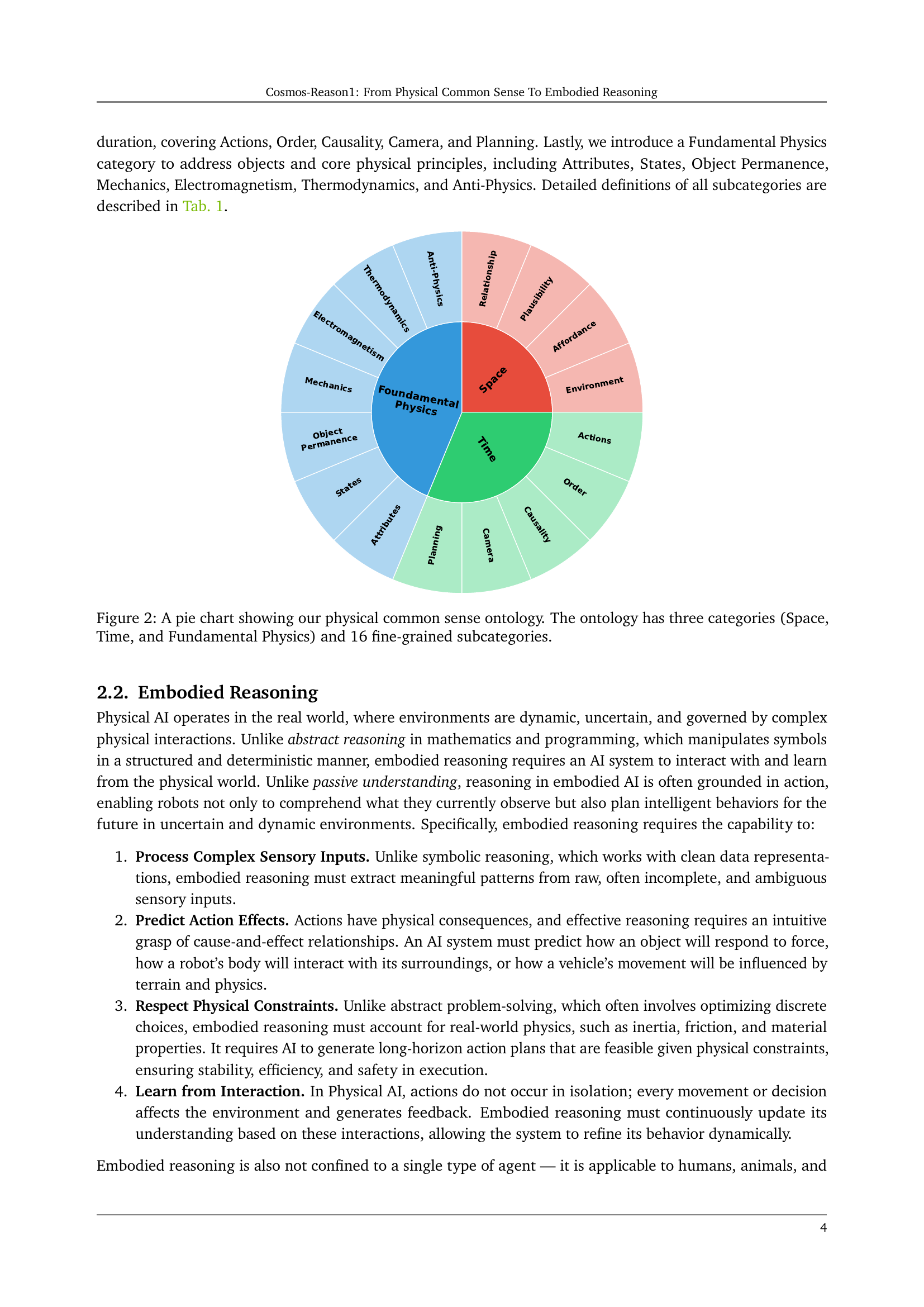
TL;DR#
Physical AI systems, vital for real-world interaction, must perceive, understand, and act. Current large language models (LLMs) struggle to ground knowledge in the physical world. Addressing this, the research defines key capabilities for Physical AI, focusing on physical common sense and embodied reasoning. They use ontologies for space, time, physics, and embodied understanding. This leads to models to understand and embodied decisions.
The research presents Cosmos-Reason1 models, trained via vision pre-training, supervised fine-tuning (SFT), and reinforcement learning (RL). The models are evaluated using newly built benchmarks for physical common sense and embodied reasoning. Results show Physical AI SFT and RL yields significant improvements. Code and pre-trained models will be available to boost Physical AI development.
Key Takeaways#
Why does it matter?#
This research presents Cosmos-Reason1, offering benchmarks to propel research in physical AI. It enables more capable AI by improving reasoning about space, time, and physics. This paper inspires new research directions with code and models.
Visual Insights#

🔼 Cosmos-Reason1 is composed of two large multimodal language models (8B and 56B parameters). These models are trained in four stages: 1) vision pre-training, 2) general supervised fine-tuning (SFT), 3) Physical AI SFT, and 4) Physical AI reinforcement learning (RL). The training process leverages two ontologies: one for physical common sense and one for embodied reasoning. Three benchmarks are used to evaluate the model’s Physical AI reasoning abilities.
read the caption
Figure 1: An overview of Cosmos-Reason1. Cosmos-Reason1 contains two multimodal large language models of 8B and 56B, trained in four stages, including vision pre-training, general SFT, Physical AI SFT, and Physical AI RL. We also define two ontologies for physical common sense and embodied reasoning, and build three benchmarks to evaluate models’ Physical AI reasoning capabilities.
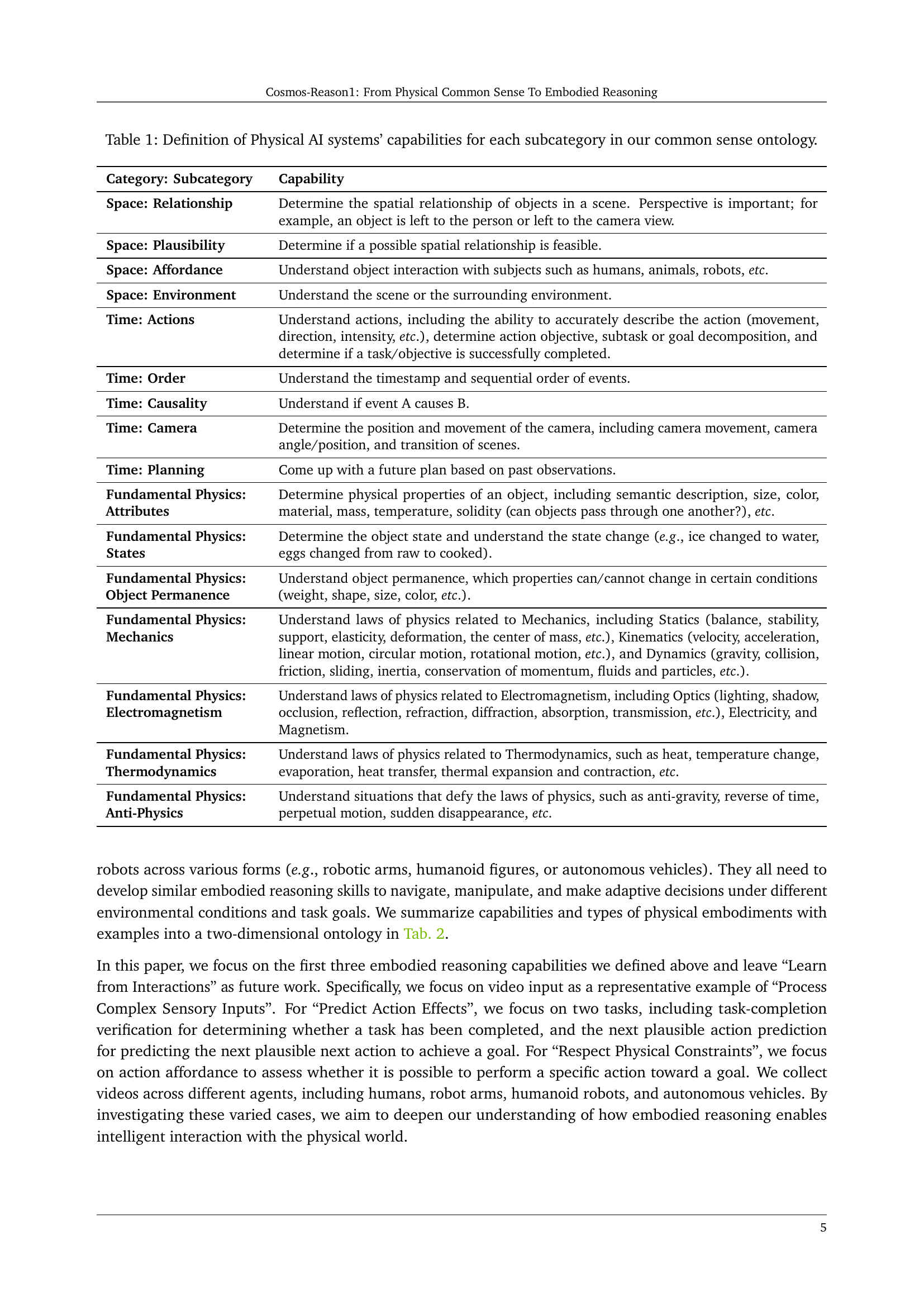
| Category: Subcategory | Capability |
| Space: Relationship | Determine the spatial relationship of objects in a scene. Perspective is important; for example, an object is left to the person or left to the camera view. |
| Space: Plausibility | Determine if a possible spatial relationship is feasible. |
| Space: Affordance | Understand object interaction with subjects such as humans, animals, robots, \etc. |
| Space: Environment | Understand the scene or the surrounding environment. |
| Time: Actions | Understand actions, including the ability to accurately describe the action (movement, direction, intensity, \etc.), determine action objective, subtask or goal decomposition, and determine if a task/objective is successfully completed. |
| Time: Order | Understand the timestamp and sequential order of events. |
| Time: Causality | Understand if event A causes B. |
| Time: Camera | Determine the position and movement of the camera, including camera movement, camera angle/position, and transition of scenes. |
| Time: Planning | Come up with a future plan based on past observations. |
| Fundamental Physics: Attributes | Determine physical properties of an object, including semantic description, size, color, material, mass, temperature, solidity (can objects pass through one another?), \etc. |
| Fundamental Physics: States | Determine the object state and understand the state change (\eg, ice changed to water, eggs changed from raw to cooked). |
| Fundamental Physics: Object Permanence | Understand object permanence, which properties can/cannot change in certain conditions (weight, shape, size, color, \etc.). |
| Fundamental Physics: Mechanics | Understand laws of physics related to Mechanics, including Statics (balance, stability, support, elasticity, deformation, the center of mass, \etc), Kinematics (velocity, acceleration, linear motion, circular motion, rotational motion, \etc), and Dynamics (gravity, collision, friction, sliding, inertia, conservation of momentum, fluids and particles, \etc). |
| Fundamental Physics: Electromagnetism | Understand laws of physics related to Electromagnetism, including Optics (lighting, shadow, occlusion, reflection, refraction, diffraction, absorption, transmission, \etc), Electricity, and Magnetism. |
| Fundamental Physics: Thermodynamics | Understand laws of physics related to Thermodynamics, such as heat, temperature change, evaporation, heat transfer, thermal expansion and contraction, \etc. |
| Fundamental Physics: Anti-Physics | Understand situations that defy the laws of physics, such as anti-gravity, reverse of time, perpetual motion, sudden disappearance, \etc. |
🔼 This table details the specific capabilities expected of a Physical AI system within the context of common sense reasoning. It breaks down the three main categories of physical common sense (Space, Time, Fundamental Physics) into sixteen subcategories. Each subcategory lists a specific capability that a successful Physical AI system should demonstrate. For example, under the ‘Space’ category, the ‘Relationship’ subcategory defines the capability to ‘Determine the spatial relationship of objects in a scene.’ This provides a detailed framework for evaluating and measuring the level of physical common sense understanding in Physical AI models.
read the caption
Table 1: Definition of Physical AI systems’ capabilities for each subcategory in our common sense ontology.
In-depth insights#
Physical AI#
Physical AI represents a paradigm shift, moving beyond abstract data processing towards embodied intelligence capable of interacting with the real world. This necessitates endowing AI systems with physical common sense and embodied reasoning, enabling them to understand how the world operates under the laws of physics and how actions affect the environment. Crucially, it’s not about mimicking humans; rather, it’s about creating adaptable agents that can achieve goals despite physical constraints and uncertain dynamics. Embodied reasoning requires processing complex sensory inputs, predicting the effects of actions, respecting physical constraints, and continuously learning from interactions. The focus shifts from passive understanding to active engagement, empowering AI systems to reason about and plan behaviors in the real world.
Cosmos-Reason1#
Cosmos-Reason1, as presented, marks a significant stride in the field of Physical AI by tackling the crucial need for grounded reasoning in embodied agents. The paper’s focus on integrating physical common sense and embodied reasoning capabilities into large language models is particularly noteworthy. By defining specific ontologies for space, time, physics, and agent interaction, Cosmos-Reason1 offers a structured framework for developing and evaluating Physical AI systems. The emphasis on learning from visual data, especially videos, is relevant, reflecting the real-world perception challenges. Reinforcement learning with rule-based rewards further refines the model’s decision-making. This represents a holistic approach, considering both knowledge representation and action planning. Also, building benchmarks are useful ways to validate the data and methodology. The framework facilitates improvements by offering code and models. The introduction of a hybrid Mamba-MLP-Transformer is the highlight of the research.
Ontology design#
From the paper, it can be understood that the ontology design focuses on physical common sense and embodied reasoning, forming a hierarchical structure for representing knowledge about space, time, and physics. This design might involve identifying key entities, relationships, and axioms relevant to how AI agents interact with the physical world. A crucial aspect of this ontology is capturing the affordances of objects and how agents can manipulate them to achieve goals. The success hinges on structuring the ontology in a way that enables efficient reasoning and planning for embodied agents. A potential challenge lies in designing an ontology that is both comprehensive and computationally tractable. An effective ontology would enable AI systems to effectively reason about the physical world
RL Post-Training#
RL post-training is a crucial step in refining models for complex tasks. It leverages rule-based, verifiable rewards, improving capabilities like reasoning and physical common sense. Unlike math/coding, physical AI has open-ended responses. Transforming data into multiple-choice questions (MCQs) facilitates reward assignment. This involves a 5-step process: 1) Video Curation, 2) Detailed Captioning, 3) QA pair prompting, 4) Extracting Reasoning Traces from models such as DeepSeek-R1 and 5) Cleaning & Rewriting data. RL post-training emphasizes equal data representation, dynamic MCQ shuffling, and specific reward types like accuracy and format rewards. This strategy enhances reasoning without human intervention, improving capabilities with reasoning about space, time, and intuitive physics.
Intuitive physics#
Intuitive physics represents a crucial aspect of AI, enabling systems to understand how the world functions. This involves reasoning about space, time, and object permanence. Existing models often struggle with these tasks, showcasing limitations in capturing the physical world’s dynamics. Datasets and methods focusing on intuitive physics reasoning become essential. Models excelling at these tasks hold promise for creating more robust and reliable AI systems that can effectively interact with their surroundings. This capability is vital for the advancement of embodied AI.
More visual insights#
More on figures

🔼 This pie chart illustrates the hierarchical ontology developed for representing physical common sense within the Cosmos-Reason1 model. The ontology is structured into three main categories: Space, Time, and Fundamental Physics. Each of these high-level categories is further broken down into more specific subcategories (16 in total) which capture detailed aspects of physical understanding. For instance, the ‘Space’ category includes subcategories such as ‘Relationship’ (describing spatial relationships between objects), ‘Plausibility’ (assessing the feasibility of spatial arrangements), ‘Affordance’ (considering how objects can be used or interacted with), and ‘Environment’ (understanding the context of the surrounding area). Similarly, ‘Time’ is subdivided into concepts such as ‘Actions’, ‘Order’, ‘Causality’, and ‘Planning’, representing various temporal relationships and reasoning capabilities. The ‘Fundamental Physics’ category covers essential physical principles, including aspects of mechanics, electromagnetism, and thermodynamics, along with the crucial concept of ‘Object Permanence.’
read the caption
Figure 2: A pie chart showing our physical common sense ontology. The ontology has three categories (Space, Time, and Fundamental Physics) and 16 fine-grained subcategories.

🔼 The figure illustrates the architecture of the Cosmos-Reason1 multimodal large language model. The process begins with an input video and a text prompt. The video is first processed by a vision encoder, which extracts relevant visual features. These features are then projected into the LLM’s token embedding space using a projector, converting them into a format compatible with the text tokens from the prompt. The video tokens and text tokens are concatenated and fed into the core of the model: a hybrid Mamba-MLP-Transformer architecture. This architecture is designed for efficient and effective processing of long sequences of tokens, enabling the model to engage in long chain-of-thought reasoning processes to generate its output. The final output is a natural language response that incorporates the information from both the video and the text prompt.
read the caption
Figure 3: An illustration of our multimodal large language model architecture. Given an input video and an input text prompt, the video is projected into the LLM’s token embedding space as video tokens by a vision encoder followed by a projector. The text tokens are concatenated with the video tokens and fed into the LLM backbone, a hybrid Mamba-MLP-Transformer architecture. Our model can output responses with long chain-of-thought reasoning processes.

🔼 This figure details the architecture of the Cosmos-Reason1 models’ backbone, a hybrid Mamba-MLP-Transformer. The diagram shows how Transformer blocks (composed of self-attention and MLP layers) are combined with alternating Mamba-MLP modules for efficiency. The middle section illustrates the 8B parameter model, while the bottom shows the architecture of the larger 56B parameter model. The Mamba modules are designed to improve the efficiency of processing long sequences.
read the caption
Figure 4: An illustration of our hybrid Mamba-MLP-Transformer backbone architecture. The middle sub-figure represents the 8B LLM backbone, and the bottom sub-figure depicts the 56B LLM backbone. A Transformer block consists of a self-attention layer and an MLP layer. We also show an example of Alternating Mamba-MLP module on top of the figure.

🔼 This figure shows an overview of the Cosmos-Reason1 model architecture. The input is a video, processed through a vision encoder and a projector to align with the text embeddings of a pre-trained large language model (LLM). The model is trained in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL). Two ontologies are used to represent physical common sense and embodied reasoning, and the model is evaluated on three benchmarks.
read the caption
(a)

🔼 This figure is a pie chart illustrating the hierarchical ontology for physical common sense used in the Cosmos-Reason1 model. The ontology categorizes fundamental knowledge about the physical world into three main categories: Space, Time, and Fundamental Physics. Each of these categories is further subdivided into more specific subcategories, representing fine-grained aspects of physical understanding. For example, ‘Space’ includes subcategories like ‘Relationship,’ ‘Plausibility,’ and ‘Affordance,’ reflecting different aspects of spatial reasoning. Similarly, ‘Time’ encompasses subcategories such as ‘Actions,’ ‘Order,’ and ‘Causality,’ while ‘Fundamental Physics’ incorporates concepts like ‘Mechanics,’ ‘Electromagnetism,’ and ‘Thermodynamics.’
read the caption
(b)

🔼 This figure shows example video frames from the Physical AI Supervised Fine-Tuning datasets. The images depict various scenarios involving different agents (humans, robots) performing actions in real-world environments. These examples illustrate the diversity and complexity of the data used to train the Cosmos-Reason1 models on physical common sense and embodied reasoning.
read the caption
(c)

🔼 This figure shows an example of video frames from the Physical AI Supervised Fine-tuning datasets. The images depict various scenarios involving different embodied agents (such as robots and humans) performing different tasks in real-world environments. These videos are used in the Physical AI SFT stage of training the Cosmos-Reason1 model to help it learn physical common sense and develop embodied reasoning capabilities.
read the caption
(d)

🔼 This figure shows an example of video frames from the Physical AI Supervised Fine-tuning datasets. It highlights the diversity of scenarios and tasks included in the dataset, encompassing various activities and agent types relevant to physical AI, such as robotic manipulation and autonomous driving. The images represent a small subset of the larger dataset used to train the models.
read the caption
(e)

🔼 This figure shows an example of video frames from the Physical AI Supervised Fine-Tuning datasets. These datasets were used to enhance the model’s ability to understand Physical AI-specific tasks, focusing on embodied reasoning capabilities such as understanding the spatial relationships between objects, the temporal order of events, and object permanence. The images illustrate the visual diversity captured within the data, showcasing a variety of actions and contexts that the model must reason about to successfully complete Physical AI tasks.
read the caption
(f)

🔼 Figure 5 presents example video frames from the Physical AI Supervised Fine-Tuning stage of the Cosmos-Reason1 model training. These diverse video clips showcase various scenarios used to train the model in understanding and reasoning about physical phenomena. The visual examples highlight the real-world contexts and diverse physical actions the model is trained on, demonstrating the wide range of physical situations represented in the dataset.
read the caption
Figure 5: Example of video frames from our Physical AI supervised fine-tuning datasets.

🔼 Figure 6 illustrates the data curation pipeline for embodied reasoning within the context of Physical AI. The example focuses on the AgiBot dataset. The process begins by extracting short video segments that represent individual subtasks from a longer video. These clips are then annotated with captions that provide detailed context about the state of the scene and the actions taken by the agent. Next, question-answer pairs are generated, focusing on predicting the most probable next subtask. The question and caption are provided as input to the DeepSeek-R1 model, which then generates a reasoning trace (a chain of thought) to answer the question. Finally, this reasoning trace is cleaned and rewritten to create high-quality supervised fine-tuning (SFT) samples.
read the caption
Figure 6: Embodied reasoning SFT data curation pipeline. We demonstrate an illustrative example for AgiBot, where we (1) extract short horizon segments corresponding to the subtask, (2) caption the extracted clip to obtain state-action context, (3) curate QA pairs for “next plausible subtask prediction”, (4) prompt R1 with the question and caption to elicit reasoning, (5) clean and rewrite the reasoning trace to obtain valid SFT samples.
More on tables
| Natural Agents (humans, animals) | Robotics Systems (robot arms, humanoid robots, autonomous vehicles) | |
| Process Complex Sensory Inputs | A person watches videos about a cooking recipe. A bat locates prey using echolocation. | A robot arm recognizes objects using its camera. A robot detects obstacles while walking. A self-driving car recognizes a stop sign and pedestrians. |
| Predict Action Effects | A carpenter anticipates wood splintering before cutting. A dog estimates a ball’s landing spot to catch it. | A robotic arm compensates for momentum before gripping an object. A robot estimates an object’s weight before lifting it. A self-driving car predicts tire slippage on ice. |
| Respect Physical Constraints | A pilot maintains altitude within aerodynamic limits. A cheetah limits speed to avoid muscle strain. | A robotic gripper limits its force to prevent breaking objects. A robot adjusts joint torque to prevent falls. A drone avoids exceeding wind resistance thresholds. |
| Learn from Interactions | A golfer corrects their stance after observing ball trajectory. A dog learns to open doors through repeated attempts. | A factory robot improves alignment after detecting misplacements. A robot learns new handshakes. A self-driving car refines braking distances. |
🔼 This table presents an ontology for embodied reasoning in Physical AI systems. It categorizes key capabilities essential for embodied reasoning (processing complex sensory inputs, predicting action effects, respecting physical constraints, and learning from interactions) and illustrates them with examples across various agent types (natural agents like humans and animals, and robotic systems like robot arms, humanoid robots, and autonomous vehicles). Each cell shows a specific example of how the capability is demonstrated by the corresponding agent type.
read the caption
Table 2: Embodied reasoning ontology, with an example for each combination of capability and agent type.
| Configuration | Cosmos-Reason1-8B | Cosmos-Reason1-56B |
| Vision Encoder | ||
| Architecture | ViT-300M | ViT-300M |
| Input Size | ||
| Patch Size | ||
| Number of Layers | ||
| Model Dimension | ||
| FFN Hidden Dimension | ||
| Projector | ||
| Downsampling | ||
| Number of Layers | ||
| Input Dimension | ||
| Hidden Dimension | ||
| Output Dimension | ||
| LLM Backbone | ||
| Architecture | Mamba-MLP-Transformer | Mamba-MLP-Transformer |
| Number of Layers | ||
| Model Dimension | ||
| FFN Hidden Dimension | ||
| Number of Attention Heads | ||
🔼 This table presents a detailed comparison of the architectural configurations for the two Cosmos-Reason1 models: Cosmos-Reason1-8B and Cosmos-Reason1-56B. It breaks down the specifications of each model’s vision encoder, projector, and LLM backbone. Specifically, it lists the architecture type, input and output dimensions, number of layers, hidden dimensions, and other relevant hyperparameters for each component. This allows for a comprehensive understanding of the differences in model size and complexity between the two variants.
read the caption
Table 3: Configuration details of Cosmos-Reason1 models.
| Physical Common Sense VQA | Embodied Reasoning | Intuitive Physics | |||||||||
| Free-form | MCQ | BridgeData V2 | RoboVQA | Agibot | HoloAssist | AV | Puzzle | AoT | Object Permanence | Total | |
| Understanding | 99K | 1.2M | 129.5K | 221.9K | 19.8K | 136.7K | 12.4K | - | - | - | 1.82M |
| Reasoning | 59.4K | 605K | 129.5K | 930K | 19.8K | 136.7K | 12.4K | 11K | 30K | 10k | 1.94M |
🔼 This table presents a summary of the datasets used for training the Physical AI Supervised Fine-Tuning stage of the Cosmos-Reason1 model. It breaks down the data by category (Physical Common Sense VQA, Embodied Reasoning, and Intuitive Physics), indicating the number of samples (free-form and multiple-choice questions) used for both understanding and reasoning annotations. It also specifies the sources from which data is obtained (e.g. BridgeData V2, RoboVQA, etc.). This detailed breakdown helps understand the composition and scale of data used in training the model to reason about Physical AI.
read the caption
Table 4: A summary of datasets used for physical AI supervised fine-tuning.
| Common Sense | Embodied Reasoning | Intuitive Physics | ||||||||
| MCQ | BridgeData V2 | RoboVQA | Agibot | HoloAssist | AV | Puzzle | AoT | Object Permanence | Total | |
| Reasoning | 5,133 | 240 | 250 | 200 | 200 | 200 | 3,998 | 9,994 | 10,087 | 30,302 |
🔼 This table presents the datasets used for the Physical AI Reinforcement Learning phase of the Cosmos-Reason1 model training. It breaks down the number of samples used for training in several categories: Physical Common Sense (MCQs and free-form questions), Embodied Reasoning (data from various sources like BridgeData V2, RoboVQA, etc.), and Intuitive Physics (data for spatial puzzles, arrow-of-time, and object permanence). The numbers represent the count of samples prepared for reinforcement learning in each category. This data is crucial in understanding the composition of the training data for this stage of model development, showing how different types of physical reasoning tasks were weighted.
read the caption
Table 5: Datasets for Physical AI reinforcement learning post-training.
| Common Sense | Embodied Reasoning | ||||||
| MCQ | BridgeData V2 | RoboVQA | RoboFail | Agibot | HoloAssist | AV | Total |
| 604 | 100 | 110 | 100 | 100 | 100 | 100 | 1214 |
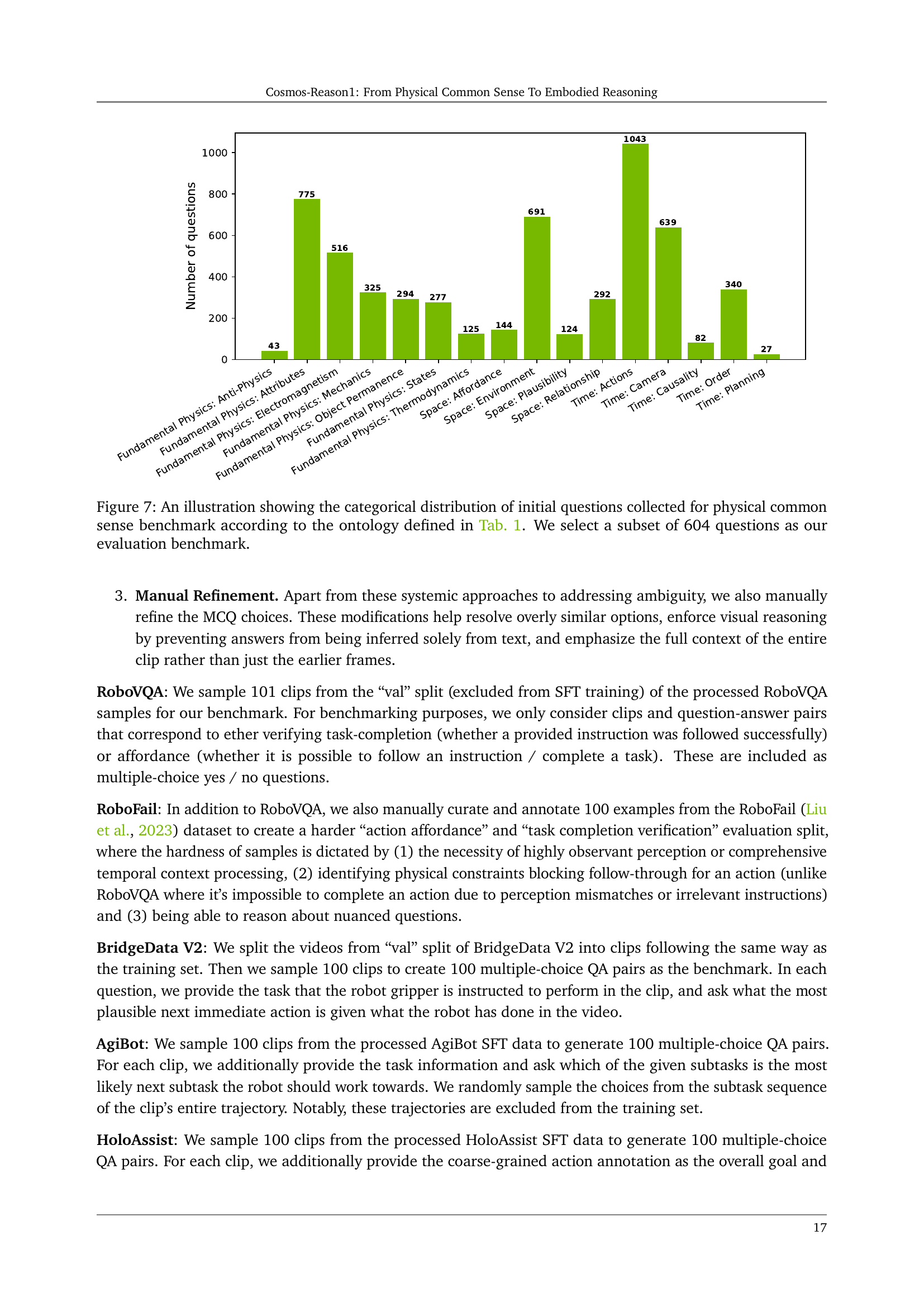
🔼 This table presents a statistical overview of the benchmarks used in the paper to evaluate the performance of the Cosmos-Reason1 models. It breaks down the number of questions and videos included in both the physical common sense and embodied reasoning benchmark sets. For common sense, it shows the distribution of questions across Space, Time, and Fundamental Physics categories. The embodied reasoning section details the number of questions and videos across various datasets and agent types (robot arms, autonomous vehicles, etc.).
read the caption
Table 6: Statistics of our curated benchmarks.
| Methods | Space | Time | Other Physics | Avg. |
| Qwen2.5-VL-7B | 48.8 | 56.4 | 37.2 | 47.4 |
| Qwen2.5-VL-72B | 53.8 | 59.1 | 51.8 | 54.9 |
| Gemini 2.0 Flash | 53.8 | 50.0 | 46.9 | 50.2 |
| GPT-4o | 61.3 | 54.7 | 50.9 | 55.6 |
| OpenAI o1 | 63.8 | 58.1 | 58.0 | 59.9 |
| 8B pre-trained backbone | 40.0 | 54.0 | 42.0 | 45.4 |
| 56B pre-trained backbone | 61.3 | 68.1 | 45.1 | 58.2 |
| Cosmos-Reason1-8B | 55.0 | 57.4 | 44.9 | 52.3 (+6.9) |
| Cosmos-Reason1-56B | 61.3 | 65.5 | 53.9 | 60.2 (+2.0) |
🔼 This table presents the results of evaluating various models on a physical common sense benchmark. It compares the performance of Cosmos-Reason1-8B and Cosmos-Reason1-56B to several other leading language models (OpenAI 01, Qwen2.5-VL-7B, Qwen2.5-VL-72B, and Gemini 2.0 Flash) across three sub-benchmarks focusing on different aspects of physical common sense: Space, Time, and Fundamental Physics. The table shows the accuracy of each model on each sub-benchmark, demonstrating the effectiveness of the Cosmos-Reason1 models, particularly the 56B variant, in this domain.
read the caption
Table 7: Evaluation on physical common sense benchmark.
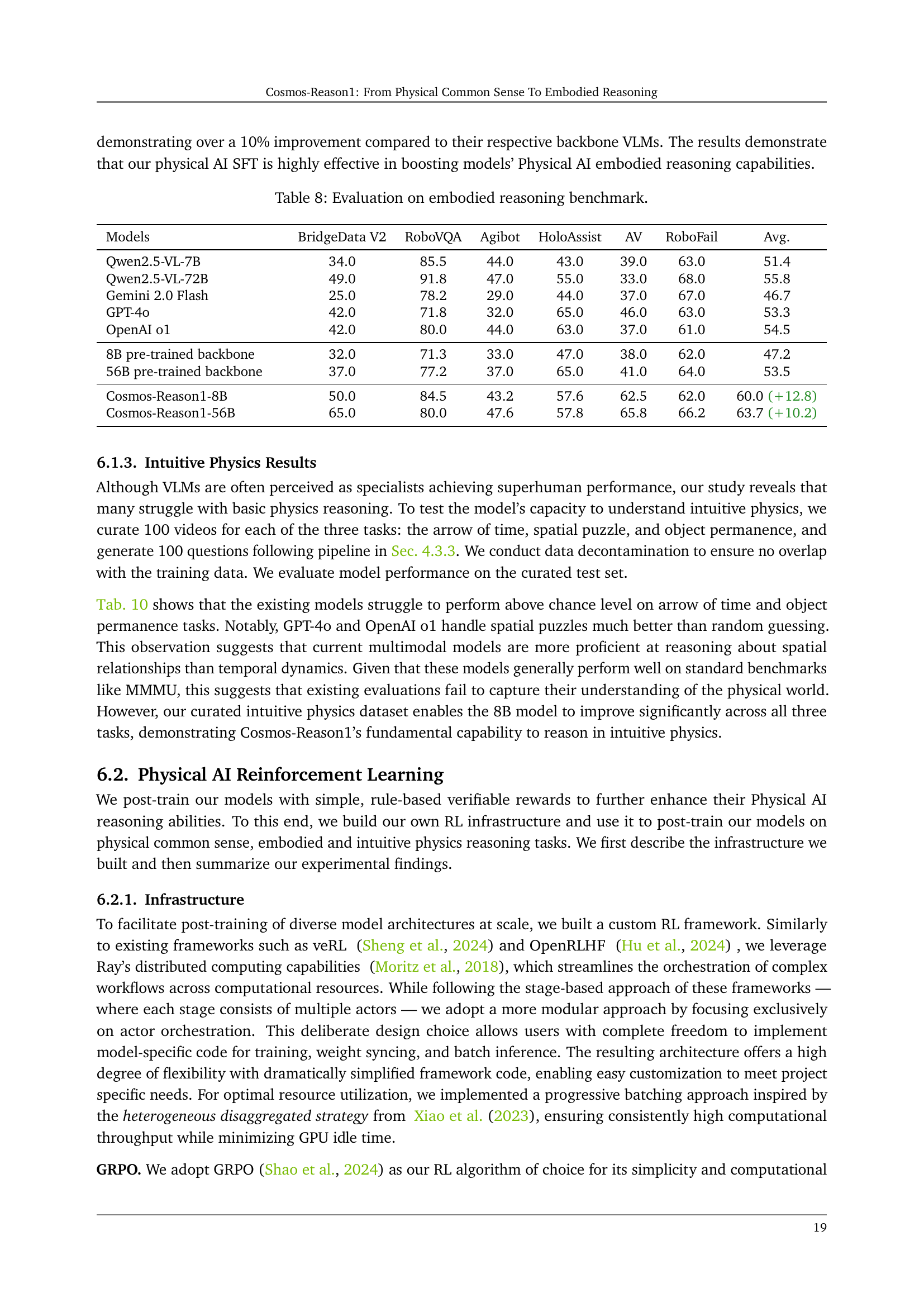
| Models | BridgeData V2 | RoboVQA | Agibot | HoloAssist | AV | RoboFail | Avg. |
| Qwen2.5-VL-7B | 34.0 | 85.5 | 44.0 | 43.0 | 39.0 | 63.0 | 51.4 |
| Qwen2.5-VL-72B | 49.0 | 91.8 | 47.0 | 55.0 | 33.0 | 68.0 | 55.8 |
| Gemini 2.0 Flash | 25.0 | 78.2 | 29.0 | 44.0 | 37.0 | 67.0 | 46.7 |
| GPT-4o | 42.0 | 71.8 | 32.0 | 65.0 | 46.0 | 63.0 | 53.3 |
| OpenAI o1 | 42.0 | 80.0 | 44.0 | 63.0 | 37.0 | 61.0 | 54.5 |
| 8B pre-trained backbone | 32.0 | 71.3 | 33.0 | 47.0 | 38.0 | 62.0 | 47.2 |
| 56B pre-trained backbone | 37.0 | 77.2 | 37.0 | 65.0 | 41.0 | 64.0 | 53.5 |
| Cosmos-Reason1-8B | 50.0 | 84.5 | 43.2 | 57.6 | 62.5 | 62.0 | 60.0 (+12.8) |
| Cosmos-Reason1-56B | 65.0 | 80.0 | 47.6 | 57.8 | 65.8 | 66.2 | 63.7 (+10.2) |
🔼 This table presents the performance comparison of different models on an embodied reasoning benchmark. The benchmark evaluates models’ ability to perform tasks requiring physical reasoning across different agent types (humans, robot arms, humanoid robots, autonomous vehicles). Each model’s accuracy is reported for six different sub-benchmarks (BridgeData V2, RoboVQA, Agibot, HoloAssist, AV, RoboFail), providing a comprehensive evaluation of their embodied reasoning capabilities. The average accuracy across all six sub-benchmarks is also included for each model.
read the caption
Table 8: Evaluation on embodied reasoning benchmark.
| Models | Common Sense | BridgeData V2 | RoboVQA | Agibot | HoloAssist | AV | RoboFail | Avg. |
| Cosmos-Reason1-8B | 52.3 | 50.0 | 84.5 | 43.2 | 57.6 | 62.5 | 62.0 | 58.9 |
| + Physical AI RL | 55.1 | 66.4 | 88.2 | 50.4 | 72.2 | 76.4 | 61.2 | 67.1 (+8.2) |
🔼 This table presents the results of evaluating the Cosmos-Reason1 models (8B and 56B) and several other models on benchmarks designed to assess physical common sense and embodied reasoning capabilities. It shows the accuracy of each model on various sub-tasks within those benchmarks, providing a comparison of the performance of Cosmos-Reason1 to other state-of-the-art models.
read the caption
Table 9: Evaluation on physical common sense and embodied reasoning benchmark.
| Models | Arrow of Time | Spatial Puzzle | Object Permanence | Avg. |
| Random Guess | 50.0 | 25.0 | 50.0 | 41.7 |
| Gemini 2.0 Flash | 50.0 | 31.0 | 48.0 | 43.0 |
| GPT-4o | 50.0 | 77.0 | 48.0 | 58.3 |
| OpenAI o1 | 51.0 | 64.0 | 49.0 | 54.7 |
| 8B pre-trained backbone | 50.0 | 27.6 | 49.2 | 42.3 |
| Cosmos-Reason1-8B | 57.0 | 85.2 | 54.8 | 65.7 (+23.4) |
| + Physical AI RL | 56.7 | 87.0 | 62.0 | 68.7 (+3.0) |
🔼 This table presents the results of evaluating various models on three intuitive physics tasks: Arrow of Time, Spatial Puzzles, and Object Permanence. The evaluation measures each model’s ability to reason about the direction of time in a video, solve spatial puzzles by identifying correctly ordered image patches, and reason about object permanence in the context of occlusions. The table compares the performance of several existing LLMs and VLMs against Cosmos-Reason1, both before and after RL fine-tuning, highlighting the impact of the model’s training on these fundamental physical reasoning abilities.
read the caption
Table 10: Evaluation on intuitive physics benchmark.
Full paper#