TL;DR#
Existing methods for Document Question Answering (DocQA) often struggle with integrating both textual and visual cues, limiting their performance on real-world documents. Current approaches using Large Language Models (LLMs) or Retrieval Augmented Generation (RAG) tend to prioritize information from a single modality, failing to effectively combine insights from both text and images.This makes it hard to answer complex questions requiring multimodal reasoning, hindering their accuracy.
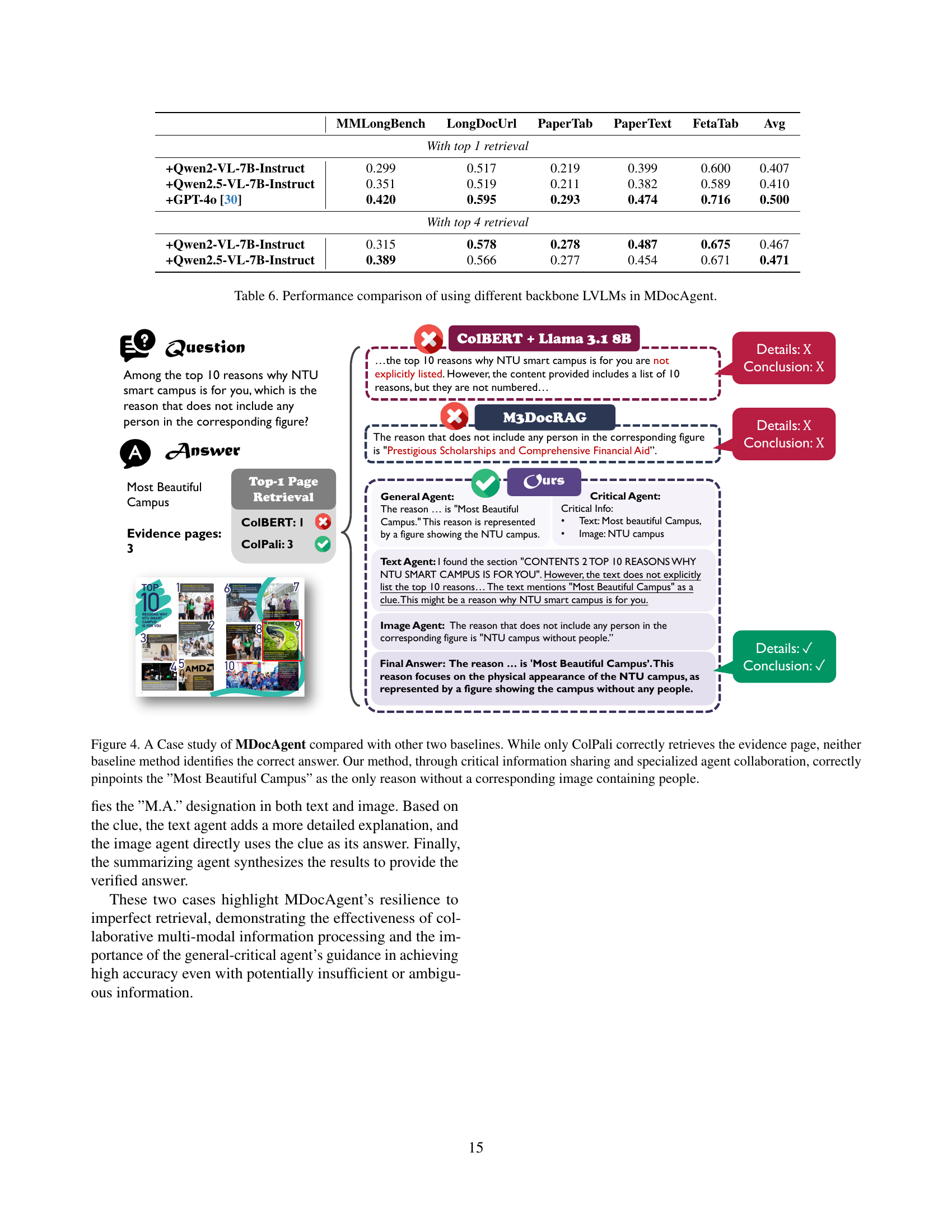
The paper introduces a novel framework that utilizes both text and image, called MDocAgent. It leverages a multi-agent system with specialized agents, including a general agent, critical agent, text agent, image agent, and summarizing agent. These agents collaborate to achieve a more comprehensive understanding of the document’s content. By employing multi-modal context retrieval and combining individual insights, the system synthesizes information from both textual and visual components, leading to improved accuracy in question answering.
Key Takeaways#
Why does it matter?#
This paper introduces a novel approach to DocQA by leveraging a multi-agent system with specialized roles, which can handle complex documents containing both text and visual information. The demonstrated improvements over existing methods make it a valuable resource for researchers. The work opens new avenues for exploring collaborative AI architectures in document understanding.
Visual Insights#
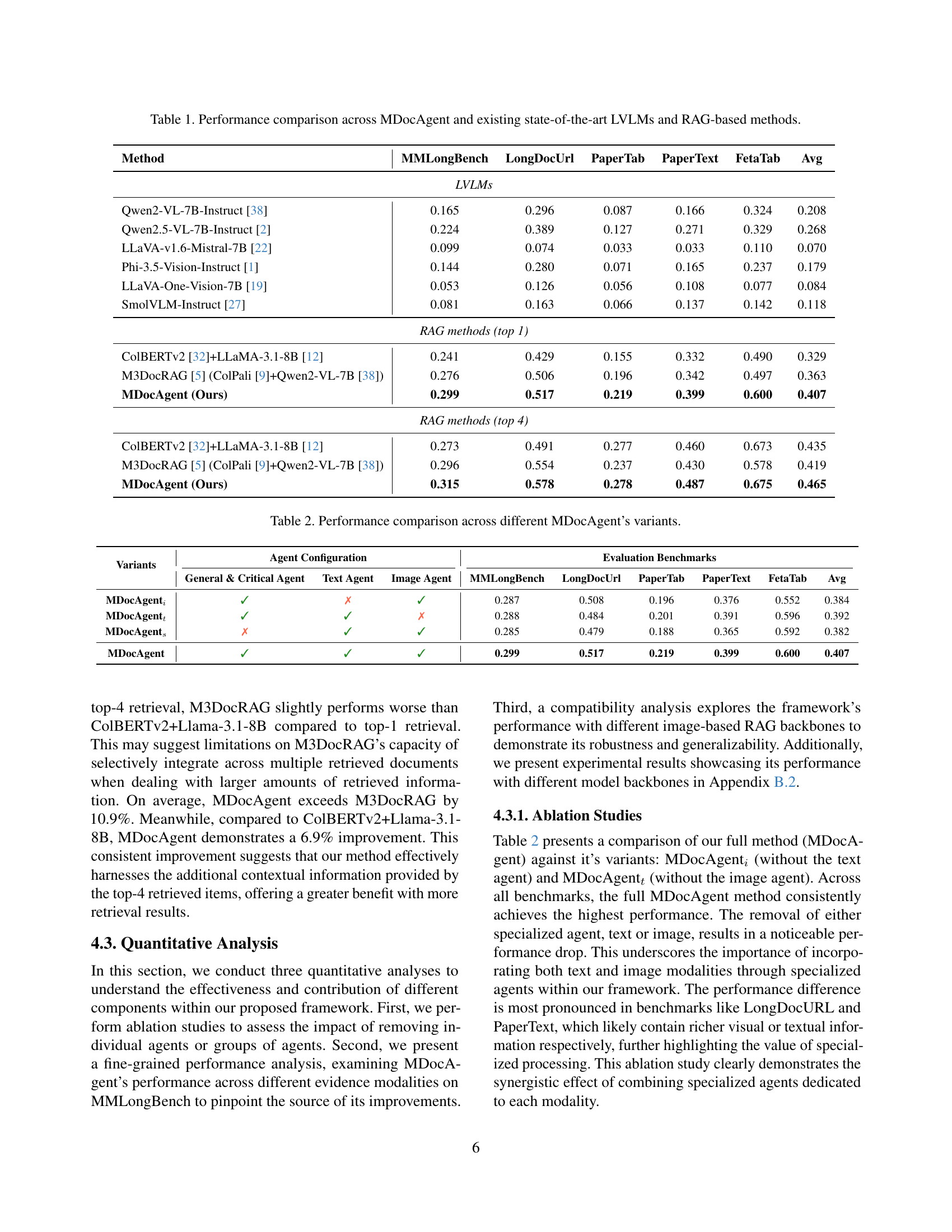
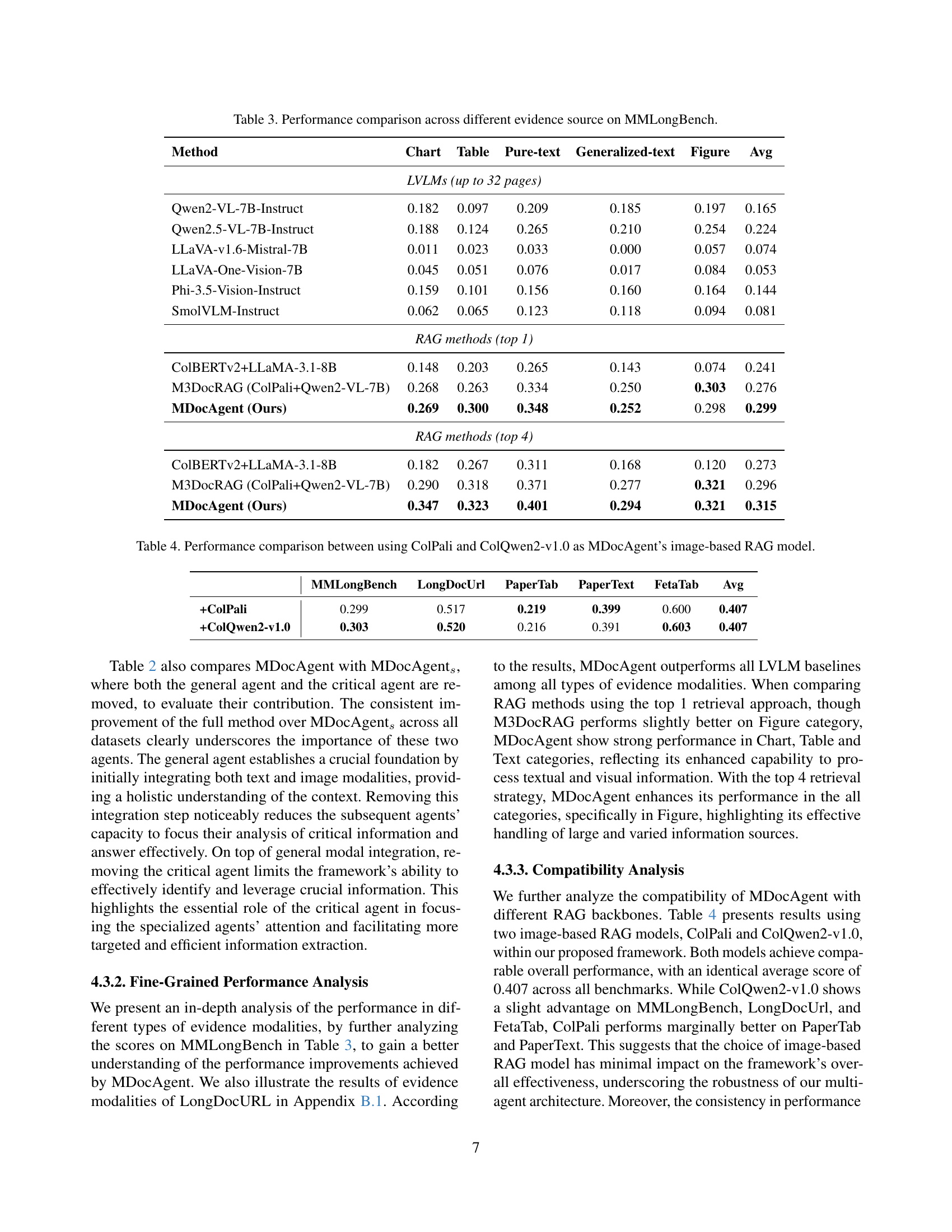
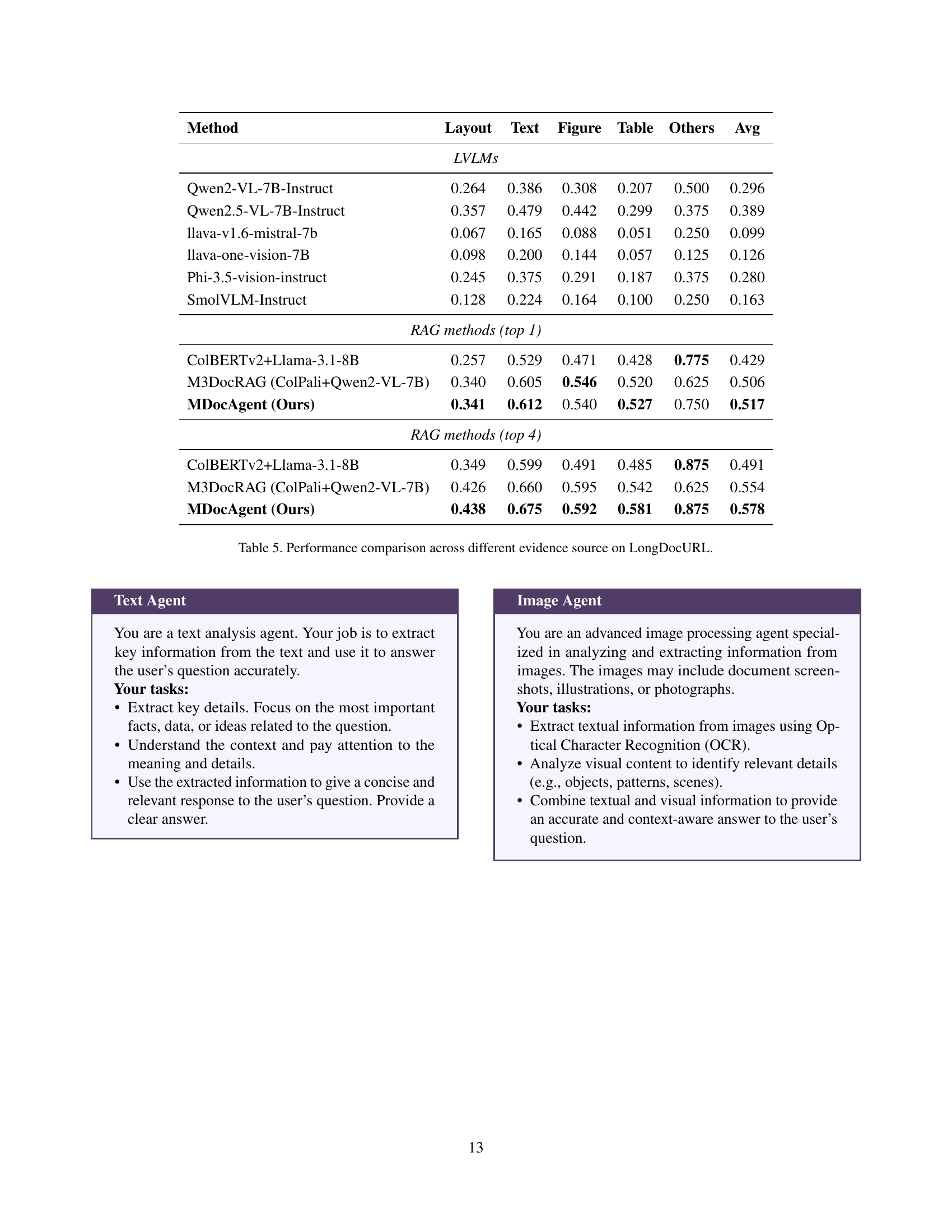
| \topruleMethod | Layout | Text | Figure | Table | Others | Avg |
|---|---|---|---|---|---|---|
| \midrule LVLMs | ||||||
| \midruleQwen2-VL-7B-Instruct | 0.264 | 0.386 | 0.308 | 0.207 | 0.500 | 0.296 |
| Qwen2.5-VL-7B-Instruct | 0.357 | 0.479 | 0.442 | 0.299 | 0.375 | 0.389 |
| llava-v1.6-mistral-7b | 0.067 | 0.165 | 0.088 | 0.051 | 0.250 | 0.099 |
| llava-one-vision-7B | 0.098 | 0.200 | 0.144 | 0.057 | 0.125 | 0.126 |
| Phi-3.5-vision-instruct | 0.245 | 0.375 | 0.291 | 0.187 | 0.375 | 0.280 |
| SmolVLM-Instruct | 0.128 | 0.224 | 0.164 | 0.100 | 0.250 | 0.163 |
| \midrule RAG methods (top 1) | ||||||
| \midruleColBERTv2+Llama-3.1-8B | 0.257 | 0.529 | 0.471 | 0.428 | 0.775 | 0.429 |
| M3DocRAG (ColPali+Qwen2-VL-7B) | 0.340 | 0.605 | 0.546 | 0.520 | 0.625 | 0.506 |
| \ours (Ours) | 0.341 | 0.612 | 0.540 | 0.527 | 0.750 | 0.517 |
| \midrule RAG methods (top 4) | ||||||
| \midruleColBERTv2+Llama-3.1-8B | 0.349 | 0.599 | 0.491 | 0.485 | 0.875 | 0.491 |
| M3DocRAG (ColPali+Qwen2-VL-7B) | 0.426 | 0.660 | 0.595 | 0.542 | 0.625 | 0.554 |
| \ours (Ours) | 0.438 | 0.675 | 0.592 | 0.581 | 0.875 | 0.578 |
| \bottomrule | ||||||
🔼 This table presents a detailed comparison of various models’ performance on the LongDocURL benchmark, broken down by different evidence types (Layout, Text, Figure, Table, Others). It contrasts the accuracy of Large Vision Language Models (LVLMs) and Retrieval Augmented Generation (RAG) methods, both using top-1 and top-4 retrieval strategies. The goal is to showcase the impact of different evidence sources and retrieval strategies on the models’ ability to accurately understand and answer questions based on long documents.
read the caption
Table \thetable: Performance comparison across different evidence source on LongDocURL.
Full paper#