TL;DR#
Robotic grasping in cluttered environments is challenging, requiring understanding of human instructions and spatial relationships. Vision-Language Models (VLMs) show potential but struggle with spatial reasoning and free-form language nuances. Existing methods lack robustness in complex scenarios, hindering effective robotic manipulation. To address these issues, the paper introduces FreeGrasp, a free-form language-based robotic grasping approach.
FreeGrasp leverages pre-trained VLMs’ world knowledge to interpret instructions and object spatial arrangement. It detects objects as keypoints and uses these to annotate images, facilitating VLM spatial reasoning. FreeGrasp determines if an object is graspable or if obstructing objects must be removed first. Validated with FreeGraspData and real-world experiments, **it demonstrates state-of-the-art performance in grasp reasoning and execution, robustly interpreting instructions and inferring actions for object grasping.
Key Takeaways#
Why does it matter?#
This paper is important as it introduces FreeGrasp, a novel framework combining VLMs with modular reasoning, addresses the spatial reasoning gaps in existing models. It offers a new dataset and methods to improve robotic grasping in complex real-world scenarios.
Visual Insights#

🔼 This figure demonstrates the process of free-form language-based robotic grasping. A human provides a natural language instruction to the robot. The robot uses a Vision-Language Model (VLM) to understand the instruction and reason about the spatial relationships between objects in a cluttered bin. If the target object is not directly graspable (indicated by a star), the VLM identifies and removes obstructing objects (indicated by circles) before grasping the target object. The robot optimizes the order of actions to complete the task efficiently.
read the caption
Figure 1: To enable a human to command a robot using free-form language instructions, our method leverages the world knowledge of Vision-Language Models to interpret instructions and reason about object spatial relationships. This is important when the target object (★) is not directly graspable, requiring the robot to first identify and remove obstructing objects (●). By optimizing the sequence of actions, our approach ensures efficient task completion.
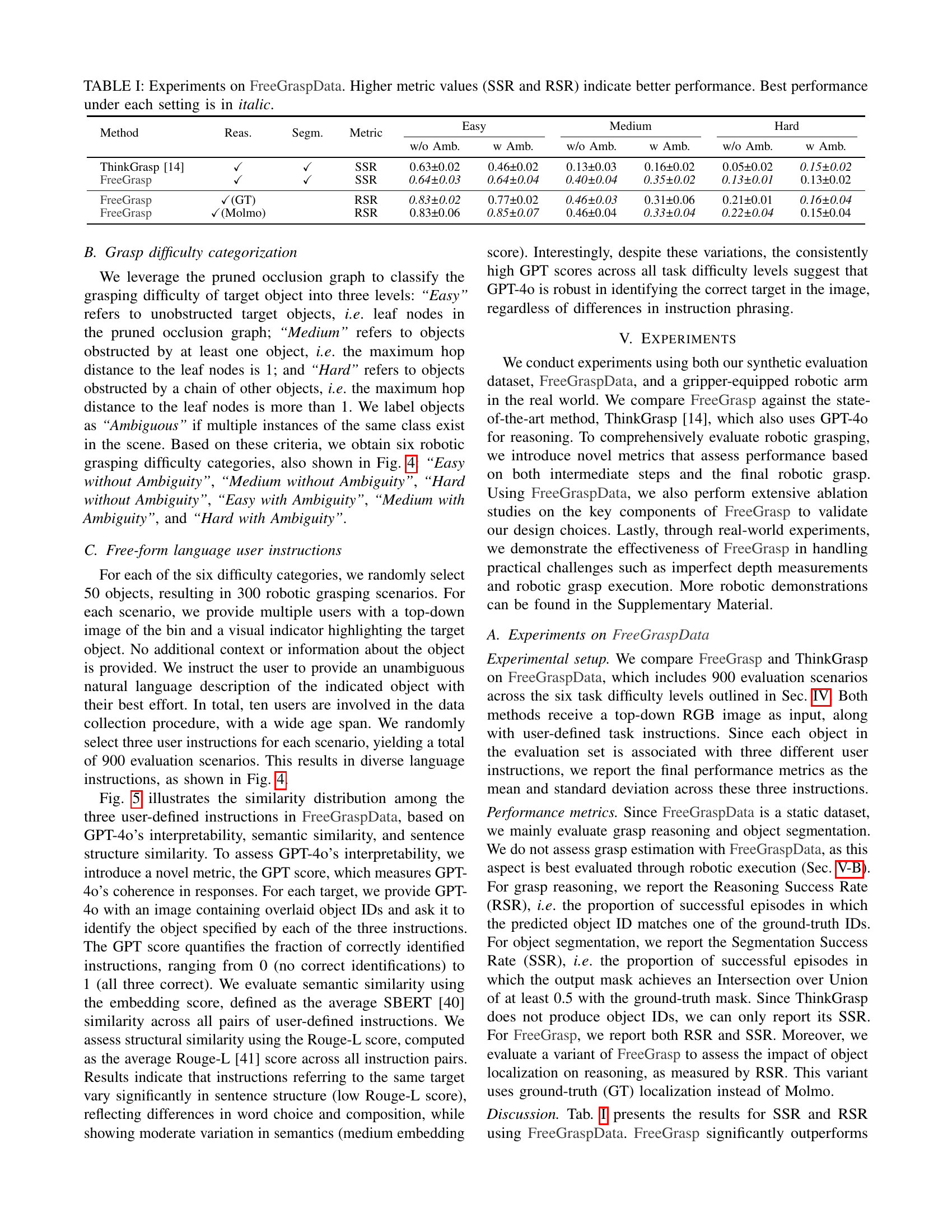
| Method | Reas. | Segm. | Metric | Easy | Medium | Hard | |||
| w/o Amb. | w Amb. | w/o Amb. | w Amb. | w/o Amb. | w Amb. | ||||
| ThinkGrasp [14] | ✓ | ✓ | SSR | 0.63±0.02 | 0.46±0.02 | 0.13±0.03 | 0.16±0.02 | 0.05±0.02 | 0.15±0.02 |
| FreeGrasp | ✓ | ✓ | SSR | 0.64±0.03 | 0.64±0.04 | 0.40±0.04 | 0.35±0.02 | 0.13±0.01 | 0.13±0.02 |
| FreeGrasp | ✓(GT) | RSR | 0.83±0.02 | 0.77±0.02 | 0.46±0.03 | 0.31±0.06 | 0.21±0.01 | 0.16±0.04 | |
| FreeGrasp | ✓(Molmo) | RSR | 0.83±0.06 | 0.85±0.07 | 0.46±0.04 | 0.33±0.04 | 0.22±0.04 | 0.15±0.04 | |
🔼 Table 1 presents the results of experiments conducted on the FreeGraspData dataset. The table compares the performance of the proposed FreeGrasp method with the ThinkGrasp method [14] across different task difficulty levels and levels of object ambiguity. Performance is measured using two metrics: Segmentation Success Rate (SSR) and Reasoning Success Rate (RSR). Higher values for both metrics indicate better performance. The table is organized by task difficulty (Easy, Medium, Hard) and the presence or absence of object ambiguity (with Ambiguity, without Ambiguity). The best performance for each setting is indicated in italics.
read the caption
TABLE I: Experiments on FreeGraspData. Higher metric values (SSR and RSR) indicate better performance. Best performance under each setting is in italic.
In-depth insights#
VLM Grounding#
VLM grounding is the crucial process of connecting abstract language instructions to the physical world, enabling robots to understand and act upon human commands effectively. It involves bridging the gap between high-level semantic information encoded in VLMs and low-level sensor data from the robot’s environment. Challenges in VLM grounding include dealing with noisy sensor data, variations in object appearance and pose, and the ambiguity of natural language. Effective grounding requires robust perception, accurate object recognition, and the ability to reason about spatial relationships. Methods for improving VLM grounding include using multimodal data fusion, incorporating contextual information, and developing more sophisticated attention mechanisms. Ultimately, reliable VLM grounding is essential for creating robots that can seamlessly interact with humans and perform complex tasks in unstructured environments. The paper emphasizes the use of mark-based visual prompting to aid the VLM in spatial reasoning for better grounding.
FreeGrasp Pipeline#
The FreeGrasp pipeline, as described, is a multi-stage process designed for robotic grasping in cluttered environments using free-form language instructions. The pipeline integrates object localization, visual prompting with ID marks, and VLM reasoning using GPT-40 to determine the grasp sequence. Object segmentation is then performed to isolate the target, followed by grasp estimation to determine the robot’s actions. The pipeline’s iterative nature accommodates changes in the scene after each grasp. This comprehensive approach highlights the system’s ability to reason about language and space.
Occlusion Limits#
While not explicitly titled “Occlusion Limits,” the reviewed paper highlights occlusion as a significant hurdle in robotic grasping. Occlusion severely impacts a robot’s ability to perceive and understand the spatial arrangement of objects, leading to failures in identifying the target and planning collision-free grasps. The study acknowledges the limitation of GPT-40 in handling occlusion, even with mark-based visual prompting. The authors found Chain-of-Thought reasoning surprisingly unhelpful due to hallucinated spatial relationships. The research instead utilizes a structured prompt for more reliable object ID and class. The results emphasize that reasoning in cluttered environments remains a challenging task that is far from solved. The lower performance in Medium and Hard difficulty scenarios proves occlusion’s impact. The research recommends further investigation into visual spatial reasoning to address these limitations, thus showing the importance of a robust occlusion handling strategy.
Mark-based Prompt#
Mark-based visual prompting is used to enhance how VLMs understand and reason. By assigning unique numeric IDs to objects and annotating the image with these numbered markers, the prompt is designed to provide a structured input. The structure of the prompt is intended to leverage VLMs’ aptitude for multiple-choice formats, aiding in object identification and spatial reasoning, thus enabling more robust and accurate analysis of the scene and user instructions. The mark based approach offers improved performance in object and spatial reasoning. It helps ground the models in the scene and improves instruction following.
Data & Metrics#
The paper uses both synthetic data (FreeGraspData) and real-world robotic experiments for evaluation. FreeGraspData, built upon MetaGraspNetV2, introduces human-annotated instructions and ground-truth grasping sequences. Metrics focus on reasoning success (RSR) and segmentation success (SSR), evaluating intermediate steps. Real-world experiments use metrics like success rate (SR), path efficiency (PE), and success-weighted path length (SPL) to assess overall performance. Ablation studies validate design choices, and real-world experiments address practical challenges. A key strength is evaluating not just final success but also the quality of reasoning and segmentation, providing a more comprehensive understanding of the system’s strengths and weaknesses. The use of FreeGraspData, along with metrics to show the model’s performance provides a strong base to evaluate the model’s ability to understand spatial relationships.
More visual insights#
More on figures

🔼 Figure 2 illustrates the FreeGrasp system. (a) shows the physical setup: a robotic arm with a two-finger gripper in front of a bin containing various cluttered objects; an RGB-D camera observes the scene from above. (b) details the FreeGrasp pipeline, a modular process starting with the user providing a free-form language instruction. The system then uses a Vision-Language Model (VLM) in a zero-shot manner (no model training on this specific task) to interpret the instruction and reason about the object locations and spatial relationships. Object localization identifies all visible items, and mark-based visual prompting enhances the VLM’s reasoning accuracy. The VLM then determines which object to grasp first, considering obstructions. Object segmentation isolates the chosen object, grasp estimation finds an appropriate grasp pose, and the robotic arm executes the grasp. This iterative process continues until the target object is successfully grasped.
read the caption
Figure 2: FreeGrasp pipeline. (a) The setup considered for the robotic reasoning and grasping task and (b) the proposed pipeline that leverages pre-trained VLMs in a zero-shot manner without additional training.

🔼 The figure compares the performance of three different methods for object localization using the MetaGraspNetV2 dataset. The methods are: using GPT-40 and LangSAM, GPT-40, LangSAM, and post-processing, and using Molmo. The comparison is based on three metrics: Average Precision (AP), Average Recall (AR), and F1 score. The results show that Molmo outperforms the other two methods, achieving higher scores in AP, AR, and F1. This suggests that Molmo is a more effective method for object localization in cluttered scenes.
read the caption
Figure 3: Object localization performance with different VLM-based method on MetaGrasNetv2 [16].

🔼 Figure 4 presents example scenarios from the FreeGraspData dataset, categorized by task difficulty (Easy, Medium, Hard) and the presence or absence of object ambiguity. Each scenario shows a cluttered bin with objects, illustrating different levels of obstruction to reach the target object. Three distinct user-provided instructions are shown for each scenario, demonstrating the variability in natural language descriptions. The target object (★) and the ground-truth sequence of objects to grasp (●) are marked to indicate the task complexity and demonstrate how the robot should plan its actions.
read the caption
Figure 4: Examples of FreeGraspData at different task difficulties with three user-provided instructions. ★ indicates the target object, and ● indicates the ground-truth objects to pick.

🔼 This figure displays the distribution of similarity scores among the three distinct user-provided instructions for each scenario within the FreeGraspData dataset. The similarity is measured using three different metrics: GPT score (measuring GPT-40’s ability to interpret instructions consistently), embedding score (measuring semantic similarity using Sentence-BERT), and ROUGE-L score (measuring structural similarity). The data is broken down based on the difficulty level (Easy, Medium, Hard) and the presence/absence of object ambiguity in the scene. This visualization helps to quantify the variations in human language instructions used in the dataset, and to examine how well a language model (like GPT-40) handles this variation.
read the caption
Figure 5: Similarity distribution among the three user-defined instructions used in the FreeGraspData scenarios.
Full paper#