TL;DR#
Autoregressive models are great for image generation, but they require discretizing continuous pixel data. To reduce errors from this process, recent works use larger codebooks, which expands vocabulary size and complicates autoregressive modeling. This paper aims to find a way to enjoy the benefits of large codebooks without making autoregressive modeling more difficult. The problem is that tokens with similar codeword representations produce similar effects on the final generated image, revealing redundancy in large codebooks.
This paper introduces Coarse-to-Fine (CTF) token prediction, realized by assigning the same coarse label for similar tokens. The framework consists of (1) an autoregressive model that predicts coarse labels sequentially, and (2) an auxiliary model that predicts fine-grained labels for all tokens conditioned on their coarse labels. CTF can maintain large codebook sizes for quality reconstruction while simplifying the autoregressive modeling task. Experiments on ImageNet demonstrate superior performance and faster sampling speeds.
Key Takeaways#
Why does it matter?#
This paper introduces a new way to approach autoregressive image generation, balancing generation quality and computational efficiency. It offers new insight and methods for researchers working on image synthesis, generative modeling, and representation learning. The CTF framework provides a promising direction for future research in autoregressive models, particularly in scenarios where large codebooks are used. The code release also encourages reproducibility and further exploration by the community.
Visual Insights#

🔼 Figure 1 illustrates the core concepts of the proposed Coarse-to-Fine (CTF) image generation method. (a) shows the process of clustering similar codewords (vectors representing image features) in the codebook of the VQ-VAE into groups, forming coarse labels. (b) demonstrates the redundancy within large codebooks by showing that images reconstructed after replacing tokens with similar ones from the same cluster retain overall structure and content with minimal detail changes. This highlights that fine-grained token-level prediction might be unnecessary. (c) details the two-stage generation process. The first stage predicts a sequence of coarse labels autoregressively, representing clusters of codewords rather than individual tokens. The second stage then uses the coarse label sequence as context to simultaneously predict all the fine-grained labels (original tokens) for the whole image in a single step. This approach reduces the autoregressive model’s computational complexity.
read the caption
Figure 1: (a) The codeword clustering process, where token indices are grouped based on the similarity of their corresponding feature vectors in the codebook. (b) Visual demonstration of token redundancy: replacing each token with another randomly sampled from the same cluster produces images with only minor variations in detail, preserving the overall structure and content. (c) Illustration of our two-stage generation process: in the first stage, the model autoregressively predicts coarse labels (cluster indices) for each token in the sequence; then the second stage model predicts fine labels (indices in the codebook) for all tokens in a single step.
| Type | Model | #Para. | FID↓ | IS↑ | Pr.↑ | Re.↑ |
|---|---|---|---|---|---|---|
| BigGAN [1] | 112M | 6.95 | 224.5 | 0.89 | 0.38 | |
| GigaGAN [16] | 569M | 3.45 | 225.5 | 0.84 | 0.61 | |
| GAN | StyleGAN-XL [30] | 166M | 2.30 | 265.1 | 0.78 | 0.53 |
| ADM [8] | 554M | 10.94 | 101.0 | 0.69 | 0.63 | |
| CDM [14] | - | 4.88 | 158.7 | - | - | |
| LDM-4 [29] | 400M | 3.60 | 247.7 | - | - | |
| Diff. | DiT-XL/2 [24] | 675M | 2.27 | 278.2 | 0.83 | 0.57 |
| MaskGIT [3] | 227M | 6.18 | 182.1 | 0.80 | 0.51 | |
| Mask. | MaskGIT-re [3] | 227M | 4.02 | 355.6 | - | - |
| VAR-d16 [33] | 310M | 3.30 | 274.4 | 0.84 | 0.51 | |
| VAR-d20 [33] | 600M | 2.57 | 302.6 | 0.83 | 0.56 | |
| VAR | VAR-d24 [33] | 1.0B | 2.09 | 312.9 | 0.82 | 0.59 |
| VQGAN [9] | 227M | 18.65 | 80.4 | 0.78 | 0.26 | |
| VQGAN [9] | 1.4B | 15.78 | 74.3 | - | - | |
| VQGAN-re [9] | 1.4B | 5.20 | 280.3 | - | - | |
| ViT-VQGAN [39] | 1.7B | 4.17 | 175.1 | - | - | |
| ViT-VQGAN-re [39] | 1.7B | 3.48 | 175.1 | - | - | |
| RQTran. [18] | 3.8B | 7.55 | 134.0 | - | - | |
| AR | RQTran.-re [18] | 3.8B | 3.80 | 323.7 | - | - |
| IAR-B† [15] | 111M | 5.14 | 202.00 | 0.85 | 0.45 | |
| IAR-L† [15] | 343M | 3.18 | 234.80 | 0.82 | 0.53 | |
| IAR-XL† [15] | 775M | 2.52 | 248.10 | 0.82 | 0.58 | |
| LlamaGen-B† [32] | 111M | 6.09 | 182.54 | 0.85 | 0.42 | |
| LlamaGen-L† [32] | 343M | 3.07 | 256.06 | 0.83 | 0.52 | |
| AR | LlamaGen-XL† [32] | 775M | 2.62 | 244.08 | 0.80 | 0.57 |
| LlamaGen-B [32] | 111M | 5.46 | 193.61 | 0.83 | 0.45 | |
| + CTF | 87M∗ | 4.15 | 254.99 | 0.86 | 0.48 | |
| LlamaGen-L [32] | 343M | 3.80 | 248.28 | 0.83 | 0.52 | |
| + CTF | 310M∗ | 2.97 | 291.53 | 0.84 | 0.53 | |
| LlamaGen-XL [32] | 775M | 3.39 | 227.08 | 0.81 | 0.54 | |
| AR | + CTF | 734M∗ | 2.76 | 299.69 | 0.84 | 0.55 |
🔼 Table 1 presents a performance comparison of various image generation models on the ImageNet dataset at a resolution of 256x256 pixels. The models are categorized by their type (Generative Adversarial Networks (GANs), Diffusion Models (Diff.), Masked Autoencoders (Mask.), Vector Quantized Generative Adversarial Networks (VQGAN), and Autoregressive Models (AR)). Each model’s performance is evaluated using four key metrics: Fréchet Inception Distance (FID), Inception Score (IS), Precision (Pr.), and Recall (Re.). Lower FID scores indicate better image quality, while higher IS scores represent better diversity and quality. Precision and Recall assess the model’s ability to accurately generate images from the given class labels. The table also notes special training conditions for some models (trained at a higher resolution and downsampled), and highlights that the autoregressive models in this study use a smaller parameter count due to vocabulary size reduction complemented by an auxiliary network for efficiency. Color-coding assists in comparing the performance of the models to their baselines.
read the caption
Table 1: Performance comparison on class-conditional ImageNet at 256×256 resolution. Models are evaluated using FID, Inception Score (IS), precision (Pr.), and recall (Re.) metrics. The background is colorized for convenient comparison with baseline. Models with ††\dagger† were trained at 384×384 resolution and downsampled to 256×256 for evaluation. ∗*∗: Our autoregressive models have fewer parameters due to the reduced vocabulary size, complemented by an auxiliary network for fine-grained prediction, see Section 5.3 for a detailed efficiency analysis.
In-depth insights#
CTF: Coarse-to-Fine#
The concept of “CTF: Coarse-to-Fine” presents a hierarchical approach to image generation, drawing parallels to multi-resolution strategies in other domains. The core idea is to decompose the complex token prediction task into manageable sub-problems, initially focusing on the overall structure and subsequently refining the details. This is achieved by first predicting “coarse” labels that represent clusters of similar tokens, thereby reducing the effective vocabulary size and simplifying the autoregressive modeling task. A separate model then predicts the “fine” labels (the original token indices) conditioned on the predicted coarse labels. A potential advantage of this approach is improved efficiency, as the initial coarse prediction can guide the subsequent fine-grained prediction, reducing the search space. This strategy could also be more robust to noise or variations in the input data, as the coarse representation captures the essential structure while filtering out irrelevant details. The trade-offs involve the complexity of defining appropriate coarse labels and the potential for information loss during the initial clustering step. The effectiveness hinges on the ability of the coarse labels to capture the essential structure of the image while still allowing for sufficient detail to be recovered in the fine prediction stage. Successfully implemented, the CTF strategy offers a way to leverage large codebooks without the computational burden.
Redundancy in Tokens#
The paper addresses redundancy in tokens within autoregressive image generation, a critical area given the increasing codebook sizes in VQ-VAE-based models. The key insight is that not all tokens are equally important; some contribute minimally to the final image, indicating redundancy. Exploiting this redundancy allows for a more efficient autoregressive modeling. By grouping similar tokens into coarse labels and predicting these first, the complexity of the prediction task is greatly reduced. This coarse-to-fine approach enables the benefits of large codebooks while maintaining a manageable vocabulary size, leading to improved performance and faster sampling speeds. This approach is effective because visually similar tokens often have similar effects on the generated image.
Faster Sampling#
The paper addresses the challenge of balancing reconstruction quality with autoregressive modeling complexity in image generation. Large codebooks improve reconstruction but complicate the autoregressive task. The study introduces a coarse-to-fine (CTF) approach, clustering similar tokens and predicting coarse labels before refining with fine-grained details. A key aspect of the CTF method lies in achieving faster sampling speeds despite adding an auxiliary network. This speedup arises from the reduced vocabulary size in the autoregressive stage, streamlining the prediction task. Furthermore, as the autoregressive model scales, the efficiency gains from the smaller vocabulary become more pronounced, offsetting the computational cost of the auxiliary network. This contributes to a notable overall improvement in sampling efficiency. The approach leverages a reduced, semantically meaningful label set, simplifying the process and enhancing real-world applications, achieving both improved performance and higher speed.
k-means Clustering#
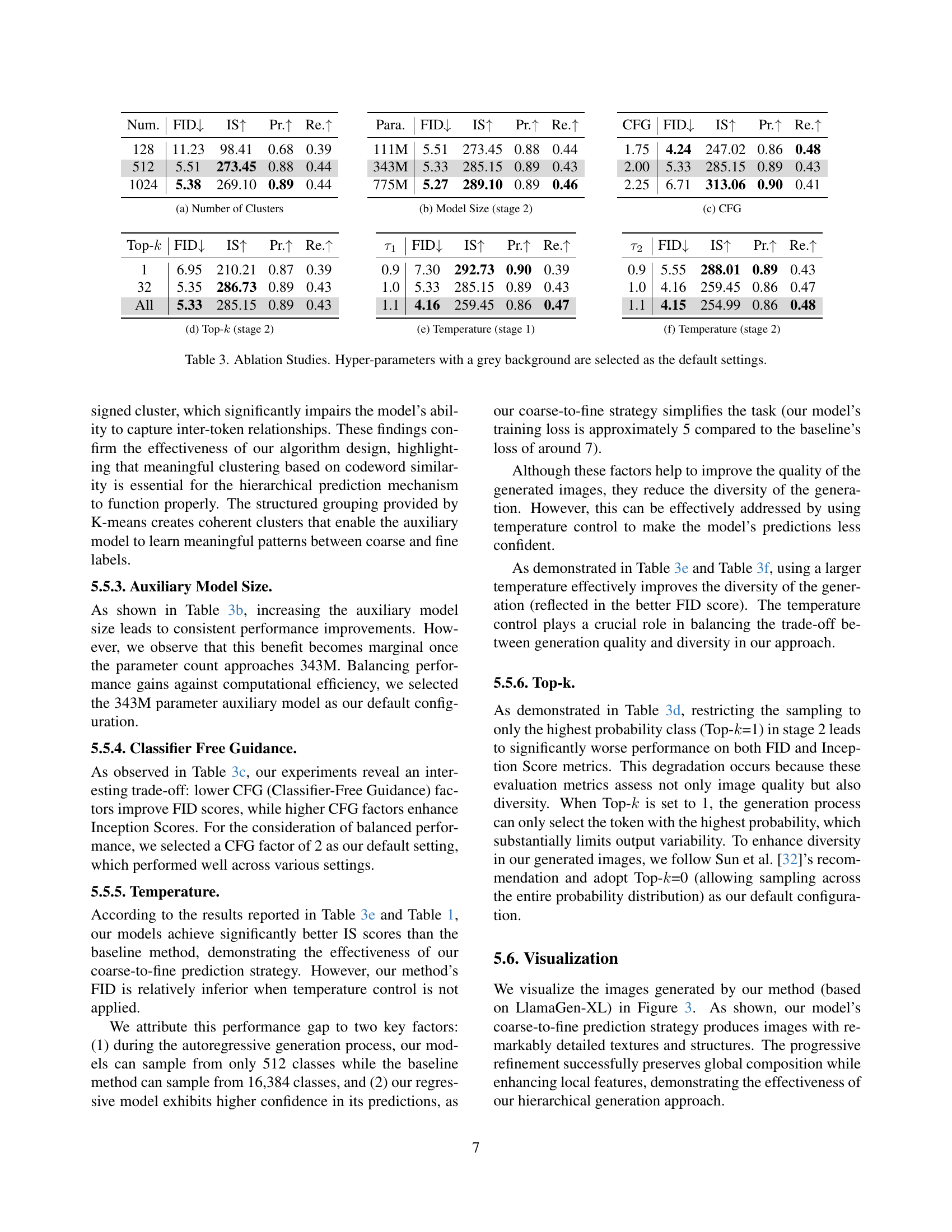
K-means clustering is employed to group tokens with similar codeword representations, assigning each cluster a coarse label. This process reduces the effective vocabulary size, simplifying the autoregressive modeling task by working with semantically meaningful clusters instead of individual tokens. K-means is chosen for its efficiency in partitioning the codebook vectors, enabling a more manageable and interpretable representation. Without k-means, the auxiliary model fails to accurately predict fine labels from coarse labels when clustering is performed randomly because of the weak correlation between tokens within the same randomly assigned cluster, which significantly impairs the model’s ability to capture inter-token relationships.
ImageNet Results#
The paper thoroughly evaluates its method on the ImageNet dataset, a standard benchmark for image generation. The results consistently demonstrate the superiority of the proposed approach, achieving significant performance gains across various model sizes. The improved Inception Score highlights the enhanced quality of generated images. The proposed method effectively enhances image generation quality and offers faster sampling speeds. The study thoroughly examines various hyperparameters, like number of clusters, KMeans, Model size, CFG, and Temperature, providing valuable insights into their impact on performance. The performance improvements are substantial, showcasing the effectiveness of the coarse-to-fine prediction strategy. The higher scores compared to baselines, demonstrates the effectiveness of redundancy reduction.
More visual insights#
More on figures

🔼 This figure displays a comparison of the performance of the baseline LlamaGen models and the models enhanced with the proposed coarse-to-fine (CTF) method across different training epochs. The plots show the Inception Score (IS) and Fréchet Inception Distance (FID) metrics over the training epochs. The CTF-enhanced models exhibit significantly better performance and faster convergence, achieving superior IS and lower FID scores compared to the baseline LlamaGen models. The graph also visually shows a speedup in convergence for the CTF models.
read the caption
Figure 2: Model performance comparison on different epochs. When our method is applied, models achieve significantly better performance.

🔼 This figure showcases several images generated using the proposed Coarse-to-Fine (CTF) method, specifically using the LlamaGen-XL model, as a benchmark on the ImageNet dataset with 256x256 resolution. The images demonstrate the model’s ability to generate high-quality, detailed images with rich textures and structures by leveraging a two-stage prediction approach. Each image shows the resulting image from the model, highlighting the effectiveness of the CTF method in producing visually appealing and coherent outputs.
read the caption
Figure 3: Generation results of our method (based on LlamaGen-XL) on ImageNet 256×256 benchmark.
More on tables
| Model | Total Param | Step | images/sec ↑ | FID ↓ | IS ↑ |
|---|---|---|---|---|---|
| LlamaGen-B | 111M | 256 | 13.75 | 5.46 | 193.61 |
| + CTF | 87M+343M | 256+1 | 12.83 | 4.15 | 254.99 |
| LlamaGen-L | 343M | 256 | 7.50 | 3.80 | 248.28 |
| + CTF | 310M+343M | 256+1 | 8.71 | 2.97 | 291.53 |
| LlamaGen-XL | 775M | 256 | 5.32 | 3.39 | 227.08 |
| + CTF | 734M+343M | 256+1 | 6.26 | 2.76 | 299.69 |
🔼 This table compares the sampling speeds of the proposed coarse-to-fine (CTF) method and baseline methods for autoregressive image generation. The comparison is performed using a single NVIDIA A100 GPU with a batch size of 64 images. Results are presented in terms of images per second and key performance metrics. Notably, despite adding an auxiliary network (343M parameters), the CTF method shows improved sampling efficiency in most cases, showcasing its computational advantages.
read the caption
Table 2: Sampling speed comparison, measured on a single A100 GPU with a batch size of 64. Although our method employs an auxiliary network with 343M parameters, our method achieved better sampling efficiency in most cases.
| Num. | FID | IS | Pr. | Re. |
|---|---|---|---|---|
| 128 | 11.23 | 98.41 | 0.68 | 0.39 |
| 512 | 5.51 | 273.45 | 0.88 | 0.44 |
| 1024 | 5.38 | 269.10 | 0.89 | 0.44 |
🔼 This table presents ablation study results focusing on the impact of the number of clusters used in the codeword clustering process. It shows how different numbers of clusters (128, 512, and 1024) affect the model’s performance, measured by FID, Inception Score (IS), precision (Pr.), and recall (Re.). The results demonstrate the importance of selecting an appropriate number of clusters to balance model complexity and performance.
read the caption
(a) Number of Clusters
| Para. | FID | IS | Pr. | Re. |
|---|---|---|---|---|
| 111M | 5.51 | 273.45 | 0.88 | 0.44 |
| 343M | 5.33 | 285.15 | 0.89 | 0.43 |
| 775M | 5.27 | 289.10 | 0.89 | 0.46 |
🔼 This table shows the impact of varying the size of the auxiliary model (Stage 2) in the proposed coarse-to-fine prediction framework on the model’s performance. It presents FID, Inception Score (IS), precision, and recall metrics for different model sizes, demonstrating how increasing the size of the auxiliary model generally improves generation quality, but with diminishing returns after a certain point.
read the caption
(b) Model Size (stage 2)
| CFG | FID | IS | Pr. | Re. |
|---|---|---|---|---|
| 1.75 | 4.24 | 247.02 | 0.86 | 0.48 |
| 2.00 | 5.33 | 285.15 | 0.89 | 0.43 |
| 2.25 | 6.71 | 313.06 | 0.90 | 0.41 |
🔼 This table presents ablation study results focusing on the impact of classifier-free guidance (CFG) on the performance of the proposed coarse-to-fine prediction framework. It shows how varying the CFG factor affects the FID and Inception Score metrics, revealing a trade-off between image quality and diversity. Specifically, lower CFG values generally lead to better FID scores (lower is better, indicating better fidelity), while higher CFG values improve Inception Scores (higher is better, indicating better diversity).
read the caption
(c) CFG
| Top- | FID | IS | Pr. | Re. |
|---|---|---|---|---|
| 1 | 6.95 | 210.21 | 0.87 | 0.39 |
| 32 | 5.35 | 286.73 | 0.89 | 0.43 |
| All | 5.33 | 285.15 | 0.89 | 0.43 |
🔼 This table presents ablation study results focusing on the impact of the top-k sampling strategy in Stage 2 (Fine Label Prediction) of the proposed coarse-to-fine framework. It shows how different values of k affect the model’s performance metrics (FID, IS, Precision, Recall) on the ImageNet dataset. Top-k sampling, in this context, refers to selecting only the top k most probable tokens when generating the fine-grained labels in the second stage. The results demonstrate the effect of controlling the diversity and quality of the generated images by adjusting k.
read the caption
(d) Top-k𝑘kitalic_k (stage 2)
| FID | IS | Pr. | Re. | |
|---|---|---|---|---|
| 0.9 | 7.30 | 292.73 | 0.90 | 0.39 |
| 1.0 | 5.33 | 285.15 | 0.89 | 0.43 |
| 1.1 | 4.16 | 259.45 | 0.86 | 0.47 |
🔼 This table presents ablation study results focusing on the impact of temperature in stage 1 of the coarse-to-fine prediction framework on the model’s performance. It shows how different temperature values (0.9, 1.0, 1.1) affect the FID, Inception Score (IS), precision, and recall metrics. This helps to analyze the effect of temperature on the trade-off between image quality and diversity during the generation process.
read the caption
(e) Temperature (stage 1)
| FID | IS | Pr. | Re. | |
|---|---|---|---|---|
| 0.9 | 5.55 | 288.01 | 0.89 | 0.43 |
| 1.0 | 4.16 | 259.45 | 0.86 | 0.47 |
| 1.1 | 4.15 | 254.99 | 0.86 | 0.48 |
🔼 This table presents ablation study results focusing on the temperature hyperparameter specifically in Stage 2 (Fine Label Prediction) of the proposed coarse-to-fine prediction framework. It shows how varying the temperature in the second stage affects the model’s performance across multiple metrics, including FID, Inception Score (IS), Precision (Pr.), and Recall (Re.). Different temperature values (0.9, 1.0, and 1.1) are tested to analyze their impact on generation quality and diversity.
read the caption
(f) Temperature (stage 2)
Full paper#