TL;DR#
Identity-preserved image generation struggles with maintaining fidelity and flexibility. Existing methods often suffer from insufficient identity similarity, poor alignment, and low quality, especially with advanced Diffusion Transformers (DiTs). This makes it hard to flexibly manipulate images while ensuring the person’s identity is maintained.
InfiniteYou (InfU) tackles these issues with InfuseNet, injecting identity features into the DiT model through residual connections. This enhances identity similarity without compromising generation capabilities. A multi-stage training strategy, including pretraining and supervised fine-tuning using synthetic data, further improves text-image alignment, quality, and aesthetics. InfU achieves state-of-the-art performance, surpassing existing methods and offering a plug-and-play design for broad compatibility.
Key Takeaways#
Why does it matter?#
This paper introduces InfU, a robust framework leveraging DiTs for identity-preserved image generation. Its plug-and-play design ensures compatibility with existing methods, offering a valuable contribution to the broader community. It sets a new benchmark and will stimulate future works.
Visual Insights#

🔼 Figure 1 showcases example images generated by InfiniteYou. The figure demonstrates the model’s ability to faithfully recreate a person’s likeness in different scenarios and outfits while adhering closely to textual descriptions. This highlights the model’s success in preserving identity, accurately reflecting the given text prompts, achieving high-quality output, and maintaining aesthetic appeal.
read the caption
Figure 1: InfiniteYou generates identity-preserved images with exceptional identity similarity, text-image alignment, quality, and aesthetics.
| Method | ID Loss | CLIPScore | PickScore |
| FLUX.1-dev IPA [20] | 0.772 | 0.243 | 0.204 |
| PuLID-FLUX [14] | 0.225 | 0.286 | 0.212 |
| InfU (Ours) | 0.209 | 0.318 | 0.221 |
🔼 This table presents a quantitative comparison of three different methods for identity-preserved image generation: FLUX.1-dev IP-Adapter, PuLID-FLUX, and the proposed InfU method. The comparison is based on three key metrics: ID Loss (measuring the difference between generated and reference identity images; lower is better), CLIPScore (measuring text-image alignment; higher is better), and PickScore (measuring overall image quality and aesthetics; higher is better). The results provide a numerical evaluation of each method’s performance across these three crucial aspects of identity-preserved image generation.
read the caption
Table 1: The ID Loss (lower is better) and CLIPScore (higher is better), and PickScore (higher is better) comparative results.
In-depth insights#
DiT Architecture#
DiT (Diffusion Transformer) architectures are pivotal in modern image generation, surpassing U-Net-based models in quality. They leverage Vision Transformers (ViTs) with text embeddings, achieving higher generative capacity. The architecture typically employs a frozen text encoder (like T5 or CLIP) to process text prompts, feeding these embeddings into the DiT. A key aspect is the use of multimodal diffusion backbones (MMDiT), separating weights for text and image modalities, enhancing representation. InfuseNet can also be integrated into the DiT architecture, facilitating identity injection through residual connections, crucial for personalized image generation while maintaining high fidelity and text alignment. The architecture’s scalability and compatibility enable integration with various plugins and methods.
InfuseNet Design#
InfuseNet, a core component, is a generalization of ControlNet, designed to inject identity features into the DiT base model via residual connections. This approach disentangles text and identity injections, enhancing identity similarity without compromising the generative capabilities of the DiT. InfuseNet predicts output residual connections of DiT blocks. Its architecture mirrors the DiT base model, ensuring scalability and compatibility. The input includes both identity and control signals, and it utilizes a projection network to process identity embeddings. This design is significant because it avoids direct modification of attention layers, mitigating potential entanglement and conflict between text and identity information. By focusing on residual connections, InfuseNet maintains the high generation quality and text-image alignment. The number of DiT blocks are reduced.
SPMS Data#
SPMS (Single-Person-Multiple-Sample) data is a crucial element in improving text-image alignment, image quality, and aesthetic appeal in identity-preserved image generation. It’s generated using a real face image as the source identity and synthetic data as the generation target, enhancing quantity, quality, and text-image alignment of training data. The SPMS format ensures the model learns high-quality aesthetics while retaining identity similarity, mitigating face copy-pasting issues. This synthetic data is generated using the pretrained model itself with modules like aesthetic LoRAs, face swap tools and other pre/post-processing tools. This process results in a dataset of paired real and synthetic images, where the real image represents the authentic identity and the corresponding synthetic image reflects the same identity with enhanced attributes dictated by text descriptions. By training on SPMS data, the model effectively bridges the gap between real and synthetic representations, thus improving generalization capabilities and reducing artifacts such as the undesirable face copy-paste effect.
RF Trajectories#
I believe the research delves into the nature of ‘Rectified Flow Trajectories’ (RF Trajectories) for generative modeling. Given the broader context of diffusion models and transformers discussed, it’s likely the work explores novel methods to define and optimize these trajectories within the latent space. This could involve exploring how different trajectory parameterizations affect the quality and efficiency of the generative process. The research could also be investigating new loss functions or training strategies specifically designed to encourage desirable properties in these RF trajectories. Given that the context also includes flexible image generation, the RF Trajectories would play a part in being able to generate many images while also holding consistent properties. In doing so this could involve fine-tuning the model by doing a multi-stage training, where you are improving the quantity, quality, and text-image alignment of the data.
Plug-and-Play#
The study showcases desirable plug-and-play properties of ‘InfiniteYou (InfU)’, emphasizing compatibility with existing methods like FLUX.1-dev variants for efficient generation and ControlNets/LoRAs for customizable tasks. InfU extends potential for multi-concept personalization with OminiControl, enabling interacted ID and object personalized generation. Though using IP-Adapter (IPA) with InfU for identity injection is suboptimal, it is readily compatible with IPA for stylization, injecting style references. InfU’s plug-and-play nature promotes extensibility to numerous approaches, contributing to the broader community. This adaptability enhances InfU’s versatility, making it a valuable tool for diverse image generation tasks.
More visual insights#
More on figures

🔼 Figure 2 demonstrates the improved image generation quality achieved by using Diffusion Transformers (DiTs) compared to U-Net based models. The left panel shows examples generated by U-Net based Stable Diffusion XL (SDXL) and DiT-based FLUX models. The right panel highlights the negative impacts of using the IP-Adapter method for identity injection in DiT-based methods. It visually compares the results generated with and without the IP-Adapter, showcasing issues such as compromised image quality and loss of text-image alignment.
read the caption
Figure 2: The superiority of the DiT-based method over the U-Net-based one and the side effects of IP-Adapter (IPA) [54].

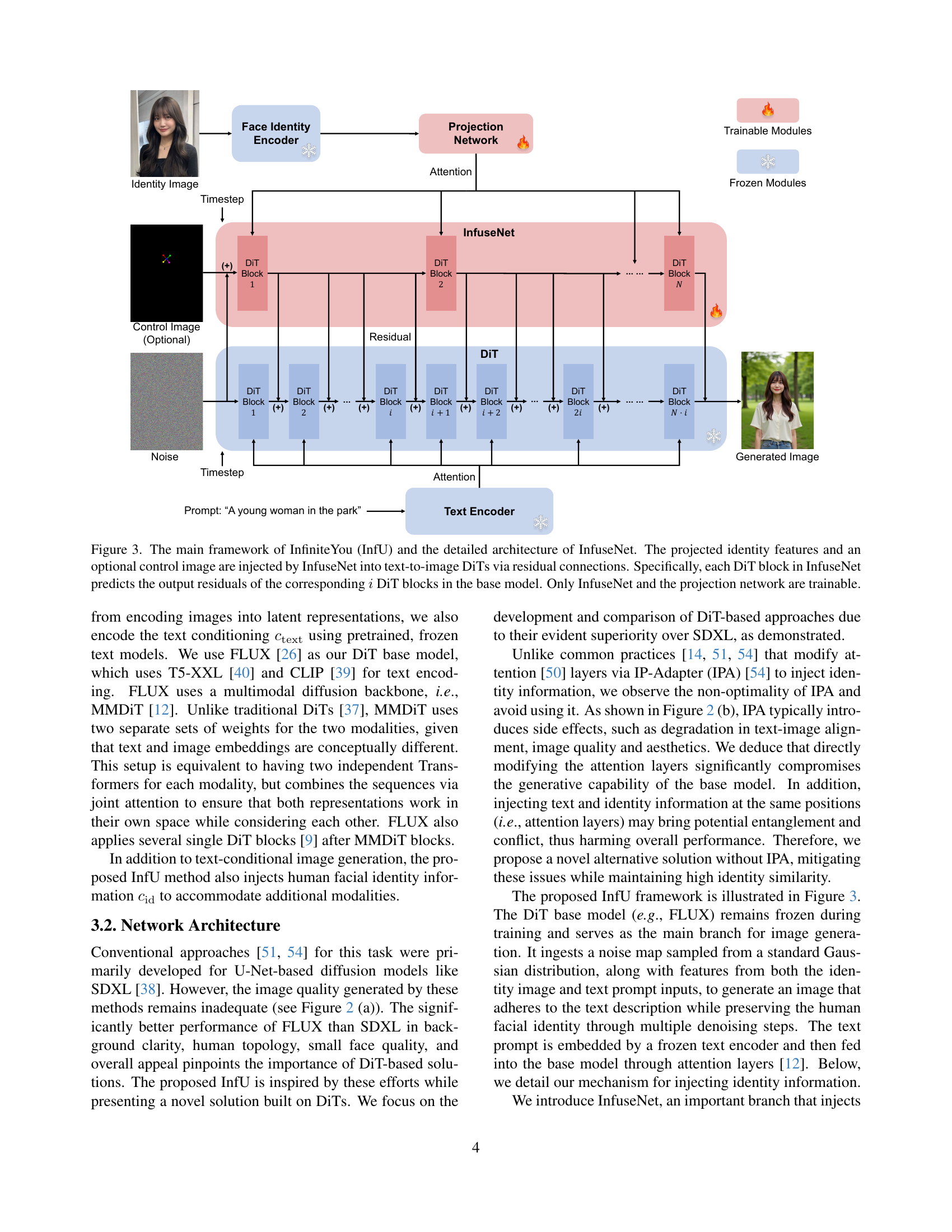
🔼 Figure 3 illustrates the architecture of InfiniteYou (InfU), a framework for identity-preserved image generation. The main components are: a Face Identity Encoder that processes an identity image; a Text Encoder that processes text prompts; a DiT (Diffusion Transformer) base model, which is a pre-trained text-to-image generation model; and InfuseNet, a novel module designed to inject identity information and optionally a control image into the DiT base model. InfuseNet injects these features via residual connections, meaning that it adds its output to the output of corresponding blocks within the main DiT model. This approach allows the model to preserve the generative capabilities of the DiT while adding identity information. A key aspect of InfuseNet’s design is that each of its blocks modifies the outputs of a multiple of the base model’s blocks (i blocks, where i is a multiplication factor), allowing it to scale and improve identity similarity. Only InfuseNet and the projection network (which transforms the identity features) are trainable; the DiT base model is kept frozen to preserve its generation capabilities. The generated image reflects the injected identity while adhering to the given text prompt and control image information.
read the caption
Figure 3: The main framework of InfiniteYou (InfU) and the detailed architecture of InfuseNet. The projected identity features and an optional control image are injected by InfuseNet into text-to-image DiTs via residual connections. Specifically, each DiT block in InfuseNet predicts the output residuals of the corresponding i𝑖iitalic_i DiT blocks in the base model. Only InfuseNet and the projection network are trainable.

🔼 Figure 4 illustrates the multi-stage training process employed to enhance the InfiniteYou model. It begins with pretraining using real single-person-single-sample (SPSS) data. Then, it leverages the pretrained model to generate synthetic single-person-multiple-sample (SPMS) data, which is used in a supervised fine-tuning (SFT) stage. The entire process aims to improve aspects like text-image alignment, image quality, and aesthetics, while maintaining identity preservation.
read the caption
Figure 4: The introduced multi-stage training strategy with synthetic single-person-multiple-sample (SPMS) data and supervised fine-tuning (SFT).

🔼 Figure 5 presents a qualitative comparison of image generation results from three different methods: InfU (the proposed method), FLUX.1-dev IP-Adapter [20], and PuLID-FLUX [14]. Each method is applied to generate images based on the same set of text prompts and identity images. The figure allows for a visual comparison of the image quality, the accuracy of identity preservation, and the degree of alignment between generated images and the corresponding text prompts. This visual comparison demonstrates the superiority of InfU in terms of generating high-quality, identity-preserved images that closely match the given text descriptions.
read the caption
Figure 5: Qualitative comparison results of InfU with the state-of-the-art baselines, FLUX.1-dev IP-Adapter [20] and PuLID-FLUX [14].
Full paper#