TL;DR#
Existing image-text models often struggle with tasks needing high-fidelity visual understanding like fine-grained object recognition because they prioritize high-level semantics over visual details. Vision-focused models, while good at processing visual data, struggle with language, thus limiting its task flexibility. There is a need to improve existing models by enhancing general-purpose visual features and maintaining language strengths.
This paper presents TULIP, a drop-in replacement for existing CLIP-like models, uses generative data augmentation, enhanced image-image and text-text contrastive learning, and reconstruction regularization to learn fine-grained visual features while preserving global semantic alignment. TULIP outperforms existing models, setting a new zero-shot performance record on ImageNet-1K and significantly improving performance on several vision-language benchmarks.
Key Takeaways#
Why does it matter?#
This paper is crucial for multimodal AI as it introduces a way to retain fine-grained details while keeping strong semantic alignment. TULIP paves the way for more adaptable models and pushes forward the capabilities and efficiency of vision-language understanding, presenting new research directions.
Visual Insights#

🔼 TULIP, a new image-text contrastive model, addresses the limitations of existing models like CLIP and SigLIP in high-fidelity visual understanding. Existing methods struggle with fine-grained tasks due to a focus on high-level semantics rather than detailed visual information. TULIP improves performance by incorporating three key innovations: 1) Generative data augmentation creates diverse training examples, enhancing the model’s ability to learn nuanced visual details and semantic relationships. 2) Global-local patch-wise image contrastive learning compares both global image representations and local image patches, capturing fine-grained visual features while maintaining semantic alignment. 3) Reconstruction-based feature regularization encourages the model to learn features that support accurate image reconstruction, leading to more robust visual representations and better grounding of language. This combined approach results in a model that excels at both high-level image-text understanding and fine-grained visual tasks.
read the caption
Figure 1: TULIP Overview. Existing contrastive image-text models struggle with high-fidelity visual understanding. TULIP is a drop-in replacement for CLIP which leverages generative data augmentation, global-local patch-wise image contrastive learning, and reconstruction-based feature regularization to learn robust visual features and fine-grained language grounding.
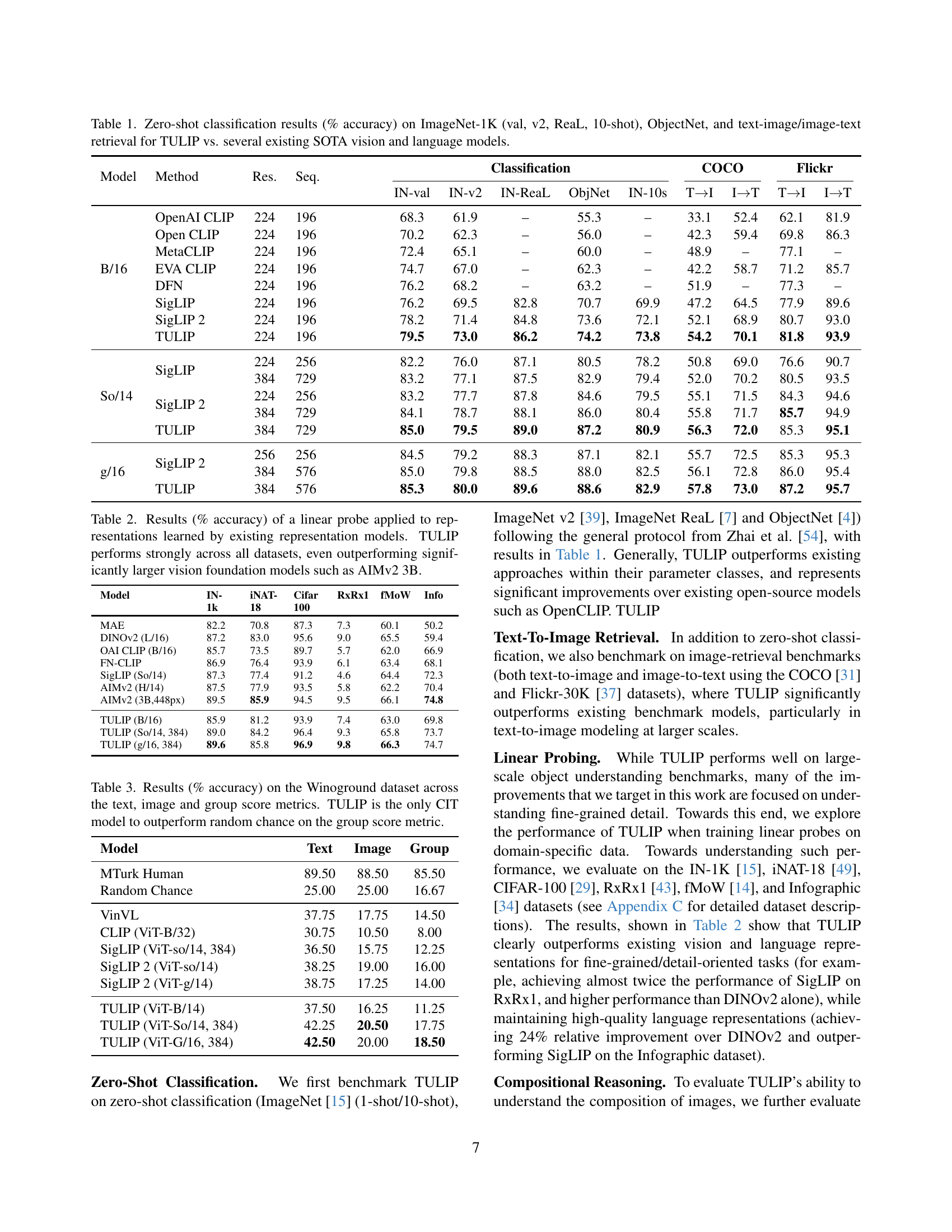
| Model | Method | Res. | Seq. | Classification | COCO | Flickr | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IN-val | IN-v2 | IN-ReaL | ObjNet | IN-10s | TI | IT | TI | IT | ||||
| B/16 | OpenAI CLIP | 224 | 196 | 68.3 | 61.9 | – | 55.3 | – | 33.1 | 52.4 | 62.1 | 81.9 |
| Open CLIP | 224 | 196 | 70.2 | 62.3 | – | 56.0 | – | 42.3 | 59.4 | 69.8 | 86.3 | |
| MetaCLIP | 224 | 196 | 72.4 | 65.1 | – | 60.0 | – | 48.9 | – | 77.1 | – | |
| EVA CLIP | 224 | 196 | 74.7 | 67.0 | – | 62.3 | – | 42.2 | 58.7 | 71.2 | 85.7 | |
| DFN | 224 | 196 | 76.2 | 68.2 | – | 63.2 | – | 51.9 | – | 77.3 | – | |
| SigLIP | 224 | 196 | 76.2 | 69.5 | 82.8 | 70.7 | 69.9 | 47.2 | 64.5 | 77.9 | 89.6 | |
| SigLIP 2 | 224 | 196 | 78.2 | 71.4 | 84.8 | 73.6 | 72.1 | 52.1 | 68.9 | 80.7 | 93.0 | |
| TULIP | 224 | 196 | 79.5 | 73.0 | 86.2 | 74.2 | 73.8 | 54.2 | 70.1 | 81.8 | 93.9 | |
| So/14 | SigLIP | 224 | 256 | 82.2 | 76.0 | 87.1 | 80.5 | 78.2 | 50.8 | 69.0 | 76.6 | 90.7 |
| 384 | 729 | 83.2 | 77.1 | 87.5 | 82.9 | 79.4 | 52.0 | 70.2 | 80.5 | 93.5 | ||
| SigLIP 2 | 224 | 256 | 83.2 | 77.7 | 87.8 | 84.6 | 79.5 | 55.1 | 71.5 | 84.3 | 94.6 | |
| 384 | 729 | 84.1 | 78.7 | 88.1 | 86.0 | 80.4 | 55.8 | 71.7 | 85.7 | 94.9 | ||
| TULIP | 384 | 729 | 85.0 | 79.5 | 89.0 | 87.2 | 80.9 | 56.3 | 72.0 | 85.3 | 95.1 | |
| g/16 | SigLIP 2 | 256 | 256 | 84.5 | 79.2 | 88.3 | 87.1 | 82.1 | 55.7 | 72.5 | 85.3 | 95.3 |
| 384 | 576 | 85.0 | 79.8 | 88.5 | 88.0 | 82.5 | 56.1 | 72.8 | 86.0 | 95.4 | ||
| TULIP | 384 | 576 | 85.3 | 80.0 | 89.6 | 88.6 | 82.9 | 57.8 | 73.0 | 87.2 | 95.7 | |
🔼 This table presents a comparison of zero-shot classification performance and image-text retrieval capabilities across several state-of-the-art (SOTA) vision and language models, including TULIP. The models are evaluated on various benchmark datasets: ImageNet-1K (validation set, ImageNet-V2, ImageNet-ReaL, and a 10-shot scenario), ObjectNet, COCO, and Flickr. For each model and dataset, the table shows the percentage accuracy achieved in zero-shot classification and text-to-image/image-to-text retrieval. This allows for a direct comparison of TULIP’s performance against existing models in both high-level image understanding tasks and fine-grained visual recognition tasks.
read the caption
Table 1: Zero-shot classification results (% accuracy) on ImageNet-1K (val, v2, ReaL, 10-shot), ObjectNet, and text-image/image-text retrieval for TULIP vs. several existing SOTA vision and language models.
In-depth insights#
Generative Data#
Generative data augmentation emerges as a powerful tool for enhancing datasets beyond traditional transformations. Instead of relying solely on fixed augmentations, generative models, particularly diffusion models, can create more diverse and realistic variations of existing data. This approach addresses limitations in standard data augmentation, which may not capture the full range of potential data distributions. Diffusion models, with their ability to perform semantic image edits and create entirely new, plausible examples, offer a promising avenue for augmenting datasets, particularly in scenarios with limited data or domain shifts. This allows for creating more accurate and robust models. Also, it provides more and more comprehensive data augmentation.
Patch-Level Details#
Patch-level details are crucial for high-fidelity image understanding, often overlooked in contrastive models prioritizing global semantics. Addressing this requires incorporating methods like patch-level augmentations (e.g., multi-crop) and objectives inspired by iBOT and DINO. A reconstruction objective can further preserve high-frequency local visual details that contrastive learning might miss. By encoding information for reconstructing the image from its latent space, the model captures essential visual nuances (color, texture) while maintaining semantic invariance. This enhancement proves beneficial in downstream tasks demanding fine-grained detail, such as visual question answering, because the model doesn’t only look at what is present but also how is the object presented in an image.
Spatial Awareness#
Spatial awareness in AI, particularly in vision-language models, is crucial for tasks requiring precise localization and understanding of object relationships within an image. Current models often prioritize high-level semantic understanding over detailed spatial reasoning, leading to limitations in tasks like counting or depth estimation. Enhancing spatial awareness involves incorporating mechanisms that capture fine-grained details and spatial relationships, such as patch-level analysis and multi-crop augmentation. By doing so, AI systems can move beyond merely identifying objects to comprehending their position and arrangement, enabling more accurate and nuanced interpretations of visual scenes. Furthermore, this heightened awareness improves performance in tasks demanding compositional reasoning and visual perspective-taking.
Unified Learning#
The concept of “Unified Learning” signifies a profound shift towards integrating diverse data modalities, such as image and text, into a cohesive learning framework. This approach aims to overcome the limitations of unimodal systems, enabling a model to leverage the synergistic relationship between different types of information. By aligning visual and textual representations into a shared embedding space, unified learning facilitates cross-modal understanding which leads to improved performance across various tasks. Specifically, this unification allows models to generalize better by leveraging the complementary strengths inherent in different data formats. The ability to connect high-level semantics with fine-grained visual details leads to more robust and versatile AI systems. Ultimately, unified learning strives to create models that exhibit human-like understanding, capable of seamlessly processing and interpreting the multimodal world around us. Such models hold immense potential for applications ranging from advanced image retrieval to sophisticated vision-language interactions.
Visual Fidelity#
While the provided research paper focuses on improving image-text pretraining (TULIP) for better vision and language understanding, the concept of “visual fidelity,” though not explicitly a heading, is implicitly addressed throughout the document. Visual fidelity refers to the degree to which a model preserves and understands the intricate details within an image. The paper tackles the challenge of existing contrastive image-text models that, while good at high-level semantics, often struggle with tasks requiring fine-grained visual understanding. This is achieved through several key mechanisms: generative data augmentation, enabling the model to learn from varied perspectives and nuanced semantic alterations; enhanced image-image and text-text contrastive learning, forcing the model to discern subtle differences; and image/text reconstruction regularization, ensuring the model retains high-frequency visual details often overlooked in standard contrastive learning. By incorporating patch-level augmentations and reconstruction objectives, TULIP aims to capture both global semantic information and localized visual intricacies, thereby enhancing visual fidelity. The positive results across multiple benchmarks demonstrate the effectiveness of these techniques in improving performance on tasks demanding precise spatial reasoning and fine-grained object recognition, ultimately leading to a more complete and accurate visual representation.
More visual insights#
More on figures

🔼 The TULIP Image Encoder processes images using both traditional augmentation methods (like cropping and color jittering) and generative augmentations from GeCo. GeCo uses large generative models to produce semantically similar or different versions of the input image. These varied image representations, along with the original image, are used in image-image and image-text contrastive learning. A key addition is the inclusion of a masked autoencoder (MAE) reconstruction loss. This loss helps ensure that the model captures both high-level semantic understanding and fine-grained details from the image.
read the caption
Figure 2: TULIP Image Encoder. Images undergo both traditional augmentations (such as cropping and color jittering) and generative augmentations via GeCo, which leverages large generative models to create semantically consistent or semantically altered views. These views are then used for image-image and image-text contrastive learning. Additionally, a masked autoencoder (MAE)-based reconstruction loss is applied to encourage the model to encode both semantic and fine-grained details.

🔼 The TULIP Text Encoder processes text data using generative augmentation techniques, including paraphrasing and controlled semantic alterations. This is achieved using large language models to create pairs of text data – positive pairs that maintain the original meaning and negative pairs that subtly alter it. These pairs are then fed into both text-text and image-text contrastive learning processes using a SigLIP objective function. Similar to the image reconstruction process in TULIP, a causal decoder (based on the T5 architecture) reconstructs the original text, preserving both high-level semantics and fine-grained linguistic details.
read the caption
Figure 3: TULIP Text Encoder. Text undergoes generative augmentation through paraphrasing and controlled semantic alterations using large language models, generating both positive and negative contrastive pairs. These pairs are used for both text-text and image-text contrastive learning with a SigLIP objective. Similar to image reconstruction, a causal decoder (based on T5) is used for text reconstruction, ensuring that the model retains both high-level semantics and fine-grained linguistic detail.

🔼 GeCo, a generative contrastive augmentation framework, uses large language models (LLaMa) and image editing models (InstructPix2Pix) to create diverse training data. For text, it generates paraphrases and semantically altered versions. For images, it produces semantically consistent (positive) and inconsistent (negative) augmentations using soft prompting. This diversification of views enhances the contrastive learning process, improving model robustness and fine-grained understanding.
read the caption
Figure 4: Overview of GeCo. Our generative augmentation framework leverages large generative models to create diverse contrastive views by generating both positive and negative augmentations for images and text. For text augmentation, we use Llama-3.1-8B-Instruct to generate paraphrases and semantically altered text variations. For image augmentation, we fine-tune an instruction-based image editing model (e.g., InstructPix2Pix) fine-tuned using soft-prompting to generate semantically consistent (positive) and semantically altered (negative) views.

🔼 This figure illustrates the GeCo (Generative Contrastive view augmentation) process. The top part shows how GeCo generates both positive and negative augmentations for images and their corresponding texts. Positive augmentations maintain the original semantic meaning, only changing visual aspects like viewpoint (e.g., different angle of the same bird). In contrast, negative augmentations alter the semantic meaning while maintaining some visual similarity. The bottom part of the figure shows how TULIP utilizes these augmentations during training. It assigns weights (+1 for positive pairs, -1 for negative pairs, and 0 to ignore certain pairs) to these augmented image-text pairs to guide the contrastive learning process. The example shown uses a bird image and its text descriptions to demonstrate the positive and negative augmentation effects.
read the caption
Figure 5: (Top) GeCo generates positive and negative augmentations of both images and text, (Bottom) TULIP uses these augmentations during training time with corresponding weights (+1 for positive pair, -1 for negative pair, 0 to ignore). Here, the generated positive image represents the same bird from a different viewpoint, while the negative image is a different bird (coloring, face structure) in the same physical location.
More on tables
| Model | IN-1k | iNAT-18 | Cifar 100 | RxRx1 | fMoW | Info |
|---|---|---|---|---|---|---|
| MAE | 82.2 | 70.8 | 87.3 | 7.3 | 60.1 | 50.2 |
| DINOv2 (L/16) | 87.2 | 83.0 | 95.6 | 9.0 | 65.5 | 59.4 |
| OAI CLIP (B/16) | 85.7 | 73.5 | 89.7 | 5.7 | 62.0 | 66.9 |
| FN-CLIP | 86.9 | 76.4 | 93.9 | 6.1 | 63.4 | 68.1 |
| SigLIP (So/14) | 87.3 | 77.4 | 91.2 | 4.6 | 64.4 | 72.3 |
| AIMv2 (H/14) | 87.5 | 77.9 | 93.5 | 5.8 | 62.2 | 70.4 |
| AIMv2 (3B,448px) | 89.5 | 85.9 | 94.5 | 9.5 | 66.1 | 74.8 |
| TULIP (B/16) | 85.9 | 81.2 | 93.9 | 7.4 | 63.0 | 69.8 |
| TULIP (So/14, 384) | 89.0 | 84.2 | 96.4 | 9.3 | 65.8 | 73.7 |
| TULIP (g/16, 384) | 89.6 | 85.8 | 96.9 | 9.8 | 66.3 | 74.7 |
🔼 This table presents the results of applying a linear probe to evaluate the quality of visual representations learned by various models, including TULIP and several state-of-the-art (SOTA) vision foundation models. A linear probe is a simple classifier trained on top of the learned representations to assess their effectiveness for downstream tasks. The table shows the accuracy achieved on several benchmark datasets (ImageNet-1K, iNAT-18, CIFAR-100, RxRx1, fMoW, and Infographics), demonstrating TULIP’s superior performance even when compared to significantly larger models. The datasets are chosen to represent a wide range of visual tasks, showcasing TULIP’s versatility and robustness.
read the caption
Table 2: Results (% accuracy) of a linear probe applied to representations learned by existing representation models. TULIP performs strongly across all datasets, even outperforming significantly larger vision foundation models such as AIMv2 3B.
| Model | Text | Image | Group |
|---|---|---|---|
| MTurk Human | 89.50 | 88.50 | 85.50 |
| Random Chance | 25.00 | 25.00 | 16.67 |
| VinVL | 37.75 | 17.75 | 14.50 |
| CLIP (ViT-B/32) | 30.75 | 10.50 | 8.00 |
| SigLIP (ViT-so/14, 384) | 36.50 | 15.75 | 12.25 |
| SigLIP 2 (ViT-so/14) | 38.25 | 19.00 | 16.00 |
| SigLIP 2 (ViT-g/14) | 38.75 | 17.25 | 14.00 |
| TULIP (ViT-B/14) | 37.50 | 16.25 | 11.25 |
| TULIP (ViT-So/14, 384) | 42.25 | 20.50 | 17.75 |
| TULIP (ViT-G/16, 384) | 42.50 | 20.00 | 18.50 |
🔼 This table presents the performance of various vision-language models on the Winoground dataset, a benchmark designed to evaluate compositional reasoning abilities. The dataset contains image-text pairs with subtly altered meanings, testing the models’ ability to correctly match images and captions based on their compositional understanding. The results are broken down by three scoring metrics: text accuracy, image accuracy, and group accuracy, reflecting the model’s performance in understanding text, images, and the relationship between them. The table highlights that TULIP is the only contrastive image-text (CIT) model that surpasses random chance on the group accuracy metric, indicating a superior ability to understand the complex relationships within the dataset.
read the caption
Table 3: Results (% accuracy) on the Winoground dataset across the text, image and group score metrics. TULIP is the only CIT model to outperform random chance on the group score metric.
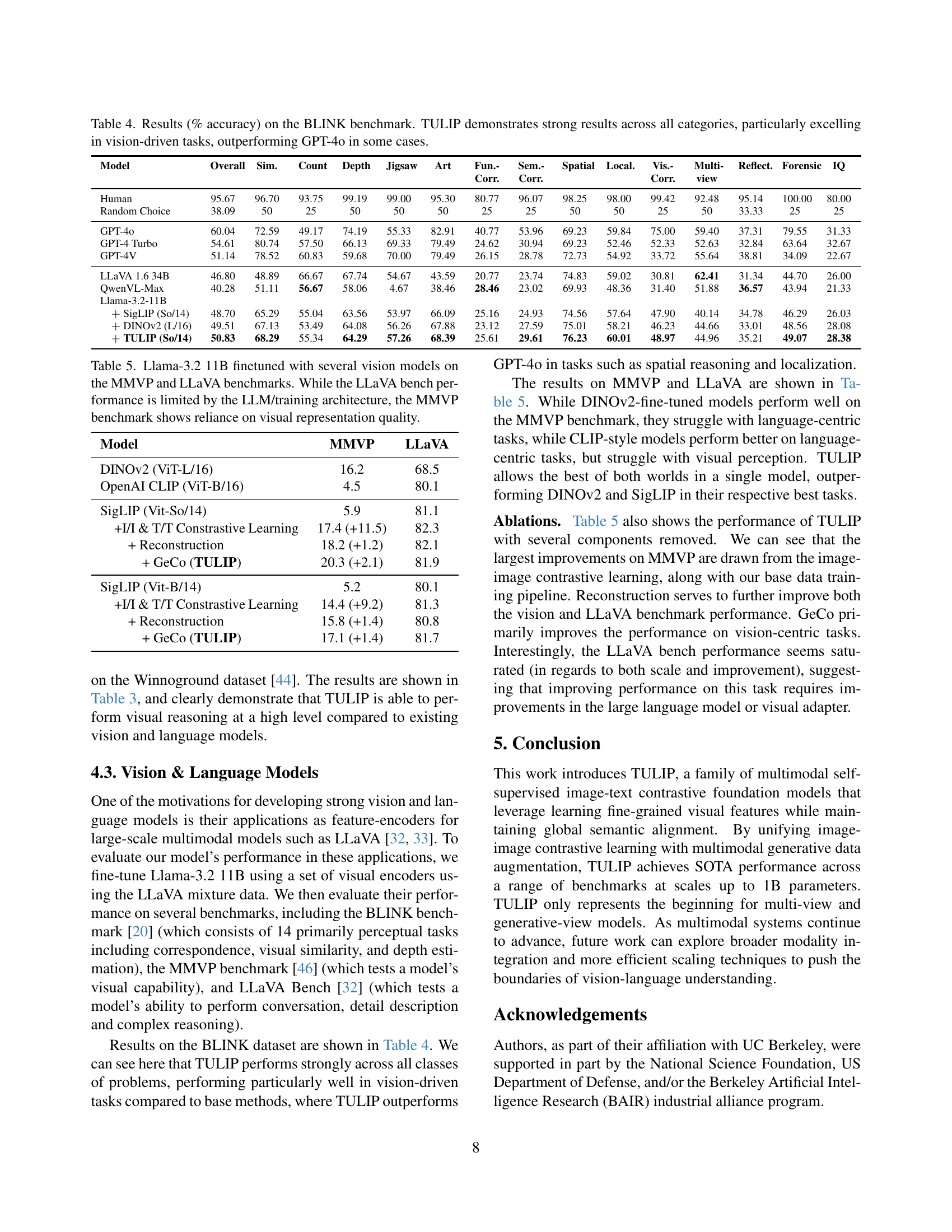
| Model | Overall | Sim. | Count | Depth | Jigsaw | Art | Fun.-Corr. | Sem.-Corr. | Spatial | Local. | Vis.-Corr. | Multi-view | Reflect. | Forensic | IQ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Human | 95.67 | 96.70 | 93.75 | 99.19 | 99.00 | 95.30 | 80.77 | 96.07 | 98.25 | 98.00 | 99.42 | 92.48 | 95.14 | 100.00 | 80.00 |
| Random Choice | 38.09 | 50 | 25 | 50 | 50 | 50 | 25 | 25 | 50 | 50 | 25 | 50 | 33.33 | 25 | 25 |
| GPT-4o | 60.04 | 72.59 | 49.17 | 74.19 | 55.33 | 82.91 | 40.77 | 53.96 | 69.23 | 59.84 | 75.00 | 59.40 | 37.31 | 79.55 | 31.33 |
| GPT-4 Turbo | 54.61 | 80.74 | 57.50 | 66.13 | 69.33 | 79.49 | 24.62 | 30.94 | 69.23 | 52.46 | 52.33 | 52.63 | 32.84 | 63.64 | 32.67 |
| GPT-4V | 51.14 | 78.52 | 60.83 | 59.68 | 70.00 | 79.49 | 26.15 | 28.78 | 72.73 | 54.92 | 33.72 | 55.64 | 38.81 | 34.09 | 22.67 |
| LLaVA 1.6 34B | 46.80 | 48.89 | 66.67 | 67.74 | 54.67 | 43.59 | 20.77 | 23.74 | 74.83 | 59.02 | 30.81 | 62.41 | 31.34 | 44.70 | 26.00 |
| QwenVL-Max | 40.28 | 51.11 | 56.67 | 58.06 | 4.67 | 38.46 | 28.46 | 23.02 | 69.93 | 48.36 | 31.40 | 51.88 | 36.57 | 43.94 | 21.33 |
| Llama-3.2-11B | |||||||||||||||
| SigLIP (So/14) | 48.70 | 65.29 | 55.04 | 63.56 | 53.97 | 66.09 | 25.16 | 24.93 | 74.56 | 57.64 | 47.90 | 40.14 | 34.78 | 46.29 | 26.03 |
| DINOv2 (L/16) | 49.51 | 67.13 | 53.49 | 64.08 | 56.26 | 67.88 | 23.12 | 27.59 | 75.01 | 58.21 | 46.23 | 44.66 | 33.01 | 48.56 | 28.08 |
| TULIP (So/14) | 50.83 | 68.29 | 55.34 | 64.29 | 57.26 | 68.39 | 25.61 | 29.61 | 76.23 | 60.01 | 48.97 | 44.96 | 35.21 | 49.07 | 28.38 |
🔼 Table 4 presents the performance of various models on the BLINK benchmark, a test designed to evaluate vision and language understanding. The benchmark includes several sub-tasks categorized by the type of visual reasoning involved (e.g., counting, depth perception, spatial reasoning). The results show TULIP’s performance compared to other models (including GPT-4) on each subtask, highlighting its strengths in vision-centric tasks. Overall accuracy and individual task scores are provided to show the model’s proficiency in different types of visual understanding.
read the caption
Table 4: Results (% accuracy) on the BLINK benchmark. TULIP demonstrates strong results across all categories, particularly excelling in vision-driven tasks, outperforming GPT-4o in some cases.
| Model | MMVP | LLaVA |
|---|---|---|
| DINOv2 (ViT-L/16) | 16.2 | 68.5 |
| OpenAI CLIP (ViT-B/16) | 4.5 | 80.1 |
| SigLIP (Vit-So/14) | 5.9 | 81.1 |
| +I/I & T/T Constrastive Learning | 17.4 (+11.5) | 82.3 |
| + Reconstruction | 18.2 (+1.2) | 82.1 |
| + GeCo (TULIP) | 20.3 (+2.1) | 81.9 |
| SigLIP (Vit-B/14) | 5.2 | 80.1 |
| +I/I & T/T Constrastive Learning | 14.4 (+9.2) | 81.3 |
| + Reconstruction | 15.8 (+1.4) | 80.8 |
| + GeCo (TULIP) | 17.1 (+1.4) | 81.7 |
🔼 This table presents the results of fine-tuning the Llama-3.2 11B language model with different vision models on two benchmark datasets: MMVP and LLaVA. The MMVP benchmark focuses on evaluating the quality of visual representations, while LLaVA assesses the overall performance of the combined vision-language model. The table highlights how different vision models (DINOv2, CLIP, SigLIP, and TULIP) impact the performance of the language model on both benchmarks. It shows that while the LLaVA performance may be constrained by the limitations of the language model architecture, MMVP scores directly reflect the visual representation quality provided by each vision model. The table also includes ablation studies showing the effects of adding contrastive learning, reconstruction loss, and generative augmentation techniques to TULIP.
read the caption
Table 5: Llama-3.2 11B finetuned with several vision models on the MMVP and LLaVA benchmarks. While the LLaVA bench performance is limited by the LLM/training architecture, the MMVP benchmark shows reliance on visual representation quality.
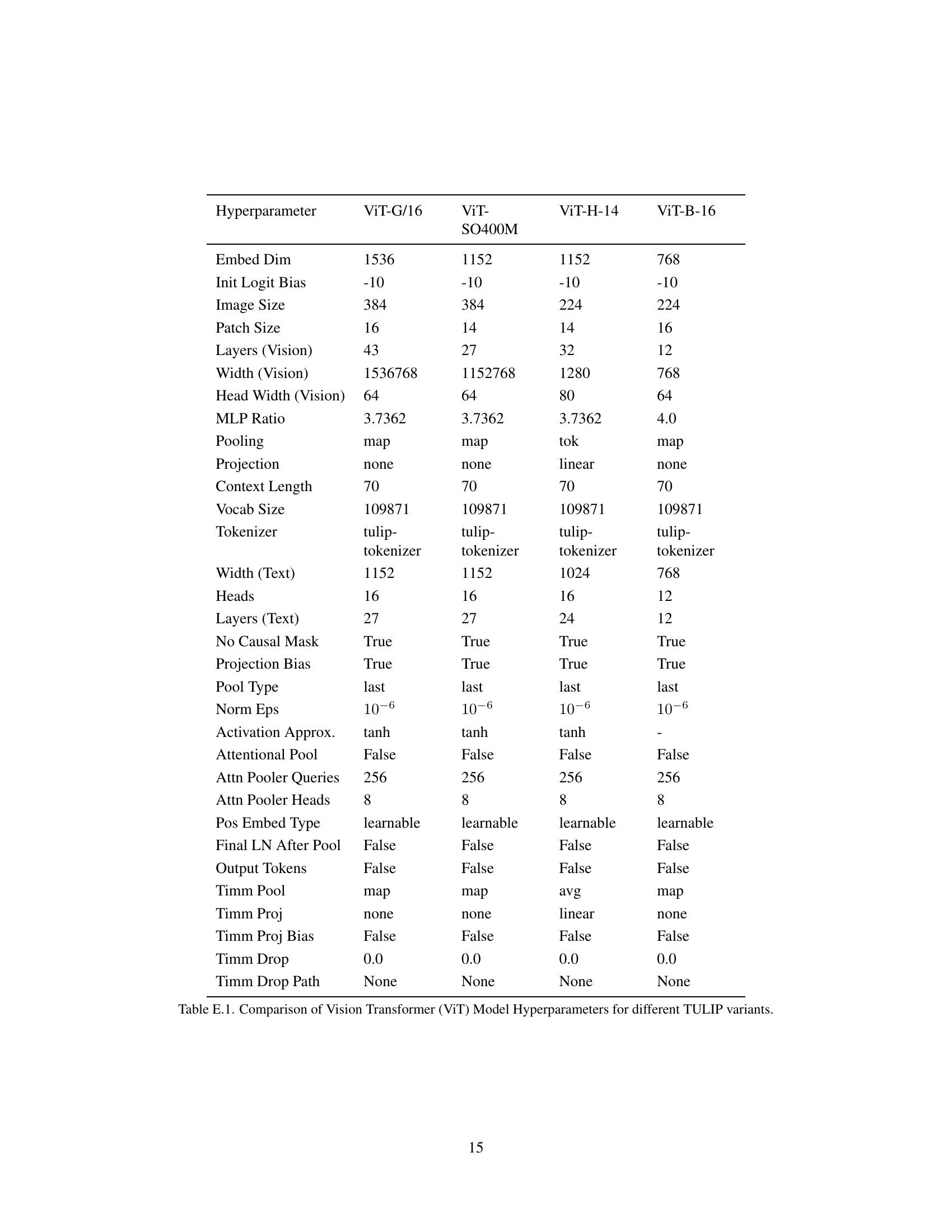
| Hyperparameter | ViT-G/16 | ViT-SO400M | ViT-H-14 | ViT-B-16 |
|---|---|---|---|---|
| Embed Dim | 1536 | 1152 | 1152 | 768 |
| Init Logit Bias | -10 | -10 | -10 | -10 |
| Image Size | 384 | 384 | 224 | 224 |
| Patch Size | 16 | 14 | 14 | 16 |
| Layers (Vision) | 43 | 27 | 32 | 12 |
| Width (Vision) | 1536768 | 1152768 | 1280 | 768 |
| Head Width (Vision) | 64 | 64 | 80 | 64 |
| MLP Ratio | 3.7362 | 3.7362 | 3.7362 | 4.0 |
| Pooling | map | map | tok | map |
| Projection | none | none | linear | none |
| Context Length | 70 | 70 | 70 | 70 |
| Vocab Size | 109871 | 109871 | 109871 | 109871 |
| Tokenizer | tulip-tokenizer | tulip-tokenizer | tulip-tokenizer | tulip-tokenizer |
| Width (Text) | 1152 | 1152 | 1024 | 768 |
| Heads | 16 | 16 | 16 | 12 |
| Layers (Text) | 27 | 27 | 24 | 12 |
| No Causal Mask | True | True | True | True |
| Projection Bias | True | True | True | True |
| Pool Type | last | last | last | last |
| Norm Eps | ||||
| Activation Approx. | tanh | tanh | tanh | - |
| Attentional Pool | False | False | False | False |
| Attn Pooler Queries | 256 | 256 | 256 | 256 |
| Attn Pooler Heads | 8 | 8 | 8 | 8 |
| Pos Embed Type | learnable | learnable | learnable | learnable |
| Final LN After Pool | False | False | False | False |
| Output Tokens | False | False | False | False |
| Timm Pool | map | map | avg | map |
| Timm Proj | none | none | linear | none |
| Timm Proj Bias | False | False | False | False |
| Timm Drop | 0.0 | 0.0 | 0.0 | 0.0 |
| Timm Drop Path | None | None | None | None |
🔼 This table details the hyperparameters used for the Vision Transformer (ViT) models within different versions of the TULIP architecture. It compares various settings across four ViT configurations (ViT-G/16, ViT-SO400M, ViT-H-14, and ViT-B-16), showing differences in embedding dimensions, image and patch sizes, the number of layers, attention head width, MLP ratio, and other key parameters of the model. This allows for a detailed comparison of the architectural choices made across different TULIP variants.
read the caption
Table E.1: Comparison of Vision Transformer (ViT) Model Hyperparameters for different TULIP variants.
Full paper#