TL;DR#
Identity-preserving video generation aims to create videos of specific individuals while maintaining accuracy, facing challenges in balancing identity consistency and facial editability. Existing methods often fall short, struggling to preserve identity or facing limitations in handling multiple identities/subjects. They increase complexity in model training/inference.
This paper introduces Concat-ID, a framework that utilizes Variational Autoencoders to extract image features, concatenated with video latents, leveraging 3D self-attention mechanisms. It balances identity consistency/facial editability through a novel cross-video pairing strategy and multi-stage training. Concat-ID demonstrates its effectiveness in single/multi-identity generation, and seamlessly scales to multi-subject scenarios like virtual try-on.
Key Takeaways#
Why does it matter?#
This paper introduces Concat-ID, a promising solution for identity-preserving video synthesis. Its scalability to multi-subject scenarios, including virtual try-on, is particularly valuable. Researchers can build upon this framework for diverse applications, exploring new methods for facial editability and identity control in video generation. The clear architecture and training strategy of Concat-ID offer a strong foundation for future research.
Visual Insights#

🔼 Concat-ID uses variational autoencoders (VAEs) to extract image features from reference images. These image features are then concatenated with video latents along the sequence dimension. The model uses only 3D self-attention mechanisms, which are commonly found in advanced video generation models. This approach avoids the need for extra modules or parameters, resulting in a simpler and more efficient architecture. The figure visually depicts this architecture, showing the flow of information from input images and text prompts to the final video generation.
read the caption
Figure 1: The architecture of Concat-ID. We utilize a VAE to extract image latents from reference images and concatenate them at the end of the video latents along the sequence dimension. Concat-ID relies solely on 3D self-attention, which are commonly present in state-of-the-art video generation models, without introducing additional modules and parameters.
| Method | Identity consistency | Text alignment | Facial editability | |
|---|---|---|---|---|
| ArcSim | CurSim | ViCLIP | CLIPDist | |
| Single identity | ||||
| ID-Animator [9] ‡ | 0.289 | 0.304 | 0.204 | 0.297 |
| ConsisID [29]‡ | 0.432 | 0.451 | 0.237 | 0.303 |
| Concat-ID (Ours) | 0.442 | 0.466 | 0.242 | 0.325 |
| Multiple identities | ||||
| Ingredients [4] ‡ | 0.293 | 0.316 | 0.199 | 0.407 |
| Concat-ID (Ours) | 0.492 | 0.514 | 0.190 | 0.410 |
🔼 This table presents a quantitative comparison of different methods for single-identity and multi-identity video generation. The metrics used are identity consistency (using ArcSim and CurSim), text alignment (ViCLIP), and facial editability (CLIPDist). Higher scores generally indicate better performance. The table shows that Concat-ID outperforms other methods (ID-Animator, ConsisID, and Ingredients) in terms of identity consistency and facial editability, while maintaining comparable or better text alignment. It’s important to note that ID-Animator, ConsisID, and Ingredients use additional adapters and auxiliary losses, making Concat-ID’s superior performance even more significant given its simpler architecture.
read the caption
Table 1: Quantitative results for single-identity and multi-identity generation. ‡‡\ddagger‡ indicates corresponding methods introduce additional adapters and auxiliary loss. Concat-ID achieves superior identity consistency and facial editability while maintaining better or comparable text alignment relative to the baselines.
In-depth insights#
VAE Feature Fuse#
VAE Feature Fusion centers on effectively incorporating image features learned by Variational Autoencoders (VAEs) into a video generation framework. VAEs offer a probabilistic latent space representation, enabling a structured way to encode facial identity information. The key lies in how these features are fused. Methods include concatenation or attention mechanisms. Concatenation may lead to spatial misalignment issues, while attention dynamically weights VAE features and video latents, but can also increase computational complexity. A balance must be achieved for optimal performance.
Cross-Video Pairs#
Cross-video pairing appears to be a clever strategy to inject diversity into the training data, specifically to improve facial editability. The core idea lies in using reference images and video frames from different videos of the same person, ensuring varied expressions and head poses. This counteracts the tendency of models trained on image-video pairs from the same source to overfit to specific facial expressions, limiting editability. The method selects pairs based on cosine similarity, ensuring they depict the same identity. The thresholds used in the selection process might require careful tuning to strike a balance between identity preservation and editability. This technique could lead to more natural and expressive video generation.
3D Self-Attn.#
3D Self-Attention mechanisms likely play a crucial role in processing spatiotemporal data within video generation. By extending self-attention to the temporal dimension, the model can capture dependencies between frames, enabling it to generate coherent and realistic video sequences. This is essential for identity-preserving video synthesis, as it allows the model to maintain facial features and expressions consistently over time. Utilizing this mechanism over other method is likely because it is already an integral part of video generation models, and avoids the addition of more modules. Concatenating image features extracted through VAEs into video latents and relying entirely on inherent 3D self-attention facilitates seamless feature fusion, bypassing problems that arise from spatial misalignments using other methods.
Multi-ID Scalable#
Thinking about “Multi-ID Scalable,” I envision a system capable of seamlessly handling scenes with numerous distinct identities while maintaining individual fidelity. Scalability isn’t just about processing power; it’s about architectural elegance. A well-designed model should avoid combinatorial explosions in parameters or computational cost as the number of identities increases. Techniques like shared latent spaces or modular identity encoders become crucial. Data management is also paramount; efficient data structures and training strategies are required to manage the diverse appearances associated with each individual. Furthermore, a truly scalable system must generalize well to unseen identities, demonstrating robustness beyond its training set. The challenges lie in disentangling identity from other factors like pose, expression, and lighting, and preventing identity leakage or blending between individuals.
Ablation Insight#
In ablation studies, the removal of key components helps understand their contribution. By selectively removing parts of the Concat-ID architecture, training strategy, or loss functions, we can isolate their individual impact. For example, removing the cross-video training stage could reveal its role in enhancing facial editability. Similarly, ablating specific loss terms might highlight their importance in maintaining identity consistency. The impact of 3D self-attention is critical in preserving identity so removing this element will provide much insight. Furthermore, this study explores each stage so that we can conclude each step is important. These studies also allow to observe trade-offs between identity preservation and facial editability. By understanding these trade-offs, we can optimize the design of future models.
More visual insights#
More on figures

🔼 This figure illustrates the process of creating three types of paired image-video data for training the identity-preserving video generation model. It starts with prompt-video pairs, which undergo face detection and video filtering to ensure data quality. These filtered pairs are then divided into three categories: pre-training pairs (high cosine similarity between image and video frames), cross-video pairs (moderate cosine similarity, enhancing facial editability), and trade-off pairs (very high similarity, focusing on consistency). This multi-stage approach helps to balance identity consistency and facial editability in the generated videos.
read the caption
(a) The procedure of data processing.

🔼 This figure shows examples of image-video pairs used in the Concat-ID model training. These are called ‘cross-video pairs.’ Unlike pairs from the same video, these pairs are from different videos but feature the same person, demonstrating a wider range of facial expressions and head poses. This diversity in the training data helps to balance identity consistency and facial editability in the generated videos.
read the caption
(b) Some samples of paired cross-video reference images.

🔼 This figure shows example pairs of images and videos used in the training process of the Concat-ID model. Specifically, it focuses on ’trade-off pairs’. These pairs are carefully selected to balance identity consistency and facial expressiveness. The images are relatively similar to the corresponding videos (high cosine similarity), helping to maintain a consistent identity, but not so close as to limit facial variability. This careful balance prevents the model from overly replicating expressions from the reference image while ensuring strong identity preservation.
read the caption
(c) Some samples of trade-off pairs.

🔼 Figure 3 illustrates the three types of image-video pairings used in the Concat-ID model training for a single identity. These pairings are designed to balance identity consistency and facial expressiveness in the generated videos. Pre-training pairs utilize images and videos from the same video, ensuring high identity consistency. Cross-video pairs use images and videos from different videos, but with similar facial features, promoting facial variability. Finally, trade-off pairs, with even greater similarity between images and videos, are used to further fine-tune the model and maintain a balance between identity preservation and editability.
read the caption
Figure 2: Constructing three types of image-video pairs for a single identity: pre-training, cross-video and trade-off pairs.

🔼 Figure 3 presents a comparison of three different video generation models (ID-Animator, ConsisID, and Concat-ID) in terms of their ability to generate videos that accurately reflect the identity of a reference image, while also offering some degree of facial expression variability. Each model is tested with three different scenarios: a man in a Superman outfit, a street artist, and a person crying on a bench. The results illustrate that ID-Animator struggles to maintain facial detail, while ConsisID generates videos that are too heavily influenced by the facial expressions of the input image; this is especially pronounced in the third scenario, where the prompt’s emotional content contrasts strongly with the reference image. In contrast, Concat-ID offers an excellent balance between preserving identity and allowing for more natural facial expressions, showing less direct imitation of the reference image’s expressions.
read the caption
Figure 3: Qualitative comparisons for single-identity generation. ID-Animator fails to preserve facial details, while ConsisID replicates the expressions of the reference images, particularly in the third case, where the semantic gap between texts and reference is significant. Concat-ID effectively preserves identity, while simultaneously preventing the direct replication of facial expressions from reference images.

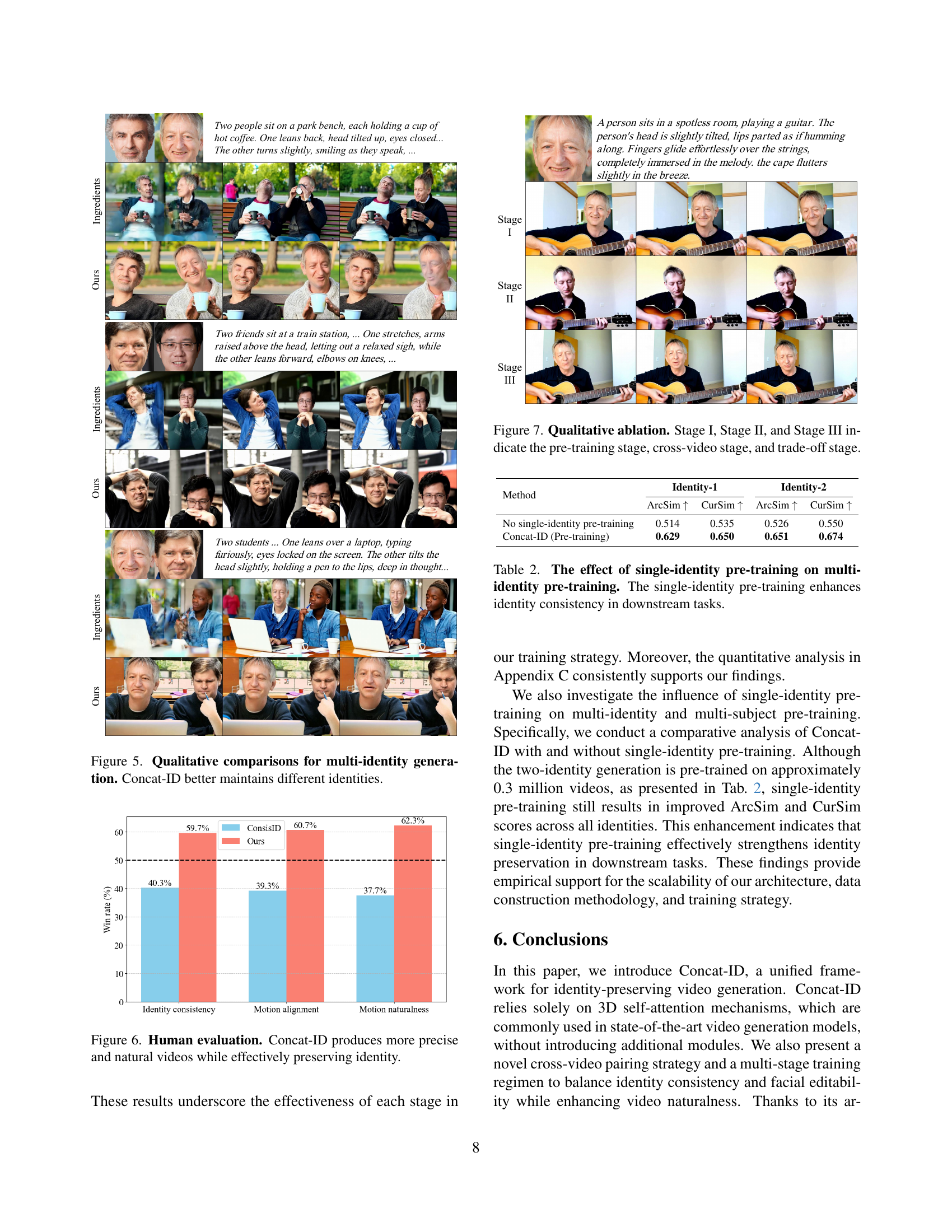
🔼 Figure 4 presents a qualitative comparison of multi-identity video generation results between Concat-ID and its main competitor, Ingredients. The figure showcases several examples where different identities are present in a single video. It visually demonstrates Concat-ID’s superior ability to maintain distinct identities across various individuals in the video compared to Ingredients, which struggles to preserve individual identities clearly. The results highlight Concat-ID’s effectiveness in managing complex scenarios with multiple individuals and preserving the distinct features of each identity.
read the caption
Figure 4: Qualitative comparisons for multi-identity generation. Concat-ID better maintains different identities.

🔼 This figure displays the results of a user study comparing the video generation quality of Concat-ID against ConsisID, focusing on identity consistency, facial motion alignment, and naturalness. Three groups of users were tasked to rate videos from both models. The bar chart shows that Concat-ID significantly outperforms ConsisID in all three aspects, demonstrating the effectiveness of its architecture in producing identity-preserving videos with natural facial movements.
read the caption
Figure 5: Human evaluation. Concat-ID produces more precise and natural videos while effectively preserving identity.
More on tables
| Method | Identity-1 | Identity-2 | ||
|---|---|---|---|---|
| ArcSim | CurSim | ArcSim | CurSim | |
| No single-identity pre-training | 0.514 | 0.535 | 0.526 | 0.550 |
| Concat-ID (Pre-training) | 0.629 | 0.650 | 0.651 | 0.674 |
🔼 This table presents a quantitative analysis of the impact of single-identity pre-training on the performance of a multi-identity video generation model. It compares the identity consistency metrics (ArcSim and CurSim) achieved by the model trained with and without the single-identity pre-training phase. The results demonstrate that incorporating the single-identity pre-training step leads to an improvement in the model’s ability to maintain consistent identities in the generated videos, thereby highlighting the beneficial effect of this training stage on downstream tasks.
read the caption
Table 2: The effect of single-identity pre-training on multi-identity pre-training. The single-identity pre-training enhances identity consistency in downstream tasks.
| Method | Identity consistency | Text alignment | Facial editability | |
|---|---|---|---|---|
| ArcSim | CurSim | ViCLIP | CLIPDist | |
| Concat-ID (Stage I) | 0.560 | 0.581 | 0.237 | 0.726 |
| Concat-ID (Stage II) | 0.185 | 0.200 | 0.248 | 0.566 |
| Concat-ID (Stage III) | 0.442 | 0.466 | 0.242 | 0.675 |
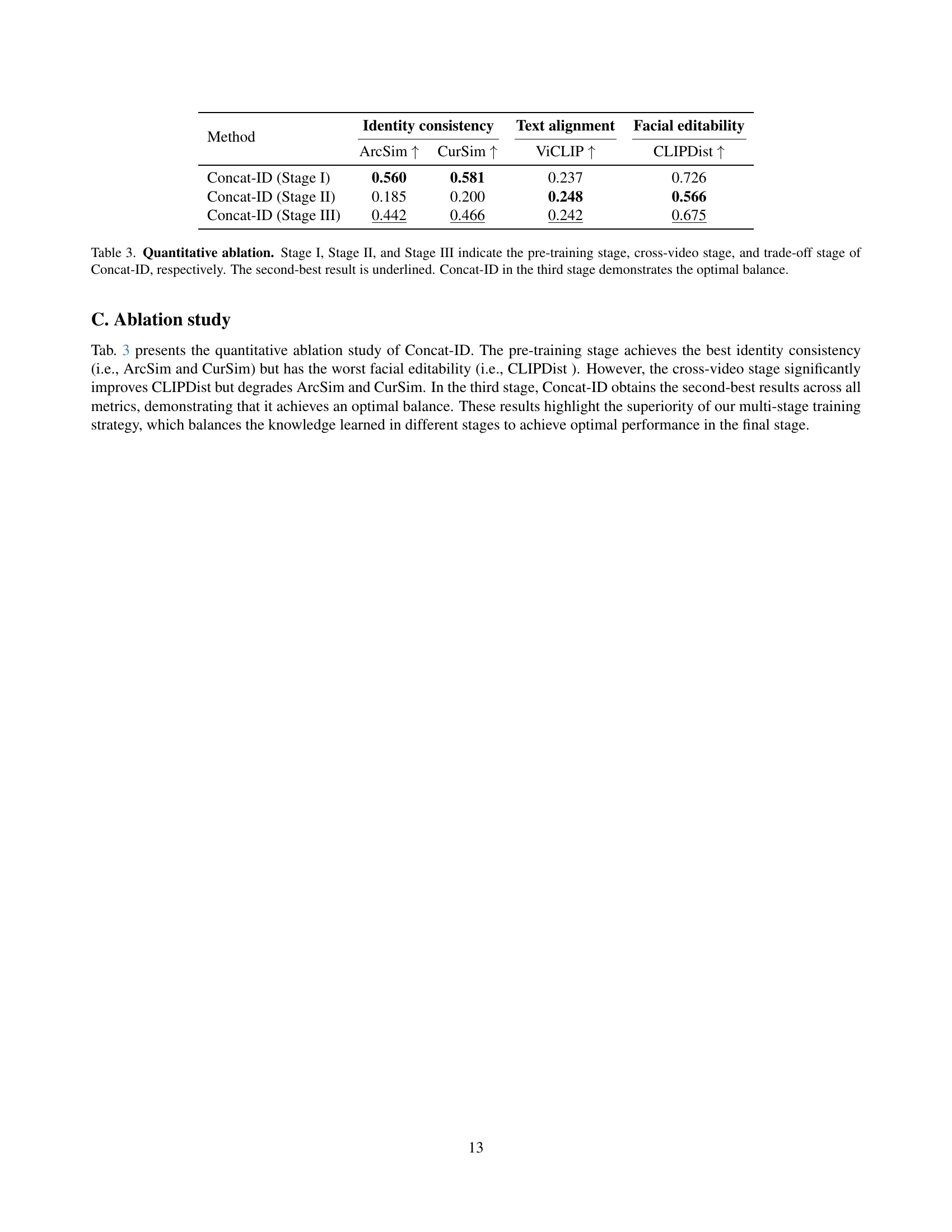
🔼 Table 3 presents a quantitative ablation study evaluating the impact of each stage in the Concat-ID training process on identity consistency, text alignment, and facial editability. Stage I (pre-training) prioritizes identity consistency but sacrifices facial editability. Stage II (cross-video) improves facial editability but reduces identity consistency. Finally, Stage III (trade-off) achieves an optimal balance between identity preservation and facial expressiveness. The table numerically demonstrates the trade-offs between these aspects at each training stage, highlighting that the final stage of Concat-ID training yields the best overall results.
read the caption
Table 3: Quantitative ablation. Stage I, Stage II, and Stage III indicate the pre-training stage, cross-video stage, and trade-off stage of Concat-ID, respectively. The second-best result is underlined. Concat-ID in the third stage demonstrates the optimal balance.
Full paper#