TL;DR#
Multi-Agent Systems (MAS) are hyped, but often flop! This study dives deep, analyzing 5 frameworks across 150+ tasks. Six experts tagged 14 failure modes, like poor design, agent miscommunication, and bad task handling. They built MASFT, a taxonomy to classify these issues, for better analysis and fixes. LLM-as-a-Judge aids scalable scoring.
They tried quick fixes- better prompts and coordination- but saw only slight gains. This suggests deep design flaws need fixing, not just surface tweaks. The MASFT framework and open-sourced data offer a roadmap for future MAS research, pushing beyond current limits. The long-term goal: making MAS a truly potent AI tool.
Key Takeaways#
Why does it matter?#
This work provides a crucial taxonomy of failures in MAS, informing future designs & benchmarks. By identifying common pitfalls, it accelerates the development of robust, reliable multi-agent systems, pushing AI research towards more effective collaboration strategies.
Visual Insights#

🔼 This figure presents the failure rates observed across five prominent Multi-Agent Large Language Model (LLM) systems. Each system was evaluated using two state-of-the-art LLMs: GPT-4o and Claude-3. The bar chart visually represents the percentage of failures recorded during system operation, enabling a direct comparison of system robustness.
read the caption
Figure 1: Failure rates of five popular Multi-Agent LLM Systems with GPT-4o and Claude-3.
| MAS | Agentic Architecture | Purpose of the System |
| MetaGPT (Hong et al., 2023) | Assembly Line | Simulating the SOPs of different roles in Software Companies to create open-ended software applications |
| ChatDev (Qian et al., 2023) | Hierarchical Workflow | Simulating different Software Engineering phases like (design, code, QA) through simulated roles in a software engineering company |
| HyperAgent (Phan et al., 2024) | Hierarchical Workflow | Simulating a software engineering team with a central Planner agent coordinating with specialized child agents (Navigator, Editor, and Executor) |
| AppWorld (Trivedi et al., 2024) | Star Topology | Tool-calling agents specialized to utility services (ex: GMail, Spotify, etc.) being orchestrated by a supervisor to achieve cross-service tasks |
| AG2 (Wu et al., 2024a) | N/A - Agentic Framework | An open-source programming framework for building agents and managing their interactions. |
🔼 This table lists the Multi-Agent Systems (MAS) used in the study, each with at least 30 human-annotated traces. For each MAS, the table provides the name, the type of agent architecture it employs (e.g., assembly line, hierarchical, workflow), and a brief description of its purpose. More detailed information on these MASs, including those with fewer than 30 traces, is available in Appendix B of the paper.
read the caption
Table 1: Table of MASs studied with at least 30 human-annotated traces. Details and other systems can be found in Appendix B.
In-depth insights#
MAS Failure Tax#
While “MAS Failure Tax” is not a direct heading, the paper extensively covers failure modes in Multi-Agent Systems (MAS). The core idea here is that MAS, while promising, often underperform compared to simpler systems. This ‘failure tax’ stems from several key factors. Poor specification of agent roles and tasks leads to miscommunication and task derailment. Inter-agent misalignment, arising from ineffective communication or conflicting actions, further compounds the issue. Crucially, the paper emphasizes the lack of robust verification and termination mechanisms, hindering quality control. This ’tax’ isn’t just about individual agent limitations; it’s deeply rooted in the MAS design itself. Addressing this requires a shift towards better organizational understanding within MAS architectures, focusing on improved communication protocols and robust verification strategies.
LLM as MAS Judge#
The concept of using an LLM as a judge for multi-agent systems (MAS) is intriguing, offering a scalable evaluation. Automated assessment of MAS performance is crucial, considering the complexity of agent interactions. The LLM’s ability to evaluate textual data could streamline failure mode analysis. However, LLM bias is a significant concern. A cross-verification with human experts becomes essential to validate its reliability. The agreement rate of 0.77 with human experts suggests promise, it highlights the need for caution. The LLM as judge should be seen as a preliminary step, aiding human annotators rather than replacing them entirely. Further work would require focusing on bias reduction and improved contextual understanding.
HRO Design Needed#
MASFT’s identification of HRO characteristic violations underscores the need for non-trivial, HRO-inspired interventions. Current failure modes, such as disobeying role specifications, directly counter HRO principles like extreme hierarchical differentiation. This calls for design principles borrowed from high-reliability organizations to guide the development of more robust MAS architectures. This could involve establishing clearer lines of communication, improving inter-agent coordination through formalized protocols, and emphasizing deference to expertise to prevent agents from overstepping their boundaries. More fundamentally, it might necessitate a re-evaluation of MAS design, moving beyond simple aggregations of agents towards systems exhibiting emergent organizational intelligence capable of mitigating inherent interaction flaws.
Structural MAS Fix#
Structural Multi-Agent System (MAS) fixes involve fundamental redesigns. Strong verification is critical, exceeding unit tests to encompass coding, QA, and reasoning with symbolic validation. Standardized communication protocols tackle LLM ambiguity by defining intentions and parameters, enabling formal coherence checks. Graph attention mechanisms model agent interactions, enhancing coordination. Reinforcement learning refines agent behavior, aligning actions with tasks via algorithms like MAPPO and SHPPO. Probabilistic confidence measures enhance decision-making by informing agents to only act above a confidence threshold and gather data when unsure, improving reliability and decision quality. Memory and state management addresses limited context and enhance understanding.
Agent Role Viol.#
Agent Role Violation is a critical failure mode in multi-agent systems (MAS). It occurs when an agent deviates from its assigned responsibilities, potentially causing system-wide disruptions. This can manifest as agents assuming unauthorized tasks or neglecting duties. Such violations disrupt the intended workflow, impacting task completion, goal alignment, and overall system robustness. The taxonomy of these failures highlights that system performance is not solely dependent on individual agent competence, but requires well-defined agent roles and responsibilities for collaboration. Addressing such failures necessitates robust mechanisms to enforce role adherence, prevent agents from exceeding their authority, and ensure accountability in task execution. Effective monitoring and verification mechanisms are vital to detect and rectify role violations promptly, thus safeguarding system integrity.
More visual insights#
More on figures

🔼 This figure presents a taxonomy of failure modes in Multi-Agent Systems (MAS). The taxonomy categorizes failures into three main areas: specification and system design, inter-agent misalignment, and task verification and termination. Within each area, several specific failure modes are identified, along with the percentage of times they appeared in the analysis of 151 MAS traces. The chart also shows the stages of an agent conversation where each failure mode is likely to occur. More details about each failure mode can be found in Appendix A.
read the caption
Figure 2: A Taxonomy of MAS Failure Modes. The inter-agent conversation stages indicate when a failure can occur in the end-to-end MAS system. If a failure mode spans multiple stages, it means the issue involves or can occur at different stages. Percentages represent how frequently each failure mode and category appeared in our analysis of 151 traces. Detailed definition and example of each failure mode is available in Appendix A.

🔼 This figure illustrates the research methodology used in the study. The process begins with collecting data from various Multi-Agent Systems (MAS). Then, failure modes are identified within these MAS datasets. Next, an iterative refinement process is conducted through inter-annotator agreement studies to enhance the consistency and precision of the taxonomy. This iterative process aims at achieving a high level of agreement among multiple annotators, as measured by Cohen’s Kappa score (0.88 in this case). Finally, a refined taxonomy of MAS failure modes is produced.
read the caption
Figure 3: Methodological workflow for systematically studying MAS, involving the identification of failure modes, taxonomy development, and iterative refinement through inter-annotator agreement studies by achieving a Cohen’s Kappa score of 0.88.

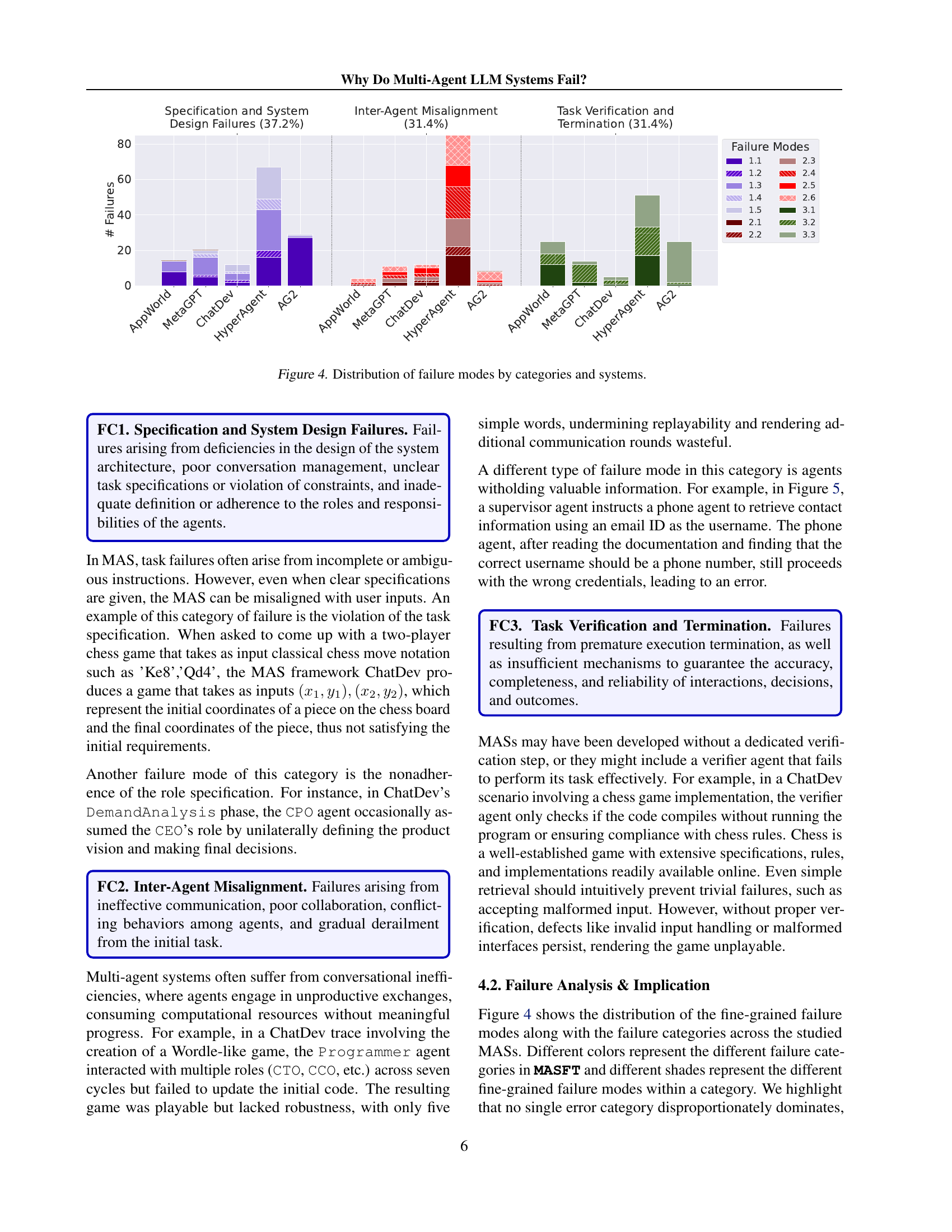
🔼 This figure presents a detailed breakdown of the distribution of various failure modes across different multi-agent systems (MAS). It visually displays how many times each failure mode was observed within three categories: Specification and System Design Failures, Inter-Agent Misalignment, and Task Verification and Termination. The figure uses a bar chart to show the number of failures in each category for each of the five MASs studied: MetaGPT, ChatDev, HyperAgent, AppWorld, and AG2.
read the caption
Figure 4: Distribution of failure modes by categories and systems.

🔼 The figure illustrates a failure mode in a multi-agent system where two agents, a Phone Agent and a Supervisor Agent, fail to successfully complete a login task due to miscommunication. The Phone Agent does not correctly convey the API requirements for login, specifically regarding the proper username format (phone number instead of email address). Simultaneously, the Supervisor Agent neglects to clarify any ambiguities or seek further clarification from the Phone Agent. This lack of collaborative effort results in repeated, unproductive attempts to log in and eventually leads to the task’s failure, marked by the Supervisor Agent. The diagram highlights the information flow and the points of miscommunication during the agents’ interaction.
read the caption
Figure 5: Phone Agent fails to communicate the API specifications and login username requirements to the Supervisor. At the other end of the conversation, the Supervisor Agent also fails to seek clarification on the login details. After a few back-and-forth attempts, the Supervisor Agent marks the task as failed.

🔼 This heatmap visualizes the correlation coefficients between the three overarching failure categories identified in the Multi-Agent System Failure Taxonomy (MASFT): Specification and System Design Failures, Inter-Agent Misalignment, and Task Verification and Termination. Each cell’s color intensity represents the strength and direction of the correlation, ranging from strong positive (dark red) to strong negative (dark blue), with lighter colors indicating weaker correlations. The diagonal shows perfect correlation (1.0) for each category with itself.
read the caption
Figure 6: MAS failure categories correlation matrix.

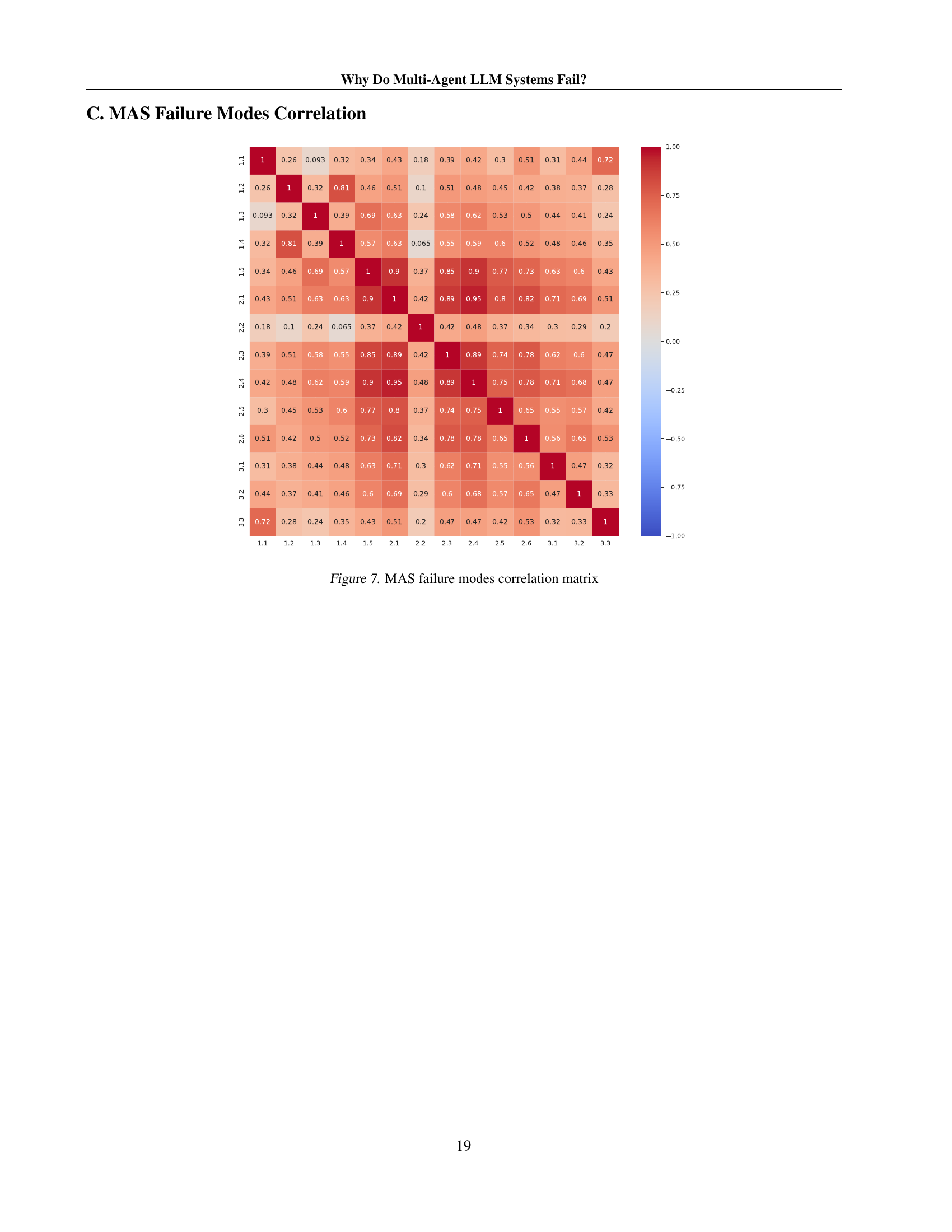
🔼 This heatmap visualizes the correlation coefficients between pairs of failure modes identified in the MASFT taxonomy. Each cell represents the correlation between two failure modes, with darker red indicating stronger positive correlation, and darker blue indicating stronger negative correlation. The values range from -1 (perfect negative correlation) to 1 (perfect positive correlation), with 0 indicating no correlation. This helps to understand whether certain failure modes tend to co-occur or if their occurrences are independent.
read the caption
Figure 7: MAS failure modes correlation matrix
More on tables
| Model | Accuracy | Recall | Precision | F1 | Cohen’s |
| o1 | 0.89 | 0.62 | 0.68 | 0.64 | 0.58 |
| o1 (few shot) | 0.94 | 0.77 | 0.833 | 0.80 | 0.77 |
🔼 This table presents the performance of the LLM-as-a-judge pipeline used for automated evaluation of Multi-Agent System (MAS) failures. It shows the accuracy, recall, precision, and F1-score achieved by the OpenAI’s ‘o1’ model, both with and without few-shot learning examples. It also reports the Cohen’s Kappa score which measures the agreement between the LLM annotations and human expert annotations.
read the caption
Table 2: Performance of LLM-as-a-judge pipeline
| Failure Category | Tactical Approaches | Structural Strategies |
| Specification & System Design | Clear role/task definitions, Engage in further discussions, Self-verification, Conversation pattern design | Comprehensive verification, Confidence quantification |
| Inter-Agent Misalignment | Cross-verification, Conversation pattern design, Mutual disambiguation, Modular agents design | Standardized communication protocols, Probabilistic confidence measures |
| Task Verification and Termination | Self-verification, Cross-verification, Topology redesign for verification | Comprehensive verification & unit test generation |
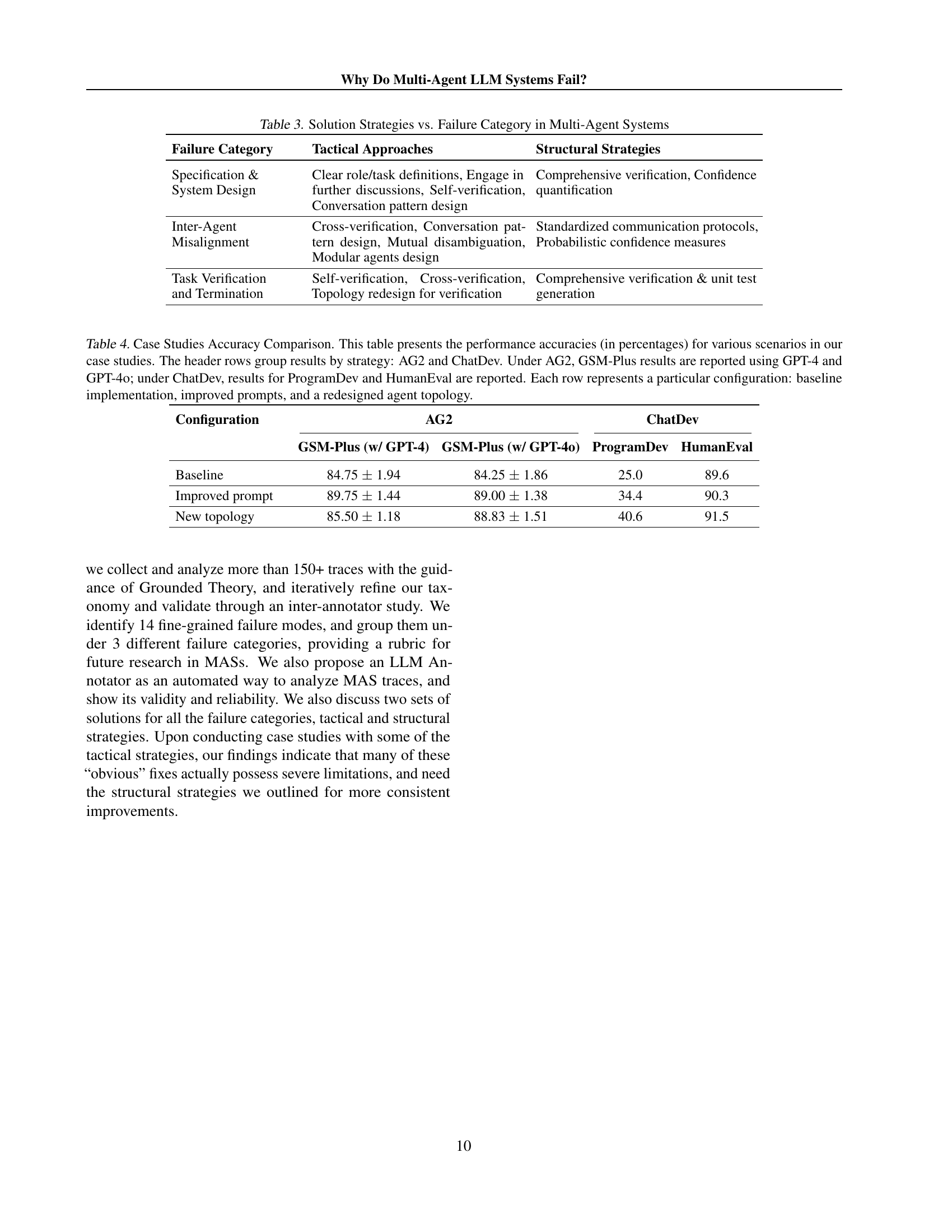
🔼 This table categorizes strategies for improving the robustness of Multi-Agent Systems (MAS), cross-referencing them with the types of failures they address. It breaks down solutions into tactical approaches (simple, prompt-focused fixes) and structural strategies (more fundamental system design changes). This helps clarify which solutions are best suited to which failure modes in MAS.
read the caption
Table 3: Solution Strategies vs. Failure Category in Multi-Agent Systems
| Configuration | AG2 | ChatDev | ||
| GSM-Plus (w/ GPT-4) | GSM-Plus (w/ GPT-4o) | ProgramDev | HumanEval | |
| Baseline | 84.75 1.94 | 84.25 1.86 | 25.0 | 89.6 |
| Improved prompt | 89.75 1.44 | 89.00 1.38 | 34.4 | 90.3 |
| New topology | 85.50 1.18 | 88.83 1.51 | 40.6 | 91.5 |
🔼 This table presents the accuracy results of two case studies that test different strategies for improving the performance of Multi-Agent Large Language Model (LLM) systems. The case studies use two different systems, AG2 and ChatDev, and two different evaluation benchmarks, GSM-Plus and HumanEval/ProgramDev. The table shows the baseline accuracy of each system, as well as the improvements achieved using improved prompts and a redesigned agent topology. Results are reported separately for different LLMs (GPT-4 and GPT-40). Each row corresponds to a specific configuration, enabling comparison of the baseline with improved prompts and a redesigned agent topology across systems and LLMs.
read the caption
Table 4: Case Studies Accuracy Comparison. This table presents the performance accuracies (in percentages) for various scenarios in our case studies. The header rows group results by strategy: AG2 and ChatDev. Under AG2, GSM-Plus results are reported using GPT-4 and GPT-4o; under ChatDev, results for ProgramDev and HumanEval are reported. Each row represents a particular configuration: baseline implementation, improved prompts, and a redesigned agent topology.
Full paper#