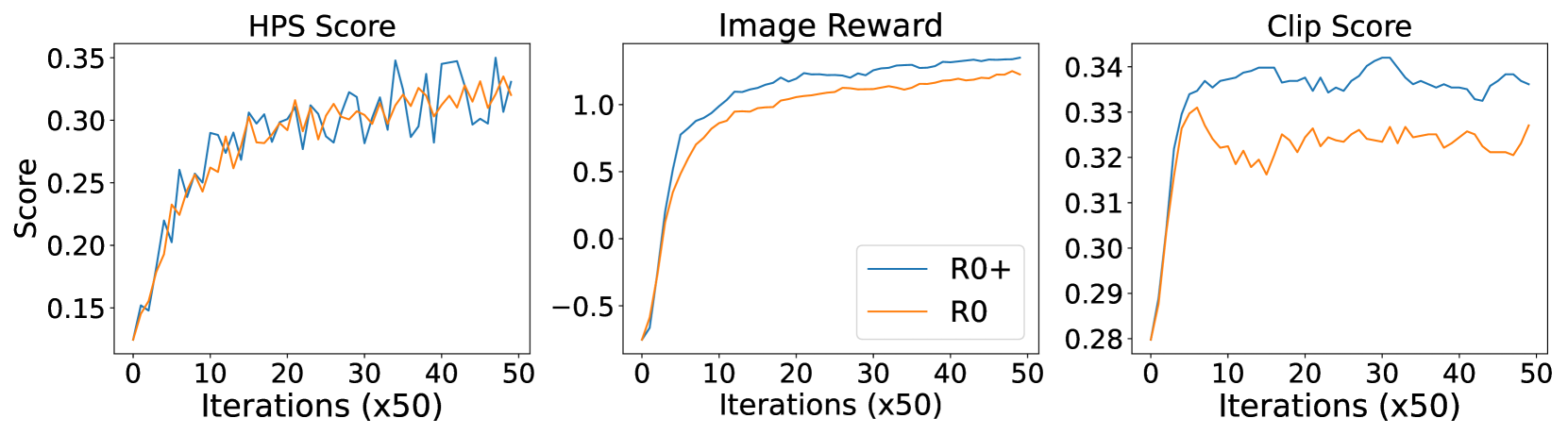
🔼 Figure 12 presents a comparison of the convergence speed achieved by two different models, R0 and R0+, during training. The training involved 1000 prompts sourced from the HPS (Human Preference Score) benchmark dataset. The figure likely shows plots of various metrics (e.g., FID, HPS scores, CLIP scores) against training iterations. This visual comparison allows for a quantitative assessment of the efficiency improvements gained by incorporating intermediate supervision into the training process of the R0+ model. The figure is useful for determining the impact of the training modifications introduced in the R0+ model on training efficiency.
read the caption
Figure 12: Comparison on the convergence speed between R0 and R0+. This is evaluated on 1k prompts from HPS benchmark.

🔼 This figure compares the generation process of the R0 and R0+ models, which are both few-step text-to-image generation models. The prompt used for both models is ‘Two dogs, best quality’. The images shown illustrate the intermediate steps in the generation process, from initial noise to final image. By comparing the intermediate steps for both models, the figure highlights how the introduction of intermediate supervision in R0+ leads to a smoother and more stable generation process compared to R0, which shows more artifacts during intermediate steps before converging to the final image.
read the caption
Figure 13: Path comparison between R0 and R0+. The prompt is “Two dogs, best quality”.

🔼 This figure demonstrates the impact of incorporating a high-resolution guidance loss during the training of the R0+ model. It visually compares image generation results from the same initial noise input, with and without the high-resolution guidance loss applied. The comparison highlights the improved image quality, particularly in terms of fine details and clarity, that the high-resolution guidance loss contributes to.
read the caption
Figure 14: The effect of high-resolution guidance loss. Images are from the same initial noise.

🔼 This figure presents a qualitative comparison of image generation results using different methods. It compares R0 (the proposed method) to several other approaches including various distillation-based methods, all using the same SD-v1.5 model backbone and starting from identical initial noise conditions. The goal is to demonstrate that R0 achieves superior image quality and better alignment between the generated image and the corresponding text prompt, even with fewer steps (4 steps in this case), when compared to distillation-based reward maximization techniques.
read the caption
Figure 15: Qualitative comparisons of R0 against distillation-based methods and diffusion base models on SD-v1.5 backbone. All images are generated by the same initial noise. We surprisingly observe that our proposed R0 has better image quality and text-image alignment compared to prior distillation-based reward maximization methods in 4-step text-to-image generation.

🔼 Figure 16 presents a qualitative comparison of the proposed R0 model against other competing methods on various downstream tasks, including image editing and integration with ControlNet. The image shows that R0, even without relying on distillation losses, achieves comparable or superior performance in downstream applications. It demonstrates versatility in handling image editing (changing a squirrel to a cat), and seamless integration with ControlNet for image generation guided by Canny edge detection, while retaining reasonable image quality. This showcases R0’s effectiveness and adaptability beyond simple image generation.
read the caption
Figure 16: Qualitative comparison against competing methods and applications in downstream tasks.
Full paper#