TL;DR#
Creating animatable head avatars usually needs lots of training data. A natural way to fix this is by using existing methods that don’t need data, like pre-trained diffusion models with score distillation sampling (SDS). But, directly making 4D avatars from video diffusion often leads to results that are too smooth because of spatial and temporal inconsistencies. This paper aims to solve this problem.
The paper introduces “Zero-1-to-A”, a method that creates a spatial and temporal consistency dataset for 4D avatar reconstruction using video diffusion. Zero-1-to-A iteratively builds video datasets and optimizes animatable avatars, making sure avatar quality improves smoothly. It uses two learning stages: Spatial Consistency Learning (fixes expressions, learns from front-to-side views) and Temporal Consistency Learning (fixes views, learns from relaxed to exaggerated expressions).
Key Takeaways#
Why does it matter?#
This paper is important because it provides a robust and data-efficient solution for creating lifelike head avatars, a key component for AR/VR, films, and games. It addresses the critical challenge of reducing data requirements, making avatar creation more accessible. The innovative method also has a high potential for future research of 3D avatar synthesis and manipulation.
Visual Insights#

🔼 This figure illustrates the difference between using only score distillation sampling (SDS) loss and the proposed Zero-1-to-A method for 4D avatar generation from video diffusion. (a) shows the over-smoothed results from directly applying SDS loss, highlighting the spatial and temporal inconsistencies of video diffusion outputs. (b) shows how Zero-1-to-A addresses these issues by creating a consistent dataset through iterative updates. This dataset caches video diffusion results, improving consistency and creating a mutually beneficial relationship between avatar generation and dataset refinement.
read the caption
Figure 1: 4D Avatar generation with SDS loss [58] and our Zero-1-to-A. Video diffusion often suffers from spatial and temporal inconsistencies. (a) The SDS loss, aligning avatar with output from video diffusion, produces over-smooth results. (b) Zero-1-to-A addresses this issue by synthesizing spatially and temporally consistent datasets for avatar reconstruction. It introduces an updatable dataset to cache video diffusion results and establishes a mutually beneficial relationship between avatar generation and dataset construction to further enhance consistency.
| CLIP-Score | ViT-L/14 | ViT-B/16 | ViT-B/32 |
|---|---|---|---|
| DreamFusion [58] | 0.244 | 0.302 | 0.300 |
| LatentNeRF [54] | 0.248 | 0.299 | 0.303 |
| Fantasia3D [12] | 0.267 | 0.304 | 0.300 |
| ProlificDreamer [71] | 0.268 | 0.320 | 0.308 |
| HeadSculpt [23] | 0.264 | 0.306 | 0.305 |
| HeadArtist [44] | 0.272 | 0.318 | 0.313 |
| HeadStudio [90] | 0.275 | 0.322 | 0.317 |
| Ours | 0.285 | 0.320 | 0.322 |
🔼 This table presents a quantitative evaluation of different methods for generating head avatars. The coherence between generated avatar images and their corresponding text descriptions is assessed using three different CLIP (Contrastive Language–Image Pre-training) models: ViT-L/14, ViT-B/16, and ViT-B/32. Higher scores indicate stronger coherence, signifying better alignment between the generated visual content and its textual description.
read the caption
Table 1: Quantitative Evaluation. Evaluating the coherence of generations with their caption using different CLIP models.
In-depth insights#
Diffusion Dataset#
Based on the provided research paper, it appears that a key challenge in animatable head avatar generation lies in the scarcity of training data. To address this, the authors propose leveraging existing, data-free static avatar generation methods such as pre-trained diffusion models using Score Distillation Sampling (SDS). However, direct distillation of 4D avatars from video diffusion can lead to over-smoothed results due to spatial and temporal inconsistencies. The research introduces Zero-1-to-A to synthesize a spatially and temporally consistent dataset for avatar reconstruction. This novel approach incorporates an updatable dataset to cache video diffusion results, reducing inconsistencies and establishing a beneficial cycle between avatar generation and dataset construction. In essence, the ‘Diffusion Dataset’ is generated using video diffusion, aiming to provide accurate guidance for avatar reconstruction by addressing inconsistencies through symbiotic generation and progressive learning strategies.
SymGEN’s Cycle#
SymGEN’s cycle represents a fascinating approach to self-improvement in generative models. The idea of a cycle suggests a closed-loop system where the model’s output is fed back as input, enabling iterative refinement. It can be used to improve the initial data quality, which creates a positive feedback. This approach could enhance consistency across generated content. The data is constantly refined using its own generated information which results in a refined outcome. The SymGen’s cycle promotes a continuous learning to achieve lifelike avatar creation.
Progressive Learn#
The idea of progressive learning is very interesting here. It mimics a curriculum-based learning approach, where the model is first exposed to simpler scenarios and gradually progresses to more complex ones. This helps in better initialization and avoids getting stuck in local minima during training. The division into spatial and temporal consistency learning is also insightful, as it decouples the challenges and allows for a more focused approach. By first learning spatial consistency with fixed expressions and then temporal consistency with varying expressions, the model can learn more robust and consistent features. This strategy tackles the inconsistencies in video diffusion models effectively, leading to better quality avatar generation.
Avatar Fidelity#
Avatar fidelity, in the context of research papers focused on generating digital human representations, refers to the accuracy and realism with which a generated avatar mimics a real person or a desired artistic style. High avatar fidelity implies the avatar possesses a high degree of visual similarity to the reference image, capturing nuanced details in texture, geometry, and expression. Achieving high fidelity is a complex challenge, requiring solutions that overcome limitations such as over-smoothing, inconsistencies in generated videos, and capturing nuanced artistic variations. Innovations in this area often involve novel network architectures, loss functions, or learning strategies that encourage the generated avatars to closely resemble the target characteristics. Improving avatar fidelity is crucial because it directly impacts the avatar’s believability and applicability in various applications, such as virtual communication, AR/VR, and entertainment.
Beyond FLAME#
Moving “Beyond FLAME” suggests exploring avenues surpassing the limitations of the FLAME model in facial representation. This likely involves addressing its inherent constraints, such as limited expressiveness due to its blendshape-based approach and difficulty in capturing fine-grained details like wrinkles or pores. Future research could focus on integrating higher-resolution data and exploring alternative representations like neural implicit functions or 3D GANs to achieve more realistic and detailed facial avatars. Furthermore, improving control over identity and expression by disentangling these attributes in the model’s latent space would be a valuable direction. Finally, bridging the gap between static models and dynamic behavior would be essential to generate truly lifelike and animatable characters.
More visual insights#
More on figures

🔼 This figure demonstrates the Zero-1-to-A model’s ability to generate high-fidelity, animatable 4D head avatars from a single input image. The process leverages a pre-trained video diffusion model without requiring any manually annotated training data. The example shows three different individuals and their corresponding avatars, highlighting the model’s ability to capture realistic facial features and expressions and render them in real-time.
read the caption
Figure 2: Image to animatable avatars generation by Zero-1-to-A. Without manually annotated data, our method can distill high-fidelity 4D avatars with real-time rendering speed from a pre-trained video diffusion using only one image input.

🔼 The figure illustrates the SymGEN framework, a novel approach for generating 4D avatars from a single image using a pretrained video diffusion model. Unlike traditional methods that rely on separate dataset creation and avatar training, SymGEN iteratively refines both simultaneously. It starts by generating an initial dataset from the video diffusion model. Then, it uses the current avatar model to render videos, which are used to improve the dataset’s spatial and temporal consistency. This improved dataset is then used to train an updated avatar model. This cycle of dataset refinement and avatar retraining repeats, creating a mutually beneficial relationship that leads to improved avatar quality and consistency.
read the caption
Figure 3: Framework of SymGEN. Our method simultaneously builds both the dataset and avatar from scratch through video diffusion. It establishes a mutually beneficial relationship between dataset construction and avatar reconstruction, iteratively updating the synthesized dataset and training the head avatar on the updated dataset to achieve unified results.

🔼 This figure illustrates the Progressive Learning pipeline used in the Zero-1-to-A method. It shows how the model learns to create consistent avatars by starting with simpler tasks and gradually increasing complexity. The process is divided into two stages: Spatial Consistency Learning, where the model learns from frontal to side views while maintaining a consistent facial expression; and Temporal Consistency Learning, where the model learns from relaxed to exaggerated expressions while keeping the camera view fixed. This staged approach helps to mitigate inconsistencies inherent in video diffusion models, ultimately leading to higher-quality, more realistic 4D avatar generation.
read the caption
Figure 4: Pipeline of Progressive Learning. It sequences learning from simple to complex, facilitating symbiotic generation to create consistent avatars from inconsistent video diffusion. This process divides 4D avatar generation into: (1) Spatial Consistency Learning: progressing from frontal to side views with a fixed expression. (2) Temporal Consistency Learning: learn from relaxed to hyperbole expressions under a fixed camera.

🔼 This figure compares the performance of Zero-1-to-A against other state-of-the-art static head avatar generation methods. Four different subjects are shown: Doctor Strange, Two-Face (from DC Comics), Vincent van Gogh, and Black Panther (from Marvel). Each subject is represented across multiple methods, showcasing the textural and geometric details produced by each approach. Zero-1-to-A demonstrates significantly superior performance in terms of detailed texture and realistic geometry when compared to the other methods.
read the caption
Figure 5: Comparison with Static Head Avatar Generation Methods. From top to bottom: Doctor Strange, Two-Face from DC, Vincent van Gogh, and Black Panther from Marvel. Guided by image prompts, our approach captures rich details and demonstrates superior performance in texture and geometry.

🔼 This figure compares the performance of Zero-1-to-A against two other dynamic head avatar generation methods (TADA and HeadStudio). The comparison uses three example avatars, showcasing the rendering speed for each method and highlighting mouth expression artifacts in the competing methods using yellow circles. The bottom-left corner of each example shows the underlying FLAME mesh used for the avatar. The results demonstrate that Zero-1-to-A produces significantly better animation quality and achieves higher rendering speeds compared to the other methods.
read the caption
Figure 6: Comparison with Dynamic Head Avatar Generation Methods. Yellow circles highlight mouth expression artifacts. Rendering speed on the same device is shown in the black box. The FLAME mesh of the avatar is visualized bottom left. Our method excels in animation quality and rendering speed compared to prior methods.

🔼 This figure compares the results of the proposed method, Zero-1-to-A, against traditional portrait video diffusion methods for generating head avatar animations. Zero-1-to-A, which uses a symbiotic generation process, produces avatars with better 3D consistency, smoother temporal transitions between frames, and more accurate expression representation. The comparison highlights how traditional methods struggle with spatial inconsistencies (incorrect eye positions in side views) and temporal inconsistencies (significant changes in expression with minimal changes in driving signal). The green boxes highlight spatial errors and the blue boxes highlight temporal inconsistencies in the traditional methods.
read the caption
Figure 7: Comparison with Portrait Video Diffusion Methods. Symbiotic generation enhances portrait video diffusion with improved 3D consistency, temporal smoothness, and expression accuracy. In contrast, traditional portrait video diffusion shows spatial inconsistencies, noted by incorrect eye positioning in side views (green boxes), and temporal inconsistencies, highlighted by significant changes with minor facial expressions (blue boxes).

🔼 This ablation study demonstrates the importance of progressive learning in generating consistent avatars from inconsistent video diffusion data. The figure shows the results of different model variations. The ‘w/o Progressive Learning’ model highlights the lack of consistency, especially with eye and mouth positioning. The ‘w/o Spatial Consistency Learning’ model shows good mouth consistency but struggles with eyes. The ‘w/o Temporal Consistency Learning’ model displays good eye and mouth alignment in simple cases, but fails to generalize to new expressions. Only the ‘Full Model’, which incorporates progressive learning, effectively creates high-quality, consistent avatars across various expressions and views.
read the caption
Figure 8: Ablation Study. Progressive learning is crucial for creating consistent avatars from inconsistent video diffusion, with spatial consistency improving eye and mouth for effective avatar control (green boxes), and temporal consistency enhancing model generalization to new expressions (blue boxes).

🔼 This figure demonstrates the robustness of the proposed Zero-1-to-A method in handling challenging scenarios during avatar generation. The left column showcases the model’s ability to generate avatars from side-view images, maintaining accuracy and detail. The middle column shows that the method can effectively generate avatars even when the eyes are closed in the input image. Finally, the right column demonstrates the capability of Zero-1-to-A to generate high-quality avatars despite the presence of facial occlusions in the input image. Each row displays a pair of images: the driving expression (input image) and the corresponding generated avatar.
read the caption
Figure 9: Challenge Cases. Our method exhibits robustness in effectively handling side views (left), eye closure (middle), and facial occlusions (right). Each pair shows the driving expression and animation result (right), and the top row contains reference images.

🔼 The image showcases a limitation of the animatable Gaussian head model used in the paper. Specifically, because the Gaussian points are aligned to the FLAME mesh (a 3D morphable model of a human head), the model struggles to accurately represent elements that extend beyond the typical head region, such as an afro hairstyle. The inability to effectively model these extra-head features is a key limitation of the method presented in the paper.
read the caption
Figure 10: Limitation. The animatable Gaussian head [60] aligns Gaussians with the FLAME mesh, limiting the modeling of elements beyond the head.

🔼 This figure illustrates the preprocessing steps involved in preparing portrait images for use in the Zero-1-to-A model. The process begins with a portrait image containing a background. The first step is background removal using a suitable technique, resulting in an image with the subject isolated. Next, FLAME (Facial Landmark Appearance Model) parameters, including the shape and expression of the face, are estimated using an appropriate method. This provides crucial data for the avatar generation process that follows.
read the caption
Figure 11: Pre-process. Given a portrait image, we first remove its background and then estimate the FLAME parameter.

🔼 This figure compares different methods for 2D image generation using a pre-trained video diffusion model. It demonstrates the results of several approaches when generating images based on a reference image. The methods compared include Score Distillation Sampling (SDS) [58], Interval Score Matching (ISM) [42], Noise-Free Score Distillation (NFSD) [35], and the baseline video diffusion generation method [73]. The figure visually showcases the differences in generated image quality and fidelity resulting from each method compared to the original reference image. It highlights the impact of various techniques on the visual characteristics of the generated output.
read the caption
Figure 12: 2D Image Generation with SDS-based Loss. From left to right: reference image, SDS [58], ISM [42], NFSD [35] and video diffusion generation [73].

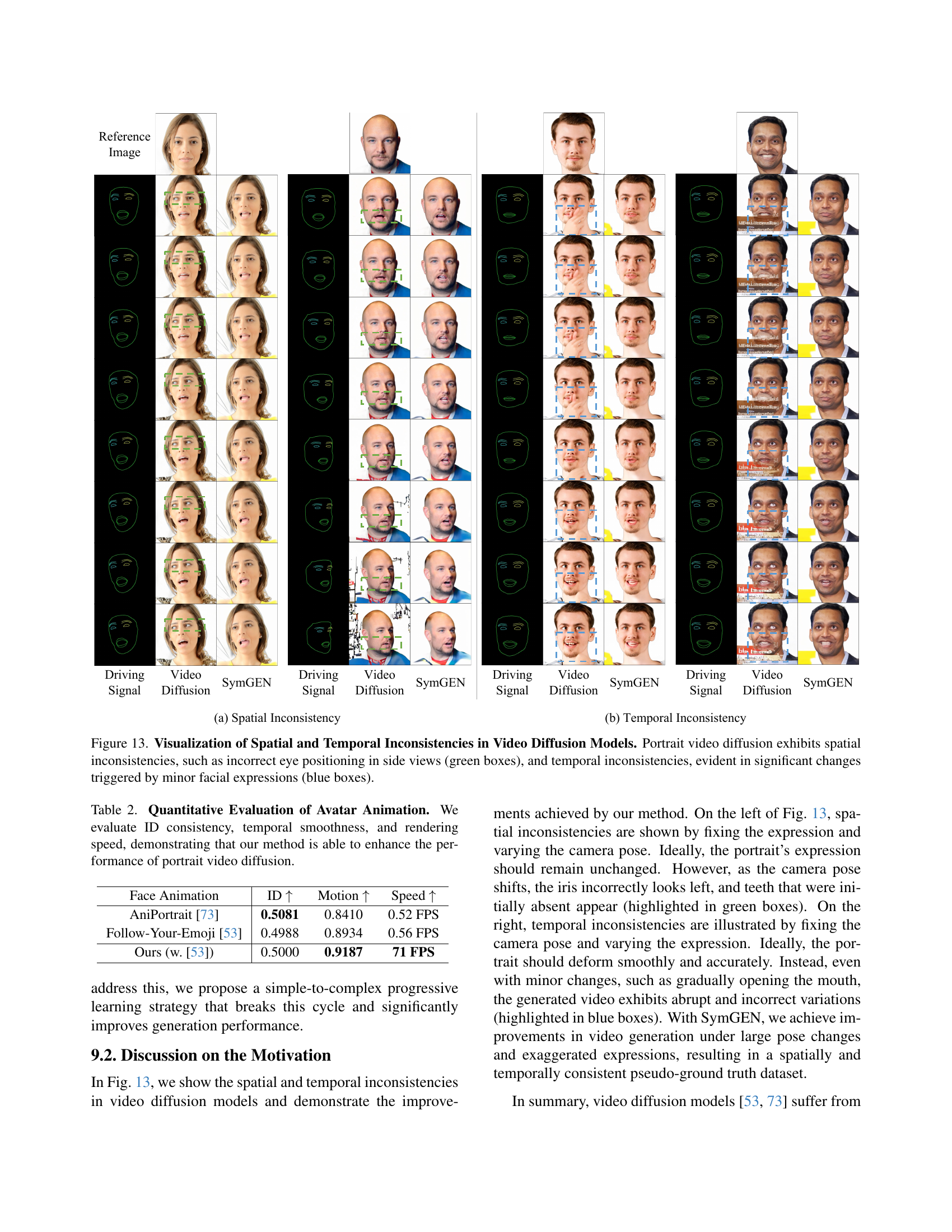
🔼 Figure 13 visualizes the spatial and temporal inconsistencies present in video diffusion models. The left side shows spatial inconsistencies where incorrect eye positioning is observed in side views (highlighted by green boxes). The right side demonstrates temporal inconsistencies where minor expression changes lead to significant variations in the generated video (highlighted by blue boxes). This figure highlights the challenges that arise when directly using the output of video diffusion models for 4D avatar generation, motivating the need for the proposed method to address these issues.
read the caption
Figure 13: Visualization of Spatial and Temporal Inconsistencies in Video Diffusion Models. Portrait video diffusion exhibits spatial inconsistencies, such as incorrect eye positioning in side views (green boxes), and temporal inconsistencies, evident in significant changes triggered by minor facial expressions (blue boxes).

🔼 Figure 14 presents a comparison of Zero-1-to-A against several state-of-the-art image-to-3D generation methods. The goal is to demonstrate Zero-1-to-A’s ability to generate high-quality 3D models from a single image. The comparison focuses on two key aspects: texture reconstruction quality and the overall 3D consistency of the resulting models. The figure visually shows that Zero-1-to-A achieves comparable results in terms of texture detail to the other methods, but it significantly outperforms them in terms of the 3D structural consistency of the generated avatar.
read the caption
Figure 14: Comparisons with Image-to-3D Methods. Our method delivers comparable performance in texture reconstruction while achieving superior 3D consistency.

🔼 Figure 15 presents a qualitative comparison of Zero-1-to-A and Portrait3D [24], highlighting that Zero-1-to-A achieves comparable quality in avatar generation while offering the additional capability of creating animatable avatars, thus expanding the range of potential applications.
read the caption
Figure 15: Comparisons with Portrait3D [24]. Our method matches the performance of Portrait3D while providing animatable avatars, enabling a wider range of applications.

🔼 This figure shows the results of applying the Zero-1-to-A method to different video diffusion models. It demonstrates the robustness and adaptability of the method by showing that it produces high-quality, animatable avatars regardless of which underlying video diffusion model is used. The consistency in the results across different models highlights a key strength of the Zero-1-to-A approach.
read the caption
Figure 16: Evaluation on Different Video Diffusion Models. Our method demonstrates its effectiveness by seamlessly adapting to various video diffusion models.

🔼 This figure showcases the robustness of the Zero-1-to-A model by testing its performance on a diverse range of real-world images from the FFHQ dataset. The images represent individuals with varying ethnicities, ages, genders, and facial features. The results demonstrate that the model generalizes well across different demographics, maintaining high-quality avatar generation. Each column shows the reference image and the generated avatar from different expressions. The diversity in the individuals tested highlights the model’s ability to handle in-the-wild scenarios.
read the caption
Figure 17: Evaluation on in-the-wild Cases.
Full paper#