TL;DR#
Long-Context Transformer Models are vital for real-world applications but suffer high computational costs due to attention’s quadratic complexity, leading to substantial bottlenecks during pre-filling and hindering practical deployment. Existing block-sparse methods grapple with a trade-off between accuracy and efficiency due to the high overhead in determining block importance, rendering them impractical for real-world use. There’s a need for a block-sparse attention mechanism that accelerates long-context Transformers without sacrificing accuracy.
XAttention is introduced as a plug-and-play framework improving the efficiency of block-sparse attention. It identifies non-essential blocks using the sum of antidiagonal values in the attention matrix as a proxy for block importance, which allows for precise pruning, high sparsity, and accelerated inference. Evaluations show accuracy comparable to full attention, delivering computational gains with up to 13.5× acceleration in attention computation. The approach unlocks the potential of block sparse attention for efficient LCTM deployment.
Key Takeaways#
Why does it matter?#
This paper introduces XAttention, a novel technique improving efficiency in long-context Transformers. It offers a practical solution to reduce computational costs, enabling broader applications in AI and opening new research directions for sparse attention mechanisms and efficient model deployment.
Visual Insights#

🔼 XAttention employs a three-step process to optimize attention computation. First, strided antidiagonal scoring sums values within 8x8 blocks of the attention matrix using a stride of 4. Blocks with higher sums (red) are considered more important than those with lower sums (blue). Second, block selection identifies the most important blocks based on their antidiagonal scores. Finally, block sparse attention performs computations only on these selected blocks (red blocks), significantly reducing the computational cost. This figure illustrates the process using a sequence length of 24.
read the caption
Figure 1: Illustration of XAttention: XAttention optimizes attention through a three-step process: (Left) Strided Antidiagonal Scoring: Each block (8×\times×8 in this example) is scored by summing values along its strided antidiagonals (stride = 4), with red lines generally indicating higher summed values and blue lines lower values. (Middle) Block Selection: High-scoring blocks are selected based on these evaluations. (Right) Block Sparse Attention: Attention is computed only on the selected blocks (red blocks on the right), achieving substantial computational savings. This example uses a sequence length of 24.
| Input Len | 4k | 8k | 16k | 32k | 64k | 128k | Avg. |
|---|---|---|---|---|---|---|---|
| Full | 96.74 | 94.03 | 92.02 | 84.17 | 81.32 | 76.89 | 87.52 |
| FlexPrefill | 95.99 | 93.67 | 92.73 | 88.14 | 81.14 | 74.67 | 87.72 |
| MInference | 96.54 | 94.06 | 91.37 | 85.79 | 83.03 | 54.12 | 84.15 |
| SeerAttn | 84.43 | 79.55 | 79.80 | 72.95 | 64.79 | 51.61 | 72.18 |
| Xattn S=8 | 96.83 | 94.07 | 93.17 | 90.75 | 84.08 | 72.31 | 88.47 |
| Xattn S=16 | 96.11 | 93.95 | 93.56 | 90.64 | 83.12 | 71.11 | 88.08 |
🔼 This table presents a comparison of the performance of different attention mechanisms on the RULER benchmark using the Llama-3.1-8B-Instruct language model. It shows the accuracy achieved by several methods (Full Attention, FlexPrefill, MInference, SeerAttn, and XAttention with strides 8 and 16) across various sequence lengths (4k, 8k, 16k, 32k, 64k, and 128k tokens). XAttention uses a novel antidiagonal scoring approach, with the minimum threshold for attention heads precisely predicted via a dynamic programming method. The average accuracy across all sequence lengths is reported for each method, allowing a direct comparison of their performance on long-context tasks. The results demonstrate XAttention’s effectiveness in balancing accuracy and efficiency for long sequence processing.
read the caption
Table 1: Accuracy comparison of different methods on Llama-3.1-8B-Instruct and sequence lengths on RULER. XAttention is configured with Stride S=8𝑆8S=8italic_S = 8 and S=16𝑆16S=16italic_S = 16 with Precisely Predicted Minimum Threshold.
In-depth insights#
Anti-Diag Scoring#
Antidiagonal scoring is presented as a method for importance prediction of attention blocks in sparse attention mechanisms. Instead of typical pooling that can miss crucial vertical or slash patterns, or complex vertical slash detection with high computational overhead, it sums elements along antidiagonals within blocks. This antidiagonal selection ensures consideration of all tokens, as each contributes to at least one antidiagonal sum. It also effectively intersects vertical and slash patterns, enabling their detection for efficient sparse attention. The method aims to balance accuracy and efficiency by providing a lightweight yet effective mechanism for identifying important attention blocks.
Block Sparsity++#
Block sparsity++ represents an evolution in sparse attention mechanisms, likely building upon existing block-sparse methods to achieve improved efficiency and accuracy. It suggests advancements that go beyond simply identifying important blocks, potentially incorporating techniques like adaptive block sizing, dynamic thresholding for block selection, or hierarchical sparsity structures. The ‘++’ implies enhancements that address limitations in previous block sparsity approaches, such as the overhead of block importance measurement or the trade-off between sparsity and representational capacity. A key area of focus might be minimizing computational costs. Further, it suggests improvements over the traditional block sparsity.
LCTM Acceleration#
Long Context Transformer Models (LCTMs) face computational bottlenecks due to attention’s quadratic complexity. Accelerating LCTMs is crucial for real-world applications. Block-sparse attention is a promising avenue, focusing on critical regions to reduce computational burden. However, existing methods struggle with the trade-off between accuracy and efficiency due to costly block importance measurements. XAttention emerges as a novel framework, dramatically accelerating long-context inference using sparse attention. It leverages the insight that antidiagonal values in the attention matrix provide a powerful proxy for block importance, enabling precise identification and pruning of non-essential blocks. This results in high sparsity and accelerated inference. Across various benchmarks, XAttention achieves accuracy comparable to full attention while delivering substantial computational gains, unlocking the practical potential of block-sparse attention for scalable and efficient deployment of LCTMs.
Stride vs. Accuracy#
The consideration of stride size in relation to accuracy is crucial for optimizing the efficiency of sparse attention mechanisms. Larger strides reduce computational overhead by sampling fewer attention map values, but excessively large strides risk compromising accuracy. This is because they may fail to adequately capture essential patterns, leading to performance degradation. Conversely, smaller strides provide more granular sampling, potentially improving accuracy but increasing computational cost. The optimal stride size balances computational efficiency and accuracy. An adequately selected stride is critical to detect the previously identified slash pattern.
Beyond Language#
While the paper’s focus is on improving the efficiency of Long-Context Transformer Models (LCTMs) primarily for language tasks, the implications extend significantly beyond language itself. The techniques developed, such as sparse attention mechanisms and antidiagonal scoring, are fundamentally about optimizing information processing within long sequences. This is crucial for handling the growing complexity of multimodal data. The shift towards processing video, images, and other non-linguistic data alongside text necessitates models capable of capturing long-range dependencies and intricate relationships within these diverse data streams. Sparse attention particularly addresses the computational bottlenecks of handling high-dimensional inputs and long sequences, making it applicable to domains such as genomics, financial time-series analysis, or any field dealing with sequential data where efficient processing and memory usage are paramount. Future research will see these techniques applied to domains far removed from natural language, as the need for efficient long-range dependency modeling continues to grow across all domains.
More visual insights#
More on figures

🔼 The figure illustrates how XAttention’s novel antidiagonal scoring method effectively captures important information within attention blocks. By summing values along antidiagonals (with a specified stride), XAttention identifies blocks containing both vertical and diagonal patterns – crucial indicators of significant relationships between tokens. This method is superior to simple pooling because it directly addresses and avoids missing these key attention patterns, leading to more precise block selection and higher efficiency in sparse attention computation.
read the caption
Figure 2: XAttention’s antidiagonal pattern intersects both vertical and slash patterns within a block, enabling efficient detection of these patterns and guiding effective sparse attention computation.

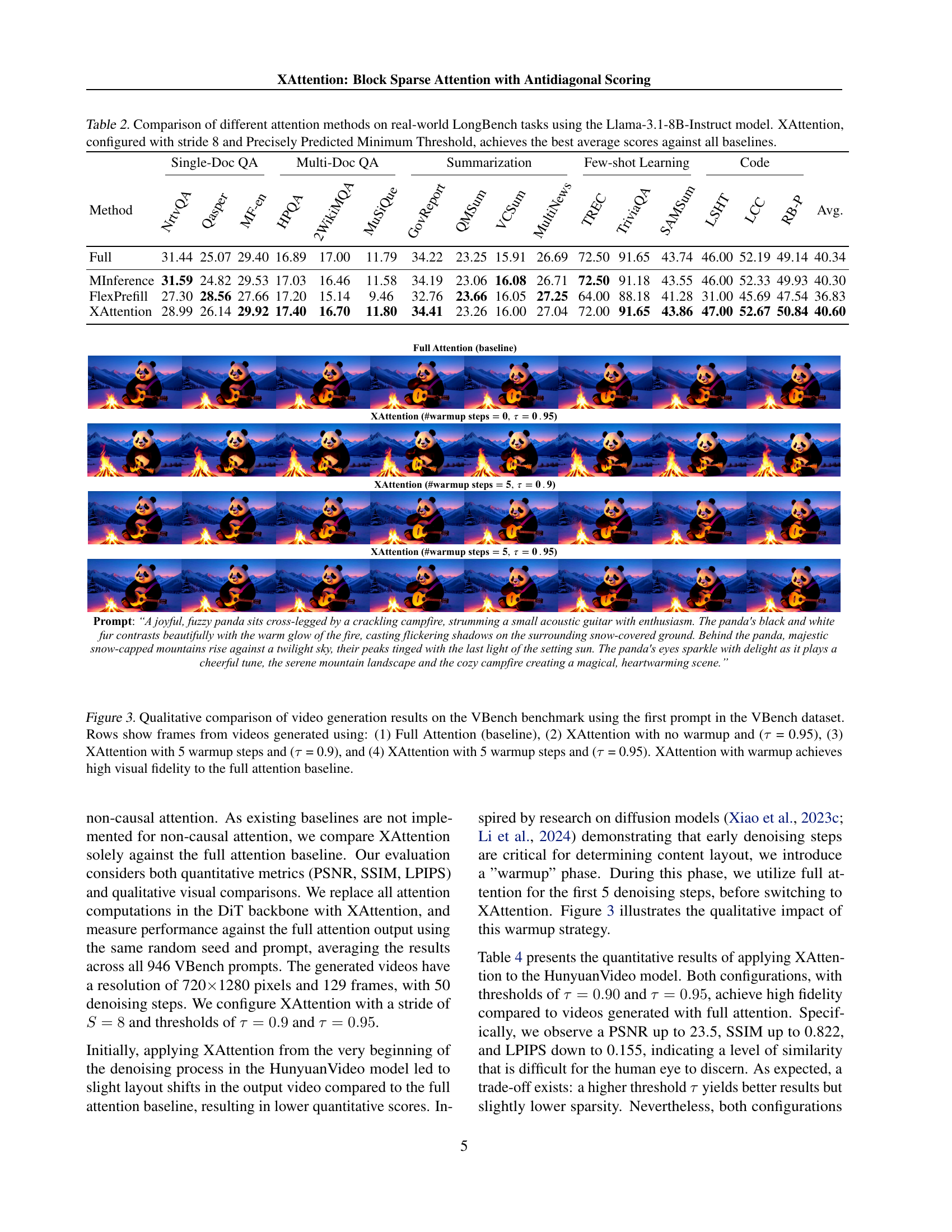
🔼 This figure presents a qualitative comparison of video generation results obtained from four different methods using the first prompt from the VBench dataset. The four methods are: (1) Full Attention (used as a baseline for comparison), (2) XAttention without any warmup period (with τ = 0.95), (3) XAttention with a 5-step warmup period (τ = 0.9), and (4) XAttention with a 5-step warmup period (τ = 0.95). Each row displays selected frames from a video generated by one of the four methods, allowing for a visual comparison of the quality and fidelity of the generated videos. The key takeaway is that XAttention, especially when using a warmup period, generates videos with high visual fidelity, closely matching the quality of those produced using the full attention baseline.
read the caption
Figure 3: Qualitative comparison of video generation results on the VBench benchmark using the first prompt in the VBench dataset. Rows show frames from videos generated using: (1) Full Attention (baseline), (2) XAttention with no warmup and (τ𝜏\tauitalic_τ = 0.95), (3) XAttention with 5 warmup steps and (τ𝜏\tauitalic_τ = 0.9), and (4) XAttention with 5 warmup steps and (τ𝜏\tauitalic_τ = 0.95). XAttention with warmup achieves high visual fidelity to the full attention baseline.

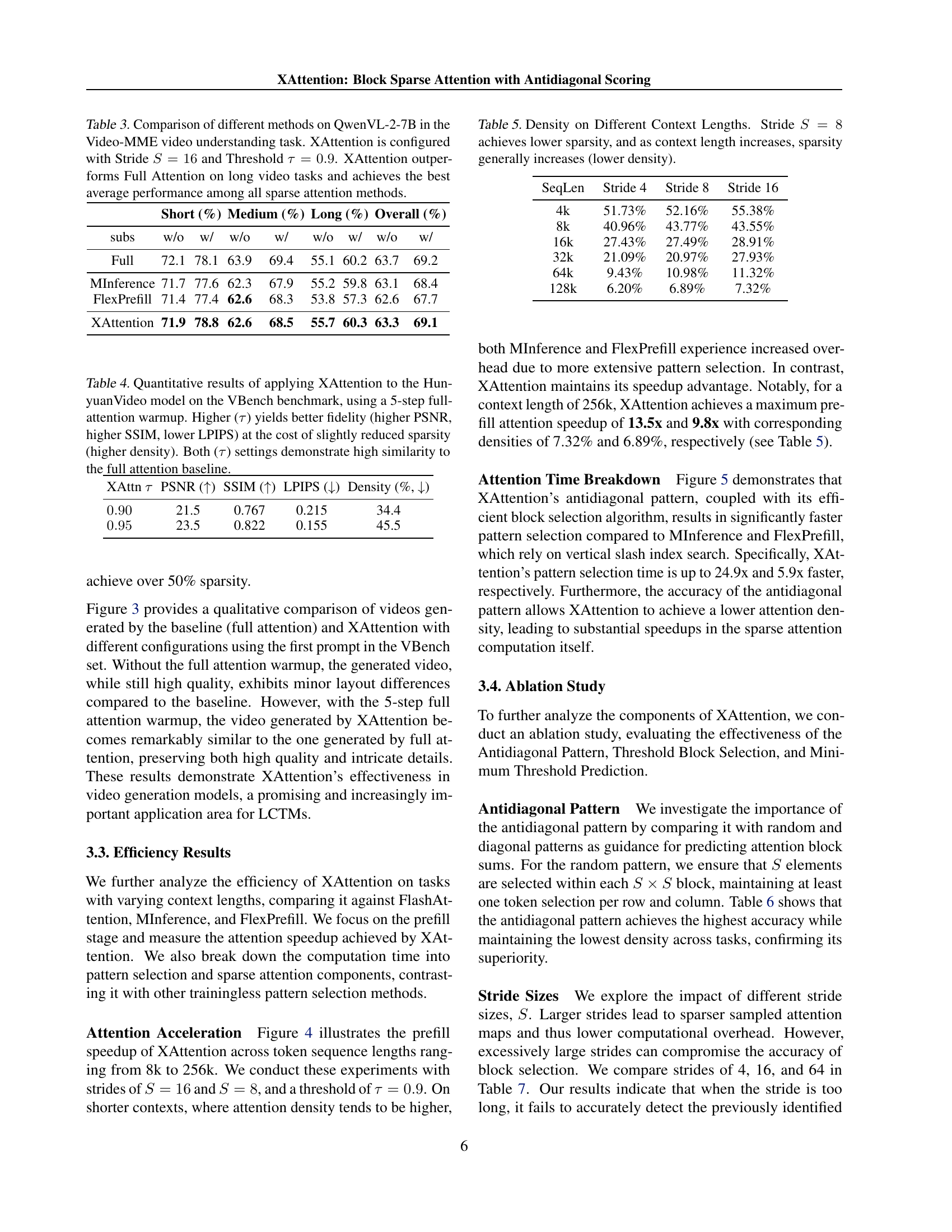
🔼 This figure compares the speedup achieved by various attention mechanisms against FlashAttention (as implemented in FlashInfer) across different context lengths. The x-axis represents the sequence length (in tokens), and the y-axis displays the speedup factor relative to FlashAttention. The results demonstrate that XAttention consistently outperforms other sparse attention methods (MInference, SeerAttention, FlexPrefill), achieving the highest speedup, reaching up to 13.5x at a context length of 256K tokens. This highlights XAttention’s efficiency in handling very long sequences.
read the caption
Figure 4: Speedup comparison of attention methods across context lengths, relative to FlashInfer’s implementation of FlashAttention. XAttention consistently outperforms other sparse attention methods, achieving up to 13.5x speedup at 256K tokens.

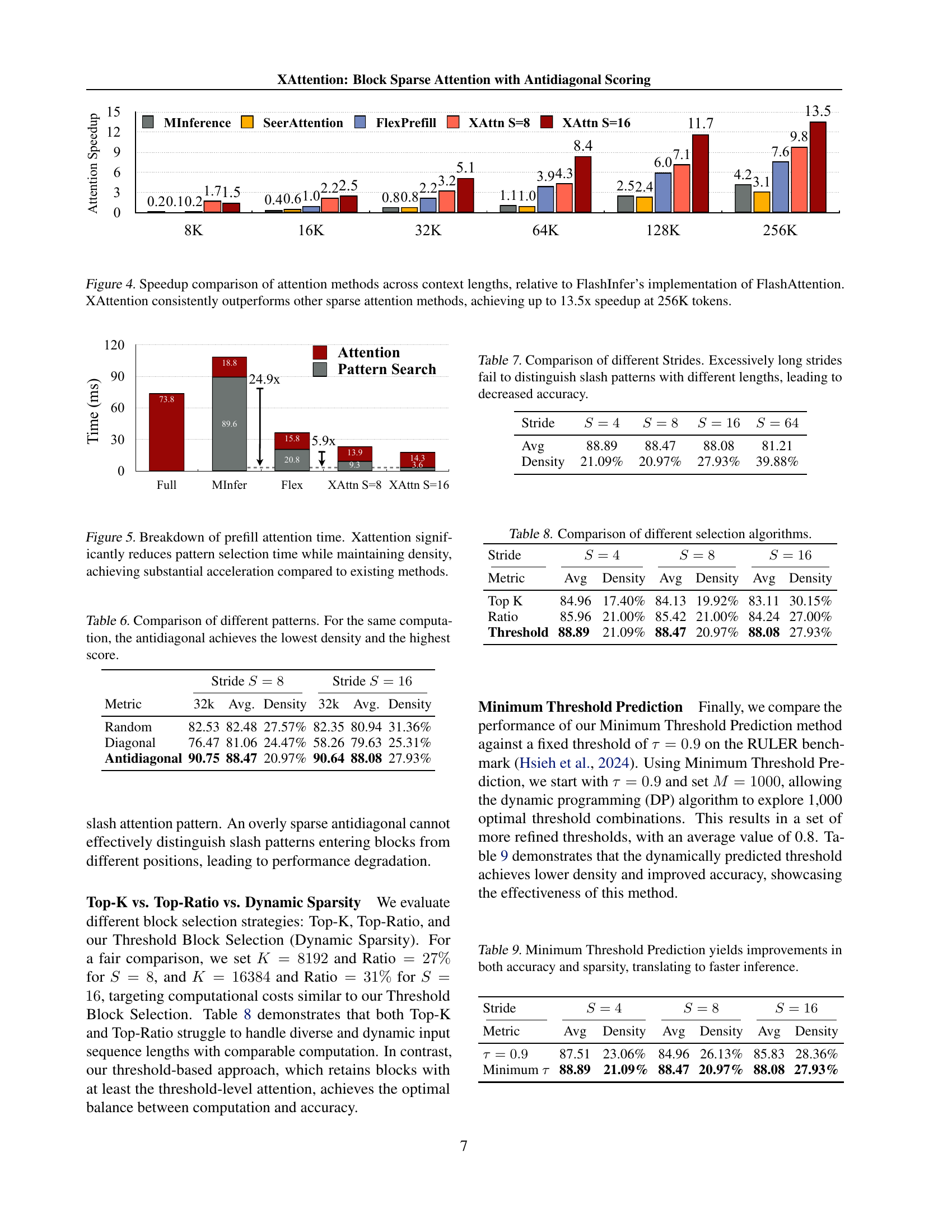
🔼 Figure 5 is a bar chart comparing the time spent on pattern search and attention computation during the prefill stage of different sparse attention methods. XAttention significantly reduces the time required for pattern search while maintaining a similar attention density compared to other methods, resulting in substantial speedup in overall attention computation.
read the caption
Figure 5: Breakdown of prefill attention time. Xattention significantly reduces pattern selection time while maintaining density, achieving substantial acceleration compared to existing methods.
More on tables
| Single-Doc QA | Multi-Doc QA | Summarization | Few-shot Learning | Code | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | NrtvQA | Qasper | MF-en | HPQA | 2WikiMQA | MuSiQue | GovReport | QMSum | VCSum | MultiNews | TREC | TriviaQA | SAMSum | LSHT | LCC | RB-P | Avg. |
| Full | 31.44 | 25.07 | 29.40 | 16.89 | 17.00 | 11.79 | 34.22 | 23.25 | 15.91 | 26.69 | 72.50 | 91.65 | 43.74 | 46.00 | 52.19 | 49.14 | 40.34 |
| MInference | 31.59 | 24.82 | 29.53 | 17.03 | 16.46 | 11.58 | 34.19 | 23.06 | 16.08 | 26.71 | 72.50 | 91.18 | 43.55 | 46.00 | 52.33 | 49.93 | 40.30 |
| FlexPrefill | 27.30 | 28.56 | 27.66 | 17.20 | 15.14 | 9.46 | 32.76 | 23.66 | 16.05 | 27.25 | 64.00 | 88.18 | 41.28 | 31.00 | 45.69 | 47.54 | 36.83 |
| XAttention | 28.99 | 26.14 | 29.92 | 17.40 | 16.70 | 11.80 | 34.41 | 23.26 | 16.00 | 27.04 | 72.00 | 91.65 | 43.86 | 47.00 | 52.67 | 50.84 | 40.60 |
🔼 This table presents a comparison of the performance of several attention mechanisms on various real-world tasks within the LongBench benchmark. The benchmark utilizes the Llama-3.1-8B-Instruct language model. The attention methods compared include XAttention (the proposed method), FlashAttention (a baseline for dense attention), MInference, FlexPrefill, and SeerAttention (other existing block-sparse methods). The results showcase XAttention’s superior performance in terms of accuracy across different LongBench tasks, particularly when employing stride 8 and a precisely predicted minimum threshold. The table details the performance (scores) achieved by each method on individual LongBench tasks (single-document QA, multi-document QA, 2WikiMQA, MuSiQue, GovReport, QMSum, VCSum, MultiNews, TREC, few-shot learning, TriviaQA, SAMSum, LSHT, LCC, RB-P, and Code), thus offering a comprehensive comparison across diverse and complex long-context natural language understanding scenarios.
read the caption
Table 2: Comparison of different attention methods on real-world LongBench tasks using the Llama-3.1-8B-Instruct model. XAttention, configured with stride 8 and Precisely Predicted Minimum Threshold, achieves the best average scores against all baselines.
| Short (%) | Medium (%) | Long (%) | Overall (%) | |||||
|---|---|---|---|---|---|---|---|---|
| subs | w/o | w/ | w/o | w/ | w/o | w/ | w/o | w/ |
| Full | 72.1 | 78.1 | 63.9 | 69.4 | 55.1 | 60.2 | 63.7 | 69.2 |
| MInference | 71.7 | 77.6 | 62.3 | 67.9 | 55.2 | 59.8 | 63.1 | 68.4 |
| FlexPrefill | 71.4 | 77.4 | 62.6 | 68.3 | 53.8 | 57.3 | 62.6 | 67.7 |
| XAttention | 71.9 | 78.8 | 62.6 | 68.5 | 55.7 | 60.3 | 63.3 | 69.1 |
🔼 Table 3 presents a comparison of different attention mechanisms on the QwenVL-2-7B model for the video understanding task within the Video-MME dataset. Specifically, it compares the performance of Full Attention (the baseline), XAttention (using a stride of 16 and a threshold of 0.9), MInference, and FlexPrefill across three video lengths: short, medium, and long. The results show XAttention’s performance relative to the baseline and other sparse attention methods. The table highlights XAttention’s superior performance on long videos and its overall best average performance among the sparse attention methods.
read the caption
Table 3: Comparison of different methods on QwenVL-2-7B in the Video-MME video understanding task. XAttention is configured with Stride S=16𝑆16S=16italic_S = 16 and Threshold τ=0.9𝜏0.9\tau=0.9italic_τ = 0.9. XAttention outperforms Full Attention on long video tasks and achieves the best average performance among all sparse attention methods.
| XAttn | PSNR () | SSIM () | LPIPS () | Density (%, ) |
|---|---|---|---|---|
| 21.5 | 0.767 | 0.215 | 34.4 | |
| 23.5 | 0.822 | 0.155 | 45.5 |
🔼 This table presents a quantitative evaluation of XAttention’s performance on the HunyuanVideo model for video generation. The experiment uses the VBench benchmark and incorporates a 5-step full-attention warmup phase. The results show the Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), and density for two different threshold settings (τ). Higher τ values lead to better video quality (higher PSNR and SSIM, lower LPIPS) but at the cost of slightly lower sparsity (higher density). Both τ settings show comparable results to the full-attention baseline, indicating that XAttention maintains good performance with significant computational savings.
read the caption
Table 4: Quantitative results of applying XAttention to the HunyuanVideo model on the VBench benchmark, using a 5-step full-attention warmup. Higher (τ𝜏\tauitalic_τ) yields better fidelity (higher PSNR, higher SSIM, lower LPIPS) at the cost of slightly reduced sparsity (higher density). Both (τ𝜏\tauitalic_τ) settings demonstrate high similarity to the full attention baseline.
| SeqLen | Stride 4 | Stride 8 | Stride 16 |
|---|---|---|---|
| 4k | 51.73% | 52.16% | 55.38% |
| 8k | 40.96% | 43.77% | 43.55% |
| 16k | 27.43% | 27.49% | 28.91% |
| 32k | 21.09% | 20.97% | 27.93% |
| 64k | 9.43% | 10.98% | 11.32% |
| 128k | 6.20% | 6.89% | 7.32% |
🔼 This table presents the density of the attention mechanism across various context lengths (4k, 8k, 16k, 32k, 64k, 128k tokens) using a stride of 8. Density refers to the proportion of attention computation performed, with lower density implying higher sparsity. The results show that using a stride of 8 leads to lower sparsity (more computation) compared to strides of 4 or 16. Furthermore, as the context length increases, the density of the attention decreases, demonstrating that the method achieves greater sparsity with longer sequences.
read the caption
Table 5: Density on Different Context Lengths. Stride S=8𝑆8S=8italic_S = 8 achieves lower sparsity, and as context length increases, sparsity generally increases (lower density).
| Stride | Stride | |||||
|---|---|---|---|---|---|---|
| Metric | 32k | Avg. | Density | 32k | Avg. | Density |
| Random | 82.53 | 82.48 | 27.57% | 82.35 | 80.94 | 31.36% |
| Diagonal | 76.47 | 81.06 | 24.47% | 58.26 | 79.63 | 25.31% |
| Antidiagonal | 90.75 | 88.47 | 20.97% | 90.64 | 88.08 | 27.93% |
🔼 Table 6 presents an ablation study comparing three different patterns used for predicting attention block importance in the XAttention model: random, diagonal, and antidiagonal. The study measures the average accuracy and density (sparsity) achieved by each pattern while maintaining the same computational cost. The results demonstrate that the antidiagonal pattern outperforms random and diagonal patterns, achieving both the highest accuracy and the lowest density, which translates to superior efficiency without compromising performance.
read the caption
Table 6: Comparison of different patterns. For the same computation, the antidiagonal achieves the lowest density and the highest score.
| Stride | ||||
|---|---|---|---|---|
| Avg | 88.89 | 88.47 | 88.08 | 81.21 |
| Density | 21.09% | 20.97% | 27.93% | 39.88% |
🔼 This table presents an ablation study on the impact of different stride sizes (S) used in the XAttention algorithm on the accuracy of identifying important attention blocks. The results show that using excessively large strides negatively affects the ability to differentiate slash patterns of varying lengths, ultimately leading to decreased overall accuracy. In essence, it explores the trade-off between computational efficiency (larger strides mean less computation) and the accuracy of identifying important attention blocks.
read the caption
Table 7: Comparison of different Strides. Excessively long strides fail to distinguish slash patterns with different lengths, leading to decreased accuracy.
| Stride | ||||||
|---|---|---|---|---|---|---|
| Metric | Avg | Density | Avg | Density | Avg | Density |
| Top K | 84.96 | 17.40% | 84.13 | 19.92% | 83.11 | 30.15% |
| Ratio | 85.96 | 21.00% | 85.42 | 21.00% | 84.24 | 27.00% |
| Threshold | 88.89 | 21.09% | 88.47 | 20.97% | 88.08 | 27.93% |
🔼 This table compares three different block selection algorithms used in XAttention for sparse attention computation: Top-K, Top-Ratio, and the proposed Threshold-based selection (Dynamic Sparsity). It shows the average density and performance (accuracy) of each method across various stride sizes (4, 8, and 16), which determine the sparsity level. The goal is to find the optimal balance between computational efficiency and accuracy in identifying important attention blocks.
read the caption
Table 8: Comparison of different selection algorithms.
| Stride | ||||||
|---|---|---|---|---|---|---|
| Metric | Avg | Density | Avg | Density | Avg | Density |
| 87.51 | 23.06% | 84.96 | 26.13% | 85.83 | 28.36% | |
| Minimum | 88.89 | 21.09% | 88.47 | 20.97% | 88.08 | 27.93% |
🔼 Table 9 presents a comparison of results obtained using a fixed threshold (T=0.9) versus a dynamically predicted minimum threshold for attention mechanism in the XAttention model. It demonstrates how the dynamic threshold method enhances both the accuracy of the model and its sparsity (resulting in lower density and faster inference) across different stride sizes (S=4, 8, 16). The table highlights the improved efficiency and accuracy achieved by using the dynamic programming approach for threshold prediction.
read the caption
Table 9: Minimum Threshold Prediction yields improvements in both accuracy and sparsity, translating to faster inference.
Full paper#