TL;DR#
Generative technology’s rapid advancements have led to powerful tools, along with social concerns. Current synthetic image detection methods lack artifact-level interpretability, are overly focused on image manipulation detection, and datasets have outdated generators and lack fine-grained annotations. To address these issues, this paper introduces SynthScars, a high-quality, diverse dataset consisting of fully synthetic images with human-expert annotations, featuring distinct image content types, categories of artifacts, and fine-grained annotations.
To complement this, the paper presents LEGION, a multimodal large language model-based image forgery analysis framework that integrates artifact detection, segmentation, and explanation. Moreover, it uses LEGION as a controller, integrating it into image refinement pipelines to guide the generation of higher-quality and more realistic images. Extensive experiments demonstrate that LEGION outperforms existing methods, achieving new state-of-the-art results on multiple benchmarks.
Key Takeaways#
Why does it matter?#
This paper matters for researchers by introducing SynthScars, a novel, high-quality dataset, paired with LEGION, an innovative forgery analysis framework. It not only enhances the detection of synthetic images but also paves the way for refining image generation processes, fostering both defensive and generative advancements in AI.
Visual Insights#

🔼 This figure compares LEGION with existing image forgery detection methods. It highlights that unlike other methods which only perform detection (Defender), LEGION performs multi-task analysis (including detection, segmentation, and explanation) and also acts as a controller in the image generation process. This ‘Controller’ aspect is unique to LEGION and allows it to guide the generation of higher-quality and more realistic images, addressing issues of current generation technologies.
read the caption
Figure 1: Comparison with Existing Image Forgery Detection Methods. LEGION not only serves as a Defender, enabling multi-task forgery analysis, but also functions as a Controller, facilitating high-quality image generation.
| Dataset | Pixel-level Mask | Explanation | Artifact Type | Annotator | Valid Sample |
| CNNSpot [54] | ✗ | ✗ | ✗ | - | 0 |
| CIFAKE [2] | ✗ | ✗ | ✗ | - | 0 |
| UniFD [38] | ✗ | ✗ | ✗ | - | 0 |
| GenImage [71] | ✗ | ✗ | ✗ | - | 0 |
| Chamelon [59] | ✗ | ✗ | ✗ | - | 0 |
| AI-Face [29] | ✗ | ✗ | ✗ | - | 0 |
| PAL4VST [67] | ✔ | ✗ | ✗ | Human | 10168 |
| RichHF-18K [28] | ✗ | ✗ | ✗ | Human | 11140 |
| LOKI [61] | ✗ | ✔ | ✗ | Human | 229 |
| MMTD-Set [58] | ✔ – | ✔ | ✗ | GPT-4 | 0 |
| FF-VQA [18] | ✗ | ✔ | ✗ | GPT-4 | 0 |
| SID-Set [17] | ✔ – | ✔ | ✗ | GPT-4 | 0 |
| SynthScars | ✔ | ✔ | ✔ | Human | 12236 |
🔼 This table compares SynthScars with other existing image forgery datasets, highlighting key differences in annotation quality and the types of synthetic images included. SynthScars stands out with its focus on fully synthesized images generated by modern techniques, featuring realistic styles, and providing both pixel-level masks and textual explanations for artifacts. In contrast, many previous datasets relied on older generators, resulting in lower-quality, easier-to-detect synthetic images, and lacked complete or detailed annotations (indicated by the ‘-’ in the last column). The ‘✔’ symbol indicates datasets with images fully generated by modern common generators and realistic styles.
read the caption
Table 1: Comparison with Existing Image Forgery Datasets. The last column shows the number of samples fully synthesized by common generators, with realistic style and valid masks. ✔ – denotes that only masks of tampered images are provided.
In-depth insights#
MLLM for Forgery#
While the exact phrase “MLLM for Forgery” isn’t present, the research leverages Multimodal Large Language Models (MLLMs) extensively for synthetic image detection. The paper addresses limitations of existing forgery detection methods by incorporating MLLMs to achieve artifact-level interpretability, a feature often lacking in traditional approaches. LEGION utilizes MLLMs for forgery analysis, including localization, explanation generation, and detection. The MLLM’s prior knowledge, reasoning, and expression abilities are crucial for generalization across diverse domains and robustness to perturbations. Instead of just detecting forgeries like existing works, LEGION explores using forgery explanations as feedback to enhance image generation, positioning the MLLM as a controller to refine images iteratively via prompt revision and guided inpainting. This represents a shift from a defensive to a generative application of forgery analysis, capitalizing on MLLMs to produce more realistic images. The experimental results highlight superior performance in both forgery detection and artifact explanation generation, demonstrating the potential of MLLMs in advancing synthetic image analysis and controlled image creation.
SynthScars: Dataset#
The SynthScars dataset addresses limitations in synthetic image detection. It avoids outdated, low-quality images and cartoon styles, featuring fine-grained annotations with irregular polygons for precise artifact outlining, alongside detailed classifications and explanations. This dual-layer annotation—spatial and explanatory—enhances the dataset’s value for advancing image detection research. The dataset includes high-quality synthetic images with diverse content types, offering pixel-level artifact annotations with detailed textual explanations. It categorizes artifacts into three types: physics, distortion, and structure. By doing so, this enables more targeted analysis and model training. The SynthScars includes 12,236 fully synthesized images across diverse real-world scenarios, categorized into human, object, animal, and scene. The dataset features 26,566 artifact instances, annotated with irregular polygon masks and classified into physics-related, distortion and structural anomalies.
LEGION: Controller#
The concept of LEGION as a “Controller” marks a significant shift in synthetic image detection, moving beyond simple identification of AI-generated artifacts towards actively guiding image generation for enhanced realism. Instead of only acting as a Defender against potentially harmful AI-generated images, LEGION leverages its understanding of forgery indicators to refine the image creation process. By integrating with image regeneration and inpainting pipelines, LEGION provides valuable feedback, correcting structural inconsistencies and refining styles. This Controller role optimizes both the image itself and the generative prompts, leading to more natural and aesthetically pleasing outcomes. LEGION’s function enhances not just detection but also the artistic and practical applications of image synthesis.
Artifact Refinement#
The research paper explores the concept of ‘Artifact Refinement’ as a crucial step in enhancing the quality and realism of synthetically generated images. Instead of solely focusing on artifact detection, the paper advocates for leveraging detection insights to guide refinement. This proactive approach transforms the role of artifact analysis from a defensive measure to a generative tool. The paper introduces two refinement strategies: prompt revision for image regeneration and inpainting to selectively correct artifact regions. Prompt revision iteratively refines textual prompts based on artifact explanations to guide image generation towards higher fidelity. Conversely, inpainting utilizes artifact masks and explanations to selectively refine anomalous regions while preserving the integrity of non-artifact areas. These techniques demonstrate a move towards closed-loop systems where detection feeds directly into generation, pushing the boundaries of both domains and highlighting the potential for AI to self-improve its outputs.
Generative Advancing#
The concept of “Generative Advancing” is intriguing, highlighting the reciprocal relationship between generative AI models and detection techniques. As generative models become more sophisticated, detection methods must evolve to identify increasingly subtle forgeries. This arms race fosters advancements on both sides. Generative Advancing means not just improving image synthesis, but also leveraging detection insights to guide further refinements in generation. For example, understanding which artifacts are easily detected informs the development of new techniques to mitigate these flaws. By using the outputs of models like LEGION as feedback to the generation process, images can iteratively get refined, moving closer to photorealism and evading detection. This is a shift from simply identifying fakes to proactively improving image quality. However, there is also a crucial ethical dimension. The advancements enabled by this could lead to easier manipulation of data which needs careful attention.
More visual insights#
More on figures
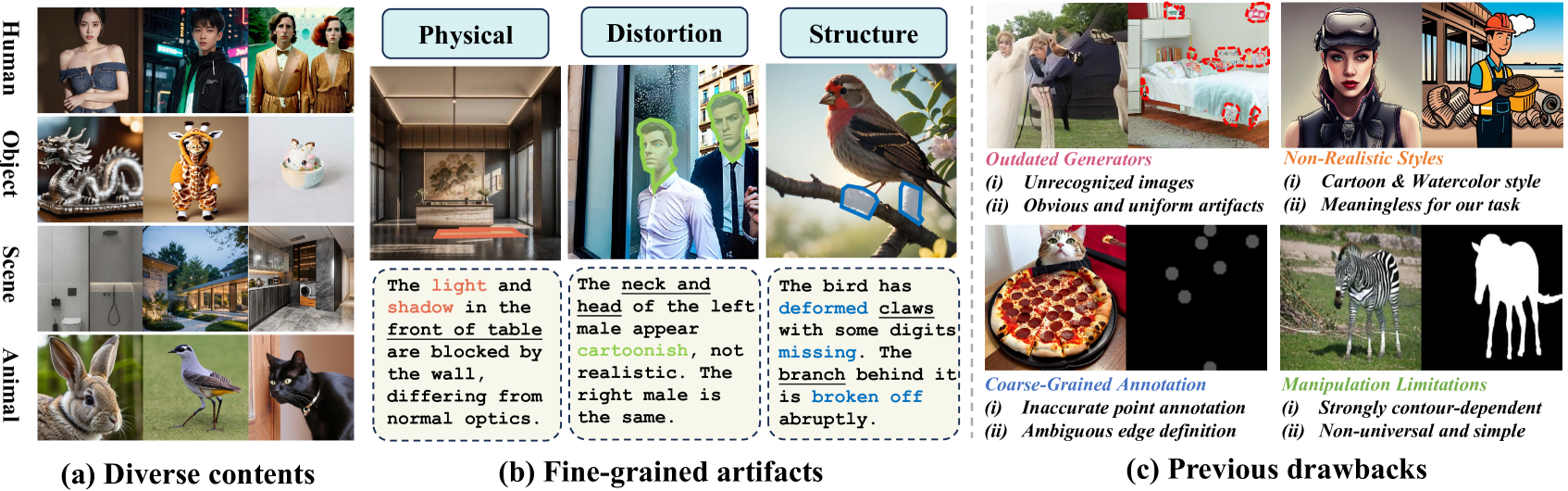
🔼 Figure 2 visualizes the SynthScars dataset, highlighting its improvements over previous datasets. Panel (a) showcases the diversity of image content within the dataset, displaying examples of human subjects, objects, animals, and scenes. Panel (b) illustrates the fine-grained artifact annotations, such as physical distortions, structural inconsistencies, and other types of image manipulation. Panel (c) summarizes the limitations of existing datasets, contrasting them with the superior characteristics of SynthScars, which include higher quality synthetic images, more comprehensive annotations, and a more diverse range of artifacts.
read the caption
Figure 2: SynthScars Datasets. (a) shows image cases across four diverse content types. (b) presents annotation cases across different fine-grained artifact types. (c) enumerates drawbacks of previous datasets, which SynthScars perfectly addresses.

🔼 Figure 3 illustrates the architecture of LEGION, a novel framework for image forgery analysis. Panel (a) details LEGION’s components: a global image encoder, a large language model (LLM), a grounding image encoder, and a pixel decoder. These components work together to perform deepfake detection, artifact localization, and explanation generation. Panels (b) and (c) show two pipelines that utilize LEGION as a controller to guide the generation of higher-quality images through iterative refinement. Panel (b) depicts an image regeneration pipeline using text-to-image (T2I) models and iterative prompt refinement based on LEGION’s analysis. Panel (c) illustrates an image inpainting pipeline that uses LEGION’s artifact location and explanation information to guide region-by-region inpainting.
read the caption
Figure 3: Architecture Overview. (a) Our proposed framework for image forgery analysis, LEGION. (b) and (c) shows two pipelines for image generation. T2I in (b) is short for text-to-image, and Loca. and Expla. in (c) denotes Location and Explanation, respectively.

🔼 Figure 4 presents a visual comparison of artifact segmentation and explanations generated by three different methods: PAL4VST, InternVL2-8B, and LEGION (the authors’ proposed method). It shows how each method identifies and describes artifacts within sample synthetic images. The ground truth is included to provide a benchmark for evaluating the accuracy and quality of the generated segmentations and explanations. This comparison highlights LEGION’s ability to more accurately identify and describe artifacts compared to other approaches, demonstrating its superior performance in synthetic image analysis.
read the caption
Figure 4: Comparison of artifact segmentation and explanations across different methods: PAL4VST, InternVL2-8B, and our proposed LEGION, alongside the ground truth.

🔼 This figure showcases two examples of image regeneration using the LEGION framework. The top example demonstrates style distortion adjustment, where the model refines an image to correct inconsistencies in style, such as removing cartoonish elements and enhancing realism. The bottom example shows detailed structure reshaping, where the model fixes structural anomalies in an image, such as correcting a deformed hand and adding missing elements. Both examples highlight the LEGION framework’s ability to guide image generation towards higher-quality and more realistic images by providing feedback based on its forgery analysis.
read the caption
Figure 5: Case studies of Image Regeneration. (Top) Style Distortion Adjustment, (Bottom) Detailed Structure Reshape.

🔼 This figure showcases an example of the image inpainting pipeline. It demonstrates how the LEGION model iteratively identifies and corrects artifacts in a synthetic image. The example focuses on correcting reflections on water that violate physical laws (mismatched color and unrealistic window shape). Each iteration highlights the refined region with progressively reduced artifacts, showing how LEGION guides the inpainting process to produce a more realistic and natural image.
read the caption
Figure 6: Case Study of Image Inpainting.

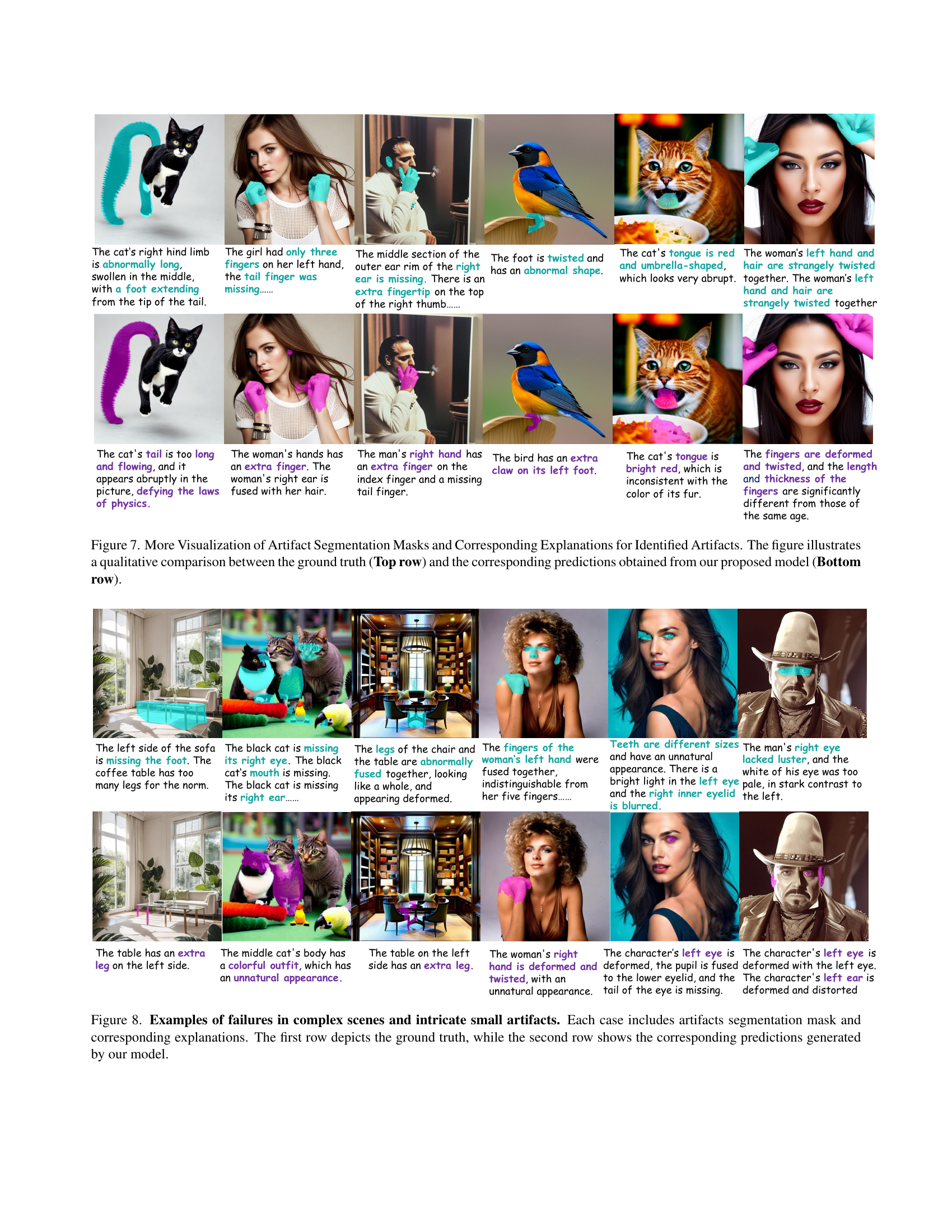
🔼 This figure provides a detailed qualitative comparison of the artifact segmentation masks and their corresponding explanations generated by the proposed LEGION model against the ground truth. The top row displays the ground truth annotations, showcasing the precise location and extent of the artifacts. The bottom row shows the corresponding results produced by the LEGION model, enabling a visual assessment of the model’s accuracy and ability to pinpoint and describe the artifacts. This comparison allows for a direct evaluation of the model’s performance in terms of both the localization and description of the identified artifacts.
read the caption
Figure 7: More Visualization of Artifact Segmentation Masks and Corresponding Explanations for Identified Artifacts. The figure illustrates a qualitative comparison between the ground truth (Top row) and the corresponding predictions obtained from our proposed model (Bottom row).

🔼 Figure 8 presents several examples where the LEGION model, designed for synthetic image artifact detection, encounters difficulties. The failures are categorized into two main types: complex scenes and tiny, subtle artifacts. Complex scenes refer to images with multiple elements making it hard to pinpoint small artifacts. Tiny, subtle artifacts refer to imperfections so small that they are difficult to detect even for the human eye. Each case shows the ground truth (top row) and the model’s prediction (bottom row), including segmentation masks and textual descriptions explaining the model’s performance and the nature of the artifacts.
read the caption
Figure 8: Examples of failures in complex scenes and intricate small artifacts. Each case includes artifacts segmentation mask and corresponding explanations. The first row depicts the ground truth, while the second row shows the corresponding predictions generated by our model.
More on tables
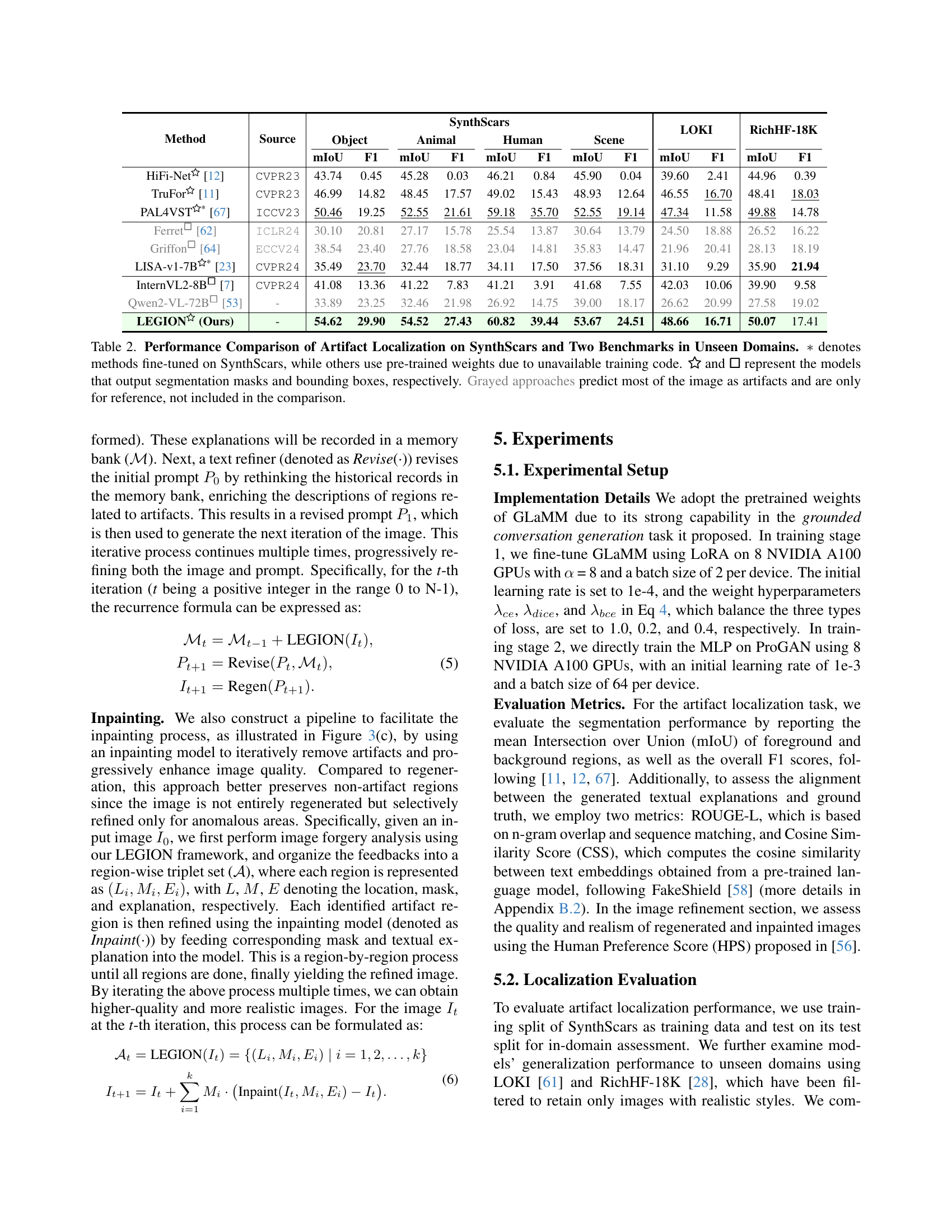
| Method | Source | SynthScars | LOKI | RichHF-18K | |||||||||
| Object | Animal | Human | Scene | ||||||||||
| mIoU | F1 | mIoU | F1 | mIoU | F1 | mIoU | F1 | mIoU | F1 | mIoU | F1 | ||
| HiFi-Net [12] | CVPR23 | 43.74 | 0.45 | 45.28 | 0.03 | 46.21 | 0.84 | 45.90 | 0.04 | 39.60 | 2.41 | 44.96 | 0.39 |
| TruFor [11] | CVPR23 | 46.99 | 14.82 | 48.45 | 17.57 | 49.02 | 15.43 | 48.93 | 12.64 | 46.55 | 16.70 | 48.41 | 18.03 |
| PAL4VST [67] | ICCV23 | 50.46 | 19.25 | 52.55 | 21.61 | 59.18 | 35.70 | 52.55 | 19.14 | 47.34 | 11.58 | 49.88 | 14.78 |
| Ferret□ [62] | ICLR24 | 30.10 | 20.81 | 27.17 | 15.78 | 25.54 | 13.87 | 30.64 | 13.79 | 24.50 | 18.88 | 26.52 | 16.22 |
| Griffon□ [64] | ECCV24 | 38.54 | 23.40 | 27.76 | 18.58 | 23.04 | 14.81 | 35.83 | 14.47 | 21.96 | 20.41 | 28.13 | 18.19 |
| LISA-v1-7B [23] | CVPR24 | 35.49 | 23.70 | 32.44 | 18.77 | 34.11 | 17.50 | 37.56 | 18.31 | 31.10 | 9.29 | 35.90 | 21.94 |
| InternVL2-8B□ [7] | CVPR24 | 41.08 | 13.36 | 41.22 | 7.83 | 41.21 | 3.91 | 41.68 | 7.55 | 42.03 | 10.06 | 39.90 | 9.58 |
| Qwen2-VL-72B□ [53] | - | 33.89 | 23.25 | 32.46 | 21.98 | 26.92 | 14.75 | 39.00 | 18.17 | 26.62 | 20.99 | 27.58 | 19.02 |
| LEGION (Ours) | - | 54.62 | 29.90 | 54.52 | 27.43 | 60.82 | 39.44 | 53.67 | 24.51 | 48.66 | 16.71 | 50.07 | 17.41 |
🔼 Table 2 presents a performance comparison of different methods for artifact localization in synthetic images. It evaluates these methods on three datasets: SynthScars (a new dataset introduced in the paper), LOKI, and RichHF-18K. The table shows the mean Intersection over Union (mIoU) and F1 score achieved by each method on each dataset, for three different categories of objects (human, animal, and scene). Note that methods marked with a ∗ are fine-tuned on SynthScars, while others use pre-trained weights due to limitations in obtaining training code. The symbols ☆ and □ indicate whether the model outputs segmentation masks or bounding boxes, respectively. Rows in gray represent methods that incorrectly identify most of the image as artifacts and are thus excluded from the main comparison.
read the caption
Table 2: Performance Comparison of Artifact Localization on SynthScars and Two Benchmarks in Unseen Domains. ∗*∗ denotes methods fine-tuned on SynthScars, while others use pre-trained weights due to unavailable training code. \faStarO and □bold-□\bm{\square}bold_□ represent the models that output segmentation masks and bounding boxes, respectively. Grayed approaches predict most of the image as artifacts and are only for reference, not included in the comparison.
| Method | Date | Params | SynthScars | LOKI | ||
| ROUGE-L | CSS | ROUGE-L | CSS | |||
| Qwen2-VL [53] | 24.09 | 72B | 25.84 | 58.15 | 11.80 | 37.64 |
| LLaVA-v1.6 [31] | 24.01 | 7B | 29.61 | 61.75 | 16.07 | 41.07 |
| InternVL2 [7] | 24.07 | 8B | 25.93 | 56.89 | 10.10 | 39.62 |
| Deepseek-VL2 [57] | 24.12 | 27B | 25.50 | 47.77 | 6.70 | 28.76 |
| GPT-4o [19] | 24.12 | - | 22.43 | 53.55 | 9.61 | 38.98 |
| LEGION (Ours) | 25.03 | 8B | 39.50 | 72.60 | 18.55 | 45.96 |
🔼 Table 3 presents a comparison of various multimodal models’ performance in generating artifact explanations for synthetic images. The models are evaluated using two metrics: ROUGE-L, assessing lexical overlap and semantic similarity, and Cosine Similarity Score (CSS), measuring the semantic similarity between generated explanations and ground truth. Scores are normalized to a 0-100 range for easier visual comparison and understanding. The table allows for a direct assessment of how effectively these different models can provide detailed and accurate textual descriptions of identified image artifacts.
read the caption
Table 3: Comparison of Multimodal Models in Artifact Explanation Generation. Metrics are normalized to the range of 0–100 for better visualization and comparison.
| HPS | Regeneration | Inpainting |
| Pre-refined Score (Avg.) | 31.24 | 29.57 |
| Post-refined Score (Avg.) | 33.36 | 30.20 |
| Growth Rate | 6.98% | 2.14% |
🔼 This table presents a comparison of Human Preference Scores (HPS) for image quality before and after applying image refinement techniques. Specifically, it shows the average HPS for images before refinement, after regeneration-based refinement, and after inpainting-based refinement. The HPS values are normalized to a 0-100 scale for easier comparison. The growth rate (percentage increase) in the average HPS after refinement is also provided, highlighting the effectiveness of the refinement methods in improving image quality.
read the caption
Table 4: HPS Comparison Before and After Refinement in Regeneration and Inpainting. Scores are normalized to the range of 0–100 for better visualization and comparison.
| Method | GANs | Deepfakes | Perceptual Loss | Low Level Vision | Diffusion | ||
| CRN | IMLE | SITD | SAN | ||||
| Co-occurence [35] | 75.17 | 59.14 | 73.06 | 87.21 | 68.98 | 60.42 | 85.53 |
| Freq-spec [68] | 75.28 | 45.18 | 53.61 | 50.98 | 47.46 | 57.12 | 69.00 |
| CNNSpot [54] | 85.29 | 53.47 | 86.31 | 86.26 | 66.67 | 48.69 | 58.63 |
| Patchfor [4] | 69.97 | 75.54 | 72.33 | 55.30 | 75.14 | 75.28 | 72.54 |
| UniFD [38] | 95.25 | 66.60 | 59.50 | 72.00 | 63.00 | 57.50 | 82.02 |
| LDGard [46] | 89.17 | 58.00 | 50.74 | 50.78 | 62.50 | 50.00 | 89.79 |
| FreqNet [47] | 94.23 | 97.40 | 71.92 | 67.35 | 88.92 | 59.04 | 83.34 |
| NPR [48] | 94.16 | 76.89 | 50.00 | 50.00 | 66.94 | 98.63 | 94.54 |
| LEGION (Ours) | 97.01 | 63.37 | 90.78 | 98.93 | 79.44 | 57.76 | 83.10 |
🔼 This table presents a comparison of various methods for synthetic image detection, evaluated on the UniversalFakeDetect benchmark. The performance of each method is shown across different generative models (GANs, CRN, IMLE, SITD, SAN, and SAS). All the models listed in the table were trained using ProGAN. This allows for an assessment of generalization capabilities of different approaches in detecting synthetic images generated from various sources.
read the caption
Table 5: Comparison of Synthetic Image Detection on UniversalFakeDetect Benchmark. All methods are trained on ProGAN.
| Image Content | Human | Object | Animal | Scene | Total |
| Train | 6253 | 1940 | 1183 | 1860 | 11236 |
| Test | 587 | 162 | 134 | 117 | 1000 |
| Total | 6840 | 2102 | 1317 | 1977 | 12236 |
🔼 Table 6 presents a statistical overview of the SynthScars dataset, highlighting the diversity of its image content. It shows the distribution of 12,236 fully synthetic images across four categories: Human, Object, Animal, and Scene. The numbers indicate the count of images in each category within the training and test sets, and the total number across both sets. This table is crucial in demonstrating the comprehensiveness and realism of the SynthScars dataset, which includes images generated from various sources. The dataset’s broad representation of real-world scenarios enhances its suitability for training robust and generalized synthetic image detection models.
read the caption
Table 6: Statistics on Image Content. SynthScars encompasses a diverse range of real-world scenarios, including 12,236 fully synthesized images from different generators.
| Artifact Type | Physics | Distortion | Structure | Total |
| Train | 1431 | 1249 | 21233 | 23913 |
| Test | 111 | 136 | 2406 | 2653 |
| Total | 1542 | 1385 | 23639 | 26566 |
🔼 Table 7 presents a detailed breakdown of artifact types within the SynthScars dataset. It shows the number of instances for each of the three fine-grained anomaly categories (Physics, Distortion, and Structure) in both the training and testing sets, totaling 26,566 artifact instances across the entire dataset. This table highlights the diversity and granularity of the annotations in SynthScars, emphasizing its value for evaluating and developing robust synthetic image detection models.
read the caption
Table 7: Statistics on Artifact Types. SynthScars classifies artifacts into three fine-grained anomaly types, and contains a total of 26,566 artifact instances.
| Artifact Definition | |
| 1. Physics (a) Optical Display: These artifacts arise from inconsistencies in the propagation and reflection of light, violating fundamental optical principles. They can occur across different objects and scenes, leading to unrealistic visual effects. Common cases include incorrect reflections, shadows, and light source positioning errors, causing synthetic images to deviate from real-world optical phenomena. (b) Physical Law Violations: These artifacts result from the failure to adhere to fundamental physical laws during image synthesis. They typically manifest as illogical scenes, such as water flowing upward or objects floating in mid-air, which contradict natural laws. (c) Space and Perspective: These artifacts stem from inaccuracies in object proportions and spatial relationships during image generation, leading to inconsistencies with real-world perspective rules. Examples include incorrect depth perception, mismatched object sizes, or spatial distortions that prevent accurate perspective alignment. 2. Structure (a) Deformed Objects: These artifacts arise when the shape or structure of objects is distorted due to errors in the generative model. Contributing factors include geometric inconsistencies, texture mapping errors, and rendering issues. (b) Asymmetrical Objects: These artifacts occur when an object exhibits unnatural asymmetry, deviating from expected structural balance. (c) Incomplete/Redundant Structures: These artifacts appear as missing or excessive structural components, leading to unrealistic representations of objects. (d) Illogical Structures: These artifacts involve the generation of unrecognizable or non-existent objects, as well as the appearance of elements that should not logically exist within the given context. (e) Text Distortion and Illegibility: These artifacts include warped, irregular, or unrecognizable text, affecting the readability and coherence of textual content within the generated image. 3. Distortion (a) Color and Texture: These artifacts result from errors in color rendering or color space conversion, leading to unnatural hues, inappropriate saturation, or other inconsistencies in color perception. (b) Noise and Blurring: These artifacts are associated with image noise reduction and clarity enhancement processes. They may arise when algorithms fail to effectively remove noise or introduce excessive blurring, causing local details to appear distorted or unnatural. (c) Artistic Style: These artifacts occur when synthetic images exhibit unintended stylization, such as cartoonish or painterly appearances that deviate from realistic textures. Such distortions are often caused by errors in style transfer or texture generation algorithms. |
🔼 This table presents a robustness analysis of the LEGION model and its competitor, PAL4VST, against various image distortions. The distortions applied include JPEG compression at different quality factors (QF), Gaussian noise with varying standard deviations (σ), and Gaussian blur with different kernel sizes (Ksize). The table shows the performance (mIoU and F1 score) of both models under each distortion level. The values in parentheses represent the percentage change in performance relative to the original, undistorted image. The model with a more robust performance under each distortion is highlighted in green, while the less robust one is in red. The results demonstrate LEGION’s superior robustness to various image perturbations compared to the expert model PAL4VST.
read the caption
Table 10: Robustness Comparison Under Different Perturbations. LEGION significantly outperforms the strongest existing expert model under severe JPEG compression (denoted as JPEG Comp.), Gaussian noise, and Gaussian blur (Ksize represents kernel size). Values in parentheses indicate degradation ratios, with the more robust method highlighted in green, otherwise in red.
Full paper#