TL;DR#
Knowledge Editing (KE) in Large Language Models (LLMs) is challenged by the need to effectively update and generalize information across multi-hop reasoning tasks. Existing KE methods struggle with integrating updated information into reasoning pathways because they focus on single or few model layers. This leads to inconsistent knowledge propagation and poor performance in downstream reasoning tasks.
This paper introduces CaKE, a novel method that enhances the integration of updated knowledge in LLMs. CaKE uses strategically curated data to enforce the model to utilize the modified knowledge, stimulating the development of appropriate reasoning circuits. Experimental results demonstrate that CaKE improves use of updated knowledge across reasoning tasks, improving the accuracy.
Key Takeaways#
Why does it matter?#
This paper introduces CaKE, a new knowledge editing method, which significantly improves the accuracy of multi-hop reasoning in LLMs. This advancement is crucial for enhancing the reliability of LLMs. It addresses issues with knowledge integration and reasoning circuits, providing a solid foundation for future research in knowledge editing and reasoning.
Visual Insights#
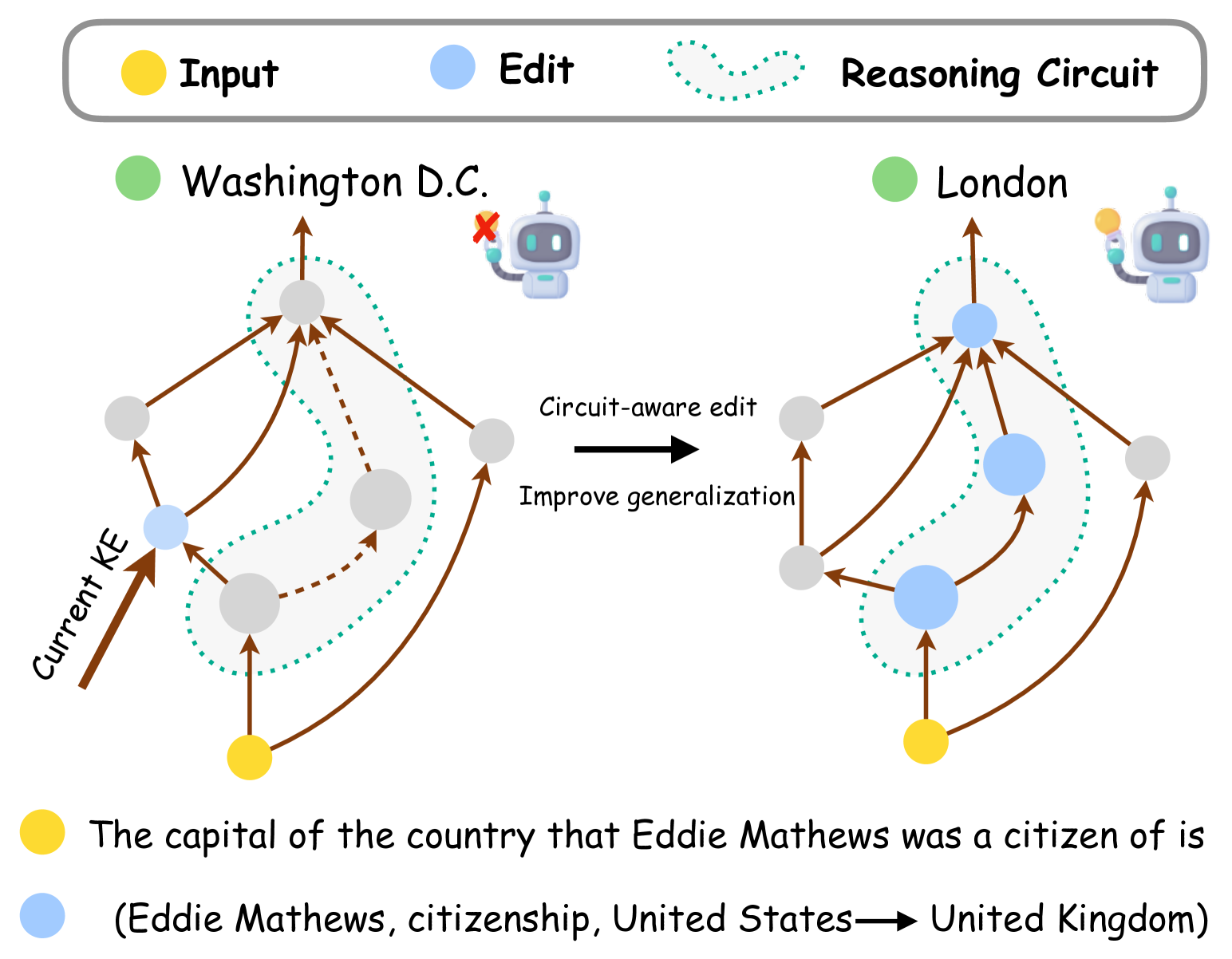
🔼 This figure illustrates the limitations of existing knowledge editing techniques in handling multi-hop reasoning tasks. The left side shows a standard knowledge editing approach where an edit is made (e.g., changing the citizenship of a person), but this edit fails to propagate correctly through the neural pathways (reasoning circuits) used by the language model to answer complex, multi-step questions. The result is that the model still produces incorrect answers even when the new information is factually correct. The right side proposes a solution, ‘circuit-aware editing,’ aimed at integrating the updated knowledge effectively within these reasoning circuits, thereby enabling the model to answer multi-hop questions correctly after the edit.
read the caption
Figure 1: The current edit cannot propagate the new knowledge to the reasoning circuit for multi-hop reasoning. We propose a circuit-aware edit to improve the model’s multi-hop reasoning performance involving the updated knowledge.
| Model | Entity Patch | Relation Patch |
| LLaMA3-8B-Ins. | 85.35 | 56.20 |
| Qwen2.5-7B-Ins. | 97.29 | 55.40 |
🔼 This table presents the success rates of activation patching experiments conducted to validate the hypothesis of a reasoning circuit in LLMs. Activation patching involves replacing the representation of an entity or relation with an alternative to determine its influence on model output. Higher success rates indicate stronger reliance on the specific representations for correct reasoning and support the circuit hypothesis.
read the caption
Table 1: Activation Patching Success Rates (%).
In-depth insights#
Circuit-Aware KE#
Circuit-aware knowledge editing (CaKE) is a fascinating area that shifts the focus from simply updating facts to strategically modifying the neural pathways (circuits) within LLMs. The key idea is that LLMs don’t just store information; they actively use it via specialized circuits. Existing KE methods often fail because they treat knowledge as isolated facts, rather than considering how it’s integrated into these reasoning circuits. CaKE attempts to address this by using curated training data, tailored to force the model to utilize the updated knowledge within relevant circuits. This involves creating tasks that explicitly require the LLM to reason with the new information, stimulating the development of appropriate reasoning circuits. This approach aims to create more robust and generalizable knowledge, leading to better performance in downstream tasks that rely on the modified information, making CaKE a promising direction for improving the reliability and utility of LLMs.
Multi-Hop Limits#
The limitations in multi-hop reasoning for language models are multifaceted. Firstly, knowledge integration across multiple hops presents a challenge, as information relevant to different stages of the reasoning process may not be effectively combined. Secondly, reasoning circuits may suffer from signal degradation, especially in deeper models, making it difficult to maintain information fidelity across multiple hops. Thirdly, the model’s attention mechanism may be biased towards certain entities or relationships, hindering its ability to explore diverse reasoning paths. Fourthly, limitations on context window might truncate important pieces of evidence, impacting ability to connect long-range relationships in the graph of knowledge. Future research should explore methods to enhance knowledge integration, bolster signal strength, improve attention mechanisms, and develop more structured representations for multi-hop reasoning.
Reasoning Circuits#
Reasoning circuits are the neural pathways LLMs use for knowledge-based inference, suggesting that knowledge isn’t statically stored but dynamically activated. The organization of these circuits plays a key role in effective knowledge utilization. Current layer-localized KE approaches like MEMIT and WISE, which edit only a few model layers, struggle to incorporate updated information into these pathways, highlighting a misalignment between KE strategies and LLM reasoning architectures. Multi-hop reasoning emerges from coordinated computing circuits, where early layers handle the first hop and bridge entities are routed to the last token position in middle layers for completing the reasoning. Effective knowledge editing requires considering the circuit-level integration, not just isolated parameter changes, to ensure the updated knowledge is consistently and accurately used across related reasoning tasks. The performance of edited models in downstream reasoning tasks that involve the updated knowledge is crucial. Critical information either fails to be properly routed to the last token position, or exhibits a weak signal, preventing effective reasoning.
KE’s Generalization#
Knowledge Editing (KE) faces significant hurdles in achieving generalization. While KE methods can successfully modify isolated facts, they often struggle to ensure that these updates propagate consistently across related knowledge structures and downstream reasoning tasks. The challenge lies in effectively integrating the edited knowledge into the broader network of information within the model, ensuring it’s not just a localized change. Overfitting to the specific edited fact can lead to poor performance on more complex, multi-hop reasoning scenarios. A truly generalizable KE method must consider the underlying reasoning circuits of the model, ensuring that the updated knowledge is accessible and utilized across a variety of tasks and contexts. Moreover, preventing unintended side effects, such as disrupting unrelated knowledge, is crucial for maintaining the model’s overall performance and reliability. The key to advancing KE’s generalization capabilities lies in developing methods that go beyond simple parameter adjustments and instead focus on creating robust and adaptable knowledge representations.
Future CoT Work#
Future work in Chain-of-Thought (CoT) reasoning can explore several avenues. One direction is to investigate more sophisticated methods for generating intermediate reasoning steps, moving beyond simple, linear chains. This could involve exploring hierarchical CoT, where sub-problems are solved independently before being integrated, or adaptive CoT, where the reasoning path is adjusted based on the input query. Another important area is improving the robustness of CoT to noisy or ambiguous information. This could involve incorporating uncertainty estimates into the reasoning process or developing methods for identifying and correcting errors in intermediate steps. Furthermore, investigating the interplay between CoT and knowledge retrieval is crucial. Combining CoT with external knowledge sources could lead to more accurate and reliable reasoning, especially in domains requiring factual knowledge. Finally, evaluating the faithfulness of CoT explanations is essential to ensure that the generated reasoning steps accurately reflect the model’s internal decision-making process.
More visual insights#
More on figures

🔼 This figure provides a visual summary of the research presented in the paper. It showcases the limitations of existing knowledge editing (KE) methods in handling multi-hop reasoning tasks. Panel (a) illustrates the multi-hop reasoning process within large language models (LLMs), highlighting the potential failure points in signal propagation and information flow. Panel (b) contrasts two prevalent KE strategies (WISE-style and ROME-style) and illustrates their failure to integrate new knowledge into the reasoning pathways effectively. Panel (c) presents the proposed Circuit-aware Knowledge Editing (CaKE) method, which strategically leverages additional features to guide the model towards utilizing updated knowledge more accurately and consistently.
read the caption
Figure 2: An overview of our work.

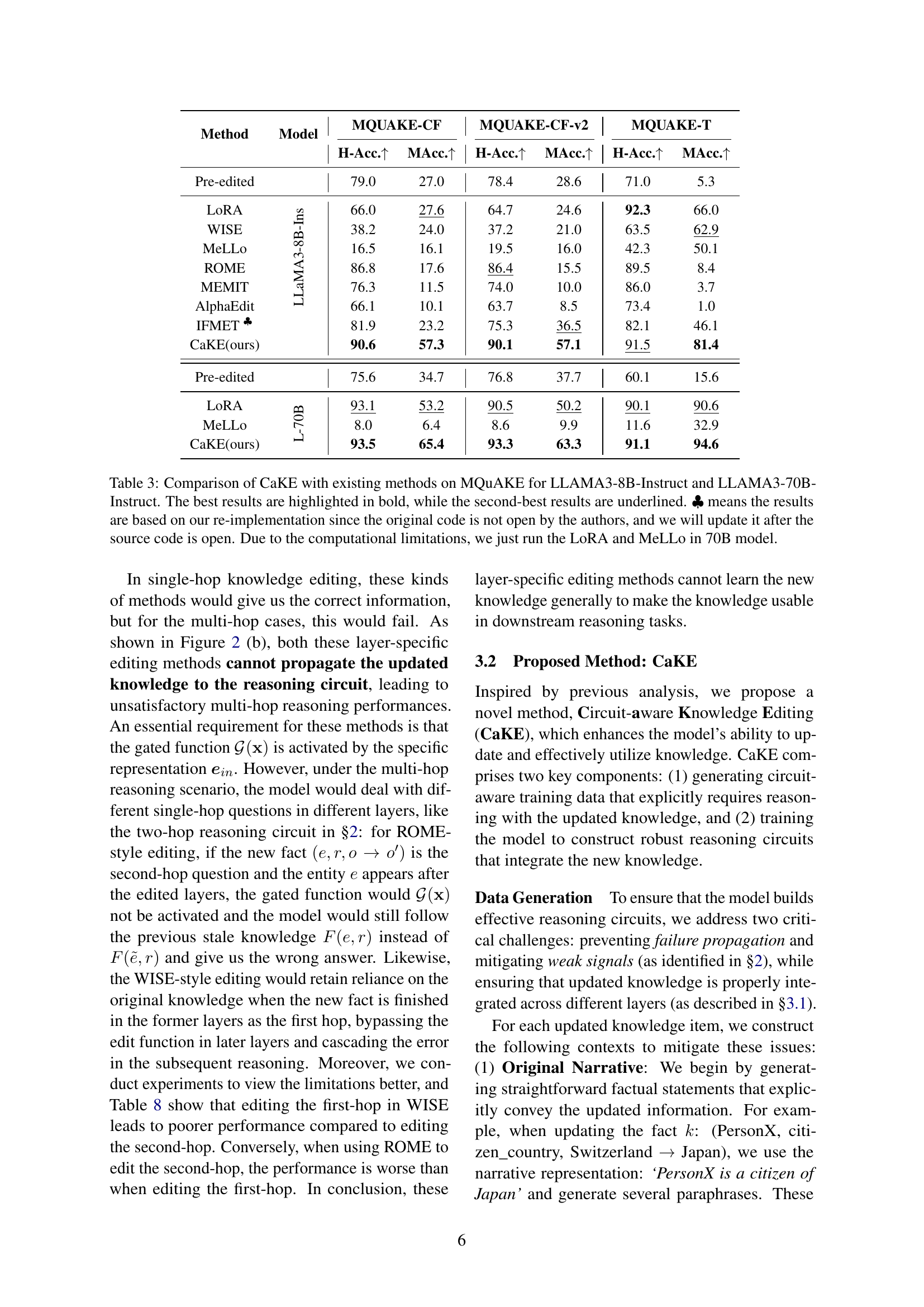
🔼 This figure displays the outcomes of experiments designed to address failures in multi-hop reasoning within LLAMA3 and Qwen2.5 language models. The experiments involved interventions to enhance information flow at critical points within the models’ reasoning circuits. The results show success rates of the intervention methods across different failure categories, indicating the effectiveness of the approaches in improving multi-hop reasoning.
read the caption
Figure 3: Results of the intervention on the failure cases in multi-hop reasoning of LLAMA3 and Qwen2.5.
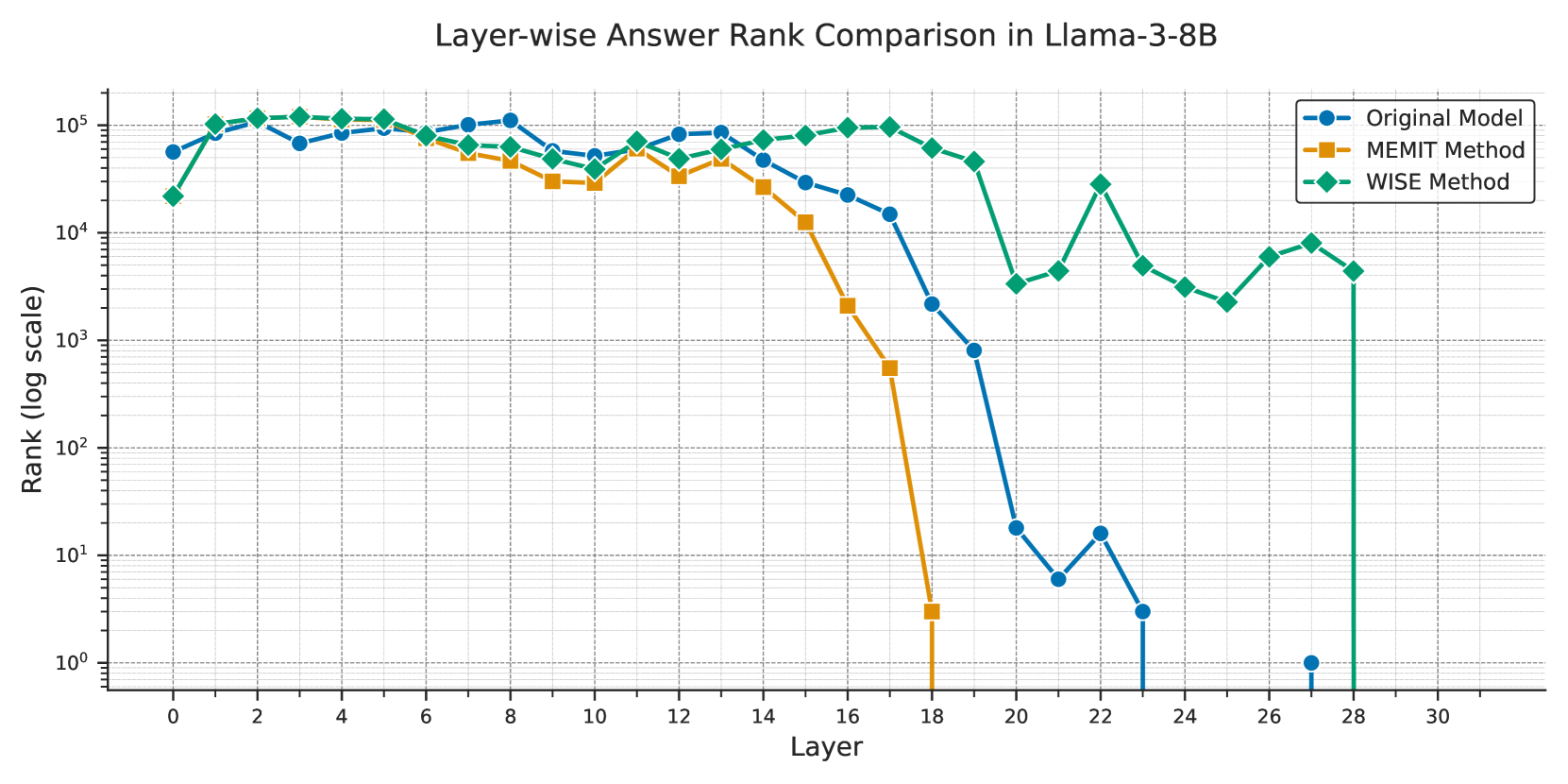
🔼 This figure compares the ranking of the correct answer token (‘Korean’) within the model’s vocabulary across different layers of the language model. It demonstrates the effect of three different knowledge editing methods (MEMIT, WISE, and the original, unedited model) on the propagation of the edited fact: changing the official language of Japan from Japanese to Korean. The rank indicates how likely the model was to predict ‘Korean’ as the correct answer at each layer, with lower ranks signifying a higher probability. This visualization helps understand how the different editing methods affect the flow of information and the integration of new knowledge within the language model’s architecture.
read the caption
Figure 4: The target answer token’s rank in the vocabulary of different editing methods when editing the fact ‘The official language of Japan is Japanese →→\rightarrow→ Korean.’

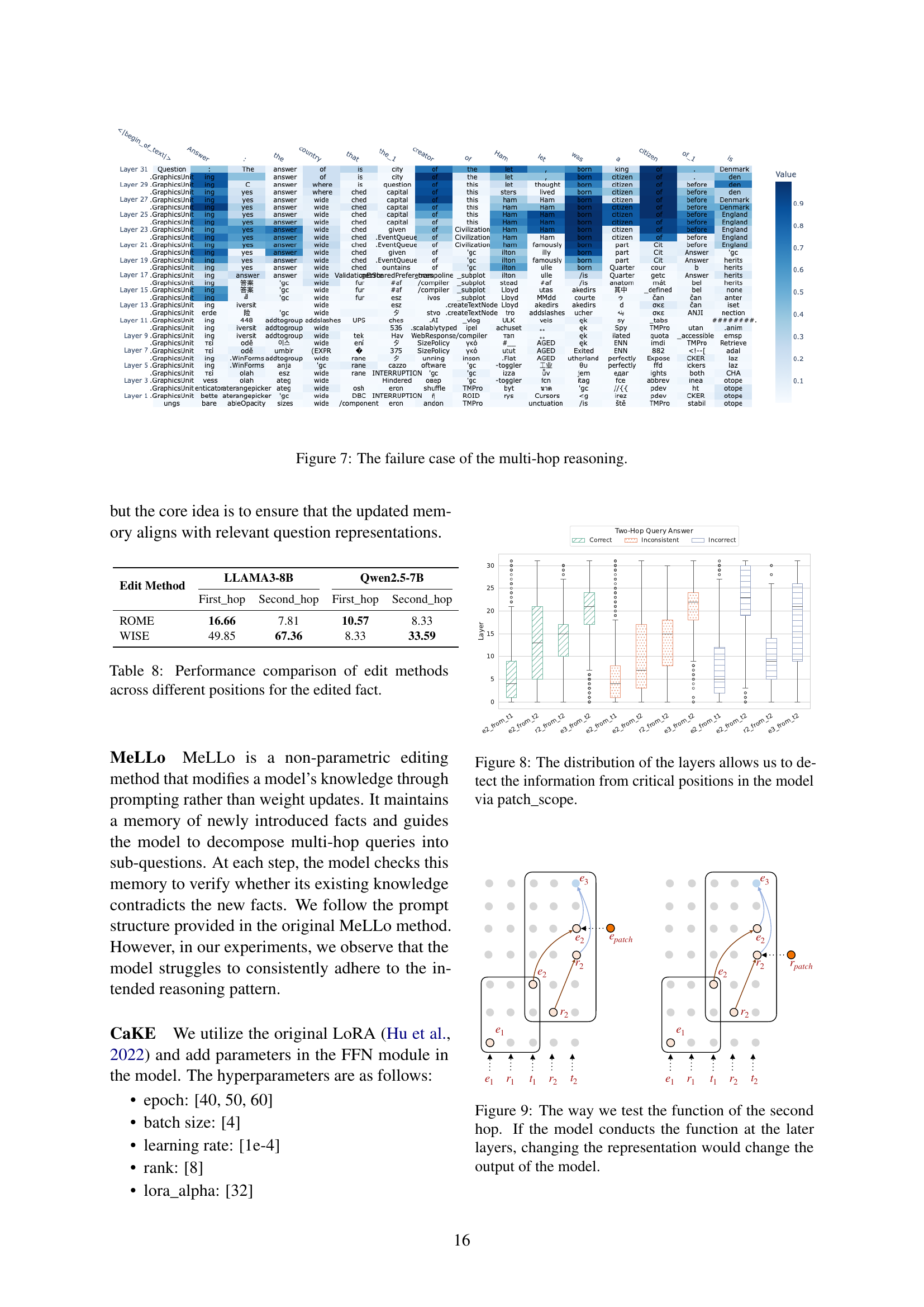
🔼 This figure displays the results of experiments conducted on the LLAMA3-8B-Instruct model using the MQuAKE-CF-3k-v2 dataset. It investigates the impact of the number of hops (the number of reasoning steps involved in a multi-hop question) and the position of the edit (where in the question sequence the knowledge is updated) on the model’s accuracy. The x-axis represents the number of hops, and the y-axis shows the accuracy. Different colors represent different edit positions: ‘pre’ (before the multi-hop question), ‘mid’ (in the middle), and ‘post’ (after). The graph visually demonstrates how the model’s performance changes based on these factors, highlighting the influence of both the number of reasoning steps and the placement of the knowledge update within the multi-hop question.
read the caption
Figure 5: Accuracies of different number hops and edit-positions in MQuAKE-CF-3k-v2 on LLAMA3-8B-Instruct.

🔼 This figure displays the logit values of the bridge entity (e2) and the second relation (r2) at the final token position (t2) for various knowledge editing methods. Logits represent the model’s confidence in each entity or relation. The goal is to show how different knowledge editing techniques affect the model’s ability to incorporate the updated knowledge, which is represented by e2 and r2, into its reasoning process. Higher logit values for e2 and r2 indicate a stronger signal for the model to correctly identify the intended entities and relations during multi-hop reasoning.
read the caption
Figure 6: e2subscript𝑒2e_{2}italic_e start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT and r2subscript𝑟2r_{2}italic_r start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT’s logits at t2subscript𝑡2t_{2}italic_t start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT in models after different knowledge editing methods.

🔼 This figure visualizes a case where multi-hop reasoning fails. It shows the layer-wise activation probabilities for various entities and relations in a language model processing a multi-hop question. The model successfully identifies intermediate elements early on but then deviates from the correct reasoning path in later layers, ultimately leading to an incorrect final answer. The heatmap allows for a visual analysis of where and when the model’s reasoning goes astray. The visualization highlights the limitations of layer-localized knowledge editing methods, which often fail to correct faulty multi-hop reasoning patterns.
read the caption
Figure 7: The failure case of the multi-hop reasoning.

🔼 Figure 8 uses the PatchScope method to analyze the layers of a language model during multi-hop reasoning tasks. It visualizes where key pieces of information (the bridge entity ’e2’ and relation ‘r2’) are present in the model’s layers for successful and unsuccessful reasoning cases. By showing the distribution of these key elements across layers, the figure helps explain why some multi-hop reasoning attempts succeed while others fail, highlighting the importance of timely and proper propagation of information within the model’s architecture for successful multi-hop reasoning. The layer distribution demonstrates the success or failure of the model to properly use information during the multi-hop reasoning process.
read the caption
Figure 8: The distribution of the layers allows us to detect the information from critical positions in the model via patch_scope.

🔼 This figure demonstrates a causal analysis to validate the hypothesis of a structured reasoning circuit in LLMs for multi-hop tasks. By replacing the representation of the bridge entity (e2) or the second relation (r2) at the last token position (t2) with alternatives, the researchers observe how these changes affect the model’s output. Successful patching confirms the model’s reliance on specific representations for reasoning in multi-hop scenarios, supporting the existence of a structured reasoning circuit.
read the caption
Figure 9: The way we test the function of the second hop. If the model conducts the function at the later layers, changing the representation would change the output of the model.

🔼 This figure illustrates the causal analysis conducted to investigate the impact of modifying variables in the multi-hop reasoning circuit of large language models (LLMs). Specifically, it shows how replacing the representation of the bridge entity (e2) or the second relation (r2) at the last token position (t2) affects the model’s output. The ‘backpatch-t1’ and ‘backpatch-t2’ interventions involve replacing the representations of e2 at t1 (end of the first hop) and t2 (end of the second hop), respectively, while ’t1-to-t2’ propagates the representation of e2 from t1 to t2. This causal analysis helps to understand the model’s reliance on specific intermediate representations and to confirm whether it properly activates the updated knowledge in the reasoning circuit.
read the caption
Figure 10: The way we conduct the backpatch and e1subscript𝑒1e_{1}italic_e start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT to e2subscript𝑒2e_{2}italic_e start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT. We substitute the hidden representations from the source position to the target position.
More on tables
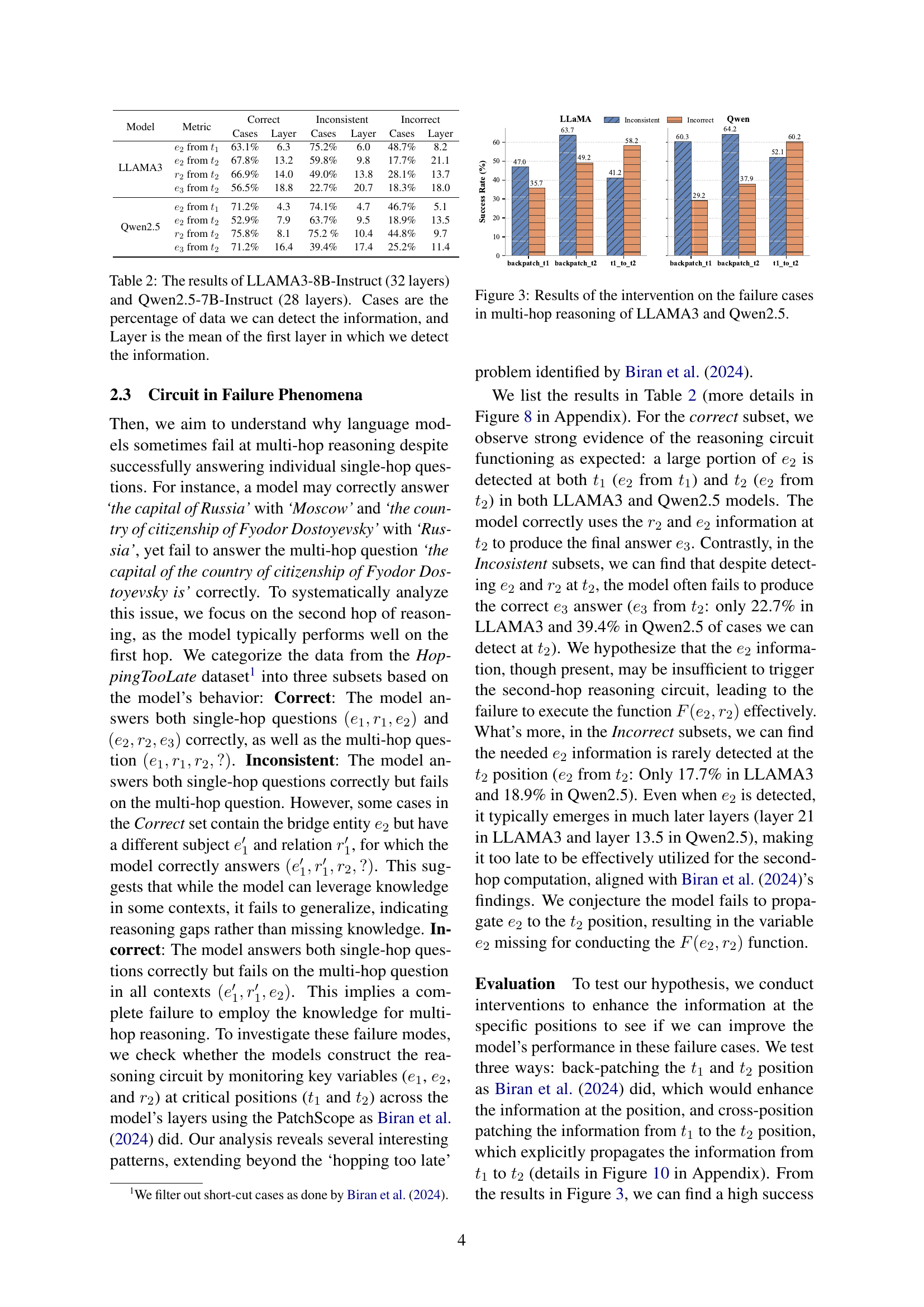
| Model | Metric | Correct | Inconsistent | Incorrect | |||
| Cases | Layer | Cases | Layer | Cases | Layer | ||
| LLAMA3 | from | 63.1% | 6.3 | 75.2% | 6.0 | 48.7% | 8.2 |
| from | 67.8% | 13.2 | 59.8% | 9.8 | 17.7% | 21.1 | |
| from | 66.9% | 14.0 | 49.0% | 13.8 | 28.1% | 13.7 | |
| from | 56.5% | 18.8 | 22.7% | 20.7 | 18.3% | 18.0 | |
| Qwen2.5 | from | 71.2% | 4.3 | 74.1% | 4.7 | 46.7% | 5.1 |
| from | 52.9% | 7.9 | 63.7% | 9.5 | 18.9% | 13.5 | |
| from | 75.8% | 8.1 | 75.2 % | 10.4 | 44.8% | 9.7 | |
| from | 71.2% | 16.4 | 39.4% | 17.4 | 25.2% | 11.4 | |
🔼 This table presents the results of an analysis conducted on two large language models, LLAMA3-8B-Instruct (32 layers) and Qwen2.5-7B-Instruct (28 layers). The analysis focuses on identifying the presence and layer depth of specific information within the models’ reasoning processes during multi-hop question answering. For each of several information elements (e2 from t1, e2 from t2, r2 from t2, and e3 from t2), the table shows the percentage of cases where the information was successfully detected (‘Cases’) and the average layer number where the information was first detected (‘Layer’). This data provides insights into how effectively the models utilize knowledge during multi-hop reasoning, shedding light on potential bottlenecks or failures in information propagation.
read the caption
Table 2: The results of LLAMA3-8B-Instruct (32 layers) and Qwen2.5-7B-Instruct (28 layers). Cases are the percentage of data we can detect the information, and Layer is the mean of the first layer in which we detect the information.
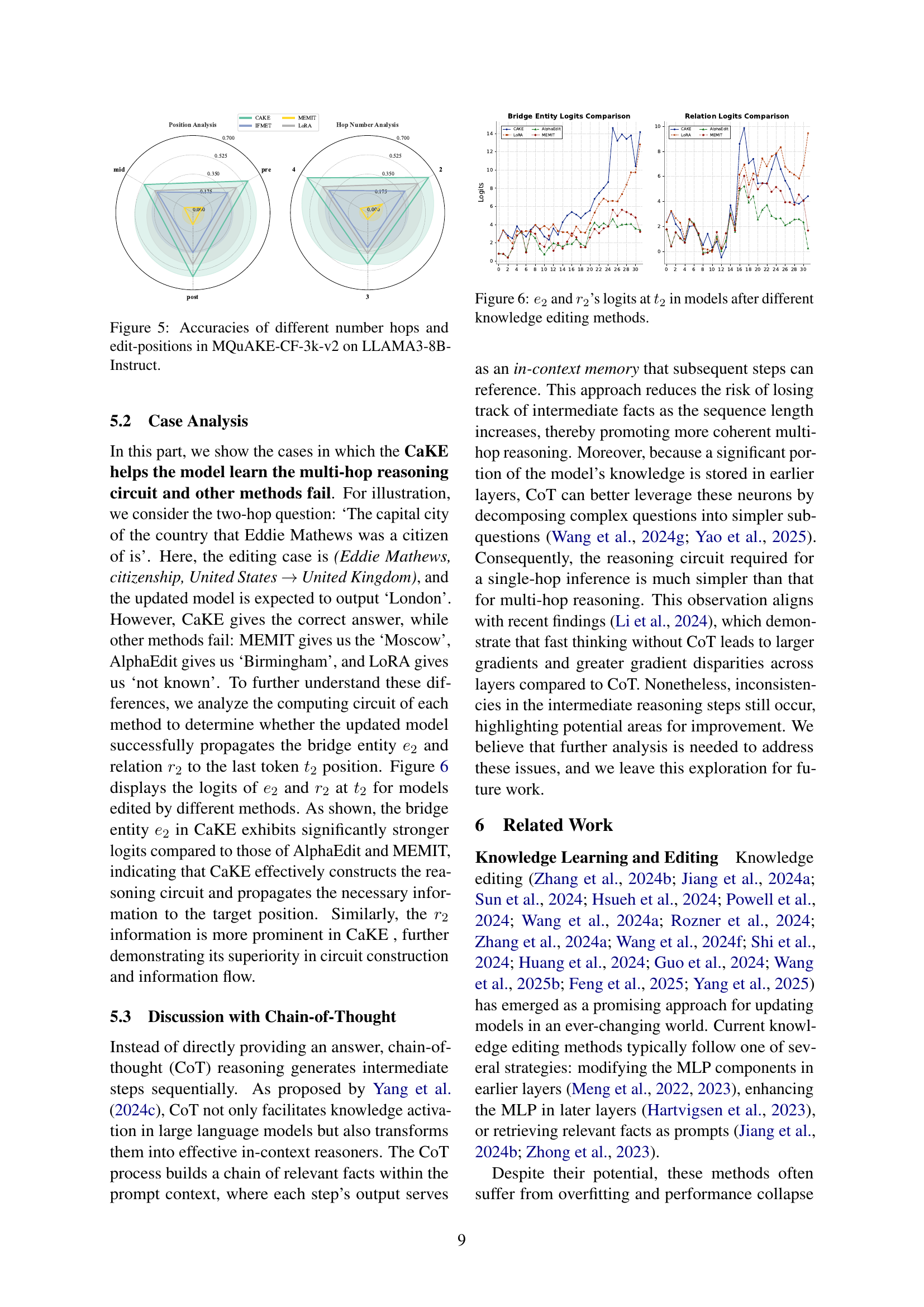
| Method | Model | MQUAKE-CF | MQUAKE-CF-v2 | MQUAKE-T | |||
| H-Acc. | MAcc. | H-Acc. | MAcc. | H-Acc. | MAcc. | ||
| Pre-edited | LLaMA3-8B-Ins | 79.0 | 27.0 | 78.4 | 28.6 | 71.0 | 5.3 |
| LoRA | 66.0 | 27.6 | 64.7 | 24.6 | 92.3 | 66.0 | |
| WISE | 38.2 | 24.0 | 37.2 | 21.0 | 63.5 | 62.9 | |
| MeLLo | 16.5 | 16.1 | 19.5 | 16.0 | 42.3 | 50.1 | |
| ROME | 86.8 | 17.6 | 86.4 | 15.5 | 89.5 | 8.4 | |
| MEMIT | 76.3 | 11.5 | 74.0 | 10.0 | 86.0 | 3.7 | |
| AlphaEdit | 66.1 | 10.1 | 63.7 | 8.5 | 73.4 | 1.0 | |
| IFMET ♣ | 81.9 | 23.2 | 75.3 | 36.5 | 82.1 | 46.1 | |
| CaKE(ours) | 90.6 | 57.3 | 90.1 | 57.1 | 91.5 | 81.4 | |
| Pre-edited | 75.6 | 34.7 | 76.8 | 37.7 | 60.1 | 15.6 | |
| LoRA | L-70B | 93.1 | 53.2 | 90.5 | 50.2 | 90.1 | 90.6 |
| MeLLo | 8.0 | 6.4 | 8.6 | 9.9 | 11.6 | 32.9 | |
| CaKE(ours) | 93.5 | 65.4 | 93.3 | 63.3 | 91.1 | 94.6 | |
🔼 This table presents a comparison of the performance of CaKE and several other existing knowledge editing methods on the MQuAKE benchmark dataset. The benchmark uses two different language models, LLAMA3-8B-Instruct and LLAMA3-70B-Instruct, and evaluates performance using two metrics: Hop Accuracy (H-Acc) and Multi-hop Accuracy (MAcc). Results are shown for three variations of the MQuAKE dataset, representing different complexities and types of multi-hop reasoning tasks. The best performing method for each metric and dataset is highlighted in bold, while the second best is underlined. Note that some results marked with ♣♣{ clubsuit}♣ indicate that the results are from re-implementations of other methods because the original code was not publicly available by those authors. Due to computational constraints, only LoRA and MeLLo were run on the larger LLAMA3-70B model.
read the caption
Table 3: Comparison of CaKE with existing methods on MQuAKE for LLAMA3-8B-Instruct and LLAMA3-70B-Instruct. The best results are highlighted in bold, while the second-best results are underlined. ♣♣{\clubsuit}♣ means the results are based on our re-implementation since the original code is not open by the authors, and we will update it after the source code is open. Due to the computational limitations, we just run the LoRA and MeLLo in 70B model.
| Method | Model | MQUAKE-CF | MQUAKE-CF-v2 | MQUAKE-T | |||
| H-Acc. | MAcc. | H-Acc. | MAcc. | Hop-wise. | MAcc. | ||
| Pre-edited | Qwen2.5-7B-Ins | 73.4 | 40.7 | 72.8 | 39.5 | 56.1 | 15.6 |
| LoRA | 35.1 | 24.9 | 36.5 | 25.9 | 25.0 | 28.6 | |
| WISE | 41.2 | 9.8 | 26.5 | 8.0 | 50.2 | 36.5 | |
| MeLLo | 35.5 | 7.8 | 34.5 | 7.6 | 52.7 | 56.5 | |
| ROME | 75.4 | 10.7 | 73.4 | 8.8 | 86.7 | 17.7 | |
| MEMIT | 82.6 | 11.1 | 83.4 | 9.6 | 88.9 | 18.5 | |
| AlphaEdit | 73.8 | 12.6 | 75.1 | 10.5 | 82.2 | 17.2 | |
| IFMET ♣ | 83.7 | 25.7 | 84.6 | 24.5 | 90.0 | 52.8 | |
| CaKE(ours) | 90.6 | 61.4 | 90.3 | 63.05 | 95.5 | 87.8 | |
🔼 This table presents a comparison of the performance of CaKE and other existing knowledge editing methods on the MQuAKE benchmark, specifically using the Qwen2.5-7B-Instruct language model. The results are broken down by three metrics: Hop-wise Accuracy (H-Acc), Multi-hop Accuracy (MAcc), and Hop-wise Accuracy (Acc) showing the accuracy across different numbers of hops in the reasoning chain. The best results for each metric are shown in bold, and the second-best results are underlined. Note that some results (marked with ♣♣{ clubsuit}♣♣) are based on the authors’ own reimplementation of the methods because the original source code was not publicly available; these results will be updated once the original code becomes available.
read the caption
Table 4: Comparison of CaKE with existing methods on MQuAKE on Qwen2.5-7B-Instruct. The best results are highlighted in bold, while the second-best results are underlined. ♣♣{\clubsuit}♣ means the results are based on our own implementation since the original code is not open by the authors, and we will update it after the source code is open.
| CSQA | BBH | MMLU | GSM8k | |
| LLaMA3-8B-Ins | 76.09 | 67.89 | 63.83 | 75.20 |
| MEMIT | 76.08 | 67.88 | 63.82 | 75.21 |
| ROME | 72.98 | 61.37 | 62.95 | 74.59 |
| CAKE | 75.10 | 67.20 | 62.98 | 76.04 |
| Qwen2.5-7B-Ins | 82.31 | 33.39 | 71.80 | 82.26 |
| MEMIT | 82.39 | 37.37 | 71.80 | 81.96 |
| ROME | 72.57 | 34.22 | 63.38 | 72.21 |
| CAKE | 82.64 | 37.44 | 71.76 | 82.79 |
🔼 This table presents the results of evaluating the locality performance of CaKE and several other knowledge editing methods. Locality refers to the ability of a knowledge editing method to update a model’s knowledge without negatively impacting its performance on unrelated tasks. The table shows the accuracy scores achieved by each method on four commonly used general-purpose benchmarks: CommonsenseQA, BigBenchHard, MMLU, and GSM8k. These benchmarks assess different aspects of language understanding, including commonsense reasoning, complex reasoning, and knowledge about various topics. The results provide insights into how well each method maintains the overall capabilities of the language model while incorporating new knowledge.
read the caption
Table 5: Locality Performance on several general benchmarks of CaKE and other editing methods.
| Model | Correct | Inconsistent | Incorrect |
| LLaMA3-8B-Ins. | 1,005 | 1,032 | 1,240 |
| Qwen2.5-7B-Ins. | 241 | 252 | 275 |
🔼 This table presents the dataset used for the circuit analysis in the paper. It shows the distribution of data points across three categories: correct, inconsistent, and incorrect, for two different language models: LLaMA3-8B-Instruct and Qwen2.5-7B-Instruct. The numbers indicate how many data points fall into each category for each model.
read the caption
Table 6: The dataset we used in the analysis.
| Knowledge Type | Template | Answer |
| {target_person} works in the field of {target_field} . | In a book related to different fields, Section A discusses {random_field}, Section B discusses {random_field}, and Section C discusses {target_field}. If you want to learn about {target_person}’s field, which section should you read? | The working field of {target_person} is discussed in Section C. |
| In a biography book, Section A discusses the life of {random_person}, Section B discusses the life of {random_person}, and Section C discusses the life of {target_person}. The field of the person in Section C is? | The person in Section C works in the field of {target_field}. | |
| {target_person} speaks the language of {target_language}. | The following facts are known: 1. {target_person} wears red clothes. 2. {random_person} wears blue clothes. 3. {random_person} wears green clothes. The language that the person in red clothes speaks is? | The language that the person in red clothes speaks is {target_language}. |
| At a global company: {target_language}-speaking employees work in Team A. {random_language}-speaking employees work in Team B. In which team would {target_person} work when he/she is at work? | {target_person} would work in Team A when he/she is at work. |
🔼 This table presents example templates used to generate training data for the CaKE model. Each template creates a multi-hop question designed to test the model’s ability to integrate updated knowledge within its reasoning circuits. The examples show how factual statements are embedded within a context that forces the model to utilize the newly learned knowledge at different steps of the reasoning process, rather than relying on simple pattern matching or memorization.
read the caption
Table 7: Sample templates for generating the circuit-aware data.
| Edit Method | LLAMA3-8B | Qwen2.5-7B | ||
| First_hop | Second_hop | First_hop | Second_hop | |
| ROME | 16.66 | 7.81 | 10.57 | 8.33 |
| WISE | 49.85 | 67.36 | 8.33 | 33.59 |
🔼 This table presents a comparison of the performance of different knowledge editing methods. The comparison is made across various positions where the edited fact is placed within the input context (First-hop, Second-hop). The performance metric used is likely accuracy or some other relevant measure of the model’s ability to incorporate the new information correctly. This analysis helps to understand how the placement of an edited fact impacts the effectiveness of different knowledge editing techniques in a multi-hop reasoning task.
read the caption
Table 8: Performance comparison of edit methods across different positions for the edited fact.
Full paper#