TL;DR#
Precisely evaluating semantic alignment between text prompts and generated videos remains a challenge in Text-to-Video (T2V) Generation. Existing text-to-video alignment metrics generate coarse-grained scores without fine-grained details, failing to align with human preference. To address this limitation, this paper introduces a novel Evaluation method of Text-to-Video Alignment via fine-grained question generation and answering. First, a multi-agent system parses prompts into semantic scene graphs to generate atomic questions. Then we design a knowledge-augmented multi-stage reasoning framework for question answering.
This paper proposes ETVA, a novel Evaluation method of Text-to-Video Alignment that contains a multi-agent framework for atomic question generation and a knowledge-augmented multi-stage reasoning framework to emulate human-like reasoning in question answering. The QG part of ETVA consists of three collaborative agents. Based on ETVA, they further construct ETVA-Bench, a comprehensive benchmark for text-to-video alignment evaluation. Our findings reveal that these models still struggle in some areas such as camera movements or physics process.
Key Takeaways#
Why does it matter?#
This paper introduces a novel evaluation metric and benchmark that addresses the limitations of existing methods for assessing text-to-video alignment. By providing a more fine-grained and human-aligned evaluation approach, this research can help researchers to better understand and improve T2V generation models. The proposed method opens avenues for developing models that more accurately capture the nuances of text prompts and generate videos that align with human expectations, ultimately advancing the field and potentially leading to more sophisticated T2V applications.
Visual Insights#

🔼 This figure demonstrates the workflow of ETVA (Evaluation of Text-to-Video Alignment) and compares its performance to existing text-to-video alignment metrics. The top half shows a text prompt describing a scene, along with two example videos generated by a text-to-video model. The bottom half displays how existing metrics (BLIP-BLEU, CLIPScore, VideoScore) evaluate these videos, showing that they don’t align well with human preferences. In contrast, ETVA’s approach is presented: It generates fine-grained questions about specific aspects of the video (e.g., ‘Is there a cup?’, ‘Is the water pouring out?’) and uses a multi-stage reasoning mechanism, including common-sense knowledge, to determine whether these questions are correctly answered by the video, ultimately leading to an alignment score. ETVA shows significantly better alignment with human judgment compared to existing methods.
read the caption
Figure 1: Illustration of how ETVA works and comparison with existing metrics.
| Metric | Existence | Action | Material | Spatial | Number | Shape | Color | Camera | Physics | Other | Overall |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BLIP-ROUGE [33] | 6.0/8.4 | 6.5/8.9 | 3.0/5.3 | 9.2/12.6 | 11.0/15.5 | 9.3/14.7 | -4.7/-5.2 | 3.3/4.9 | 5.9/8.8 | 5.3/7.1 | 6.3/8.8 |
| BLIP-BLEU [33] | 9.3/12.9 | 8.4/11.6 | 6.2/10.1 | 11.2/15.4 | 10.0/13.6 | 9.2/12.7 | 6.6/10.5 | 10.3/14.7 | 10.1/14.4 | 8.6/11.4 | 8.5/12.1 |
| CLIPScore [42] | 10.2/13.7 | 10.6/13.6 | 9.9/12.8 | 12.2/16.1 | 10.9/14.8 | 14.6/20.8 | 11.8/18.8 | 12.9/15.2 | 9.7/14.2 | 10.2/12.9 | 10.3/13.8 |
| UMTScore [22] | 17.9/24.0 | 14.3/19.0 | 25.4/34.4 | 21.6/28.2 | 9.1/13.5 | 24.4/32.1 | 22.5/31.1 | 22.2/29.0 | 18.4/23.2 | 15.5/20.6 | 17.6/23.5 |
| ViCLIPScore [56] | 20.2/27.1 | 17.9/24.2 | 16.2/20.4 | 20.6/27.2 | 16.9/22.4 | 29.4/38.4 | 13.8/13.5 | 23.6/31.8 | 19.8/26.3 | 17.0/22.7 | 19.4/25.9 |
| VideoScore [12] | 23.2/30.6 | 22.7/30.2 | 29.9/37.3 | 24.8/31.7 | 26.6/35.9 | 28.1/35.7 | 11.7/16.2 | 19.2/26.3 | 20.3/23.9 | 23.9/31.6 | 23.7/31.0 |
| ETVA | 47.7/57.4 | 38.3/46.6 | 55.5/66.1 | 56.0/66.8 | 44.0/53.9 | 64.1/75.1 | 31.5/39.7 | 35.5/44.2 | 50.6/60.4 | 49.0/59.2 | 47.2/58.5 |
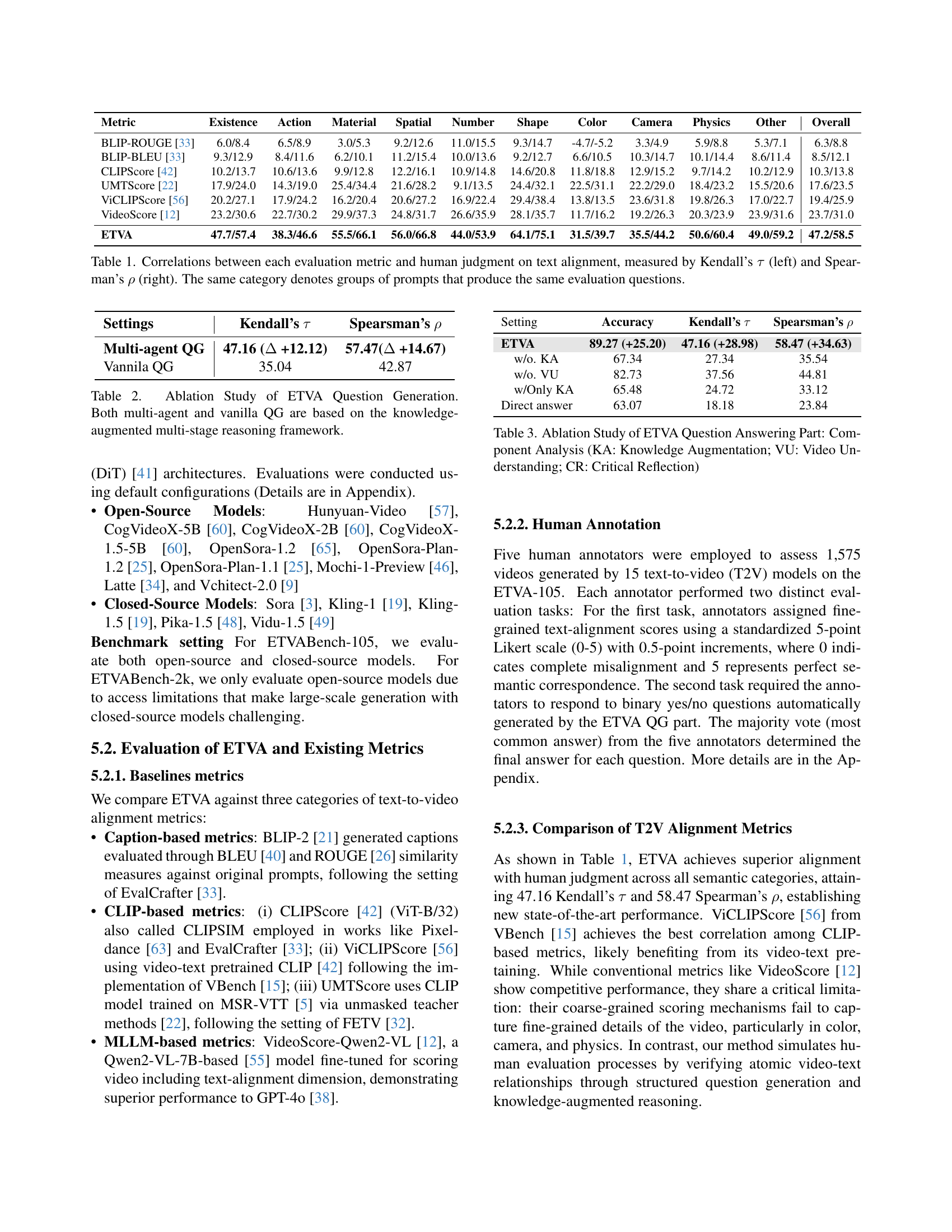
🔼 Table 1 presents the correlation analysis between automatic text-to-video alignment metrics and human judgment. It shows Kendall’s tau (τ) and Spearman’s rho (ρ) correlation coefficients, indicating the strength and direction of the relationship between each metric’s scores and human ratings of alignment quality. The table is broken down by 10 categories of prompts, grouping together prompts that generated the same evaluation questions to ensure a fair comparison. Higher values represent stronger positive correlations. This helps assess how well each metric aligns with human perception of alignment.
read the caption
Table 1: Correlations between each evaluation metric and human judgment on text alignment, measured by Kendall’s τ𝜏\tauitalic_τ (left) and Spearman’s ρ𝜌\rhoitalic_ρ (right). The same category denotes groups of prompts that produce the same evaluation questions.
In-depth insights#
T2V Alignment#
The paper addresses the crucial challenge of evaluating the semantic alignment between text prompts and generated videos in Text-to-Video (T2V) generation. Existing metrics, like CLIPScore, are deemed insufficient as they offer only coarse-grained scores, failing to capture fine-grained alignment details and often diverging from human preference. To overcome these limitations, the paper introduces ETVA, a novel evaluation method centered around fine-grained question generation and answering. This innovative approach hinges on a multi-agent system that parses prompts into semantic scene graphs, enabling the generation of atomic questions. A knowledge-augmented multi-stage reasoning framework is designed for question answering, utilizing an auxiliary LLM to retrieve relevant common-sense knowledge, coupled with a video LLM for answering questions through a multi-stage process. The paper includes a new benchmark specifically for text-to-video alignment evaluation, featuring diverse prompts and atomic questions. Through a comprehensive evaluation of existing T2V models, the research identifies their key capabilities and limitations, paving the way for next-generation T2V generation. ETVA demonstrates a higher correlation with human judgment compared to existing metrics, marking a significant advancement in T2V evaluation.
ETVA Framework#
The ETVA framework is a novel approach designed for evaluating the semantic alignment between text prompts and generated videos, a significant challenge in the field of Text-to-Video (T2V) generation. Existing metrics often fall short, ETVA leverages a multi-agent system to parse prompts into semantic scene graphs and generate atomic questions, enabling fine-grained alignment analysis. A knowledge-augmented multi-stage reasoning framework, incorporates auxiliary LLMs for commonsense knowledge retrieval, further enhancing question answering accuracy by video LLMs. ETVA’s architecture focuses on generating detailed questions and emulating human-like reasoning, mitigating hallucinations and improving alignment with human preferences. ETVA is a crucial step towards reliable evaluation, addressing existing metrics’ limitations.
Benchmarking T2V#
Benchmarking Text-to-Video (T2V) generation is crucial for assessing model capabilities, identifying limitations, and driving progress in the field. Current benchmarks are categorized into general benchmarks evaluating overall performance (quality, consistency, aesthetics) and specific benchmarks focusing on particular aspects (human actions, multi-object composition, physics phenomenon, time-lapse video). General benchmarks often lack fine-grained detail, while specific benchmarks offer in-depth analysis of narrow aspects. A comprehensive benchmark should ideally encompass diverse prompts, atomic questions, and evaluation across various semantic categories (existence, action, material, spatial, number, shape, color, camera, physics, other). Developing reliable automatic metrics for T2V alignment is essential, as existing metrics often produce coarse-grained scores and fail to align with human preference. Benchmarking requires careful consideration of question generation and answering strategies, along with human annotation for accurate evaluation. Constructing structured scene graph for atomic element is important for achieving overall efficiency.
Atomic Question#
Atomic questions play a crucial role in enhancing the granularity and accuracy of text-to-video alignment evaluation. By breaking down complex prompts into smaller, more manageable questions, the evaluation focuses on assessing specific details within the generated video, addressing limitations of metrics like CLIPScore that offer coarse-grained scores failing to capture fine-grained nuances. This approach ensures a deeper understanding of the video’s content and its alignment with the original text prompt. These atomic questions systematically verify various aspects of the video, reducing semantic redundancy, ensuring complete coverage, and generating answerable queries for video LLMs. This strategy aids in overcoming issues such as video LLM hallucination, where the model might struggle with complex or ambiguous questions, and allows for a more precise and human-aligned assessment.
Hallucination#
Hallucination in text-to-video generation is a significant issue, where models generate content inconsistent with the input prompt. This paper addresses this challenge by focusing on improving the alignment between the text prompt and the generated video content. The core problem is that existing metrics often fail to capture fine-grained alignment details, leading to discrepancies between automated evaluations and human preferences. To mitigate this, the authors introduce a novel evaluation method called ETVA, which employs a multi-agent system for atomic question generation and a knowledge-augmented multi-stage reasoning framework for question answering. This approach aims to simulate human-like reasoning to better assess the semantic alignment between text and video. The key contribution lies in the fine-grained analysis facilitated by generating detailed questions covering various aspects of the video content, ensuring a more comprehensive evaluation than coarse-grained metrics like CLIPScore. By incorporating commonsense knowledge and multi-stage reasoning, ETVA effectively reduces hallucinations and improves the reliability of text-to-video alignment evaluation. Extensive experiments validate the effectiveness of ETVA, demonstrating superior correlation with human judgment compared to existing evaluation metrics. Furthermore, the paper introduces ETVABench, a comprehensive benchmark for text-to-video alignment evaluation, facilitating systematic comparison and analysis of different T2V models. The study highlights the limitations of current models in accurately simulating real-world physics and camera movements, paving the way for future research to address these specific challenges and enhance the overall quality and coherence of generated videos.
More visual insights#
More on figures

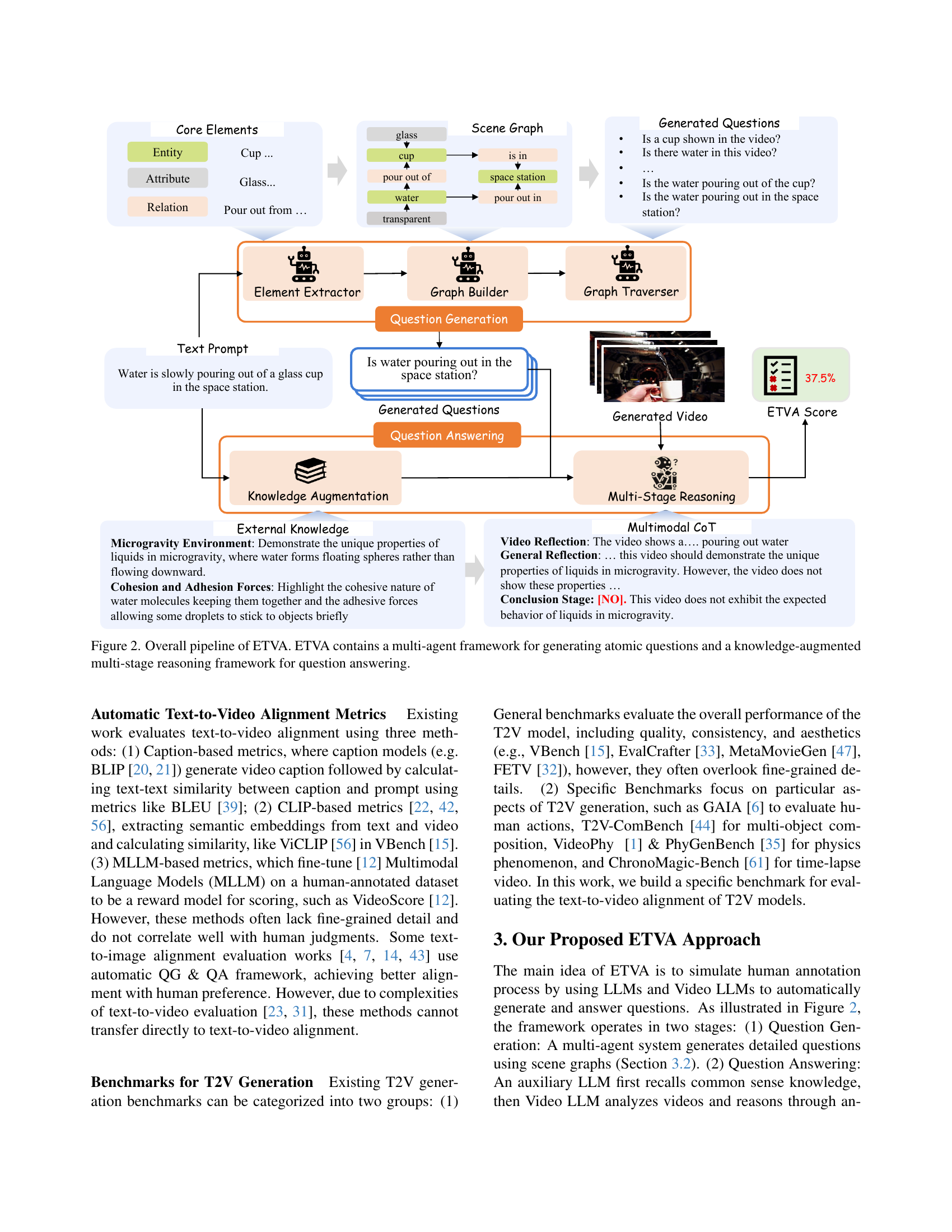
🔼 The figure illustrates the overall architecture of the ETVA (Evaluation of Text-to-Video Alignment) model. ETVA uses a two-stage process. The first stage involves a multi-agent system for question generation which takes a text prompt as input. This system parses the prompt into a scene graph, representing entities, attributes, and relationships. Then, a graph traverser systematically traverses this scene graph to generate atomic (fine-grained) yes/no questions. The second stage consists of a knowledge-augmented multi-stage reasoning framework for question answering. Here, an auxiliary LLM provides common sense knowledge that is combined with the video content and the generated questions. The video LLM then answers the questions through a step-by-step reasoning process that involves video understanding, general reflection, and a final conclusion. The final ETVA score is computed based on the combined answers to all the questions.
read the caption
Figure 2: Overall pipeline of ETVA. ETVA contains a multi-agent framework for generating atomic questions and a knowledge-augmented multi-stage reasoning framework for question answering.

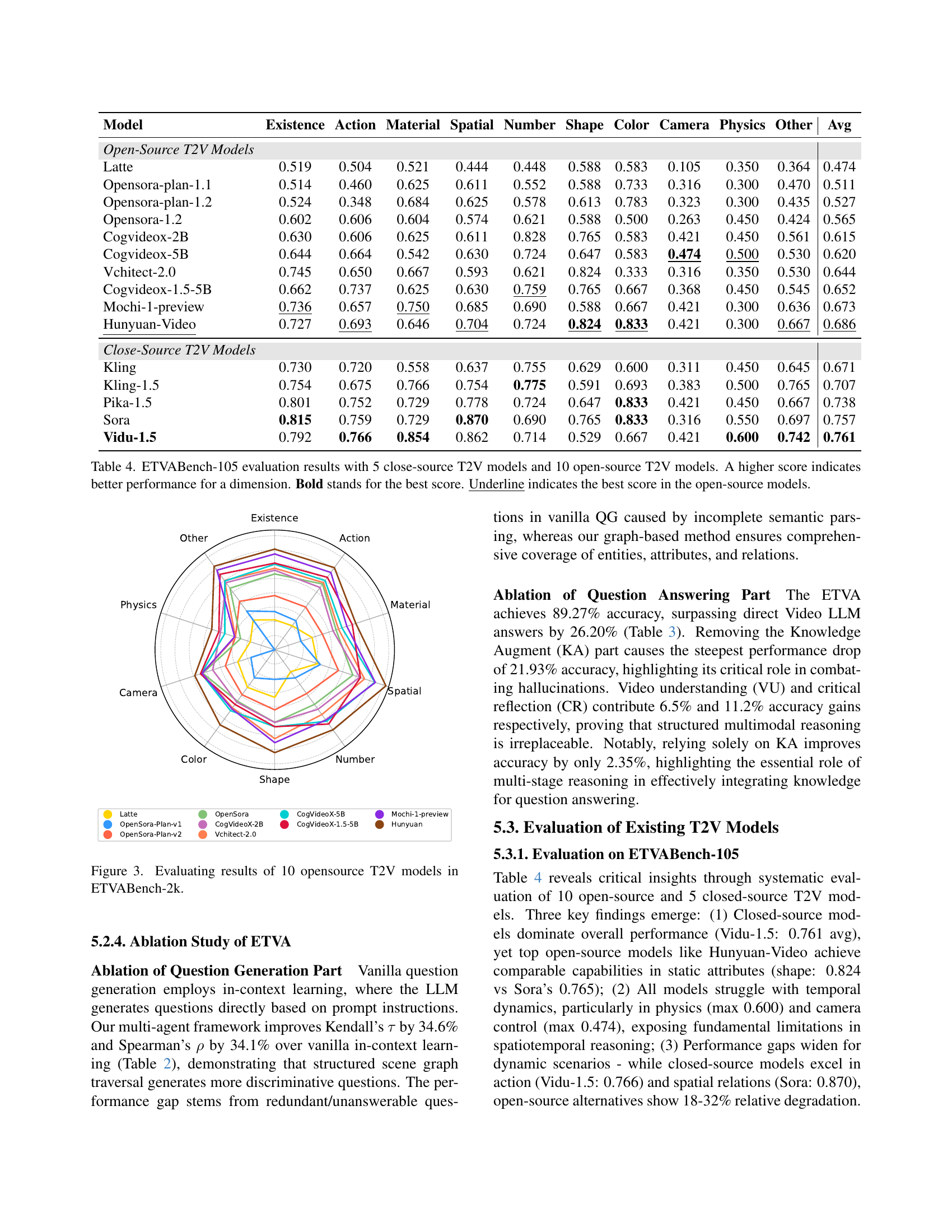
🔼 This radar chart visualizes the performance of ten open-source text-to-video (T2V) models across ten different categories within the ETVABench-2k benchmark. Each category represents a specific aspect of video generation, such as the presence of objects, actions, materials, spatial relationships, numbers, shapes, colors, camera angles, physics, and other miscellaneous elements. The chart allows for a direct comparison of the models’ capabilities in each category, revealing their strengths and weaknesses in various video generation aspects. A higher score indicates better performance for a dimension.
read the caption
Figure 3: Evaluating results of 10 opensource T2V models in ETVABench-2k.

🔼 This figure showcases four examples that illustrate how ETVA evaluates text-to-video alignment. Each example highlights a different aspect of the alignment challenge: (1) Physics phenomenon: accurately modeling the behavior of liquids in microgravity; (2) Color transition: smoothly changing the color of an object across a video; (3) Number accuracy: correctly representing the count of objects in the video; and (4) Gestural semantic: correctly interpreting and rendering human actions and gestures. The figure directly compares the results from different text-to-video (T2V) models using ETVA, showing how the models perform in each of these four alignment categories.
read the caption
Figure 4: Four Cases of using ETVA to evaluate text-to-video alignment in T2V models, covering physics phenomenon, color transition, number accuracy and gestrual semnatic.

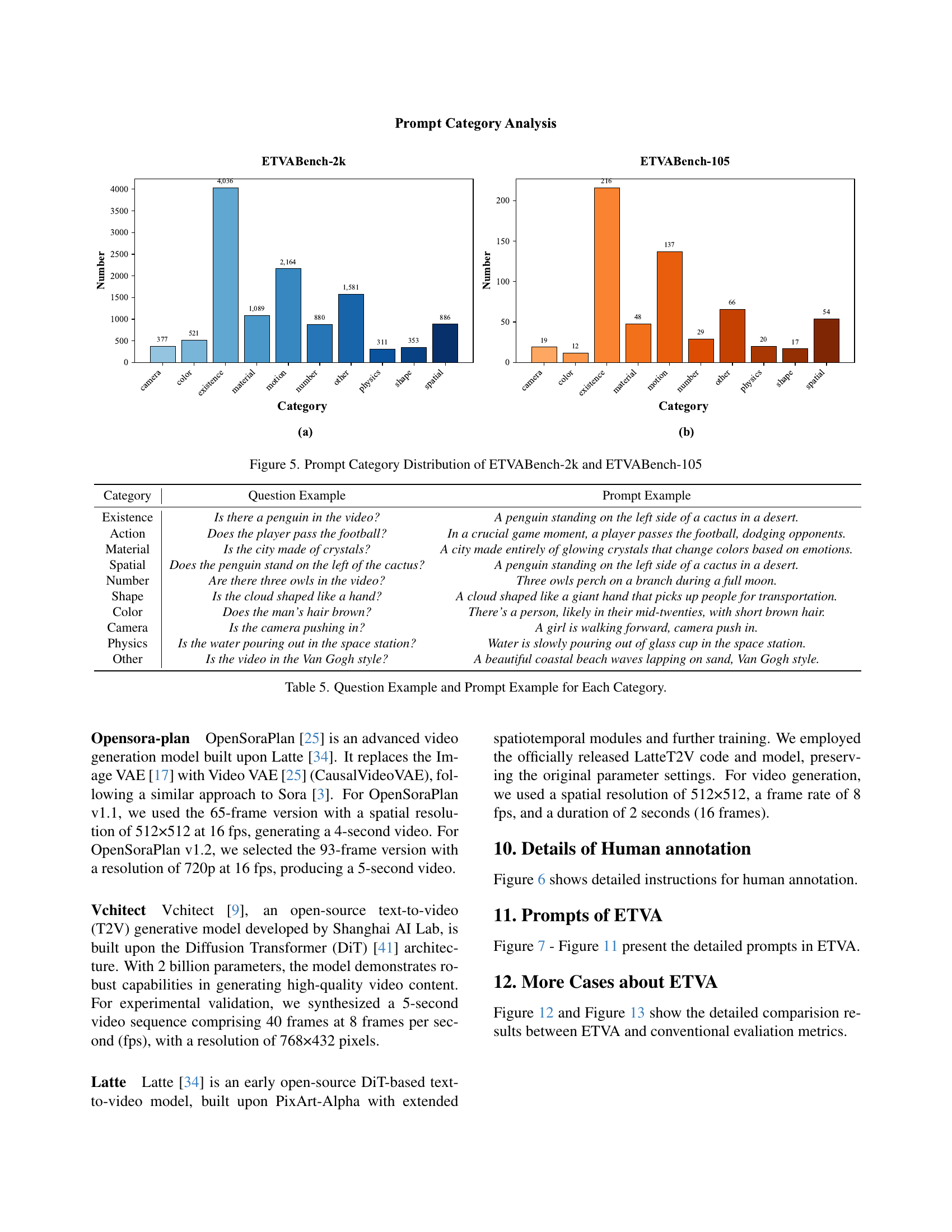
🔼 This figure shows a comparison of the prompt category distributions for two benchmark datasets: ETVABench-2k and ETVABench-105. Both datasets are used to evaluate text-to-video alignment models. The figure visually represents the number of prompts belonging to each of the ten defined categories in both datasets. This allows for a comparison of the relative frequency of each prompt type across the two benchmark versions.
read the caption
Figure 5: Prompt Category Distribution of ETVABench-2k and ETVABench-105

🔼 This figure provides detailed instructions for human annotators evaluating the alignment between text prompts and generated videos. It outlines the scoring process for assessing semantic consistency, emphasizing that the evaluation should focus solely on the semantic match between text and video, ignoring factors like video quality, resolution, or visual clarity. It also explains the process of evaluating specific binary yes/no questions derived from the text descriptions to assess whether the generated videos correctly answer them.
read the caption
Figure 6: Instruction for Human Annotation

🔼 This figure shows the prompt used for the Element Extractor, one of the three agents in the multi-agent question generation framework of ETVA. The prompt instructs the Element Extractor to meticulously analyze the input prompts and extract background information, camera information, entities, attributes, and relationships. It provides a detailed explanation of how each of these data elements should be formatted before being processed by the following agents.
read the caption
Figure 7: Prompt for Element Extractor.

🔼 This figure shows the prompt used to instruct the Graph Builder agent within the ETVA framework. The Graph Builder agent takes the extracted entities, attributes, and relations from the text prompt as input and constructs a hierarchical scene graph. This graph represents the relationships between elements in the prompt, creating a structured knowledge representation for question generation. The prompt emphasizes the need for a coherent, hierarchical graph that accurately reflects the semantics of the input, ensuring that all mappings between elements are accurate and contextually relevant.
read the caption
Figure 8: Prompt for Graph Builder.

🔼 This figure details the prompt instructions given to the Graph Traverser agent within the ETVA framework. The Graph Traverser is responsible for generating atomic yes/no questions from the structured scene graph created by previous agents in the system. The prompt provides examples of different question types (content, attribute, relation) and illustrates how the input, question type, and specific content should be formatted. This ensures consistency and facilitates the generation of comprehensive and relevant video evaluation questions.
read the caption
Figure 9: Prompt for Graph Traverser.

🔼 This figure displays the prompt used for the Knowledge Augmentation module within the ETVA framework. The prompt instructs an LLM to identify implicit knowledge—common sense or relevant physical principles—not explicitly stated in a video’s text prompt but necessary for generating a realistic video. The prompt provides three examples to illustrate how to extract and express this implicit knowledge, focusing on providing detailed descriptions to enrich video understanding.
read the caption
Figure 10: Prompt for Knowledge Augmentation.

🔼 This figure shows the prompt used for the Multi-stage Reasoning stage of the ETVA framework. The prompt instructs a multimodal assistant to answer a video-related question by engaging in a three-stage process: Video Understanding, Critical Reflection, and Conclusion. The assistant has access to the textual prompt used to generate the video, additional common-sense knowledge, and the video itself. The prompt guides the assistant to analyze how well the video matches both the text and the common sense, identify discrepancies or gaps, and then provide a yes/no answer with a brief justification.
read the caption
Figure 11: Prompt for Multi-stage Reasoning.

🔼 This figure compares the performance of ETVA (a novel text-to-video alignment evaluation metric) against three existing metrics: BLIP-BLEU, CLIPScore, and VideoScore. The comparison is based on a specific text prompt: ‘Water is slowly pouring out of glass cup in the space station.’ For each metric, the scores for two generated videos are shown. The figure visually demonstrates how ETVA’s fine-grained assessment differs from the coarser-grained scores of the conventional methods, ultimately better reflecting human preferences regarding video-text alignment.
read the caption
Figure 12: Illustration of a comparative analysis between ETVA and conventional evaluation metrics, based on the text prompt: “Water is slowly pouring out of glass cup in the space station”. We compare our ETVA score with conventional text-to-video alignment metrics.

🔼 Figure 13 presents a comparative analysis of ETVA and conventional evaluation metrics for a specific text prompt: ‘A leaf turns from green to red.’ It shows the generated videos from various models, alongside their scores from metrics like BLIP-BLEU, CLIPScore, VideoScore, and ETVA. This visual comparison allows for a direct assessment of how well each method aligns with human perception of text-to-video alignment quality. The figure highlights ETVA’s ability to more accurately capture the nuanced aspects of semantic correspondence than traditional metrics, which often provide only coarse-grained evaluations.
read the caption
Figure 13: Illustration of a comparative analysis between ETVA and conventional evaluation metrics, based on the text prompt: ”A leaf turns from green to red”. We compare our ETVA score with conventional text-to-video alignment metrics.
More on tables
| Settings | Kendall’s | Spearsman’s |
|---|---|---|
| Multi-agent QG | 47.16 ( +12.12) | 57.47( +14.67) |
| Vannila QG | 35.04 | 42.87 |
🔼 This ablation study investigates the impact of different question generation methods within the ETVA framework. Specifically, it compares the performance of a multi-agent question generation (QG) approach against a simpler vanilla QG approach. Both methods utilize the same knowledge-augmented multi-stage reasoning framework for question answering; only the question generation process differs. The results show the improvement achieved by the multi-agent QG in terms of Kendall’s τ and Spearman’s ρ correlation coefficients, demonstrating the effectiveness of the more sophisticated question generation strategy.
read the caption
Table 2: Ablation Study of ETVA Question Generation. Both multi-agent and vanilla QG are based on the knowledge-augmented multi-stage reasoning framework.
| Setting | Accuracy | Kendall’s | Spearsman’s |
|---|---|---|---|
| ETVA | 89.27 (+25.20) | 47.16 (+28.98) | 58.47 (+34.63) |
| w/o. KA | 67.34 | 27.34 | 35.54 |
| w/o. VU | 82.73 | 37.56 | 44.81 |
| w/Only KA | 65.48 | 24.72 | 33.12 |
| Direct answer | 63.07 | 18.18 | 23.84 |
🔼 This table presents the results of an ablation study on the question-answering part of the ETVA model. It analyzes the contribution of three key components: Knowledge Augmentation (KA), Video Understanding (VU), and Critical Reflection (CR). The table shows the accuracy, Kendall’s τ correlation, and Spearman’s ρ correlation achieved by the full ETVA model and variations where one or more of these components are removed. This allows for a quantitative assessment of the importance of each component in achieving high human alignment scores.
read the caption
Table 3: Ablation Study of ETVA Question Answering Part: Component Analysis (KA: Knowledge Augmentation; VU: Video Understanding; CR: Critical Reflection)
| Category | Question Example | Prompt Example |
|---|---|---|
| Existence | Is there a penguin in the video? | A penguin standing on the left side of a cactus in a desert. |
| Action | Does the player pass the football? | In a crucial game moment, a player passes the football, dodging opponents. |
| Material | Is the city made of crystals? | A city made entirely of glowing crystals that change colors based on emotions. |
| Spatial | Does the penguin stand on the left of the cactus? | A penguin standing on the left side of a cactus in a desert. |
| Number | Are there three owls in the video? | Three owls perch on a branch during a full moon. |
| Shape | Is the cloud shaped like a hand? | A cloud shaped like a giant hand that picks up people for transportation. |
| Color | Does the man’s hair brown? | There’s a person, likely in their mid-twenties, with short brown hair. |
| Camera | Is the camera pushing in? | A girl is walking forward, camera push in. |
| Physics | Is the water pouring out in the space station? | Water is slowly pouring out of glass cup in the space station. |
| Other | Is the video in the Van Gogh style? | A beautiful coastal beach waves lapping on sand, Van Gogh style. |
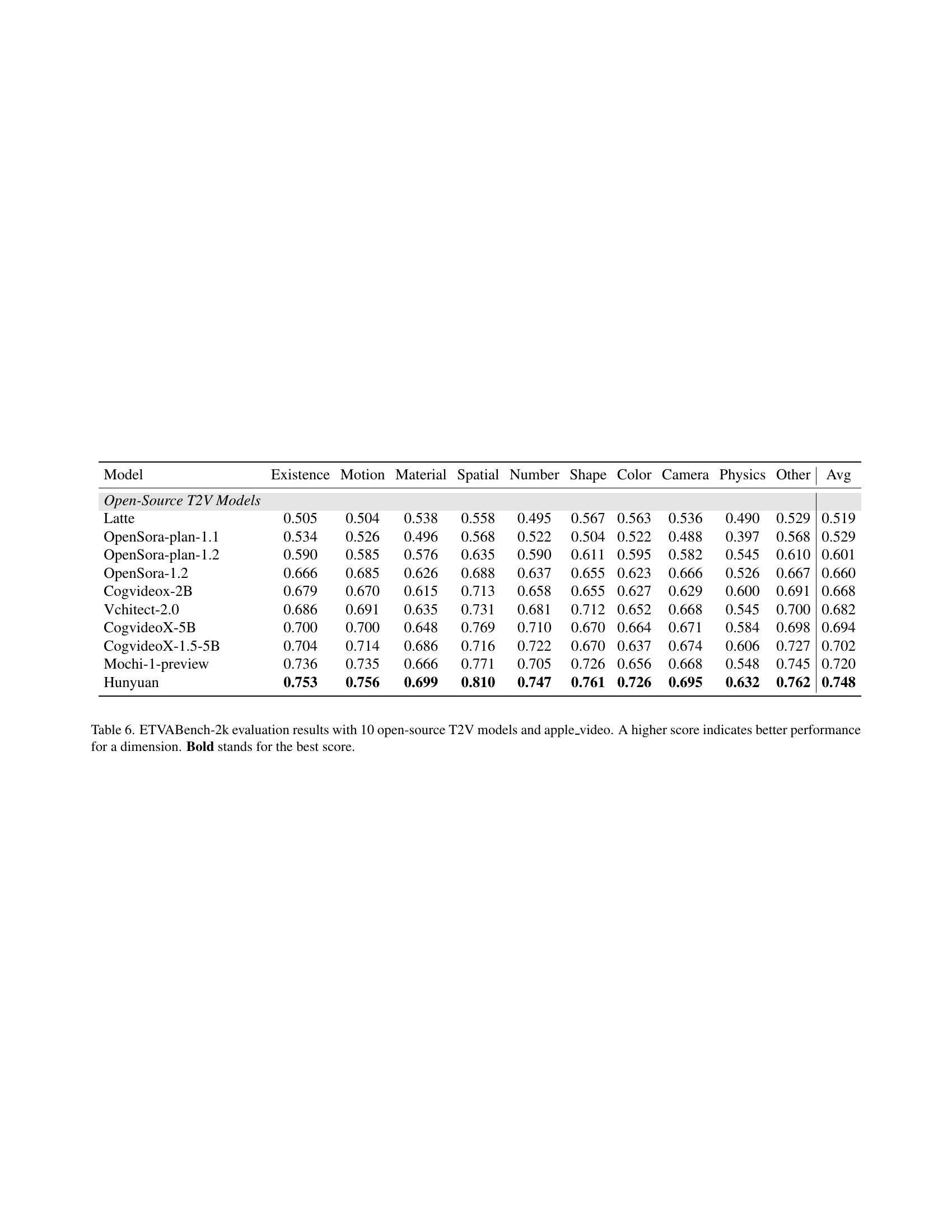
🔼 Table 4 presents a comprehensive evaluation of 15 text-to-video (T2V) models on the ETVABench-105 benchmark. The benchmark consists of 105 diverse text prompts, each designed to evaluate specific aspects of video generation quality, categorized into 10 dimensions: Existence, Action, Material, Spatial, Number, Shape, Color, Camera, Physics, and Other. For each prompt, each model generates a short video clip. The table shows the performance scores of each model on each dimension. A higher score indicates better performance in that dimension. Scores are presented as percentages, ranging from 0 to 1. Bold values highlight the overall best performance across all models for each dimension. Underlined values indicate the best performance among the 10 open-source models for each dimension, distinguishing them from the 5 closed-source models. This table provides a detailed comparison of the models’ capabilities across various aspects of video generation and helps identify strengths and weaknesses across different model architectures.
read the caption
Table 4: ETVABench-105 evaluation results with 5 close-source T2V models and 10 open-source T2V models. A higher score indicates better performance for a dimension. Bold stands for the best score. Underline indicates the best score in the open-source models.
Full paper#