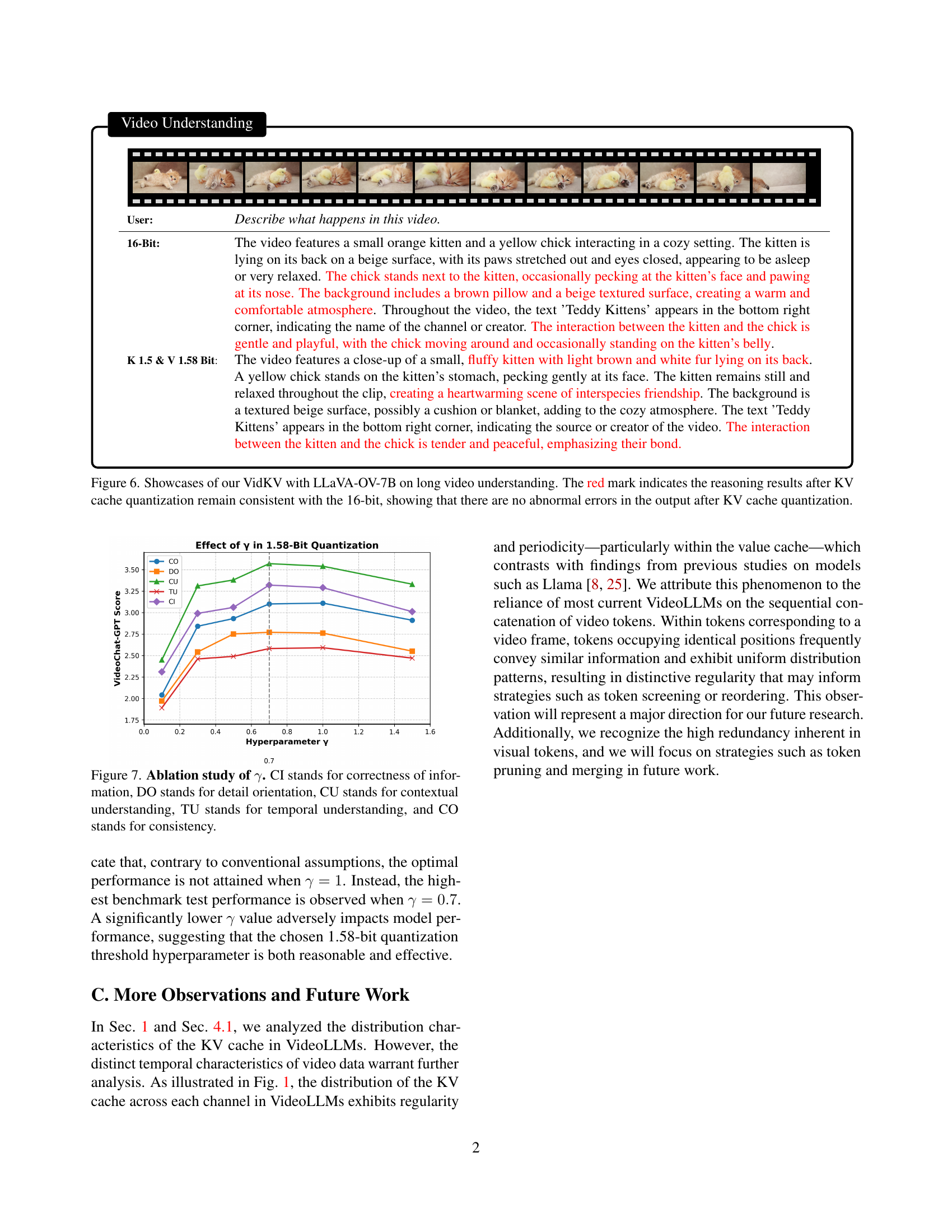
TL;DR#
Video Large Language Models(VideoLLMs) are powerful for understanding video content, but they require a lot of memory for key-value (KV) caches, which limits their efficiency. Existing KV cache quantization techniques reduce memory usage, but their applicability to VideoLLMs remains largely unexplored. This paper shows a basic group-wise 2-bit KV cache quantization has achieved promising performance for VideoLLMs.
To improve upon existing methods, this paper introduces VidKV, a training-free method that employs mixed-precision quantization for the key cache (2-bit for anomalous channels, 1-bit with FFT for normal channels) and 1.58-bit quantization for the value cache, selectively preserving semantically salient tokens. VidKV effectively compresses the KV cache with minimal performance loss.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient video processing. By introducing a method to significantly compress KV cache with minimal performance loss, it addresses a key bottleneck in VideoLLMs. This work has great potential of enabling faster and more scalable video understanding and analysis. It opens new research avenues in low-bit quantization techniques for video data.
Visual Insights#

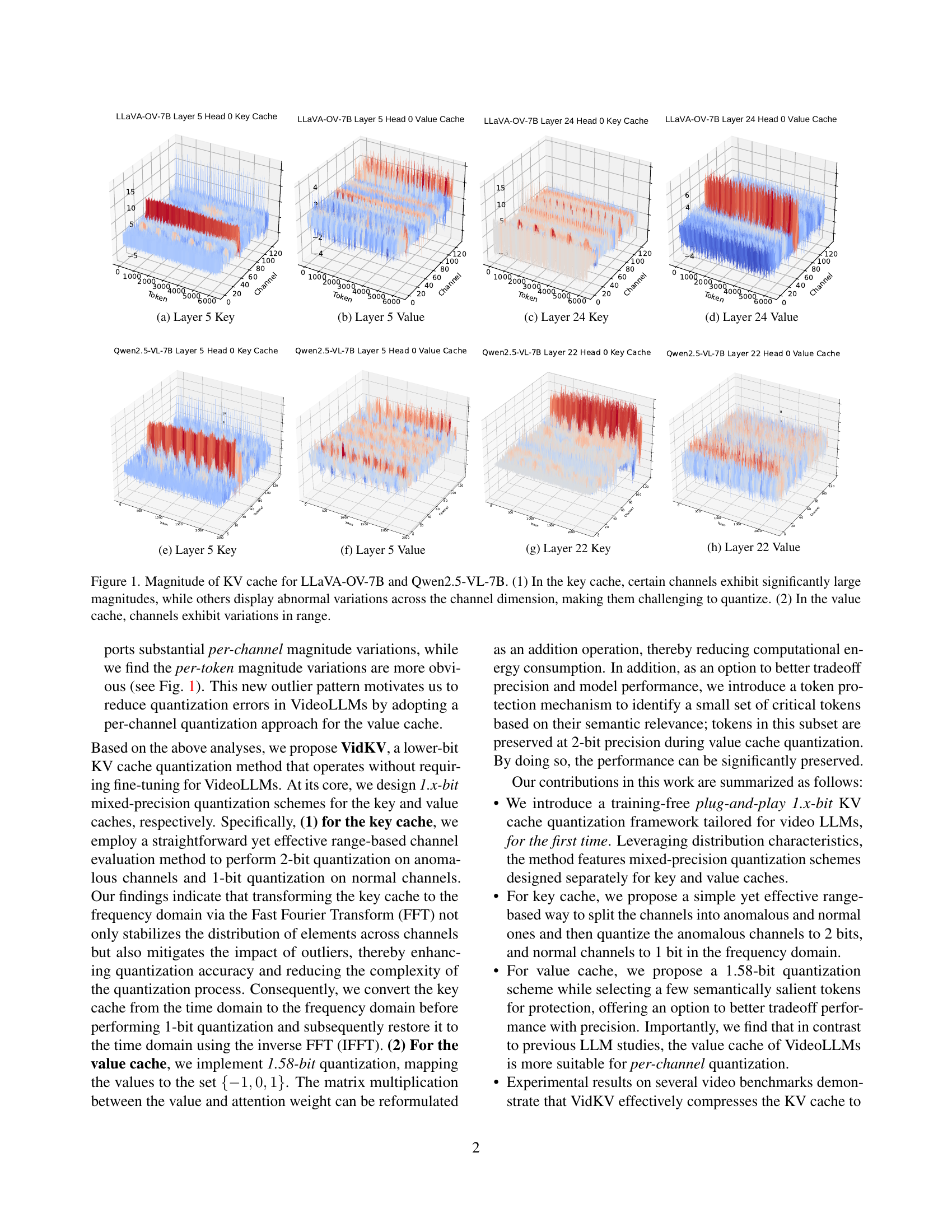
🔼 This figure displays the magnitude of the key cache in layer 5 of the LLaVA-OV-7B model. It shows a heatmap visualization of the key cache’s values across the channel and token dimensions. The heatmap allows for the visual identification of channels with significantly larger magnitudes than others. This visualization is used in the paper to support the argument for a mixed-precision quantization strategy for the key cache, where different quantization levels are applied to channels with different magnitude characteristics.
read the caption
(a) Layer 5 Key
| LLaVA-OV-7B | Bit (K/V) | VideoDC | MovieChat |
| Baseline | 16 | 3.01 | 47.87 |
| K - , V - | 2 / 2 | 3.03 | 47.68 |
| K - , V - | 2 / 2 | 3.00 | 43.63 |
| K - , V - | 1.5 / 1.58 | 2.79 | 47.08 |
| K - , V - | 1.5 / 1.58 | 2.21 | 13.76 |
| Variance | 1.5 / 2 | 2.71 | 45.11 |
| Range | 1.5 / 2 | 2.95 | 48.28 |
| Outlier | 1.5 / 2 | 2.51 | 32.87 |
🔼 Table 1 presents the results of an experiment evaluating the effects of different quantization methods on the key-value (KV) cache of the LLaVA-OV-7B video large language model. The experiment uses group-wise quantization with a group size of 32. The table compares several quantization strategies: 16-bit (baseline), 2-bit per-channel (K-C, V-C), 2-bit per-token (K-C, V-T), and 1.5/1.58-bit mixed-precision. The 1.58-bit quantization uses the range {-1, 0, 1}. Three metrics—Range (max-min), Variance, and Outlier—were used to select channels for mixed-precision quantization of the key cache. The table shows the performance impact (measured by VideoDC and MovieChat scores) of each strategy.
read the caption
Table 1: Results of simulated KV cache group-wise quantization under various configurations on LLaVA-OV-7B. The group size is fixed at 32. ℂℂ\mathbb{C}blackboard_C denotes per-channel quantization, while 𝕋𝕋\mathbb{T}blackboard_T represents per-token quantization. The quantization range for 1.58-bit quantization is {−1,0,1}101\{-1,0,1\}{ - 1 , 0 , 1 }. Range, Variance, and Outlier are the metrics employed for channel selection in the mixed-precision quantization of the key cache, where Range is defined as max−min𝑚𝑎𝑥𝑚𝑖𝑛max-minitalic_m italic_a italic_x - italic_m italic_i italic_n.
In-depth insights#
VidKV: 1.x-bit#
VidKV: 1.x-bit presents a novel approach to KV cache quantization for video LLMs, targeting lower bit precisions (below 2 bits) to address memory bottlenecks. It introduces a mixed-precision quantization scheme, adapting bit allocation based on channel characteristics, using 2-bit for anomalous channels and 1-bit (with FFT) for normal channels in the key cache. For the value cache, a 1.58-bit quantization is employed, with an option for semantic token protection. VidKV explores how the KV caches should also be quantized in the per-channel form. Experiments show the effectiveness of this method in compressing KV caches while mostly retaining performance which leads to the conclusion that we can quantize the KV caches even lower than what we currently have.
VideoLLM Quant#
VideoLLM Quantization is crucial for efficient video processing. KV cache quantization is a primary method to reduce memory usage. Initial findings show 2-bit quantization is almost lossless due to video token redundancy, prompting exploration of lower-bit quantization. Techniques like mixed-precision quantization for keys, using channel dimension analysis, and 1.58-bit quantization for values, with selective preservation of salient tokens, are key areas. Unlike LLMs, VideoLLMs benefit more from per-channel quantization for value caches, as opposed to per-token. Future advancements might include strategies to handle challenges in 1-bit quantization, like managing quantization errors caused by drastically fluctuating channels. The study shows the potential for more efficient VideoLLMs through quantization.
Channel-wise KV#
Channel-wise KV quantization presents a paradigm shift from per-token methods, potentially better aligning with the inherent structure of video data in VideoLLMs. The key insight is that, rather than each token being independently quantized, channels (representing feature dimensions) are quantized together. This is particularly relevant when considering the spatial and temporal redundancy present in video, where certain feature dimensions may exhibit similar characteristics across multiple tokens within a channel. Channel-wise quantization allows for efficient compression while retaining crucial information. The success of channel-wise over per-token highlights the importance of adapting quantization strategies to the specific data modality. Furthermore, It opens the door for exploring other adaptive quantization techniques, such as dynamic bit allocation across channels.
FFT Key Enhance#
Enhancing the key component using FFT (Fast Fourier Transform) could be a novel method to optimize KV cache quantization. FFT can transform data into frequency domain, potentially revealing patterns not obvious in the time domain. This transformation might stabilize data distribution, mitigating the impact of outliers and improving quantization accuracy. Further, quantization errors can be minimized, leading to a more compact and efficient representation of the key cache. FFT-based enhancement can be combined with mixed-precision strategies, allocating more bits to critical frequency components and fewer bits to less significant ones. This approach balances compression and performance. To leverage on FFT’s power in noise reduction, the key part is enhanced for more refined quantization.
Future: 1-bit KV#
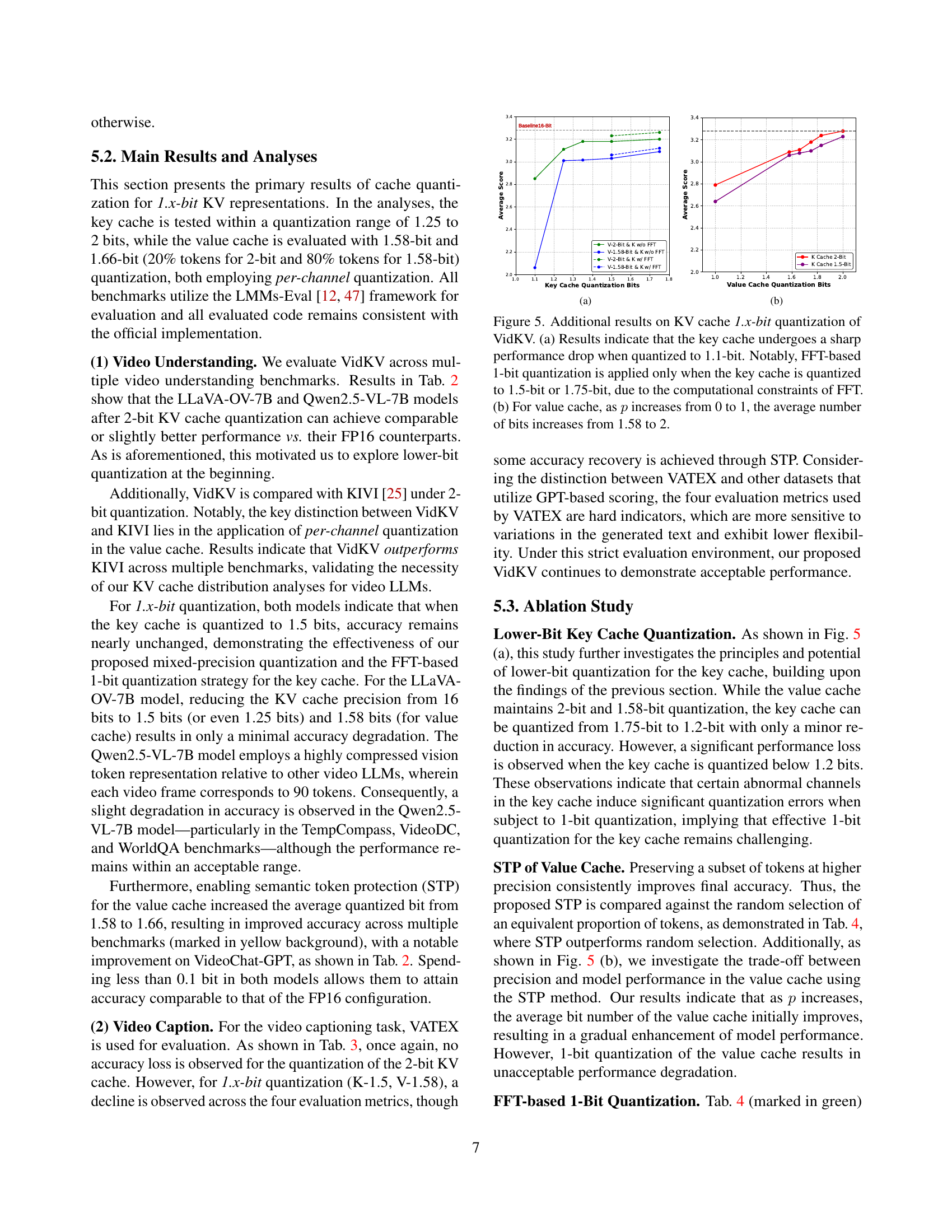
Exploring the future of 1-bit KV cache quantization presents significant challenges and opportunities. While the current research demonstrates promising results with 1.5-bit and 1.58-bit quantization, achieving stable and effective 1-bit quantization remains elusive. The primary hurdle lies in the substantial information loss associated with such aggressive compression. Mitigating this loss requires innovative approaches, such as highly selective token preservation strategies, more sophisticated quantization schemes that adapt to the unique characteristics of different KV cache elements, or leveraging external knowledge to compensate for the reduced precision. Addressing this limitation is crucial to unlock the full potential of extremely low-bit quantization for significantly reducing memory footprint and accelerating inference in large models.
More visual insights#
More on figures

🔼 This figure displays the magnitude of the value cache in layer 5 of the LLaVA-OV-7B model. It shows the distribution of values across both the channel and token dimensions. The heatmap visualization allows one to understand the variation in magnitude of the values across different channels and tokens, highlighting potential areas of redundancy or sparsity that could be leveraged for quantization.
read the caption
(b) Layer 5 Value

🔼 This figure displays the magnitude of the key cache in layer 24 of the Qwen2.5-VL-7B model. It is a 3D heatmap showing the channel dimension on the x-axis, the token dimension on the y-axis, and the magnitude of the key values on the z-axis. The heatmap visualizes the distribution of values within the key cache, highlighting variations across channels and tokens. This visualization helps to understand the distribution characteristics of the key cache, which is crucial for designing effective quantization strategies.
read the caption
(c) Layer 24 Key

🔼 The figure displays a 3D heatmap visualizing the magnitude of the value cache in layer 24 of a video large language model (VideoLLM). The heatmap shows the magnitude of values across different channels (vertical axis) and tokens (horizontal axis). The color intensity represents the magnitude, with warmer colors indicating larger magnitudes. This visualization helps to understand the distribution of values within the KV cache, which is crucial for effective quantization and compression techniques. The specific model shown could be LLaVA-OV-7B or Qwen2.5-VL-7B, depending on which sub-figure is referenced in the paper.
read the caption
(d) Layer 24 Value

🔼 This figure displays the magnitude of the value cache in layer 5 of the Qwen2.5-VL-7B model. The heatmap shows the distribution of values across channels and tokens, visualizing the variability and potential for quantization. Each channel is represented by a line on the y-axis and each token is along the x-axis. The color scale indicates the magnitude of the values, with warmer colors representing larger magnitudes and cooler colors representing smaller magnitudes.
read the caption
(f) Layer 5 Value

🔼 This figure displays the magnitude of the key cache in layer 22 of the Qwen2.5-VL-7B model. The heatmap shows the values across the channel dimension (y-axis) and token dimension (x-axis). The color intensity represents the magnitude, with warmer colors (red) indicating larger magnitudes and cooler colors (blue) indicating smaller magnitudes. This visualization helps to understand the distribution of values within the key cache, which is important for designing effective quantization strategies.
read the caption
(g) Layer 22 Key

🔼 This figure displays the magnitude of the value cache in layer 22 of the Qwen2.5-VL-7B model. It shows the distribution of values across channels and tokens. The visualization helps to understand the distribution characteristics of the value cache, especially in terms of magnitude variations, which are crucial for designing effective quantization strategies. High magnitude variations across channels may indicate a greater challenge for quantization methods. This figure is part of the analysis of KV cache distributions in video LLMs, which informs the proposed mixed-precision quantization scheme in the VidKV method.
read the caption
(h) Layer 22 Value
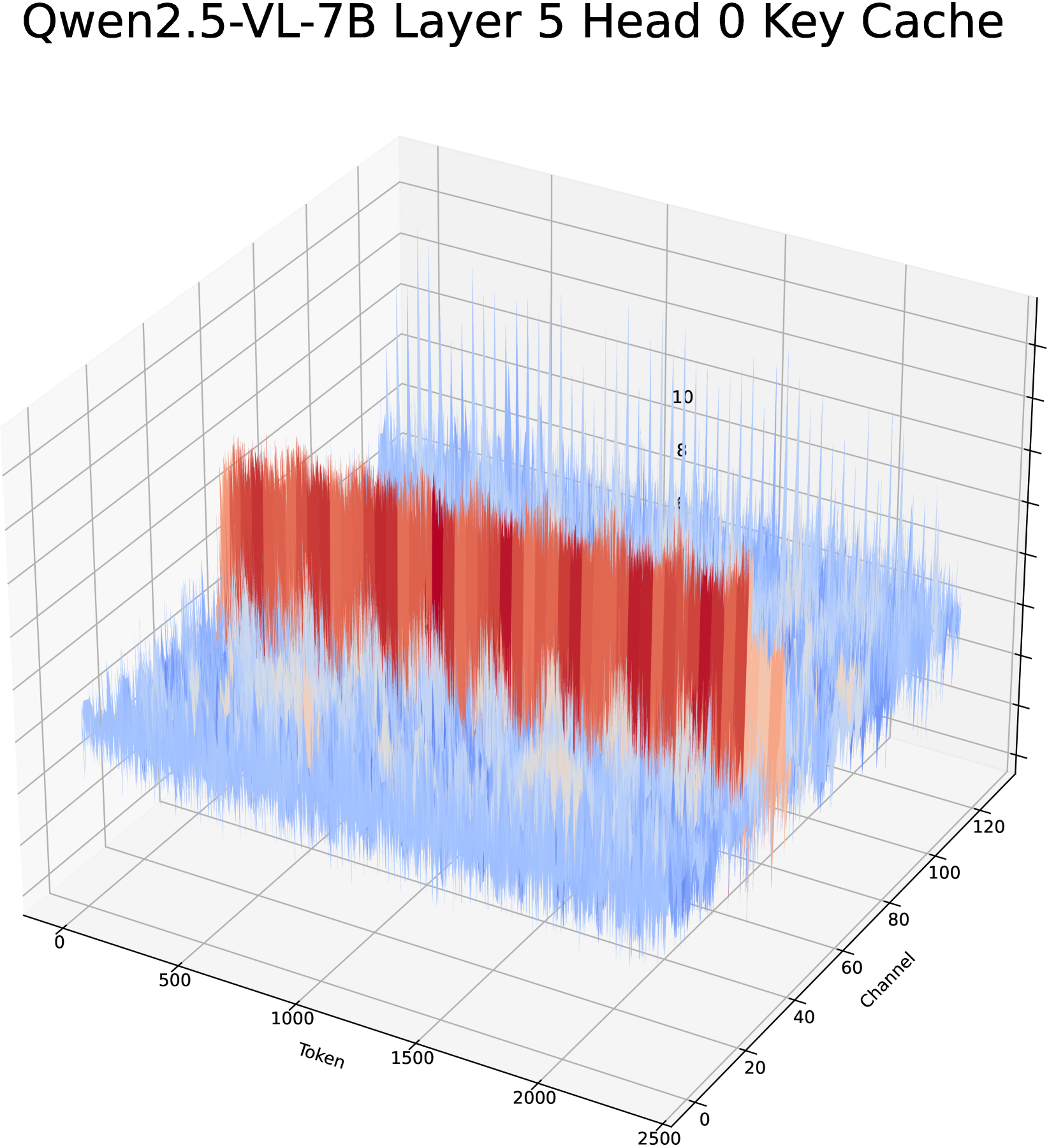
🔼 Figure 1 visualizes the distribution patterns of key-value (KV) cache data within the LLaVA-OV-7B and Qwen2.5-VL-7B video large language models (VideoLLMs). The heatmaps illustrate the magnitude of values across both the channel and token dimensions for different layers and heads within each model. Specifically, the visualization reveals that certain channels in the key cache exhibit exceptionally high magnitudes, presenting a challenge for quantization. Other channels display irregular variations across the channel dimension, adding further complexity to the quantization process. Conversely, the value cache demonstrates variations primarily in the range of values across channels. This observation of different distribution patterns in the key and value caches informs the design choices within the VidKV quantization method.
read the caption
Figure 1: Magnitude of KV cache for LLaVA-OV-7B and Qwen2.5-VL-7B. (1) In the key cache, certain channels exhibit significantly large magnitudes, while others display abnormal variations across the channel dimension, making them challenging to quantize. (2) In the value cache, channels exhibit variations in range.

🔼 This figure displays the magnitude of the key cache in layer 5 of the Qwen2.5-VL-7B model. The heatmap shows the values across the channel dimension (y-axis) and token dimension (x-axis). Different colors represent different magnitudes of the values, with warmer colors (red) representing higher magnitudes and cooler colors (blue) representing lower magnitudes. The visualization helps in understanding the distribution of values within the key cache, which is important for designing efficient quantization strategies. The visualization highlights which channels are more challenging to quantize due to their larger values or higher variability across tokens.
read the caption
(e) Layer 5 Key

🔼 This figure illustrates the VidKV method, a 1.x-bit mixed-precision quantization technique for key-value (KV) caches in video large language models (VideoLLMs). VidKV uses a mixed-precision approach: 1.x-bit for the key cache and 1.58-bit for the value cache. Importantly, for the key cache, mixed-precision quantization is applied along the channel dimension, while for the value cache, it is applied along the token dimension. To improve performance, VidKV incorporates important token selection in the value cache, protecting crucial visual tokens from aggressive quantization by using higher bit precision. This approach contrasts with previous methods like KIVI [25], which quantized KV caches in a per-token fashion.
read the caption
Figure 2: Overview of our proposed method VidKV. We implement 1.x-bit mixed-precision quantization for the key cache and 1.58-bit quantization for the value cache. In addition, as shown in the figure, to balance precision and model performance, we protect important visual tokens in the value cache. It is noteworthy that we perform mixed-precision quantization on the key cache along the channel dimension, whereas on the value cache, we apply mixed-precision quantization along the token dimension. All key-value caches are quantized in a per-channel fashion, different from prior KV cache quantization methods for LLMs such as KIVI [25].

🔼 Figure 3 illustrates the impact of Fast Fourier Transform (FFT) on the distribution of elements within the key cache of a video large language model. The left panel shows the distribution in the time domain, demonstrating sharp fluctuations and significant variations across channels. These variations make it challenging to effectively quantize the data using lower bit representations. In contrast, the right panel shows the distribution after applying FFT, which transforms the data into the frequency domain. The resulting distribution is significantly smoother, exhibiting less variability. This smoother frequency-domain representation leads to a reduction in quantization error when using techniques like low-bit quantization. The FFT-based approach enhances quantization accuracy by mitigating the impact of outliers and improving the stability of the elements across the channels.
read the caption
Figure 3: Analysis of the normal channel in the key cache and its distribution following FFT transformation reveals that the frequency-domain distribution is smoother after using FFT transformation, resulting in reduced quantization error.
More on tables

 Quantization Error 2.39
Quantization Error 1.14
Quantization Error 2.39
Quantization Error 1.14
|
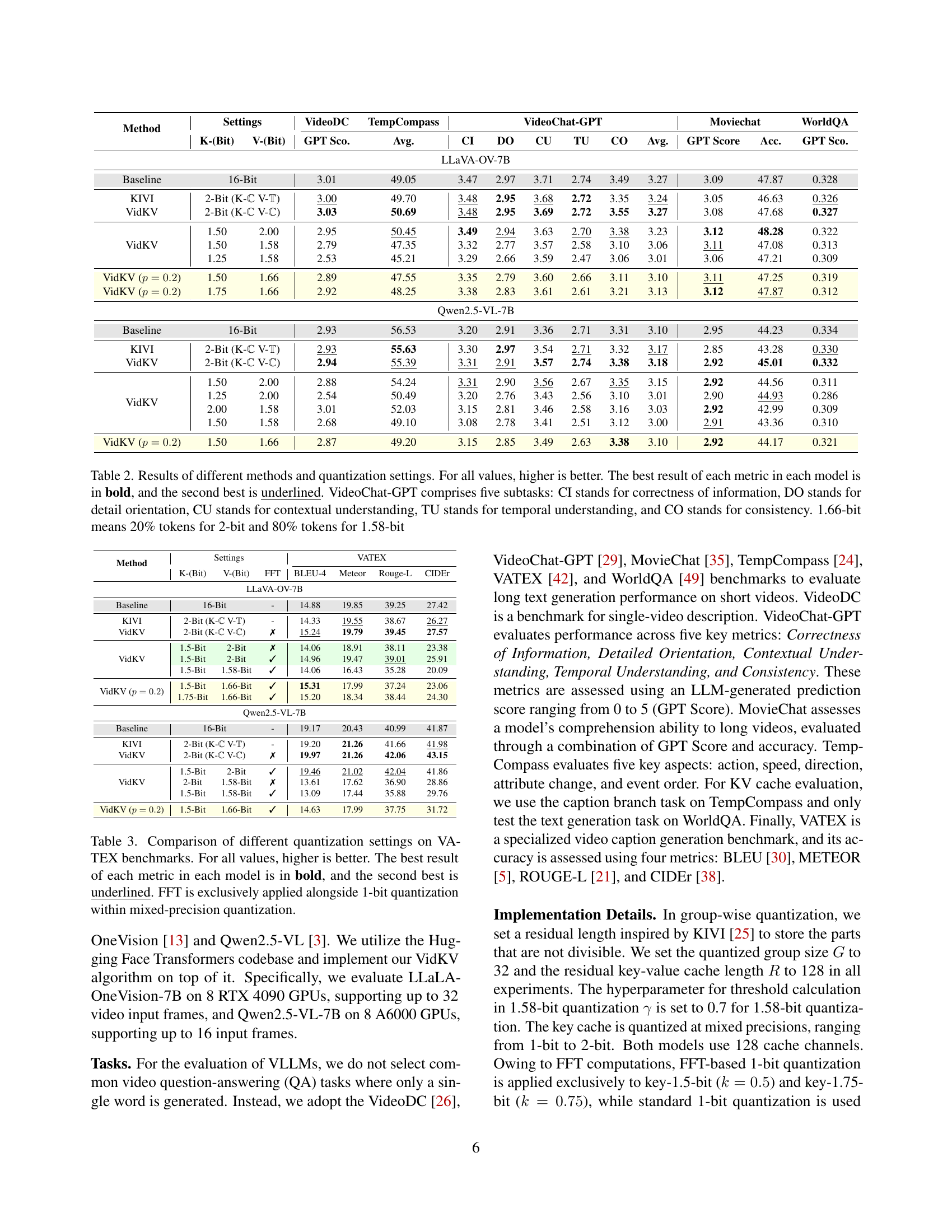
🔼 This table presents a comprehensive comparison of different quantization methods and bit depths applied to Key-Value (KV) caches in two video large language models: LLaVA-OV-7B and Qwen2.5-VL-7B. The performance is evaluated across several benchmarks, including VideoDC, GPT Score, TempCompass, and VideoChat-GPT (with sub-tasks CI, DO, CU, TU, and CO representing Correctness of Information, Detail Orientation, Contextual Understanding, Temporal Understanding, and Consistency, respectively). The results show the impact of different quantization techniques (Baseline, KIVI, and VidKV) and bit depths (16-bit, 2-bit, 1.5-bit, 1.58-bit, 1.66-bit) on model performance. Higher scores indicate better performance. The 1.66-bit configuration signifies a mixed precision approach where 20% of the tokens are quantized to 2-bits, and 80% are quantized to 1.58-bits.
read the caption
Table 2: Results of different methods and quantization settings. For all values, higher is better. The best result of each metric in each model is in bold, and the second best is underlined. VideoChat-GPT comprises five subtasks: CI stands for correctness of information, DO stands for detail orientation, CU stands for contextual understanding, TU stands for temporal understanding, and CO stands for consistency. 1.66-bit means 20% tokens for 2-bit and 80% tokens for 1.58-bit
| Method | Settings | VideoDC | TempCompass | VideoChat-GPT | Moviechat | WorldQA | |||||||
| K-(Bit) | V-(Bit) | GPT Sco. | Avg. | CI | DO | CU | TU | CO | Avg. | GPT Score | Acc. | GPT Sco. | |
| LLaVA-OV-7B | |||||||||||||
| Baseline | 16-Bit | 3.01 | 49.05 | 3.47 | 2.97 | 3.71 | 2.74 | 3.49 | 3.27 | 3.09 | 47.87 | 0.328 | |
| KIVI | 2-Bit (K- V-) | 3.00 | 49.70 | 3.48 | 2.95 | 3.68 | 2.72 | 3.35 | 3.24 | 3.05 | 46.63 | 0.326 | |
| VidKV | 2-Bit (K- V-) | 3.03 | 50.69 | 3.48 | 2.95 | 3.69 | 2.72 | 3.55 | 3.27 | 3.08 | 47.68 | 0.327 | |
| VidKV | 1.50 | 2.00 | 2.95 | 50.45 | 3.49 | 2.94 | 3.63 | 2.70 | 3.38 | 3.23 | 3.12 | 48.28 | 0.322 |
| 1.50 | 1.58 | 2.79 | 47.35 | 3.32 | 2.77 | 3.57 | 2.58 | 3.10 | 3.06 | 3.11 | 47.08 | 0.313 | |
| 1.25 | 1.58 | 2.53 | 45.21 | 3.29 | 2.66 | 3.59 | 2.47 | 3.06 | 3.01 | 3.06 | 47.21 | 0.309 | |
| VidKV () | 1.50 | 1.66 | 2.89 | 47.55 | 3.35 | 2.79 | 3.60 | 2.66 | 3.11 | 3.10 | 3.11 | 47.25 | 0.319 |
| VidKV () | 1.75 | 1.66 | 2.92 | 48.25 | 3.38 | 2.83 | 3.61 | 2.61 | 3.21 | 3.13 | 3.12 | 47.87 | 0.312 |
| Qwen2.5-VL-7B | |||||||||||||
| Baseline | 16-Bit | 2.93 | 56.53 | 3.20 | 2.91 | 3.36 | 2.71 | 3.31 | 3.10 | 2.95 | 44.23 | 0.334 | |
| KIVI | 2-Bit (K- V-) | 2.93 | 55.63 | 3.30 | 2.97 | 3.54 | 2.71 | 3.32 | 3.17 | 2.85 | 43.28 | 0.330 | |
| VidKV | 2-Bit (K- V-) | 2.94 | 55.39 | 3.31 | 2.91 | 3.57 | 2.74 | 3.38 | 3.18 | 2.92 | 45.01 | 0.332 | |
| VidKV | 1.50 | 2.00 | 2.88 | 54.24 | 3.31 | 2.90 | 3.56 | 2.67 | 3.35 | 3.15 | 2.92 | 44.56 | 0.311 |
| 1.25 | 2.00 | 2.54 | 50.49 | 3.20 | 2.76 | 3.43 | 2.56 | 3.10 | 3.01 | 2.90 | 44.93 | 0.286 | |
| 2.00 | 1.58 | 3.01 | 52.03 | 3.15 | 2.81 | 3.46 | 2.58 | 3.16 | 3.03 | 2.92 | 42.99 | 0.309 | |
| 1.50 | 1.58 | 2.68 | 49.10 | 3.08 | 2.78 | 3.41 | 2.51 | 3.12 | 3.00 | 2.91 | 43.36 | 0.310 | |
| VidKV () | 1.50 | 1.66 | 2.87 | 49.20 | 3.15 | 2.85 | 3.49 | 2.63 | 3.38 | 3.10 | 2.92 | 44.17 | 0.321 |
🔼 Table 3 presents a detailed comparison of various quantization techniques applied to the VATEX benchmark, focusing on the impact of different bit-depths for key and value caches within the context of Video Large Language Models (VideoLLMs). The table highlights the performance across multiple metrics (VATEX, FFT, BLEU-4, METEOR, ROUGE-L, and CIDEr), comparing the baseline 16-bit precision against several quantization strategies. These strategies include 2-bit quantization (KIVI) as well as the proposed VidKV method with mixed-precision quantization (1.5-bit and 1.58-bit). The results demonstrate the effectiveness of VidKV in maintaining performance while significantly reducing the bit-depth and memory requirements of the KV cache. Notably, the table also illustrates the exclusive application of Fast Fourier Transform (FFT) in conjunction with 1-bit quantization within the VidKV’s mixed-precision approach.
read the caption
Table 3: Comparison of different quantization settings on VATEX benchmarks. For all values, higher is better. The best result of each metric in each model is in bold, and the second best is underlined. FFT is exclusively applied alongside 1-bit quantization within mixed-precision quantization.
| Method | Settings | VATEX | |||||
| K-(Bit) | V-(Bit) | FFT | BLEU-4 | Meteor | Rouge-L | CIDEr | |
| LLaVA-OV-7B | |||||||
| Baseline | 16-Bit | - | 14.88 | 19.85 | 39.25 | 27.42 | |
| KIVI | 2-Bit (K- V-) | - | 14.33 | 19.55 | 38.67 | 26.27 | |
| VidKV | 2-Bit (K- V-) | ✗ | 15.24 | 19.79 | 39.45 | 27.57 | |
| VidKV | 1.5-Bit | 2-Bit | ✗ | 14.06 | 18.91 | 38.11 | 23.38 |
| 1.5-Bit | 2-Bit | ✓ | 14.96 | 19.47 | 39.01 | 25.91 | |
| 1.5-Bit | 1.58-Bit | ✓ | 14.06 | 16.43 | 35.28 | 20.09 | |
| VidKV () | 1.5-Bit | 1.66-Bit | ✓ | 15.31 | 17.99 | 37.24 | 23.06 |
| 1.75-Bit | 1.66-Bit | ✓ | 15.20 | 18.34 | 38.44 | 24.30 | |
| Qwen2.5-VL-7B | |||||||
| Baseline | 16-Bit | - | 19.17 | 20.43 | 40.99 | 41.87 | |
| KIVI | 2-Bit (K- V-) | - | 19.20 | 21.26 | 41.66 | 41.98 | |
| VidKV | 2-Bit (K- V-) | ✗ | 19.97 | 21.26 | 42.06 | 43.15 | |
| VidKV | 1.5-Bit | 2-Bit | ✓ | 19.46 | 21.02 | 42.04 | 41.86 |
| 2-Bit | 1.58-Bit | ✗ | 13.61 | 17.62 | 36.90 | 28.86 | |
| 1.5-Bit | 1.58-Bit | ✓ | 13.09 | 17.44 | 35.88 | 29.76 | |
| VidKV () | 1.5-Bit | 1.66-Bit | ✓ | 14.63 | 17.99 | 37.75 | 31.72 |
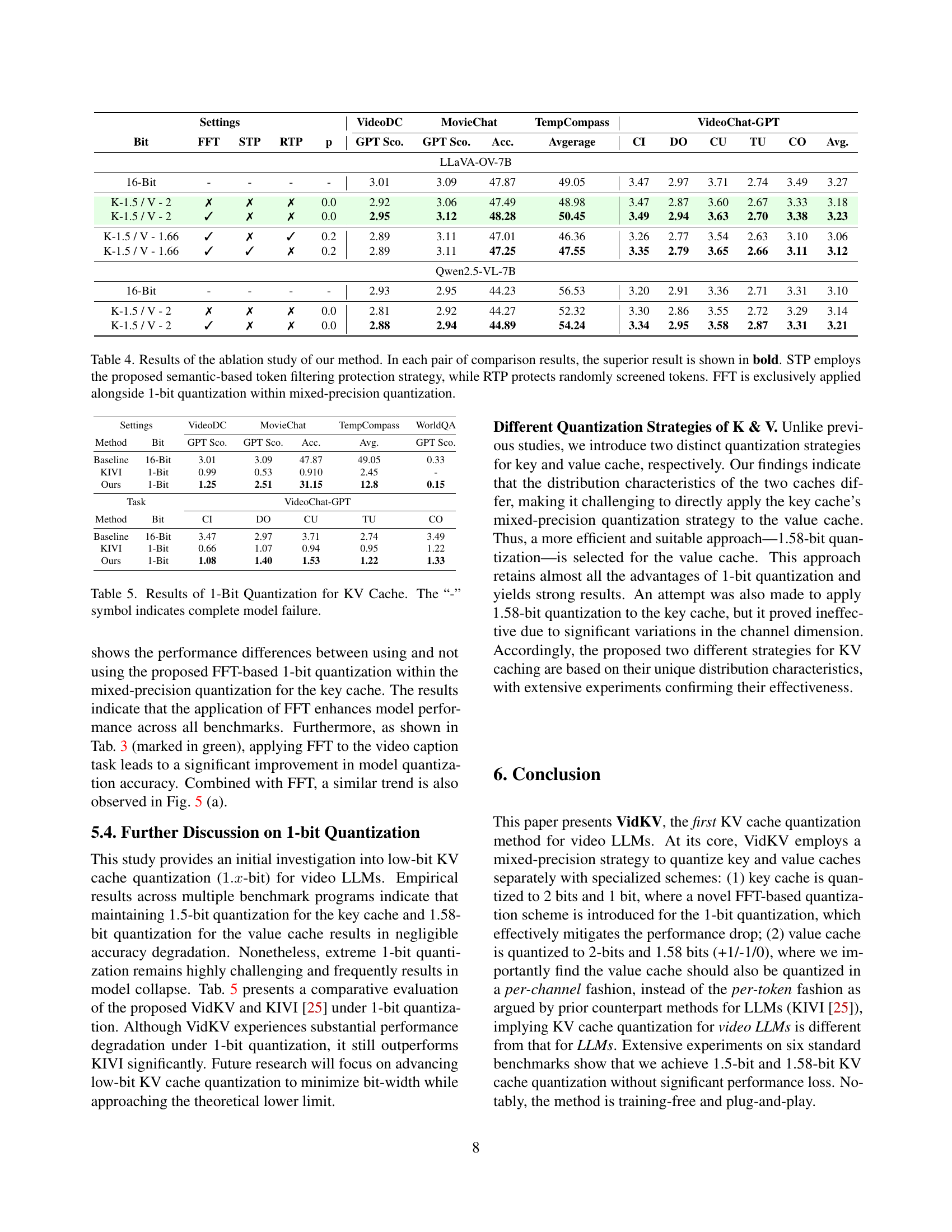
🔼 Table 4 presents an ablation study analyzing the impact of different components of the proposed VidKV method on various video understanding benchmarks. Each row represents a different configuration, systematically varying the use of FFT (Fast Fourier Transform) for 1-bit quantization of the key cache, the Semantic Token Protection (STP) strategy for the value cache, and the Random Token Protection (RTP) strategy, used as a baseline for comparison with STP. The results are compared across multiple metrics for several video benchmarks. The best result for each metric in each experimental setup is highlighted in bold to clearly show the effectiveness of the individual components.
read the caption
Table 4: Results of the ablation study of our method. In each pair of comparison results, the superior result is shown in bold. STP employs the proposed semantic-based token filtering protection strategy, while RTP protects randomly screened tokens. FFT is exclusively applied alongside 1-bit quantization within mixed-precision quantization.

 (a)
(b)
(a)
(b)
|
🔼 This table presents the results of applying 1-bit quantization to both the key and value components of the KV cache in VideoLLMs. It compares the performance of the proposed VidKV method against the KIVI method on several video understanding tasks (VideoDC, MovieChat, TempCompass, WorldQA, and VideoChat-GPT). The results are shown in terms of various metrics such as GPT scores and accuracy. The ‘-’ symbol denotes that the model failed completely under those specific conditions.
read the caption
Table 5: Results of 1-Bit Quantization for KV Cache. The “-” symbol indicates complete model failure.
Full paper#