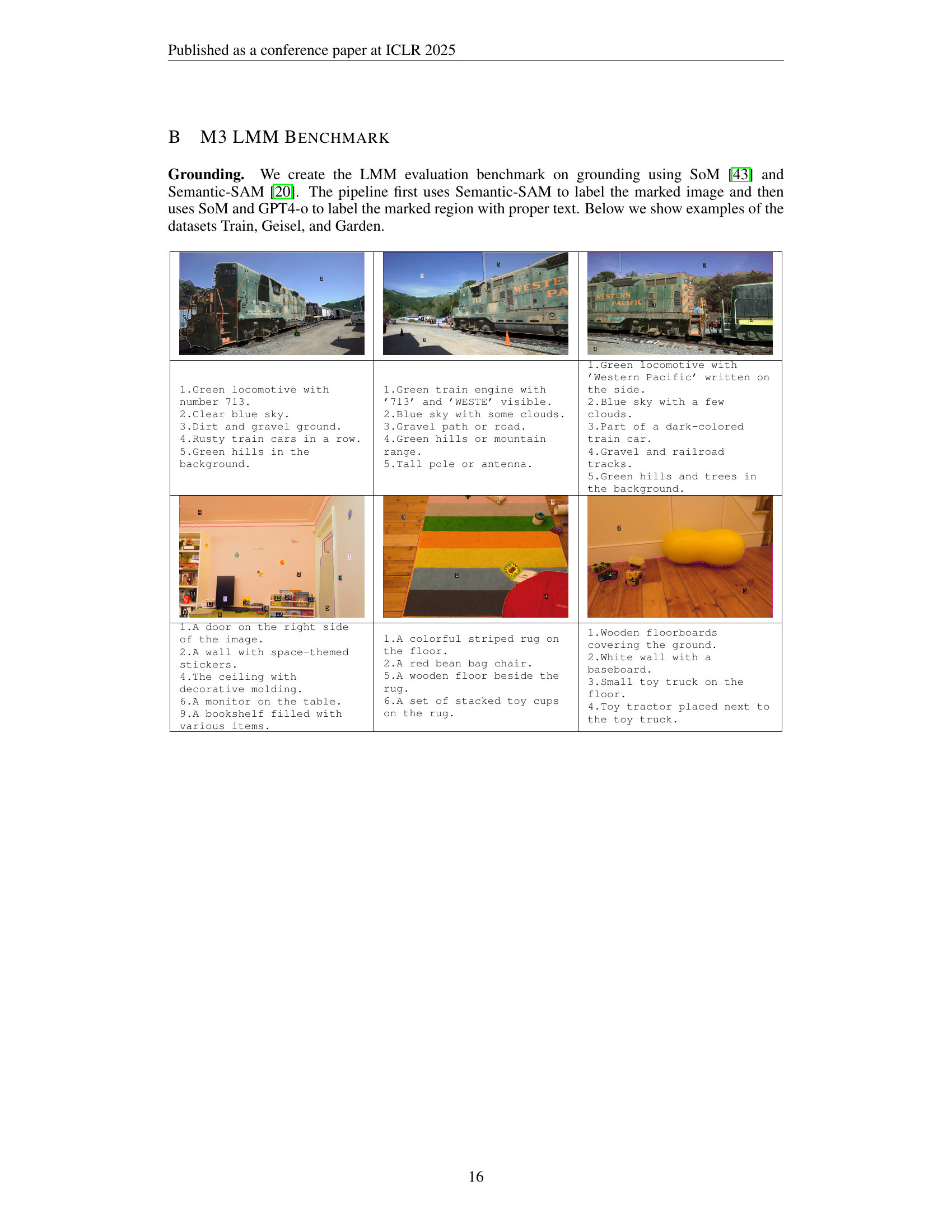
TL;DR#
Existing feature splatting methods often face computational constraints when storing high-dimensional features for each Gaussian primitive. They also suffer from misalignment between distilled and original features, leading to information loss. The paper introduces a system to retain information about medium-sized static scenes through video sources for visual perception.
The proposed system, MultiModal Memory (M3), addresses these challenges by integrating 3D Gaussian Splatting with foundation models. It stores high-dimensional 2D feature maps in a memory bank and uses low-dimensional queries from 3D Gaussians as indices. M3 uses Gaussian memory attention between principal scene components and queries to render foundation model embeddings in a 3D scene, enabling efficient training and inference.
Key Takeaways#
Why does it matter?#
This paper introduces a novel memory system that can handle complex multimodal information for 3D scene understanding, addressing key limitations in feature distillation. It advances research in areas like robotic perception, spatial AI, and multimodal learning by enabling robots to interact in the real world.
Visual Insights#

🔼 This figure illustrates the architecture of the proposed MultiModal Memory (M3) system. M3 combines 3D Gaussian splatting with various foundation models (like CLIP, LLaMA, DINO, etc.) to create a memory system that efficiently stores and retrieves multimodal information about a scene. The Gaussian splatting technique provides an effective way to represent the spatial structure of the scene, while the foundation models contribute rich semantic understanding. The figure shows how these components work together to generate high-fidelity feature maps that maintain the expressiveness of the foundation models, enabling tasks such as rendering, retrieval, and captioning.
read the caption
Figure 1: Our proposed MultiModal Memory integrates Gaussian splatting with foundation models to efficiently store multimodal memory in a Gaussian structure. The feature maps rendered by our approach exhibit high fidelity, preserving the strong expressive capabilities of the foundation models.
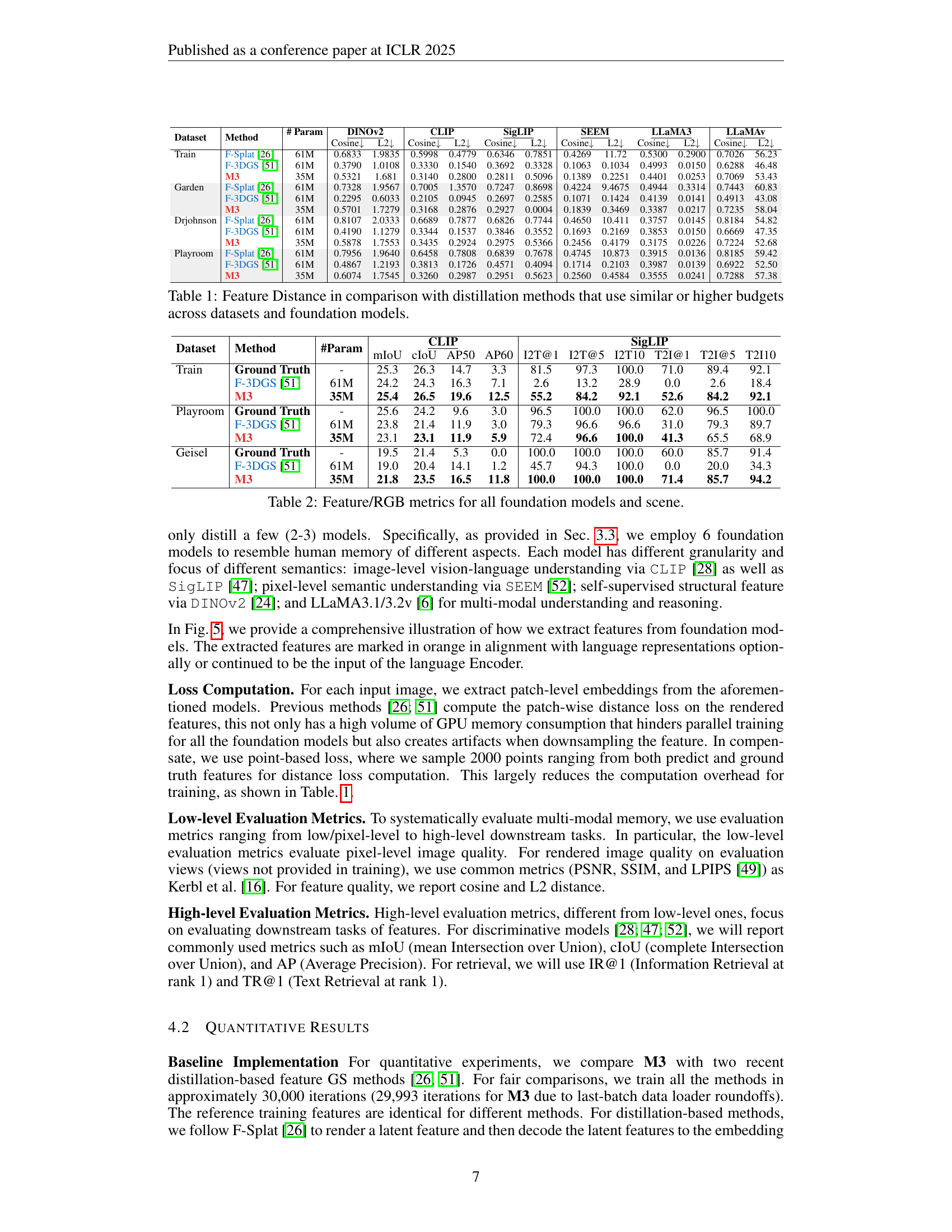
| # Param | \ulDINOv2 | \ulCLIP | \ulSigLIP | \ulSEEM | \ulLLaMA3 | \ulLLaMAv | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Method | Cosine | L2 | Cosine | L2 | Cosine | L2 | Cosine | L2 | Cosine | L2 | Cosine | L2 | |
| Train | F-Splat [26] | 61M | 0.6833 | 1.9835 | 0.5998 | 0.4779 | 0.6346 | 0.7851 | 0.4269 | 11.72 | 0.5300 | 0.2900 | 0.7026 | 56.23 |
| F-3DGS [51] | 61M | 0.3790 | 1.0108 | 0.3330 | 0.1540 | 0.3692 | 0.3328 | 0.1063 | 0.1034 | 0.4993 | 0.0150 | 0.6288 | 46.48 | |
| M3 | 35M | 0.5321 | 1.681 | 0.3140 | 0.2800 | 0.2811 | 0.5096 | 0.1389 | 0.2251 | 0.4401 | 0.0253 | 0.7069 | 53.43 | |
| Garden | F-Splat [26] | 61M | 0.7328 | 1.9567 | 0.7005 | 1.3570 | 0.7247 | 0.8698 | 0.4224 | 9.4675 | 0.4944 | 0.3314 | 0.7443 | 60.83 |
| F-3DGS [51] | 61M | 0.2295 | 0.6033 | 0.2105 | 0.0945 | 0.2697 | 0.2585 | 0.1071 | 0.1424 | 0.4139 | 0.0141 | 0.4913 | 43.08 | |
| M3 | 35M | 0.5701 | 1.7279 | 0.3168 | 0.2876 | 0.2927 | 0.0004 | 0.1839 | 0.3469 | 0.3387 | 0.0217 | 0.7235 | 58.04 | |
| Drjohnson | F-Splat [26] | 61M | 0.8107 | 2.0333 | 0.6689 | 0.7877 | 0.6826 | 0.7744 | 0.4650 | 10.411 | 0.3757 | 0.0145 | 0.8184 | 54.82 |
| F-3DGS [51] | 61M | 0.4190 | 1.1279 | 0.3344 | 0.1537 | 0.3846 | 0.3552 | 0.1693 | 0.2169 | 0.3853 | 0.0150 | 0.6669 | 47.35 | |
| M3 | 35M | 0.5878 | 1.7553 | 0.3435 | 0.2924 | 0.2975 | 0.5366 | 0.2456 | 0.4179 | 0.3175 | 0.0226 | 0.7224 | 52.68 | |
| Playroom | F-Splat [26] | 61M | 0.7956 | 1.9640 | 0.6458 | 0.7808 | 0.6839 | 0.7678 | 0.4745 | 10.873 | 0.3915 | 0.0136 | 0.8185 | 59.42 |
| F-3DGS [51] | 61M | 0.4867 | 1.2193 | 0.3813 | 0.1726 | 0.4571 | 0.4094 | 0.1714 | 0.2103 | 0.3987 | 0.0139 | 0.6922 | 52.50 | |
| M3 | 35M | 0.6074 | 1.7545 | 0.3260 | 0.2987 | 0.2951 | 0.5623 | 0.2560 | 0.4584 | 0.3555 | 0.0241 | 0.7288 | 57.38 | |
🔼 This table presents a quantitative comparison of feature distances achieved by M3 against two other distillation methods (F-Splat and F-3DGS). The comparison is done across multiple datasets (Train, Garden, Drjohnson, Playroom) and foundation models (DINOV2, CLIP, SigLIP, SEEM, LLaMA3, LLaMAv). The metrics used are cosine similarity and L2 distance, reflecting the similarity and difference between the features generated by each method. Lower values in both cosine similarity and L2 distance are better, indicating that the generated features are closer to the ground truth. The table highlights M3’s efficiency by achieving comparable or superior results with a significantly smaller parameter budget.
read the caption
Table 1: Feature Distance in comparison with distillation methods that use similar or higher budgets across datasets and foundation models.
In-depth insights#
3DGS Multimodal#
The intersection of 3D Gaussian Splatting (3DGS) and multimodal learning presents exciting possibilities for scene representation and understanding. 3DGS excels at photorealistic rendering and efficient storage of 3D scenes, but lacks inherent semantic understanding. Multimodal learning, on the other hand, leverages diverse data sources (e.g., text, audio, depth) to enrich scene representations with semantic information. Combining these techniques can lead to systems that not only render scenes beautifully but also understand their content, relationships, and context. Challenges include aligning features from different modalities to the Gaussian primitives, developing effective fusion strategies, and managing the increased computational complexity. Success in this area promises enhanced applications in robotics, augmented reality, and scene editing, allowing machines to interact with and manipulate virtual environments more intelligently.
Memory Attention#
The ‘Memory Attention’ mechanism seems crucial for efficiently retrieving and utilizing stored knowledge. It likely involves weighting different memory components based on their relevance to a given query or context. A successful implementation would require addressing challenges like scalability (handling large memory sizes), content addressing (retrieving relevant information quickly), and robustness (dealing with noisy or incomplete queries). The attention mechanism could be implemented using various techniques, like dot-product attention, or learned attention weights. The design should also consider how to update the memory and prevent catastrophic forgetting. Analyzing the integration of this component alongside other modalities such as gaussian splatting could uncover insights in multi-modal integration which can have far reaching consequences in AI.
Feature Fidelity#
Feature Fidelity appears to be a central concern in the study, particularly when integrating foundation models with Gaussian Splatting. The paper emphasizes the importance of preserving the expressive capabilities of foundation models during the distillation process. A key challenge is avoiding information bottlenecks when reducing feature vector dimensions, ensuring the distilled features accurately capture the knowledge embedded in the original model. The research addresses potential misalignment between distilled and original features, highlighting the need for methods like Gaussian memory attention to maintain fidelity. Evaluations focus on feature similarity and downstream task performance, demonstrating the system’s ability to retain critical information while optimizing efficiency. Preserving feature fidelity enables rich semantic understanding and supports various tasks.
Robotic M3 Apps#
While the paper doesn’t explicitly detail “Robotic M3 Apps,” we can infer its potential significance. It suggests leveraging the M3 (Multimodal Memory) system in robotic applications. This implies robots equipped with M3 could benefit from enhanced environmental understanding, improved navigation, and superior object manipulation capabilities. By integrating visual, language, and spatial information, robots could perform complex tasks, such as fetching specific items or navigating cluttered environments, with greater precision and efficiency. The M3’s ability to compress and retain scene knowledge would enable long-term autonomy and adaptive behavior in dynamic real-world settings, marking a substantial leap in robotic intelligence.
LLM Integration#
Integrating Large Language Models (LLMs) into 3D spatial memory systems offers a transformative approach to scene understanding and interaction. By endowing the system with LLMs’ reasoning and knowledge capabilities, we move beyond mere spatial reconstruction to achieve semantically rich scene representations. LLMs can provide contextual awareness, enabling the system to interpret objects and their relationships within the environment. This enhances the ability to perform complex tasks like scene captioning, object retrieval, and grounding. Furthermore, LLMs can facilitate interactive queries, allowing users to engage with the scene in a more intuitive way. The challenge lies in efficiently encoding and retrieving visual information in a format compatible with LLMs. Addressing this challenge could unlock new possibilities for robotics, augmented reality, and other applications that require a deep understanding of the environment.
More visual insights#
More on figures
🔼 The figure illustrates the architecture of M3, a 3D Spatial Multimodal Memory system. It shows how the system combines multiple foundation models (e.g., CLIP, LLaMA, DINO) to extract multi-granular semantic knowledge from a scene represented as a video (V). This knowledge, along with the scene’s spatial structure captured using 3D Gaussian splatting, is integrated into a unified multimodal memory representation. This memory allows for various downstream tasks, including image retrieval, caption generation, and object grounding. The figure visually depicts the process, showing how foundation models process the scene’s input video to generate features and how Gaussian splatting structures this information for efficient storage and retrieval.
read the caption
Figure 2: A scene (𝐕𝐕\mathbf{V}bold_V) is composed of both structure (𝐒𝐒\mathbf{S}bold_S) and knowledge (𝐈𝐈\mathbf{I}bold_I). To model these, we leverage multiple foundation models to extract multi-granularity scene knowledge, and employ 3D Gaussian splatting to represent the spatial structure. By combining these techniques, we construct a spatial multimodal memory (M3), which enables downstream applications such as retrieval, captioning and grounding.

🔼 Figure 3 illustrates the MultiModal Memory (M3) pipeline. A video sequence is input, and foundation models extract raw features. These high-dimensional features are then reduced using Algorithm 1 to create principal scene components (PSCs), which are stored in a memory bank. Optimizable attribute queries are applied to Gaussian primitives, and a Gaussian Memory Attention mechanism generates final rendered features. These rendered features retain the semantic information from the foundation models and are used for downstream tasks via connections to various model heads.
read the caption
Figure 3: Given a video sequence, we utilize foundation models (𝐅𝐅\mathbf{F}bold_F) to extract raw features (𝐑𝐑\mathbf{R}bold_R). These features are reduced using Algorithm 1, producing principal scene components (𝐏𝐒𝐂𝐏𝐒𝐂\mathbf{PSC}bold_PSC), which are stored in a memory bank. We introduce optimizable attribute queries (q𝑞qitalic_q) to Gaussian primitives, and apply a Gaussian Memory Attention (𝐀gmsubscript𝐀𝑔𝑚\mathbf{A}_{gm}bold_A start_POSTSUBSCRIPT italic_g italic_m end_POSTSUBSCRIPT) mechanism to produce the final rendered features (𝐑^^𝐑\hat{\mathbf{R}}over^ start_ARG bold_R end_ARG), which can be linked back to various heads of the foundation models.

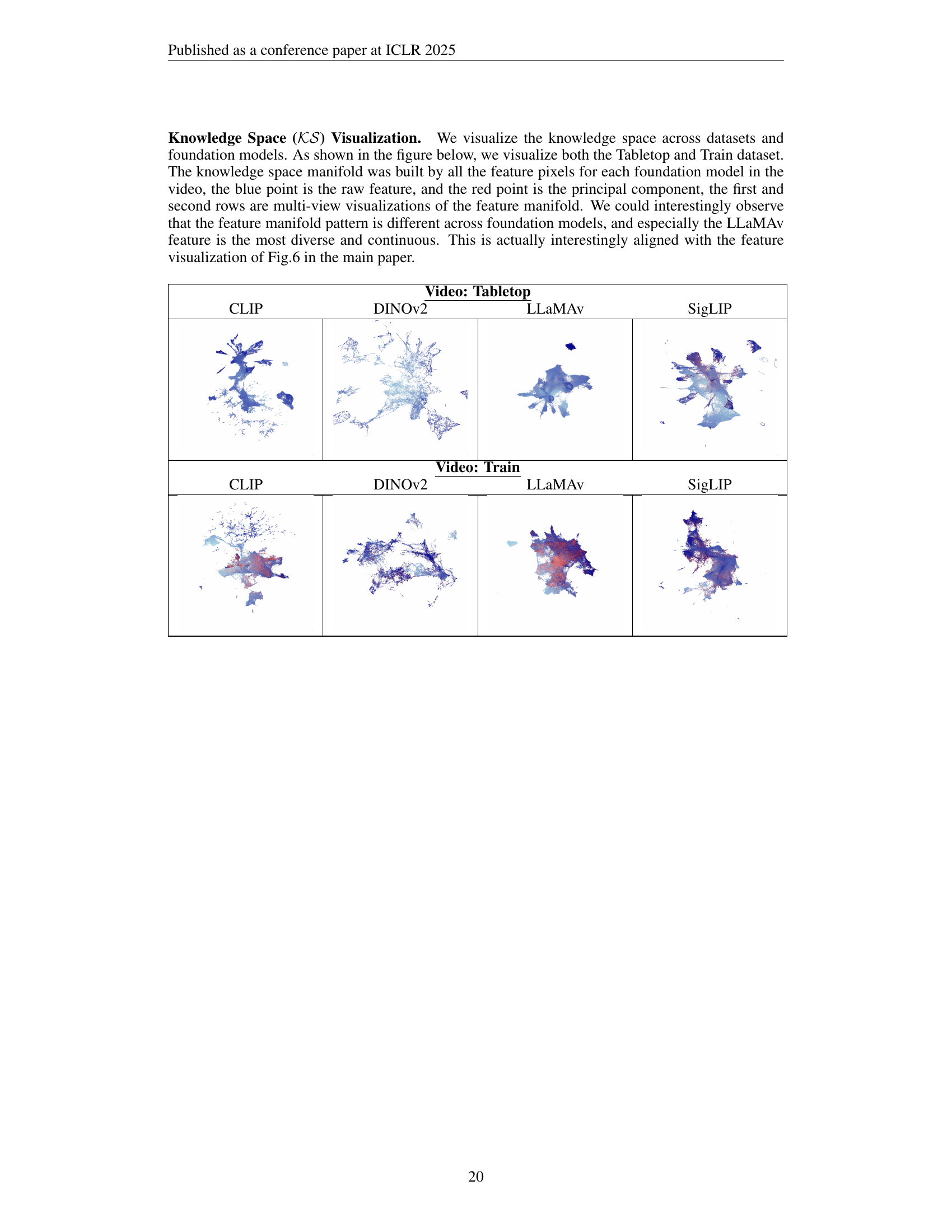
🔼 This UMAP visualization shows the embedding manifolds for different foundation models used in the paper. Each model’s embeddings form a distinct cluster shape, illustrating how each model focuses on different aspects of scene understanding. The different shapes highlight the unique features and perspectives extracted by the diverse foundation models, which range from vision-language models to perception models. This visualization emphasizes the multi-modality and multi-granularity of features extracted for the proposed multimodal memory.
read the caption
Figure 4: The UMAP visualization of model embedding manifolds reveals distinct shapes, reflecting different focus.

🔼 This figure illustrates the process of extracting patch-level visual embeddings from various foundation models for downstream tasks. It shows how different models (DINOv2, CLIP, SigLIP, LLaMA3, LLaMAv) process input images, focusing on their respective strengths in vision and language understanding. The extracted features from different layers of these models are used to build a comprehensive understanding of the scene at a granular level. The output shows how the combined features can be effectively used in applications such as visual question answering, captioning, and retrieval.
read the caption
Figure 5: Illustration of patch-level visual embedding extraction their applications.

🔼 Figure 6 presents a qualitative comparison of the M3 model’s performance across four diverse datasets: Garden, Playroom, Drjohnson, and Tabletop. The images showcase the model’s consistent ability to accurately capture and render fine-grained details, intricate textures, and complex scene structures, regardless of the dataset’s specific characteristics. The results demonstrate M3’s robustness and generalizability in handling various visual environments.
read the caption
Figure 6: Qualitative results across datasets using M3. The figure showcases the consistent performance of the M3 across various datasets (Garden, Playroom, Drjohnson, Table-top).

🔼 The figure shows a quadruped robot grasping a rubber duck. The robot uses the M3 model to locate and identify the object based on a text query (‘yellow bath duck’). The image sequence demonstrates the robot’s ability to identify the object, determine its position using a depth camera, and execute a grasping action. This showcases the real-world applicability of the M3 model for tasks involving object manipulation.
read the caption
Figure 7: Real robot deployment.

🔼 This figure showcases the capabilities of the M3 model in real-world robot manipulation tasks. Three scenarios are depicted: part-level understanding (picking up a specific object by its handle), multi-scene understanding (grounding and grasping objects across different environments), and long-horizon tasks (completing a multi-step task such as retrieving an object from a different location and placing it elsewhere). Each scenario is demonstrated with a sequence of images illustrating the robot’s actions.
read the caption
Figure 8: Real robot deployment on part-level understanding, multi-scene and long-horizon tasks.
More on tables
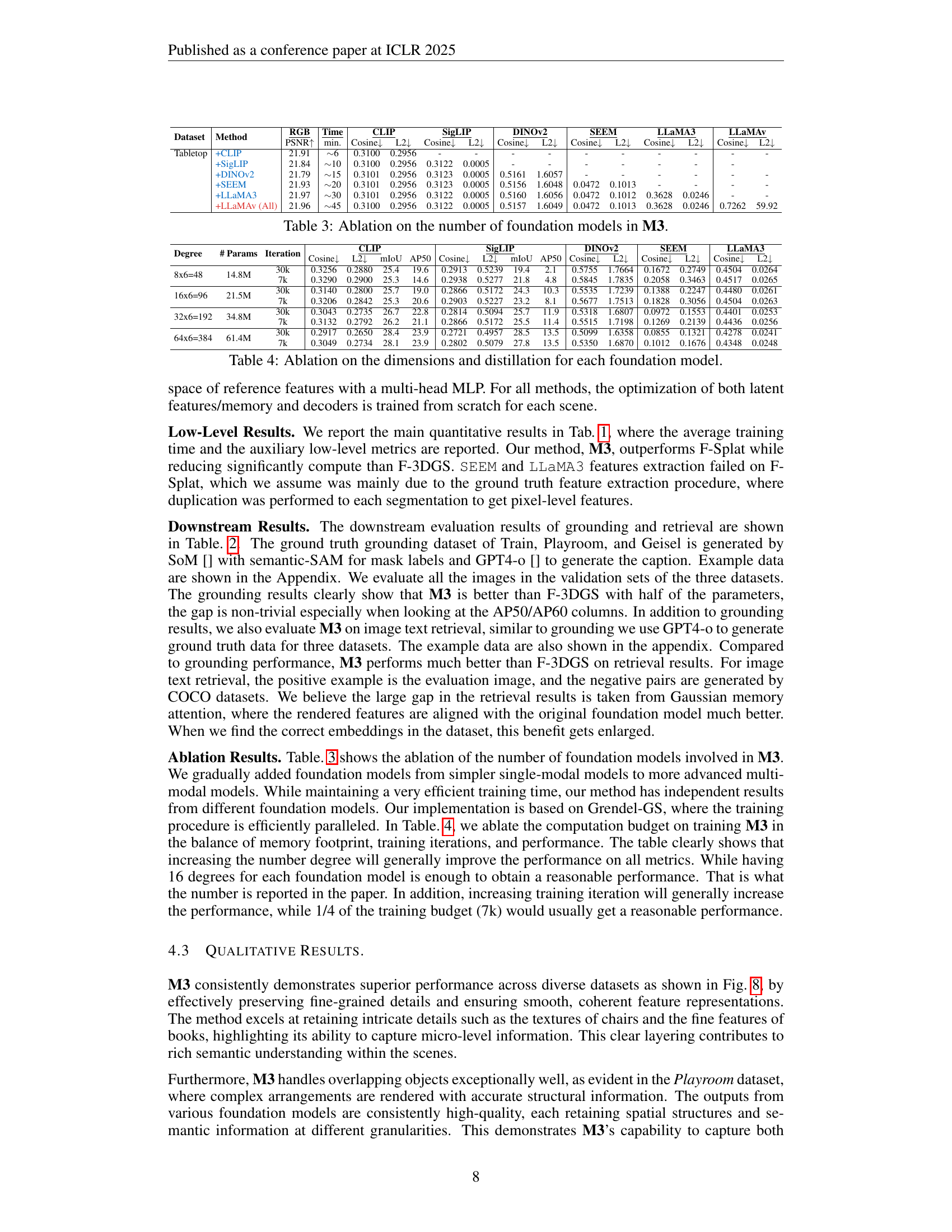
| \ulCLIP | \ulSigLIP | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Method | #Param | mIoU | cIoU | AP50 | AP60 | I2T@1 | I2T@5 | I2T10 | T2I@1 | T2I@5 | T2I10 |
| Train | Ground Truth | - | 25.3 | 26.3 | 14.7 | 3.3 | 81.5 | 97.3 | 100.0 | 71.0 | 89.4 | 92.1 |
| F-3DGS [51] | 61M | 24.2 | 24.3 | 16.3 | 7.1 | 2.6 | 13.2 | 28.9 | 0.0 | 2.6 | 18.4 | |
| M3 | 35M | 25.4 | 26.5 | 19.6 | 12.5 | 55.2 | 84.2 | 92.1 | 52.6 | 84.2 | 92.1 | |
| Playroom | Ground Truth | - | 25.6 | 24.2 | 9.6 | 3.0 | 96.5 | 100.0 | 100.0 | 62.0 | 96.5 | 100.0 |
| F-3DGS [51] | 61M | 23.8 | 21.4 | 11.9 | 3.0 | 79.3 | 96.6 | 96.6 | 31.0 | 79.3 | 89.7 | |
| M3 | 35M | 23.1 | 23.1 | 11.9 | 5.9 | 72.4 | 96.6 | 100.0 | 41.3 | 65.5 | 68.9 | |
| Geisel | Ground Truth | - | 19.5 | 21.4 | 5.3 | 0.0 | 100.0 | 100.0 | 100.0 | 60.0 | 85.7 | 91.4 |
| F-3DGS [51] | 61M | 19.0 | 20.4 | 14.1 | 1.2 | 45.7 | 94.3 | 100.0 | 0.0 | 20.0 | 34.3 | |
| M3 | 35M | 21.8 | 23.5 | 16.5 | 11.8 | 100.0 | 100.0 | 100.0 | 71.4 | 85.7 | 94.2 | |
🔼 This table presents a comprehensive quantitative evaluation of the M3 model’s performance across various foundation models and scenes. It shows feature and RGB metrics (mIoU, cIoU, AP50, AP60, I2T@1, I2T@5, I2T@10, T2I@1, T2I@5, T2I@10) for different scenes (Train, Playroom, Geisel) and the ground truth. This allows for a comparison of M3’s performance against the ground truth and other methods. The metrics assess both the similarity between features extracted by M3 and the ground truth, as well as the model’s performance on downstream tasks, providing insights into the effectiveness of M3 in representing and recalling scene information.
read the caption
Table 2: Feature/RGB metrics for all foundation models and scene.
| \ulRGB | \ulTime | \ulCLIP | \ulSigLIP | \ulDINOv2 | \ulSEEM | \ulLLaMA3 | \ulLLaMAv | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | Method | PSNR | min. | Cosine | L2 | Cosine | L2 | Cosine | L2 | Cosine | L2 | Cosine | L2 | Cosine | L2 |
| Tabletop | +CLIP | 21.91 | 6 | 0.3100 | 0.2956 | - | - | - | - | - | - | - | - | - | - |
| +SigLIP | 21.84 | 10 | 0.3100 | 0.2956 | 0.3122 | 0.0005 | - | - | - | - | - | - | - | ||
| +DINOv2 | 21.79 | 15 | 0.3101 | 0.2956 | 0.3123 | 0.0005 | 0.5161 | 1.6057 | - | - | - | - | - | - | |
| +SEEM | 21.93 | 20 | 0.3101 | 0.2956 | 0.3123 | 0.0005 | 0.5156 | 1.6048 | 0.0472 | 0.1013 | - | - | - | - | |
| +LLaMA3 | 21.97 | 30 | 0.3101 | 0.2956 | 0.3122 | 0.0005 | 0.5160 | 1.6056 | 0.0472 | 0.1012 | 0.3628 | 0.0246 | - | - | |
| +LLaMAv (All) | 21.96 | 45 | 0.3100 | 0.2956 | 0.3122 | 0.0005 | 0.5157 | 1.6049 | 0.0472 | 0.1013 | 0.3628 | 0.0246 | 0.7262 | 59.92 | |
🔼 This table presents an ablation study analyzing the impact of using different numbers of foundation models within the M3 model. It shows how the performance changes as more models (CLIP, SigLIP, DINOv2, SEEM, LLaMA3, and LLaMAv) are incorporated into the system. The results are evaluated using PSNR, cosine similarity, and L2 distance metrics across different feature spaces, showing the trade-off between model complexity and performance.
read the caption
Table 3: Ablation on the number of foundation models in M3.
| Degree | # Params | Iteration | CLIP | SigLIP | DINOv2 | SEEM | LLaMA3 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cosine↓ | L2↓ | mIoU | AP50 | Cosine↓ | L2↓ | mIoU | AP50 | Cosine↓ | L2↓ | Cosine↓ | L2↓ | Cosine↓ | L2↓ | |||
| 8x6=48 | 14.8M | 30k | 0.3256 | 0.2880 | 25.4 | 19.6 | 0.2913 | 0.5239 | 19.4 | 2.1 | 0.5755 | 1.7664 | 0.1672 | 0.2749 | 0.4504 | 0.0264 |
| 7k | 0.3290 | 0.2900 | 25.3 | 14.6 | 0.2938 | 0.5277 | 21.8 | 4.8 | 0.5845 | 1.7835 | 0.2058 | 0.3463 | 0.4517 | 0.0265 | ||
| 16x6=96 | 21.5M | 30k | 0.3140 | 0.2800 | 25.7 | 19.0 | 0.2866 | 0.5172 | 24.3 | 10.3 | 0.5535 | 1.7239 | 0.1388 | 0.2247 | 0.4480 | 0.0261 |
| 7k | 0.3206 | 0.2842 | 25.3 | 20.6 | 0.2903 | 0.5227 | 23.2 | 8.1 | 0.5677 | 1.7513 | 0.1828 | 0.3056 | 0.4504 | 0.0263 | ||
| 32x6=192 | 34.8M | 30k | 0.3043 | 0.2735 | 26.7 | 22.8 | 0.2814 | 0.5094 | 25.7 | 11.9 | 0.5318 | 1.6807 | 0.0972 | 0.1553 | 0.4401 | 0.0253 |
| 7k | 0.3132 | 0.2792 | 26.2 | 21.1 | 0.2866 | 0.5172 | 25.5 | 11.4 | 0.5515 | 1.7198 | 0.1269 | 0.2139 | 0.4436 | 0.0256 | ||
| 64x6=384 | 61.4M | 30k | 0.2917 | 0.2650 | 28.4 | 23.9 | 0.2721 | 0.4957 | 28.5 | 13.5 | 0.5099 | 1.6358 | 0.0855 | 0.1321 | 0.4278 | 0.0241 |
| 7k | 0.3049 | 0.2734 | 28.1 | 23.9 | 0.2802 | 0.5079 | 27.8 | 13.5 | 0.5350 | 1.6870 | 0.1012 | 0.1676 | 0.4348 | 0.0248 | ||
🔼 This table presents an ablation study analyzing the impact of varying the dimensionality and distillation techniques for each foundation model used in the M3 system. It shows how different settings of feature vector dimensions and the application (or not) of feature distillation affect performance across various metrics and foundation models. This helps to understand the optimal configuration for balancing model complexity and performance.
read the caption
Table 4: Ablation on the dimensions and distillation for each foundation model.
Full paper#