TL;DR#
Key Takeaways#
Why does it matter?#
This paper introduces a new trajectory-controllable video generation framework which allows researchers to flexibly control object movements, create high-quality videos, and easily evaluate models. The dataset and benchmark can help the development of future video generation tasks.
Visual Insights#

🔼 This figure showcases example videos generated using MagicMotion. The process involves three stages, each demonstrating a different level of control, progressing from dense to sparse guidance. Stage 1 uses dense masks to define object movement. Stage 2 employs bounding boxes for less precise control. Finally, Stage 3 utilizes sparse bounding boxes, offering the most flexible, though less precise, control. The input to MagicMotion is a single image and a trajectory (path) defined by the user. The system then generates high-quality video where the designated objects within the image smoothly move along the specified trajectory path.
read the caption
Figure 1: Example videos generated by MagicMotion. MagicMotion consists of three stages, each supporting a different level of control from dense to sparse: mask, box, and sparse box. Given an input image and any form of trajectory, MagicMotion can generate high-quality videos, animating objects in the image to move along the user-specified path.
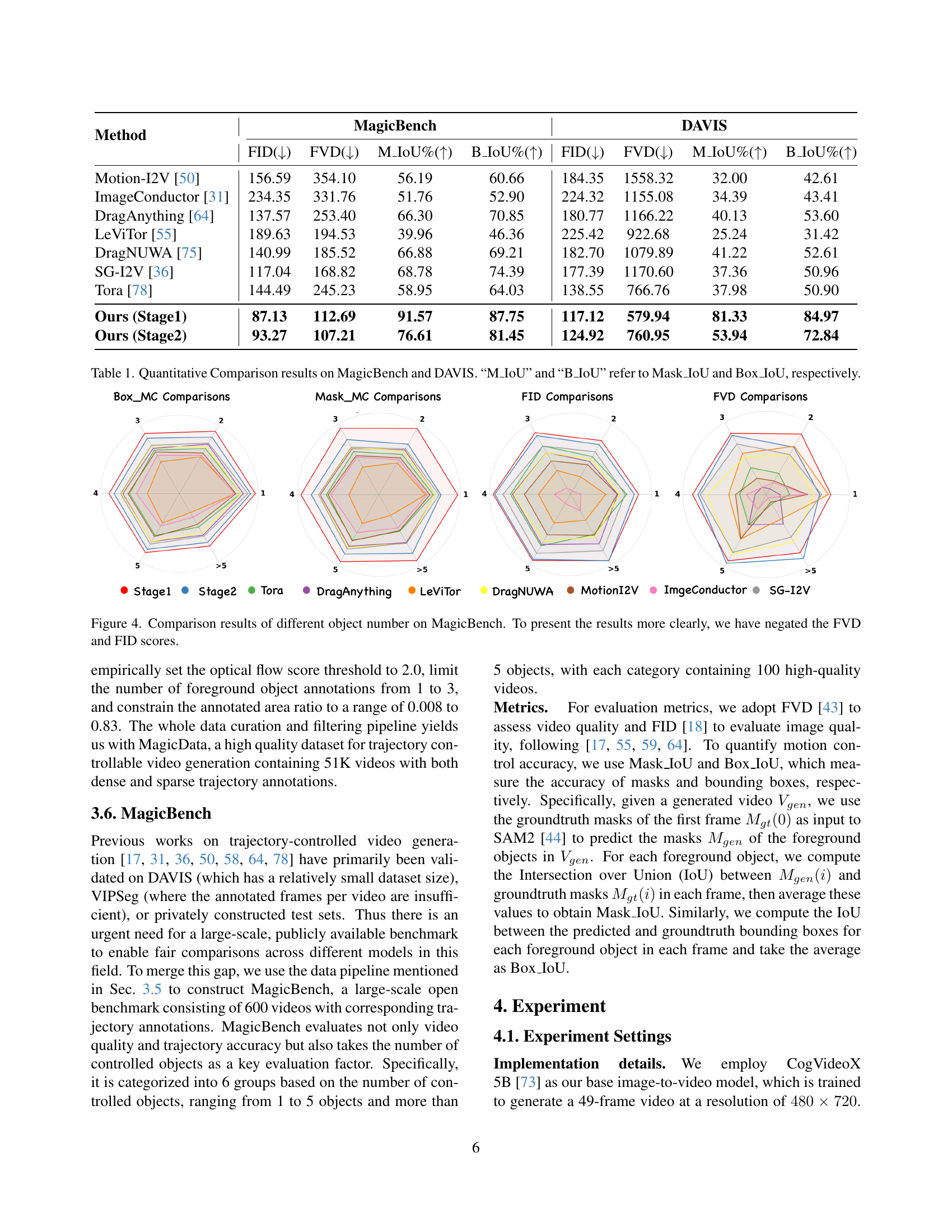
| Method | MagicBench | DAVIS | ||||||
|---|---|---|---|---|---|---|---|---|
| FID() | FVD() | M_IoU%() | B_IoU%() | FID() | FVD() | M_IoU%() | B_IoU%() | |
| Motion-I2V [50] | 156.59 | 354.10 | 56.19 | 60.66 | 184.35 | 1558.32 | 32.00 | 42.61 |
| ImageConductor [31] | 234.35 | 331.76 | 51.76 | 52.90 | 224.32 | 1155.08 | 34.39 | 43.41 |
| DragAnything [64] | 137.57 | 253.40 | 66.30 | 70.85 | 180.77 | 1166.22 | 40.13 | 53.60 |
| LeViTor [55] | 189.63 | 194.53 | 39.96 | 46.36 | 225.42 | 922.68 | 25.24 | 31.42 |
| DragNUWA [75] | 140.99 | 185.52 | 66.88 | 69.21 | 182.70 | 1079.89 | 41.22 | 52.61 |
| SG-I2V [36] | 117.04 | 168.82 | 68.78 | 74.39 | 177.39 | 1170.60 | 37.36 | 50.96 |
| Tora [78] | 144.49 | 245.23 | 58.95 | 64.03 | 138.55 | 766.76 | 37.98 | 50.90 |
| Ours (Stage1) | 87.13 | 112.69 | 91.57 | 87.75 | 117.12 | 579.94 | 81.33 | 84.97 |
| Ours (Stage2) | 93.27 | 107.21 | 76.61 | 81.45 | 124.92 | 760.95 | 53.94 | 72.84 |
🔼 Table 1 presents a quantitative comparison of different video generation models on two benchmark datasets: MagicBench and DAVIS. The models are evaluated based on several metrics, providing a comprehensive assessment of their performance. These metrics include the Fréchet Inception Distance (FID), which measures the visual quality of the generated videos; the Fréchet Video Distance (FVD), also assessing visual quality with a focus on temporal consistency; and the mean Intersection over Union (mIoU) and bounding box IoU (B_IoU), which evaluate the accuracy of the trajectory control, specifically measuring how well the generated videos match the specified trajectories using mask and bounding box annotations. Higher mIoU and B_IoU values indicate more accurate trajectory adherence. Lower FID and FVD values indicate higher visual quality.
read the caption
Table 1: Quantitative Comparison results on MagicBench and DAVIS. “M_IoU” and “B_IoU” refer to Mask_IoU and Box_IoU, respectively.
In-depth insights#
Dense-Sparse Guidance#
The concept of dense-to-sparse guidance in video generation offers a compelling strategy for balancing control and user-friendliness. Dense guidance, like masks, provides precise control but demands significant user effort. Conversely, sparse guidance, such as bounding boxes or keypoints, simplifies user input but sacrifices fine-grained control. A framework leveraging both could offer adaptable control, allowing users to start with sparse guidance and progressively refine with denser inputs. Furthermore, training strategies could progressively leverage data with increasing density allowing a model to learn coarse motion patterns before focusing on finer details. This approach not only improves usability but also potentially enhances video quality by guiding the generation process from high-level structure to low-level detail, promoting coherence and realism. The implementation should explore how information is transitioned, fused and how to leverage pre-existing data from varying densities.
Trajectory ControlNet#
The Trajectory ControlNet is inspired by ControlNet to inject trajectory information into the diffusion model. It employs a trainable copy of pre-trained DiT blocks to encode user-provided trajectory information. The output of each block is processed through a zero-initialized convolution layer and added to the corresponding DiT block in the base model. This design choice ensures that trajectory control is incorporated seamlessly without disrupting the pre-trained model’s capabilities. By using a separate, trainable network for trajectory encoding, the framework allows for flexible adaptation to different trajectory types and control levels, ranging from dense masks to sparse boxes.
Latent Segmentation#
The concept of “Latent Segmentation” aims to enhance video generation by incorporating segmentation mask information during training, particularly for improving fine-grained object shape perception. It tackles the challenge of bounding box-based trajectories lacking precise shape control. By predicting segmentation masks directly in the latent space, the approach reduces computational costs while leveraging the rich semantic information within diffusion models. This enables a lightweight segmentation head to refine object boundaries, improving the model’s understanding of object shapes even under sparse control conditions, like bounding boxes. The Euclidean distance between predicted and ground truth mask latents serves as the loss function, guiding the model to generate more accurate and detailed object representations.
MagicData Details#
Based on the provided information, MagicData seems to be a crucial, novel dataset specifically designed for trajectory-controlled video generation. Addressing the lack of publicly available, large-scale datasets in this domain, its creation appears motivated by limitations in existing VOS datasets. MagicData consists of 51K videos, each meticulously annotated with a<video, text, trajectory> triplet. To generate such a dataset, the authors have proposed a data generation pipeline where a large language model (LLM) extracts the main moving objects in the video, which is followed by Segment Anything Model (SAM2) to annotate both segmentation masks and bounding boxes of the detected objects. This systematic approach addresses critical needs within video generation research, enabling more robust training, standardized benchmarks, and ultimately, advancing the field towards more controllable and high-quality video synthesis.
Object # Impact#
In trajectory-controlled video generation, the number of objects significantly influences the complexity and impact of results. Fewer objects might lead to simpler, more predictable motion paths, which can be easier to control but potentially less visually interesting. More objects introduce intricate relationships and interactions, demanding more sophisticated algorithms for consistent movement and appearance maintenance. Moreover, manipulating a high number of objects elevates the creative possibilities, enabling diverse, dynamic scenes. However, it also introduces challenges in ensuring each object adheres to its specified trajectory while preventing collisions or occlusions. Quantitatively, the number of objects acts as a critical dimension for evaluating video generation models, since controlling more objects simultaneously serves as an indicator of model robustness.
More visual insights#
More on figures

🔼 MagicMotion uses a pretrained 3D Variational Autoencoder (VAE) to transform the input trajectory, the first frame of the video, and the training video into a latent space. The architecture has two main branches. The video branch processes video and image tokens. The trajectory branch uses a Trajectory ControlNet to combine trajectory and image tokens. These combined tokens are then integrated into the video branch via a zero-initialized convolution layer. Diffusion features from DiT (Diffusion Transformer) blocks are then combined and processed by a trainable segment head to generate latent segmentation masks, improving the model’s understanding of object shapes and contributing to the latent segmentation loss.
read the caption
Figure 2: Overview of MagicMotion Architecture (text prompt and encoder are omitted for simplicity). MagicMotion employs a pretrained 3D VAE to encode the input trajectory, first-frame image, and training video into latent space. It has two separate branches: the video branch processes video and image tokens, and the trajectory branch uses Trajectory ControlNet to fuse trajectory and image tokens, which is later integrated to the video branch through a zero-initialized convolution layer. Besides, diffusion features from DiT blocks are concatenated and processed by a trainable segment head to predict latent segmentation masks, which contribute to our latent segment loss.

🔼 Figure 3 illustrates the two-stage pipeline used to create the MagicData dataset. The first stage, the Curation Pipeline, extracts trajectory information from the video-text dataset, starting by identifying main moving objects from the textual descriptions and then using SAM to generate segmentation masks and bounding boxes. The second stage, the Filtering Pipeline, removes unsuitable videos using various criteria, such as optical flow analysis and checks on mask and bounding box sizes, to ensure only high-quality and relevant videos are included for training. This process results in a refined dataset suitable for training a trajectory controllable video generation model.
read the caption
Figure 3: Overview of the Dataset Pipeline. The Curation Pipeline is used to construct trajectory annotations, while the Filtering Pipeline filters out unsuitable videos for training.

🔼 Figure 4 presents a radar chart comparison of various video generation methods across different numbers of moving objects, evaluated using the MagicBench benchmark. The chart visualizes the performance of each method on metrics such as Fréchet Video Distance (FVD) and Fréchet Inception Distance (FID), both critical for assessing video quality. Importantly, FVD and FID scores have been negated for clearer visual representation, with lower scores indicating better performance. This allows for easy comparison of methods’ effectiveness in handling varying numbers of objects (1, 2, 3, 4, 5 and more than 5 moving objects). The figure illustrates how effectively each method controls objects in videos with differing levels of complexity, providing insights into their ability to maintain accuracy and quality with increasing object counts.
read the caption
Figure 4: Comparison results of different object number on MagicBench. To present the results more clearly, we have negated the FVD and FID scores.

🔼 Figure 5 presents a qualitative comparison of video generation results from MagicMotion and seven other state-of-the-art methods. Each row shows the results of a different method in response to the same prompt and trajectory input. The top row shows results from MagicMotion, demonstrating successful control over the objects’ movement along the specified path. The subsequent rows display results from the competing methods, which all show significant flaws in object tracking and/or visual consistency. These errors are highlighted with orange boxes in the figure.
read the caption
Figure 5: MagicMotion successfully controls the main objects moving along the provided trajectory, while all other methods exhibit significant defects marked with the orange box.

🔼 This ablation study compares the performance of the MagicMotion model trained on the MagicData dataset against a model trained on a different dataset (an ablation dataset created from MeViS and MOSE datasets). The image shows the results of a video generation task where the goal is to move a boy from one position to another. The model trained without MagicData fails to maintain consistent object identity, generating an unexpected child alongside the intended boy. In contrast, the model trained with MagicData correctly performs the video generation task.
read the caption
Figure 6: Ablation Study on MagicData. Not using MagicData causes the model to generate an unexpected child.

🔼 This ablation study investigates the impact of the progressive training procedure on MagicMotion’s performance. The figure compares video frames generated with and without the progressive training. The results show that omitting this training step leads to significant distortions, particularly noticeable in the generated shapes of objects’ heads, demonstrating the importance of this training strategy for accurate and consistent video generation.
read the caption
Figure 7: Ablation study on the progressive training procedure. Without it, the generated head shapes become noticeably distorted.

🔼 This ablation study investigates the impact of the latent segment loss on the model’s ability to generate accurate object shapes, particularly when dealing with sparse trajectory information. The figure shows a comparison of video frames generated with and without the latent segment loss. The results demonstrate that omitting the latent segment loss leads to incomplete or inaccurate object shapes, such as missing parts of a person’s arms in the example shown. This highlights the importance of the latent segment loss in improving the model’s understanding of object shapes and ensuring the generation of visually consistent and accurate video sequences.
read the caption
Figure 8: Ablation Study on latent segment loss. Without it, the generated arms appear partially missing.

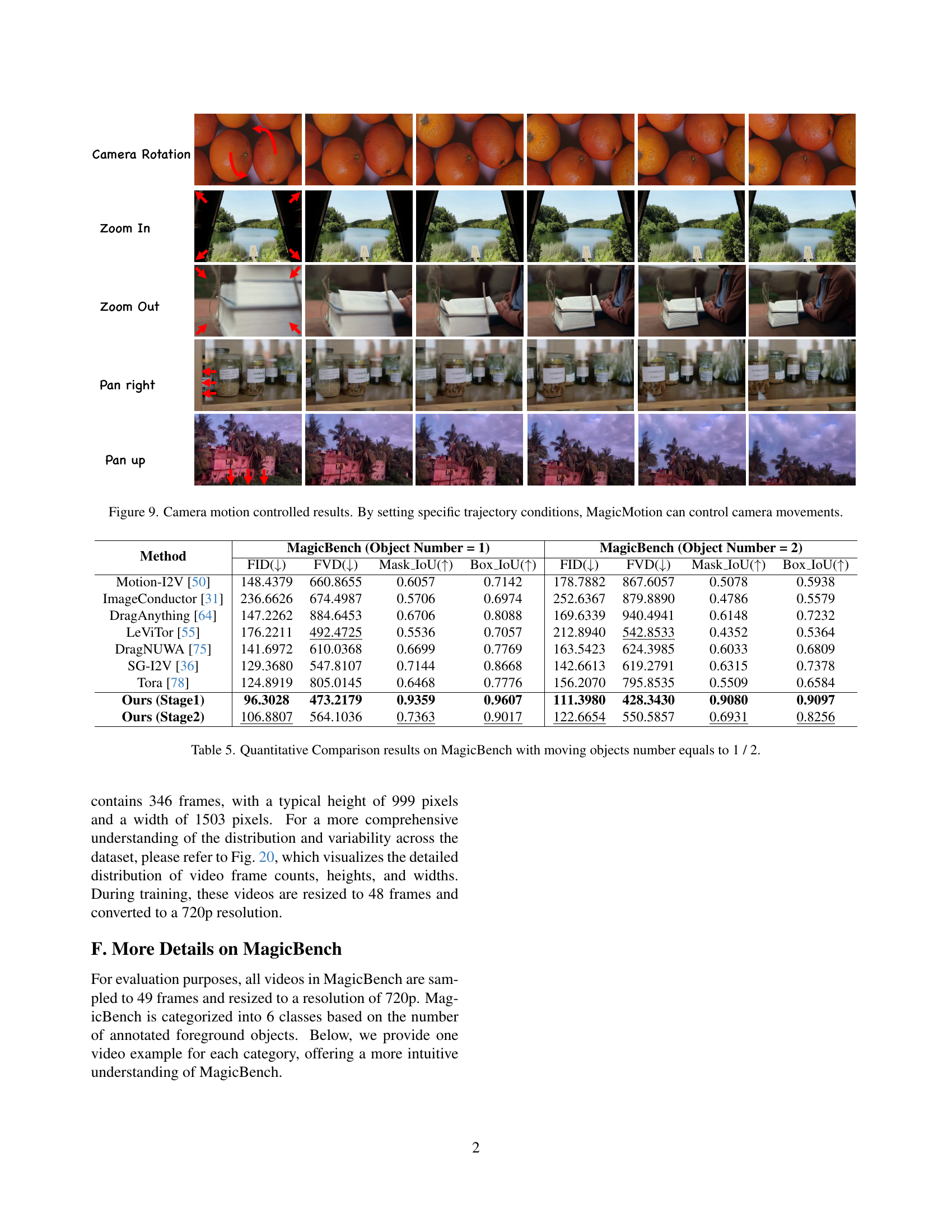
🔼 This figure showcases MagicMotion’s capability to control camera movements by manipulating trajectory conditions. The top row demonstrates rotation, the second and third rows show zooming in and out, respectively, achieved by altering the size of bounding boxes. The bottom two rows illustrate panning left and down, demonstrating versatile camera control during video generation.
read the caption
Figure 9: Camera motion controlled results. By setting specific trajectory conditions, MagicMotion can control camera movements.

🔼 Figure 10 demonstrates the application of MagicMotion for video editing. The process begins by using FLUX [29] to modify the first frame of a video. This modified frame then serves as input to MagicMotion’s Stage 1. The trajectory information from the original video is used as guidance for MagicMotion. Consequently, the foreground objects in the video are smoothly animated along the paths from the original video, resulting in high-quality edited videos. The figure showcases several examples of this video editing approach with varying types of video edits, including transforming a swan, a camel, and a hiker.
read the caption
Figure 10: Video Editing Results. We use FLUX [29] to edit the first-frame image and MagicMotion Stage1 to move the foreground objects following the trajectory of the origin video.

🔼 This figure demonstrates the controllability of MagicMotion. Using a single input image, MagicMotion generates multiple videos by applying different trajectories to the same objects within the image. The red arrows highlight the varied trajectories used for each video. This showcases MagicMotion’s ability to generate diverse video outputs from a single starting point, controlled solely by altering the input trajectory.
read the caption
Figure 11: MagicMotion can generate videos using the same input image and different trajectories (marked by red arrows).

🔼 Figure 12 shows the visualization of latent segment masks predicted by MagicMotion. Even when only sparse bounding box trajectory information is available as input, MagicMotion can still accurately generate latent segment masks for every frame of the generated video. This demonstrates MagicMotion’s ability to infer detailed object shapes and boundaries from limited guidance, which is crucial for high-quality and precise video generation.
read the caption
Figure 12: Latent Segment Masks visualization. MagicMotion can predict out latent segment masks of each frame even when only provided with sparse bounding boxes guidance.

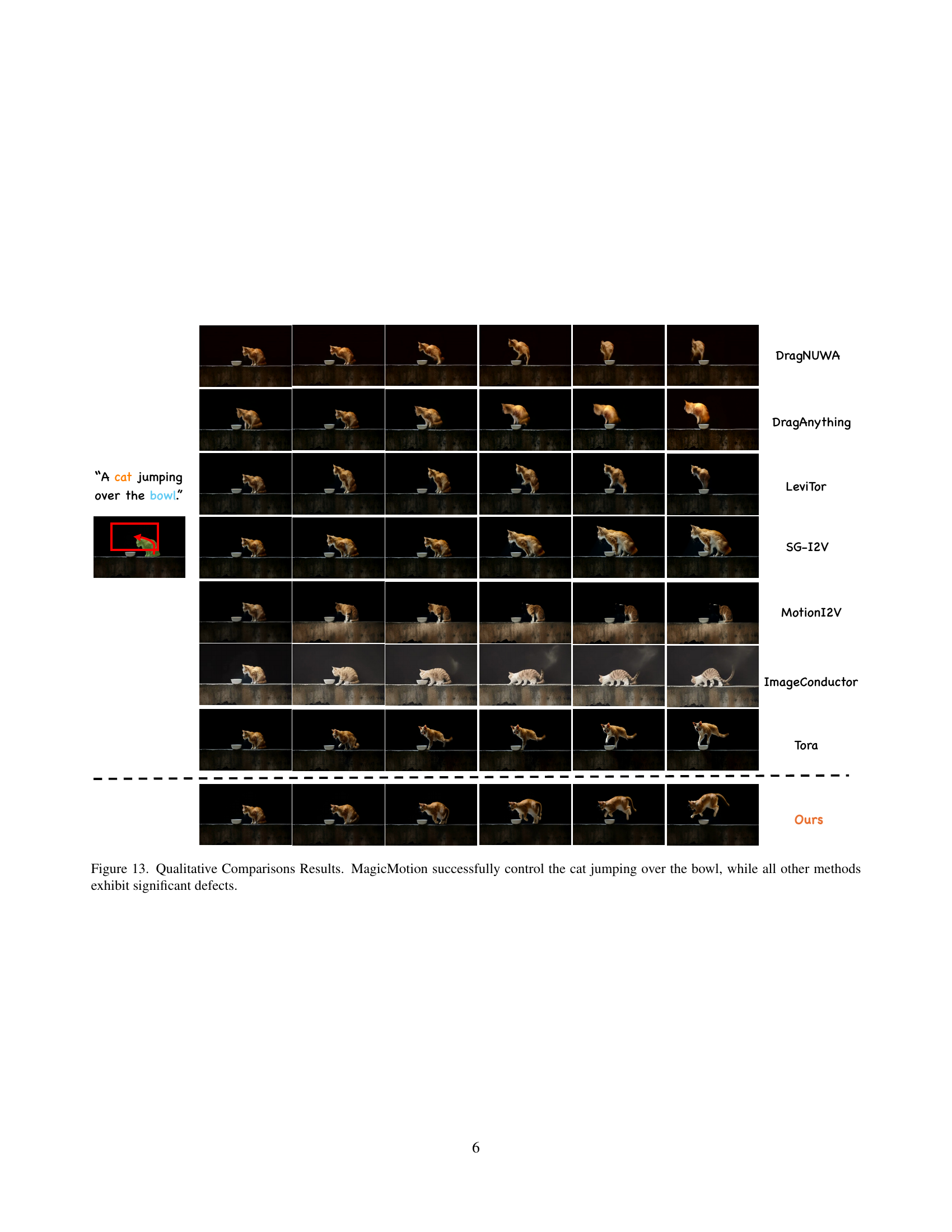
🔼 Figure 13 presents a qualitative comparison of different video generation models’ performance on a task involving a cat jumping over a bowl. Each model is given the same input: a still image depicting the cat and bowl along with trajectory information guiding the cat’s movement. The generated videos are shown, revealing that only MagicMotion successfully animates the cat accurately along the specified trajectory, while all other models produce videos that exhibit flaws such as artifacts, shape distortions, or inaccurate motion.
read the caption
Figure 13: Qualitative Comparisons Results. MagicMotion successfully control the cat jumping over the bowl, while all other methods exhibit significant defects.

🔼 This figure presents a qualitative comparison of different video generation models’ performance in controlling the trajectory of a witch flying over houses. The input consists of a starting image and a trajectory path. Each row shows the output of a different model, illustrating how effectively they can generate a video where the witch follows the specified path while maintaining visual quality and consistency. The comparison highlights MagicMotion’s success in accurately controlling the object’s movement along the designated trajectory, while other models show significant flaws, such as inconsistencies in object appearance or motion.
read the caption
Figure 14: Qualitative Comparisons Results. MagicMotion successfully control the witch flying over the input trajectory, while all other methods exhibit significant defects.

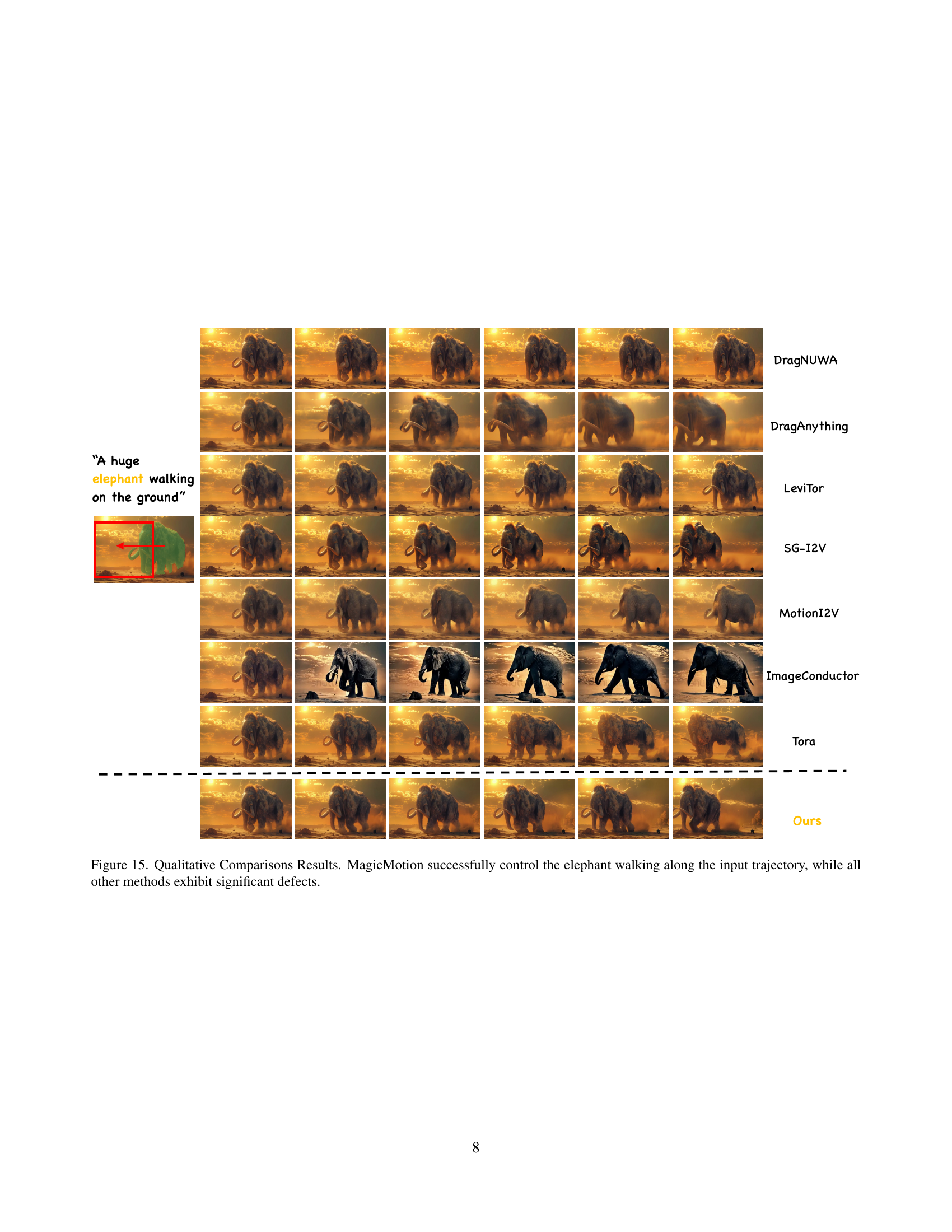
🔼 Figure 15 presents a qualitative comparison of various video generation models’ ability to animate an elephant along a predefined trajectory. The input to each model includes a still image of an elephant and the desired trajectory. MagicMotion accurately animates the elephant following the path, maintaining its shape and visual quality. Conversely, the other methods demonstrate significant inconsistencies, including distortions in the elephant’s form, inaccurate trajectory following, or artifacts in the generated video frames.
read the caption
Figure 15: Qualitative Comparisons Results. MagicMotion successfully control the elephant walking along the input trajectory, while all other methods exhibit significant defects.

🔼 Figure 16 presents a qualitative comparison of various video generation models’ ability to accurately render a robot’s movement along a predetermined path. The input is a trajectory indicating the desired robot motion, and each model attempts to generate a video sequence showing the robot following that trajectory. MagicMotion, the method proposed in this paper, successfully animates the robot along the intended path. In contrast, other state-of-the-art methods shown (DragNUWA, DragAnything, LeViTor, SG-I2V, MotionI2V, ImageConductor, and Tora) exhibit significant discrepancies between their generated robot motion and the target trajectory. These discrepancies manifest as inaccuracies in the robot’s position, speed, and overall movement fidelity.
read the caption
Figure 16: Qualitative Comparisons Results. MagicMotion successfully control the robot moving along the input trajectory, while all other methods exhibit significant defects.

🔼 Figure 17 presents a qualitative comparison of various video generation models’ ability to accurately control the movement of a tiger’s head along a predefined trajectory. The comparison highlights MagicMotion’s superior performance in precisely animating the tiger’s head compared to other methods, which show significant discrepancies and inaccuracies in following the specified trajectory. The other models fail to generate consistent or realistic head movements, underscoring the advanced trajectory control capabilities of MagicMotion.
read the caption
Figure 17: Qualitative Comparisons Results. MagicMotion successfully control the tiger’s head moving along the input trajectory, while all other methods exhibit significant defects.

🔼 This figure shows a qualitative comparison of video generation results using different settings and datasets. It includes three sets of comparisons: (1) comparing the model trained on MagicData versus the model trained on an ablation dataset; (2) comparing the model trained using the progressive training procedure versus a model trained without it; and (3) comparing the model trained using Latent Segment Loss versus one trained without it. Each comparison shows a sequence of frames generated by each approach, along with a red box highlighting any noticeable defects or inconsistencies. This allows for a visual evaluation of the impact of different training techniques and data on the quality and accuracy of video generation.
read the caption
Figure 18: Additional Ablation results.

🔼 Figure 19 presents a detailed statistical overview of the MagicData dataset. It provides histograms illustrating the distribution of video lengths (number of frames), video heights, and video widths. This allows for a better understanding of the dataset’s characteristics and the variability in video parameters.
read the caption
Figure 19: Detail information on MagicData.
More on tables
| Method | MagicBench/DAVIS | |||
|---|---|---|---|---|
| FID() | FVD() | M_IoU%() | B_IoU%() | |
| w/o MagicData | 99.55/128.16 | 125.19/768.27 | 73.39/50.95 | 78.66/70.05 |
| Ours | 93.27/124.91 | 107.21/760.95 | 76.61/53.94 | 81.45/72.84 |
🔼 This ablation study compares the performance of the MagicMotion model trained on the MagicData dataset against a model trained without it. The results demonstrate that training with MagicData significantly improves performance across all evaluation metrics, highlighting the dataset’s importance for achieving high-quality trajectory-controlled video generation.
read the caption
Table 2: Ablation Study on MagicData. The model trained with MagicData outperforms the one trained without it across all metrics.
| Method | MagicBench | DAVIS | ||
|---|---|---|---|---|
| M_IoU%() | B_IoU%() | M_IoU%() | B_IoU%() | |
| w/o LSL | 74.65 | 78.02 | 49.19 | 64.19 |
| w/o PT | 74.61 | 79.49 | 49.22 | 67.34 |
| Ours | 76.61 | 81.45 | 53.94 | 72.84 |
🔼 This ablation study investigates the impact of two key components in the MagicMotion model: Progressive Training (PT) and Latent Segment Loss (LSL). Progressive Training involves training the model sequentially through different levels of trajectory detail (dense to sparse), while Latent Segment Loss guides the model to better understand and generate precise object shapes, particularly when using sparse trajectory information. The table quantifies the effects of removing each component on model performance using standard metrics (M_IoU%, B_IoU%) across two datasets (MagicBench and DAVIS). The results demonstrate the effectiveness of both PT and LSL in achieving improved trajectory control accuracy and enhanced representation of fine-grained object shapes.
read the caption
Table 3: Ablation Study on Progressive Training (PT) and Latent Segment Loss (LSL). Experimental results demonstrate that these techniques enhance the model with better comprehension on fine-grained object shapes.
| Resolution | Length | Base Model | |
|---|---|---|---|
| Motion-I2V [50] | 320*512 | 16 | AnimateDiff [16] |
| ImageConductor [31] | 256*384 | 16 | AnimateDiff [16] |
| DragAnything [64] | 320*576 | 25 | SVD [3] |
| LeViTor [55] | 288*512 | 16 | SVD [3] |
| DragNUWA [75] | 320*576 | 14 | SVD [3] |
| SG-I2V [36] | 576*1024 | 14 | SVD [3] |
| Tora [78] | 480*720 | 49 | CogVideoX [73] |
| MagicMotion | 480*720 | 49 | CogVideoX [73] |
🔼 This table compares the backbone architectures used by different image-to-video generation methods, including the resolution and length of the videos generated by each method. It provides context for understanding the differences in performance observed between models, as different architectures have varying capabilities. The methods are compared based on their base models for video generation, the resulting video resolution, and the length of videos they can generate.
read the caption
Table 4: Comparisons on each method’s backbone.
| Method | MagicBench (Object Number = 1) | MagicBench (Object Number = 2) | ||||||
|---|---|---|---|---|---|---|---|---|
| FID() | FVD() | Mask_IoU() | Box_IoU() | FID() | FVD() | Mask_IoU() | Box_IoU() | |
| Motion-I2V [50] | 148.4379 | 660.8655 | 0.6057 | 0.7142 | 178.7882 | 867.6057 | 0.5078 | 0.5938 |
| ImageConductor [31] | 236.6626 | 674.4987 | 0.5706 | 0.6974 | 252.6367 | 879.8890 | 0.4786 | 0.5579 |
| DragAnything [64] | 147.2262 | 884.6453 | 0.6706 | 0.8088 | 169.6339 | 940.4941 | 0.6148 | 0.7232 |
| LeViTor [55] | 176.2211 | 492.4725 | 0.5536 | 0.7057 | 212.8940 | 542.8533 | 0.4352 | 0.5364 |
| DragNUWA [75] | 141.6972 | 610.0368 | 0.6699 | 0.7769 | 163.5423 | 624.3985 | 0.6033 | 0.6809 |
| SG-I2V [36] | 129.3680 | 547.8107 | 0.7144 | 0.8668 | 142.6613 | 619.2791 | 0.6315 | 0.7378 |
| Tora [78] | 124.8919 | 805.0145 | 0.6468 | 0.7776 | 156.2070 | 795.8535 | 0.5509 | 0.6584 |
| Ours (Stage1) | 96.3028 | 473.2179 | 0.9359 | 0.9607 | 111.3980 | 428.3430 | 0.9080 | 0.9097 |
| Ours (Stage2) | 106.8807 | 564.1036 | 0.7363 | 0.9017 | 122.6654 | 550.5857 | 0.6931 | 0.8256 |
🔼 This table presents a quantitative comparison of different video generation methods on the MagicBench benchmark. Specifically, it focuses on scenarios with one or two moving objects. The comparison uses metrics such as Fréchet Inception Distance (FID), Fréchet Video Distance (FVD), Mask Intersection over Union (Mask IoU), and Box Intersection over Union (Box IoU) to evaluate the generated videos’ quality and accuracy of trajectory control. Lower FID and FVD scores indicate better visual quality, while higher Mask IoU and Box IoU values represent more precise trajectory adherence.
read the caption
Table 5: Quantitative Comparison results on MagicBench with moving objects number equals to 1 / 2.
| Method | MagicBench (Object Number = 3) | MagicBench (Object Number = 4) | ||||||
|---|---|---|---|---|---|---|---|---|
| FID() | FVD() | Mask_IoU() | Box_IoU() | FID() | FVD() | Mask_IoU() | Box_IoU() | |
| Motion-I2V [50] | 168.2760 | 842.6530 | 0.5366 | 0.6076 | 149.3808 | 744.5470 | 0.6018 | 0.6484 |
| ImageConductor [31] | 243.8881 | 927.3884 | 0.5169 | 0.5578 | 221.8339 | 832.4498 | 0.5679 | 0.5417 |
| DragAnything [64] | 144.5718 | 925.2795 | 0.6332 | 0.6625 | 120.3439 | 901.7427 | 0.6946 | 0.7148 |
| LeViTor [55] | 195.1743 | 607.7522 | 0.3809 | 0.4671 | 183.5972 | 688.8164 | 0.3555 | 0.4044 |
| DragNUWA [75] | 145.0172 | 642.4184 | 0.6420 | 0.7012 | 122.8971 | 512.5130 | 0.7085 | 0.7250 |
| SG-I2V [36] | 126.4608 | 520.2733 | 0.6531 | 0.7068 | 97.3747 | 460.1303 | 0.7145 | 0.7423 |
| Tora [78] | 126.4421 | 742.4080 | 0.5926 | 0.6356 | 115.4566 | 779.0798 | 0.6226 | 0.6312 |
| Ours (Stage1) | 89.1128 | 421.0036 | 0.9107 | 0.8797 | 73.5877 | 396.4754 | 0.9231 | 0.8896 |
| Ours (Stage2) | 97.4697 | 440.2373 | 0.7562 | 0.8097 | 77.4146 | 442.0640 | 0.7998 | 0.8253 |
🔼 This table presents a quantitative comparison of different video generation methods on the MagicBench benchmark. Specifically, it focuses on scenarios with 3 or 4 moving objects. The comparison uses metrics such as Fréchet Inception Distance (FID), Fréchet Video Distance (FVD), Mask Intersection over Union (Mask IoU), and Box Intersection over Union (Box IoU) to evaluate the quality and accuracy of video generation and trajectory control.
read the caption
Table 6: Quantitative Comparison results on MagicBench with moving objects number equals to 3 / 4.
| Method | MagicBench (Object Number = 5) | MagicBench (Object Number >5) | ||||||
|---|---|---|---|---|---|---|---|---|
| FID() | FVD() | Mask_IoU() | Box_IoU() | FID() | FVD() | Mask_IoU() | Box_IoU() | |
| Motion-I2V [50] | 148.1927 | 582.0029 | 0.6295 | 0.6267 | 146.4851 | 923.2557 | 0.4899 | 0.4511 |
| ImageConductor [31] | 235.7079 | 857.3489 | 0.5180 | 0.4737 | 215.3864 | 963.6862 | 0.4536 | 0.3442 |
| DragAnything [64] | 120.7039 | 710.5812 | 0.7050 | 0.7011 | 122.6998 | 719.2442 | 0.6534 | 0.6045 |
| LeViTor [55] | 180.9895 | 578.5567 | 0.3913 | 0.4281 | 188.8038 | 763.3157 | 0.2812 | 0.2768 |
| DragNUWA [75] | 130.7921 | 435.9205 | 0.7253 | 0.6988 | 142.0180 | 549.7680 | 0.6638 | 0.5709 |
| SG-I2V [36] | 96.1895 | 453.1147 | 0.7431 | 0.7367 | 103.7038 | 596.4075 | 0.6616 | 0.6211 |
| Tora [78] | 117.2917 | 709.1618 | 0.6228 | 0.6111 | 148.9100 | 907.9254 | 0.4976 | 0.4866 |
| Ours (Stage1) | 76.4964 | 374.6467 | 0.9155 | 0.8600 | 75.8724 | 449.3122 | 0.9012 | 0.7653 |
| Ours (Stage2) | 79.5924 | 350.5010 | 0.8106 | 0.8123 | 75.6016 | 396.0661 | 0.8004 | 0.7124 |
🔼 This table presents a quantitative comparison of different video generation methods on the MagicBench benchmark dataset. Specifically, it focuses on evaluating the performance of these methods when dealing with videos containing 5 or more moving objects. The comparison uses metrics such as FID (Fréchet Inception Distance), FVD (Fréchet Video Distance), Mask IoU (Intersection over Union for masks), and Box IoU (Intersection over Union for bounding boxes), which comprehensively assess both video quality and the accuracy of trajectory control. Lower FID and FVD scores indicate better video quality, while higher Mask IoU and Box IoU scores represent better trajectory accuracy.
read the caption
Table 7: Quantitative Comparison results on MagicBench with moving objects number equals to 5 / above 5.
Full paper#