TL;DR#
Automated Prompt Optimization (APO) is crucial for improving the effectiveness of Large Language Models (LLMs), but existing methods often suffer from inflexibility due to fixed templates and inefficient search in the prompt space. To address these challenges, this paper proposes MARS: a Multi-Agent framework Incorporating Socratic guidance. MARS utilizes multi-agent collaboration for planning and iterative refinement to break free from cognitive biases.
MARS employs seven distinct agents, including a Planner for autonomous pathfinding and a Teacher-Critic-Student model for Socratic dialogue-based optimization. This setup facilitates iterative prompt refinement, enhancing search efficiency. The method demonstrates improved performance across diverse datasets. The framework’s design emphasizes flexibility and incorporates interpretability, outperforming other APO techniques and demonstrating advancements in prompt optimization and multi-agent collaboration.
Key Takeaways#
Why does it matter?#
This paper introduces MARS, a multi-agent APO framework with Socratic guidance, showing significant performance gains and opening new research avenues in prompt engineering and multi-agent systems. The interpretable optimization process allows for future research.
Visual Insights#

🔼 This figure displays three different prompts used for a word sorting task and their corresponding outputs generated by a large language model. The prompts vary in style: a zero-shot prompt (no specific instructions), a chain-of-thought (CoT) prompt (step-by-step reasoning), and a prompt optimized using the MARS framework (the paper’s proposed method). The comparison highlights how prompt engineering significantly influences the accuracy and effectiveness of the model’s response, demonstrating the importance of prompt optimization.
read the caption
Figure 1: Three different prompts along with their corresponding responses for the word sorting task.
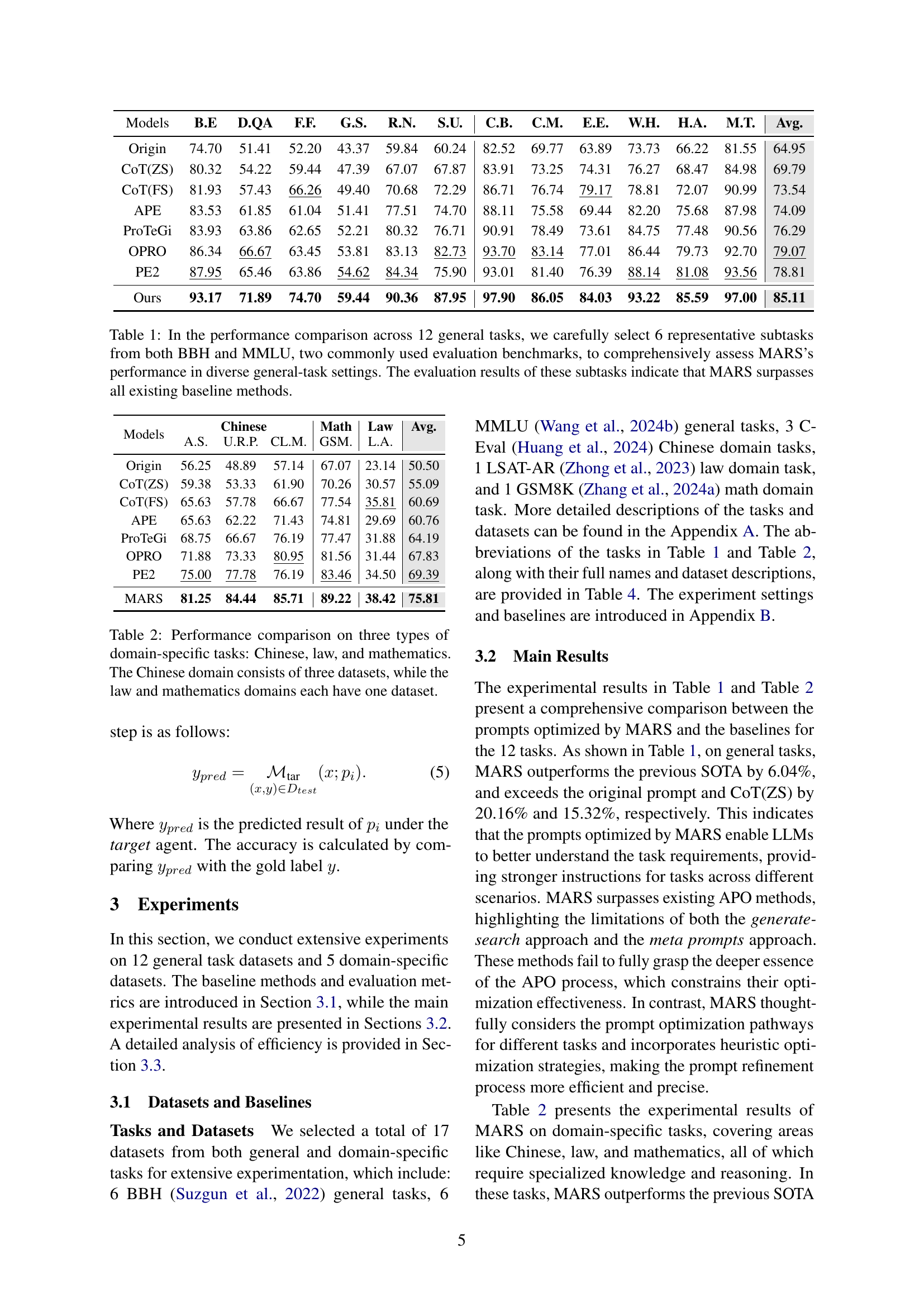
| Models | B.E | D.QA | F.F. | G.S. | R.N. | S.U. | C.B. | C.M. | E.E. | W.H. | H.A. | M.T. | Avg. |
| Origin | 74.70 | 51.41 | 52.20 | 43.37 | 59.84 | 60.24 | 82.52 | 69.77 | 63.89 | 73.73 | 66.22 | 81.55 | 64.95 |
| CoT(ZS) | 80.32 | 54.22 | 59.44 | 47.39 | 67.07 | 67.87 | 83.91 | 73.25 | 74.31 | 76.27 | 68.47 | 84.98 | 69.79 |
| CoT(FS) | 81.93 | 57.43 | 66.26 | 49.40 | 70.68 | 72.29 | 86.71 | 76.74 | 79.17 | 78.81 | 72.07 | 90.99 | 73.54 |
| APE | 83.53 | 61.85 | 61.04 | 51.41 | 77.51 | 74.70 | 88.11 | 75.58 | 69.44 | 82.20 | 75.68 | 87.98 | 74.09 |
| ProTeGi | 83.93 | 63.86 | 62.65 | 52.21 | 80.32 | 76.71 | 90.91 | 78.49 | 73.61 | 84.75 | 77.48 | 90.56 | 76.29 |
| OPRO | 86.34 | 66.67 | 63.45 | 53.81 | 83.13 | 82.73 | 93.70 | 83.14 | 77.01 | 86.44 | 79.73 | 92.70 | 79.07 |
| PE2 | 87.95 | 65.46 | 63.86 | 54.62 | 84.34 | 75.90 | 93.01 | 81.40 | 76.39 | 88.14 | 81.08 | 93.56 | 78.81 |
| Ours | 93.17 | 71.89 | 74.70 | 59.44 | 90.36 | 87.95 | 97.90 | 86.05 | 84.03 | 93.22 | 85.59 | 97.00 | 85.11 |
🔼 This table compares the performance of the MARS model against several baseline methods across twelve general tasks. Six tasks were selected from each of the BBH and MMLU benchmark datasets to ensure a comprehensive evaluation across diverse task types. The results demonstrate that MARS outperforms all existing baselines.
read the caption
Table 1: In the performance comparison across 12 general tasks, we carefully select 6 representative subtasks from both BBH and MMLU, two commonly used evaluation benchmarks, to comprehensively assess MARS’s performance in diverse general-task settings. The evaluation results of these subtasks indicate that MARS surpasses all existing baseline methods.
In-depth insights#
Socratic APO#
The idea of Socratic APO, or Automated Prompt Optimization guided by Socratic principles, presents a novel approach to refining prompts for large language models (LLMs). This method moves beyond simple trial-and-error or meta-prompt engineering by incorporating a structured dialogue between different AI agents. One agent, acting as a Teacher, poses questions in a Socratic style, prompting another agent, the Student, to iteratively improve the prompt. A Critic agent evaluates the questions, ensuring they adhere to Socratic principles of open-ended inquiry and guided self-discovery. This approach aims to make the optimization process more transparent and interpretable, allowing us to understand why certain prompts perform better than others. By encouraging the LLM to express its reasoning and challenge assumptions, Socratic APO could lead to prompts that are more robust, generalizable, and aligned with human understanding. This further contributes to the field by integrating educational theories into the APO pipeline, potentially leading to better prompted LLMs.
Multi-Agent MARS#
MARS leverages a multi-agent architecture for automated prompt optimization (APO), which is a novel approach to address limitations of fixed templates in existing APO methods. This architecture includes a Planner agent that autonomously plans optimization paths, which ensures flexibility and individual tasks follow a unique plan. Further, MARS employs a Teacher-Critic-Student Socratic guidance dialogue pattern for iterative prompt refinement and effective search. This dialogue is crucial as the Teacher employs questions, the Critic evaluates them, and the Student optimizes, which allows MARS to search the entire prompt space and converge towards an optimal prompt. Validating prompts through a Target agent further refines results.
Flexibility Issue#
The flexibility issue in Automated Prompt Optimization (APO) arises from the reliance on fixed templates or meta-prompts. These templates, while useful for certain tasks, often lack the adaptability needed for diverse scenarios, limiting their effectiveness. This inflexibility can lead to sub-optimal results, as the prompts cannot be dynamically adjusted to address the specific nuances of each task. A more adaptable approach is needed to overcome the limitations imposed by fixed templates and fully leverage the potential of LLMs.
Search Inefficiency#
Search inefficiency in prompt optimization (APO) arises from various factors. The vast prompt space makes exhaustive search infeasible, leading to reliance on heuristics or local optimization methods that may miss the global optimum. Fixed templates limit exploration, hindering adaptation to diverse tasks. The absence of systematic exploration strategies and efficient evaluation metrics further exacerbates the problem. Techniques to mitigate this include multi-agent frameworks for planning optimization paths, Socratic dialogue to guide exploration, and adaptive search algorithms to dynamically adjust search strategies based on feedback and task characteristics, ultimately improving the effectiveness of APO. Heuristic optimization methods can also contribute in addressing the challenges of search ineffeciency.
Future Interactive APO#
The field of Automated Prompt Optimization (APO) is ripe for incorporating interactive elements, moving beyond the current paradigm of automated, black-box optimization. Future Interactive APO could leverage human input at various stages. For example, a user could provide feedback on generated prompts, guiding the search process towards more interpretable or relevant solutions. Another avenue is to incorporate real-world feedback into the optimization loop. For instance, if a prompt is designed to elicit a specific response from a model, the actual outcome of that response in a real-world application could be used as a reward signal. Human-in-the-loop APO systems can ensure that models are not optimized solely for metrics but for actual downstream effectiveness. Finally, interactive visualization tools can help users understand the optimization process, identifying patterns in effective prompts and gaining insights into model behavior. This approach could allow for more nuanced prompt design, adapting to specific needs and constraints beyond what automated methods can achieve. By integrating human expertise and real-world context, Interactive APO promises more robust, adaptable, and ultimately more useful prompt optimization strategies.
More visual insights#
More on figures

🔼 The MARS model uses seven large language model (LLM) agents to optimize prompts. The Manager coordinates the agents. The UserProxy receives the initial prompt and task description. The Planner creates an optimization plan. The Teacher, Critic, and Student agents iteratively refine prompts using a Socratic dialogue. Finally, the Target agent evaluates and records the results.
read the caption
Figure 2: The overall architecture of the MARS model. It consists of seven LLM agents. The Manager oversees the entire process, responsible for communication between agents and the allocation of speakers. The UserProxy receives input and the original prompt. The Planner formulates the APO plan based on the received input and task description. In the Socratic guidance dialogue pattern, the Teacher-Critic-Student system iteratively refines the prompts according to the Planner’s plan, with the final evaluation and recording done by the Target.

🔼 This figure illustrates an example of the Teacher-Critic-Student Socratic dialogue method used in the MARS framework. The Teacher agent asks open-ended questions to guide the Student agent’s prompt optimization, while the Critic agent evaluates the quality of the Teacher’s questions. This iterative process is shown here during the fifth optimization step, demonstrating the dialogue pattern and how it refines the prompt towards better performance. Each speech bubble shows the contribution from a specific agent, guiding the process toward a better optimized prompt.
read the caption
Figure 3: A specific illustration of a Teacher-Critic-Student Socratic guidance dialogue pattern. The case shows the fifth step optimization iteration.

🔼 This bar chart visualizes the Prompt Efficiency (PE) for different prompt optimization methods across twelve general tasks. Prompt Efficiency is a metric that balances the accuracy of the model’s output with the number of LLM API calls required to achieve that result. Higher PE values indicate more efficient prompt optimization. Each task is represented by a cluster of bars, each bar showing the PE for a specific method (MARS and several baselines). This arrangement allows for a direct comparison of the efficiency of various techniques in solving different kinds of tasks.
read the caption
Figure 4: The Efficiency Analysis chart presents a comparison of the PE metric between MARS and other baseline methods across different tasks. For each task, different models are grouped together in a single bar chart cluster, allowing for a clear visual comparison of performance efficiency differences.

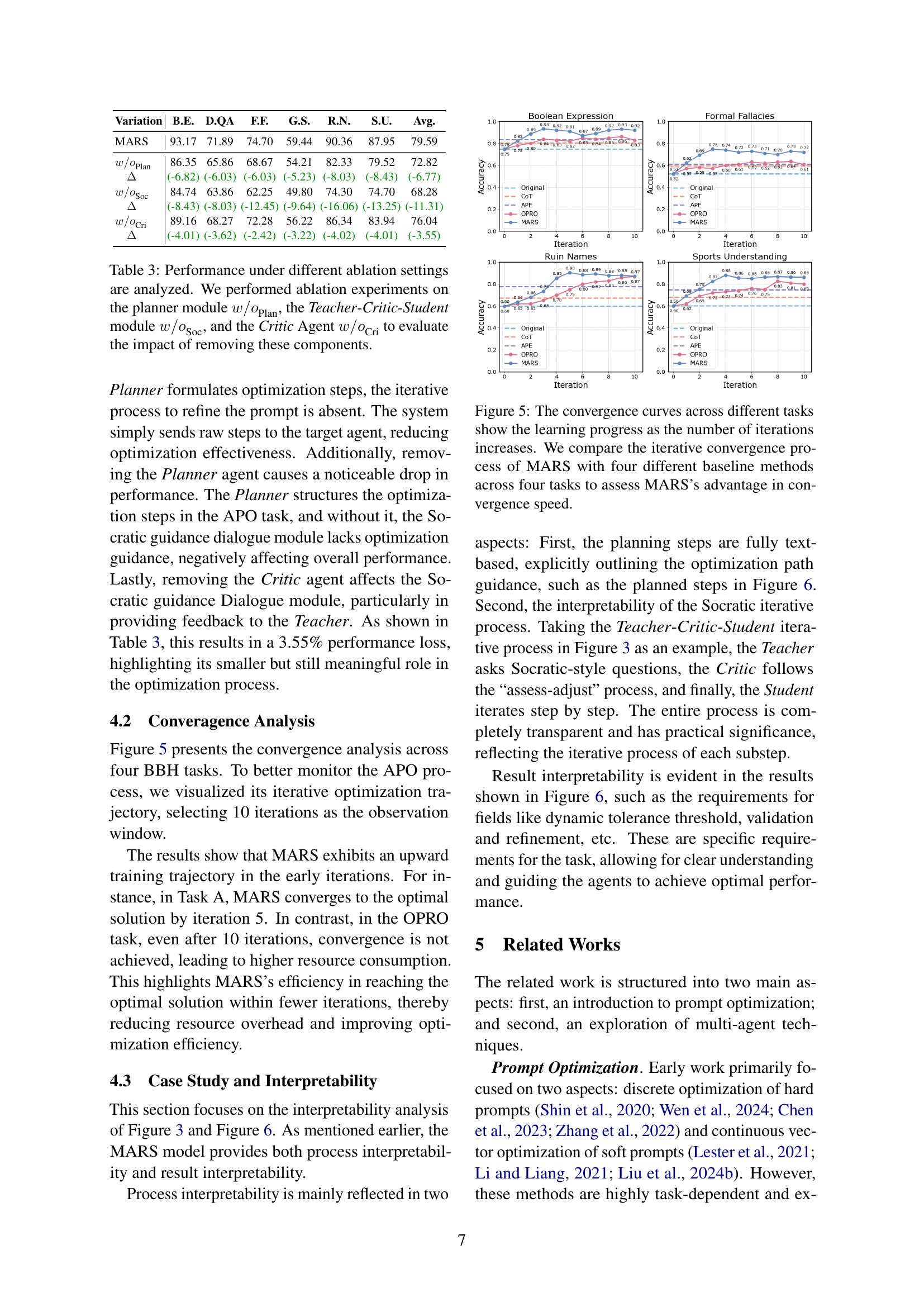
🔼 Figure 5 presents a detailed analysis of the convergence speed of the MARS model compared to four baseline methods across four different tasks. The x-axis represents the number of iterations in the prompt optimization process, while the y-axis represents the accuracy achieved. The figure visually demonstrates how MARS converges to a high accuracy level more rapidly than the baseline models, highlighting its efficiency and effectiveness in optimizing prompts. Each line on the graph corresponds to a different task, allowing for a comparison of MARS’s performance across various scenarios.
read the caption
Figure 5: The convergence curves across different tasks show the learning progress as the number of iterations increases. We compare the iterative convergence process of MARS with four different baseline methods across four tasks to assess MARS’s advantage in convergence speed.

🔼 Figure 6 shows a detailed example of how the MARS framework optimizes prompts for a geometry task. It illustrates the step-by-step planning process conducted by the Planner agent, followed by the iterative refinement of the prompt through a Socratic dialogue between the Teacher, Critic, and Student agents. The figure visually depicts each agent’s contribution and the resulting optimized prompt that significantly improves the accuracy of the LLM’s response.
read the caption
Figure 6: Case study of a geometry shape task, showing the planning step and new prompt after optimized iterations.

🔼 Figure 7 presents a detailed step-by-step breakdown of how the MARS model solves a geometry problem. It illustrates the collaboration between seven AI agents (Manager, UserProxy, Planner, Teacher, Critic, Student, Target) in a single iteration. Each agent contributes sequentially, demonstrating the model’s collaborative and iterative approach to prompt optimization. The figure shows how the agents work together to refine a prompt, highlighting the process of analyzing task requirements, planning the optimization steps, refining the prompt through Socratic questioning, evaluating each step’s effectiveness, and finally generating an optimized prompt.
read the caption
Figure 7: This figure presents a complete example of the collaborative output from all agents in a single iteration, using the Geometry Shapes task from the BBH dataset.
More on tables
| Models | Chinese | Math | Law | Avg. | ||
| A.S. | U.R.P. | CL.M. | GSM. | L.A. | ||
| Origin | 56.25 | 48.89 | 57.14 | 67.07 | 23.14 | 50.50 |
| CoT(ZS) | 59.38 | 53.33 | 61.90 | 70.26 | 30.57 | 55.09 |
| CoT(FS) | 65.63 | 57.78 | 66.67 | 77.54 | 35.81 | 60.69 |
| APE | 65.63 | 62.22 | 71.43 | 74.81 | 29.69 | 60.76 |
| ProTeGi | 68.75 | 66.67 | 76.19 | 77.47 | 31.88 | 64.19 |
| OPRO | 71.88 | 73.33 | 80.95 | 81.56 | 31.44 | 67.83 |
| PE2 | 75.00 | 77.78 | 76.19 | 83.46 | 34.50 | 69.39 |
| MARS | 81.25 | 84.44 | 85.71 | 89.22 | 38.42 | 75.81 |
🔼 Table 2 presents a performance comparison of different models on three types of domain-specific tasks: Chinese, law, and mathematics. The Chinese domain includes three individual datasets, while the law and mathematics domains each have a single dataset. The table shows how well each model performs on these tasks, allowing for a comparison of their accuracy and effectiveness across different domains and dataset sizes.
read the caption
Table 2: Performance comparison on three types of domain-specific tasks: Chinese, law, and mathematics. The Chinese domain consists of three datasets, while the law and mathematics domains each have one dataset.
| Variation | B.E. | D.QA | F.F. | G.S. | R.N. | S.U. | Avg. |
| MARS | 93.17 | 71.89 | 74.70 | 59.44 | 90.36 | 87.95 | 79.59 |
| 86.35 | 65.86 | 68.67 | 54.21 | 82.33 | 79.52 | 72.82 | |
| (-6.82) | (-6.03) | (-6.03) | (-5.23) | (-8.03) | (-8.43) | (-6.77) | |
| 84.74 | 63.86 | 62.25 | 49.80 | 74.30 | 74.70 | 68.28 | |
| (-8.43) | (-8.03) | (-12.45) | (-9.64) | (-16.06) | (-13.25) | (-11.31) | |
| 89.16 | 68.27 | 72.28 | 56.22 | 86.34 | 83.94 | 76.04 | |
| (-4.01) | (-3.62) | (-2.42) | (-3.22) | (-4.02) | (-4.01) | (-3.55) |
🔼 This table presents the results of ablation experiments conducted to assess the impact of removing individual components from the MARS model. The experiments involved removing the Planner agent (w/oPlan), the Teacher-Critic-Student module (w/oSoc), and the Critic agent (w/oCri) one at a time. The table shows the resulting performance (accuracy) on various tasks (B.E., D.QA, F.F., G.S., R.N., S.U.) for each ablation experiment, compared to the full MARS model. The performance differences (Δ) between the full model and each ablation are also shown, highlighting the contribution of each removed component to the overall model performance.
read the caption
Table 3: Performance under different ablation settings are analyzed. We performed ablation experiments on the planner module w/oPlan𝑤subscript𝑜Plan{w/o}_{\text{Plan}}italic_w / italic_o start_POSTSUBSCRIPT Plan end_POSTSUBSCRIPT, the Teacher-Critic-Student module w/oSoc𝑤subscript𝑜Soc{w/o}_{\text{Soc}}italic_w / italic_o start_POSTSUBSCRIPT Soc end_POSTSUBSCRIPT, and the Critic Agent w/oCri𝑤subscript𝑜Cri{w/o}_{\text{Cri}}italic_w / italic_o start_POSTSUBSCRIPT Cri end_POSTSUBSCRIPT to evaluate the impact of removing these components.
| Tasks | ABBR. | Train | Test |
| Bigbench | |||
| Boolean Expressions | B.E. | 1 | 249 |
| Disambiguation QA | D.QA | 1 | 249 |
| Formal Fallacies | F.F. | 1 | 249 |
| Geometric Shapes | G.S. | 1 | 249 |
| Ruin Names | R.N. | 1 | 249 |
| Sports Understanding | S.U. | 1 | 249 |
| MMLU | |||
| College Biology | C.B. | 1 | 143 |
| College Medicine | C.M. | 1 | 172 |
| Electrical Engineering | E.E. | 1 | 144 |
| HighSchool World History | W.H. | 1 | 236 |
| Human Aging | H.A. | 1 | 222 |
| Marketing | M.T. | 1 | 233 |
| C-EVAL | |||
| Art Studies | A.S. | 1 | 32 |
| Urban And Rural Planner | U.R.P. | 1 | 45 |
| Clinical Medicine | CL.M. | 1 | 21 |
| GSM8K | GSM. | 1 | 1318 |
| LSAT-AR | L.A. | 1 | 229 |
🔼 Table 4 details the data splits used for training and testing across various general and domain-specific tasks. For each task (e.g., Boolean Expressions, College Biology, etc.), only one instance was used for training the model, while the remaining instances served as the test set. The ‘ABBR.’ column provides a concise abbreviation for each task name.
read the caption
Table 4: Data split of general tasks and domain-specific tasks. One instance for training and others for testing. The ‘ABBR.’ column represents the abbreviations for all the tasks.
| Tasks | BBH | MMLU | Chinese | GSM. | L.A. | Avg. |
| Origin | 60.92 | 83.73 | 58.26 | 72.31 | 20.96 | 59.24 |
| CoT(ZS) | 62.81 | 85.62 | 64.26 | 76.25 | 24.45 | 62.68 |
| CoT(FS) | 63.42 | 88.27 | 68.69 | 83.92 | 28.82 | 66.62 |
| APE | 64.36 | 86.72 | 69.03 | 81.18 | 30.13 | 66.28 |
| ProTeGi | 76.43 | 86.35 | 73.52 | 82.70 | 31.88 | 70.18 |
| OPRO | 78.73 | 88.25 | 75.79 | 84.74 | 32.75 | 72.05 |
| PE2 | 77.59 | 91.89 | 74.67 | 85.43 | 35.81 | 73.08 |
| MARS | 81.13 | 92.82 | 78.11 | 90.97 | 40.17 | 76.58 |
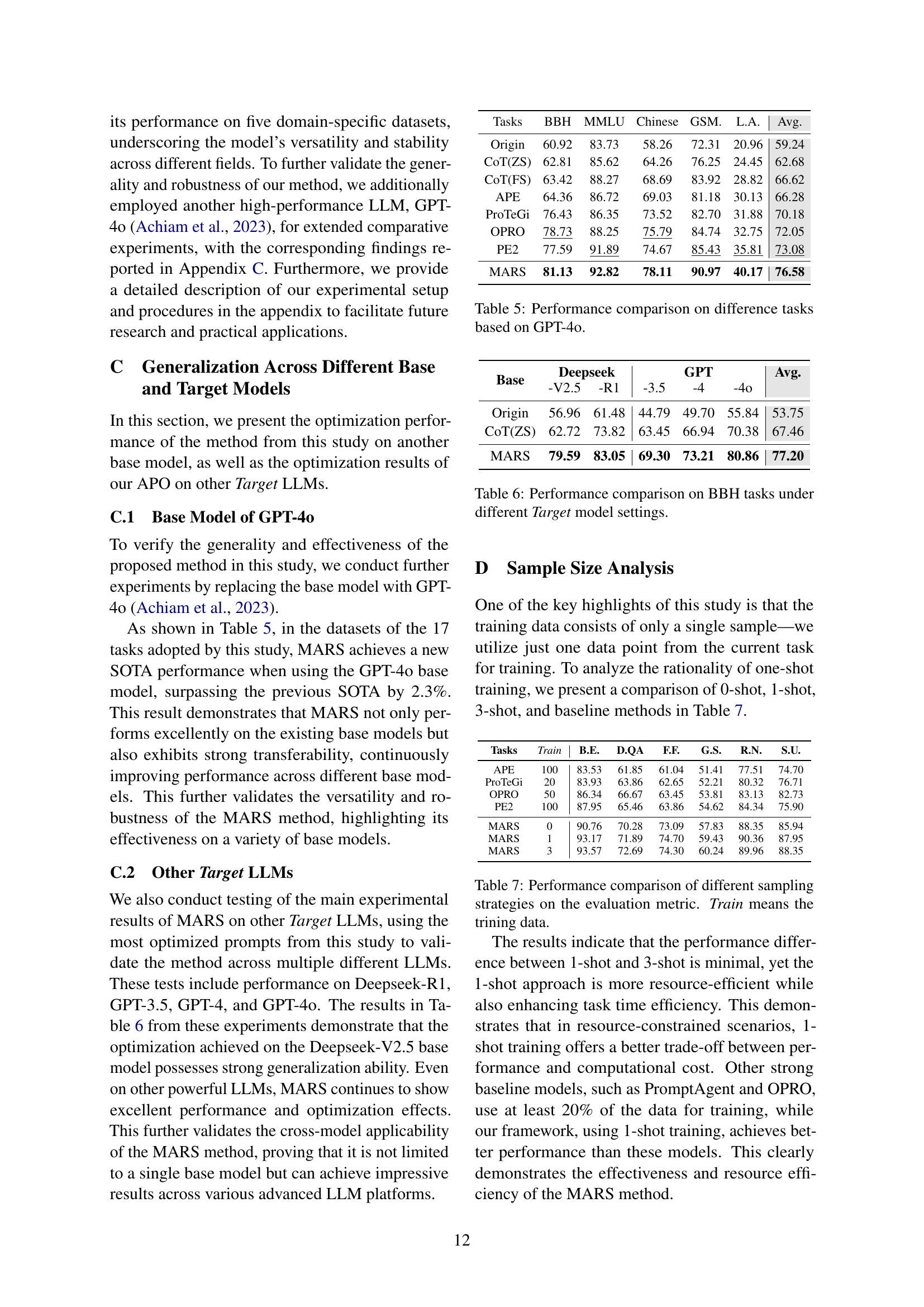
🔼 This table presents a performance comparison of different prompt optimization methods across various tasks, using GPT-40 as the base language model. It shows how the accuracy of different methods (Origin, CoT(ZS), CoT(FS), APE, ProTeGi, OPRO, PE2, and MARS) varies across different tasks from BBH, MMLU, Chinese, GSM8K, and LSAT-AR datasets. This allows for a comprehensive evaluation of the methods’ effectiveness in diverse scenarios and domains.
read the caption
Table 5: Performance comparison on difference tasks based on GPT-4o.
| Base | Deepseek | GPT | Avg. | |||
| -V2.5 | -R1 | -3.5 | -4 | -4o | ||
| Origin | 56.96 | 61.48 | 44.79 | 49.70 | 55.84 | 53.75 |
| CoT(ZS) | 62.72 | 73.82 | 63.45 | 66.94 | 70.38 | 67.46 |
| MARS | 79.59 | 83.05 | 69.30 | 73.21 | 80.86 | 77.20 |
🔼 This table presents a comparison of the performance of different prompt optimization methods on six tasks from the Big Bench Hard (BBH) benchmark. The results show the accuracy achieved when using different large language models (LLMs) as the target model for prompt optimization. The methods compared include using the original prompt, a Chain-of-Thought (CoT) prompt, and several state-of-the-art automated prompt optimization (APO) techniques. MARS is the proposed method in the paper. The table aims to illustrate the generalization capability of MARS across different LLMs.
read the caption
Table 6: Performance comparison on BBH tasks under different Target model settings.
| Tasks | Train | B.E. | D.QA | F.F. | G.S. | R.N. | S.U. |
| APE | 100 | 83.53 | 61.85 | 61.04 | 51.41 | 77.51 | 74.70 |
| ProTeGi | 20 | 83.93 | 63.86 | 62.65 | 52.21 | 80.32 | 76.71 |
| OPRO | 50 | 86.34 | 66.67 | 63.45 | 53.81 | 83.13 | 82.73 |
| PE2 | 100 | 87.95 | 65.46 | 63.86 | 54.62 | 84.34 | 75.90 |
| MARS | 0 | 90.76 | 70.28 | 73.09 | 57.83 | 88.35 | 85.94 |
| MARS | 1 | 93.17 | 71.89 | 74.70 | 59.43 | 90.36 | 87.95 |
| MARS | 3 | 93.57 | 72.69 | 74.30 | 60.24 | 89.96 | 88.35 |
🔼 This table presents a comparison of the performance of MARS across different sampling strategies for training data. It compares the accuracy achieved using 0-shot, 1-shot, and 3-shot learning approaches, indicating how the amount of training data affects the model’s performance. It also includes a comparison with other strong baseline methods for reference.
read the caption
Table 7: Performance comparison of different sampling strategies on the evaluation metric. Train means the trining data.
| Manager |
| You are the ChatManager, please schedule the right Agent for the job as needed. |
| UserProxy |
| Here is a topic for geometric graph generation: Given a full SVG path element containing multiple commands, determine the geometric shape that would be generated if one were to execute the full path element. For example: This SVG path element ‘<path d="M 64.00,63.00 L 44.00,63.00 L 44.00,50.00 L 64.00,50.00 L 64.00,45.00 L 85.00,57.00 L 64.00,68.00 L 64.00,63.00"/>’ draws a: Options: (A) circle (B) heptagon (C) hexagon (D) kite (E) line (F) octagon (G) pentagon (H) rectangle (I) sector (J) triangle I want to input a prompt and this topic into the big language model so that the big language model outputs the highest correctness rate. Please generate the most suitable prompt according to the requirements I just mentioned. |
| Planner |
| Split the task ’Here is a topic for geometric graph generation: Given a full SVG path element containing multiple commands, determine the geometric shape that would be generated if one were to execute the full path element. For example: This SVG path element <path d=M 64.00,63.00 L 44.00,63.00 L 44.00,50.00 L 64.00,50.00 L 64.00,45.00 L 85.00,57.00 L 64.00,68.00 L 64.00,63.00""/> draws a Options: (A) circle (B) heptagon (C) hexagon (D) kite (E) line (F) octagon (G) pentagon (H) rectangle (I) sector (J) triangle I want to input a prompt and this topic into the big language model so that the big language model outputs the highest correctness rate. Please generate the most suitable prompt according to the requirements I just mentioned.’ into detailed steps and details. For example, for the clinical medicine Test, the task is planned as follows: Total steps: 4 Step 1: Analyze the input requirements, focusing on the type of clinical medicine question and the format of the options. Step 2: Design a prompt that encourages the model to consider the specific clinical characteristics of the condition described in the question and match the most appropriate option based on medical knowledge. Step 3: Request the model to evaluate each option in the context of clinical presentation, symptoms, and diagnostic characteristics of the condition to ensure it selects the most accurate answer. Step 4: Test and refine the prompt to ensure the model produces the highest correctness rate for similar clinical medicine questions. |
| Teacher |
| You are a teacher who asks questions in the Socratic manner based on objectives and student responses. Please ask a total of two questions: The first one is for the problem that appeared in the prompt given by the students in the last round. The second one is an optimization solution based on the current steps of the task. Please include only questions in your output and do not make answers for your students. |
| Student |
| You are a prompt generator, please proceed to iterate over the existing prompts as required. Note that you should only output the new prompt you generated. |
| Critic |
| You are an evaluator responsible for judging the correctness of a given task. Your output must strictly follow these rules: 1. If the task is judged as correct, output only: [True] 2. If the task is judged as incorrect, output: [False] [suggestion: <reason for the incorrect judgment>] Replace ‘<reason for the incorrect judgment>‘ with a clear and concise explanation of why the task is incorrect. Do not include any additional text, comments, or explanations beyond the specified format. |
| Target |
| Prompt: Systematically analyze the given SVG path element by first breaking it down into its individual commands, such as ’M’ (move to), ’L’ (line to), and others. For each command, map the sequence of points it generates, ensuring you accurately trace the path step by step. As you follow the path, focus on identifying key geometric properties, such as equal side lengths, parallel lines, specific angles, or symmetries, that emerge between consecutive points. Use these properties to classify the shape based on its defining characteristics. For example, given the path <path d=M 64.00,63.00 L 44.00,63.00 L 44.00,50.00 L 64.00,50.00 L 64.00,45.00 L 85.00,57.00 L 64.00,68.00 L 64.00,63.00/>, calculate the distances between points to check for equal side lengths, measure angles to identify parallelism or perpendicularity, and look for symmetries that align with known geometric shapes. Based on these observations, determine whether the shape is a circle, heptagon, hexagon, kite, line, octagon, pentagon, rectangle, sector, or triangle. Provide the correct answer by reasoning through the geometric properties derived from the path commands. Question: question Please don’t output the process of doing the question, only the content of the answer.The answer should be a parenthesis containing the capital letter of the chosen answer. please do not add any other spaces or symbols. |
🔼 This table details the prompts used for each agent within the MARS framework. Each agent plays a distinct role in the prompt optimization process, from managing the overall process to generating and refining prompts. The specific prompts shown in the table are examples drawn from the Geometry Shapes task within the BBH dataset, illustrating how these prompts are applied to a real-world scenario.
read the caption
Table 8: The table summarizes the prompts used for all Agents in this paper. The examples in the table are from the Geometry Shapes Task of the BBH dataset.
| Boolean Expressions |
| Evaluate the truth value of the following Boolean expression step by step. The expression consists of Boolean constants (True, False) and basic Boolean operators (and, or, not). Carefully analyze each part of the expression, apply the correct Boolean logic, and provide the final truth value as your answer. For example, if the input is ’not ( True ) and ( True ) is’, the correct output is ’False’. Ensure your reasoning is clear and accurate. |
🔼 This table presents the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic Guidance) method for the Boolean Expressions task within the Big-Bench Hard (BBH) dataset. The optimized prompt is designed to improve the accuracy and efficiency of large language models (LLMs) in evaluating Boolean expressions by providing a structured approach and clear instructions. The prompt’s structure is likely to guide LLMs to break down the expression into smaller parts, correctly apply Boolean logic operations (AND, OR, NOT), and provide the accurate truth value as the answer.
read the caption
Table 9: The table shows the final optimized prompt for the Boolean Expressions task of BBH using the MARS method.
| Disambiguation QA |
| Analyze the following sentence to determine whether the pronoun is inherently ambiguous or if it can be linked to a specific antecedent. Follow these streamlined steps to efficiently evaluate pronoun disambiguation while maintaining accuracy, especially in complex sentence structures: 1. Identify the Pronoun and Its Grammatical Role: 2. Identify Key Contextual Cues: 3. List and Filter Potential Antecedents: 4. Evaluate Plausibility: 5. Determine Ambiguity or Specific Antecedent: 6. Align with Provided Options: Evaluation Metrics for Model Output: 1. Correctness: 2. Clarity: 3. Efficiency: 4. Consistency: Additional Considerations: 1. Grammatical Structure Influence: 2. Optimizing Contextual Cue Identification: By simplifying the steps and focusing on key evaluation metrics, the model can process and apply the disambiguation process more efficiently while maintaining high accuracy and clarity in its outputs, even in complex sentence structures. |
🔼 This table presents the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic guidance) method for the Disambiguation QA task within the Big Bench Hard (BBH) benchmark. The MARS method iteratively refines prompts using a multi-agent system and Socratic dialogue. The optimized prompt is designed to improve the accuracy and efficiency of pronoun disambiguation in complex sentences by providing a structured approach for identifying pronouns, relevant contextual cues, and potential antecedents, ultimately leading to a more precise determination of pronoun ambiguity.
read the caption
Table 10: The table shows the final optimized prompt for the Disambiguation QA task of BBH using the MARS method.
| Formal Fallacies Syllogisms Negation |
| Analyze the following argument step by step to determine its logical validity. Carefully consider the premises provided and assess whether the conclusion necessarily follows from them. Pay special attention to the role of negations in the argument. After evaluating the logical structure, decide whether the argument is deductively valid or invalid based on the given premises. Choose the correct option from the provided choices: valid or invalid. Ensure your reasoning is thorough and aligns with formal logical principles. |
🔼 This table presents the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic Guidance) method for the ‘Formal Fallacies Syllogisms Negation’ task within the BBH (Big Bench Hard) dataset. The optimized prompt is designed to improve the accuracy and efficiency of Large Language Models (LLMs) in evaluating the logical validity of arguments, particularly those involving negations. The prompt likely includes a structured, step-by-step approach guiding the LLM through a logical analysis of the premises and conclusion to determine the argument’s validity.
read the caption
Table 11: The table shows the final optimized prompt for the Formal Fallacies Syllogisms Negation task of BBH using the MARS method.
| Geometric Shapes |
| Given an SVG path element and a list of geometric shape options, systematically analyze and interpret the sequence of SVG path commands to determine the number of vertices and the overall structure of the geometric shape. Follow this structured and optimized approach: 1. Dynamic Tolerance Threshold for Vertex Identification: Detailed Explanation 2. Optimized Vertex Counting and Connection: Detailed Explanation 3. Critical SVG Path Command Analysis:Detailed Explanation 4. Accurate Vertex Counting and Connection:Detailed Explanation 5. Distinguishing Between Similar Shapes:Detailed Explanation 6. Systematic Comparison with Provided Options:Detailed Explanation 7. Validation and Refinement:Detailed Explanation 8. Optimization for Similar Shapes:Detailed Explanation Key Considerations for Dynamic Tolerance and Vertex Identification:Detailed Explanation Optimized Comparison Process:Detailed Explanation By integrating these considerations into the analysis, the model can achieve a higher correctness rate in identifying geometric shapes from SVG paths, even when dealing with shapes that have similar properties. |
🔼 This table presents the final optimized prompt generated by the MARS method for the Geometric Shapes task within the BBH benchmark. The prompt is designed to guide a large language model (LLM) in accurately identifying geometric shapes from SVG path data by systematically analyzing the path commands and their geometric implications. It outlines a structured approach, including steps for dynamic tolerance thresholding in vertex identification, optimized vertex counting and connection analysis, critical SVG command analysis, and comparison with provided options. Key considerations for dynamic tolerance and vertex identification, along with optimized comparison processes are also detailed to ensure the model’s accuracy and efficiency.
read the caption
Table 12: The table shows the final optimized prompt for the Geometric Shapes task of BBH using the MARS method.
| Ruin Names |
| Given an artist, band, or movie name, create a one-character edit that changes the name in a humorous and universally recognizable way. The edit must involve only a single-character change (adding, removing, or substituting one letter) and should prioritize simplicity, absurdity, and surprise to evoke humor effectively. Ensure the edit maintains a clear connection to the original name, making the humor immediately recognizable and universally understandable, while avoiding overly specific or niche references. Key Guidelines: 1. Simplicity and Surprise: 2. Cultural Universality: 3. Absurdity and Creativity: Evaluation Metrics: Strategies for Simplicity and Surprise: Systematic Testing Strategies: Examples: Refinement for Evaluation Metrics: Focus on generating edits that are simple, surprising, and universally amusing, ensuring they strictly adhere to the one-character constraint and meet the evaluation criteria for humor, cultural relevance, and clarity. Test each edit with a diverse set of sample inputs and audiences to validate its humor consistency and cultural universality, ensuring the edit is immediately recognizable and universally understandable. |
🔼 This table presents the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic Guidance) method for the Ruin Names task within the Big Bench Hard (BBH) dataset. The prompt is designed to guide a large language model in creating humorous and universally recognizable one-character edits to names (artist, band, movie). It emphasizes simplicity, absurdity, and surprise while maintaining a clear connection to the original name. The prompt provides specific guidelines and evaluation metrics to ensure the generated edits are both creative and easily understandable.
read the caption
Table 13: The table shows the final optimized prompt for the Ruin Names task of BBH using the MARS method.
| Sports Understanding |
| Evaluate the plausibility of the following sports-related sentence by considering the following key aspects: 1. Player Abilities and Historical Performance: 2. Event Context and Historical Significance: 3. Terminology and Sport-Specific Knowledge: 4. Rarity vs. Impossibility: Guidelines: - If the action is rare but historically documented or consistent with the player’s abilities, consider it plausible. - For lesser-known players or niche sports, evaluate based on typical performance levels and historical precedents within that sport. - Prioritize consistency with the sport’s rules, norms, and historical records. Examples: Additional Context for Ambiguous Cases: Rationale Requirement: Potential Biases and Limitations: Edge Cases and Testing: Simplified Evaluation Process: - Focus on the core aspects of player abilities, event context, and sport-specific knowledge to streamline the evaluation. - Use historical examples and edge cases as supplementary references rather than primary determinants to avoid over-reliance and potential biases. Output ’yes’ if the sentence is plausible, or ’no’ if it is not, followed by a brief rationale. Now, evaluate the following sentence: [input sentence]. |
🔼 This table displays the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic Guidance) method for the Sports Understanding task within the BBH (Big Bench Hard) dataset. The prompt is designed to improve the accuracy and efficiency of evaluating the plausibility of sports-related sentences by focusing on key aspects such as player abilities, event context, terminology, and rarity. The MARS method iteratively refines prompts using a multi-agent system and Socratic dialogue to achieve optimal performance.
read the caption
Table 14: The table shows the final optimized prompt for the Sports Understanding task of BBH using the MARS method.
| College Biology |
| Generate a set of multiple-choice biology questions that explicitly test higher-order thinking skills, such as application, analysis, and synthesis, within the specific contexts of cellular structure, molecular biology, and ecology. Each question should require students to apply biological principles to novel scenarios, analyze complex biological systems, or synthesize information from multiple disciplines to arrive at a solution. Ensure that the questions are scientifically accurate, grounded in established biological principles, and reflect current research trends in these areas. For each question, provide a clear, concise, and scientifically valid explanation for the correct answer, detailing how the interdisciplinary nature of biology informs the reasoning. The explanations should not only justify the correct answer but also deepen understanding of the underlying biological concepts, fostering both accuracy and conceptual clarity. Additionally, include specific examples of how higher-order thinking skills are integrated into the questions, such as requiring students to predict outcomes based on molecular interactions, analyze ecological data to infer population dynamics, or synthesize cellular and molecular processes to explain organismal behavior. To optimize the challenge level, ensure that the questions are neither too simplistic nor overly complex, striking a balance that is appropriate for college-level biology students. This approach will ensure the questions are comprehensive, robust, and aligned with the goal of testing advanced cognitive skills in biology while maintaining relevance to the specified topics. Furthermore, refine the prompt to explicitly guide the language model to generate questions that test higher-order thinking skills while maintaining scientific accuracy and relevance to college-level biology. Optimize specific elements of the current prompt to better align with the goal of producing questions that balance challenge and clarity, ensuring they are neither too simplistic nor overly complex. This includes emphasizing the need for questions to be contextually rich, requiring students to integrate multiple biological concepts, and ensuring that the difficulty level is calibrated to challenge students without overwhelming them. The refined prompt should also encourage the generation of questions that are clear, concise, and free from ambiguity, while still requiring deep biological reasoning to arrive at the correct answer. |
🔼 This table presents the final optimized prompt generated by the MARS method for the College Biology questions from the MMLU dataset. The prompt is designed to improve the quality and accuracy of answers by guiding the language model to create multiple-choice questions that assess higher-order thinking skills (application, analysis, synthesis) across various biological contexts (cellular structure, molecular biology, ecology). It emphasizes scientific accuracy, the inclusion of real-world examples and scenarios, clear explanations, and appropriate difficulty levels for college students. The prompt is iteratively refined to improve performance.
read the caption
Table 15: The table shows the final optimized prompt for the College Biology task of MMLU using the MARS method.
| College Medicine |
| Refined Prompt: Analyze the following scenario step by step, integrating interdisciplinary knowledge from biochemistry, sociology, and reasoning to identify the psychological framework that best explains unconscious bias in medical practice… Next, evaluate each option (Behaviorist, Psychoanalytic, Cognitive Behavioral, Humanistic) by considering how well it explains the influence of unconscious bias on clinical decision-making. … To encourage deeper critical thinking, incorporate elements of Socratic questioning by asking probing questions such as… Ensure the prompt is structured clearly and concisely, balancing detailed theoretical explanations with clarity to guide the model effectively toward identifying the correct psychological framework. … To optimize the prompt for generating high-quality, contextually appropriate multiple-choice questions for a college medicine test, incorporate the following elements: 1. Clarity and Precision: 2. Depth and Relevance: 3. Alignment with Learning Objectives: 4. Distractor Quality: 5. Contextual Examples: 6. Theoretical and Practical Balance: By incorporating these elements, the prompt will guide the model to generate questions that are not only accurate and relevant but also aligned with the objectives of a college medicine test, ensuring a high correctness rate and educational value. … Additional Instructions for Generating High-Quality Distractors: Enhancements Based on New Questions:1. Inclusion of Real-World Examples: 2. Iterative Testing and Refinement: By following these steps, the prompt will be continuously improved to generate questions that are both challenging and aligned with the learning objectives of a college medicine test, ensuring that students are effectively tested on their ability to apply interdisciplinary knowledge to real-world medical scenarios involving unconscious bias. Specific Adjustments for Enhanced Critical Analysis and Practical Application:1. Interdisciplinary Integration: 2. Scenario-Based Questions: 3. Critical Thinking Emphasis:4. Practical Mitigation Strategies: By making these adjustments, the prompt will better align with the learning objectives of a college medicine test, ensuring that students are not only tested on foundational knowledge but also challenged to critically analyze and apply interdisciplinary concepts in real-world medical scenarios involving unconscious bias. Further Refinement for Detailed Explanation and High-Quality Distractors: Final Refinement for Enhanced Real-World Application and Iterative Testing: 1. Real-World Application: 2. Iterative Testing and Refinement: By following these steps, the prompt will be continuously improved to generate questions that are both challenging and aligned with the learning objectives of a college medicine test, ensuring that students are effectively tested on their ability to apply interdisciplinary knowledge to real-world medical scenarios involving unconscious bias. Specific Adjustments for Enhanced Real-World Application and Distractor Quality: 1. Interdisciplinary Integration: 2. High-Quality Distractors: By making these adjustments, the prompt will guide the model to generate questions that not only accurately identify the correct psychological framework but also provide a detailed explanation of how unconscious bias manifests in specific medical scenarios and its impact on patient outcomes… |
🔼 This table presents the final optimized prompt generated by the MARS method for the College Medicine task within the MMLU benchmark. The prompt is designed to improve the accuracy and quality of answers by incorporating elements of interdisciplinary knowledge, Socratic questioning techniques, and detailed explanations.
read the caption
Table 16: The table shows the final optimized prompt for the College Medicine task of MMLU using the MARS method.
| Electrical Engineering |
| Analyze the question by focusing on the specific conditions of the Barkhausen criterion for oscillators, which are loop gain and phase shift. … Next, provide a clear, step-by-step explanation of the Barkhausen criterion, emphasizing the two fundamental requirements: 1. Loop gain must be exactly unity for sustained oscillations.2. Phase shift of the feedback signal must be 0° or 360° relative to the input. To enhance understanding, include specific real-world examples, such as the design of an LC oscillator or a phase-locked loop, to illustrate how the Barkhausen criterion is applied in practical scenarios… Proceed to evaluate each option (A, B, C, D) systematically, using the following structure for clarity… For each option, connect the reasoning back to fundamental electrical engineering principles and provide real-world examples or applications where the Barkhausen criterion is critical… Conclude the response by reiterating the correct answer (D) and summarizing its significance in practical electrical engineering applications… To ensure the prompt’s structure and depth enhance the language model’s ability to generate accurate and relevant responses, consider the following adjustments: 1. Clarify the introduction 2. Focus on critical concepts 3. Use structured evaluation: Systematically evaluate each option with clear, logical reasoning and real-world examples to reinforce understanding and relevance. 4. Iterative refinement By structuring the response in this manner and iteratively refining the prompt… Additional Considerations: 1. Influence of Real-World Examples 2. Structural Adjustments Refinement for Multiple-Choice Evaluation: 1. Explicitly state the evaluation criteria 2. Incorporate real-world scenarios 3. Maintain brevity and clarity 4. Highlight key takeaways By refining the prompt in this manner, the language model will be better equipped to… Iterative Refinement Process: 1. Initial Response Generation 2. Review for Accuracy and Relevance 3. Adjust Prompt Accordingly 4. Repeat the Process This iterative approach ensures that the prompt evolves to better guide the language model, resulting in responses that are not only theoretically sound but also practically relevant and aligned with real-world electrical engineering applications. Optimizing the Iterative Refinement Process: 1. Incorporating Feedback Loops: 2. Enhancing Real-World Context: 3. Balancing Depth and Brevity: 4. Focusing on Key Concepts: By implementing these optimizations, the iterative refinement process… Explicit Guidance for Multiple-Choice Evaluation: 1. Explicitly State the Evaluation Criteria 2. Incorporate Real-World Scenarios 3. Maintain Brevity and Clarity 4. Highlight Key Takeaways Adjustments for Balancing Theoretical Depth and Practical Application: 1. Focus on Core Principles 2. Use Structured Evaluation 3. Avoid Overloading with Details 4. Incorporate Real-World Examples By refining the prompt in this manner, the language model will be better equipped to generate responses… Specific Adjustments for Real-World Examples: 1. Demonstrate Practical Implications 2. Highlight Design Considerations 3. Provide Contextual Understanding Balancing Theoretical Depth and Practical Relevance: 1. Integrate Theoretical and Practical Elements 2. Maintain Focus on Core Principles 3. Use Clear, Concise Language By incorporating these adjustments, the prompt will guide the language model to… Influence of Real-World Examples: 1. Illustrate Practical Applications 2. Highlight Consequences of Deviations 3. Provide Contextual Understanding Optimizing the Iterative Refinement Process: 1. Incorporating Feedback Loops 2. Enhancing Real-World Context 3. Balancing Depth and Brevity 4. Focusing on Key Concepts By implementing these optimizations, the iterative refinement process will enhance the language model’s ability to generate responses that are both theoretically accurate and practically relevant, ensuring a high correctness rate and alignment with real-world electrical engineering applications. |
🔼 This table presents the final optimized prompt generated by the MARS method for the Electrical Engineering task within the MMLU dataset. The prompt is designed to guide a large language model towards generating accurate and relevant responses by incorporating specific conditions of the Barkhausen criterion, providing step-by-step explanations, emphasizing key requirements, including real-world examples, using a structured evaluation process, and iteratively refining the prompt based on feedback and performance. The prompt is structured to enhance understanding, ensure clarity, and align with the principles of electrical engineering.
read the caption
Table 17: The table shows the final optimized prompt for the Electrical Engineering task of MMLU using the MARS method.
| High School World History |
| Generate a set of multiple-choice questions that test both factual knowledge and critical analysis of the interconnected historical developments of the Ottoman Empire, economic imperialism, and World War I. Each question should require students to analyze how these events influenced each other, leading to the outbreak of World War I, with a focus on cause-and-effect relationships and broader historical significance. Instructions for Question Design: 1. Interconnectedness and Cause-and-Effect: 2. Accessibility and Rigor: 3. Balanced Difficulty: 4. Critical Thinking and Historical Significance: 5. Format and Contextual Accuracy: Example Question with Passage:: one example Additional Constraints: - Engagement and Relatability: Use engaging and relatable examples or analogies where appropriate to make the questions more accessible and interesting to students. For instance, compare historical events to modern-day scenarios to help students draw parallels. - Depth of Analysis: Include questions that require students to analyze multiple layers of historical causation, such as how economic imperialism not only influenced European powers but also destabilized regions like the Balkans, contributing to the outbreak of World War I. - Historical Contextualization: Ensure that each question provides enough historical context for students to understand the significance of the events being discussed, without overwhelming them with unnecessary details. By following these guidelines, generate a set of 5-10 multiple-choice questions that effectively test students’ understanding of the interconnectedness of the Ottoman Empire’s decline, economic imperialism, and World War I, while promoting critical thinking, historical analysis, and a deeper appreciation of cause-and-effect relationships in history. |
🔼 This table presents the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic Guidance) method for the High School World History task within the MMLU (Massive Multitask Language Understanding) benchmark. The prompt is designed to evaluate students’ understanding of the interconnectedness of the Ottoman Empire’s decline, economic imperialism, and World War I, emphasizing critical analysis and cause-and-effect relationships. The optimized prompt incorporates detailed instructions, guidelines, and examples to enhance the accuracy and effectiveness of the large language model in generating high-quality assessment questions.
read the caption
Table 18: The table shows the final optimized prompt for the High School World History task of MMLU using the MARS method.
| Human Aging |
| Refine the hierarchical elimination process to ensure the model accurately distinguishes between overlapping themes like cognitive decline and personality changes, especially when new terminology such as ’neuroinflammation’ is introduced, by implementing the following steps: 1. Test the Hierarchical Elimination Process with a Sample Question: 2. Optimize the Dynamic Scoring System and Contextual Weighting: 3. Enhance the Focus Identification Protocol with Continuous Learning: 4. Dynamic Evidence Integration with Contextual Weighting: 5. Source Reliability Scoring with Provisional Scoring for Emerging Evidence: 6. Evidence Strength Assessment with Contextual Weighting: 7. Specific Metrics for Question Evaluation: By refining the hierarchical elimination process with these steps and incorporating specific metrics, the model can more effectively navigate overlapping themes in human aging questions, ensuring the highest correctness rate while maintaining precision and contextual relevance. |
🔼 This table presents the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic Guidance) method for the Human Aging task within the MMLU (Massive Multitask Language Understanding) benchmark. The MARS method iteratively refines prompts using a multi-agent system with a Socratic dialogue pattern. The prompt in the table represents the result of this iterative optimization process, aiming to improve the accuracy and effectiveness of Large Language Models (LLMs) in answering questions about human aging.
read the caption
Table 19: The table shows the final optimized prompt for the Human Aging task of MMLU using the MARS method.
| Marketing |
| Analyze the following marketing-related question step by step, considering the principles of segmentation, pricing, market research, and other relevant marketing concepts. Carefully evaluate each of the provided options (A, B, C, D) and select the most suitable answer based on your analysis. Ensure your reasoning is clear and aligns with established marketing theories and practices. For example, if the question involves a hierarchy of effects or sequential model used in advertising, identify the correct model from the options provided and justify your choice. Proceed methodically to arrive at the most accurate answer. |
🔼 This table presents the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic Guidance) method for the Marketing task within the MMLU (Massive Multitask Language Understanding) benchmark. The prompt is designed to guide a large language model (LLM) in answering marketing-related multiple choice questions accurately and efficiently by applying established marketing principles. The optimized prompt likely includes step-by-step instructions, emphasizing logical reasoning and the application of core marketing concepts such as segmentation, pricing, and market research, to ensure the LLM arrives at the correct answer.
read the caption
Table 20: The table shows the final optimized prompt for the Marketing task of MMLU using the MARS method.
| GSM8K |
| Think step by step to solve linguistically diverse elementary school math application problems. Break down the problem into 2-8 logical steps, perform the necessary calculations at each step, and provide the final result. Ensure accuracy by carefully following the problem’s instructions and verifying each intermediate step. For example: Input: Janet’s ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers’ market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers’ market? Step 1: Calculate the total eggs used daily: 3 (eaten) + 4 (baked) = 7 eggs. Step 2: Subtract the used eggs from the total laid: 16 - 7 = 9 eggs. Step 3: Calculate the daily earnings: 9 eggs × 18. Answer: 18 Follow this structured approach to solve similar problems. |
🔼 This table presents the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic Guidance) method for the GSM8K (Grade School Math) task. The optimized prompt is designed to improve the accuracy and efficiency of large language models (LLMs) in solving diverse elementary-level math word problems. It provides a structured approach to problem-solving, guiding the LLM to break down complex problems into smaller, manageable steps, perform necessary calculations, and verify results, ensuring higher accuracy.
read the caption
Table 21: The table shows the final optimized prompt for the GSM8K task using the MARS method.
| LSAT-AR |
| Carefully analyze the given scheduling problem step by step, prioritizing logical reasoning, reading comprehension, and analytical reasoning to ensure a thorough evaluation. Begin by explicitly listing and understanding all the constraints, with a focus on the most critical ones first. Follow this structured approach to systematically eliminate options that violate any of the given conditions: 1. Prioritize the most restrictive constraints first. 2. Evaluate secondary constraints. 3. Assess the implications of Nina’s scheduling. Throughout this process, avoid making assumptions beyond the provided constraints. Do not infer additional rules or conditions that are not explicitly stated. Stick strictly to the given information and apply logical reasoning to interpret and enforce the constraints. By adhering to this structured, methodical approach, you will systematically eliminate incorrect options and arrive at the correct schedule with the highest accuracy. This process mirrors the analytical rigor required in legal reasoning and ensures that the model’s output aligns with the principles of logical and legal analysis. |
🔼 This table presents the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic Guidance) method for the LSAT-AR (Law School Admission Test - Argumentative Reasoning) task within the AGIEval benchmark. The prompt is designed to guide a large language model in solving legal reasoning problems by systematically applying logical reasoning and eliminating options based on given constraints. It emphasizes a structured approach, prioritizing constraints, and avoiding assumptions beyond stated information.
read the caption
Table 22: The table shows the final optimized prompt for the LSAT-AR task of AGIEval using the MARS method.
| Art Studies |
| Please delve into the historical period represented by each option, paying particular attention to major breakthroughs or developments in textile technology and dye processes. First, collate the cultural context and technological advances of each period and analyze which period’s technological achievements are most likely to be relevant to the method of blue print fabric printing. Based on this, the accuracy of the model in answering questions related to these historical and technological contexts is assessed. The output of the model is evaluated by setting specific judgment criteria, such as accurate description of the historical context, sound reasoning about process characteristics, and coherence of conclusions. Based on these criteria, the presentation of the prompts is iteratively adjusted and optimized to improve the model’s performance in selecting correct answers. |
🔼 This table displays the final optimized prompt generated by the MARS method for the Art Studies task within the C-Eval dataset. The prompt is designed to improve the accuracy and effectiveness of large language models in answering questions related to art history and technology by providing clear instructions and emphasizing the importance of considering historical context and technological advancements.
read the caption
Table 23: The table shows the final optimized prompt for the Art Studies task of C-Eval using the MARS method.
| Urban And Rural Planner |
| When optimizing prompts for assessing waste management plans in urban and rural planning, how can identifying aspects of solid pollutant control planning that are less emphasized (e.g., e-pollutants) help us improve our assessment methods? When testing prompts, what specific criteria should we consider to effectively assess their accuracy and relevance with respect to nuances in waste management programs? In addition, how can we ensure that models can accurately understand and prioritize the treatment of different types of waste to effectively guide urban and rural planning decisions? |
🔼 This table presents the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic Guidance) method for the ‘Urban and Rural Planner’ task within the C-Eval benchmark. The MARS method iteratively refines prompts using a multi-agent system and a Socratic dialogue pattern. The optimized prompt is designed to improve the accuracy and relevance of responses when assessing waste management plans in urban and rural planning contexts.
read the caption
Table 24: The table shows the final optimized prompt for the Urban And Rural Planner task of C-Eval using the MARS method.
| Clinical Medicine |
| In order to improve the accuracy of choosing the most appropriate answer in a clinical medicine test question, it is crucial to systematically compare the key symptoms in the question stem with each of the options on a case-by-case basis. The key to this process is to 1) accurately identify diagnosticallysymptoms and features in the question stem, 2) logically assess and eliminate these features based on their association with the options, and 3) apply clinically typical presentations and relevant background knowledge to validate the plausibility of each option. Based on this, the following iterative adjustments should be made: first, by continuously acquiring clinical knowledge to strengthen the identification of difficult symptoms; second, by adjusting the strategy in order to be more flexible in matching potential answers; and finally, by utilizing reflection and evaluating the effectiveness of the model in responding to similar questions over time, to identify and correct deficiencies. This fine-tuning and analysis can increase the probability of choosing the correct answer. |
🔼 This table presents the final optimized prompt generated by the MARS (Multi-Agent framework Incorporating Socratic Guidance) method for the Clinical Medicine task within the C-Eval benchmark. The MARS method iteratively refines prompts using a multi-agent system and Socratic dialogue to improve the accuracy and relevance of large language model responses. This optimized prompt is designed to guide the model to effectively analyze and compare symptoms to select the most appropriate answer in a clinical medicine scenario.
read the caption
Table 25: The table shows the final optimized prompt for the Clinical Medicine task of C-Eval using the MARS method.
Full paper#