TL;DR#
Action-based decision-making using Visual Language Action (VLA) models has gained attention. Previous approaches, focusing on action post-training, often missed foundation model enhancements. To tackle this, the authors present Act from Visual Language Post-Training, which refines Vision Language Models (VLMs) through visual and linguistic self-supervision, boosting world knowledge, visual recognition, and spatial grounding.
The new training paradigms led to the first VLA models in Minecraft capable of following human instructions across 1k atomic tasks like crafting, smelting, and killing. Experiments show a 40% improvement over existing agents and state-of-the-art performance surpassing imitation learning. The team open-sourced JARVIS-VLA’s code, models, and datasets to facilitate future research and development.
Key Takeaways#
Why does it matter?#
This research significantly advances VLA models for interactive environments like Minecraft. By enhancing pre-training and open-sourcing resources, it promotes further research in AI agents capable of complex tasks and better human-AI collaboration. It helps build AI that is more aligned with how people naturally learn and interact.
Visual Insights#

🔼 Figure 1 illustrates the JARVIS-VLA model architecture and training process. JARVIS-VLA is a novel Vision-Language-Action (VLA) model that leverages a multi-stage training approach called ActVLP. This approach first involves post-training the model on non-decision making visual-language tasks to enhance its world knowledge, visual recognition, and spatial understanding. Only after this initial post-training phase, does the model undergo training on trajectory datasets (data showing sequences of actions) to improve its decision-making capabilities. This two-stage process is shown schematically in the figure, highlighting the key components of the model (Visual Transformer, Causal Transformer, Action Decoder) and their interaction with the environment.
read the caption
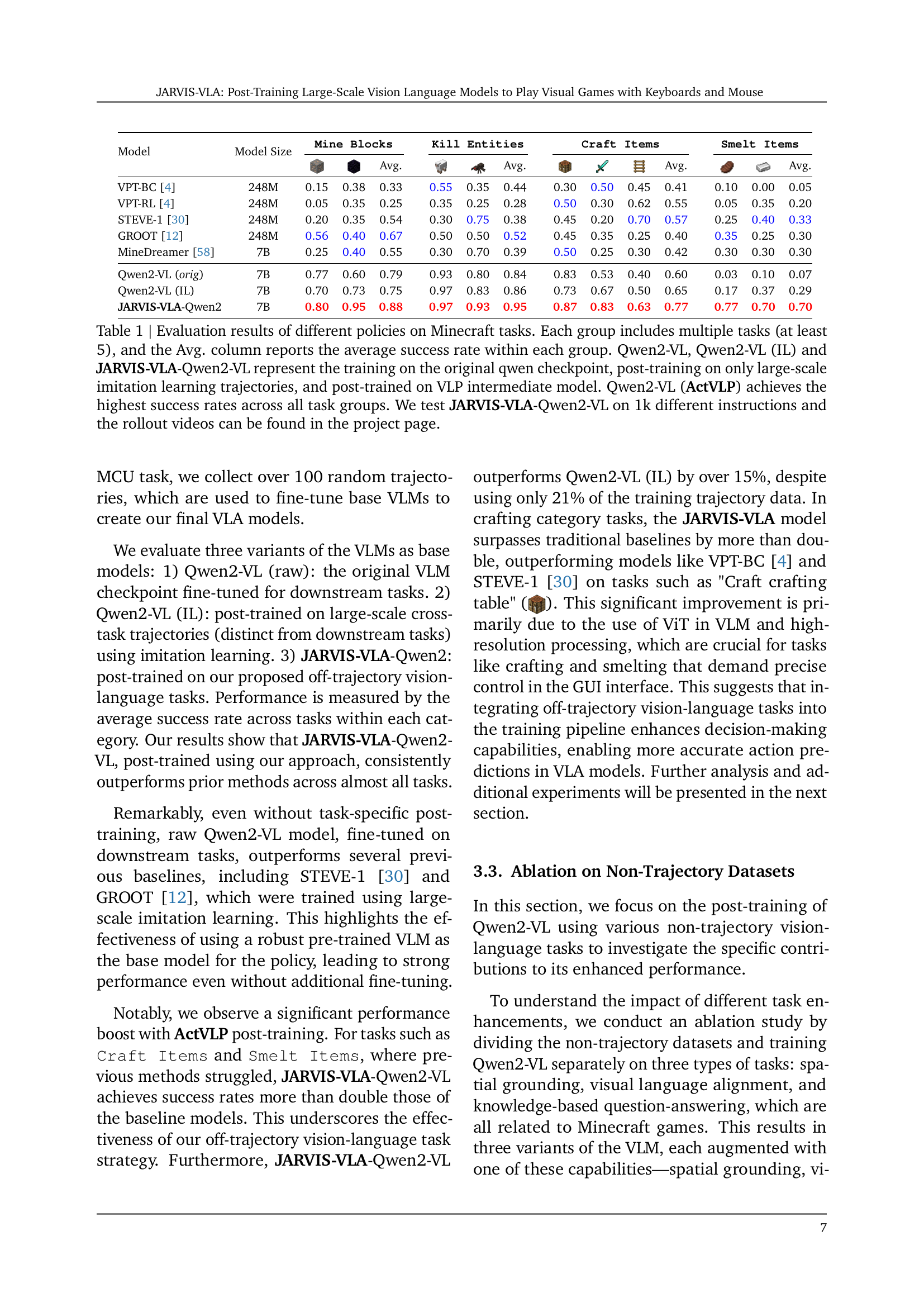
Figure 1: We present JARVIS-VLA, a novel Vision-Language-Action (VLA) model trained with ActVLP paradigm, post-trained on vision language tasks (non-decision-making tasks) before training on trajectory datasets to have better decision-making capabilities.
| Model | Model Size | Mine Blocks | Kill Entities | Craft Items | Smelt Items | ||||||||||||
| Avg. | Avg. | Avg. | Avg. | ||||||||||||||
| VPT-BC [4] | 248M | 0.15 | 0.38 | 0.33 | 0.55 | 0.35 | 0.44 | 0.30 | 0.50 | 0.45 | 0.41 | 0.10 | 0.00 | 0.05 | |||
| VPT-RL [4] | 248M | 0.05 | 0.35 | 0.25 | 0.35 | 0.25 | 0.28 | 0.50 | 0.30 | 0.62 | 0.55 | 0.05 | 0.35 | 0.20 | |||
| STEVE-1 [30] | 248M | 0.20 | 0.35 | 0.54 | 0.30 | 0.75 | 0.38 | 0.45 | 0.20 | 0.70 | 0.57 | 0.25 | 0.40 | 0.33 | |||
| GROOT [12] | 248M | 0.56 | 0.40 | 0.67 | 0.50 | 0.50 | 0.52 | 0.45 | 0.35 | 0.25 | 0.40 | 0.35 | 0.25 | 0.30 | |||
| MineDreamer [58] | 7B | 0.25 | 0.40 | 0.55 | 0.30 | 0.70 | 0.39 | 0.50 | 0.25 | 0.30 | 0.42 | 0.30 | 0.30 | 0.30 | |||
| Qwen2-VL (orig) | 7B | 0.77 | 0.60 | 0.79 | 0.93 | 0.80 | 0.84 | 0.83 | 0.53 | 0.40 | 0.60 | 0.03 | 0.10 | 0.07 | |||
| Qwen2-VL (IL) | 7B | 0.70 | 0.73 | 0.75 | 0.97 | 0.83 | 0.86 | 0.73 | 0.67 | 0.50 | 0.65 | 0.17 | 0.37 | 0.29 | |||
| JARVIS-VLA-Qwen2 | 7B | 0.80 | 0.95 | 0.88 | 0.97 | 0.93 | 0.95 | 0.87 | 0.83 | 0.63 | 0.77 | 0.77 | 0.70 | 0.70 | |||
🔼 This table presents a comparison of the success rates of various models on different Minecraft tasks. The tasks are grouped into four categories: Mine Blocks, Kill Entities, Craft Items, and Smelt Items. Each category contains multiple sub-tasks (at least 5). The ‘Avg.’ column shows the average success rate across all tasks within each category. The models compared are: VPT-BC, VPT-RL, STEVE-1, GROOT, MineDreamer, Qwen2-VL (original), Qwen2-VL (trained with imitation learning only), and JARVIS-VLA (trained with the ActVLP method). The table highlights that JARVIS-VLA significantly outperforms other models across all task categories, achieving the highest average success rates. The model sizes are provided for reference. JARVIS-VLA was tested on 1000 different tasks, and videos demonstrating its performance are available on the project page.
read the caption
Table 1: Evaluation results of different policies on Minecraft tasks. Each group includes multiple tasks (at least 5), and the Avg. column reports the average success rate within each group. Qwen2-VL, Qwen2-VL (IL) and JARVIS-VLA-Qwen2-VL represent the training on the original qwen checkpoint, post-training on only large-scale imitation learning trajectories, and post-trained on VLP intermediate model. Qwen2-VL (ActVLP) achieves the highest success rates across all task groups. We test JARVIS-VLA-Qwen2-VL on 1k different instructions and the rollout videos can be found in the project page.
In-depth insights#
ActVLP Paradigm#
The ActVLP paradigm, or “Act from Visual Language Post-Training,” signifies a novel approach in refining VLMs for decision-making. It prioritizes enhancing the foundational model’s understanding of world knowledge, visual recognition, and spatial grounding before task-specific training. This contrasts with traditional methods that focus on action post-training. By incorporating visual and linguistic guidance in a self-supervised manner, ActVLP aims to improve the VLM’s ability to interpret open-world environments. The core idea is that a more informed and capable VLM will lead to better action generation and decision-making, ultimately surpassing the limitations of imitation learning. ActVLP uses non-trajectory tasks.
Minecraft VLA#
Minecraft VLA could be a specialized area within Visual Language Action models, tailored for the Minecraft environment. It likely involves agents that can understand visual and textual instructions to perform tasks in the game, requiring strong spatial reasoning, object recognition, and planning abilities. Such models might use techniques like imitation learning from human gameplay or reinforcement learning to optimize actions. A key challenge would be the vast action space and partially observable environment, requiring robust handling of uncertainty and long-term dependencies. Datasets for Minecraft VLA could include gameplay videos with human annotations and synthesized data. The performance of these models could be evaluated based on their ability to follow instructions, complete complex tasks, and generalize to new scenarios within the Minecraft world.
Vision grounding#
Vision grounding is a crucial aspect of AI, enabling models to link visual inputs to semantic concepts. In the context of visual games, it allows agents to ‘understand’ what they see – identifying objects, locations, and relationships. This is vital for tasks like navigation, object manipulation, and following instructions. Effective vision grounding requires models to overcome challenges such as variations in viewpoint, lighting, and object appearance. Techniques like attention mechanisms and spatial reasoning are often employed. Improving vision grounding leads to more robust and capable agents in visually rich environments. It is important to use various techniques such as object localization, relation extraction and scene understanding to achieve better results in vision grounding.
Token efficiency#
Token efficiency is a critical aspect often overlooked in large language models (LLMs). A more efficient tokenization strategy can lead to reduced computational costs during training and inference, as fewer tokens translate to shorter sequences that the model needs to process. Efficient tokenization can allow LLMs to process more data within a given memory constraint, potentially improving overall performance and enabling the use of longer context windows. Strategic token selection, repurposing infrequently used tokens for specific tasks like action representation (as seen in this work), can significantly enhance a model’s ability to handle diverse tasks without substantially increasing vocabulary size. Additionally, token chunking is a good way to effectively use the token. Ultimately, optimizing token efficiency represents a vital step towards creating more powerful and sustainable LLMs.
Scaling Laws#
Scaling laws in VLMs is the trend where performance improves with model size, data, and compute. ActVLP reveals VLAs benefit from scaling, particularly with non-trajectory data, enhancing downstream task success. Datasets and tuning impacts performance. Larger datasets and loss reduction from knowledge tasks aids scaling, improving decision-making. Task difficulty is affected by dataset size. A non-zero rate will be there when losses are less than 0.3. Scaling laws in vision language models, obtained through post-training on VLMs, exhibit similar scaling behavior.
More visual insights#
More on figures

🔼 This figure illustrates the difference between traditional VLA training methods and the proposed ActVLP approach. Traditional methods directly fine-tune a vision-language model on large-scale datasets using imitation learning to predict actions. In contrast, ActVLP is a three-stage training pipeline. Stage 1 post-trains the language model on text-based world knowledge using supervised fine-tuning with next-token prediction. Stage 2 further post-trains both the vision encoder and language model on multimodal datasets focusing on vision-language alignment and spatial grounding, again using supervised fine-tuning with next-token prediction. Finally, Stage 3 post-trains only the language model on multimodal instruction-following datasets via imitation learning. This multi-stage approach aims to enhance the model’s world knowledge, visual understanding, and spatial reasoning capabilities before relying solely on imitation learning for action prediction.
read the caption
Figure 2: Previous VLA methods usually directly use imitation learning to finetune original vision-language models on large-scale multi-domain decision-making datasets to predict the actions [25, 7]. Our ActVLP training pipeline includes three stages: 1) post-training language models on text-only world knowledge with next-token prediction supervised fine-tuning, 2) post-training both vision encoder and language models on multimodal vision-language alignment and spatial grounding datasets with next-token prediction supervised fine-tuning, and 3) post-training only language models on multi-modal instruction following datasets with imitation learning.

🔼 Figure 3 illustrates the diverse visual-language datasets used for post-training the model. A unified tokenizer allows the model to leverage these datasets, improving its performance on various vision-language tasks including question answering, image captioning, image/video question answering, and visual grounding (which incorporates both point and bounding box annotations). This multifaceted approach enhances the model’s decision-making capabilities.
read the caption
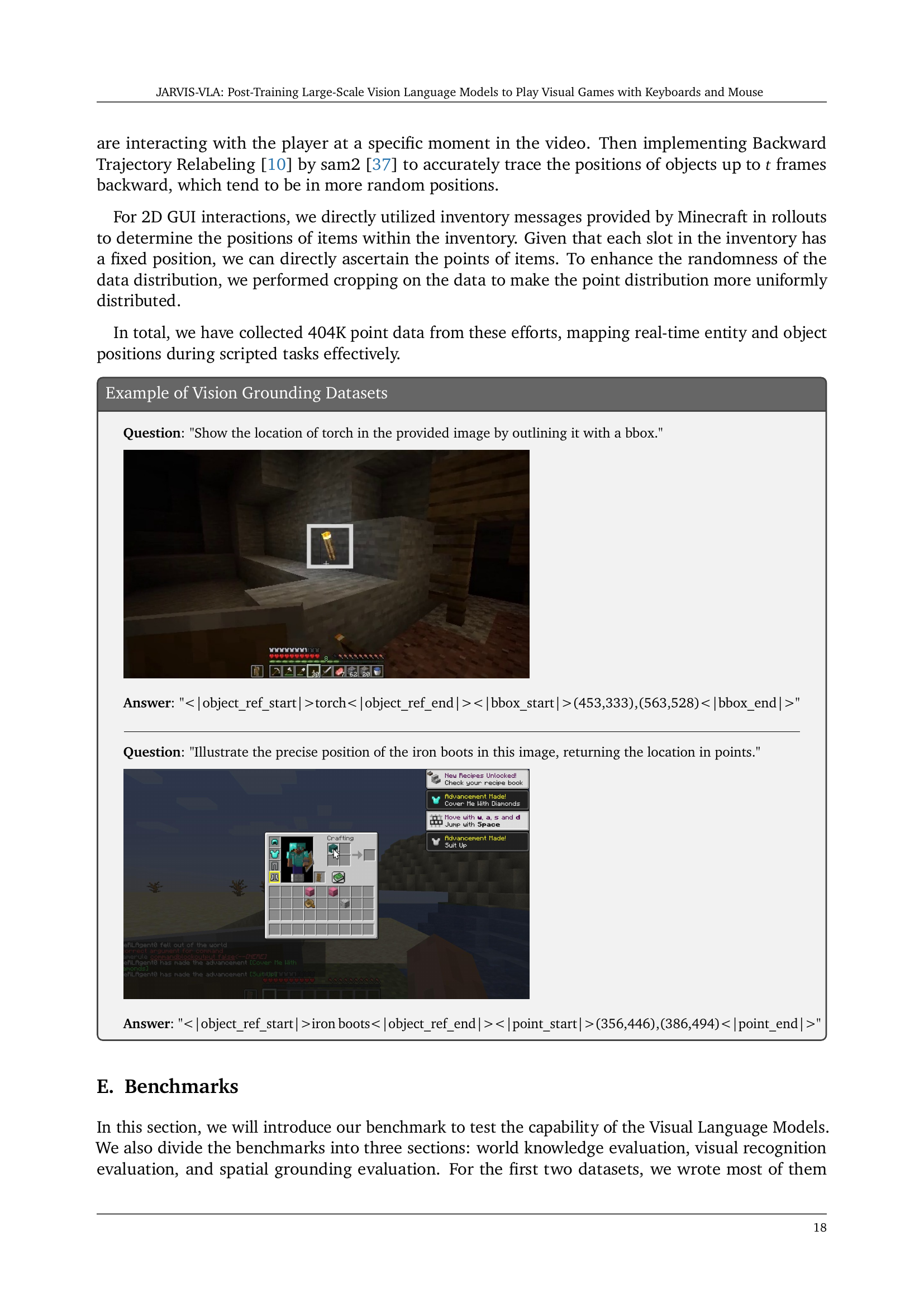
Figure 3: Illustration of various post-training datasets. Models can post-train on various vision-language datasets using a unified tokenizer and support diverse vision-language applications, such as question answering, image captioning, image/video question answering, visual grounding (including points and bounding box), and decision-making. More examples can be found in Appendix D.

🔼 This figure displays the results of ablation studies conducted to determine the impact of different post-training datasets on downstream decision-making tasks. Three types of datasets were used: knowledge datasets, visual question-answering datasets, and spatial grounding datasets. The results show the success rates for three downstream tasks (crafting a sword, mining obsidian, and cooking beef) when different combinations of post-training datasets were used. This illustrates which visual-language capabilities are most crucial for effective task performance, highlighting the importance of a well-rounded, multi-faceted post-training process.
read the caption
Figure 4: Ablation results on different post-training datasets. We select knowledge datasets, visual question-answering datasets, and spatial grounding datasets to conduct ablation experiments. Our goal is to evaluate which capabilities and post-training datasets most significantly influence downstream decision-making tasks.

🔼 Figure 5 illustrates the relationship between the success rate of downstream tasks, the training loss, and the number of training steps in a model. The graph shows that increasing the number of downstream fine-tuning trajectories improves the model’s success rate, but only when the training loss is below 0.22. This indicates a threshold where additional data significantly impacts performance.
read the caption
Figure 5: The relation between downstream task success rate, training loss, and training steps. The curve shows that scaling downstream finetuning trajectories can scale up the success rate when the loss is lower than 0.22.

🔼 This figure illustrates the correlation between the loss during post-training on non-trajectory datasets and the success rate on downstream tasks. It demonstrates that increasing the size of the non-trajectory training data improves the performance on downstream tasks, even when the amount of fine-tuning trajectory data remains constant. This highlights the importance of comprehensive pre-training in enhancing the model’s ability to generalize to new tasks.
read the caption
Figure 6: The relationship between post-training loss and downstream task success rates. Our findings indicate that increasing the size of post-training non-trajectory datasets can significantly enhance downstream task success rates, even with a fixed number of fine-tuning trajectories.
More on tables
| Category | Quantity | Example Question | Example Answer |
| Craft | 9 | What materials are needed to craft a jukebox in Minecraft? | 8 Planks and 1 Diamond. |
| Plant | 5 | What is the maximum height sugarcane can reach in Minecraft? | 3. |
| Mobs | 12 | What happens when a creeper gets struck by lightning in Minecraft? | A creeper becomes a charged creeper. |
| Kill | 3 | Can shield block crossbow attack in Minecraft? | No. |
| Enchant | 3 | What happens if the player put on an item with Curse of Binding enchant in Minecraft? | It cannot be removed until the item breaks or the player dies. |
| Potion | 4 | What materials are needed to craft a potion of poison in Minecraft? | Water bottle, Nether wart, blaze powder, spider eye. |
| Biomes | 4 | Which biome is the only place you can find blue orchids in Minecraft? | Swamp. |
| Architecture | 7 | How many chests are typically found in a shipwreck in Minecraft? | 1 to 3. |
🔼 This table details the evaluation dataset for the World Knowledge portion of the Minecraft benchmark. It breaks down 47 questions into eight subcategories (Craft, Plant, Mobs, Kill, Enchant, Potions, Biomes, Architecture), showing the number of questions per category and example questions and answers. This provides a detailed look at the types of knowledge questions used to assess the models’ understanding of the Minecraft world.
read the caption
Table 2: Summary of Minecraft knowledge questions and answers Evaluation.
| Category | Quantity | Image | Example Question | Example Answer |
| Scene | 11 | ![[Uncaptioned image]](x11.png) | What biome you think is the player currently in? | Mushroom Fields biome. |
| Object | 13 | Are there any hostile mobs in the picture? | No, there are only 4 pigs in the picture. | |
| Info | 7 | ![[Uncaptioned image]](x13.png) | Is the player’s hunger bar currently full? | No. |
| Inventory | 6 | Is there any oak wood in the inventory? | Yes, there are oak wood planks in the inventory. | |
| OCR | 6 | What instructions are visible on the screen? | Open your inventory Press e. |
🔼 This table details the evaluation metrics for the Vision Understanding portion of the Minecraft benchmark. It breaks down the evaluation into five subcategories: Scene, Object, Info, Inventory, and OCR. Each category contains several questions related to aspects of the Minecraft game environment and the player’s status. The table lists the number of questions per category, provides example questions and answers, and includes an image to illustrate the visual information used in each question.
read the caption
Table 3: Summary of Vision Understanding Evaluation.
| Category | Quantity | Image | Example Question | Example Answer |
| GUI | 100 | Point the wheat_seeds | [284,206] | |
| Embodied | 236 | Point the oak_leaves. | [315,174] |
🔼 Table 4 presents a summary of the evaluation results for spatial grounding tasks in the paper. It shows the number of GUI (Graphical User Interface) and Embodied data points used for evaluation, provides example questions, and displays the format of the expected answers. The results are crucial for assessing the model’s ability to accurately locate objects within Minecraft scenes, differentiating between GUI elements and objects within the 3D game environment.
read the caption
Table 4: Summary of spatial grounding evaluation results for visual grounding tasks.
| Model | Model Size | World Knowledge | Visual Understanding | Visual Grounding | |||
| Acc | Rank | Acc | Rank | Acc | Rank | ||
| GPT-4o [1] | - | 96.6 | 1 | 76.7 | 1 | - | - |
| GPT-4o-mini [1] | - | 75.9 | 2 | 62.8 | 4 | - | - |
| Llava-Next [27] | 8B | 19.0 | 8 | 41.9 | 10 | - | - |
| Molmo-d-0924 [16] | 7B | 12.1 | 10 | 58.1 | 5 | 24.8 | 3 |
| Llama-3.2 [33] | 11B | 20.7 | 7 | 44.2 | 9 | - | - |
| Qwen2-VL [43] | 7B | 17.3 | 9 | 46.5 | 7 | 16.6 | 5 |
| Qwen2-VL (Knowledge) | 7B | 65.5 | 5 | 46.5 | 7 | 16.6 | 5 |
| Qwen2-VL (Vision) | 7B | 62.1 | 6 | 65.1 | 3 | 19.8 | 4 |
| Qwen2-VL (Grounding) | 7B | 67.2 | 4 | 51.2 | 6 | 63.6 | 2 |
| JARVIS-VLA-Qwen2-VL | 7B | 70.7 | 3 | 76.7 | 1 | 88.0 | 1 |
🔼 This table compares the performance of various Vision-Language Models (VLMs) on a benchmark designed to evaluate their knowledge of Minecraft, visual understanding, and spatial reasoning abilities. The models compared include both commercially available large language models (like GPT-4 and its smaller variant) and open-source models (such as Llava-Next, Molmo-d-0924, Llama-3.2, and Qwen2-VL). The table shows each model’s accuracy and ranking across these three categories. The key finding is that the JARVIS-VLA model, the authors’ approach, significantly improves the core capabilities of the other models, though a performance gap still exists relative to state-of-the-art models.
read the caption
Table 5: We compared the performance of various VLMs using our benchmark, including commercial large models (GPT-4 and GPT-4-mini [35]), open-source models (Llava-Next [27], Molmo-d-0924 [16], Llama-3.2 [33], and Qwen2-VL [43]), as well as JARVIS-VLA. The results demonstrate that our method significantly enhances the core capabilities of these models, although there remains a gap when compared to state-of-the-art models.
| Methods | Models | World Knowledge | Visual Alignment | Spatial Grounding | ||
| Raw | Llava-Next-8B | 18.9 | 41.8 | - | 26.7 | 10.0 |
| ActVLP | Llava-Next-8B | 55.8 | 60.3 | - | 53.3 | 16.6 |
| Raw | Qwen2-VL-7B | 17.3 | 46.5 | 16.6 | 83.3 | 0.0 |
| ActVLP | Qwen2-VL-7B | 70.7 | 76.7 | 88.0 | 86.7 | 83.3 |
🔼 This table presents the ablation study results, demonstrating the robustness of ActVLP across different vision-language models. ActVLP, the proposed Visual Language Post-Training method, is applied to two distinct base models: Llava-Next-8B and Qwen2-VL-7B. The table compares their performance on world knowledge, visual alignment, and spatial grounding tasks before and after applying ActVLP. It showcases the performance improvements achieved by ActVLP and indicates its effectiveness regardless of the underlying base model.
read the caption
Table 6: Ablation experiments on base model and model structure. We adopt ActVLP on Llava-Next-8B [27] and Qwen2-VL-7B [43] to validate the robustness across different base vision language models.
Full paper#