TL;DR#
Large Language Models combined with visual inputs(MLLMs) struggle to maintain focus on visual information as reasoning progresses, leading to text-over-reliance. This “visual forgetting” degrades performance, especially in tasks requiring continuous visual grounding like geometry problems. Analysis shows MLLMs diminish attention to images with increased context length, causing hallucinations and limiting full reasoning potential.
To tackle this, the paper introduces Take-along Visual Conditioning (TVC). It shifts image input to critical reasoning stages and compresses redundant visual tokens. TVC uses Dynamic Visual Reaffirmation (DVR) for training and Periodic Visual Calibration (PVC) at inference. TVC maintains visual attention throughout reasoning, improving performance on mathematical benchmarks by 3.4%.
Key Takeaways#
Why does it matter?#
This paper addresses the critical issue of visual forgetting in MLLMs, offering a promising solution with TVC. By enhancing visual grounding, it opens avenues for more robust and reliable multimodal reasoning, impacting diverse applications from robotics to medical imaging.
Visual Insights#

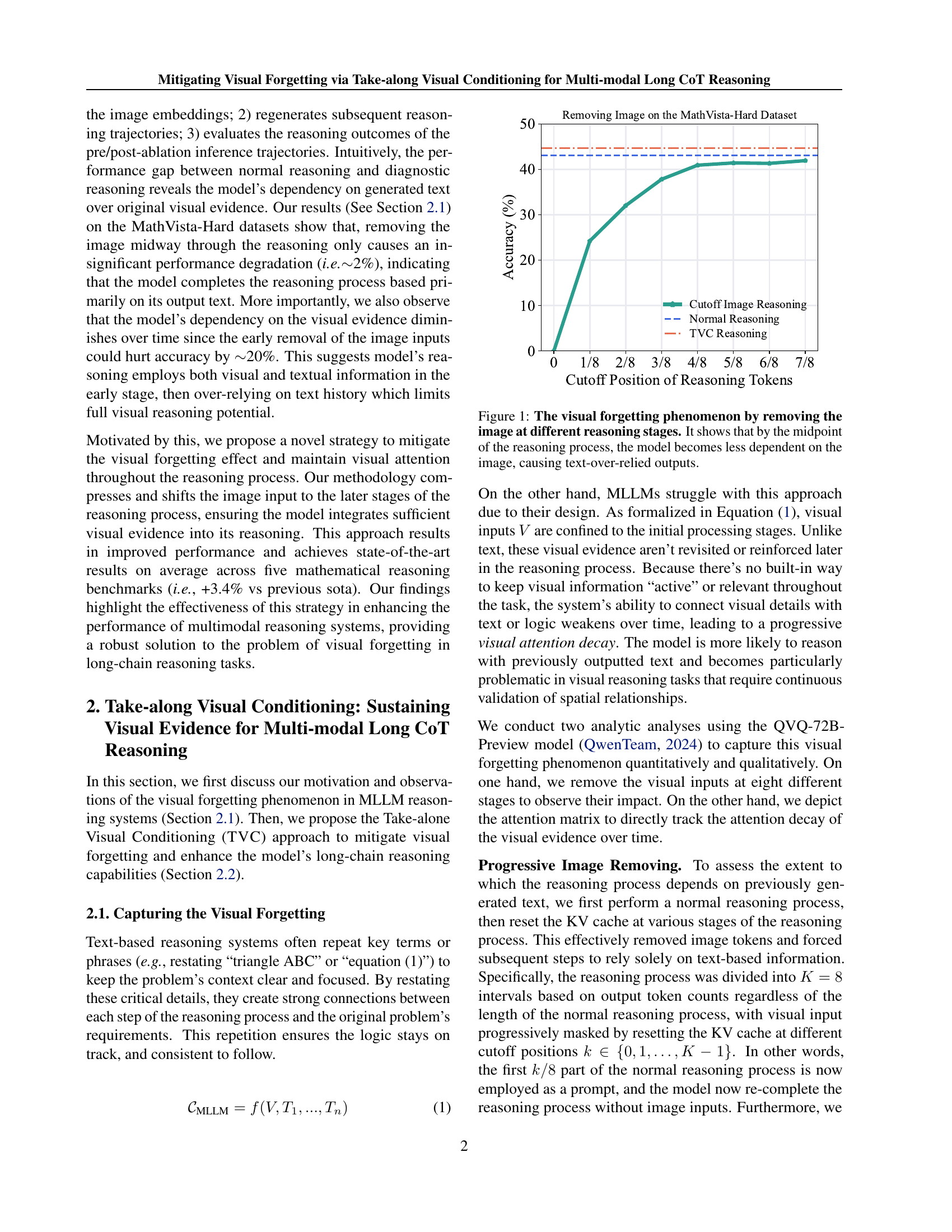
🔼 This figure illustrates the concept of ‘visual forgetting’ in multimodal LLMs. The experiment involves interrupting the reasoning process at various stages (indicated by the x-axis, ‘Cutoff Position of Reasoning Tokens’), removing the image input, and then letting the model continue the reasoning using only the text generated so far. The y-axis shows the accuracy of the model’s completion of the reasoning process. The blue line (‘Normal Reasoning’) represents the accuracy when the image is available throughout; the orange line (‘Cutoff Image Reasoning’) represents accuracy when the image is removed at various points. The small difference in accuracy between the two lines, especially as the cutoff position approaches the midpoint, demonstrates that the model increasingly relies on the generated text rather than the original image as reasoning progresses. This shift in reliance, where visual information is neglected, is termed ‘visual forgetting’.
read the caption
Figure 1: The visual forgetting phenomenon by removing the image at different reasoning stages. It shows that by the midpoint of the reasoning process, the model becomes less dependent on the image, causing text-over-relied outputs.
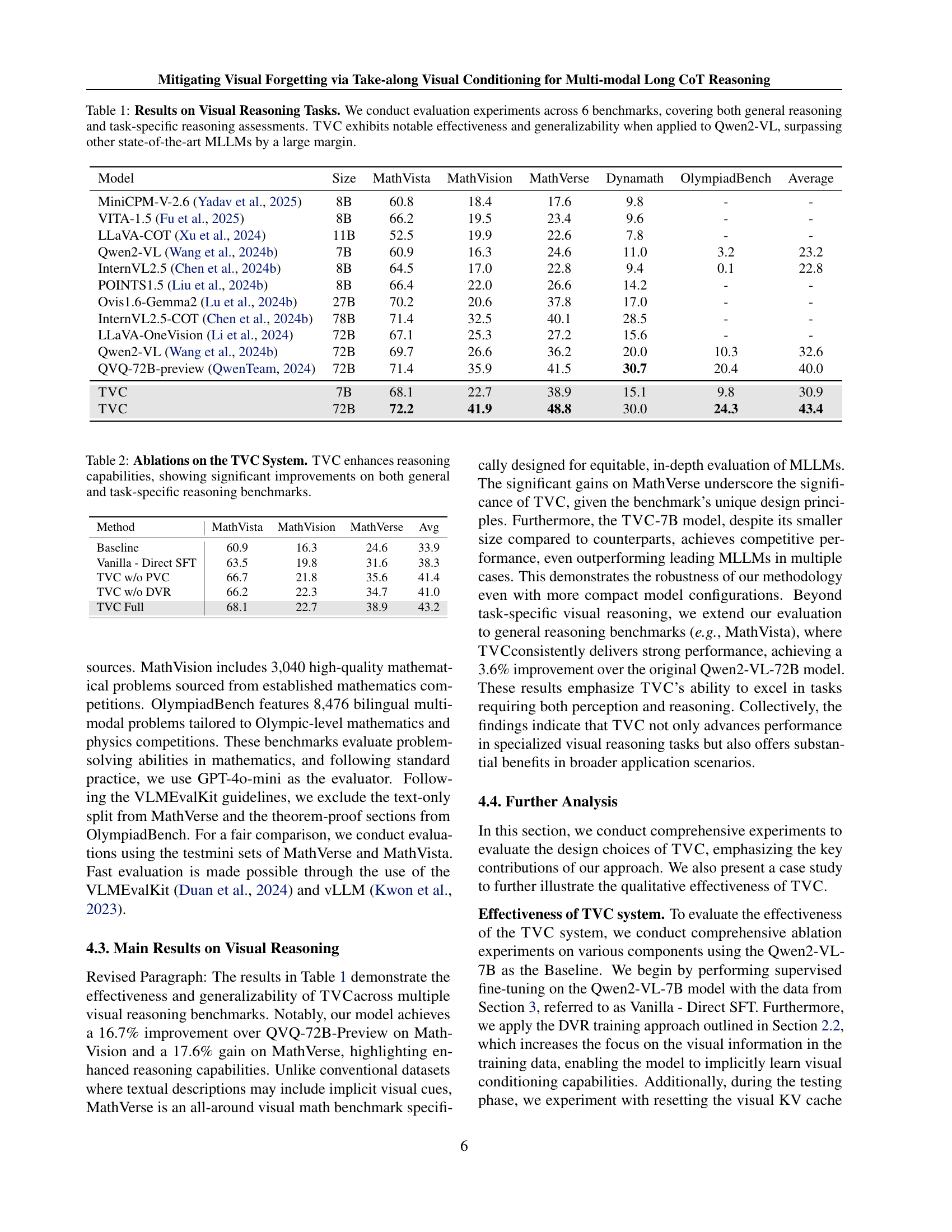
| Model | Size | MathVista | MathVision | MathVerse | Dynamath | OlympiadBench | Average |
| MiniCPM-V-2.6 (Yadav et al., 2025) | 8B | 60.8 | 18.4 | 17.6 | 9.8 | - | - |
| VITA-1.5 (Fu et al., 2025) | 8B | 66.2 | 19.5 | 23.4 | 9.6 | - | - |
| LLaVA-COT (Xu et al., 2024) | 11B | 52.5 | 19.9 | 22.6 | 7.8 | - | - |
| Qwen2-VL (Wang et al., 2024b) | 7B | 60.9 | 16.3 | 24.6 | 11.0 | 3.2 | 23.2 |
| InternVL2.5 (Chen et al., 2024b) | 8B | 64.5 | 17.0 | 22.8 | 9.4 | 0.1 | 22.8 |
| POINTS1.5 (Liu et al., 2024b) | 8B | 66.4 | 22.0 | 26.6 | 14.2 | - | - |
| Ovis1.6-Gemma2 (Lu et al., 2024b) | 27B | 70.2 | 20.6 | 37.8 | 17.0 | - | - |
| InternVL2.5-COT (Chen et al., 2024b) | 78B | 71.4 | 32.5 | 40.1 | 28.5 | - | - |
| LLaVA-OneVision (Li et al., 2024) | 72B | 67.1 | 25.3 | 27.2 | 15.6 | - | - |
| Qwen2-VL (Wang et al., 2024b) | 72B | 69.7 | 26.6 | 36.2 | 20.0 | 10.3 | 32.6 |
| QVQ-72B-preview (QwenTeam, 2024) | 72B | 71.4 | 35.9 | 41.5 | 30.7 | 20.4 | 40.0 |
| TVC | 7B | 68.1 | 22.7 | 38.9 | 15.1 | 9.8 | 30.9 |
| TVC | 72B | 72.2 | 41.9 | 48.8 | 30.0 | 24.3 | 43.4 |
🔼 Table 1 presents the performance comparison of various Multimodal Large Language Models (MLLMs) on six visual reasoning benchmarks. These benchmarks assess both general reasoning abilities and task-specific skills. The models are evaluated on their accuracy in solving problems that require understanding and reasoning with visual information alongside textual instructions. The table shows that the Take-along Visual Conditioning (TVC) method, when applied to the Qwen2-VL model, significantly improves performance compared to other state-of-the-art MLLMs across all six benchmarks.
read the caption
Table 1: Results on Visual Reasoning Tasks. We conduct evaluation experiments across 6 benchmarks, covering both general reasoning and task-specific reasoning assessments. TVC exhibits notable effectiveness and generalizability when applied to Qwen2-VL, surpassing other state-of-the-art MLLMs by a large margin.
In-depth insights#
Visual Attention Decay#
The concept of visual attention decay in multimodal models is intriguing. As models process information, the initial focus on visual elements diminishes, leading to a reliance on textual data. This decay impacts performance, especially in tasks needing sustained visual grounding. The challenge lies in maintaining consistent visual relevance throughout the processing steps. Effective solutions would re-emphasize visual inputs or develop methods to encode visual features more persistently within the model’s representation. Techniques like dynamic attention mechanisms or visual grounding techniques may help combat this. Further investigation is needed to understand how model architectures contribute to visual attention decay and how to mitigate its effects.
TVC: Reaffirming Vision#
Take-along Visual Conditioning (TVC) represents a method that re-injects visual inputs at strategic intervals, addressing visual attention decay. This strategy ensures visual evidence is revisited during decision-making, improving long-chain reasoning capacity. TVC mitigates visual forgetting by periodically reaffirming visual information. By actively reinforcing visual inputs throughout the reasoning process, TVC helps the model to maintain focus on relevant visual cues**, preventing over-reliance on textual context** and improving performance on tasks requiring continuous validation of spatial relationships.
Data-Centric MLLM#
Data-Centric Multimodal LLMs focus on enhancing performance through optimized data strategies. This involves curating high-quality datasets, employing data augmentation techniques, and strategically injecting visual information. Techniques like Dynamic Visual Reaffirmation are employed to iteratively reinforce visual evidence. The goal is to ensure models effectively integrate and utilize visual cues during reasoning, thus mitigating issues like visual forgetting. The success of these models heavily relies on the quality and diversity of training data which directly impacts the model’s reasoning and generation capabilities.
Visual Token Scaling#
Visual token scaling is a crucial aspect of multimodal learning, especially when dealing with large language models. Reducing the number of visual tokens while retaining essential information is paramount for computational efficiency and preventing the model from being overwhelmed by visual data. Strategies for visual token scaling include adaptive pooling, where image features are compressed using techniques like average pooling, reducing the spatial resolution while preserving semantic content. Another approach involves prioritizing salient visual features, selectively attending to the most informative regions of an image. Effective visual token scaling is a trade-off between compression and information retention. Too much compression can lead to a loss of crucial details, while insufficient scaling can hinder performance and increase computational costs. The goal is to optimize the visual representation so that the model can efficiently process and integrate visual information with textual data, ultimately improving the accuracy and efficiency of multimodal reasoning.
Beyond Visuals#
Beyond Visuals often refers to exploring avenues to enhance AI models that go beyond mere image or video processing. This could involve integrating other sensory inputs like audio, or tactile feedback, creating a richer, more nuanced understanding of the world. It also suggests improving models’ ability to infer abstract concepts or reason about the underlying physical properties that give rise to visual data. Further, the summary also includes improving multimodal understanding and reasoning using complex datasets for versatile real-world applications, which is crucial for creating truly intelligent AI systems capable of solving sophisticated problems. Lastly, it could refer to the ethical considerations around using AI-generated imagery, addressing concerns about bias, misinformation, and artistic integrity.
More visual insights#
More on figures

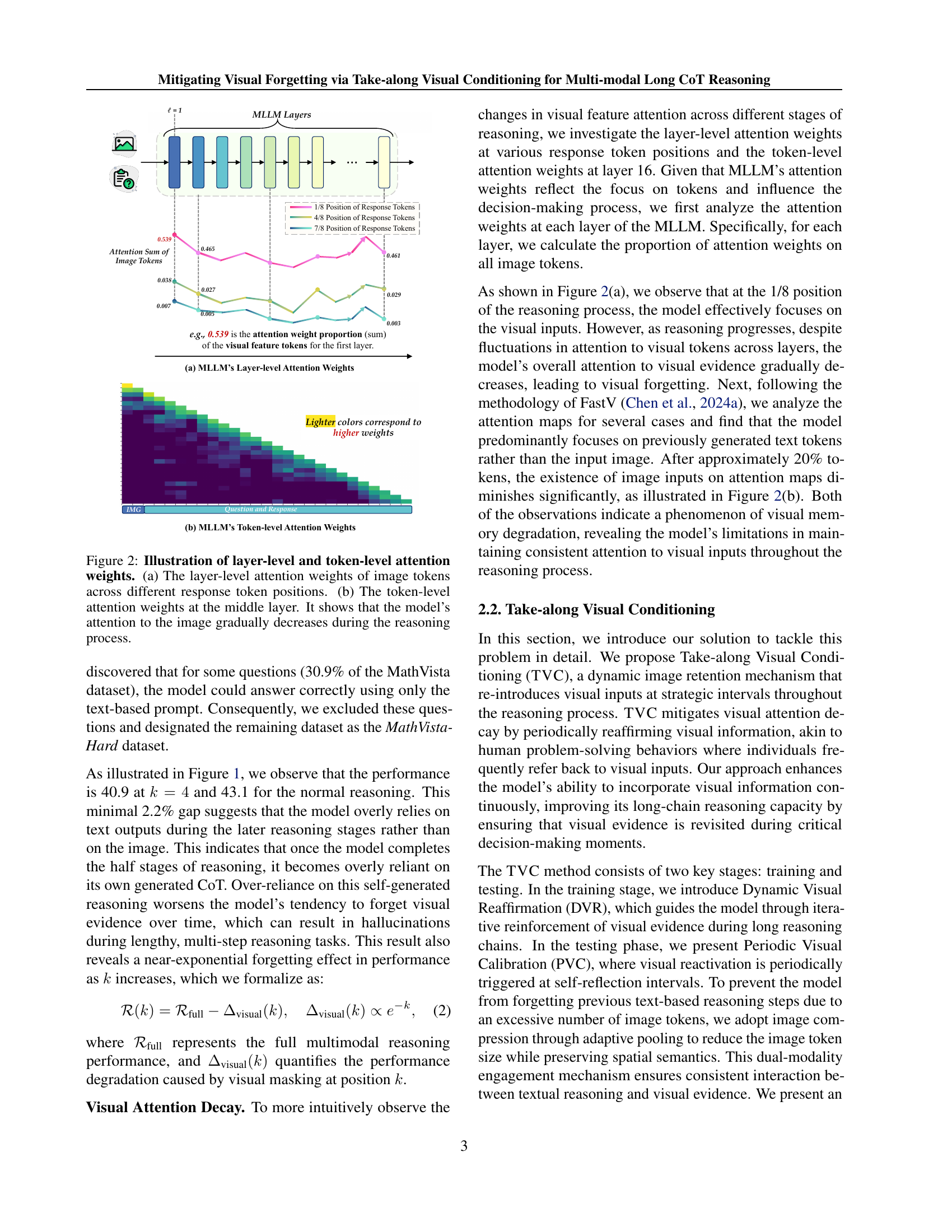
🔼 Figure 2 visualizes the model’s attention mechanism over the course of a multi-step reasoning process. Panel (a) displays the layer-level attention weights given to image tokens at various stages of the response generation. It demonstrates a clear trend: as the response progresses, the model’s focus on visual information diminishes. Panel (b) provides a detailed view of the token-level attention weights at a specific middle layer, further illustrating the gradual decrease in attention toward image tokens as the reasoning process unfolds. This figure directly supports the paper’s claim that models experience ‘visual forgetting’ during extended reasoning tasks, losing track of visual details in favor of the generated textual context.
read the caption
Figure 2: Illustration of layer-level and token-level attention weights. (a) The layer-level attention weights of image tokens across different response token positions. (b) The token-level attention weights at the middle layer. It shows that the model’s attention to the image gradually decreases during the reasoning process.

🔼 The figure illustrates the Take-along Visual Conditioning (TVC) system’s design, detailing its two-stage process. The training stage involves a Dynamic Visual Reaffirmation (DVR) method that strategically reinjects visual information at intervals during the reasoning process to maintain visual attention. The inference stage utilizes a Periodic Visual Calibration (PVC) mechanism that periodically re-introduces visual inputs, incorporating image compression to prevent information overload. The overall system design allows the model to retain and re-engage with visual information throughout the reasoning chain, thereby mitigating the effect of ‘visual forgetting’.
read the caption
Figure 3: Overview of TVC System Design. We enable the model to have take-along visual conditioning capabilities through two stages: training and inference.

🔼 This figure illustrates the process of creating a high-quality dataset for training the Take-along Visual Conditioning (TVC) model. It begins with an iterative distillation method where a teacher model generates long-chain reasoning data. This data then undergoes a multi-stage filtering process. The filtering process includes several steps to eliminate low-quality responses, ensure data consistency and improve the efficiency of the reasoning process. The steps are: (1) Deterministic Initial Sampling using a temperature of 0 to get highly confident results; (2) Answer-Centric Reject Sampling where an LLM is used to validate answers and filter out incorrect ones; (3) Best-of-N Error Correction to recover potential errors in data; and finally (4) filtering for length and removal of reflection words to ensure reasoning quality and remove redundancy. The end result is a refined dataset that greatly enhances the TVC model’s performance.
read the caption
Figure 4: Data Generation Pipeline of TVC. We use iterative distillation to collect long-chain reasoning data, followed by a comprehensive response filtering process to ensure high-quality reasoning.

🔼 This figure shows the impact of varying amounts of training data on the performance of the Take-along Visual Conditioning (TVC) model. The x-axis represents the amount of training data used (in thousands), and the y-axis represents the relative performance of the model compared to a baseline. As the amount of training data increases, the relative performance of the TVC model consistently improves, demonstrating its ability to benefit from and leverage larger datasets for improved reasoning capabilities.
read the caption
Figure 5: Ablations on the amount of training data. TVC benefits from data scaling, continually improving the reasoning capabilities.

🔼 This figure shows a case study comparing the reasoning process of a base model (without Take-along Visual Conditioning or TVC) and the TVC model. The task is a visual question answering problem involving identifying which cube in a set does not match a given unfolded net. The base model incorrectly identifies the answer due to neglecting certain object attributes when reasoning from the image. In contrast, the TVC model uses dynamic visual reaffirmation. This means that during the reasoning process, the model pauses and revisits the image, allowing it to re-focus on essential details and correct the initial error, leading to the correct answer. The attention weights at the token level are also displayed to illustrate this refocusing behavior.
read the caption
Figure 6: Case Study of TVC. TVC effectively re-examines the image during the reflection process to correct mistakes, guiding the model to the correct answer.

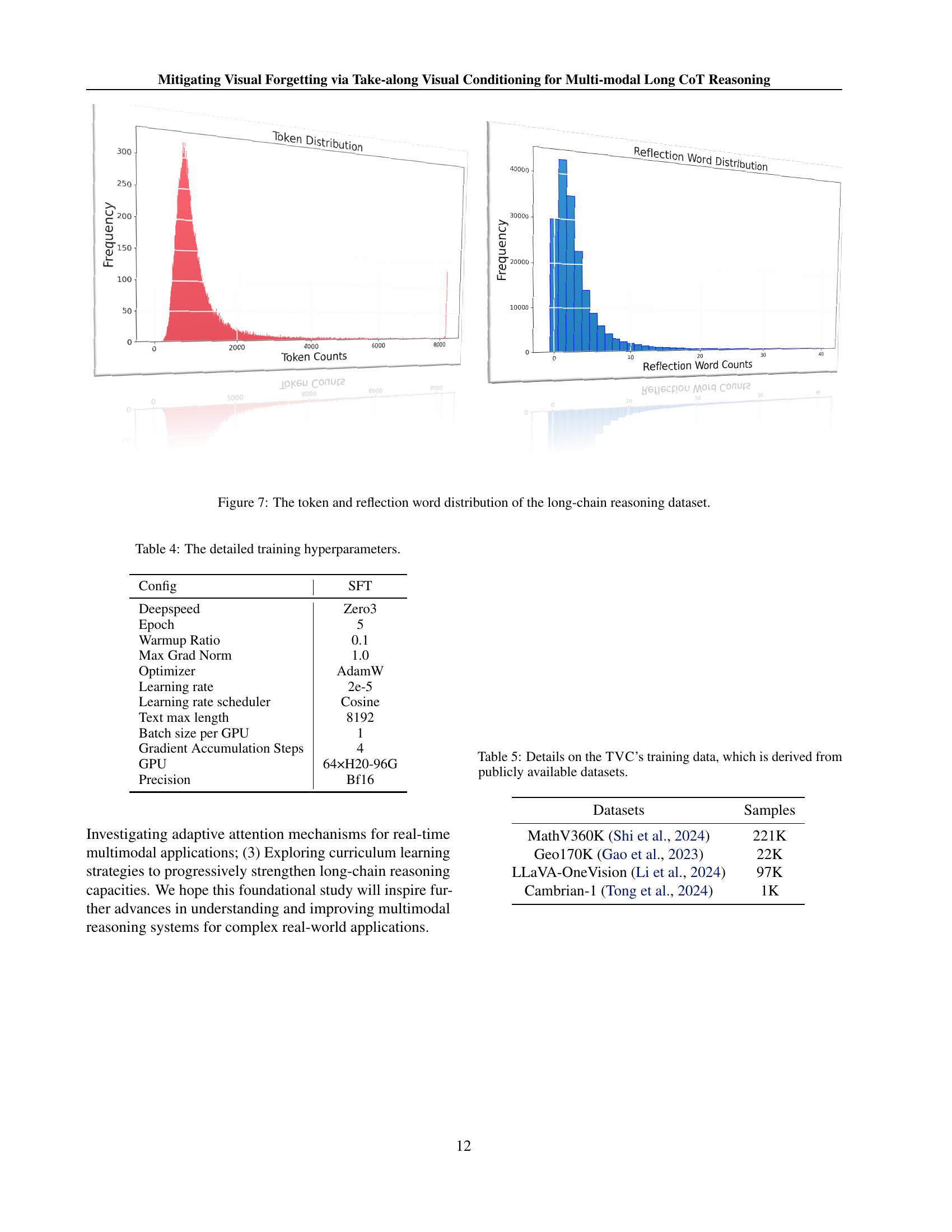
🔼 This figure shows two histograms visualizing the distribution of token counts and reflection word counts within a dataset used for long-chain reasoning. The left histogram displays the distribution of token counts, revealing that most reasoning chains have a moderate number of tokens, while a smaller number of chains have significantly more tokens. This indicates the dataset contains both concise and more elaborate reasoning chains. The right histogram displays the distribution of reflection word counts, a metric relating to the frequency with which a model’s reasoning process involves revisiting prior steps or considering alternative paths. A concentration in the lower counts suggests that most reasoning chains involve a limited amount of self-reflection. This implies that most reasoning chains proceeded in a relatively linear fashion, with only some involving repeated or iterative considerations.
read the caption
Figure 7: The token and reflection word distribution of the long-chain reasoning dataset.

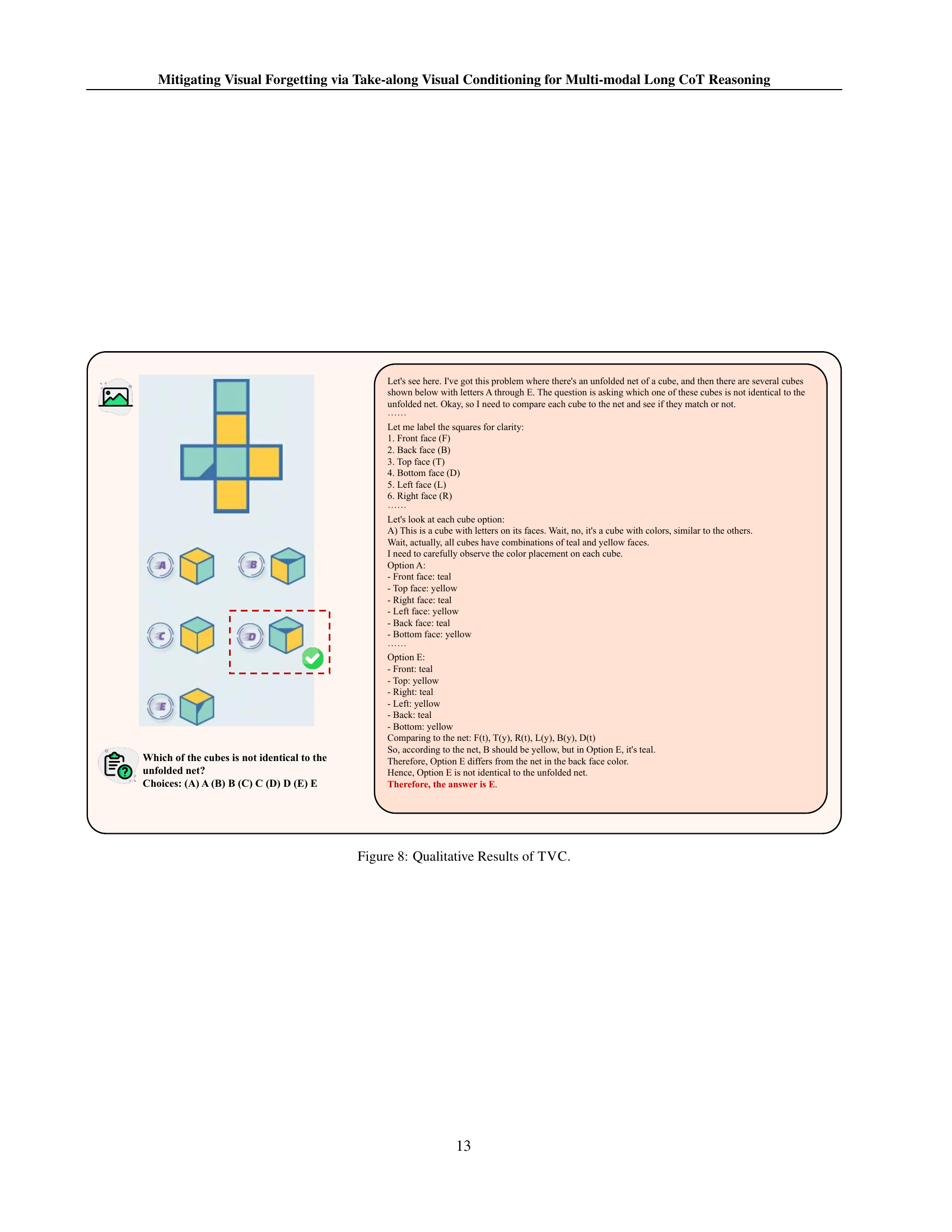
🔼 Figure 8 shows a qualitative example illustrating how Take-along Visual Conditioning (TVC) improves the reasoning process. The task involves identifying which cube doesn’t match a given unfolded net. The base CoT reasoning method makes an incorrect conclusion due to a lack of attention to details. The TVC method, however, demonstrates a step-by-step reasoning process that correctly identifies the mismatched cube by explicitly revisiting and analyzing the visual information, highlighting the benefits of TVC in maintaining visual attention during complex reasoning tasks.
read the caption
Figure 8: Qualitative Results of TVC.
More on tables
| Method | MathVista | MathVision | MathVerse | Avg |
| Baseline | 60.9 | 16.3 | 24.6 | 33.9 |
| Vanilla - Direct SFT | 63.5 | 19.8 | 31.6 | 38.3 |
| TVC w/o PVC | 66.7 | 21.8 | 35.6 | 41.4 |
| TVC w/o DVR | 66.2 | 22.3 | 34.7 | 41.0 |
| TVC Full | 68.1 | 22.7 | 38.9 | 43.2 |
🔼 Table 2 presents an ablation study evaluating the impact of different components of the Take-along Visual Conditioning (TVC) system on reasoning performance. It compares the performance of a baseline model (no TVC) against models using only periodic visual calibration (PVC), only dynamic visual reaffirmation (DVR), and the full TVC system across multiple reasoning benchmarks (MathVista, MathVision, MathVerse). The results demonstrate that the TVC system, combining both PVC and DVR, significantly enhances reasoning capabilities on both general and task-specific benchmarks.
read the caption
Table 2: Ablations on the TVC System. TVC enhances reasoning capabilities, showing significant improvements on both general and task-specific reasoning benchmarks.
| Method | MathVista | MathVision | MathVerse | Avg |
| TVC Baseline | 68.3 | 21.5 | 39.6 | 43.1 |
| + 2x2 Avg Pooling | 67.8 | 22.9 | 38.3 | 43.0 |
| + 4x4 Avg Pooling | 68.1 | 22.7 | 38.9 | 43.2 |
🔼 This table presents the results of ablation studies conducted to evaluate the impact of different token compression techniques on the model’s performance. It compares the performance (measured across MathVista, MathVision, and MathVerse benchmarks) of the baseline TVC model with variations using 2x2 and 4x4 average pooling for visual token compression. The average performance across all three benchmarks is also provided for comparison, illustrating the effect of different compression strategies on the overall model’s ability to reason effectively.
read the caption
Table 3: Ablations on Token Compression.
| Config | SFT |
| Deepspeed | Zero3 |
| Epoch | 5 |
| Warmup Ratio | 0.1 |
| Max Grad Norm | 1.0 |
| Optimizer | AdamW |
| Learning rate | 2e-5 |
| Learning rate scheduler | Cosine |
| Text max length | 8192 |
| Batch size per GPU | 1 |
| Gradient Accumulation Steps | 4 |
| GPU | 64×H20-96G |
| Precision | Bf16 |
🔼 Table 4 provides a comprehensive overview of the hyperparameters used during the training phase of the Take-along Visual Conditioning (TVC) system. It details the specific configurations and settings employed to optimize the model’s performance. This includes information about the deepspeed configuration, number of training epochs, learning rate and scheduler, maximum gradient norm, optimizer used, text maximum length, batch size per GPU, and gradient accumulation steps. The precision of the training process is also specified, providing a clear picture of the technical specifications behind the training methodology.
read the caption
Table 4: The detailed training hyperparameters.
| Datasets | Samples |
| MathV360K (Shi et al., 2024) | 221K |
| Geo170K (Gao et al., 2023) | 22K |
| LLaVA-OneVision (Li et al., 2024) | 97K |
| Cambrian-1 (Tong et al., 2024) | 1K |
🔼 This table details the composition of the training data used for the Take-along Visual Conditioning (TVC) model. It lists the publicly available datasets that were combined to create the TVC training set and specifies the number of samples contributed by each dataset.
read the caption
Table 5: Details on the TVC’s training data, which is derived from publicly available datasets.
Full paper#