TL;DR#
Triangle meshes are essential in 3D applications. Existing auto-regressive methods, which generate structured meshes by predicting vertex tokens, often face limitations in face counts and mesh completeness. Moreover, these methods struggle with aligning outputs with human aesthetic preferences, leading to geometric inaccuracies and a lack of artistic refinement. These challenges hinder the creation of high-quality, artist-like 3D meshes.
To address these issues, this paper presents a framework that optimizes mesh generation through two key innovations. First, an efficient pre-training strategy incorporates a novel tokenization algorithm. Second, Reinforcement Learning (RL) is introduced into 3D mesh generation, achieving human preference alignment via Direct Preference Optimization (DPO). With a scoring standard combining human evaluation and 3D metrics, the framework generates detailed, precise meshes, outperforming existing methods in precision and quality.
Key Takeaways#
Why does it matter?#
This research introduces a novel approach to 3D mesh generation with human-aligned artistry, offering new methods for geometric detail & visual appeal. It opens avenues for exploring RL in generative modeling & artistic mesh creation.
Visual Insights#

🔼 This figure showcases a variety of 3D meshes generated by the DeepMesh model. Each mesh is conditioned on a given point cloud as input, demonstrating the model’s ability to efficiently create aesthetically pleasing, artist-quality meshes from this sparse input data. The variety of the meshes highlights DeepMesh’s capabilities in producing diverse, high-fidelity results.
read the caption
Figure 1: Gallery of DeepMesh’s generation results. DeepMesh efficiently generates aesthetic, artist-like meshes conditioned on the given point cloud.
| Metrics | C.Dist. | H.Dist. | User Study |
|---|---|---|---|
| MeshAnythingv2 [6] | 0.1249 | 0.2991 | 10% |
| BPT [67] | 0.1425 | 0.2796 | 19% |
| Ours w/o DPO | 0.1001 | 0.1861 | 34% |
| Ours w DPO | 0.0884 | 0.1708 | 37% |
🔼 This table presents a quantitative comparison of DeepMesh against other state-of-the-art baselines for 3D mesh generation. The metrics used likely assess the geometric accuracy (e.g., Chamfer Distance, Hausdorff Distance) and the visual quality (e.g., user study scores) of the generated meshes. Lower Chamfer and Hausdorff distances indicate better geometric fidelity to the ground truth. Higher user study scores represent better subjective visual appeal. The results demonstrate DeepMesh’s superior performance in both geometric accuracy and visual quality compared to the competing methods.
read the caption
Table 1: Quantitative comparison with other baselines. Our method outperforms other baselines in generated geometry and visual quality.
In-depth insights#
Mesh Tokenization#
Mesh tokenization is crucial for enabling transformer-based models to process 3D meshes. Efficient tokenization schemes aim to reduce sequence length, thereby decreasing computational cost and memory requirements. The key challenge involves balancing compression ratio with preserving geometric details and maintaining manageable vocabulary size. Effective algorithms typically employ techniques like face traversal, vertex quantization, and hierarchical indexing to represent meshes as discrete tokens suitable for auto-regressive modeling. Optimizing tokenization enhances training efficiency and enables the generation of high-resolution, artist-like meshes, addressing limitations in face counts and mesh completeness often encountered in existing methods.
DPO for 3D Mesh#
Direct Preference Optimization (DPO) has emerged as a promising technique for aligning generative models with human preferences, showing success in language models and vision-language models. Applying DPO to 3D mesh generation could significantly improve the aesthetic quality and geometric accuracy of generated meshes. This involves collecting preference data where humans evaluate pairs of meshes and select the preferred one based on visual appeal and geometric correctness. A key challenge is designing a scoring standard that effectively captures human preferences for 3D meshes, potentially combining subjective visual assessments with objective 3D metrics like Chamfer distance and mesh quality metrics. Overcoming these challenges could lead to a new state-of-the-art in 3D mesh generation.
Pre-Training Refined#
Refining pre-training is crucial for auto-regressive models. A refined pre-training phase could involve several key aspects. Firstly, it’s about the data: curating a high-quality dataset is essential, filtering out noisy or incomplete meshes and prioritizing those with clean geometry and topology. Then there’s the tokenization process. An efficient tokenization scheme could reduce sequence length without sacrificing geometric detail, leading to faster training and reduced memory consumption. Efficient tokenization allows us to use high-resolution meshes for training. A refined pre-training strategy ensures better initial weights, leading to faster convergence and improved final performance in downstream tasks like generating artist-like meshes.
Data Curation Vital#
Data curation is vital because the quality of training data fundamentally governs model performance. In the context of 3D mesh generation, existing datasets often exhibit high variability in quality, including irregular topology, excessive fragmentation, or extreme geometric complexity. Addressing these issues through data curation is essential to mitigate potential problems such as unstable training, loss spikes, and compromised model generalization. A well-designed data curation strategy can filter out poor-quality meshes based on geometric structure and visual fidelity. This ensures that the model is trained on a high-quality dataset, leading to more stable training and superior mesh generation results. By focusing on clean, representative data, the model can learn more effectively and avoid being misled by noisy or incomplete examples. This enhances the overall reliability and performance of the 3D mesh generation process.
Scalable Artist Mesh#
The concept of “Scalable Artist Mesh” is intriguing, suggesting a method to create 3D meshes that maintain artistic quality while scaling efficiently. This could involve novel mesh representations, tokenization, or procedural generation techniques. A key challenge would be balancing artistic control and computational cost, possibly using hierarchical structures or adaptive mesh refinement. Another aspect involves training data - the quality and size of artist-created meshes significantly impact the model’s ability to learn and generate aesthetically pleasing results. Reinforcement learning to align outputs with human preferences could play a role, as could data curation techniques to improve the quality of training examples.
More visual insights#
More on figures

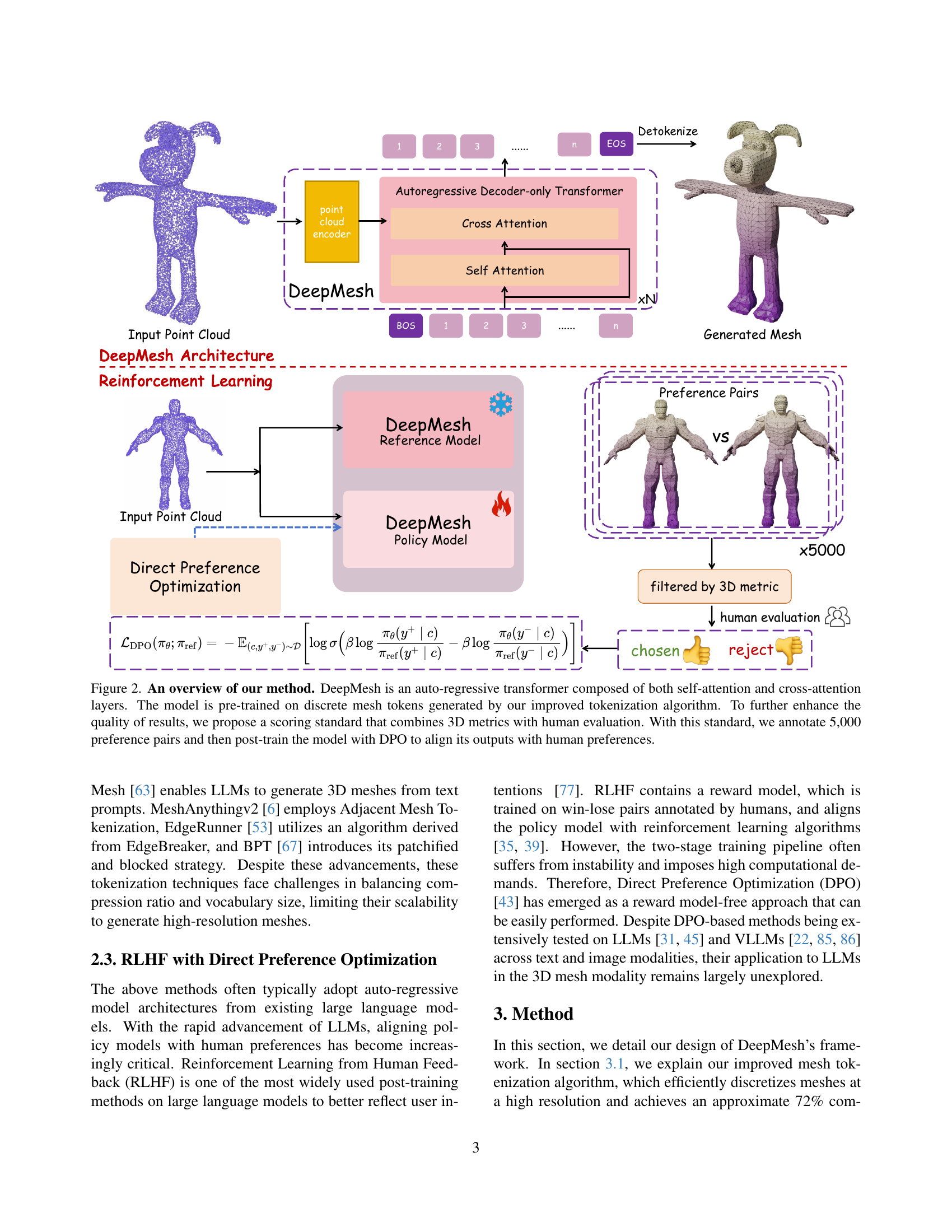
🔼 This figure illustrates the DeepMesh architecture and training process. DeepMesh uses an autoregressive transformer with self-attention and cross-attention layers to generate meshes. The model is first pre-trained using a novel tokenization algorithm on discrete mesh tokens. Then, a scoring system that combines 3D metrics with human evaluation is used to create 5000 preference pairs. Finally, the model is fine-tuned with Direct Preference Optimization (DPO) using these preference pairs to better align the generated meshes with human preferences.
read the caption
Figure 2: An overview of our method. DeepMesh is an auto-regressive transformer composed of both self-attention and cross-attention layers. The model is pre-trained on discrete mesh tokens generated by our improved tokenization algorithm. To further enhance the quality of results, we propose a scoring standard that combines 3D metrics with human evaluation. With this standard, we annotate 5,000 preference pairs and then post-train the model with DPO to align its outputs with human preferences.

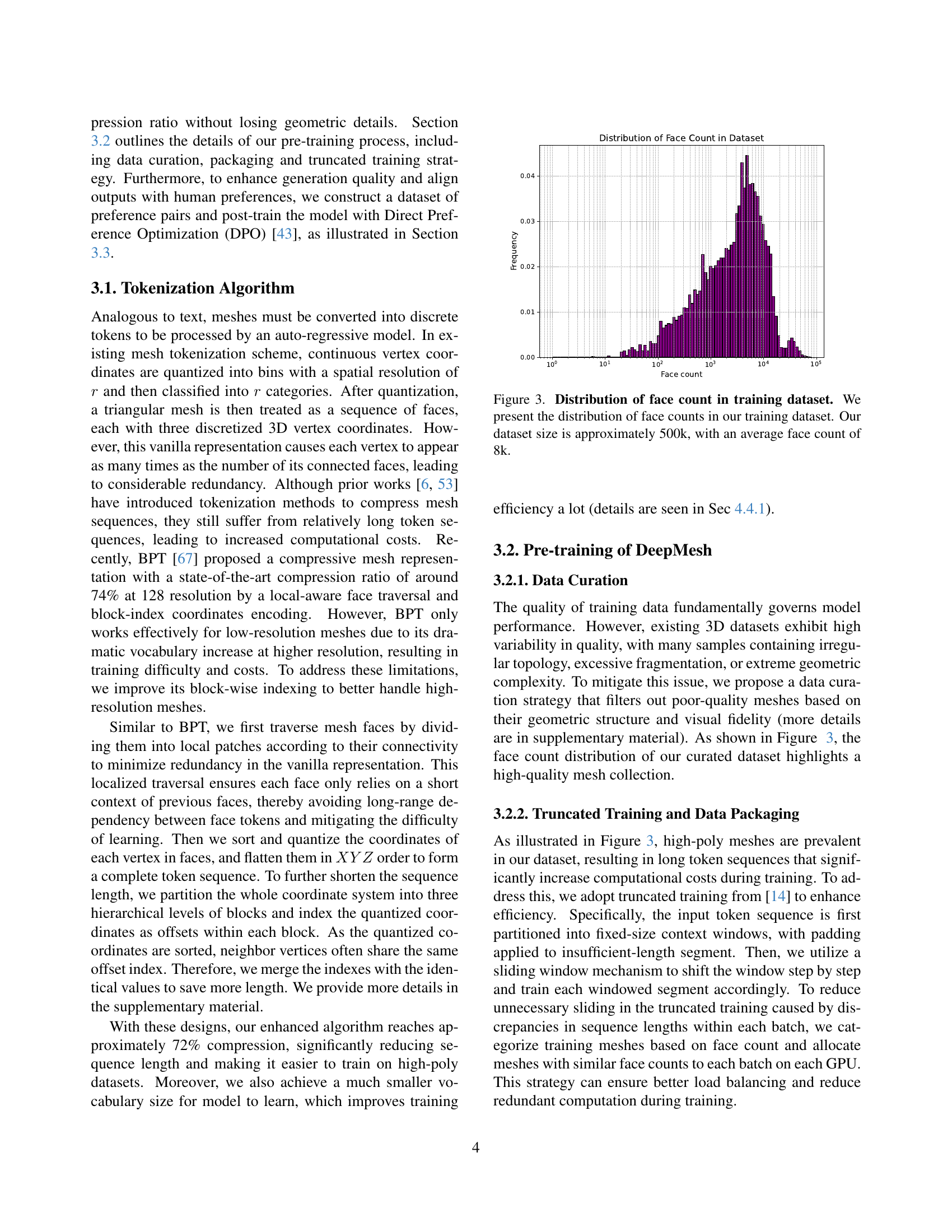
🔼 This histogram displays the distribution of polygon face counts within the DeepMesh training dataset. The x-axis represents the number of faces per mesh, and the y-axis shows the frequency of meshes with that face count. The dataset comprises approximately 500,000 meshes, with an average of 8,000 faces per mesh. This visualization highlights the prevalence of high-polygon meshes in the dataset, which is important to note for model training.
read the caption
Figure 3: Distribution of face count in training dataset. We present the distribution of face counts in our training dataset. Our dataset size is approximately 500k, with an average face count of 8k.

🔼 This figure displays examples from a dataset of mesh preference pairs used in training the DeepMesh model. Each row shows a pair of generated meshes, one preferred and one rejected. The preference annotations are based on three key aspects: how complete the mesh geometry is (geometry completeness), the level of detail in the mesh’s surface (surface details), and how clean and well-organized the mesh’s wireframe is (wireframe structure). This dataset helps train the model to generate more aesthetically pleasing meshes that satisfy human preferences.
read the caption
Figure 4: Some examples of the collected preference pairs. We annotate the preferred meshes based on their geometry completeness, surface details and wireframe structure.

🔼 Figure 5 presents a qualitative comparison of point cloud-conditioned mesh generation results between DeepMesh and several baseline methods. The figure shows that DeepMesh generates meshes with superior geometric accuracy and preservation of fine details compared to other methods. A key observation is that DeepMesh produces meshes with a significantly higher number of faces, suggesting a greater level of detail and complexity.
read the caption
Figure 5: Qualitative comparison on point cloud conditioned generation between DeepMesh and baselines. DeepMesh outperforms baselines in both generated geometry and preservation of fine-grained details. The meshes generated by ours have much more faces than others.
🔼 This figure showcases examples of 3D meshes generated by the DeepMesh model when conditioned on input images. The results demonstrate the model’s capability to generate high-fidelity meshes that accurately reflect the details and overall structure present in the original images, showcasing a strong alignment between the input image and generated 3D mesh.
read the caption
Figure 6: Image-conditioned generation results of our method. Our method can generate high-fidelity meshes aligned with the input images.

🔼 Given the same input point cloud, DeepMesh demonstrates its ability to generate a variety of meshes with different appearances, showcasing its capacity for creative and diverse output.
read the caption
Figure 7: Diversity of generations. DeepMesh can generate meshes with diverse appearance given the same point cloud.

🔼 This ablation study compares mesh generation results with and without Direct Preference Optimization (DPO). Both methods produce meshes with good geometric accuracy. However, the image clearly shows that meshes generated with DPO are aesthetically more pleasing and visually appealing, demonstrating the effectiveness of DPO in enhancing the visual quality of the generated meshes.
read the caption
Figure 8: Ablation study on the effectiveness of DPO. We can observe that while both approaches yield excellent geometry, the results generated using DPO are more visually appealing.

🔼 This figure details a novel mesh tokenization algorithm. The process begins by traversing the mesh faces, grouping them into connected patches. Each vertex within these patches is then quantized into one of 512 discrete values. The entire coordinate system is divided into a three-level hierarchy of blocks, and each quantized coordinate is represented as an offset within its block. Finally, to further reduce the length of the token sequence, identical offsets for neighboring vertices are merged.
read the caption
Figure 9: Details of our tokenization algorithm. We first traverse mesh faces by dividing them into patches according to their connectivity and quantize each vertex of faces into r𝑟ritalic_r bins (in our setting r=512𝑟512r=512italic_r = 512).Then we partition the whole coordinate system into three hierarchical levels of blocks and index the quantized coordinates as offsets within each block. We merge the index of neighbor vertices if they have the identical values.

🔼 This figure compares the training efficiency of DeepMesh’s novel tokenization algorithm against existing methods (AMT, EdgeRunner, BPT). The experiment involved integrating each algorithm into the same model architecture and training on a dataset containing 80 meshes per face count category (10K, 20K, 30K, 40K faces). The results demonstrate that DeepMesh’s tokenization method consistently achieves the fastest training times across all face count categories, highlighting its superior training efficiency.
read the caption
Figure 10: Comparison with other tokenization algorithms in training effciency. We integrate all tokenization algorithms into our model architecture and train them on a dataset of 80 meshes for each face count category (10K, 20K, 30K, 40K). Our method achieves the fastest training time across all face count categories, demonstrating superior training efficiency.

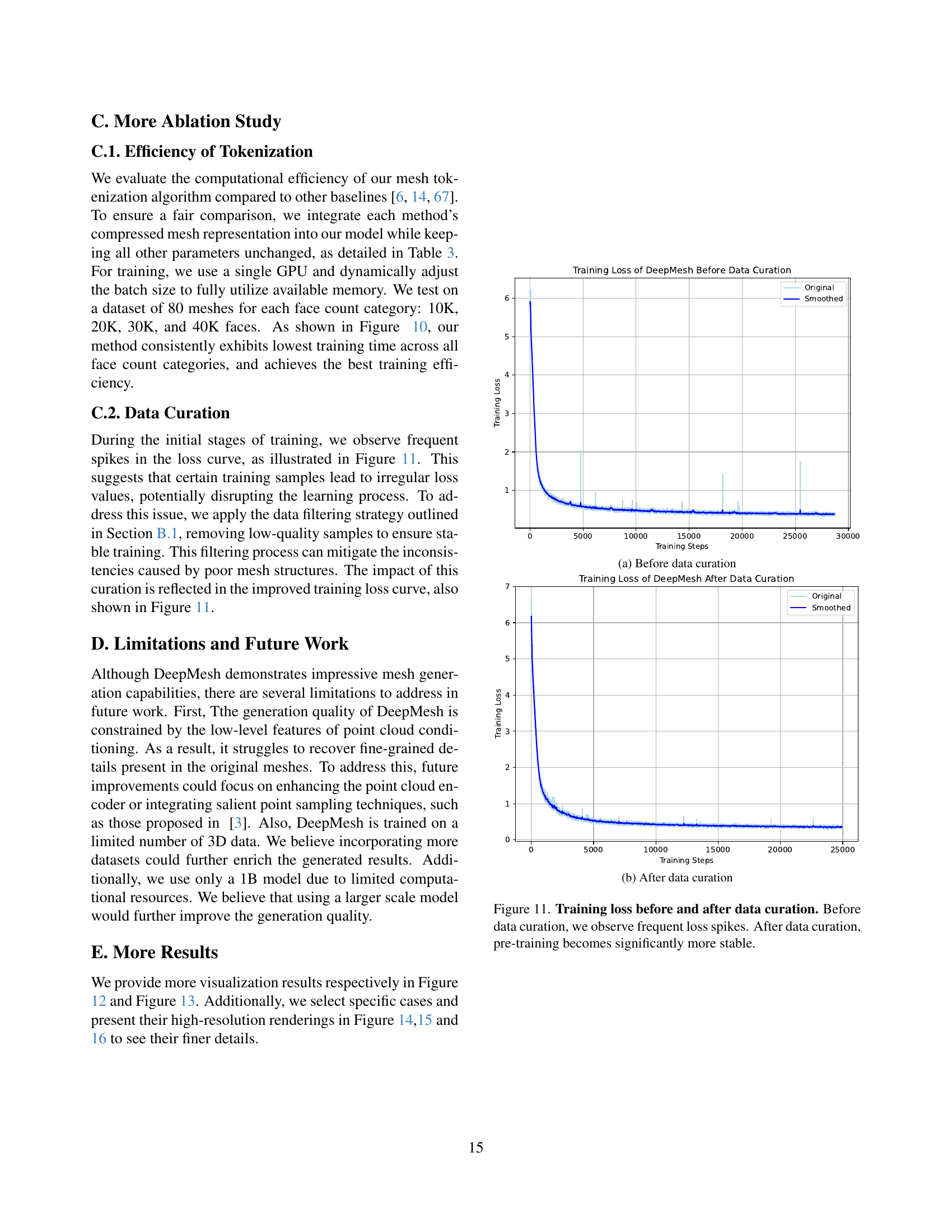
🔼 The figure shows the training loss curves before and after data curation. Before data curation, the loss curve exhibits frequent spikes, indicating instability in the training process due to low-quality data samples. After data curation, where low-quality samples were removed, the training loss curve becomes significantly more stable, highlighting the positive effect of data curation on the training process.
read the caption
(a) Before data curation

🔼 This figure shows the impact of data curation on the training process of the DeepMesh model. The graph displays the training loss over time, comparing the original training data (before curation) with the curated dataset (after curation). The graph demonstrates that the training process is significantly more stable after the data curation step, as indicated by the reduced frequency and magnitude of loss spikes in the loss curve.
read the caption
(b) After data curation

🔼 This figure shows a comparison of training loss curves before and after data curation. The graph on the left (before data curation) displays frequent and significant spikes in the loss, indicating instability in the training process. This instability likely results from the inclusion of noisy or low-quality data in the training set. The graph on the right (after data curation) shows a much smoother and stable loss curve. The data curation process removed problematic data points, leading to a more consistent and stable model training process. The smoother curve indicates that the model is learning more effectively and consistently without the disruptions caused by the poor-quality data.
read the caption
Figure 11: Training loss before and after data curation. Before data curation, we observe frequent loss spikes. After data curation, pre‑training becomes significantly more stable.

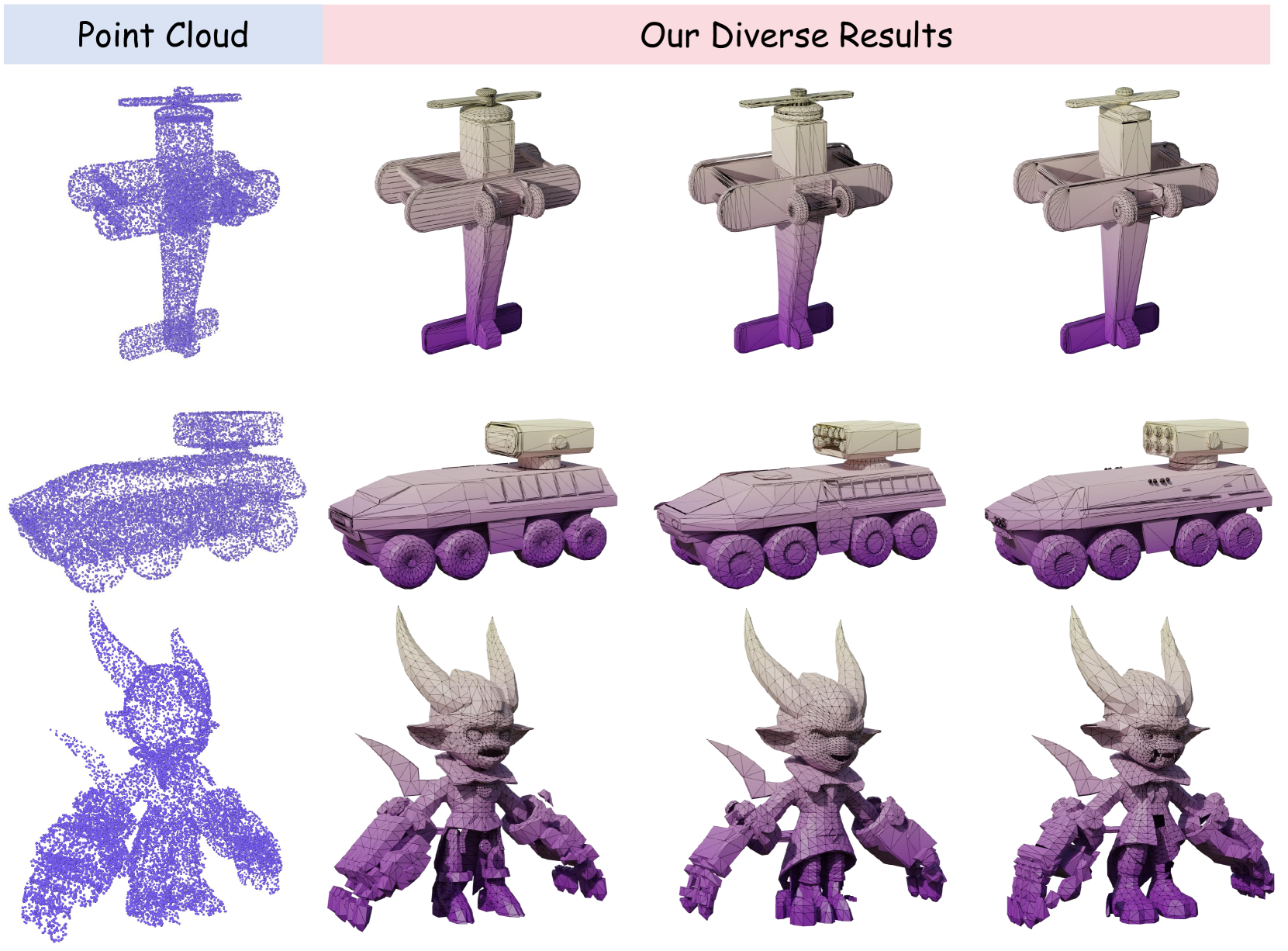
🔼 Figure 12 showcases additional examples of 3D meshes generated by the DeepMesh model. These examples highlight the model’s ability to generate high-fidelity, detailed meshes across a range of object categories and styles. The variety of objects demonstrates the model’s versatility and capacity to handle complex geometries. Each mesh is presented as a wireframe rendering, clearly showing the intricate detail and topology of the generated models.
read the caption
Figure 12: More results of DeepMesh. We present more high-fidelity results generated by our method.

🔼 Figure 13 showcases additional high-quality 3D meshes generated by the DeepMesh model. These examples demonstrate the model’s ability to create detailed and aesthetically pleasing meshes across a variety of object categories, highlighting its capacity for generating complex and intricate 3D structures.
read the caption
Figure 13: More results of DeepMesh. We present more high-fidelity results generated by our method.

🔼 This figure showcases high-resolution renderings of 3D meshes generated by the DeepMesh model. The detailed view highlights the model’s capability to create intricate and realistic surface details, demonstrating the effectiveness of the proposed method in generating high-quality, artist-like 3D assets.
read the caption
Figure 14: High resolution results of our generated meshes.
More on tables
| Metrics | AMT | EdgeRunner | BPT | Ours |
|---|---|---|---|---|
| Comp Ratio | 0.46 | 0.47 | 0.26 | 0.28 |
| Vocal Size | 512 | 512 | 40960 | 4736 |
| Time (s) | 816 | - | 540 | 480 |
🔼 This table compares the performance of four different mesh tokenization algorithms: the proposed method and three existing methods (AMT, EdgeRunner, BPT). The comparison focuses on three key metrics: compression ratio (lower is better, indicating more efficient data representation), vocabulary size (smaller is better, implying faster training), and training time (shorter is better, representing higher computational efficiency). The results demonstrate that the proposed algorithm significantly outperforms the existing methods in all three metrics, achieving the lowest compression ratio, the smallest vocabulary size, and the fastest training time, showcasing its superior efficiency and compactness for mesh processing.
read the caption
Table 2: Quantitative comparison with other tokenization algorithms. Our improved tokenization algorithm achieves a low compression ratio, a small vocabulary size, and the highest computational efficiency, making it both compact and highly efficient for mesh processing.
| Small scale | Large scale | |
| Parameter count | 500 M | 1.1B |
| Batch Size | 9 | 5 |
| Layers | 21 | 20 |
| Heads | 10 | 14 |
| 1280 | 1792 | |
| 5120 | 7168 | |
| Learning rate | ||
| LR scheduler | Cosine | Cosine |
| Weight decay | 0.1 | 0.1 |
| Gradient Clip | 1.0 | 1.0 |
🔼 This table details the architecture and training hyperparameters used for both the small-scale and large-scale versions of the DeepMesh model. It shows the parameter count, batch size, number of layers, number of heads, hidden dimension size (d_model), feed-forward network dimension size (d_FFN), learning rate, learning rate scheduler, weight decay, and gradient clipping used during training. These specifications provide a comprehensive overview of the model’s configuration and training process.
read the caption
Table 3: Deepmesh’s architectural and training details.
Full paper#