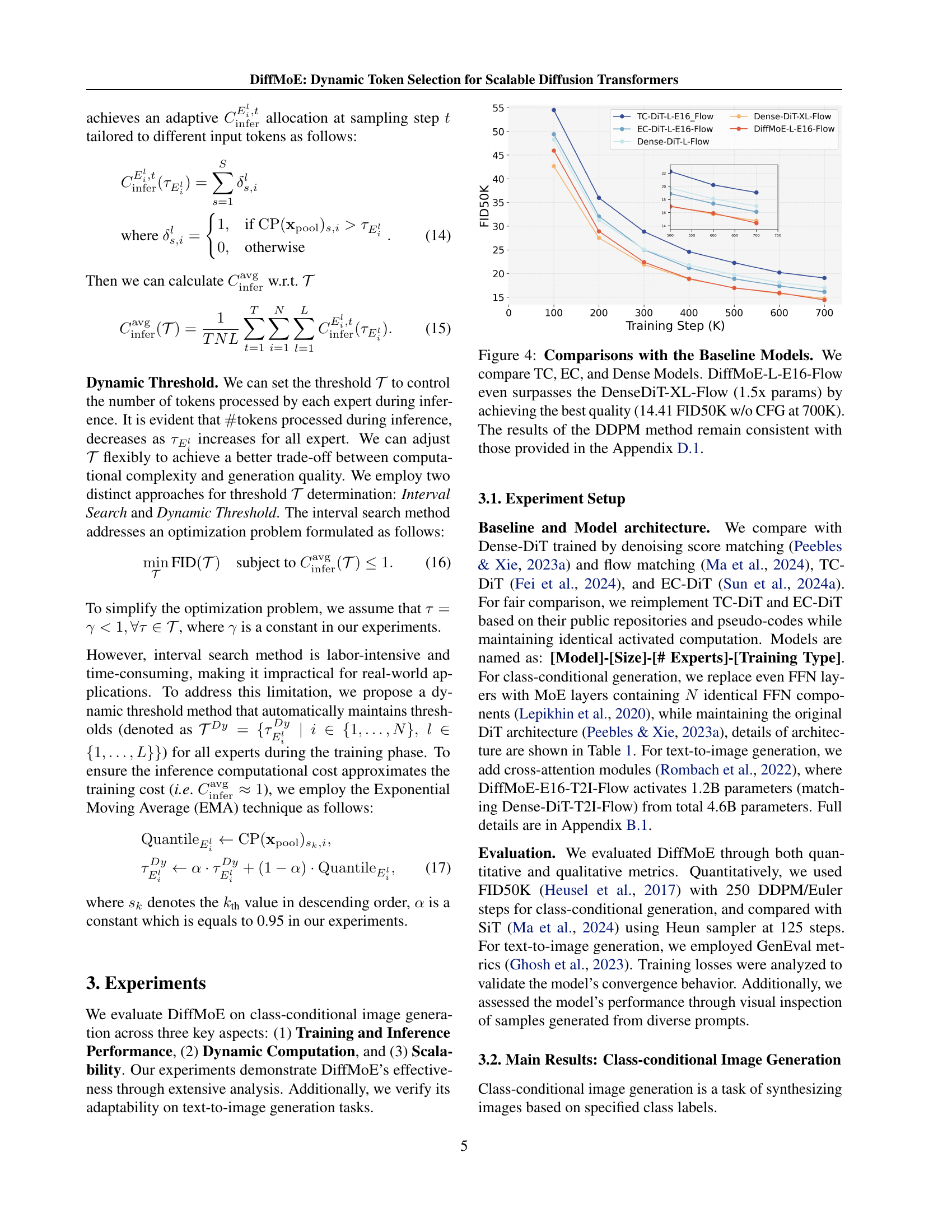
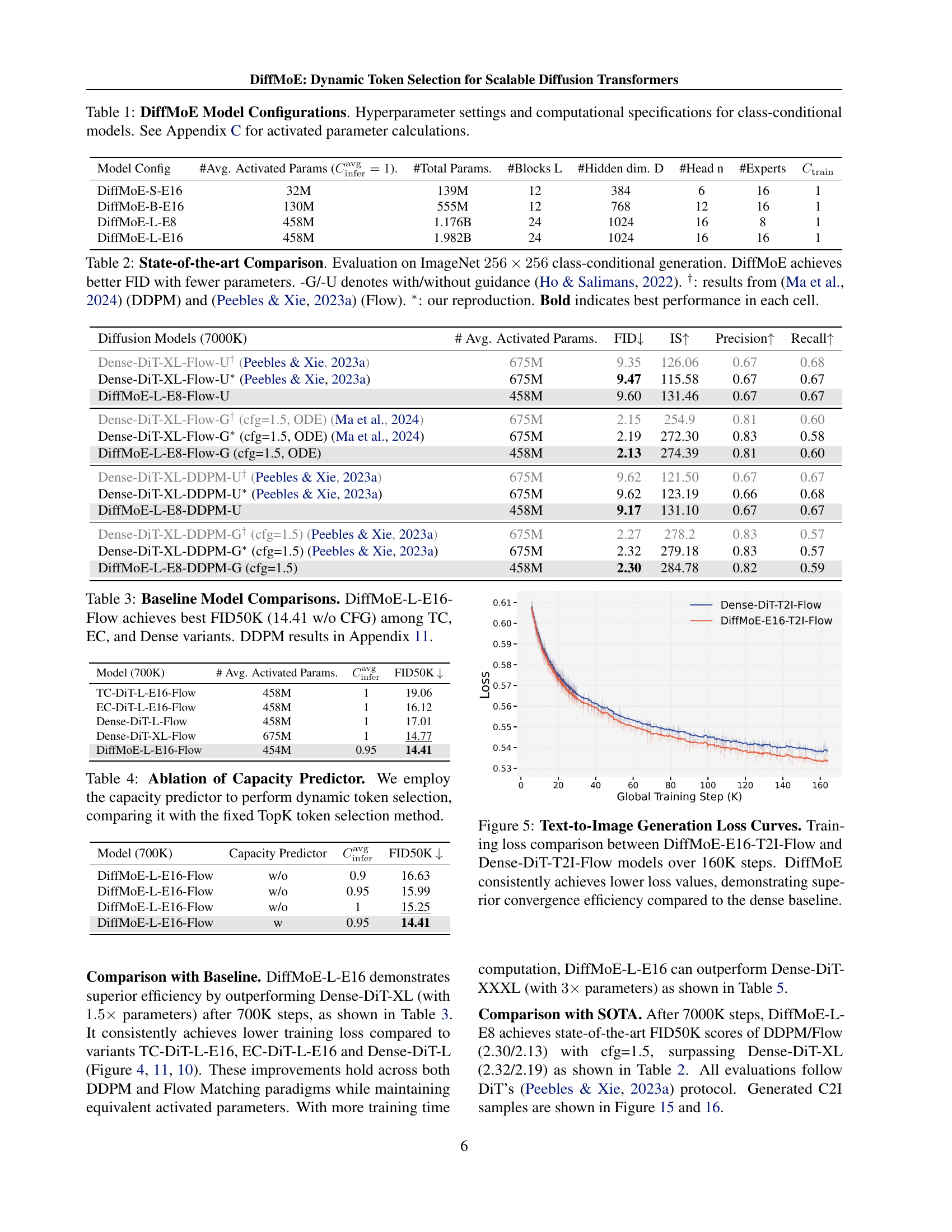
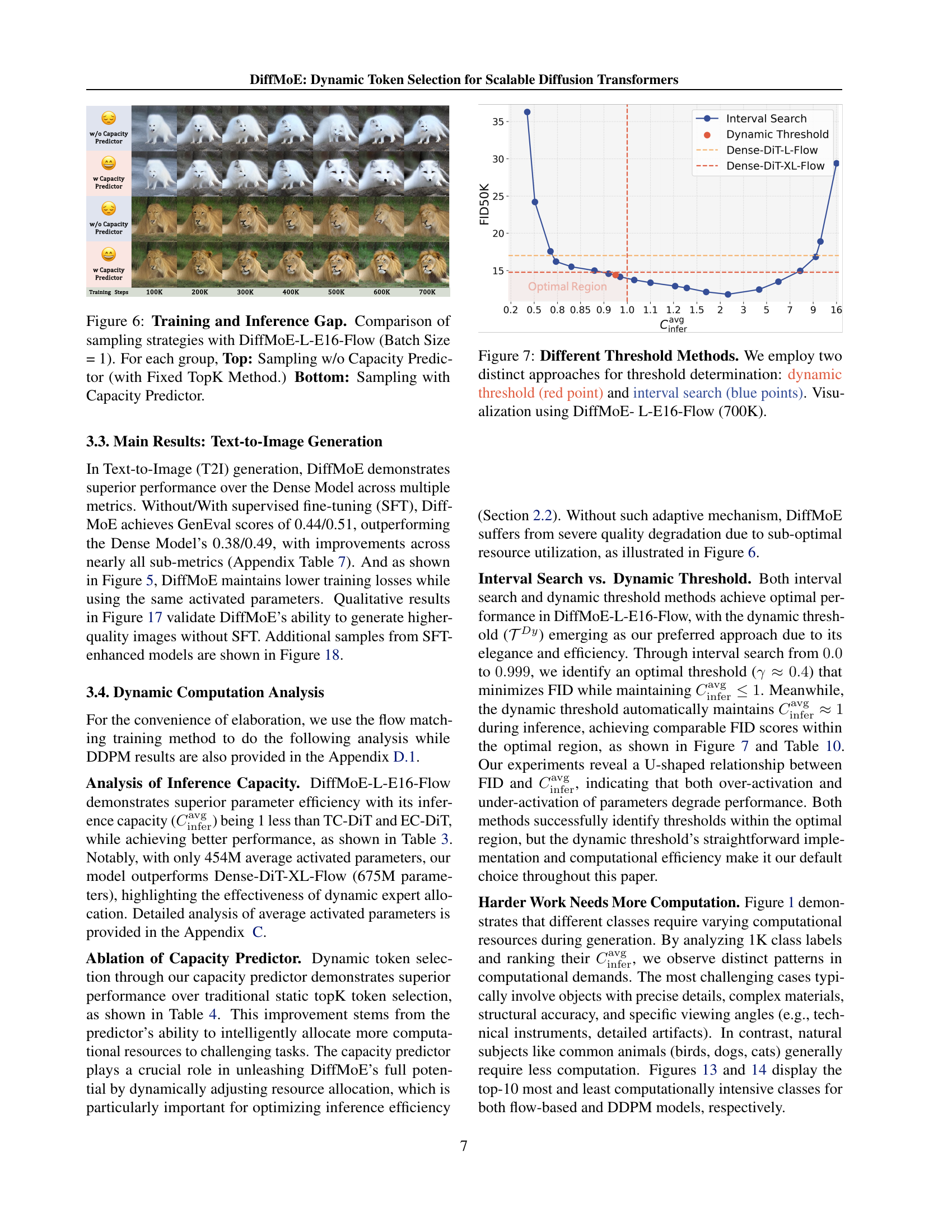
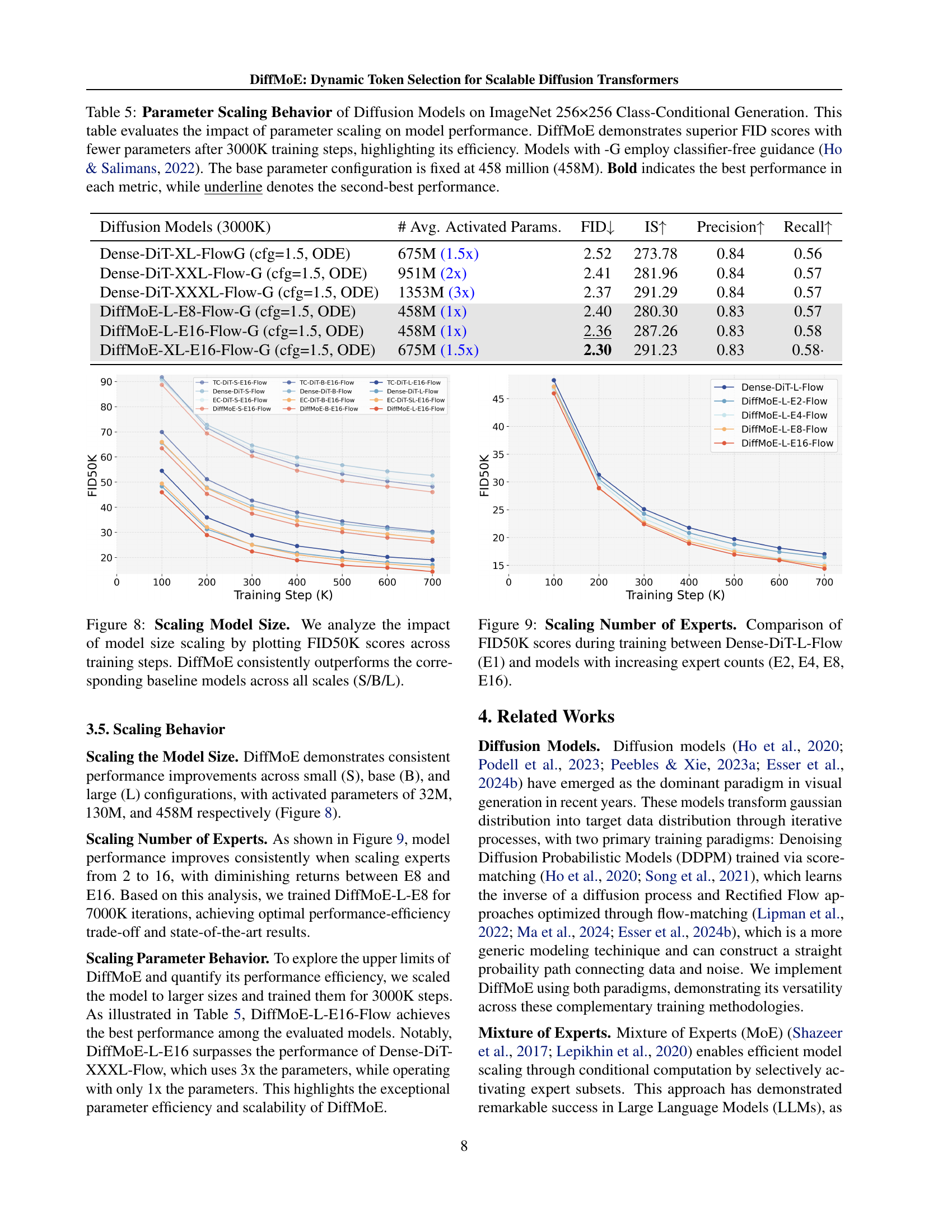
TL;DR#
Diffusion Transformers excel in visual generation but treat all inputs uniformly, missing heterogeneity benefits. Mixture-of-Experts (MoE) aims to fix this, but struggles with limited token access and fixed patterns. The current MoE limits token selection within individual samples and noise levels. Dense and TC-MoE isolate tokens while EC-DiT restricts intra-sample interaction. Thus, it hinders model capture of heterogeneity in the diffusion process.
To solve these issues, DiffMoE was introduced. DiffMoE uses a batch-level global token pool for enhanced cross-sample interaction. A capacity predictor dynamically allocates resources. This leads to state-of-the-art performance, outperforming dense architectures with 3× activated parameters while maintaining 1×. DiffMoE’s method extends to text-to-image tasks and is broadly applicable across diffusion models.
Key Takeaways#
Why does it matter?#
This work on dynamic token selection addresses scalability and efficiency in diffusion models, offering state-of-the-art image generation. It opens avenues for new architectures in AI, potentially impacting various applications beyond image synthesis.
Visual Insights#
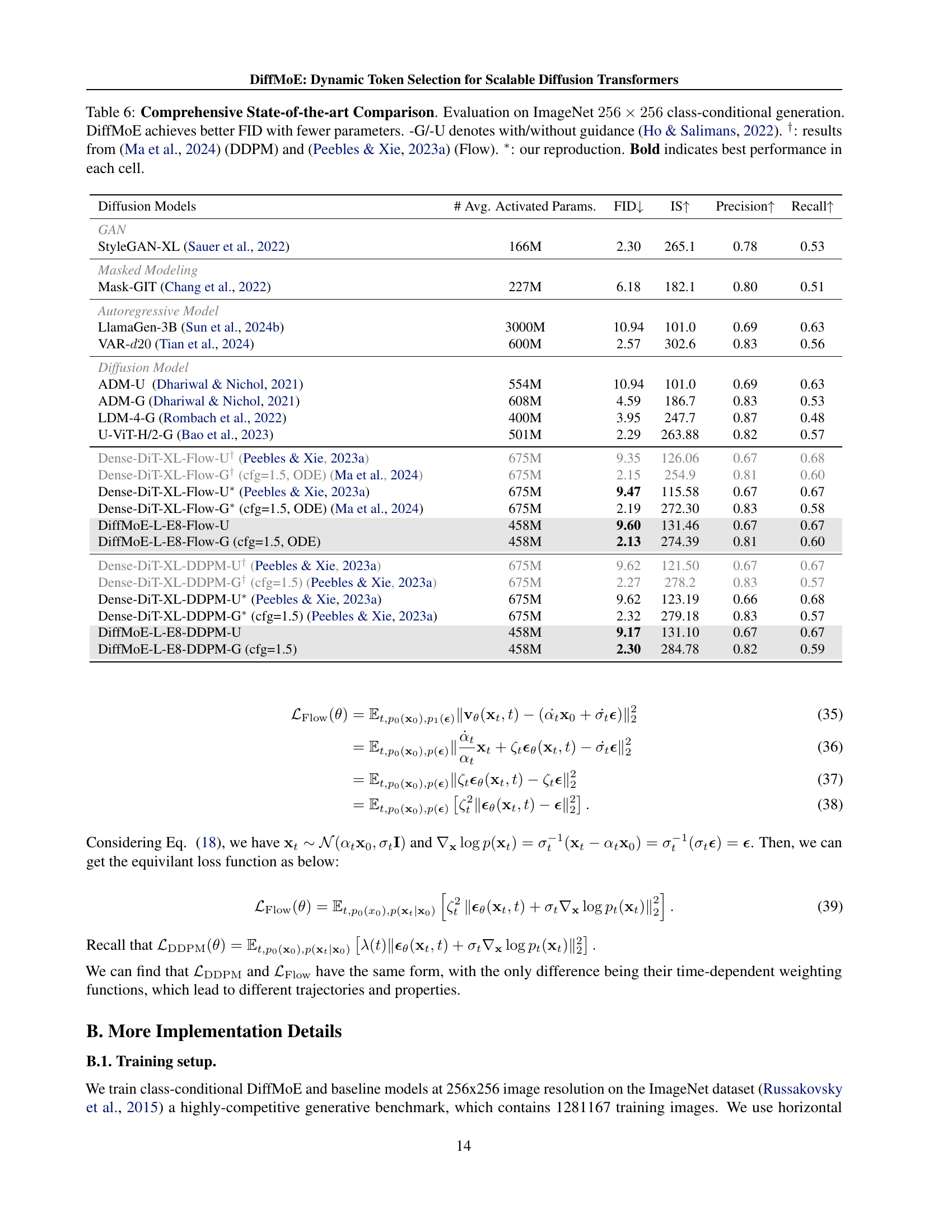
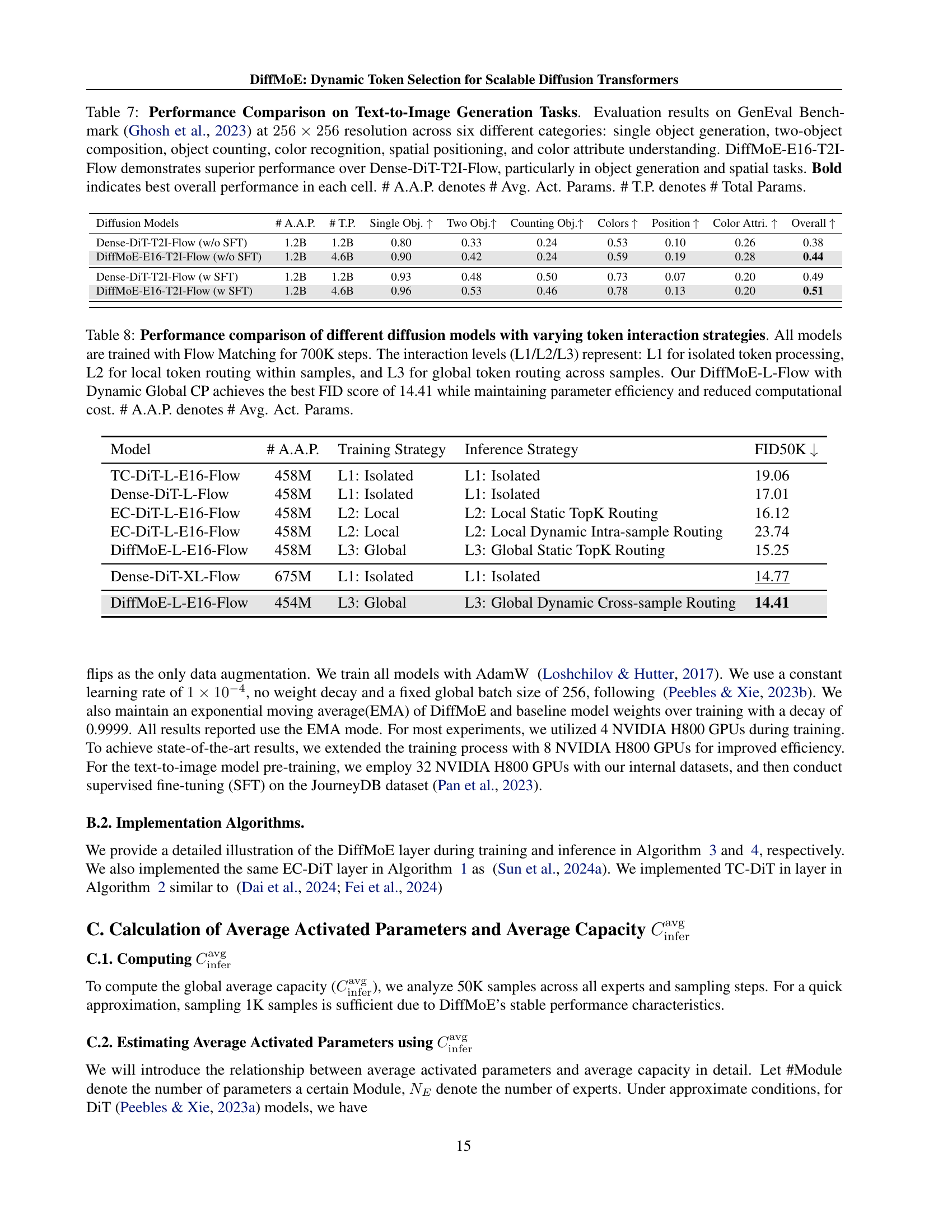
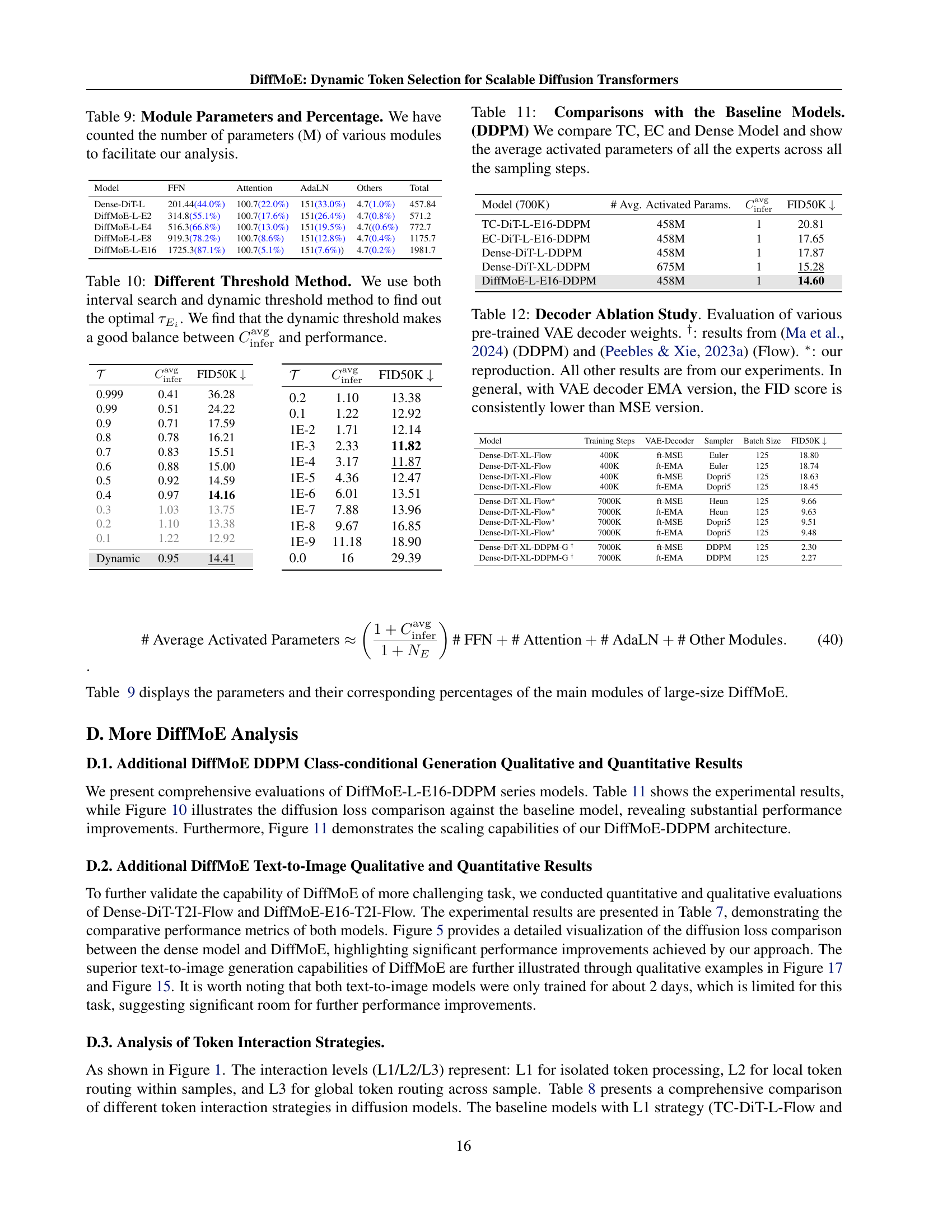
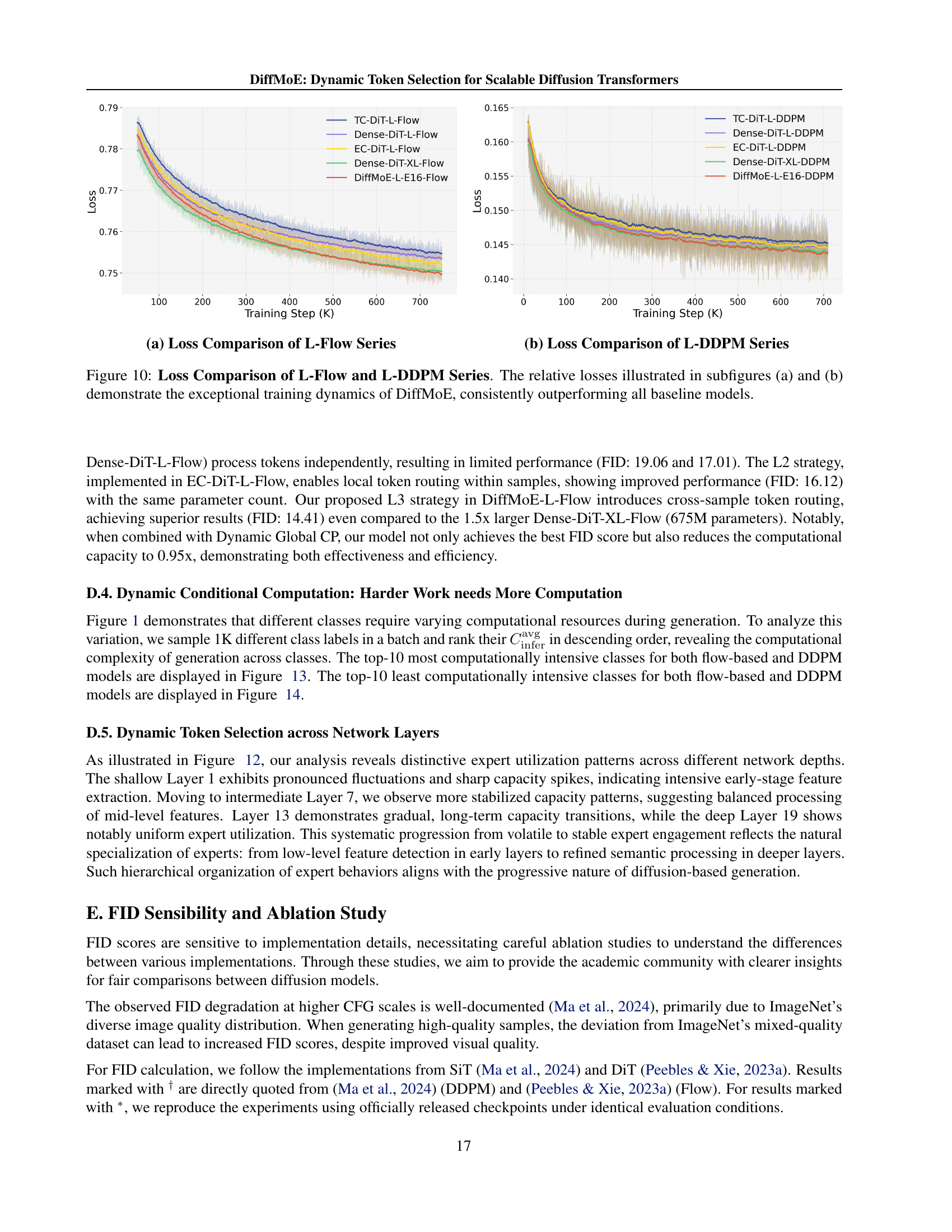
| Model | # A.A.P. | Training Strategy | Inference Strategy | FID50K |
| TC-DiT-L-E16-Flow | 458M | L1: Isolated | L1: Isolated | 19.06 |
| Dense-DiT-L-Flow | 458M | L1: Isolated | L1: Isolated | 17.01 |
| EC-DiT-L-E16-Flow | 458M | L2: Local | L2: Local Static TopK Routing | 16.12 |
| EC-DiT-L-E16-Flow | 458M | L2: Local | L2: Local Dynamic Intra-sample Routing | 23.74 |
| DiffMoE-L-E16-Flow | 458M | L3: Global | L3: Global Static TopK Routing | 15.25 |
| Dense-DiT-XL-Flow | 675M | L1: Isolated | L1: Isolated | 14.77 |
| DiffMoE-L-E16-Flow | 454M | L3: Global | L3: Global Dynamic Cross-sample Routing | 14.41 |
🔼 This table details the different configurations used for training the DiffMoE model for class-conditional image generation. It lists hyperparameters such as the number of activated parameters, total parameters, number of blocks, hidden dimension, number of heads, and the number of experts. These configurations represent different model sizes and complexities, allowing for a comparative analysis of performance across varying computational budgets. Refer to Appendix C for a detailed explanation of how activated parameters were calculated.
read the caption
Table 1: DiffMoE Model Configurations. Hyperparameter settings and computational specifications for class-conditional models. See Appendix C for activated parameter calculations.
Full paper#