TL;DR#
Text-to-image diffusion models have shown great progress but training them for high-resolution image generation is difficult. It’s especially hard when training data & computing power are limited. Current methods need large datasets & lots of GPU memory to fine-tune models or struggle to produce high-quality synthetic data. This paper asks if the ultra-resolution adaptation process can be simplified.
This paper answers the question positively by proposing URAE, a set of guidelines focusing on data & parameter efficiency. It shows that using synthetic data created by some teacher models can greatly help training convergence. When synthetic data isn’t available, tuning minor components of weight matrices is better than low-rank adapters. Lastly, it is found disabling classifier-free guidance is essential for guidance-distilled models like FLUX.
Key Takeaways#
Why does it matter?#
This paper introduces URAE, guidelines for ultra-resolution adaptation with limited data and computational resources. It shows using synthetic data and tuning minor components can enhance text-to-image diffusion models and opens new avenues for research in efficient high-resolution generation.
Visual Insights#

🔼 This figure showcases the high-resolution image generation capabilities of the proposed method, ‘Ultra-Resolution Adaptation with Ease (URAE)’. It presents several examples of images generated by the model, demonstrating its ability to produce detailed and visually appealing results at higher resolutions than typically seen in text-to-image models. The diverse range of image styles and subject matter highlights the model’s versatility and potential across various applications.
read the caption
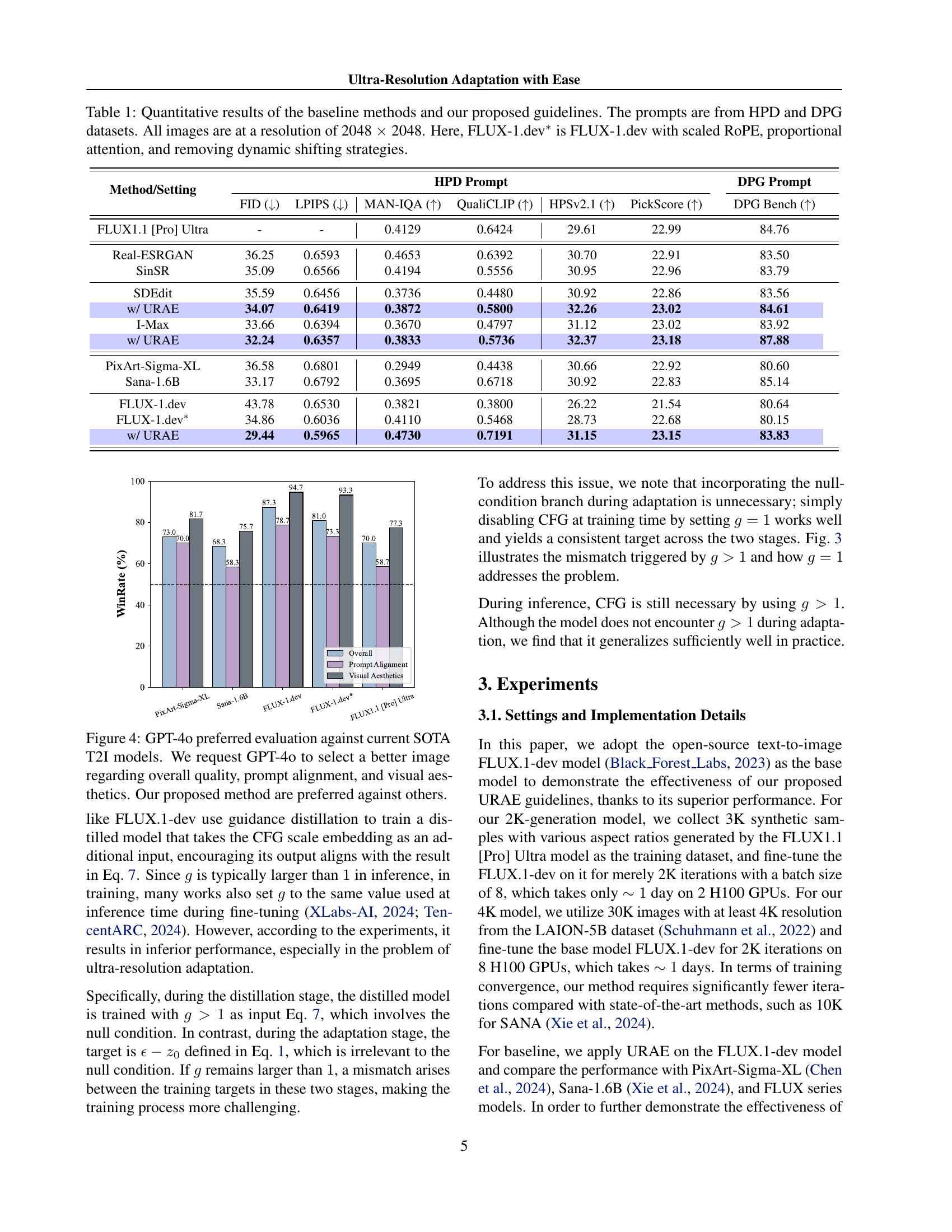
Figure 1: High-resolution results by our method.
| Method/Setting | HPD Prompt | DPG Prompt | ||||||||
| FID () | LPIPS () | MAN-IQA () | QualiCLIP () | HPSv2.1 () | PickScore () | DPG Bench () | ||||
| FLUX1.1 [Pro] Ultra | - | - | 0.4129 | 0.6424 | 29.61 | 22.99 | 84.76 | |||
| Real-ESRGAN | 36.25 | 0.6593 | 0.4653 | 0.6392 | 30.70 | 22.91 | 83.50 | |||
| SinSR | 35.09 | 0.6566 | 0.4194 | 0.5556 | 30.95 | 22.96 | 83.79 | |||
| SDEdit | 35.59 | 0.6456 | 0.3736 | 0.4480 | 30.92 | 22.86 | 83.56 | |||
| w/ URAE | 34.07 | 0.6419 | 0.3872 | 0.5800 | 32.26 | 23.02 | 84.61 | |||
| I-Max | 33.66 | 0.6394 | 0.3670 | 0.4797 | 31.12 | 23.02 | 83.92 | |||
| w/ URAE | 32.24 | 0.6357 | 0.3833 | 0.5736 | 32.37 | 23.18 | 87.88 | |||
| PixArt-Sigma-XL | 36.58 | 0.6801 | 0.2949 | 0.4438 | 30.66 | 22.92 | 80.60 | |||
| Sana-1.6B | 33.17 | 0.6792 | 0.3695 | 0.6718 | 30.92 | 22.83 | 85.14 | |||
| FLUX-1.dev | 43.78 | 0.6530 | 0.3821 | 0.3800 | 26.22 | 21.54 | 80.64 | |||
| FLUX-1.dev∗ | 34.86 | 0.6036 | 0.4110 | 0.5468 | 28.73 | 22.68 | 80.15 | |||
| w/ URAE | 29.44 | 0.5965 | 0.4730 | 0.7191 | 31.15 | 23.15 | 83.83 | |||
🔼 Table 1 presents a quantitative comparison of different text-to-image generation methods. The metrics used are FID (Fréchet Inception Distance), LPIPS (Learned Perceptual Image Patch Similarity), MAN-IQA (a full-reference image quality assessment metric), QualiCLIP (a CLIP-based metric), HPSv2.1 (a human preference metric), PickScore (another human preference metric), and DPG Bench (a benchmark specifically for the DPG dataset). The methods compared include several baseline models and the same models after applying the proposed Ultra-Resolution Adaptation with Ease (URAE) technique. The evaluation is conducted using prompts from the HPD and DPG datasets, with all generated images at a resolution of 2048x2048. A modified version of the FLUX-1.dev model (FLUX-1.dev*) is also included, incorporating scaled RoPE (Rotary Position Embedding), proportional attention, and the removal of dynamic shifting strategies.
read the caption
Table 1: Quantitative results of the baseline methods and our proposed guidelines. The prompts are from HPD and DPG datasets. All images are at a resolution of 2048 ×\times× 2048. Here, FLUX-1.dev∗ is FLUX-1.dev with scaled RoPE, proportional attention, and removing dynamic shifting strategies.
In-depth insights#
URA w/ ease#
URA w/ Ease represents a compelling approach to ultra-resolution adaptation in text-to-image diffusion models. The research tackles the practical challenges of training high-resolution models with limited data and computational resources. The proposed guidelines, URAE, focus on data and parameter efficiency. Synthesizing data from teacher models and tuning minor weight matrix components are key strategies. Disabling classifier-free guidance in specific models is also highlighted. URAE achieves comparable 2K and superior 4K generation performance, establishing new benchmarks and improving compatibility with existing pipelines. This comprehensive strategy offers a pathway to easier ultra-resolution adaptation.
Data Efficiency#
Data efficiency is paramount in ultra-resolution adaptation. The research emphasizes training data scarcity, proposing synthetic data from teacher models to boost convergence. Overcoming the challenges such as data collection, transmission, storage and processing high-resolution images is key. Although large-scale real datasets tend to be noisy, high-quality synthetic data shows much improvement. Diminishing label noise can be achieved if the reference model providing the synthetic data is accurate. These methods allow for the models to become useful particularly for ultra-resolution adaptation.
Tune with URAE#
The concept of ‘Tune with URAE’ suggests an efficient method for fine-tuning models, potentially diffusion models for image generation, using the URAE framework. This implies a departure from traditional fine-tuning, which can be computationally expensive. ‘Tune with URAE’ likely leverages the key guidelines of URAE - data efficiency and parameter efficiency. For data efficiency, it could involve using synthetic data or a subset of real data. Parameter efficiency might involve methods like tuning only a minor set of parameters or low-rank adaptation. The tuning process would be geared towards adapting the model to a specific task or domain, possibly ultra-high resolution image generation while minimizing computational cost and data requirements. This is valuable as it expands accessibility of powerful models.
CFG Guidance#
Classifier-Free Guidance (CFG) is crucial for diffusion models, balancing image quality and diversity. Disabling it during training, especially in distillation, aligns targets and boosts performance in ultra-resolution adaptation. CFG leverages a null-condition branch to guide image generation, but mismatch between training and inference targets can hinder adaptation. Setting the guidance scale to 1 during training resolves this, ensuring consistency and improving results, as models generalize effectively even without encountering specific guidance values during training. Therefore CFG plays a significant role in text to image generation.
Qualitative 4K#
While the paper doesn’t explicitly have a section titled “Qualitative 4K,” the discussion around 4K image generation implicitly addresses qualitative aspects. Achieving high resolution alone isn’t sufficient; the perceived quality by humans is critical. This involves assessing photorealism, detail richness, and aesthetic appeal. The paper showcases that their approach, URAE, improves perceived quality, potentially surpassing other methods. Visualizations show the enhancements, but qualitative assessment can be subjective. User studies (e.g., GPT-4o preference) become vital to provide quantifiable measures of subjective quality. The ultimate goal is to generate 4K images that are not just high-resolution, but also visually compelling and aesthetically pleasing to the human eye. They are also working on better training to further enhance this process.
More visual insights#
More on figures

🔼 Figure 2 illustrates a simplified linear regression model to demonstrate the impact of using synthetic data during model training. The model is trained with a mix of real data (containing noise in the labels) and synthetic data generated by a pre-trained reference model (Wref). The graph displays training error as a function of the number of training iterations, for varying proportions (p) of synthetic data in the training dataset. This shows how the inclusion of synthetic data can impact the convergence speed and accuracy of the model, revealing the trade-off between error due to noise in real labels and error due to the difference between the reference model’s parameters and the optimal parameters.
read the caption
Figure 2: A toy linear regression case. There are real data with noisy labels and synthetic data generated by a reference model Wrefsubscript𝑊𝑟𝑒𝑓W_{ref}italic_W start_POSTSUBSCRIPT italic_r italic_e italic_f end_POSTSUBSCRIPT. The proportion of synthetic data is p𝑝pitalic_p.

🔼 This figure illustrates the impact of classifier-free guidance (CFG) during the training phase of CFG-distilled diffusion models. CFG introduces an additional ’null-condition’ branch during inference, improving the quality of generated samples. However, using CFG during training introduces a mismatch between the training and inference stages. The figure shows that disabling CFG (setting guidance scale to 1) during training yields a consistent target across both stages. Using CFG during training is shown to result in ‘improper matching’ while disabling CFG results in ‘proper matching’. The variables zt (noisy latent representation) and t (timestep) are omitted from the figure for simplicity.
read the caption
Figure 3: For CFG-distilled models, classifier-free guidance should be disabled in the training time. ztsubscript𝑧𝑡z_{t}italic_z start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT and t𝑡titalic_t are omitted from the inputs of ϵθsubscriptitalic-ϵ𝜃\epsilon_{\theta}italic_ϵ start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT and ϵθ′subscriptitalic-ϵsuperscript𝜃′\epsilon_{\theta^{\prime}}italic_ϵ start_POSTSUBSCRIPT italic_θ start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_POSTSUBSCRIPT here for simplicity.

🔼 This figure presents a comparison of different text-to-image (T2I) models, evaluated by GPT-4. The evaluation focuses on three key aspects: overall image quality, how well the generated image aligns with the given text prompt (prompt alignment), and the visual aesthetics of the image. For each prompt, two images generated by different methods were compared and GPT-4 selected the preferred image. The results show that the proposed method consistently outperforms existing state-of-the-art T2I models across all three evaluation criteria.
read the caption
Figure 4: GPT-4o preferred evaluation against current SOTA T2I models. We request GPT-4o to select a better image regarding overall quality, prompt alignment, and visual aesthetics. Our proposed method are preferred against others.

🔼 Figure 5 demonstrates the effectiveness of the proposed Ultra-Resolution Adaptation with Ease (URAE) method when integrated with training-free high-resolution generation pipelines. The input prompt is a simple sentence: ‘A giraffe stands beneath a tree beside a marina.’ The figure showcases the results of several different high-resolution generation pipelines, both with and without the URAE method applied, highlighting the improved visual quality and detail achieved by URAE. This visual comparison shows that URAE significantly enhances the detail and overall quality of the generated images, particularly at higher resolutions.
read the caption
Figure 5: Visualizations of our proposed method apply to training-free high-resolution generation pipelines. The prompt is A giraffe stands beneath a tree beside a marina.

🔼 Figure 6 presents a qualitative comparison of image generation results from various methods, including the proposed URAE approach and several baseline models. Each method is evaluated using the same prompt, and the resulting images (all 2048x2048 pixels) illustrate the differences in visual quality, detail, and adherence to the prompt’s description. This comparison helps showcase the advantages of URAE in terms of image generation quality and fidelity.
read the caption
Figure 6: Qualitative comparisons with baseline methods. All the images are of 2048 ×\times× 2048 size.

🔼 This figure visualizes the results of ablation studies performed to evaluate the effectiveness of different components within the proposed ultra-resolution adaptation method (URAE). The image generation was conducted using the prompt: ‘Imogen Poots portrayed as a D&D Paladin in a fantasy concept art by Tomer Hanuka.’
read the caption
Figure 7: Visualization results of ablation studies. The prompt is Imogen Poots portrayed as a D&D Paladin in a fantasy concept art by Tomer Hanuka.

🔼 Figure 8 presents a comparison of ultra-high-resolution (4096x4096 pixels) images generated by different methods. It showcases the visual quality achieved by various approaches for generating 4K images, highlighting the differences in detail, clarity, and overall aesthetic appeal. The methods compared include: Sana-1.6B, FLUX.1-dev*, PixArt-Sigma-XL, and two versions of the proposed method, URAE (Major-4K) and URAE (Minor-4K). This allows a visual assessment of the effectiveness of the proposed URAE framework in ultra-resolution image generation.
read the caption
Figure 8: Visualization results for ultra-resolution image generation task. All the images are of 4096 ×\times× 4096 size.
More on tables
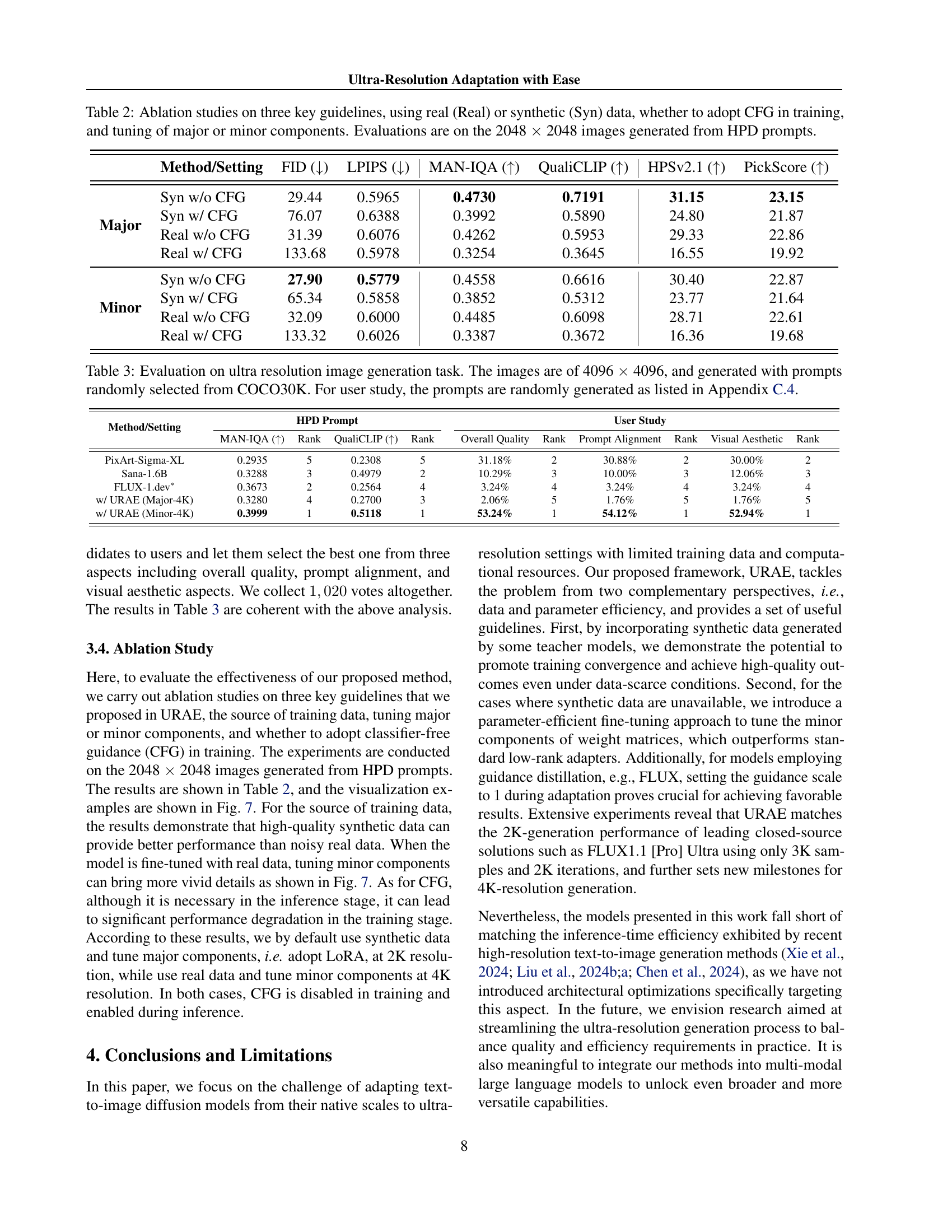
| Method/Setting | FID () | LPIPS () | MAN-IQA () | QualiCLIP () | HPSv2.1 () | PickScore () | |
|---|---|---|---|---|---|---|---|
| Major | Syn w/o CFG | 29.44 | 0.5965 | 0.4730 | 0.7191 | 31.15 | 23.15 |
| Syn w/ CFG | 76.07 | 0.6388 | 0.3992 | 0.5890 | 24.80 | 21.87 | |
| Real w/o CFG | 31.39 | 0.6076 | 0.4262 | 0.5953 | 29.33 | 22.86 | |
| Real w/ CFG | 133.68 | 0.5978 | 0.3254 | 0.3645 | 16.55 | 19.92 | |
| Minor | Syn w/o CFG | 27.90 | 0.5779 | 0.4558 | 0.6616 | 30.40 | 22.87 |
| Syn w/ CFG | 65.34 | 0.5858 | 0.3852 | 0.5312 | 23.77 | 21.64 | |
| Real w/o CFG | 32.09 | 0.6000 | 0.4485 | 0.6098 | 28.71 | 22.61 | |
| Real w/ CFG | 133.32 | 0.6026 | 0.3387 | 0.3672 | 16.36 | 19.68 |
🔼 This ablation study investigates the impact of three key guidelines proposed in the Ultra-Resolution Adaptation with Ease (URAE) method. The guidelines are: using real or synthetic data for training; employing classifier-free guidance (CFG) during training; and tuning major or minor components of the model’s weight matrices. The table shows the results of experiments comparing different combinations of these guidelines, using FID, LPIPS, MAN-IQA, QualiCLIP, HPSv2.1, and PickScore metrics. All evaluations are performed on 2048x2048 images generated from HPD prompts.
read the caption
Table 2: Ablation studies on three key guidelines, using real (Real) or synthetic (Syn) data, whether to adopt CFG in training, and tuning of major or minor components. Evaluations are on the 2048 ×\times× 2048 images generated from HPD prompts.
| Method/Setting | HPD Prompt | User Study | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAN-IQA () | Rank | QualiCLIP () | Rank | Overall Quality | Rank | Prompt Alignment | Rank | Visual Aesthetic | Rank | ||||
| PixArt-Sigma-XL | 0.2935 | 5 | 0.2308 | 5 | 31.18% | 2 | 30.88% | 2 | 30.00% | 2 | |||
| Sana-1.6B | 0.3288 | 3 | 0.4979 | 2 | 10.29% | 3 | 10.00% | 3 | 12.06% | 3 | |||
| FLUX-1.dev∗ | 0.3673 | 2 | 0.2564 | 4 | 3.24% | 4 | 3.24% | 4 | 3.24% | 4 | |||
| w/ URAE (Major-4K) | 0.3280 | 4 | 0.2700 | 3 | 2.06% | 5 | 1.76% | 5 | 1.76% | 5 | |||
| w/ URAE (Minor-4K) | 0.3999 | 1 | 0.5118 | 1 | 53.24% | 1 | 54.12% | 1 | 52.94% | 1 | |||
🔼 Table 3 presents a quantitative evaluation of ultra-high-resolution (4096x4096 pixels) image generation. The models were tested using prompts randomly chosen from the COCO30K dataset. Additionally, a user study was conducted to assess the generated images; the prompts used in this study are detailed in Appendix C.4. The table likely shows various metrics evaluating the quality and fidelity of the generated 4K images.
read the caption
Table 3: Evaluation on ultra resolution image generation task. The images are of 4096 ×\times× 4096, and generated with prompts randomly selected from COCO30K. For user study, the prompts are randomly generated as listed in Appendix C.4.
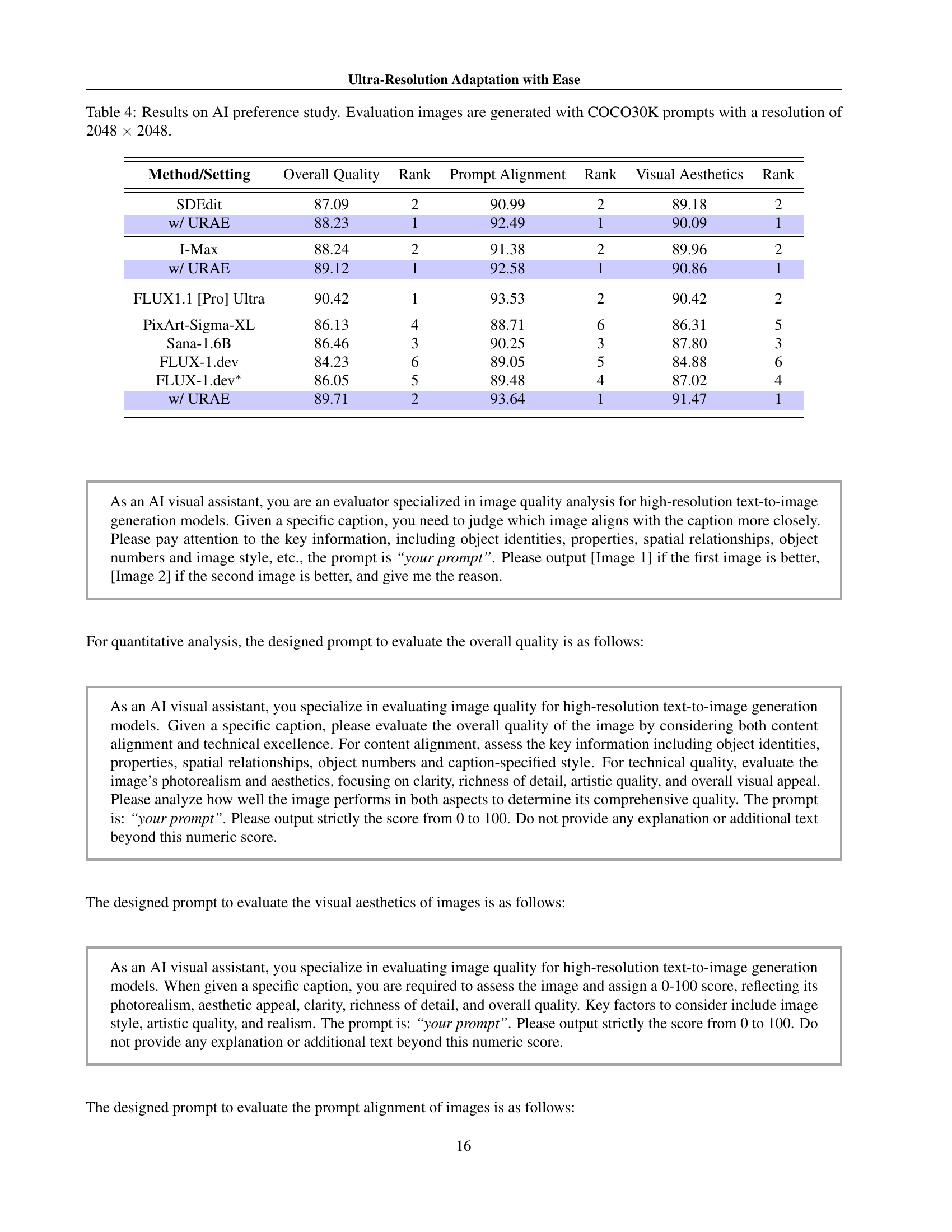
| Method/Setting | Overall Quality | Rank | Prompt Alignment | Rank | Visual Aesthetics | Rank |
|---|---|---|---|---|---|---|
| SDEdit | 87.09 | 2 | 90.99 | 2 | 89.18 | 2 |
| w/ URAE | 88.23 | 1 | 92.49 | 1 | 90.09 | 1 |
| I-Max | 88.24 | 2 | 91.38 | 2 | 89.96 | 2 |
| w/ URAE | 89.12 | 1 | 92.58 | 1 | 90.86 | 1 |
| FLUX1.1 [Pro] Ultra | 90.42 | 1 | 93.53 | 2 | 90.42 | 2 |
| PixArt-Sigma-XL | 86.13 | 4 | 88.71 | 6 | 86.31 | 5 |
| Sana-1.6B | 86.46 | 3 | 90.25 | 3 | 87.80 | 3 |
| FLUX-1.dev | 84.23 | 6 | 89.05 | 5 | 84.88 | 6 |
| FLUX-1.dev∗ | 86.05 | 5 | 89.48 | 4 | 87.02 | 4 |
| w/ URAE | 89.71 | 2 | 93.64 | 1 | 91.47 | 1 |
🔼 Table 4 presents the results of an AI preference study comparing different text-to-image generation models. Using 300 prompts from the COCO30K dataset, images were generated at a resolution of 2048x2048. The GPT-40 AI model acted as the evaluator and ranked each model across three key criteria: overall image quality, how well the image aligned with the prompt, and visual aesthetics. Rankings for each method and various modifications are shown.
read the caption
Table 4: Results on AI preference study. Evaluation images are generated with COCO30K prompts with a resolution of 2048 ×\times× 2048.
Full paper#