TL;DR#
With the rise of AI-generated content, assessing image authenticity is more challenging than ever. Existing methods often lack human interpretability and struggle with the complexity of synthetic data. This limits users’ understanding of the reasons behind system’s decisions, affecting the process’s transparency and trustworthiness.
To address these challenges, the paper introduces FakeVLM, a large multimodal model for synthetic image detection with artifact explanation. Along with FakeVLM, the authors create FakeClue, a comprehensive dataset. The paper demonstrates the model’s superior performance, marking a significant advancement in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers navigating the evolving landscape of AI-generated content. It offers a robust method for detecting synthetic images and interpretable explanations of artifacts, enhancing trust and transparency. The dataset provides a valuable resource, paving the way for future advancements.
Visual Insights#

🔼 FakeVLM is a large multimodal model designed to identify both DeepFake and general synthetic images across a wide range of image categories, including animals, objects, humans, and scenery. It is designed to not only classify images as real or fake but also explain its classification decision through the generation of a natural language description that pinpoints specific image artifacts indicating synthesis. This figure shows an example of FakeVLM’s capabilities.
read the caption
Figure 1: FakeVLM is a specialized large multimodal model designed for both DeepFake and general synthetic image detection tasks across multiple domains.
| Dataset | Field | Artifact | Annotator | Category | Number |
| DD-VQA [61] | DF | Syn | Human | 5k | |
| FF-VQA [17] | DF | Syn | GPT | 95K | |
| LOKI [58] | Gen | Syn | Human | ✓ | 3k |
| Fakebench [28] | Gen | Syn | Human | ✓ | 6k |
| MMTD-Set [52] | Gen | Tam | GPT | 100k | |
| FakeClue | DF+Gen | Syn | Multi-LMMs | ✓ | 100k |
🔼 This table compares FakeClue dataset with other existing datasets used for synthetic image detection. It provides a comparison across several key dimensions: the type of synthetic images included (DeepFake, general synthetic images, or those with tampering), the type of artifacts annotated (synthesis artifacts only, or both synthesis and tampering artifacts), the annotation method used (human annotation, or using GPT models), the number of images, and the overall accuracy. This allows readers to understand the relative size, scope and characteristics of FakeClue in comparison to prior work, and to understand FakeClue’s unique contributions.
read the caption
Table 1: Comparison with existing synthetic detection datasets (DF: DeepFake, Gen: General, Syn: Synthesis, Tam: Tampering).
In-depth insights#
Artifacts’ Insight#
The paper addresses the challenge of detecting synthetic images, especially with the rise of AI-generated content. A key insight is the need for interpretability in synthetic image detection. Existing methods often lack human-understandable explanations. The research introduces FakeVLM, a model designed to detect synthetic images and provide natural language explanations of image artifacts. This combines detection with explanation, enhancing transparency. It also introduces FakeClue, a dataset containing images with detailed artifact clues in natural language to make the model robust. The research highlights the importance of identifying and explaining specific artifacts created by synthetic image generation techniques, rather than simply classifying images as real or fake. The insight focuses on enhancing user trust and understanding through detailed artifact-based analysis.
FakeVLM Design#
The FakeVLM design, built upon the LLaVA architecture, cleverly integrates a Global Image Encoder (using CLIP-ViT), an MLP Projector for modality bridging, and a Large Language Model (LLM), specifically Vicuna-v1.5. By fine-tuning all parameters, FakeVLM comprehensively adapts to synthetic data nuances while retaining instruction-following. It not only extracts common points and ignores outliers from multiple model responses but also organizes them into a hierarchical structure, ultimately enhancing the model’s interpretability in detecting synthetic images by generating excellent interpretability for artifact details in synthetic images.
Beyond Binary#
The concept of “Beyond Binary” suggests a move away from simplistic true/false or real/fake classifications in synthetic image detection, advocating for a more nuanced and interpretable approach. It acknowledges that the authenticity of an image exists on a spectrum rather than a dichotomy. This requires models to provide richer explanations beyond a simple label, detailing the specific artifacts or inconsistencies that contribute to its perceived authenticity. Furthermore, “Beyond Binary” implies considering the contextual and subjective aspects of image authenticity, understanding that the perception of what is real or fake can vary depending on the viewer and the intended use of the image. This shift necessitates developing more sophisticated metrics and evaluation frameworks that capture the multifaceted nature of image authenticity. The goal is to enhance transparency and trustworthiness in synthetic image detection, enabling users to make informed decisions based on a comprehensive understanding of an image’s characteristics, leading to a more robust and reliable system that considers the complex and evolving nature of synthetic media, moving beyond simple classification to detailed analysis and explanations, enhancing human interpretability and decision-making.
Category Matters#
The idea that ‘Category Matters’ when analyzing AI-generated content is crucial. Different categories of images (e.g., animals, humans, landscapes) possess distinct artifact patterns. Anomaly in animal images might involve structural inconsistencies or unnatural textures, while issues in human images might relate to facial distortions. By tailoring the analysis to the specific category, detection accuracy and interpretability can be significantly improved. Without such categorization, generic detection methods might overlook subtle category-specific inconsistencies, leading to less reliable results. Moreover, category-specific knowledge enables the generation of more focused explanations about the detected artifacts, enhancing user trust and understanding. Failing to account for category differences can hinder the development of robust and reliable synthetic image detection systems.
LMMs’ Limits?#
Although Large Multimodal Models (LMMs) possess strong text explanation capabilities, pretrained LMMs often fail to achieve satisfactory performance when tasked with determining whether an image was AI-generated or identifying forged images. This highlights the difficulty of relying on LMMs for authenticity judgment, as these models aren’t inherently designed for synthetic data detection tasks. Nonetheless, LMMs have developed strong visual feature extraction abilities and alignment with text through extensive pretraining. Therefore, the question arises: can the internal representations of LMMs encode information to distinguish real images from synthetic ones?
More visual insights#
More on figures

🔼 The figure illustrates the creation process of the FakeClue dataset. It begins with data collection from both publicly available open-source datasets and data generated specifically for this project. The collected data then undergoes preprocessing, including categorization of images into specific types (e.g., animals, objects, scenery). Subsequently, labels and prompts are designed for annotation, leveraging category-specific knowledge to guide the labeling process. Finally, the data is annotated with multiple large multimodal models (LMMs) and these annotations are aggregated to create the final FakeClue dataset. This multifaceted approach ensures a rich and diverse dataset for evaluating synthetic image detection models.
read the caption
Figure 2: Construction pipeline of FakeClue dataset, including data collection from open source and self-synthesized datasets, pre-processing with categorization, label prompt design based on category knowledge, and multiple LMMs annotation with result aggregation.

🔼 This figure compares four different approaches for synthetic image detection using large multimodal models (LMMs) and evaluates their performance on the LOKI and FakeClue datasets. The four approaches are: 1. QA with Frozen LMMs (no training): A pre-trained LMM is used directly for question answering (QA), without any further training. This serves as a baseline to evaluate the potential of directly using pre-trained LMMs for detection without additional fine-tuning. 2. Frozen backbone + linear probe (only linear layer trained): The vision backbone of the LMM is frozen (weights remain fixed), and only a small linear layer is trained on top of the frozen backbone features. This approach helps to investigate how well the existing features can be used for detection with minimal changes. 3. Direct Real/Fake QA tuning: This method involves fine-tuning the entire LMM directly using real/fake QA pairs for synthetic image detection. This assesses the effect of full LMM training for detection. 4. VQA with artifact explanations tuning: This method fine-tunes the LMM for visual question answering (VQA) that focuses on identifying and explaining artifacts in synthetic images. This explores the benefit of fine-tuning the LMM for a more nuanced, explanation-focused approach, assessing performance and interpretability. The figure likely displays the results (e.g., accuracy, F1 score) of each approach on both datasets, comparing their relative performance and demonstrating the improvements achieved by using more sophisticated fine-tuning strategies.
read the caption
Figure 3: Comparison of synthetic image detection approaches on LOKI and FakeClue datasets: (1) QA with Frozen LMMs (no training), (2) Frozen backbone + linear probe (only linear layer trained), (3) Direct Real/Fake QA tuning, and (4) VQA with artifact explanations tuning.

🔼 FakeVLM is a multimodal model built upon LLaVA, designed for synthetic image detection and artifact explanation. It uses a vision encoder (CLIP-ViT), a multi-modal projector, and a large language model (Vicuna) to process images and generate explanations for detected artifacts. Multiple captioning models are integrated to improve the robustness and accuracy of both the detection and explanation tasks. The figure illustrates the architecture of FakeVLM, showcasing the flow of image data through the different components and the generation of a natural language response.
read the caption
Figure 4: Overview of FakeVLM, our proposed framework for detecting synthetic images and explaining their artifacts. Built upon LLaVA, FakeVLM integrates multiple captioning models to assess key visual aspects.

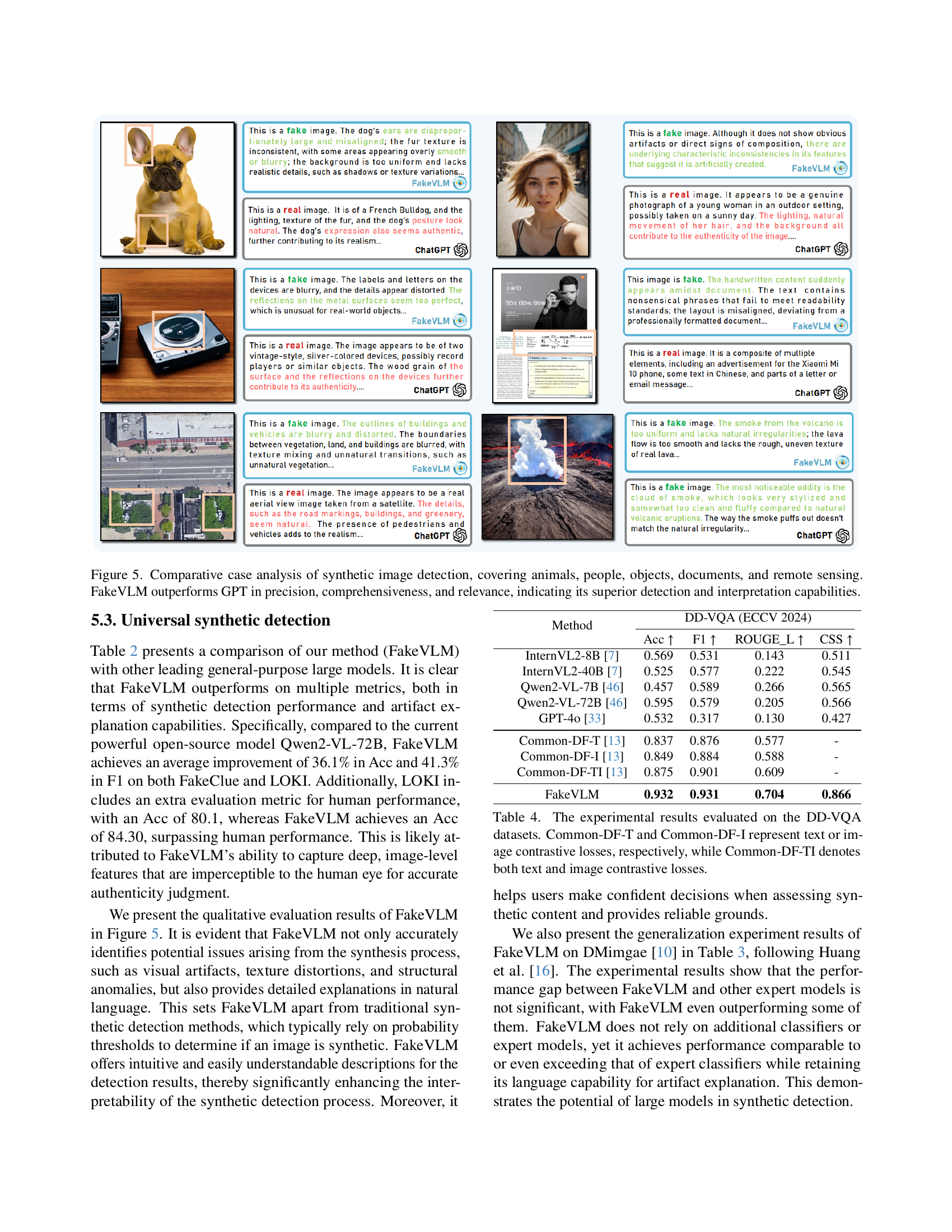
🔼 Figure 5 presents a qualitative comparison of FakeVLM and GPT’s performance on synthetic image detection across various domains. Each example shows an image and its corresponding analysis from both models. FakeVLM demonstrates superior capabilities by providing more precise, comprehensive, and relevant explanations for its judgments compared to GPT. The diverse image types include animals (a dog), people (a woman), objects (vintage devices), documents (a document with mixed handwritten text), and remote sensing (satellite imagery). This figure highlights FakeVLM’s superior ability to not only accurately identify synthetic images but also to articulate detailed and insightful explanations of the specific image artifacts that led to that conclusion.
read the caption
Figure 5: Comparative case analysis of synthetic image detection, covering animals, people, objects, documents, and remote sensing. FakeVLM outperforms GPT in precision, comprehensiveness, and relevance, indicating its superior detection and interpretation capabilities.
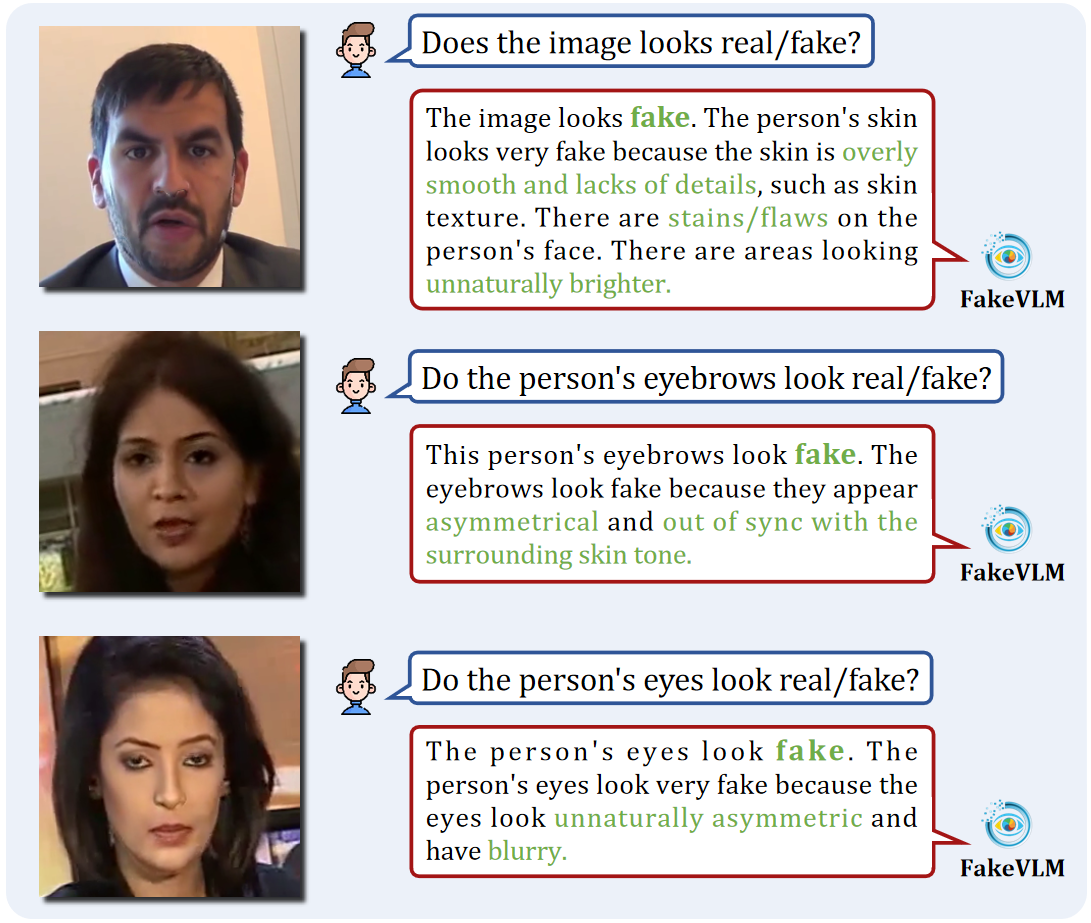
🔼 Figure 6 showcases example outputs from the FakeVLM model when evaluated on the DD-VQA dataset, which focuses on fine-grained DeepFake detection. The figure presents several image examples along with the model’s corresponding textual explanations. Each example highlights a specific area or artifact within the image and explains why the model classifies it as a synthetic artifact. This demonstrates FakeVLM’s ability to not only identify subtle signs of image manipulation but also to articulate the reasons behind its assessment in natural language, thereby offering both accurate detection and interpretability. The examples cover various types of facial manipulation artifacts.
read the caption
Figure 6: Typical cases on DD-VQA dataset. Our model accurately identifies and explains the synthetic artifacts, demonstrating its effectiveness in fine-grained DeepFake detection and interpretation.

🔼 This figure shows the results of applying FakeVLM to real images. It demonstrates FakeVLM’s ability to correctly identify real images, avoiding false positives (incorrectly classifying a real image as fake). This is important because a reliable synthetic image detector should not misclassify authentic images as forgeries. The results highlight the model’s robustness and accuracy in a real-world scenario where the majority of images are genuine.
read the caption
Figure 7: Performance of FakeVLM on real images.
More on tables
| Method | Real | Fake | Overall | |||
| Acc | F1 | Acc | F1 | Acc | F1 | |
| CNNSpot [48] | 87.8 | 88.4 | 28.4 | 44.2 | 40.6 | 43.3 |
| Gram-Net [30] | 22.8 | 34.1 | 78.8 | 88.1 | 67.4 | 79.4 |
| Fusing [20] | 87.7 | 86.1 | 15.5 | 27.2 | 40.4 | 36.5 |
| LNP [3] | 63.1 | 67.4 | 56.9 | 72.5 | 58.2 | 68.3 |
| UnivFD [32] | 89.4 | 88.3 | 44.9 | 61.2 | 53.9 | 60.7 |
| AntifakePrompt [4] | 91.3 | 92.5 | 89.3 | 91.2 | 90.6 | 91.2 |
| SIDA [16] | 92.9 | 93.1 | 90.7 | 91.0 | 91.8 | 92.4 |
| FakeVLM | 98.2 | 99.1 | 89.7 | 94.6 | 94.0 | 94.3 |
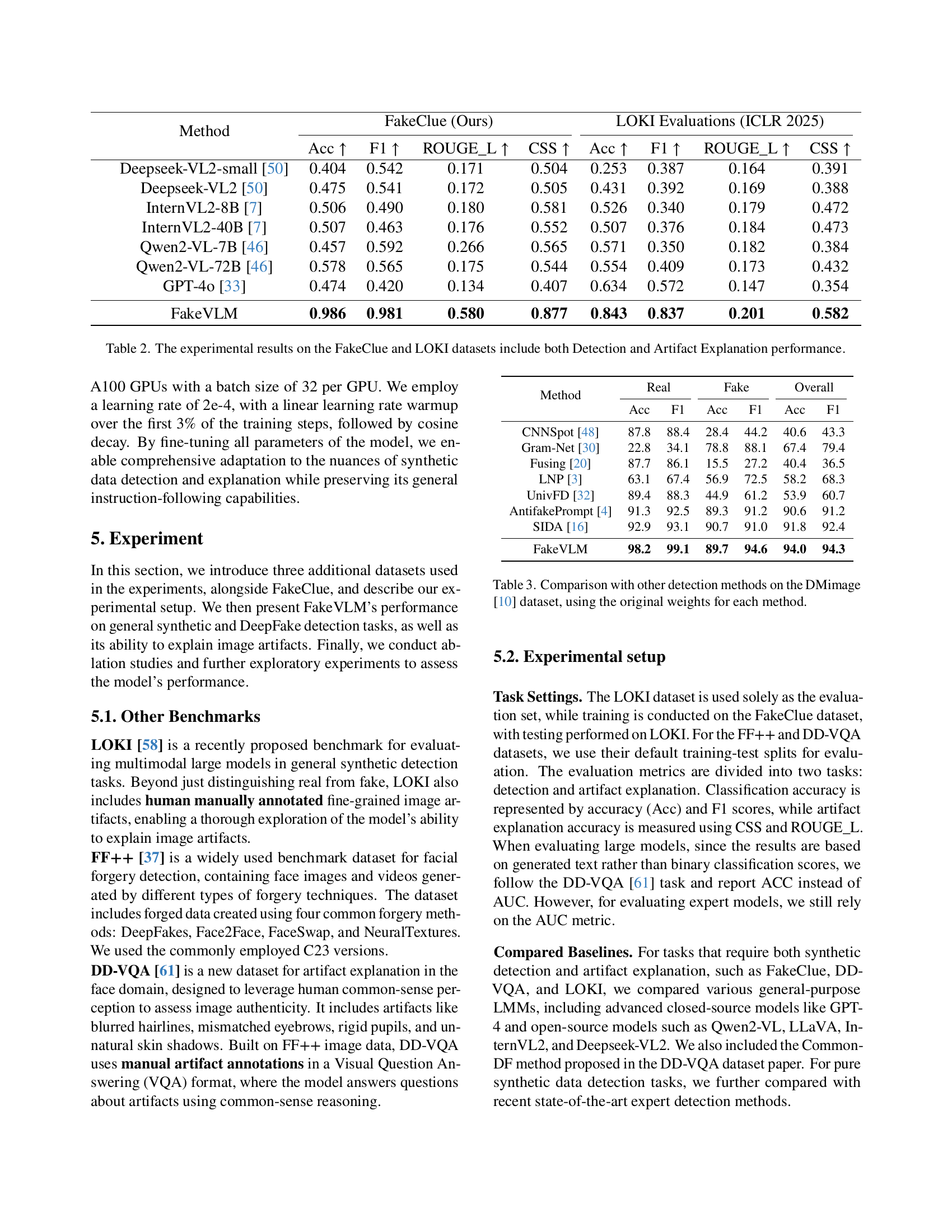
🔼 Table 2 presents a comprehensive comparison of various methods’ performance on two datasets: FakeClue and LOKI. It evaluates both the accuracy of synthetic image detection (real vs. fake) and the quality of artifact explanations generated by the models. The metrics used encompass accuracy (Acc), F1 score (F1), ROUGE-L (for explanation quality), and CSS (for explanation consistency). The table allows for a direct comparison of FakeVLM against other state-of-the-art models, highlighting its strengths in both accurate classification and meaningful artifact explanation.
read the caption
Table 2: The experimental results on the FakeClue and LOKI datasets include both Detection and Artifact Explanation performance.
| Method | FF++ (ICCV 2019) - AUC(%) | ||||
| FF-DF | FF-F2F | FF-FS | FF-NT | Average | |
| FWA [47] | 92.1 | 90.0 | 88.4 | 81.2 | 87.7 |
| Face X-ray [25] | 97.9 | 98.7 | 98.7 | 92.9 | 95.9 |
| SRM [23] | 97.3 | 97.0 | 97.4 | 93.0 | 95.8 |
| CDFA [53] | 99.9 | 86.9 | 93.3 | 80.7 | 90.2 |
| FakeVLM | 97.2 | 96.0 | 96.8 | 95.0 | 96.3 |
🔼 Table 3 presents a comparison of the performance of FakeVLM against other state-of-the-art synthetic image detection methods on the DMimage dataset. Unlike the other methods, FakeVLM uses its original, pretrained weights, without any further fine-tuning or modifications. This highlights FakeVLM’s ability to achieve competitive results without requiring additional training steps tailored to the specific DMimage dataset. The table shows the accuracy and F1 scores for real and fake image classification and the overall performance across both.
read the caption
Table 3: Comparison with other detection methods on the DMimage [10] dataset, using the original weights for each method.
Full paper#