TL;DR#
Current Multimodal Large Language Models(MLLMs) are not good at reasoning 3D space, even though the ability to reason about 3D scenes is important for real world applications like robotics and AR/VR. The current methods also do not use depth and multi-view images effectively. The paper addresses this limitation by introducing high-quality 3D scene data with annotations to enable MLLMs to better understand 3D space and use multi-view images and depth information effectively.
The paper has 2 major contributions: The researchers introduce a novel dataset called Cubify Anything VQA (CA-VQA) and create a new evaluation benchmark, focused on indoor scenes. The new dataset covers diverse spatial tasks like predicting spatial relations and predicting metric size. It also uses metric depth and multi-view inputs. The paper also introduces MM-Spatial, a generalist MLLM that excels at 3D spatial understanding and achieves state-of-the-art performance on 3D spatial understanding benchmarks, including the benchmark created in this paper.
Key Takeaways#
Why does it matter?#
This research offers a new 3D spatial understanding dataset and benchmark, enabling MLLMs to reason effectively about 3D environments. It improves performance and opens new avenues for research in robotics, AR/VR, and general visual comprehension by better understanding multi-view and depth information.
Visual Insights#

🔼 Figure 1 illustrates the two main contributions of the paper. The left panel showcases the Cubify Anything VQA (CA-VQA) dataset and benchmark. CA-VQA is designed to evaluate 3D spatial reasoning abilities in multimodal large language models (MLLMs). It offers diverse input modalities, including single images, sensor-based and estimated depth maps, and multiple views or frames. The benchmark covers a wide array of spatial understanding tasks such as predicting relative spatial relationships between objects, estimating distances and sizes, and performing 3D object grounding. The right panel describes MM-Spatial, a novel multimodal LLM developed by the authors, which excels at 3D spatial understanding. MM-Spatial uses a chain-of-thought (CoT) reasoning process. It leverages 2D object grounding and depth estimation capabilities to answer complex spatial queries, and can even incorporate depth input through tool-use.
read the caption
Figure 1: (Left) We generate the Cubify Anything VQA (CA-VQA) dataset and benchmark, covering various 1) input signals: single image, metric depth (sensor-based and estimated), multi-frame/-view, and 2) spatial understanding tasks: e.g., relationship prediction, metric estimation, 3D grounding. (Right) We train MM-Spatial, a generalist multimodal LLM that excels at 3D spatial understanding. It supports Chain-of-Thought spatial reasoning involving 2D grounding and depth estimation, and can also leverage depth input via tool-use.
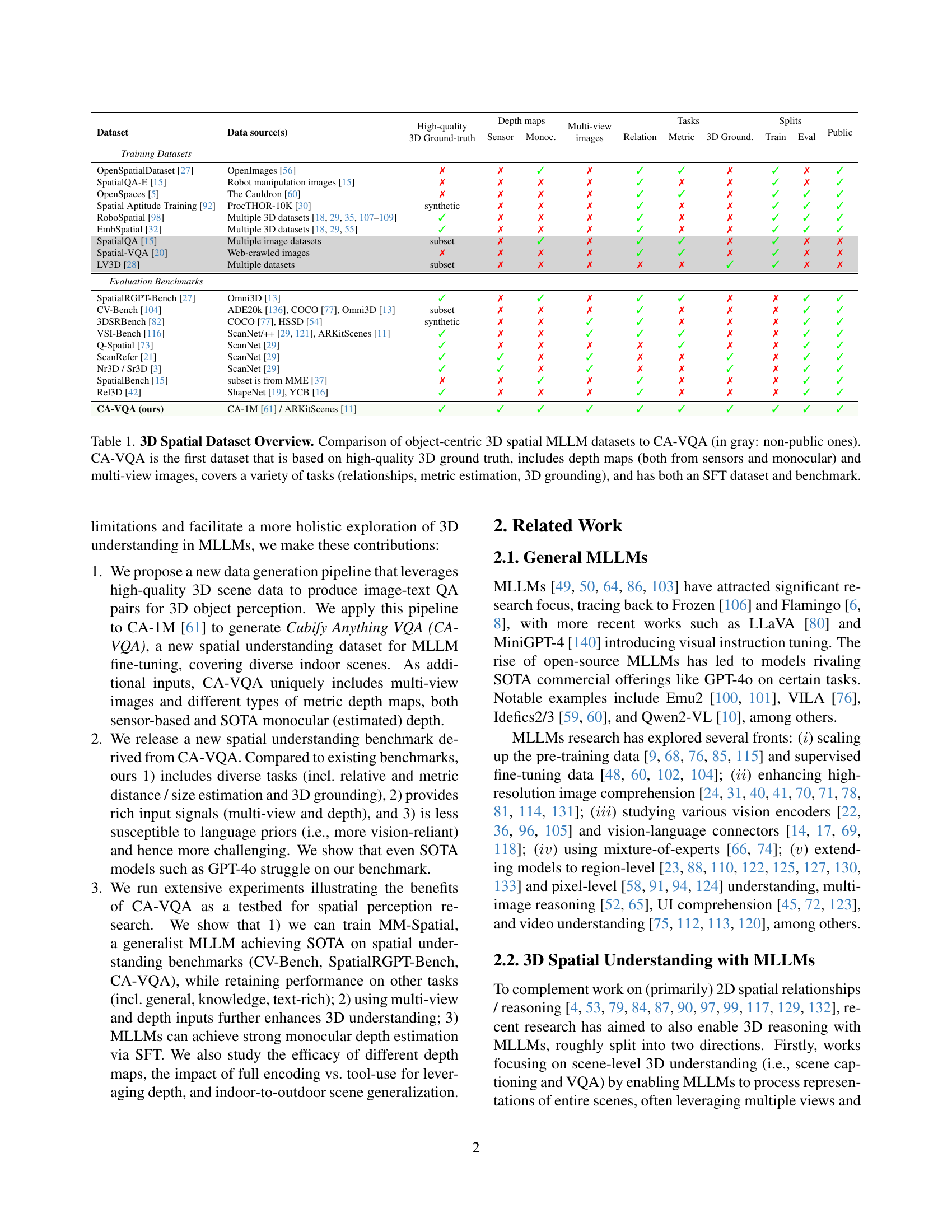
| Dataset | Data source(s) | High-quality 3D Ground-truth | Depth maps | Multi-view images | Tasks | Splits | Public | ||||
| Sensor | Monoc. | Relation | Metric | 3D Ground. | Train | Eval | |||||
| Training Datasets | |||||||||||
| OpenSpatialDataset [27] | OpenImages [56] | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✓ |
| SpatialQA-E [15] | Robot manipulation images [15] | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ |
| OpenSpaces [5] | The Cauldron [60] | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ |
| Spatial Aptitude Training [92] | ProcTHOR-10K [30] | synthetic | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ |
| RoboSpatial [98] | Multiple 3D datasets [29, 18, 108, 107, 35, 109] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ |
| EmbSpatial [32] | Multiple 3D datasets [29, 18, 55] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ |
| SpatialQA [15] | Multiple image datasets | subset | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ |
| Spatial-VQA [20] | Web-crawled images | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ |
| LV3D [28] | Multiple datasets | subset | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ |
| Evaluation Benchmarks | |||||||||||
| SpatialRGPT-Bench [27] | Omni3D [13] | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ |
| CV-Bench [104] | ADE20k [136], COCO [77], Omni3D [13] | subset | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ |
| 3DSRBench [82] | COCO [77], HSSD [54] | synthetic | ✗ | ✗ | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ |
| VSI-Bench [116] | ScanNet/++ [29, 121], ARKitScenes [11] | ✓ | ✗ | ✗ | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ |
| Q-Spatial [73] | ScanNet [29] | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✓ |
| ScanRefer [21] | ScanNet [29] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ |
| Nr3D / Sr3D [3] | ScanNet [29] | ✓ | ✓ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ |
| SpatialBench [15] | subset is from MME [37] | ✗ | ✗ | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Rel3D [42] | ShapeNet [19], YCB [16] | ✓ | ✗ | ✗ | ✗ | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ |
| CA-VQA (ours) | CA-1M [61] / ARKitScenes [11] | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
🔼 Table 1 provides a comprehensive comparison of existing object-centric 3D spatial datasets designed for training and evaluating Multimodal Large Language Models (MLLMs). It highlights the unique features of each dataset, including data sources, the availability of 3D ground truth information, the types of depth maps provided (sensor-based or monocular estimates), whether multi-view images are included, the range of spatial tasks supported (relationship prediction, metric estimation, 3D bounding box prediction), the availability of training and evaluation splits, and finally, whether the dataset is publicly available. The table emphasizes the novelty of the Cubify Anything VQA (CA-VQA) dataset, which stands out due to its high-quality 3D ground truth, inclusion of diverse depth maps and multi-view images, coverage of various spatial tasks, and availability as both an SFT dataset and a benchmark for MLLM evaluation. This allows researchers to compare their 3D spatial reasoning models against a comprehensive and challenging benchmark.
read the caption
Table 1: 3D Spatial Dataset Overview. Comparison of object-centric 3D spatial MLLM datasets to CA-VQA (in gray: non-public ones). CA-VQA is the first dataset that is based on high-quality 3D ground truth, includes depth maps (both from sensors and monocular) and multi-view images, covers a variety of tasks (relationships, metric estimation, 3D grounding), and has both an SFT dataset and benchmark.
In-depth insights#
MM-Spatial LLM#
Based on the context, MM-Spatial LLM seems to be a multimodal large language model tailored for 3D spatial understanding. It likely excels at tasks requiring spatial reasoning, like distance estimation or 3D grounding. The research probably investigates how to train such a model using datasets like CA-VQA and how to leverage input signals like depth maps and multi-view images to enhance its performance. The core idea is to bridge the gap in MLLMs’ ability to understand and reason about 3D space.
CA-VQA Dataset#
The CA-VQA dataset is a key contribution, designed to push the boundaries of 3D spatial understanding in MLLMs. It uniquely incorporates high-quality 3D scene data with open-set annotations, enabling supervised fine-tuning and evaluation. The dataset’s strength lies in its diversity, covering spatial relationships, metric size/distance estimation, and 3D grounding within indoor scenes. It sets itself apart by including multi-view images and various depth maps, both sensor-based and estimated. This allows for a more comprehensive assessment of depth perception and multi-view reasoning abilities. The dataset’s construction leverages careful QA pair generation using 3D and semantic annotations. Crucially, the dataset also incorporates blind filtering to mitigate language priors, ensuring that models truly rely on visual understanding rather than linguistic cues.
3D Understanding#
3D understanding in multimodal learning focuses on interpreting complex visual scenes by reasoning about object locations and spatial relationships. While MLLMs excel in 2D tasks, 3D perception lags behind, hindering applications in robotics and AR/VR. Research addresses this gap by creating datasets and benchmarks emphasizing spatial tasks like relative depth estimation, metric size/distance prediction, and 3D bounding box localization. Datasets often include diverse input signals such as multi-view images and depth maps (sensor-based and estimated), improving model performance. Models leveraging chain-of-thought reasoning and tool use, such as depth estimation, achieve state-of-the-art results. The goal is to develop generalist MLLMs capable of robust 3D spatial reasoning without compromising performance on other tasks, ultimately bridging the gap between 2D visual understanding and comprehensive 3D scene interpretation.
Tool-use Depth#
Tool-use depth involves employing external tools to acquire depth information, enabling the model to focus on higher-level reasoning. This method leverages modularity, as the depth estimation task is handled separately, reducing the complexity for the main model. By querying a depth estimation tool for specific regions, the MLLM can access accurate depth values without needing to process the entire depth map. The Chain-of-Thought method, in contrast, generates depth predictions directly, fostering an integrated approach. Ultimately, the best method depends on factors like the trade-off between resource usage, model size, and accuracy requirements. Tool-use Depth could reduce the computational burden, enhancing its effectiveness when dealing with complex real-world scenarios. The model might make precise and effective use of outside knowledge, when it is most needed.
Indoor Bias#
Indoor bias is a significant factor in visual understanding, especially for models trained and evaluated primarily on indoor datasets. This bias arises from the specific characteristics of indoor environments, such as constrained lighting, fixed object arrangements, and limited viewpoint variations. Models trained predominantly on indoor scenes may struggle to generalize to outdoor environments due to the stark differences in these attributes. Addressing this bias requires strategies like domain adaptation, data augmentation with outdoor scenes, and training with datasets that offer a balanced representation of both indoor and outdoor settings. Understanding and mitigating the indoor bias is crucial for developing robust and versatile visual understanding systems that can effectively operate in diverse real-world scenarios. Additionally, scaling and resolution issues can be problematic for spatial understanding in outdoor scenes.
More visual insights#
More on figures

🔼 This figure shows a sample from the Cubify Anything VQA (CA-VQA) dataset. It illustrates the multiple data modalities included in the dataset for each image. A main reference image is shown, along with up to four additional support frames from slightly different viewpoints. Each frame (both reference and support) provides three depth maps: one from a high-accuracy FARO laser scanner (ground truth), one from Apple’s ARKit (LiDAR-fused), and one from a monocular depth estimation model (DepthPro). For each support frame, relative pose information (showing its position and orientation relative to the reference frame) and camera intrinsic parameters are also included.
read the caption
Figure 2: CA-VQA Data Example. Example of a single sample from our dataset. Each reference frame has between 0-4 multi-view support frames. All frames (reference and support) come with three metric depth maps: Ground truth (FARO laser), ARKit Depth (LiDAR-fused) and Monocular (DepthPro). Each support frame contains the relative pose from the reference image, along with camera intrinsics.

🔼 This figure illustrates the process of using depth information to answer spatial questions. The model first identifies objects in an image and determines their 2D bounding boxes. Then, it queries a ’tool’ (a function that extracts depth information) for the median depth value within each bounding box. This depth information is then used by the model in a chain-of-thought reasoning process to answer a question involving spatial relationships, such as ‘Is the pillow behind the television?’
read the caption
Figure 3: Example of leveraging depth maps via tool-use. The model predicts the objects’ 2D bounding boxes and function calls, receives the tool outputs (which is the median depth value within the box, marked with an ×\mathbf{\times}×), and finally reasons about the answer.

🔼 Figure 4 presents a qualitative comparison of different models’ performance on a complex spatial reasoning task from the CA-VQA benchmark. It highlights the superior performance of the MM-Spatial model. The figure shows that while strong commercial and research models fail to accurately answer the question, MM-Spatial provides a much better response. Further improvements are observed when using Chain-of-Thought (CoT) reasoning and ground truth depth, demonstrating the model’s ability to ground objects in 2D space, estimate depth accurately, and reason spatially. The use of monocular depth estimation, while also helpful, is shown to be less accurate than ground truth depth.
read the caption
Figure 4: Qualitative Example. We show the predictions of various models on a challenging example from our CA-VQA benchmark. Strong commercial (2a&b) and research models (2c&d) fail. MM-Spatial (1a) is much better, and even more so with CoT enabled (1b), demonstrating our model’s strong object grounding (see predicted 2D boxes in the image), depth estimation, and spatial reasoning ability. Accuracy improves further when leveraging ground-truth depth via tool-use (1c), although our CoT model’s (1b) predictions are very close to that, for both the intermediate depth values and final answer; monocular estimated depth (1d) is less accurate and yields a worse result.

🔼 Figure 5 showcases example question-answer pairs from the Cubify Anything VQA (CA-VQA) dataset. CA-VQA is designed to improve 3D spatial reasoning capabilities in multimodal large language models (MLLMs). It leverages high-quality 3D ground truth annotations from the CA-1M dataset to create diverse spatial perception questions. These questions cover a wide range of tasks including relative spatial relationships between objects, metric measurements (distances and sizes), and 3D object bounding box identification. The figure visually demonstrates the variety of question types and the dataset’s focus on detailed 3D spatial understanding.
read the caption
Figure 5: CA-VQA Overview. Example QA pairs from our Cubify Anything VQA (CA-VQA) dataset, aiming to unlock object-centric 3D spatial understanding in MLLMs. Using high-quality 3D ground truth annotations from CA-1M [61], we generate spatial perception questions across a variety of different tasks, e.g., involving relative relationships, metric measurements, and 3D object bounding boxes.

🔼 Figure 6 presents example questions and answers from the CA-VQA dataset, categorized into Binary, Counting, and Multi-choice question types. The Binary examples showcase questions about spatial relationships (e.g., Is object A in front of object B?), relative object sizes, and object presence. Counting questions involve counting the number of objects of a specific type in the image. Multi-choice examples combine different question types into a multiple-choice format. The figure visually demonstrates the variety of question formats and types of spatial reasoning tasks included in the CA-VQA dataset.
read the caption
Figure 6: Examples of CA-VQA data samples from the Binary, Counting and Multi-choice categories.

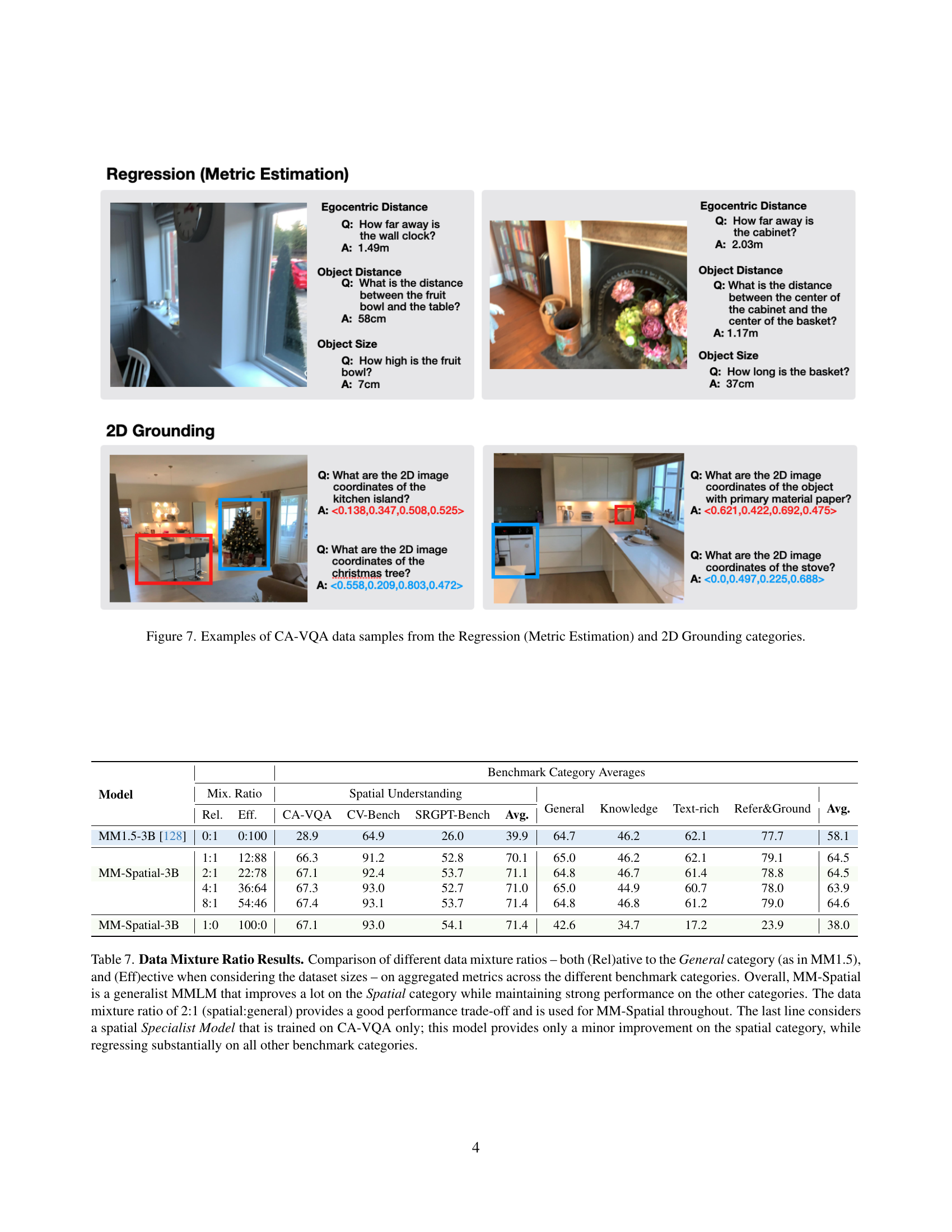
🔼 Figure 7 shows example questions and answers from the CA-VQA dataset that belong to two categories: Regression (Metric Estimation) and 2D Grounding. The Regression examples demonstrate questions that require estimating distances (e.g., how far away is an object, distance between two objects) and sizes (e.g., height, length) of objects. The 2D Grounding examples showcase questions that ask for the 2D image coordinates of objects given either their names or material properties. The figure illustrates the diversity of questions and the types of answers expected in CA-VQA.
read the caption
Figure 7: Examples of CA-VQA data samples from the Regression (Metric Estimation) and 2D Grounding categories.
More on tables
| Model | Benchmark Category Averages | |||||
| Spatial | General | Knowl. | Text-rich | Ref./Ground | Avg. | |
| MM1.5-3B [128] | 39.9 | 64.7 | 46.2 | 62.1 | 77.7 | 58.1 |
| MM-Spatial-3B | 70.1 | 65.0 | 46.2 | 62.1 | 79.1 | 64.5 |
🔼 Table 2 presents a performance comparison between the MM-Spatial model and the MM1.5 baseline model across various benchmark categories. It highlights that MM-Spatial significantly improves performance in the ‘Spatial’ category while maintaining competitive performance with MM1.5 in other categories such as General, Knowledge, Text-rich, and Referring/Grounding. This demonstrates MM-Spatial’s effectiveness as a generalist multimodal large language model (MLLM) that excels in spatial reasoning without sacrificing performance on other tasks.
read the caption
Table 2: Benchmark Category Results MM-Spatial is a generalist MLLM that improves strongly on the Spatial category while rivaling the MM1.5 baseline across the other task categories.
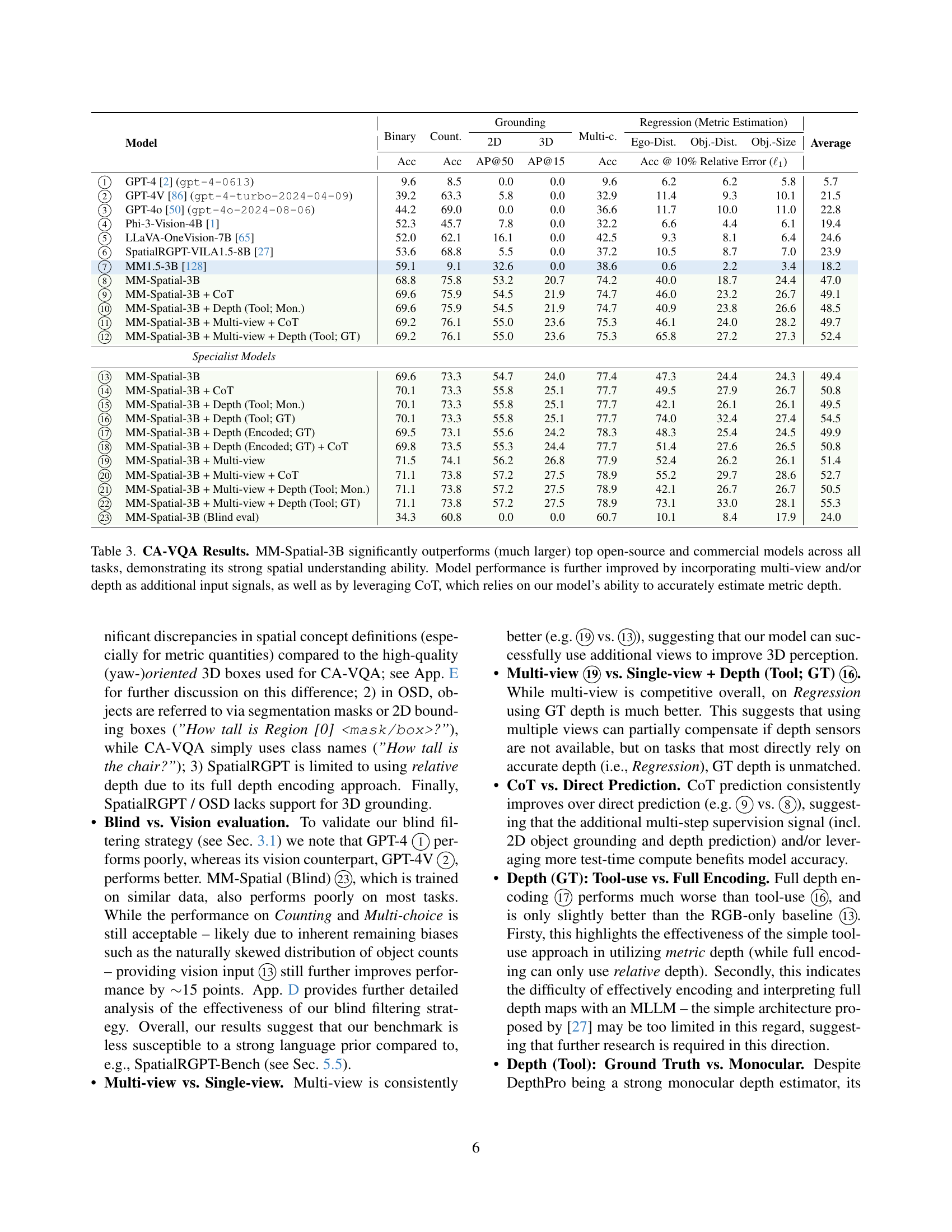
| Model | Binary | Count. | Grounding | Multi-c. | Regression (Metric Estimation) | Average | ||||
| 2D | 3D | Ego-Dist. | Obj.-Dist. | Obj.-Size | ||||||
| Acc | Acc | AP@50 | AP@15 | Acc | Acc @ 10% Relative Error () | |||||
| GPT-4 [2] (gpt-4-0613) | 9.6 | 8.5 | 0.0 | 0.0 | 9.6 | 6.2 | 6.2 | 5.8 | 5.7 | |
| GPT-4V [86] (gpt-4-turbo-2024-04-09) | 39.2 | 63.3 | 5.8 | 0.0 | 32.9 | 11.4 | 9.3 | 10.1 | 21.5 | |
| GPT-4o [50] (gpt-4o-2024-08-06) | 44.2 | 69.0 | 0.0 | 0.0 | 36.6 | 11.7 | 10.0 | 11.0 | 22.8 | |
| Phi-3-Vision-4B [1] | 52.3 | 45.7 | 7.8 | 0.0 | 32.2 | 6.6 | 4.4 | 6.1 | 19.4 | |
| LLaVA-OneVision-7B [65] | 52.0 | 62.1 | 16.1 | 0.0 | 42.5 | 9.3 | 8.1 | 6.4 | 24.6 | |
| SpatialRGPT-VILA1.5-8B [27] | 53.6 | 68.8 | 5.5 | 0.0 | 37.2 | 10.5 | 8.7 | 7.0 | 23.9 | |
| MM1.5-3B [128] | 59.1 | 9.1 | 32.6 | 0.0 | 38.6 | 0.6 | 2.2 | 3.4 | 18.2 | |
| MM-Spatial-3B | 68.8 | 75.8 | 53.2 | 20.7 | 74.2 | 40.0 | 18.7 | 24.4 | 47.0 | |
| MM-Spatial-3B + CoT | 69.6 | 75.9 | 54.5 | 21.9 | 74.7 | 46.0 | 23.2 | 26.7 | 49.1 | |
| MM-Spatial-3B + Depth (Tool; Mon.) | 69.6 | 75.9 | 54.5 | 21.9 | 74.7 | 40.9 | 23.8 | 26.6 | 48.5 | |
| MM-Spatial-3B + Multi-view + CoT | 69.2 | 76.1 | 55.0 | 23.6 | 75.3 | 46.1 | 24.0 | 28.2 | 49.7 | |
| MM-Spatial-3B + Multi-view + Depth (Tool; GT) | 69.2 | 76.1 | 55.0 | 23.6 | 75.3 | 65.8 | 27.2 | 27.3 | 52.4 | |
| Specialist Models | ||||||||||
| MM-Spatial-3B | 69.6 | 73.3 | 54.7 | 24.0 | 77.4 | 47.3 | 24.4 | 24.3 | 49.4 | |
| MM-Spatial-3B + CoT | 70.1 | 73.3 | 55.8 | 25.1 | 77.7 | 49.5 | 27.9 | 26.7 | 50.8 | |
| MM-Spatial-3B + Depth (Tool; Mon.) | 70.1 | 73.3 | 55.8 | 25.1 | 77.7 | 42.1 | 26.1 | 26.1 | 49.5 | |
| MM-Spatial-3B + Depth (Tool; GT) | 70.1 | 73.3 | 55.8 | 25.1 | 77.7 | 74.0 | 32.4 | 27.4 | 54.5 | |
| MM-Spatial-3B + Depth (Encoded; GT) | 69.5 | 73.1 | 55.6 | 24.2 | 78.3 | 48.3 | 25.4 | 24.5 | 49.9 | |
| MM-Spatial-3B + Depth (Encoded; GT) + CoT | 69.8 | 73.5 | 55.3 | 24.4 | 77.7 | 51.4 | 27.6 | 26.5 | 50.8 | |
| MM-Spatial-3B + Multi-view | 71.5 | 74.1 | 56.2 | 26.8 | 77.9 | 52.4 | 26.2 | 26.1 | 51.4 | |
| MM-Spatial-3B + Multi-view + CoT | 71.1 | 73.8 | 57.2 | 27.5 | 78.9 | 55.2 | 29.7 | 28.6 | 52.7 | |
| MM-Spatial-3B + Multi-view + Depth (Tool; Mon.) | 71.1 | 73.8 | 57.2 | 27.5 | 78.9 | 42.1 | 26.7 | 26.7 | 50.5 | |
| MM-Spatial-3B + Multi-view + Depth (Tool; GT) | 71.1 | 73.8 | 57.2 | 27.5 | 78.9 | 73.1 | 33.0 | 28.1 | 55.3 | |
| MM-Spatial-3B (Blind eval) | 34.3 | 60.8 | 0.0 | 0.0 | 60.7 | 10.1 | 8.4 | 17.9 | 24.0 | |
🔼 Table 3 presents a comprehensive evaluation of the MM-Spatial model on the Cubify Anything VQA (CA-VQA) benchmark. It compares MM-Spatial’s performance across various spatial reasoning tasks (binary classification, counting, multi-choice questions, and metric regression) against several leading open-source and commercial large language models. The results show that MM-Spatial-3B significantly surpasses these other models, highlighting its superior 3D spatial understanding capabilities. The table also demonstrates the positive impact of incorporating additional input signals, such as multi-view images and depth information (obtained through both tool-use and Chain-of-Thought reasoning), further enhancing the accuracy of MM-Spatial’s predictions. The improvement through chain-of-thought highlights the model’s ability to accurately estimate metric depth, a critical component in advanced spatial reasoning.
read the caption
Table 3: CA-VQA Results. MM-Spatial-3B significantly outperforms (much larger) top open-source and commercial models across all tasks, demonstrating its strong spatial understanding ability. Model performance is further improved by incorporating multi-view and/or depth as additional input signals, as well as by leveraging CoT, which relies on our model’s ability to accurately estimate metric depth.
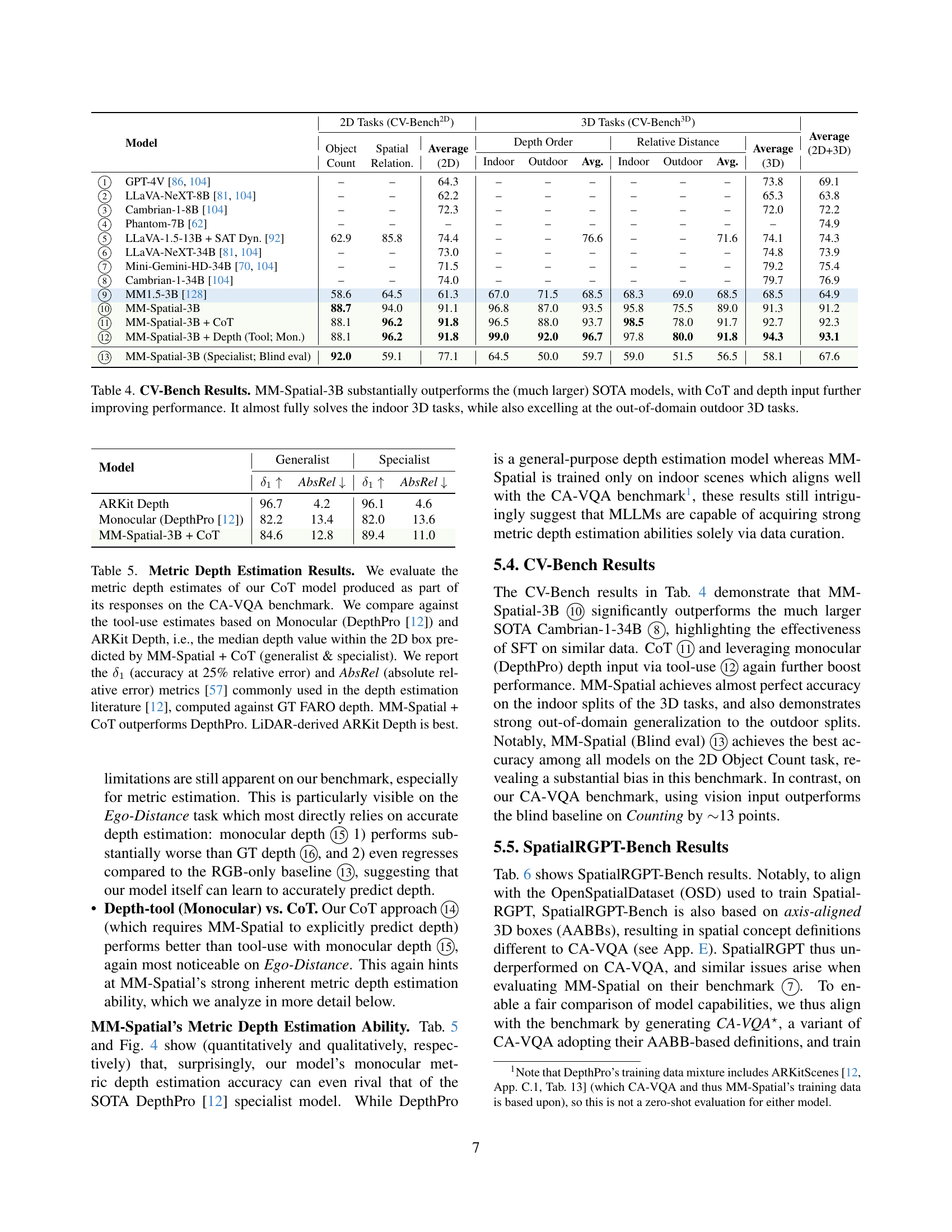
| Model | 2D Tasks (CV-Bench) | 3D Tasks (CV-Bench) | Average (2D+3D) | |||||||||
| Object Count | Spatial Relation. | Average (2D) | Depth Order | Relative Distance | Average (3D) | |||||||
| Indoor | Outdoor | Avg. | Indoor | Outdoor | Avg. | |||||||
| GPT-4V [86, 104] | – | – | 64.3 | – | – | – | – | – | – | 73.8 | 69.1 | |
| LLaVA-NeXT-8B [81, 104] | – | – | 62.2 | – | – | – | – | – | – | 65.3 | 63.8 | |
| Cambrian-1-8B [104] | – | – | 72.3 | – | – | – | – | – | – | 72.0 | 72.2 | |
| Phantom-7B [62] | – | – | – | – | – | – | – | – | – | – | 74.9 | |
| LLaVA-1.5-13B + SAT Dyn. [92] | 62.9 | 85.8 | 74.4 | – | – | 76.6 | – | – | 71.6 | 74.1 | 74.3 | |
| LLaVA-NeXT-34B [81, 104] | – | – | 73.0 | – | – | – | – | – | – | 74.8 | 73.9 | |
| Mini-Gemini-HD-34B [70, 104] | – | – | 71.5 | – | – | – | – | – | – | 79.2 | 75.4 | |
| Cambrian-1-34B [104] | – | – | 74.0 | – | – | – | – | – | – | 79.7 | 76.9 | |
| MM1.5-3B [128] | 58.6 | 64.5 | 61.3 | 67.0 | 71.5 | 68.5 | 68.3 | 69.0 | 68.5 | 68.5 | 64.9 | |
| MM-Spatial-3B | 88.7 | 94.0 | 91.1 | 96.8 | 87.0 | 93.5 | 95.8 | 75.5 | 89.0 | 91.3 | 91.2 | |
| MM-Spatial-3B + CoT | 88.1 | 96.2 | 91.8 | 96.5 | 88.0 | 93.7 | 98.5 | 78.0 | 91.7 | 92.7 | 92.3 | |
| MM-Spatial-3B + Depth (Tool; Mon.) | 88.1 | 96.2 | 91.8 | 99.0 | 92.0 | 96.7 | 97.8 | 80.0 | 91.8 | 94.3 | 93.1 | |
| MM-Spatial-3B (Specialist; Blind eval) | 92.0 | 59.1 | 77.1 | 64.5 | 50.0 | 59.7 | 59.0 | 51.5 | 56.5 | 58.1 | 67.6 | |
🔼 Table 4 presents a comprehensive comparison of MM-Spatial-3B’s performance on the CV-Bench benchmark against other state-of-the-art (SOTA) models. CV-Bench evaluates performance across both 2D and 3D spatial reasoning tasks. The results demonstrate that MM-Spatial-3B significantly surpasses the performance of larger SOTA models, particularly in 3D spatial reasoning tasks. Furthermore, incorporating Chain-of-Thought (CoT) reasoning and utilizing depth input (either via sensor or monocular depth estimation) further improves the performance of MM-Spatial-3B. Notably, MM-Spatial-3B achieves near-perfect accuracy on indoor 3D tasks and also shows high performance on outdoor 3D tasks, showcasing its ability to generalize well beyond the training data.
read the caption
Table 4: CV-Bench Results. MM-Spatial-3B substantially outperforms the (much larger) SOTA models, with CoT and depth input further improving performance. It almost fully solves the indoor 3D tasks, while also excelling at the out-of-domain outdoor 3D tasks.
| Model | Generalist | Specialist | ||
| AbsRel | AbsRel | |||
| ARKit Depth | 96.7 | 4.2 | 96.1 | 4.6 |
| Monocular (DepthPro [12]) | 82.2 | 13.4 | 82.0 | 13.6 |
| MM-Spatial-3B + CoT | 84.6 | 12.8 | 89.4 | 11.0 |
🔼 This table presents a quantitative evaluation of metric depth estimation. It compares the performance of the MM-Spatial model’s Chain-of-Thought (CoT) approach against two baselines: a monocular depth estimation model (DepthPro) and a LiDAR-based depth estimation method (ARKit Depth). The evaluation uses the CA-VQA benchmark and focuses on the accuracy of depth prediction, measured using two common metrics: δ1 (accuracy at 25% relative error) and AbsRel (absolute relative error). The results show that the MM-Spatial + CoT model surpasses DepthPro’s performance, although the LiDAR-based ARKit Depth remains the most accurate.
read the caption
Table 5: Metric Depth Estimation Results. We evaluate the metric depth estimates of our CoT model produced as part of its responses on the CA-VQA benchmark. We compare against the tool-use estimates based on Monocular (DepthPro [12]) and ARKit Depth, i.e., the median depth value within the 2D box predicted by MM-Spatial + CoT (generalist & specialist). We report the δ1subscript𝛿1\delta_{1}italic_δ start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT (accuracy at 25% relative error) and AbsRel (absolute relative error) metrics [57] commonly used in the depth estimation literature [12], computed against GT FARO depth. MM-Spatial + CoT outperforms DepthPro. LiDAR-derived ARKit Depth is best.
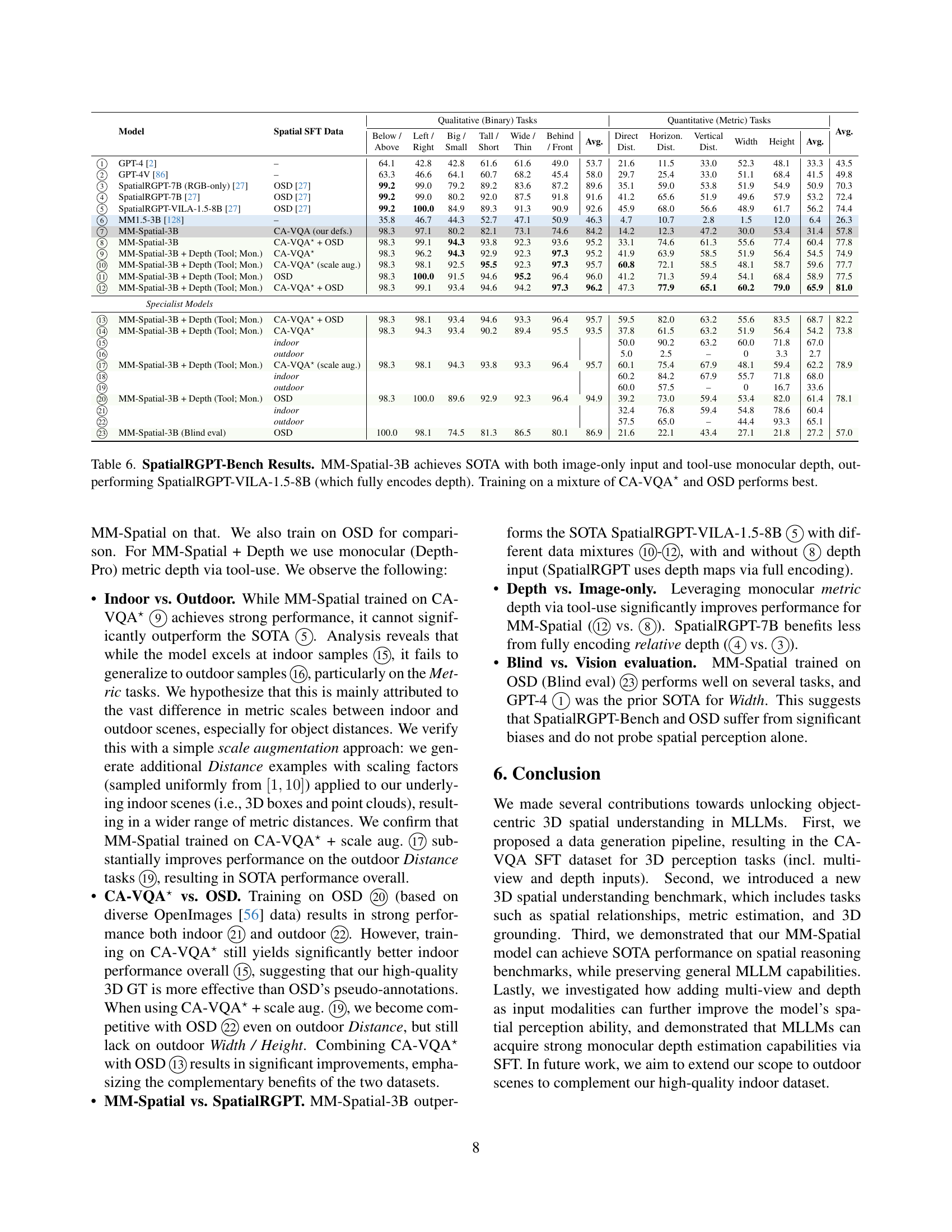
| Model | Spatial SFT Data | Qualitative (Binary) Tasks | Quantitative (Metric) Tasks | Avg. | ||||||||||||
| Below / Above | Left / Right | Big / Small | Tall / Short | Wide / Thin | Behind / Front | Avg. | Direct Dist. | Horizon. Dist. | Vertical Dist. | Width | Height | Avg. | ||||
| GPT-4 [2] | – | 64.1 | 42.8 | 42.8 | 61.6 | 61.6 | 49.0 | 53.7 | 21.6 | 11.5 | 33.0 | 52.3 | 48.1 | 33.3 | 43.5 | |
| GPT-4V [86] | – | 63.3 | 46.6 | 64.1 | 60.7 | 68.2 | 45.4 | 58.0 | 29.7 | 25.4 | 33.0 | 51.1 | 68.4 | 41.5 | 49.8 | |
| SpatialRGPT-7B (RGB-only) [27] | OSD [27] | 99.2 | 99.0 | 79.2 | 89.2 | 83.6 | 87.2 | 89.6 | 35.1 | 59.0 | 53.8 | 51.9 | 54.9 | 50.9 | 70.3 | |
| SpatialRGPT-7B [27] | OSD [27] | 99.2 | 99.0 | 80.2 | 92.0 | 87.5 | 91.8 | 91.6 | 41.2 | 65.6 | 51.9 | 49.6 | 57.9 | 53.2 | 72.4 | |
| SpatialRGPT-VILA-1.5-8B [27] | OSD [27] | 99.2 | 100.0 | 84.9 | 89.3 | 91.3 | 90.9 | 92.6 | 45.9 | 68.0 | 56.6 | 48.9 | 61.7 | 56.2 | 74.4 | |
| MM1.5-3B [128] | – | 35.8 | 46.7 | 44.3 | 52.7 | 47.1 | 50.9 | 46.3 | 4.7 | 10.7 | 2.8 | 1.5 | 12.0 | 6.4 | 26.3 | |
| MM-Spatial-3B | CA-VQA (our defs.) | 98.3 | 97.1 | 80.2 | 82.1 | 73.1 | 74.6 | 84.2 | 14.2 | 12.3 | 47.2 | 30.0 | 53.4 | 31.4 | 57.8 | |
| MM-Spatial-3B | CA-VQA⋆ + OSD | 98.3 | 99.1 | 94.3 | 93.8 | 92.3 | 93.6 | 95.2 | 33.1 | 74.6 | 61.3 | 55.6 | 77.4 | 60.4 | 77.8 | |
| MM-Spatial-3B + Depth (Tool; Mon.) | CA-VQA⋆ | 98.3 | 96.2 | 94.3 | 92.9 | 92.3 | 97.3 | 95.2 | 41.9 | 63.9 | 58.5 | 51.9 | 56.4 | 54.5 | 74.9 | |
| MM-Spatial-3B + Depth (Tool; Mon.) | CA-VQA⋆ (scale aug.) | 98.3 | 98.1 | 92.5 | 95.5 | 92.3 | 97.3 | 95.7 | 60.8 | 72.1 | 58.5 | 48.1 | 58.7 | 59.6 | 77.7 | |
| MM-Spatial-3B + Depth (Tool; Mon.) | OSD | 98.3 | 100.0 | 91.5 | 94.6 | 95.2 | 96.4 | 96.0 | 41.2 | 71.3 | 59.4 | 54.1 | 68.4 | 58.9 | 77.5 | |
| MM-Spatial-3B + Depth (Tool; Mon.) | CA-VQA⋆ + OSD | 98.3 | 99.1 | 93.4 | 94.6 | 94.2 | 97.3 | 96.2 | 47.3 | 77.9 | 65.1 | 60.2 | 79.0 | 65.9 | 81.0 | |
| Specialist Models | ||||||||||||||||
| MM-Spatial-3B + Depth (Tool; Mon.) | CA-VQA⋆ + OSD | 98.3 | 98.1 | 93.4 | 94.6 | 93.3 | 96.4 | 95.7 | 59.5 | 82.0 | 63.2 | 55.6 | 83.5 | 68.7 | 82.2 | |
| MM-Spatial-3B + Depth (Tool; Mon.) | CA-VQA⋆ | 98.3 | 94.3 | 93.4 | 90.2 | 89.4 | 95.5 | 93.5 | 37.8 | 61.5 | 63.2 | 51.9 | 56.4 | 54.2 | 73.8 | |
| indoor | 50.0 | 90.2 | 63.2 | 60.0 | 71.8 | 67.0 | ||||||||||
| outdoor | 5.0 | 2.5 | – | 0 | 3.3 | 2.7 | ||||||||||
| MM-Spatial-3B + Depth (Tool; Mon.) | CA-VQA⋆ (scale aug.) | 98.3 | 98.1 | 94.3 | 93.8 | 93.3 | 96.4 | 95.7 | 60.1 | 75.4 | 67.9 | 48.1 | 59.4 | 62.2 | 78.9 | |
| indoor | 60.2 | 84.2 | 67.9 | 55.7 | 71.8 | 68.0 | ||||||||||
| outdoor | 60.0 | 57.5 | – | 0 | 16.7 | 33.6 | ||||||||||
| MM-Spatial-3B + Depth (Tool; Mon.) | OSD | 98.3 | 100.0 | 89.6 | 92.9 | 92.3 | 96.4 | 94.9 | 39.2 | 73.0 | 59.4 | 53.4 | 82.0 | 61.4 | 78.1 | |
| indoor | 32.4 | 76.8 | 59.4 | 54.8 | 78.6 | 60.4 | ||||||||||
| outdoor | 57.5 | 65.0 | – | 44.4 | 93.3 | 65.1 | ||||||||||
| MM-Spatial-3B (Blind eval) | OSD | 100.0 | 98.1 | 74.5 | 81.3 | 86.5 | 80.1 | 86.9 | 21.6 | 22.1 | 43.4 | 27.1 | 21.8 | 27.2 | 57.0 | |
🔼 Table 6 presents a comparison of the performance of different models on the SpatialRGPT-Bench benchmark. The key finding is that MM-Spatial-3B achieves state-of-the-art (SOTA) results, surpassing even the SpatialRGPT-VILA-1.5-8B model, which uses full depth encoding. The table shows that MM-Spatial-3B’s performance improves further when using tool-use monocular depth. Additionally, it demonstrates that training MM-Spatial-3B on a combined dataset consisting of both CA-VQA* and OSD yields the best overall results.
read the caption
Table 6: SpatialRGPT-Bench Results. MM-Spatial-3B achieves SOTA with both image-only input and tool-use monocular depth, outperforming SpatialRGPT-VILA-1.5-8B (which fully encodes depth). Training on a mixture of CA-VQA⋆ and OSD performs best.
| Model | Benchmark Category Averages | ||||||||||
| Mix. Ratio | Spatial Understanding | General | Knowledge | Text-rich | Refer&Ground | Avg. | |||||
| Rel. | Eff. | CA-VQA | CV-Bench | SRGPT-Bench | Avg. | ||||||
| MM1.5-3B [128] | 0:1 | 0:100 | 28.9 | 64.9 | 26.0 | 39.9 | 64.7 | 46.2 | 62.1 | 77.7 | 58.1 |
| 1:1 | 12:88 | 66.3 | 91.2 | 52.8 | 70.1 | 65.0 | 46.2 | 62.1 | 79.1 | 64.5 | |
| MM-Spatial-3B | 2:1 | 22:78 | 67.1 | 92.4 | 53.7 | 71.1 | 64.8 | 46.7 | 61.4 | 78.8 | 64.5 |
| 4:1 | 36:64 | 67.3 | 93.0 | 52.7 | 71.0 | 65.0 | 44.9 | 60.7 | 78.0 | 63.9 | |
| 8:1 | 54:46 | 67.4 | 93.1 | 53.7 | 71.4 | 64.8 | 46.8 | 61.2 | 79.0 | 64.6 | |
| MM-Spatial-3B | 1:0 | 100:0 | 67.1 | 93.0 | 54.1 | 71.4 | 42.6 | 34.7 | 17.2 | 23.9 | 38.0 |
🔼 This table presents the results of experiments evaluating different ratios of training data for a multimodal large language model (MLLM) specialized for 3D spatial understanding. The model, MM-Spatial, was trained on a mixture of general-purpose data and spatial data from the CA-VQA dataset. The table compares performance across various benchmark categories (General, Knowledge, Text-rich, Referring & Grounding, and Spatial) for different ratios of spatial to general data in the training set (e.g., 0:1, 1:1, 2:1, 4:1, 8:1, 1:0). It shows that a 2:1 ratio provides a good balance between performance on the spatial category and maintaining performance on other categories, confirming the model’s generalist nature. The last row shows a control experiment training a specialized spatial model, illustrating that a generalist approach with mixed data is superior to a specialist approach using only CA-VQA data.
read the caption
Table 7: Data Mixture Ratio Results. Comparison of different data mixture ratios – both (Rel)ative to the General category (as in MM1.5), and (Eff)ective when considering the dataset sizes – on aggregated metrics across the different benchmark categories. Overall, MM-Spatial is a generalist MMLM that improves a lot on the Spatial category while maintaining strong performance on the other categories. The data mixture ratio of 2:1 (spatial:general) provides a good performance trade-off and is used for MM-Spatial throughout. The last line considers a spatial Specialist Model that is trained on CA-VQA only; this model provides only a minor improvement on the spatial category, while regressing substantially on all other benchmark categories.
| Model | Knowledge Benchmarks | General Benchmarks | |||||||
| AI2D (test) | MMMU (val) | MathV (testmini) | MME (P/C) | SEED | POPE | LLaVA | MM-Vet | RealWorldQA | |
| MiniCPM-V 2.0-3B [119] | 62.9 | 38.2 | 38.7 | 1808.2† | 67.1 | 87.8 | 69.2 | 38.2 | 55.8 |
| VILA1.5-3B [76] | – | 33.3 | – | 1442.4/– | 67.9 | 85.9 | – | – | – |
| SpatialRGPT-VILA-1.5-3B [27] | – | 33.0 | – | 1424.0/– | 69.0 | 85.5 | – | 38.2 | |
| TinyLLaVA [137] | – | – | – | 1464.9/– | – | 86.4 | 75.8 | 32.0 | – |
| Gemini Nano-2 [103] | 51.0 | 32.6 | 30.6 | – | – | – | – | – | – |
| Bunny [44] | – | 41.4 | – | 1581.5/361.1 | 72.5 | 87.2 | – | – | – |
| BLIP-3 [115] | – | 41.1 | 39.6 | – | 72.2 | 87.0 | – | – | 60.5 |
| Phi-3-Vision-4B [1] | 76.7 | 40.4 | 44.5 | 1441.6/320.0 | 71.8 | 85.8 | 71.6 | 46.2 | 59.4 |
| MM1.5-3B [128] | 64.5 | 37.1 | 37.1 | 1423.7/277.9 | 70.2 | 87.9 | 74.3 | 37.1 | 57.7 |
| MM-Spatial-3B | 63.6 | 36.6 | 38.4 | 1530.5/251.8 | 71.3 | 88.0 | 69.9 | 38.0 | 59.0 |
| Gemini-1.5-Pro [93] | 79.1 | 60.6 | 57.7 | 2110.6† | – | 88.2 | 95.3 | 64.0 | 64.1 |
| GPT-4V [86] | 75.9 | 53.8 | 48.7 | 1771.5† | 71.6 | 75.4 | 93.1 | 56.8 | 56.5 |
| GPT-4o [50] | 84.6 | 69.2 | 61.3 | 2310.3† | 77.1 | 85.6 | 102.0 | 69.1 | 75.4 |
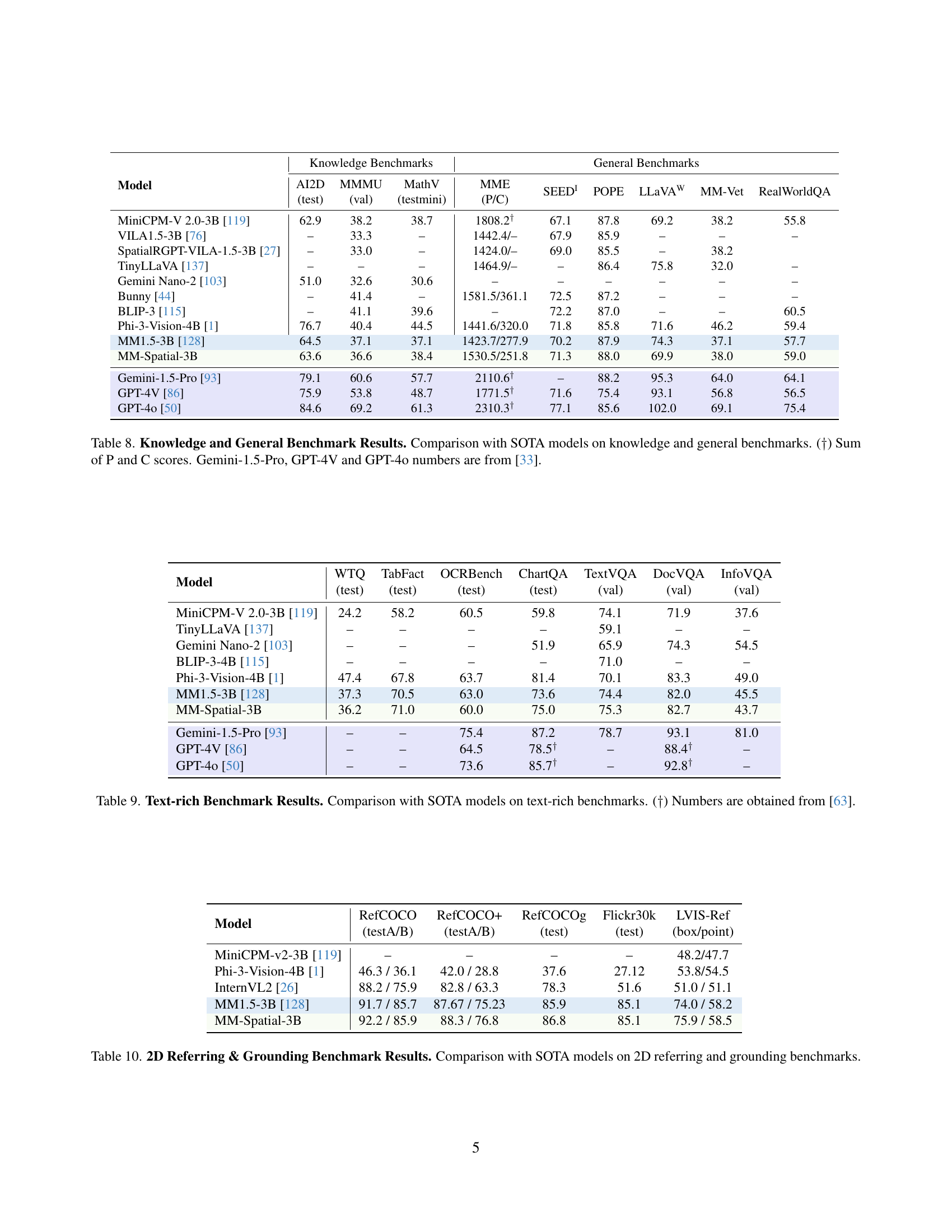
🔼 Table 8 presents a comparison of the MM-Spatial model’s performance against state-of-the-art (SOTA) models on a range of knowledge and general benchmark tasks. It shows scores for various sub-tasks within each benchmark, providing a comprehensive evaluation of the model’s capabilities beyond just spatial reasoning. Note that some SOTA model scores are sourced from a different reference paper ([33]). The table highlights the model’s ability to perform competitively on these general tasks while excelling in spatial understanding.
read the caption
Table 8: Knowledge and General Benchmark Results. Comparison with SOTA models on knowledge and general benchmarks. (††\dagger†) Sum of P and C scores. Gemini-1.5-Pro, GPT-4V and GPT-4o numbers are from [33].
| Model | WTQ (test) | TabFact (test) | OCRBench (test) | ChartQA (test) | TextVQA (val) | DocVQA (val) | InfoVQA (val) |
| MiniCPM-V 2.0-3B [119] | 24.2 | 58.2 | 60.5 | 59.8 | 74.1 | 71.9 | 37.6 |
| TinyLLaVA [137] | – | – | – | – | 59.1 | – | – |
| Gemini Nano-2 [103] | – | – | – | 51.9 | 65.9 | 74.3 | 54.5 |
| BLIP-3-4B [115] | – | – | – | – | 71.0 | – | – |
| Phi-3-Vision-4B [1] | 47.4 | 67.8 | 63.7 | 81.4 | 70.1 | 83.3 | 49.0 |
| MM1.5-3B [128] | 37.3 | 70.5 | 63.0 | 73.6 | 74.4 | 82.0 | 45.5 |
| MM-Spatial-3B | 36.2 | 71.0 | 60.0 | 75.0 | 75.3 | 82.7 | 43.7 |
| Gemini-1.5-Pro [93] | – | – | 75.4 | 87.2 | 78.7 | 93.1 | 81.0 |
| GPT-4V [86] | – | – | 64.5 | 78.5† | – | 88.4† | – |
| GPT-4o [50] | – | – | 73.6 | 85.7† | – | 92.8† | – |
🔼 This table presents a comparison of the performance of various models, including the proposed MM-Spatial model, on several text-rich benchmarks. The benchmarks assess the models’ abilities to understand and generate text in the context of rich textual data. The results are reported as scores and allow for a quantitative comparison of the different models’ capabilities in handling complex textual information.
read the caption
Table 9: Text-rich Benchmark Results. Comparison with SOTA models on text-rich benchmarks. (††\dagger†) Numbers are obtained from [63].
| Model | RefCOCO (testA/B) | RefCOCO+ (testA/B) | RefCOCOg (test) | Flickr30k (test) | LVIS-Ref (box/point) |
| MiniCPM-v2-3B [119] | – | – | – | – | 48.2/47.7 |
| Phi-3-Vision-4B [1] | 46.3 / 36.1 | 42.0 / 28.8 | 37.6 | 27.12 | 53.8/54.5 |
| InternVL2 [26] | 88.2 / 75.9 | 82.8 / 63.3 | 78.3 | 51.6 | 51.0 / 51.1 |
| MM1.5-3B [128] | 91.7 / 85.7 | 87.67 / 75.23 | 85.9 | 85.1 | 74.0 / 58.2 |
| MM-Spatial-3B | 92.2 / 85.9 | 88.3 / 76.8 | 86.8 | 85.1 | 75.9 / 58.5 |
🔼 This table compares the performance of the MM-Spatial model against state-of-the-art (SOTA) models on several established 2D referring and grounding benchmarks. It evaluates the model’s ability to accurately locate and identify objects within images using natural language descriptions. The benchmarks assess different aspects of this capability, and the table provides a quantitative comparison of results (e.g., accuracy scores) across these benchmarks.
read the caption
Table 10: 2D Referring & Grounding Benchmark Results. Comparison with SOTA models on 2D referring and grounding benchmarks.
| Model | Eval Inputs | Binary | Count. | Multi-c. | Regression (Metric Estimation) | Average | |||
| Ego-Dist. | Obj.-Dist. | Obj.-Size | |||||||
| Acc | Acc | Acc | Acc @ 10% Relative Error () | ||||||
| Before Blind Filtering | |||||||||
| GPT-4 [2] | Text | 57.9 | 35.1 | 52.7 | 8.9 | 8.2 | 17.0 | 30.0 | |
| GPT-4V [86] | Image + Text | 61.6 | 68.1 | 63.2 | 6.4 | 8.4 | 19.7 | 37.9 | |
| Improvement from using vision | = – | +3.7 | +33.0 | +10.5 | -2.5 | +0.2 | +2.7 | +7.9 | |
| MM-Spatial-3B (Specialist) | Text | 69.3 | 69.5 | 77.6 | 12.9 | 11.0 | 25.2 | 44.3 | |
| MM-Spatial-3B (Specialist) | Image + Text | 83.8 | 76.9 | 84.2 | 46.9 | 25.4 | 29.5 | 57.8 | |
| Improvement from using vision | = - | +14.5 | +7.4 | +6.6 | +34.0 | +14.4 | +4.3 | +13.5 | |
| After Blind Filtering | |||||||||
| GPT-4 [2] | Text | 9.6 | 8.5 | 9.6 | 6.2 | 6.2 | 5.8 | 7.7 | |
| GPT-4V [86] | Image + Text | 39.2 | 63.3 | 32.9 | 11.4 | 9.3 | 10.1 | 27.7 | |
| Improvement from using vision | = – | +29.6 | +54.8 | +23.3 | +5.2 | +3.1 | +4.3 | +20.0 | |
| MM-Spatial-3B (Specialist) | Text | 34.3 | 60.8 | 60.7 | 10.1 | 8.4 | 17.9 | 32.0 | |
| MM-Spatial-3B (Specialist) | Image + Text | 69.6 | 73.3 | 77.4 | 47.3 | 24.4 | 24.3 | 52.7 | |
| Improvement from using vision | = – | +35.3 | +12.5 | +16.7 | +37.2 | +16.0 | +6.4 | +20.7 | |
| Increase in Vision Improvement: Before vs. After Blind Filtering | |||||||||
| GPT-4/V | = – | +25.9 | +21.8 | +12.8 | +7.7 | +2.9 | +1.6 | +12.1 | |
| MM-Spatial-3B (Specialist) | = – | +20.8 | +5.1 | +10.1 | +3.2 | +1.6 | +2.1 | +7.2 | |
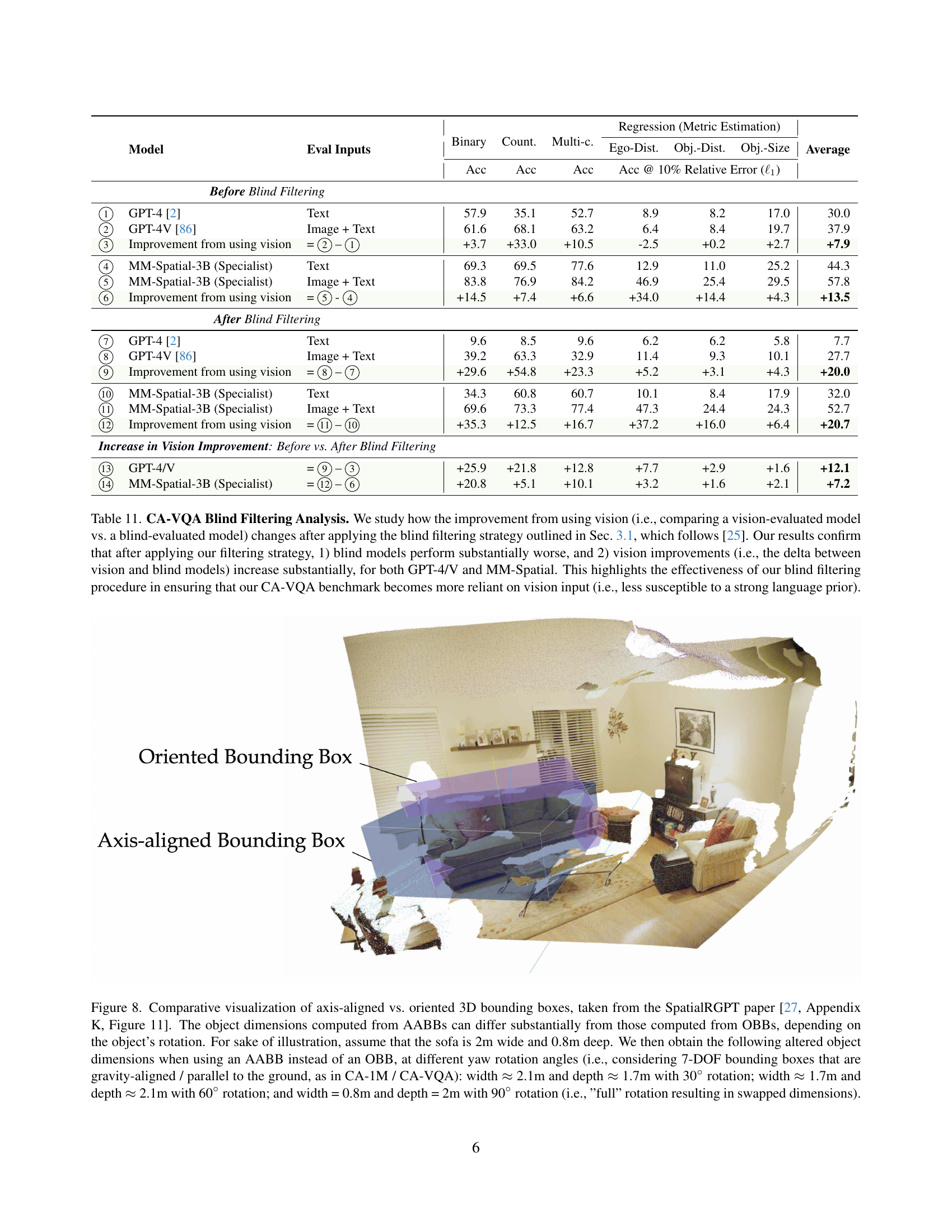
🔼 Table 11 analyzes the impact of a blind filtering technique on the CA-VQA benchmark. This technique removes questions easily solvable without visual input, thus increasing the benchmark’s reliance on visual reasoning. The table compares the performance of GPT-4, GPT-4V, and MM-Spatial models before and after applying the filter, both with and without visual input. The results show that after filtering, blind models (no visual input) perform significantly worse, while the improvement in performance gained by using visual input increases substantially for all models. This demonstrates that the filtering effectively reduces bias from language priors and enhances the benchmark’s ability to test true visual understanding.
read the caption
Table 11: CA-VQA Blind Filtering Analysis. We study how the improvement from using vision (i.e., comparing a vision-evaluated model vs. a blind-evaluated model) changes after applying the blind filtering strategy outlined in Sec. 3.1, which follows [25]. Our results confirm that after applying our filtering strategy, 1) blind models perform substantially worse, and 2) vision improvements (i.e., the delta between vision and blind models) increase substantially, for both GPT-4/V and MM-Spatial. This highlights the effectiveness of our blind filtering procedure in ensuring that our CA-VQA benchmark becomes more reliant on vision input (i.e., less susceptible to a strong language prior).
Full paper#