TL;DR#
Text-to-Video generation is impeded by the inaccurate binding of attributes, spatial relationships and action interactions among multiple subjects. Models still exhibit issues such as semantic leakage, misaligned spatial relationships, and subject missing. Existing methods involve the use of object-grounding layouts or multi-round evaluations based on language models, but still have limitations such as failure to capture the fine-grained shape variations, and high computational and training costs.
To solve this, the paper proposes a novel training-free method that enhances compositional T2V generation through dual-phase refinement. This strategy reinforces subject-specific semantics, resolves inter-subject ambiguity, and integrates grounding priors and model-adaptive spatial perception to flexibly bind subjects to their spatiotemporal regions through masked attention modulation. Experiments demonstrate that it outperforms state-of-the-art methods.
Key Takeaways#
Why does it matter?#
This paper introduces a training-free framework that significantly improves compositional video generation by addressing challenges like semantic ambiguity and spatial relationships. Its model-agnostic design and superior performance on standard benchmarks make it highly relevant for researchers seeking practical, efficient solutions for complex video synthesis tasks.
Visual Insights#

🔼 Figure 1 illustrates the MagicComp framework’s architecture and capabilities. Panel (a) details the two main modules: Semantic Anchor Disambiguation (SAD), which clarifies ambiguous relationships between subjects in the input text prompt, and Dynamic Layout Fusion Attention (DLFA), which precisely binds visual attributes and locations to the subjects during video generation. Panel (b) highlights the training-free nature of MagicComp and its effectiveness in overcoming common challenges in compositional video generation—semantic confusion, spatial misalignment, and missing entities—while maintaining efficiency.
read the caption
Figure 1: Overall pipeline for MagicComp. (a) Our MagicComp comprises two core modules: Semantic Anchor Disambiguation (SAD) for resolving inter-subject ambiguity during conditioning, and Dynamic Layout Fusion Attention (DLFA) for spatial-attribute binding via fused layout masks in denoising. (b) MagicComp is a training-free framework, which effectively address the challenges (e.g., semantic confusion, misaligned spatial relationship, missing entities) in compositional video generation with minimal additional inference overhead.
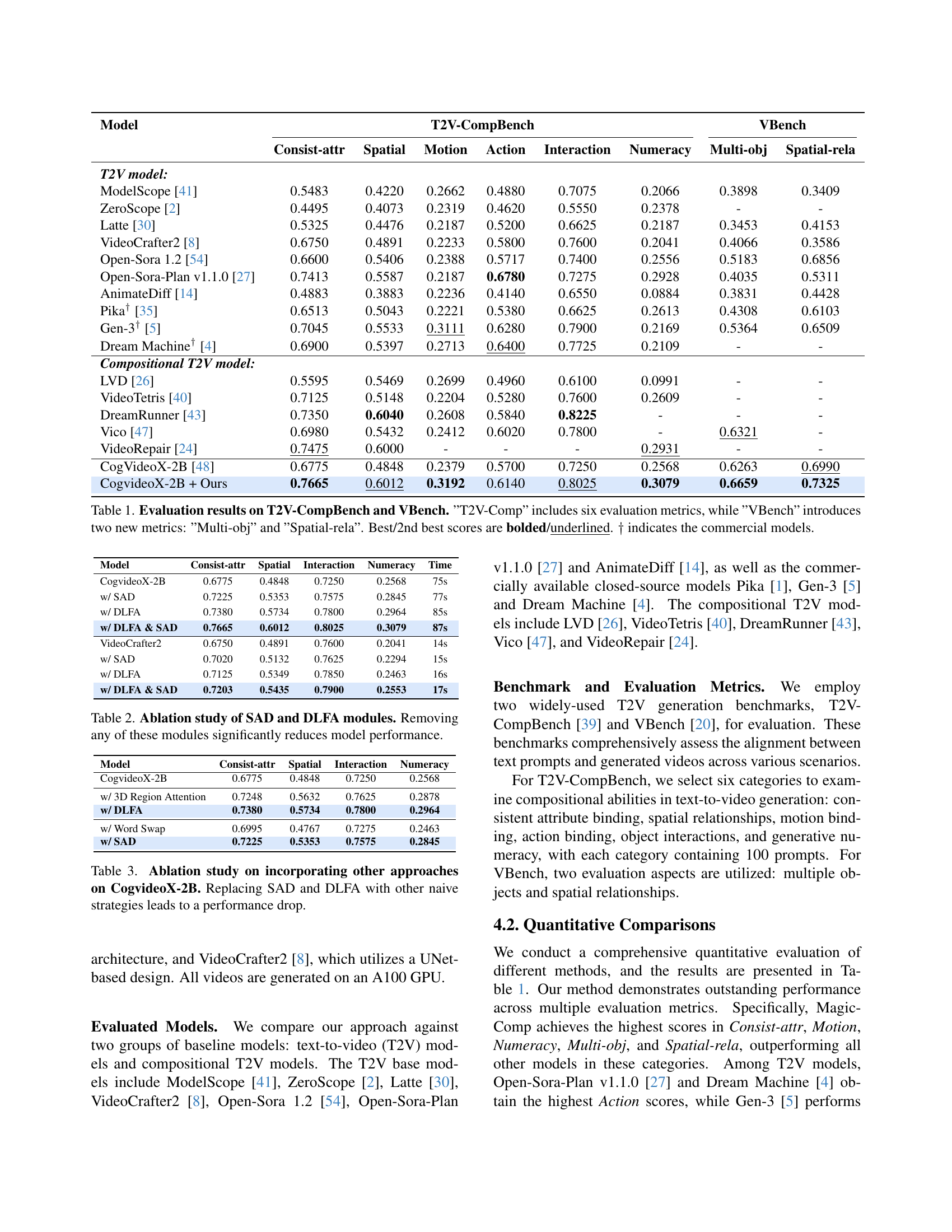
| Model | T2V-CompBench | VBench | ||||||
| Consist-attr | Spatial | Motion | Action | Interaction | Numeracy | Multi-obj | Spatial-rela | |
| T2V model: | ||||||||
| ModelScope [41] | 0.5483 | 0.4220 | 0.2662 | 0.4880 | 0.7075 | 0.2066 | 0.3898 | 0.3409 |
| ZeroScope [2] | 0.4495 | 0.4073 | 0.2319 | 0.4620 | 0.5550 | 0.2378 | - | - |
| Latte [30] | 0.5325 | 0.4476 | 0.2187 | 0.5200 | 0.6625 | 0.2187 | 0.3453 | 0.4153 |
| VideoCrafter2 [8] | 0.6750 | 0.4891 | 0.2233 | 0.5800 | 0.7600 | 0.2041 | 0.4066 | 0.3586 |
| Open-Sora 1.2 [54] | 0.6600 | 0.5406 | 0.2388 | 0.5717 | 0.7400 | 0.2556 | 0.5183 | 0.6856 |
| Open-Sora-Plan v1.1.0 [27] | 0.7413 | 0.5587 | 0.2187 | 0.6780 | 0.7275 | 0.2928 | 0.4035 | 0.5311 |
| AnimateDiff [14] | 0.4883 | 0.3883 | 0.2236 | 0.4140 | 0.6550 | 0.0884 | 0.3831 | 0.4428 |
| Pika† [35] | 0.6513 | 0.5043 | 0.2221 | 0.5380 | 0.6625 | 0.2613 | 0.4308 | 0.6103 |
| Gen-3† [5] | 0.7045 | 0.5533 | 0.3111 | 0.6280 | 0.7900 | 0.2169 | 0.5364 | 0.6509 |
| Dream Machine† [4] | 0.6900 | 0.5397 | 0.2713 | 0.6400 | 0.7725 | 0.2109 | - | - |
| Compositional T2V model: | ||||||||
| LVD [26] | 0.5595 | 0.5469 | 0.2699 | 0.4960 | 0.6100 | 0.0991 | - | - |
| VideoTetris [40] | 0.7125 | 0.5148 | 0.2204 | 0.5280 | 0.7600 | 0.2609 | - | - |
| DreamRunner [43] | 0.7350 | 0.6040 | 0.2608 | 0.5840 | 0.8225 | - | - | - |
| Vico [47] | 0.6980 | 0.5432 | 0.2412 | 0.6020 | 0.7800 | - | 0.6321 | - |
| VideoRepair [24] | 0.7475 | 0.6000 | - | - | - | 0.2931 | - | - |
| CogVideoX-2B [48] | 0.6775 | 0.4848 | 0.2379 | 0.5700 | 0.7250 | 0.2568 | 0.6263 | 0.6990 |
| CogvideoX-2B + Ours | 0.7665 | 0.6012 | 0.3192 | 0.6140 | 0.8025 | 0.3079 | 0.6659 | 0.7325 |
🔼 This table presents a comprehensive comparison of various text-to-video (T2V) models’ performance on two benchmark datasets: T2V-CompBench and VBench. T2V-CompBench evaluates models across six key aspects of compositional video generation: consistency of attributes, spatial relationships, motion accuracy, action coherence, interaction quality, and numerical accuracy. VBench expands on this by adding two additional metrics: the ability to handle multiple objects and the accuracy in representing spatial relationships between them. The table highlights the best and second-best performing models for each metric, clearly indicating which models excel in different aspects of compositional video generation. Commercial models are also identified.
read the caption
Table 1: Evaluation results on T2V-CompBench and VBench. ”T2V-Comp” includes six evaluation metrics, while ”VBench” introduces two new metrics: ”Multi-obj” and ”Spatial-rela”. Best/2nd best scores are bolded/underlined. ††{\dagger}† indicates the commercial models.
In-depth insights#
Dual-Phase Refine#
The dual-phase refinement strategy appears to be a core innovation, suggesting a structured approach to address the complexities of compositional video generation. The conditioning phase likely focuses on preparing the input text and layout, addressing issues such as semantic ambiguity early on. The denoising phase refines the generated video by focusing on spatial relationships and finer details. By separating these two crucial aspects, the dual-phase refinement can allow each phase to optimize for specific goals, leading to better overall quality. This separation is smart, allowing for a model-agnostic approach, improving attribute-location binding, and mitigating semantic leakage, which are persistent problems in T2V generation. Furthermore, it allows a sequential refinement, which progressively makes the generated video more like the intended result.
Sem. Disambiguate#
The concept of ‘Semantic Disambiguation’ is crucial for AI systems to truly understand and process information like humans. It tackles the challenge where words or phrases can have multiple meanings depending on the context. Effective semantic disambiguation ensures that AI correctly identifies the intended meaning, avoiding misinterpretations. Methods might include analyzing surrounding words, using knowledge bases to understand relationships, or employing machine learning models trained on vast amounts of text. The success of semantic disambiguation directly impacts the performance of various AI applications, such as machine translation, question answering, and information retrieval. Without it, AI struggles to deal with the nuances of human language, leading to errors and hindering its ability to provide accurate and relevant responses.
Dynamic Layout#
A dynamic layout mechanism in video generation focuses on the adaptive arrangement of objects within a scene over time. It’s crucial for creating realistic and engaging videos where objects move and interact naturally. Unlike static layouts, a dynamic layout considers the temporal dimension, ensuring that the spatial relationships between objects evolve consistently with the action. This involves predicting the future positions of objects, managing occlusions, and handling changes in object size and shape. Effective dynamic layout models leverage techniques such as recurrent neural networks or transformers to capture the dependencies between frames. Challenges include dealing with uncertainty in object motion and maintaining long-term consistency in the layout. Successful implementation can significantly enhance the realism and coherence of generated videos, making them more compelling and believable. A flexible model allows for better control over the narrative and composition of the video, enabling more creative and expressive storytelling.
Model-Agnostic T2V#
The concept of a model-agnostic text-to-video (T2V) system is compelling because it aims for versatility and broad applicability. Such a system would ideally function effectively across diverse T2V architectures, eliminating the need for retraining or significant modifications when switching between different underlying models. This approach offers several advantages, including reduced development costs, faster prototyping, and the ability to leverage the strengths of various T2V models without being tied to a specific architecture. A key challenge in achieving model-agnosticism is the design of intermediate representations that are compatible across different models. This might involve using a common latent space or developing techniques for adapting the input and output formats of different models. The development of such techniques would significantly advance the field, enabling the creation of more flexible and adaptable T2V systems.
No Extra Training#
Training-free methods are increasingly attractive in video generation due to their efficiency. Eliminating the training phase dramatically reduces computational costs and time, making these methods more accessible. This is particularly important when adapting models to new datasets or tasks. Training-free methods often rely on pre-trained models and leverage techniques like prompt engineering or attention manipulation to achieve desired results. This approach offers flexibility and rapid prototyping. The absence of training can lead to challenges in fine-grained control and customization, potentially limiting the model’s ability to capture complex nuances or handle specialized tasks. While potentially slightly limiting ultimate performance, training-free approaches offer a compelling balance between efficiency and quality, making them valuable tools for many video generation scenarios.
More visual insights#
More on figures

🔼 MagicComp’s dual-phase refinement process is illustrated. The first phase, Semantic Anchor Disambiguation (SAD), resolves ambiguity between subjects in the text prompt by independently processing each subject’s semantics (using the example of ‘cat’ for simplicity) to generate anchor embeddings. These embeddings are then used to adjust the initial text embeddings, reducing ambiguity before the generation process begins. The second phase, Dynamic Layout Fusion Attention (DLFA), precisely binds attributes and locations to each subject during the denoising phase using both pre-defined and model-learned spatial masks. This ensures accurate placement of objects in the generated video.
read the caption
Figure 2: Detailed architecture of MagicComp. The dual-phase refinement strategy of MagicComp contains two core steps: (a) Semantic Anchor Disambiguation (SAD) module for inter-subject disambiguation during the conditioning stage. We only display disambiguation process of subject “cat' for simplicity, other subjects follow the similar way. (b) Dynamic Layout Fusion Attention (DLFA) module for precise attribute–location binding of each subject during the denoising stage.

🔼 This figure demonstrates the effectiveness of Semantic Anchor Disambiguation (SAD) in resolving semantic ambiguity. Part (a) shows a comparison of cosine similarity scores between the embeddings of ‘brown dog’ and ‘gray cat’ under three conditions: without SAD, with SAD, and with a standard T5 encoding (no SAD). This illustrates how SAD reduces the similarity between the two subjects, improving the clarity of their distinct semantic representations. Part (b) visualizes cross-attention maps between video tokens from the middle frame and pooled subject tokens. This demonstrates how SAD leads to more distinct attention patterns for ‘brown dog’ and ‘gray cat,’ preventing semantic confusion during the generation process.
read the caption
Figure 3: Visualization of the disambiguation effect brought by SAD. (a) Cos similarity between the pooled embeddings of “brown dog' and “gray cat' under different settings. “Standard' indicates the cos similarity is computed when each subject are independently encoded by T5. (b) Cross attention maps between the middle frame video tokens and the pooled subject tokens.

🔼 This figure compares different masking strategies used in the Dynamic Layout Fusion Attention (DLFA) module. Panel (a) visualizes the prior layout mask generated by a large language model (LLM) alongside the model-adaptive perception layout mask. The LLM mask provides a coarse initial estimation of subject locations, while the adaptive mask refines these locations based on the video content and its correlation with the text. Panel (b) then shows the resulting videos generated using each masking method. This comparison highlights how the combination of prior and adaptive masks improves the accuracy and detail in the generated subject-specific regions compared to using only the prior LLM-generated masks.
read the caption
Figure 4: Comparison of different masking strategy. (a) Visualization of prior layout mask and model-adaptive perception layout. (b) Comparison of the generated videos.

🔼 Figure 5 presents a qualitative comparison of different text-to-video (T2V) models on the T2V-CompBench benchmark. The figure showcases the results of various models on six compositional generation tasks: consistent attribute binding, spatial relationships, motion, action, interaction, and numeracy. Each task is represented with examples of generated video frames using different models, demonstrating MagicComp’s superior ability to generate videos that accurately reflect the complex relationships and interactions specified in the textual prompts. In contrast, existing methods like Vico and CogVideoX often fail to correctly capture the fine-grained details and interactions described in the prompts, highlighting MagicComp’s advancement in handling complex compositional scenarios.
read the caption
Figure 5: Qualitative Comparison on T2V-CompBench. Our MagicComp significantly outperforms existing approaches across various compositional generation tasks, and the methods such as Vico [47] and CogVideoX [48] struggle to capture fine-grained concepts.

🔼 Figure 6 presents a comparison of video generation results across different models in response to a complex prompt. The prompt describes a scene with multiple interacting elements and specific attributes (a skeleton pirate, a ghost ship, a dark sea, glowing lanterns, and a treasure map). The figure visually demonstrates that, unlike other models, MagicComp accurately generates the video according to the complex prompt’s specifications.
read the caption
Figure 6: Application on complex prompt-based video generation. It is evident that among all models, only MagicComp strictly follows the prompt to generate complex scenarios.

🔼 Figure 7 demonstrates the application of MagicComp to achieve trajectory-controllable video generation. The figure showcases that by integrating MagicComp into CogVideoX [48], the model gains the ability to control the trajectory of objects in generated videos without requiring any extra computational cost or additional training. This highlights the efficiency and practical value of MagicComp in enhancing video generation capabilities beyond standard compositional tasks.
read the caption
Figure 7: Application about trajectory-controllable video generation. By incorporating the proposed methods, CogVideoX [48] can achieve trajectory control seamlessly without additional cost.

🔼 This figure shows instructions on how to create a YAML file for describing the layout of video generation. It details the process of annotating key subjects in video captions and planning their motion paths using bounding boxes. Specific requirements are provided, including normalization of bounding boxes, consistent movement, attribute binding, and handling of multiple objects. An example YAML file is given to illustrate the expected format.
read the caption
Figure 1: Instruction prompt for prior layout generation.

🔼 This figure displays a qualitative comparison of different models’ performance on the ‘Consistent Attributes’ task. It shows generated video frames from five different models (MagicComp, CogVideoX-2B, Vico, VideoTetris, and Open-Sora-Plan). Two scenarios are presented: ‘Big hearts and small stars floating upwards’ and ‘Oblong canoe gliding past a circular buoy’. The comparison highlights MagicComp’s superior ability to maintain consistent attributes throughout the generated video sequence, compared to other models that struggle with this task.
read the caption
Figure 2: Qualitative results on Consist-attr.

🔼 This figure displays a qualitative comparison of different models’ performance on the ‘Consistent Attributes’ task from the T2V-CompBench benchmark. It showcases the results of generating videos based on prompts describing objects with specific attributes. Each row represents a different model (MagicComp, CogVideoX-2B, Vico, VideoTetris, and Open-Sora-Plan), and each column displays a sequence of frames from the generated videos for two different prompts. The prompts used are: ‘Star-shaped cookie resting on a round coaster’ and ‘Green tractor plowing near a white farmhouse’. The figure demonstrates MagicComp’s superior ability to maintain consistent visual attributes (shape and color) of objects throughout the generated video sequences compared to other methods.
read the caption
Figure 3: Qualitative results on Consist-attr.

🔼 This figure displays qualitative results focusing on the ‘Motion’ aspect of compositional video generation. It presents a visual comparison of how different models, including MagicComp and several baselines, handle the generation of videos involving movement and dynamic interactions. By comparing the video frames generated by each model for the same prompts, the figure helps illustrate the effectiveness and accuracy of the models in capturing motion accurately and consistently.
read the caption
Figure 4: Qualitative results on Motion.

🔼 This figure displays qualitative results comparing different models’ performance on actions and motion in video generation. Each row shows the output of a different model (MagicComp, CogVideoX-2B, Vico, VideoTeris, Open-Sora-Plan) for two example prompts: a sheep walking on grass with a hot air balloon above and a boat sailing on the ocean. The image sequence for each model shows how well each model’s output captures the specified actions and motions in the prompts. The goal is to illustrate how MagicComp excels in generating videos that accurately reflect the dynamic aspects of action and motion compared to existing methods.
read the caption
Figure 5: Qualitative results on Action & Motion.

🔼 This figure showcases a qualitative comparison of various models’ performance on numeracy tasks within compositional video generation. It presents two example prompts: ’two elephants and five buckets in a zoo’ and ‘seven bees buzz around a blooming flower bed’. For each prompt, it visually displays the generated video frames produced by different models, allowing for a direct comparison of their ability to accurately represent numerical quantities within a scene. The goal is to highlight the relative strengths and weaknesses of each model in handling numerical concepts during compositional video generation.
read the caption
Figure 6: Qualitative results on Numeracy.
More on tables
| Model | Consist-attr | Spatial | Interaction | Numeracy | Time |
| CogvideoX-2B | 0.6775 | 0.4848 | 0.7250 | 0.2568 | 75s |
| w/ SAD | 0.7225 | 0.5353 | 0.7575 | 0.2845 | 77s |
| w/ DLFA | 0.7380 | 0.5734 | 0.7800 | 0.2964 | 85s |
| w/ DLFA & SAD | 0.7665 | 0.6012 | 0.8025 | 0.3079 | 87s |
| VideoCrafter2 | 0.6750 | 0.4891 | 0.7600 | 0.2041 | 14s |
| w/ SAD | 0.7020 | 0.5132 | 0.7625 | 0.2294 | 15s |
| w/ DLFA | 0.7125 | 0.5349 | 0.7850 | 0.2463 | 16s |
| w/ DLFA & SAD | 0.7203 | 0.5435 | 0.7900 | 0.2553 | 17s |
🔼 This ablation study analyzes the individual contributions of the Semantic Anchor Disambiguation (SAD) and Dynamic Layout Fusion Attention (DLFA) modules within the MagicComp framework. It demonstrates that removing either module significantly degrades the model’s performance, highlighting their importance in achieving high-quality results in compositional video generation. The table quantifies this performance drop across multiple metrics, showcasing the synergistic effect of combining SAD and DLFA.
read the caption
Table 2: Ablation study of SAD and DLFA modules. Removing any of these modules significantly reduces model performance.
| Model | Consist-attr | Spatial | Interaction | Numeracy |
| CogvideoX-2B | 0.6775 | 0.4848 | 0.7250 | 0.2568 |
| w/ 3D Region Attention | 0.7248 | 0.5632 | 0.7625 | 0.2878 |
| w/ DLFA | 0.7380 | 0.5734 | 0.7800 | 0.2964 |
| w/ Word Swap | 0.6995 | 0.4767 | 0.7275 | 0.2463 |
| w/ SAD | 0.7225 | 0.5353 | 0.7575 | 0.2845 |
🔼 This ablation study analyzes the impact of integrating different modules into the CogVideoX-2B model. It specifically investigates the effects of replacing the Semantic Anchor Disambiguation (SAD) and Dynamic Layout Fusion Attention (DLFA) modules with alternative, simpler methods. The results demonstrate that replacing SAD and DLFA with naive strategies significantly reduces the model’s performance, highlighting the importance of these two components in achieving superior results in compositional video generation.
read the caption
Table 3: Ablation study on incorporating other approaches on CogvideoX-2B. Replacing SAD and DLFA with other naive strategies leads to a performance drop.
| Hyperparameters | CogVideoX | VideoCrafter2 |
| Sampler | DPM-Solver | DPM-Solver |
| Denoising step | 50 | 50 |
| Guidance scale | 12 | 6 |
| Resolution | ||
| Number of frames | 16 | 49 |
🔼 This table details the hyperparameters used in the implementation of MagicComp, a training-free dual-phase refinement method for compositional video generation. It shows the settings for both CogVideoX and VideoCrafter2 models, covering aspects like the sampler, denoising steps, guidance scale, resolution, and number of frames generated.
read the caption
Table 1: More implementation details.
Full paper#