TL;DR#
Existing text-conditioned streaming motion generation methods struggle with online response and long-term error accumulation. Diffusion models are limited by pre-defined motion lengths. GPT-based methods suffer from delayed responses and non-causal tokenization hinders performance. Thus, there’s a need for continuous, causally-aware models that can adapt to real-time text input while maintaining motion coherence and minimizing errors.
To address these issues, this paper presents MotionStreamer, a novel framework that uses a continuous causal latent space within a probabilistic autoregressive model. This mitigates information loss and reduces error accumulation. A causal motion compressor enables online decoding. Two new training strategies: Two-Forward training and Mixed training, address error accumulation and improve compositional learning. The method achieves SOTA performance and supports multi-round generation and dynamic motion composition.
Key Takeaways#
Why does it matter?#
This paper introduces a novel approach to streaming motion generation, enabling more realistic and responsive virtual characters. It has potential for real-time applications like games and robotics. The method of continuous causal latent space opens new avenues for research, potentially improving other generative tasks. It also provides benchmarks and downstream applications that can lead to further investigations.
Visual Insights#

🔼 This figure visualizes the process of online motion generation. The system receives text input incrementally, meaning one word or phrase at a time, rather than a complete sentence or paragraph. As each piece of text is added, the model generates the corresponding portion of the motion sequence. The five depicted poses illustrate how the model adapts to changes in text, creating a continuous, flowing motion that accurately reflects the text’s meaning. This continuous update of both the text input and motion output is a key aspect of the ‘streaming’ approach.
read the caption
Figure 1: Visualization of streaming motion generation process. Texts are incrementally inputted and motions are generated online.
| Methods | FID | R@1 | R@2 | R@3 | MM-D | Div |
|---|---|---|---|---|---|---|
| Real motion | 0.002 | 0.711 | 0.851 | 0.903 | 15.805 | 27.670 |
| MDM [53] | 22.557 | 0.524 | 0.693 | 0.773 | 17.223 | 27.355 |
| MLD [9] | 17.226 | 0.548 | 0.732 | 0.805 | 16.338 | 26.551 |
| T2M-GPT [60] | 11.175 | 0.608 | 0.772 | 0.831 | 16.810 | 27.617 |
| MotionGPT [26] | 14.175 | 0.436 | 0.598 | 0.668 | 17.890 | 27.014 |
| MoMask [19] | 10.731 | 0.622 | 0.782 | 0.850 | 16.128 | 27.317 |
| AttT2M [64] | 15.438 | 0.590 | 0.767 | 0.837 | 15.734 | 26.680 |
| Ours | 10.724 | 0.631 | 0.784 | 0.851 | 16.639 | 27.657 |
🔼 Table 1 presents a quantitative comparison of MotionStreamer against several existing text-to-motion generation methods. The evaluation was performed on the HumanML3D [17] test set, using a variety of metrics to assess both the quality and diversity of generated motion sequences. These metrics include FID (Frechet Inception Distance), which measures the similarity of generated motion distributions to real ones, R@k (Recall@k), indicating the top k retrieval accuracy of generated motions, MM-Dist (Multimodal Distance) showing the alignment between generated motion features and text features, and Div (Diversity), quantifying the diversity of generated motions.
read the caption
Table 1: Comparison with baseline text-to-motion generation methods on HumanML3D [17] test set. MM-D and Div denote MM-Dist and Diversity respectively.
In-depth insights#
Causal Latents#
Causal latents represent a significant advancement in sequence modeling, particularly for tasks requiring temporal coherence and online processing. Unlike traditional latent spaces that might treat each element in a sequence independently, causal latents explicitly encode temporal dependencies, ensuring that the latent representation at any given time step only depends on past information. This causality is crucial for applications like streaming generation, where future context is unavailable. The use of continuous causal latents mitigates information loss associated with discrete tokenization methods. By avoiding discretization, the model preserves fine-grained details and reduces error accumulation during long-term generation. Moreover, enforcing causality in the latent space allows for online decoding, enabling real-time responses to sequential inputs.
Online Response#
Online response in motion generation implies real-time or near-real-time generation of human motions based on textual prompts. This is essential for interactive applications such as games and robotics. Achieving low latency is crucial, necessitating efficient architectures that minimize processing time. Traditional methods using discrete tokenization and full sequence decoding often struggle with online response due to delays in processing and decoding. Solutions involve causal models that can generate motions incrementally, leveraging continuous latent spaces to avoid information loss and reduce error accumulation. Techniques to reduce ‘First-frame Latency’ are also significant in evaluating the system. Additionally, strategies like Two-Forward Training and Mixed Training mitigate error accumulation, further improving the quality and stability of generated motions for online interactive scenarios.
Error Reduction#
In addressing error reduction in streaming motion generation, several key areas need focus. First, continuous latent spaces can mitigate information loss inherent in discrete tokenization, a common source of error in autoregressive models. By maintaining continuous representations, the model avoids the accumulation of quantization errors over long sequences, leading to more coherent and stable motion generation. Temporal causal dependencies are crucial; establishing these dependencies allows the model to effectively integrate historical motion data with incoming textual conditions, enhancing the accuracy of online motion decoding. This involves designing architectures that explicitly model temporal causality, such as the proposed Causal Temporal AutoEncoder (Causal TAE), which ensures that predictions only depend on past information. Finally, training strategies play a vital role. Two-forward training and mixed training methodologies can mitigate exposure bias and improve generalization by blending ground truth and predicted motion latents during training. Mixed training combines atomic and contextual data to learn compositional semantics and handle diverse motion combinations, further reducing error accumulation and improving overall performance.
Mix Training#
The ‘Mix Training’ approach addresses a critical challenge in streaming motion generation: seamlessly transitioning between atomic (isolated text-motion pairs) and contextual data (text, history motion, and current motion triplets). By unifying these two types of training examples, the model learns to leverage both immediate text cues and long-range dependencies, potentially enhancing semantic consistency and generalization to unseen motion combinations. This integration likely involves carefully balancing the contribution of each data type during training, perhaps using a weighting scheme or curriculum learning approach. The core benefit lies in its ability to foster compositional semantics learning, meaning the model becomes proficient in assembling motion sequences from diverse sources, ultimately leading to more robust and versatile performance in real-world streaming scenarios. This is especially crucial where motion is interactively directed, and actions shift fluidly.
Stopping Cond.#
The document addresses the challenge of determining when to stop generating motion in a streaming fashion. This is crucial for avoiding the generation of unrealistic or nonsensical movements beyond the intended action, a problem particularly relevant in scenarios with variable-length inputs. The document proposes a novel approach by embedding an “impossible pose”, essentially a null state, into the latent space. The distance between the generated motion latent and this reference end latent serves as the criterion. A threshold is defined, and when the distance falls below it, the generation halts. This eliminates the need for a separate binary classifier and mitigates class imbalance issues. This approach allows for more nuanced control over generation length and avoids abrupt, unnatural stops. Further investigation might explore adaptive threshold based on text input.
More visual insights#
More on figures

🔼 MotionStreamer processes text input and previous motion information using an autoregressive (AR) model to predict the next motion latent in a streaming fashion. This prediction is continuously updated with new text inputs and previous motion. A diffusion head helps refine the latent representation. The predicted latent is instantly decoded to generate a frame of the motion sequence, allowing for online motion generation. The figure shows both the overall streaming process (a) and a detailed view of the AR model with the diffusion head (b).
read the caption
Figure 2: Overview of MotionStreamer. During inference, the AR model streamingly predicts next motion latents conditioned on the current text and previous motion latents. Each latent can be decoded into motion frames online as soon as it is generated.

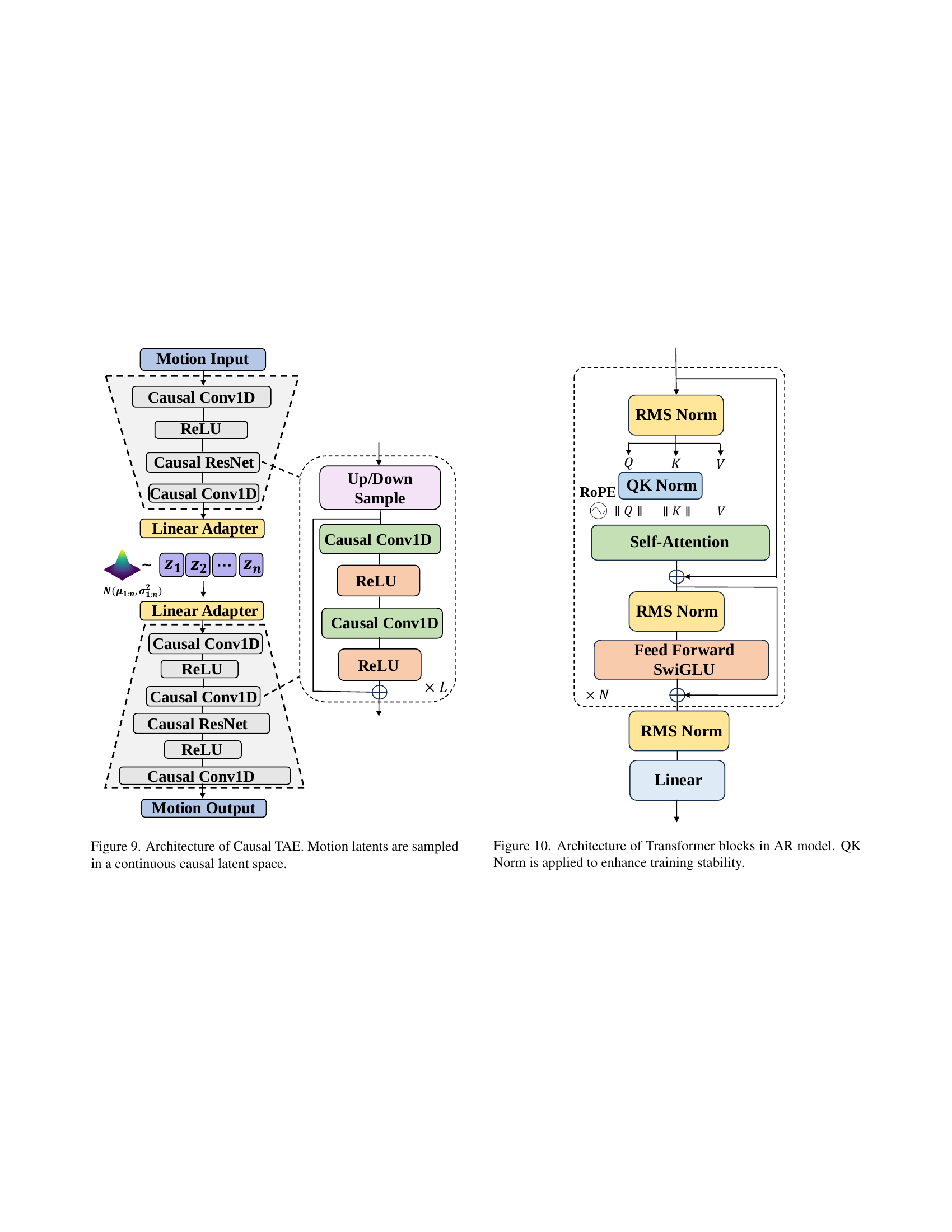
🔼 The figure illustrates the architecture of the Causal Temporal Autoencoder (Causal TAE), a key component of the MotionStreamer framework. It shows a network with both a causal encoder and a causal decoder. The encoder takes in raw motion sequences as input and transforms them into a continuous latent space representation, using 1D causal convolutions. These 1D causal convolutions ensure that only past data influences the representation of the current time step, respecting the temporal causality of motion data. The decoder then takes the generated latents and reconstructs the motion sequence. The resulting continuous latent representations (z1:n) are crucial for mitigating information loss and error accumulation during streaming motion generation.
read the caption
Figure 3: Architecture of Causal TAE. 1D temporal causal convolution is applied in both the encoder and decoder. Variables z1:nsubscript𝑧:1𝑛z_{1:n}italic_z start_POSTSUBSCRIPT 1 : italic_n end_POSTSUBSCRIPT are sampled as continuous motion latent representations.

🔼 Figure 4 illustrates the first-frame latency for various motion generation methods. The x-axis shows the number of frames generated, and the y-axis shows the time (in seconds) it took each method to produce its very first frame. This metric is crucial for evaluating the speed and responsiveness of real-time motion generation, particularly in streaming scenarios where immediate feedback is essential. The figure clearly demonstrates the significant performance advantage of MotionStreamer (Causal TAE) in terms of producing the initial frame much faster than other models, highlighting the efficiency of its causal approach.
read the caption
Figure 4: Comparison on the First-frame Latency of different methods. The horizontal axis represents the number of generated frames, while the vertical axis indicates the time required to produce the first output frame.

🔼 Figure 5 presents a comparison of MotionStreamer’s motion generation capabilities against several baseline methods (T2M-GPT [60], MoMask [19], AttT2M [64], and FlowMDM [4]). The figure is structured in three rows, each demonstrating a different aspect of motion generation. The first row showcases text-to-motion generation, comparing how accurately each method translates a single text prompt into a corresponding motion sequence. The second row focuses on long-term motion generation, where a series of text descriptions are used to generate a longer, continuous motion. This row highlights each algorithm’s ability to maintain coherence and context across multiple text inputs. Finally, the third row shows dynamic motion composition. In this scenario, multiple, short motion sequences are combined in response to different prompts, demonstrating the system’s ability to generate a seamless and natural-looking flow between diverse movements.
read the caption
Figure 5: Visualization results between our method and some baseline methods [60, 19, 64, 4]. The first row shows text-to-motion generation results, the second row shows long-term generation results and the third row shows the application of dynamic motion composition.
More on tables
| Methods | Subsequence | Transition | ||||||
|---|---|---|---|---|---|---|---|---|
| R@3 | FID | Div | MM-Dist | FID | Div | PJ | AUJ | |
| GT | 0.634 | 0.000 | 24.907 | 17.543 | 0.000 | 21.472 | 0.03 | 0.00 |
| DoubleTake [48] | 0.452 | 23.937 | 22.732 | 21.783 | 51.232 | 18.892 | 0.48 | 1.83 |
| FlowMDM [4] | 0.492 | 18.736 | 23.847 | 20.253 | 34.721 | 20.293 | 0.06 | 0.51 |
| T2M-GPT* [60] | 0.364 | 39.482 | 24.317 | 20.692 | 43.823 | 20.797 | 0.12 | 1.43 |
| VQ-LLaMA | 0.383 | 24.342 | 19.329 | 38.285 | 36.293 | 19.932 | 0.08 | 1.20 |
| Ours | 0.568 | 15.743 | 23.546 | 15.397 | 32.888 | 19.986 | 0.04 | 0.90 |
🔼 This table compares the performance of various long-term motion generation methods on the BABEL dataset. The metrics used are FID (Frechet Inception Distance), measuring the difference between the distribution of generated and real motions; Diversity, indicating the variety of generated motion sequences; MM-Dist (Multimodal Distance), representing the distance between generated motion and its corresponding text description; and R@3 (Recall@3), indicating the accuracy of top 3 retrieved motions. Lower FID and MM-Dist, higher R@3 and Diversity values are preferred. The table also shows results for PJ (Peak Jerk) and AUJ (Area Under the Jerk), evaluating the smoothness of the generated motion, with lower scores indicating smoother motions. The best and second-best results for each metric are bolded and underlined, respectively.
read the caption
Table 2: Comparison with long-term motion generation methods on BABEL [43] dataset. Symbols ↑↑\uparrow↑, ↓↓\downarrow↓ and →→\rightarrow→ indicate the higher, lower and closer to Ground Truth are better. Bold and underline indicate the best and second best results.
| Methods | Reconstruction | Generation | ||||
|---|---|---|---|---|---|---|
| FID | MPJPE | FID | R@3 | MM-D. | Div. | |
| Real motion | - | - | 0.002 | 0.903 | 15.805 | 27.670 |
| VQ-VAE | 5.173 | 63.9 | 11.024 | 0.834 | 16.792 | 27.614 |
| AE | 0.001 | 1.7 | 43.818 | 0.473 | 22.041 | 27.085 |
| VAE | 2.092 | 26.2 | 19.914 | 0.755 | 17.948 | 27.520 |
| Ours | 0.737 | 24.89 | 10.724 | 0.851 | 16.639 | 27.657 |
🔼 This table presents the results of an ablation study comparing different motion compression methods used in the MotionStreamer model. The study evaluates the performance of various methods on the HumanML3D dataset’s test set. The metrics used to assess the performance include FID (Frechet Inception Distance), MPJPE (Mean Per Joint Position Error), and other metrics reflecting the quality and diversity of the generated motion. The goal of the ablation study is to determine which motion compression technique contributes most effectively to the overall performance of the MotionStreamer model.
read the caption
Table 3: Ablation Study of different motion compressors on HumanML3D [17] test set. MPJPE is measured in millimeters.
| AR Design choices | FID | R@3 | MM-Dist | Diversity |
|---|---|---|---|---|
| w/o QK Norm | 11.127 | 0.839 | 16.525 | 27.530 |
| w/o Two-Forward | 11.978 | 0.847 | 16.440 | 27.703 |
| w/o Diffusion Head | 59.195 | 0.361 | 22.884 | 26.825 |
| CLIP | 14.033 | 0.792 | 17.564 | 27.328 |
| Ours | 10.724 | 0.851 | 16.639 | 27.657 |
🔼 This table presents an ablation study analyzing the impact of different architectural design choices within the autoregressive (AR) model component of MotionStreamer, specifically focusing on the HumanML3D dataset. The design choices investigated include the inclusion or exclusion of Query-Key Normalization (QK Norm), the Two-Forward training strategy, the diffusion head, and the use of either the T5-XXL language model or the CLIP model for text encoding. The results, expressed in terms of FID, R@3, MM-Dist, and Diversity metrics, demonstrate the effect of these design decisions on the model’s performance in motion generation tasks.
read the caption
Table 4: Analysis of design choices of the AR model on HumanML3D [17] test set. CLIP indicates the use of CLIP model [44] as the text encoder to extract text features.
| FID | MPJPE | |
|---|---|---|
| 5.0 | 0.946 | 29.2 |
| 6.0 | 0.882 | 28.6 |
| 7.0 | 0.838 | 27.5 |
| 8.0 | 0.855 | 27.9 |
| 9.0 | 0.962 | 29.4 |
🔼 This table presents an ablation study analyzing the impact of the hyperparameter λ (lambda) on the performance of the MotionStreamer model. Specifically, it shows how different values of λ affect the Frechet Inception Distance (FID) and Mean Per Joint Position Error (MPJPE) metrics on the HumanML3D [17] test dataset. Lower FID and MPJPE values indicate better performance.
read the caption
Table 5: Analysis of λ𝜆\lambdaitalic_λ on the HumanML3D [17] test dataset.
| Methods | Reconstruction | Generation | ||||||
|---|---|---|---|---|---|---|---|---|
| FID | MPJPE | FID | R@1 | R@2 | R@3 | MM-Dist | Diversity | |
| Real motion | - | - | 0.002 | 0.711 | 0.851 | 0.903 | 15.805 | 27.670 |
| (12,512) | 8.862 | 38.5 | 21.078 | 0.600 | 0.759 | 0.827 | 17.143 | 27.755 |
| (12,1024) | 1.710 | 31.2 | 12.778 | 0.628 | 0.779 | 0.845 | 16.756 | 27.408 |
| (12,1280) | 2.035 | 32.9 | 12.872 | 0.642 | 0.785 | 0.854 | 16.587 | 27.455 |
| (12,1792) | 1.563 | 28.3 | 11.916 | 0.635 | 0.782 | 0.854 | 16.468 | 27.661 |
| (12,2048) | 1.732 | 28.9 | 13.394 | 0.611 | 0.770 | 0.831 | 16.852 | 27.417 |
| (14,512) | 2.902 | 33.6 | 16.612 | 0.607 | 0.772 | 0.836 | 16.947 | 27.328 |
| (14,1024) | 0.838 | 27.5 | 11.933 | 0.627 | 0.778 | 0.840 | 16.593 | 27.443 |
| (14,1280) | 0.919 | 26.4 | 12.603 | 0.603 | 0.772 | 0.841 | 16.863 | 27.414 |
| (14,1792) | 0.732 | 24.8 | 11.358 | 0.628 | 0.776 | 0.856 | 16.652 | 27.122 |
| (14,2048) | 1.370 | 26.5 | 12.261 | 0.621 | 0.768 | 0.841 | 16.734 | 27.417 |
| (16,512) | 1.300 | 30.3 | 14.096 | 0.605 | 0.770 | 0.839 | 16.882 | 27.306 |
| (16,1024) | 0.737 | 24.89 | 10.724 | 0.631 | 0.784 | 0.851 | 16.639 | 27.657 |
| (16,1280) | 1.087 | 25.0 | 12.975 | 0.598 | 0.761 | 0.831 | 17.002 | 27.403 |
| (16,1792) | 0.540 | 22.0 | 11.192 | 0.632 | 0.767 | 0.859 | 16.644 | 27.419 |
| (16,2048) | 1.547 | 26.2 | 12.778 | 0.604 | 0.755 | 0.824 | 16.897 | 27.306 |
| (18,512) | 2.043 | 27.7 | 19.150 | 0.553 | 0.701 | 0.775 | 17.776 | 27.345 |
| (18,1024) | 0.656 | 23.4 | 11.488 | 0.619 | 0.775 | 0.840 | 16.816 | 27.356 |
| (18,1280) | 0.820 | 23.1 | 11.815 | 0.629 | 0.776 | 0.847 | 16.816 | 27.461 |
| (18,1792) | 1.045 | 22.1 | 12.514 | 0.612 | 0.774 | 0.840 | 16.915 | 27.911 |
| (18,2048) | 0.595 | 21.5 | 11.803 | 0.613 | 0.766 | 0.832 | 17.004 | 27.451 |
| (20,512) | 0.531 | 24.5 | 12.247 | 0.613 | 0.765 | 0.832 | 16.920 | 27.277 |
| (20,1024) | 0.379 | 19.9 | 11.010 | 0.630 | 0.765 | 0.847 | 16.802 | 27.485 |
| (20,1280) | 0.429 | 20.11 | 16.465 | 0.557 | 0.705 | 0.774 | 17.680 | 27.490 |
| (20,1792) | 0.548 | 20.1 | 11.145 | 0.616 | 0.776 | 0.842 | 16.919 | 27.597 |
| (20,2048) | 0.690 | 20.7 | 11.910 | 0.625 | 0.782 | 0.844 | 16.785 | 27.542 |
🔼 This table presents a quantitative comparison of MotionStreamer against other methods that use various motion tokenization techniques. The performance is evaluated on the HumanML3D [17] test dataset using metrics such as Fréchet Inception Distance (FID), Mean Per Joint Position Error (MPJPE), and Recall@K (R@K). The results are shown for different latent dimensions and hidden sizes of the Causal Temporal Autoencoder (Causal TAE) in MotionStreamer. A lower FID indicates better generation quality, while a lower MPJPE signifies more accurate reconstruction. Higher Recall@K values demonstrate better retrieval accuracy.
read the caption
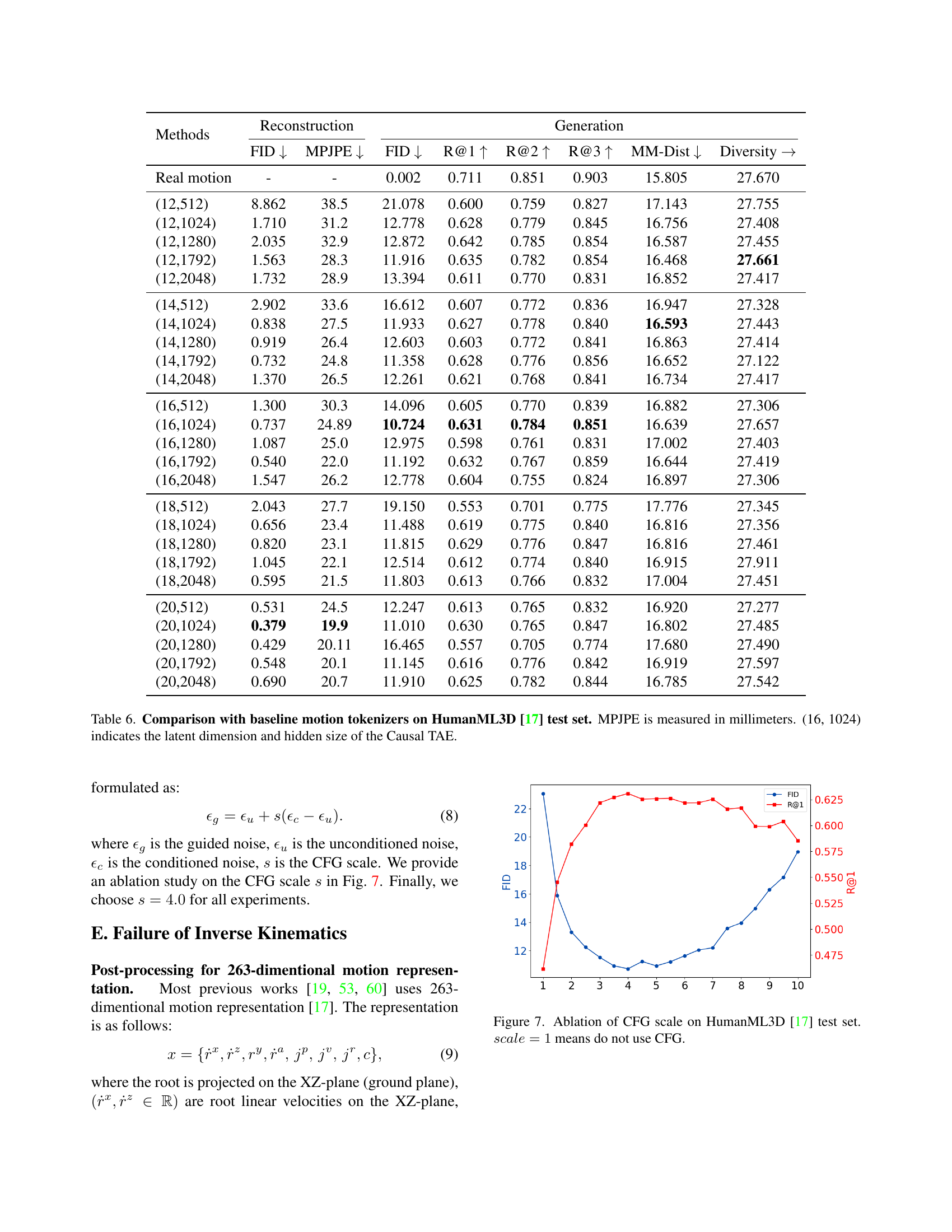
Table 6: Comparison with baseline motion tokenizers on HumanML3D [17] test set. MPJPE is measured in millimeters. (16, 1024) indicates the latent dimension and hidden size of the Causal TAE.
| AR. layers | AR. heads | AR. dim | Diff. layers | FID | R@1 | R@2 | R@3 | MM-Dist | Diversity |
|---|---|---|---|---|---|---|---|---|---|
| 8 | 8 | 512 | 2 | 14.336 | 0.598 | 0.747 | 0.802 | 16.983 | 27.787 |
| 8 | 8 | 512 | 3 | 13.764 | 0.602 | 0.758 | 0.819 | 16.972 | 27.742 |
| 8 | 8 | 512 | 4 | 12.893 | 0.608 | 0.764 | 0.828 | 16.661 | 27.351 |
| 8 | 8 | 512 | 9 | 11.721 | 0.623 | 0.772 | 0.835 | 16.655 | 27.585 |
| 8 | 8 | 512 | 16 | 12.460 | 0.621 | 0.778 | 0.849 | 16.784 | 27.410 |
| 12 | 12 | 768 | 2 | 11.899 | 0.601 | 0.763 | 0.828 | 16.952 | 27.406 |
| 12 | 12 | 768 | 3 | 11.783 | 0.632 | 0.779 | 0.844 | 16.761 | 27.482 |
| 12 | 12 | 768 | 4 | 12.051 | 0.604 | 0.762 | 0.829 | 16.940 | 27.501 |
| 12 | 12 | 768 | 9 | 10.724 | 0.631 | 0.784 | 0.851 | 16.639 | 27.657 |
| 12 | 12 | 768 | 16 | 11.825 | 0.624 | 0.773 | 0.844 | 16.757 | 27.541 |
| 16 | 16 | 1024 | 2 | 12.836 | 0.606 | 0.765 | 0.832 | 16.901 | 27.619 |
| 16 | 16 | 1024 | 3 | 12.436 | 0.601 | 0.761 | 0.830 | 16.919 | 27.607 |
| 16 | 16 | 1024 | 4 | 13.005 | 0.614 | 0.763 | 0.830 | 16.967 | 27.196 |
| 16 | 16 | 1024 | 9 | 12.093 | 0.614 | 0.778 | 0.843 | 16.850 | 27.508 |
| 16 | 16 | 1024 | 16 | 11.411 | 0.635 | 0.780 | 0.846 | 16.598 | 27.586 |
🔼 This table presents an ablation study analyzing the impact of different architectural choices within the Autoregressive (AR) model on the performance of motion generation. The study focuses on the HumanML3D dataset, holding the Causal Temporal Autoencoder (TAE) constant across all model variations. The results allow for comparison of metrics such as FID, R@K recall, and MM-Dist with varying numbers of AR layers, attention heads, hidden dimensions, and diffusion layers to determine the optimal AR model architecture.
read the caption
Table 7: Ablation study of AR Model architecture on HumanML3D [17] test set. For each architecture, we use the same Causal TAE.
| Components | Architecture |
|---|---|
| Causal TAE Encoder | (0): CausalConv1D(, 1024, kernel_size=(3,), stride=(1,), dilation=(1,), padding=(2,)) |
| (1): ReLU() | |
| (2): 2 Sequential( | |
| (0): CausalConv1D(1024, 1024, kernel_size=(4,), stride=(2,), dilation=(1,), padding=(2,)) | |
| (1): CausalResnet1D( | |
| (0): CausalResConv1DBlock( | |
| (activation1): ReLU() | |
| (conv1): CausalConv1D(1024, 1024, kernel_size=(3,), stride=(1,), dilation=(9,), padding=(18,)) | |
| (activation2): ReLU() | |
| (conv2): CausalConv1D(1024, 1024, kernel_size=(1,), stride=(1,), dilation=(1,), padding=(0,))) | |
| (1): CausalResConv1DBlock( | |
| (activation1): ReLU() | |
| (conv1): CausalConv1D(1024, 1024, kernel_size=(3,), stride=(1,), dilation=(3,), padding=(6,)) | |
| (activation2): ReLU() | |
| (conv2): CausalConv1D(1024, 1024, kernel_size=(1,), stride=(1,), dilation=(1,), padding=(0,))) | |
| (2): CausalResConv1DBlock( | |
| (activation1): ReLU() | |
| (conv1): CausalConv1D(1024, 1024, kernel_size=(3,), stride=(1,), dilation=(1,), padding=(2,)) | |
| (activation2): ReLU() | |
| (conv2): CausalConv1D(1024, 1024, kernel_size=(1,), stride=(1,), dilation=(1,), padding=(0,))))) | |
| (3): CausalConv1D(1024, 1024, kernel_size=(3,), stride=(1,), dilation=(1,), padding=(2,)) | |
| Causal TAE Decoder | (0): CausalConv1D(1024, 1024, kernel_size=(3,), stride=(1,), dilation=(1,), padding=(2,)) |
| (1): ReLU() | |
| (2): 2 Sequential( | |
| (0): CausalResnet1D( | |
| (0): CausalResConv1DBlock( | |
| (activation1): ReLU() | |
| (conv1): CausalConv1D(1024, 1024, kernel_size=(3,), stride=(1,), dilation=(9,), padding=(18,)) | |
| (activation2): ReLU() | |
| (conv2): CausalConv1D(1024, 1024, kernel_size=(1,), stride=(1,), dilation=(1,), padding=(0,))) | |
| (1): CausalResConv1DBlock( | |
| (activation1): ReLU() | |
| (conv1): CausalConv1D(1024, 1024, kernel_size=(3,), stride=(1,), dilation=(3,), padding=(6,)) | |
| (activation2): ReLU() | |
| (conv2): CausalConv1D(1024, 1024, kernel_size=(1,), stride=(1,), dilation=(1,), padding=(0,))) | |
| (2): CausalResConv1DBlock( | |
| (activation1): ReLU() | |
| (conv1): CausalConv1D(1024, 1024, kernel_size=(3,), stride=(1,), dilation=(1,), padding=(2,)) | |
| (activation2): ReLU() | |
| (conv2): CausalConv1D(1024, 1024, kernel_size=(1,), stride=(1,), dilation=(1,), padding=(0,))))) | |
| (1): Upsample(scale_factor=2.0, mode=nearest) | |
| (2): CausalConv1D(1024, 1024, kernel_size=(3,), stride=(1,), dilation=(1,), padding=(2,)) | |
| (3) CausalConv1D(1024, 1024, kernel_size=(3,), stride=(1,), dilation=(1,), padding=(2,)) | |
| (4): ReLU() | |
| (5): CausalConv1D(1024, , kernel_size=(3,), stride=(1,), dilation=(1,), padding=(2,)) |
🔼 Table 8 provides a detailed breakdown of the Causal Temporal AutoEncoder (Causal TAE) architecture, a key component of the MotionStreamer framework. It outlines the specific layers, activation functions, and configurations used in both the encoder and decoder parts of the Causal TAE. This level of detail is crucial for understanding how the model processes and compresses motion data into a continuous causal latent space, enabling efficient and temporally coherent streaming motion generation.
read the caption
Table 8: Detail architecture of the proposed Causal TAE.
Full paper#