TL;DR#
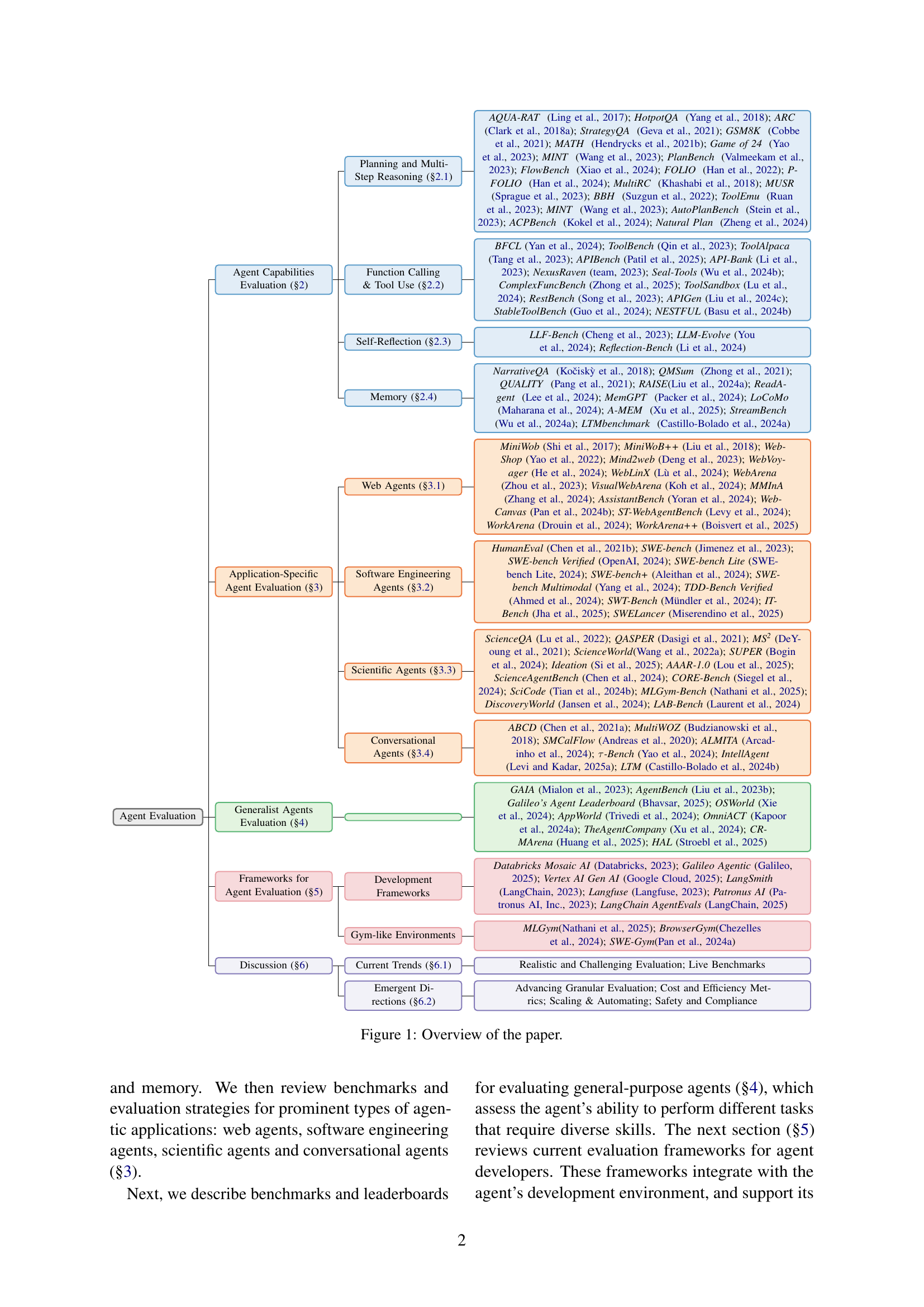
LLM-based agents represent a paradigm shift in AI, enabling autonomous systems to perform complex tasks in dynamic environments. This paper addresses the need for reliable evaluation methods. It covers fundamental agentic capabilities like planning, tool use, memory and identifies gaps in cost, safety and robustness.
This survey comprehensively maps evaluation, serving LLM agent developers and practitioners. It reviews benchmarks and strategies for prominent applications: web, software engineering, scientific, and conversational agents. The paper discusses current trends, and directions for future research, highlighting opportunities for better metrics.
Key Takeaways#
Why does it matter?#
This survey is important as it provides a comprehensive overview of LLM agent evaluation, offering crucial insights for developers, practitioners, and researchers. It highlights current challenges, emerging trends, and gaps in areas like safety and cost-efficiency, guiding future innovation and responsible development in the rapidly evolving field of AI agents. It enables researchers to better grasp the capabilities and limitations of current agents.
Visual Insights#
| Framework | Stepwise Assessment | Monitoring | Trajectory Assessment | Human in the Loop | Synthetic Data Generation | A/B Comparisons |
|---|---|---|---|---|---|---|
| LangSmith (LangChain) | ✓ | ✓ | ✓ | ✓ | × | ✓ |
| Langfuse (Langfuse) | ✓ | ✓ | × | ✓ | × | ✓ |
| Google Vertex AI evaluation (Google Cloud) | ✓ | ✓ | ✓ | × | × | ✓ |
| Arize AI’s Evaluation (Arize AI, Inc) | ✓ | ✓ | × | ✓ | ✓ | ✓ |
| Galileo Agentic Evaluation (Galileo) | ✓ | ✓ | × | ✓ | × | ✓ |
| Patronus AI (Patronus AI, Inc.) | ✓ | ✓ | × | ✓ | ✓ | ✓ |
| AgentsEval (LangChain) | × | × | ✓ | × | × | × |
| Mosaic AI (Databricks) | ✓ | ✓ | × | ✓ | ✓ | ✓ |
🔼 This table compares the capabilities of several prominent frameworks for evaluating Large Language Model (LLM) agents. It shows which frameworks support various assessment features, including stepwise assessment (evaluating individual actions), trajectory assessment (analyzing the overall sequence of actions), the use of human-in-the-loop evaluations, the generation of synthetic data for evaluation, and A/B comparisons (comparing the performance of different versions or setups). The caption notes that some capabilities are still under development.
read the caption
Table 1: Supported evaluation capabilities of major agent frameworks. Note that some of these capabilities are still in initial phases of development, as discussed further in the text.
Full paper#