TL;DR#
Non-factoid question-answering (NFQA) is hard because of its open-ended nature and the need for multi-aspect reasoning, making regular methods not good enough. Existing NFQA approaches don’t do well across different questions and don’t use large language models (LLMs) and retrieval-augmented generation (RAG) frameworks effectively. Standard RAG improves context but fails to handle the differences in questions, leading to responses that lack the needed multi-aspect depth.
To solve these issues, Typed-RAG is introduced. This is a type-aware multi-aspect decomposition framework for NFQA within the RAG setup. It sorts NFQs into types like debate, experience, and comparison, then uses aspect-based decomposition to improve retrieval and generation. By breaking down complex NFQs into simpler parts and combining the results, Typed-RAG makes answers more helpful and relevant.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it introduces Typed-RAG, a novel framework for NFQA, which addresses the limitations of current RAG systems. The Wiki-NFQA dataset provides a valuable resource for future research. The method not only elevates the answers’ ranks but also improves their relative quality, leading to better user satisfaction.
Visual Insights#

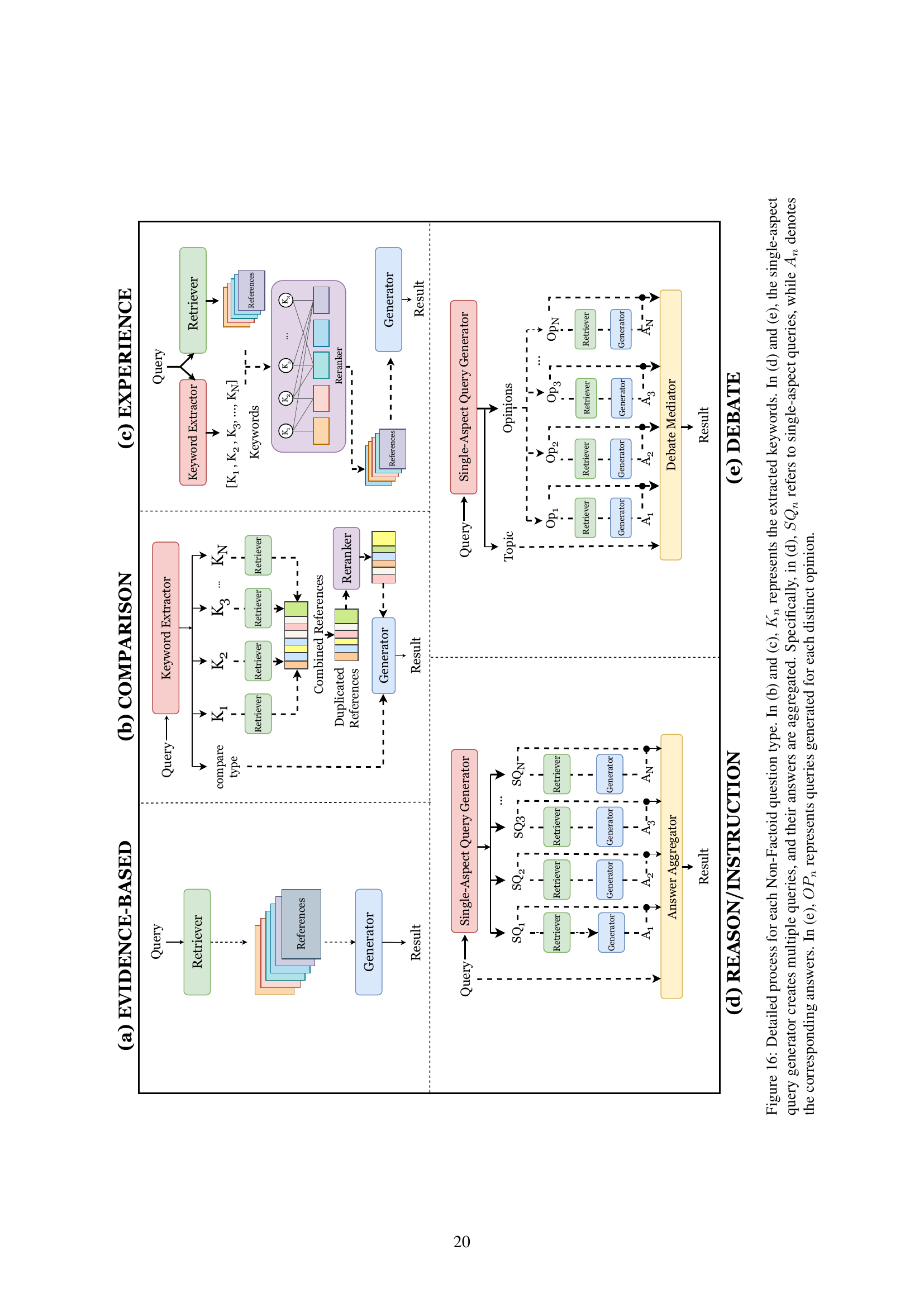
🔼 This figure illustrates the Typed-RAG architecture, a framework for answering non-factoid questions. The process begins with a non-factoid question being inputted into a type classifier. Based on the question’s type (e.g., debate, experience, comparison), it then follows a tailored pathway. Multi-aspect questions are decomposed into single-aspect sub-queries, which are then processed through retrieval and generation modules. Finally, an answer aggregator synthesizes these individual responses into a comprehensive, well-rounded answer that addresses the nuanced aspects of the initial non-factoid question. The specific prompts used in the multi-aspect decomposition and answer aggregation steps are detailed in Appendix A.4.
read the caption
Figure 1: An overview of Typed-RAG. Non-factoid questions are classified by the type classifier and processed based on their type. Prompts for the multi-aspect decomposer and answer aggregator handle the unique requirements of each type. Details of the prompt can be found in Appendix A.4.
| Model | Scorer LLM | Methods | Wiki-NFQA Dataset | |||||
|---|---|---|---|---|---|---|---|---|
| NQ-NF | SQD-NF | TQA-NF | 2WMH-NF | HQA-NF | MSQ-NF | |||
| Llama-3.2-3B | Mistral-7B | LLM | 0.5893 | 0.5119 | 0.6191 | 0.3565 | 0.4825 | 0.4262 |
| RAG | 0.5294 | 0.4944 | 0.5470 | 0.4150 | 0.4530 | 0.4047 | ||
| Typed-RAG | 0.7659 | 0.6493 | 0.7061 | 0.4544 | 0.5624 | 0.5356 | ||
| GPT-4o mini | LLM | 0.4934 | 0.4506 | 0.5380 | 0.3070 | 0.3669 | 0.2917 | |
| RAG | 0.4187 | 0.3553 | 0.4586 | 0.2859 | 0.2957 | 0.2866 | ||
| Typed-RAG | 0.8366 | 0.7139 | 0.7013 | 0.3692 | 0.5470 | 0.4482 | ||
| Mistral-7B | Mistral-7B | LLM | 0.6356 | 0.5450 | 0.6363 | 0.4821 | 0.5255 | 0.5081 |
| RAG | 0.5635 | 0.5069 | 0.6233 | 0.4789 | 0.5323 | 0.4438 | ||
| Typed-RAG | 0.7103 | 0.6333 | 0.6709 | 0.4747 | 0.6035 | 0.4512 | ||
| GPT-4o mini | LLM | 0.4656 | 0.4222 | 0.5921 | 0.3175 | 0.3965 | 0.3384 | |
| RAG | 0.4411 | 0.3817 | 0.5450 | 0.2890 | 0.3562 | 0.3079 | ||
| Typed-RAG | 0.8413 | 0.7444 | 0.7767 | 0.3987 | 0.6653 | 0.4929 | ||
🔼 This table presents a comparative analysis of different language models and methods on the Wiki-NFQA dataset. It uses Mean Reciprocal Rank (MRR) as the evaluation metric, and the rankings were determined using the LINKAGE method (Yang et al., 2024). The table shows the MRR scores for various combinations of language models (LLMs), scorer LLMs, and question answering methods (LLM-only, RAG, and Typed-RAG). This allows for assessing the impact of different LLMs, scoring strategies, and question answering architectures on the performance of non-factoid question answering systems.
read the caption
Table 1: Evaluation results on the Wiki-NFQA dataset using Mean Reciprocal Rank (MRR), comparing the performance of various language models, scorer LLMs, and methods. Answers were ranked using LINKAGE Yang et al. (2024) scored with the MRR metric.
In-depth insights#
Type-aware RAG#
Type-aware RAG introduces a nuanced approach to Retrieval-Augmented Generation, tailoring it to different question types for non-factoid QA. The core idea revolves around classifying NFQs and adapting retrieval/generation strategies accordingly. The paper likely argues that standard RAG falls short due to the diverse nature of NFQs. Type-aware RAG aims to improve relevance and coherence by decomposing complex queries into sub-queries based on question type (e.g., comparison, debate). This allows for more targeted retrieval and synthesis, ultimately leading to more comprehensive and user-aligned answers. A key innovation might be the use of different prompts/models for each question type within the RAG pipeline. This could lead to significant improvements in handling the complexities inherent in NFQA.
Wiki-NFQA Data#
The Wiki-NFQA dataset, introduced in this paper, appears to be a significant contribution to the field of non-factoid question answering (NFQA). Constructing such a dataset likely involved a rigorous filtering process of existing Wikipedia-based datasets to extract questions requiring more than simple factual answers. Given the nature of NFQA, the dataset’s quality hinges on high-quality reference answers, necessitating careful generation and annotation. The authors probably used multiple LLMs and annotation steps to generate and assess the diversity and quality of these answers. Wiki-NFQA could be used as a robust benchmark for evaluating QA systems, pushing research beyond traditional factoid QA and encouraging the development of models capable of generating nuanced, comprehensive, and contextually relevant responses. Dataset diversity across NFQ types like comparison, experience, and reason is essential.
Multi-Aspect QA#
Multi-aspect QA represents a significant challenge in question answering, as it necessitates synthesizing information from various perspectives. It moves beyond simple fact retrieval, requiring systems to consider multiple facets of a topic to provide comprehensive answers. This complexity stems from the open-ended nature of many real-world queries, where a single, definitive answer is insufficient. Systems tackling multi-aspect QA must effectively integrate information from diverse sources, resolve potential conflicts, and present a coherent response that addresses all relevant aspects of the question. Effective decomposition strategies are crucial, breaking down complex questions into manageable sub-queries to facilitate targeted information retrieval. Type-aware is also critical since questions have varying intents. The key is to create contextually relevant answers from these gathered results, by making it an essential ingredient for building intelligent systems.
Eval: LINKAGE#
The evaluation using LINKAGE is a key aspect. It signifies a shift towards more nuanced assessment beyond traditional metrics. LINKAGE’s ability to rank answers listwise is vital for NFQA, where semantic richness matters. The system leverages LLMs to score and rank, aligning more closely with human annotation, overcoming limitations of ROUGE/BERTScore. This ensures that high-quality answers that are comprehensive, contextual, and user-aligned are ranked higher, thereby emphasizing the importance of relevance and user satisfaction in evaluating non-factoid responses. This highlights its superiority in capturing nuanced quality variations.
Future NFQA Dev#
Future NFQA (Non-Factoid Question Answering) development holds significant promise. Future efforts should focus on creating more nuanced evaluation metrics beyond traditional measures like ROUGE and BERTScore, which often fail to capture the semantic richness required for non-factoid answers. Incorporating LLMs as scorers and developing listwise ranking frameworks, as demonstrated by LINKAGE, could offer more robust assessments. More diverse datasets, and Addressing the limitations of RAG, particularly the introduction of noise through irrelevant retrieved information, remains critical. Strategies such as multi-aspect decomposition and type-aware retrieval can improve the precision and relevance of retrieved content. Future research should compare Typed-RAG with existing rewriting techniques, refine its evaluation, and benchmark against established methodologies to further advance NFQA.
More visual insights#
More on figures

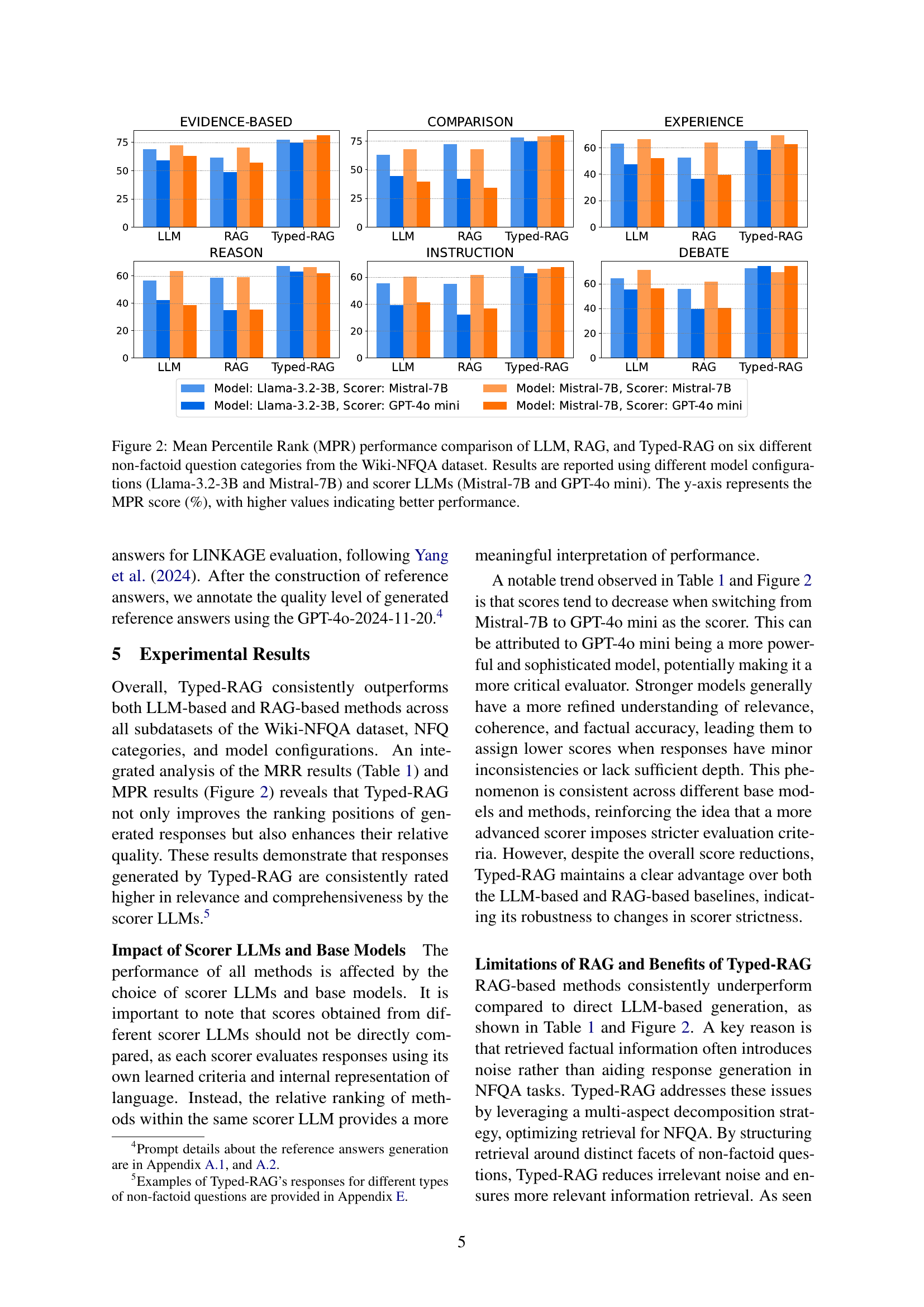
🔼 Figure 2 presents a comparison of the performance of three different question answering methods (LLM, RAG, and Typed-RAG) across six categories of non-factoid questions. The performance metric used is Mean Percentile Rank (MPR), expressed as a percentage. Higher MPR scores indicate better performance. The figure showcases results obtained using two different base language models (Llama-3.2-3B and Mistral-7B) and two different scorer LLMs (Mistral-7B and GPT-40 mini), demonstrating the impact of these model choices on the overall results. Each bar in the figure represents the average MPR for a particular question answering method within a specific non-factoid question category.
read the caption
Figure 2: Mean Percentile Rank (MPR) performance comparison of LLM, RAG, and Typed-RAG on six different non-factoid question categories from the Wiki-NFQA dataset. Results are reported using different model configurations (Llama-3.2-3B and Mistral-7B) and scorer LLMs (Mistral-7B and GPT-4o mini). The y-axis represents the MPR score (%), with higher values indicating better performance.

🔼 This figure presents the prompt template employed by Yang et al. (2024) to generate a high-quality reference answer using the internal knowledge of a Large Language Model (LLM). The template instructs the LLM to rewrite a provided non-factoid question and its corresponding ground truth answer, leveraging its internal knowledge base to produce a superior, more comprehensive and polished version of the answer. This ensures the reference answers used for evaluating the model’s performance are of high quality and consistency, thereby enhancing the robustness and reliability of the evaluation process.
read the caption
Figure 3: Prompt template proposed by Yang et al. (2024) to generate the highest standard reference answer using LLM’s internal knowledge.
More on tables
| NFQ Type | Example of Question | ||
|---|---|---|---|
| Evidence-based | “How does sterilisation help to keep the money flow even?” | ||
| Comparison | “what is the difference between dysphagia and odynophagia” | ||
| Experience | “What are some of the best Portuguese wines?” | ||
| Reason |
| ||
| Instruction | “How can you find a lodge to ask to be a member of?” | ||
| Debate |
|
🔼 This table presents example questions representing each of the six non-factoid question (NFQ) types included in the Wiki-NFQA dataset. The types are: Evidence-based, Comparison, Experience, Reason, Instruction, and Debate. Each row shows an example question categorized by type, illustrating the variety of NFQs the dataset contains.
read the caption
Table 2: Representative example questions for each type of non-factoid question (NFQ) in the Wiki-NFQA dataset.
| “Kresy, which roughly was a part of the land beyond the so-called Curson Line, |
| was drawn for what reason?” |
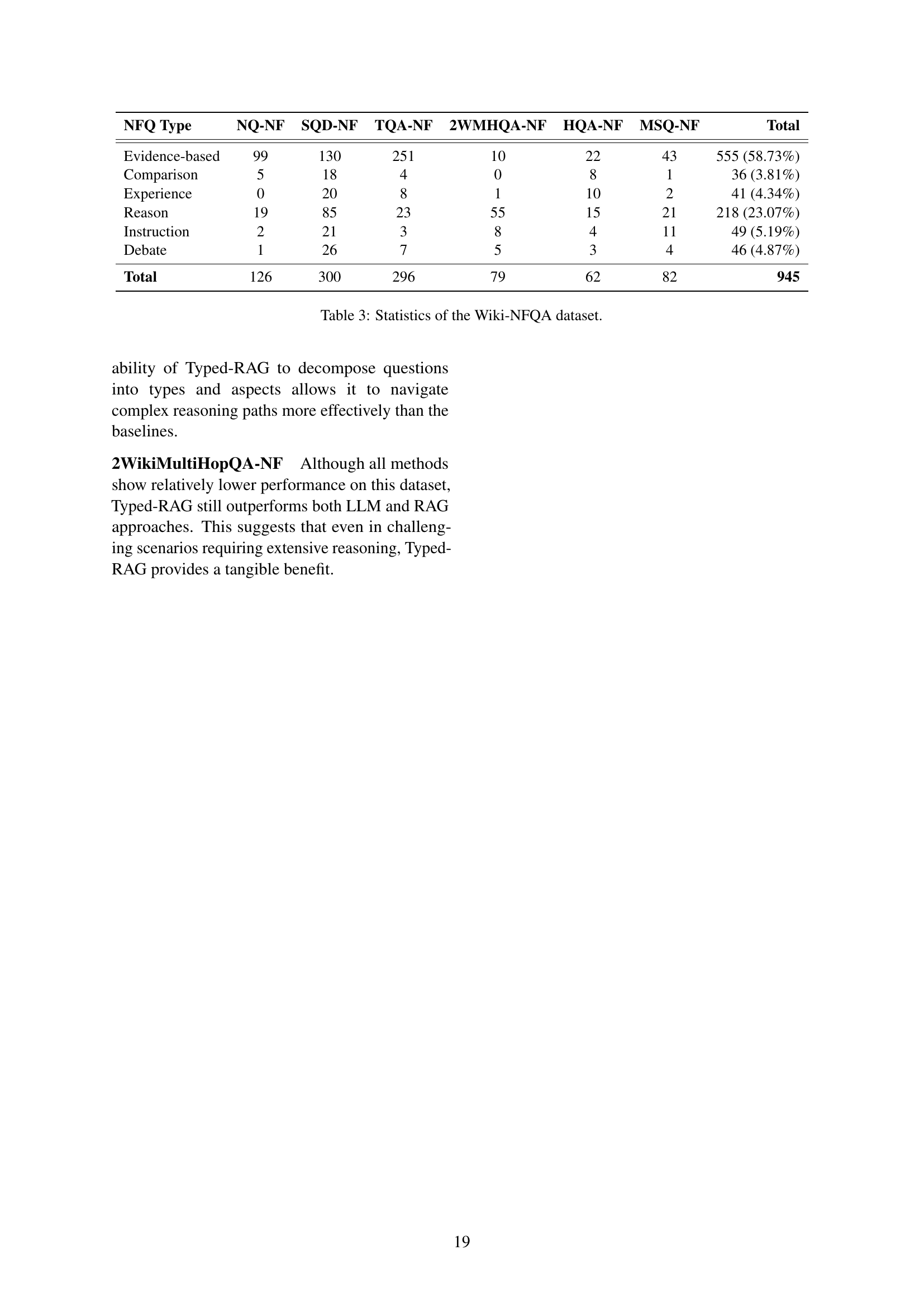
🔼 This table presents a statistical overview of the Wiki-NFQA dataset, which is a benchmark dataset for non-factoid question answering. It breaks down the total number of questions (945) across six different categories of non-factoid questions (Evidence-based, Comparison, Experience, Reason, Instruction, Debate) and shows the distribution of questions within each category for different subsets of the Wiki-NFQA dataset (NQ-NF, SQD-NF, TQA-NF, 2WMHQA-NF, HQA-NF, MSQ-NF). This allows researchers to understand the composition and characteristics of the dataset before using it for experiments.
read the caption
Table 3: Statistics of the Wiki-NFQA dataset.
| “I Can See Your Voice, a reality show from South Korea, offers what kind of |
| performers a chance to make their dreams of stardom a reality?” |
🔼 This table showcases example responses generated by the Typed-RAG model for various types of non-factoid questions. It demonstrates the model’s ability to produce answers tailored to the specific nuances and intentions of different question types, such as evidence-based, comparison, experience-based, reason-based, instruction-based, and debate-style questions. Each example shows how Typed-RAG addresses the unique challenges inherent in each type.
read the caption
Table 4: Examples of Typed-RAG responses for different types of non-factoid questions.
Full paper#