TL;DR#
Generating realistic 3D scenes from text is gaining momentum. Current methods struggle with accurately capturing scenes due to the difficulty of jointly modeling camera poses and images. While some approaches fine-tune 2D generative models, they often face instability and modality gaps. This requires external models and refinement steps to stabilize training and inference, adding complexity and hindering seamless integration. These limitations impact the quality and efficiency of 3D scene generation, especially for unbounded real-world environments.
To tackle these issues, this paper introduces a dual-stream architecture. A dedicated pose generation model is attached alongside a pre-trained video generation model, with communication blocks. Asynchronous sampling denoises poses faster than images. It ensures cross-modal consistency, all while reducing mutual ambiguity. The model outperforms existing direct generation methods that depend on post-hoc refinement. It achieves superior results without these refinements. The results confirm the design approach to 3D generation.
Key Takeaways#
Why does it matter?#
This work is important for researchers because it introduces a novel architecture and sampling strategy for direct text-to-3D scene generation, reducing the dependency on computationally expensive post-hoc refinement methods like SDS. The proposed VideoRFSplat model opens new avenues for generating realistic and detailed 3D scenes from text prompts, advancing the field of 3D content creation and offering a more efficient alternative to existing approaches.
Visual Insights#

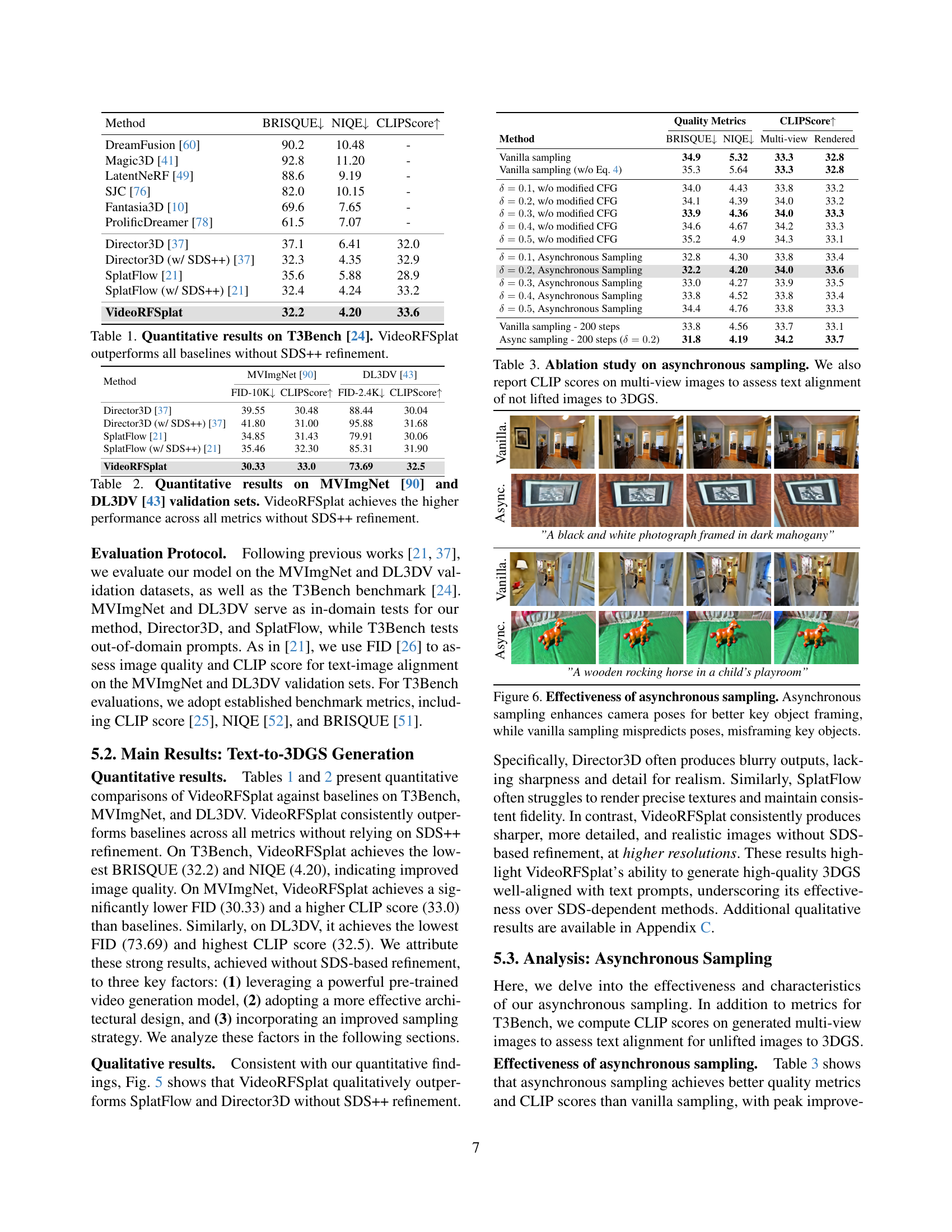
🔼 This figure demonstrates the effects of prioritizing image denoising over pose denoising in an asynchronous sampling approach for 3D scene generation. By reversing the typical strategy of faster pose denoising, the results show a significant decline in image quality and scene coherence. This highlights the importance of the chosen denoising order for stable and high-quality 3D scene generation.
read the caption
Figure A.1: Generated multi-view images from image-first asynchronous sampling. Accelerating the denoising of multi-view images, instead of the pose modality, leads to severe degeneration.
In-depth insights#
Beyond SDS Refine#
The phrase ‘Beyond SDS Refinement’ suggests a direction in 3D generative modeling that seeks to move past score distillation sampling (SDS). Current SDS methods, while effective, often require costly per-scene optimization and reliance on pretrained 2D diffusion models. The focus would likely be on direct 3D generation methods, aiming for end-to-end training and faster inference. This entails developing novel architectures or training strategies that inherently capture 3D structure and multi-view consistency. Research might explore alternative loss functions that directly optimize for 3D metrics, or innovative model designs that better leverage 3D inductive biases. A key challenge involves reducing the modality gap between 2D and 3D representations, potentially through cross-modal learning techniques or joint embeddings. Ultimately, the goal is to achieve high-quality 3D generation without the need for computationally expensive post-hoc refinements, offering a more efficient and seamless pipeline.
Dual-Stream Design#
A dual-stream design in generative modeling, particularly for complex tasks like text-to-3D scene generation, smartly addresses the challenge of balancing multiple modalities (e.g., image and pose). By dedicating separate processing pathways for each modality (streams), the architecture can minimize interference. Pre-trained models can be better leveraged, retaining their specialized knowledge. Communication between streams via cross-attention mechanisms is crucial, allowing controlled information exchange while preserving each stream’s specialized function. Asynchronous sampling further refines the process by decoupling timesteps. This allows one modality (e.g., pose) to denoise faster, providing clearer guidance to the other (image generation) and reducing ambiguity. This design is especially useful when bridging distinct data distributions, preventing one from overwhelming the other. The key lies in the strategic interaction and timing of information flow.
Asynch. Sampling#
Asynchronous sampling emerges as a crucial technique to address inherent instability in joint modeling of multi-view images and camera poses. Synchronous denoising of both modalities, especially at early timesteps, often leads to mutual ambiguity, increasing uncertainty and unstable generation. By decoupling the timesteps for pose and multi-view generation models, asynchronous sampling enables each modality to denoise at its own pace. The pose modality, being more robust, can denoise faster, reducing ambiguity and stabilizing sampling. This, coupled with asynchronous adaptation of Classifier-Free Guidance (CFG), allows clearer poses to guide multi-view image generation effectively.
Real-Scene 3DGS Gen#
Real-Scene 3DGS Generation represents a significant challenge in 3D content creation due to the complexities of unconstrained environments. Unlike object-centric approaches with controlled settings, real-world scenes exhibit diverse camera motions, unbounded spatial extents, and variations in lighting and texture. Generating 3D Gaussian Splattings (3DGS) directly from text for real scenes requires models to implicitly infer scene layout and handle complex occlusions, view synthesis and maintain consistency across multiple views. Overcoming these hurdles necessitates advanced architectures and sampling strategies to achieve photorealistic and geometrically accurate reconstructions without relying on external refinements, showcasing the potential for efficient and high-quality 3D scene synthesis.
Camera Control#
Camera Control in generative 3D models is a burgeoning area, enabling nuanced scene creation. Models often struggle with coherent viewpoints and scene-specific motions. Advanced approaches involve joint learning of multi-view images and camera trajectories, inferring scene pose implicitly from text. A key challenge lies in maintaining stability when extending 2D generative models due to the modality gap, requiring innovative techniques to ensure image and pose alignment. Dual-stream architectures and asynchronous sampling strategies, where camera poses are rapidly denoised to guide image generation, hold promise for reducing ambiguity and enhancing cross-modal consistency. Such innovations are vital for high-fidelity 3D generation capable of capturing diverse real-world scenes without manual intervention.
More visual insights#
More on figures

🔼 This figure presents a qualitative comparison of 3D scene generation results between VideoRFSplat and two other methods: Director3D and SplatFlow. Each method is used to generate 3D scenes from the same text prompts. The generated scenes from each method are visually compared to highlight the differences in realism and detail. Notably, VideoRFSplat produces more realistic scenes without needing a post-processing refinement step called SDS++, unlike the other two methods. This demonstrates that VideoRFSplat’s direct generation approach is superior in terms of visual quality.
read the caption
Figure A.2: Additional qualitative comparison with Director3D [li2025director3d] and SplatFlow [go2024splatflow]. Our VideoRFSplat generates more realistic scenes compared to baselines without relying on SDS++ [li2025director3d].

🔼 This figure shows eight example scenes generated by the VideoRFSplat model. Each scene is accompanied by a 3D representation of the camera positions used to render the views, and the individual images are bordered with different colors to indicate which camera viewpoint they represent. The accompanying text describes the scene depicted in the images.
read the caption
Figure A.3: Additional qualitative results.We present eight rendered scenes along with their corresponding camera poses from text prompts, with image border colors indicating the respective cameras.

🔼 This figure displays eight 3D-rendered scenes generated from text prompts using the VideoRFSplat model. Each scene is accompanied by its corresponding camera poses. The image borders are color-coded to differentiate the various camera viewpoints, enhancing understanding of the model’s multi-view generation capabilities.
read the caption
Figure A.4: Additional qualitative results.We present eight rendered scenes along with their corresponding camera poses from text prompts, with image border colors indicating the respective cameras.
Full paper#