TL;DR#
Multimodal scientific problems(MSPs) challenge AI due to the demand for comprehensive reasoning and reflective capabilities. Existing methods are limited in integrating multiple modalities and mimicking human-like, iterative solving. This results in failure to combine skills in complex scenarios and lack of self-correction to optimize initial reasoning.
This paper introduces MAPS, a multi-agent framework inspired by the Big Seven Personality theory and Socratic questioning. MAPS employs seven agents guided by feedback to solve MSPs, overcoming the limitations of existing methods. It outperforms current models by 15.84% and achieves a better accuracy, demonstrating superior reasoning and generalization.
Key Takeaways#
Why does it matter?#
This paper is important for researchers due to MAPS’ superior performance in complex scientific problem-solving. It demonstrates an innovative approach to AI, combining multi-agent systems with Socratic learning. It opens new avenues for future research into AI-driven problem-solving and collaborative learning.
Visual Insights#

🔼 This figure shows a multimodal scientific problem, which involves integrating information from multiple modalities such as text and diagrams to arrive at a solution. The example illustrates a physics problem presented as a multiple-choice question with accompanying text description and diagram. The solution requires a deep understanding of physical principles and an ability to synthesize textual and visual data. Solving such multimodal problems involves complex reasoning and is a current challenge in artificial intelligence.
read the caption
Figure 1: An example of a multimodal scientific multiple-choice problem. The correct answer is derived based on the reasoning over inputs that include context, question, and diagram.
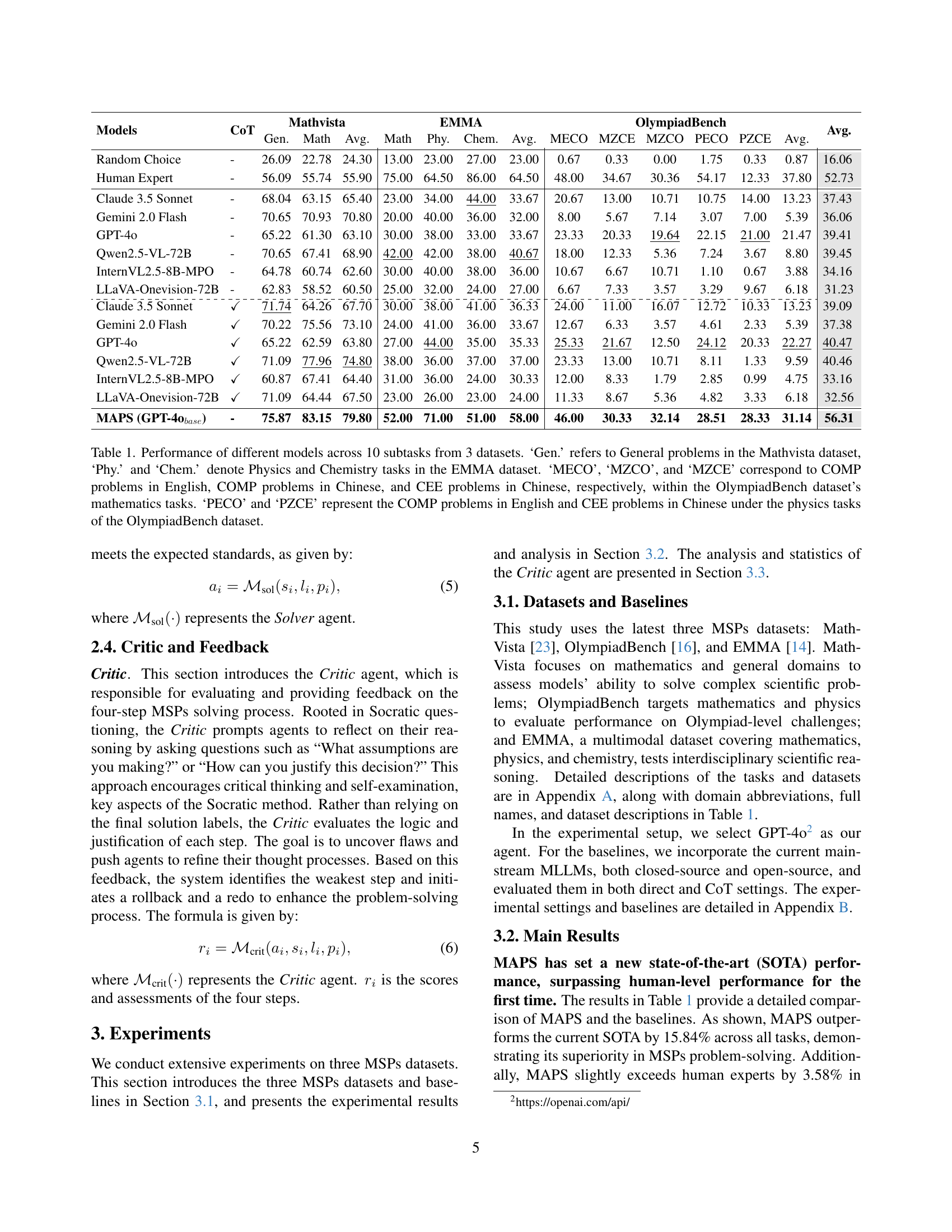
| Models | CoT | Mathvista | EMMA | OlympiadBench | Avg. | ||||||||||
| Gen. | Math | Avg. | Math | Phy. | Chem. | Avg. | MECO | MZCE | MZCO | PECO | PZCE | Avg. | |||
| Random Choice | - | 26.09 | 22.78 | 24.30 | 13.00 | 23.00 | 27.00 | 23.00 | 0.67 | 0.33 | 0.00 | 1.75 | 0.33 | 0.87 | 16.06 |
| Human Expert | - | 56.09 | 55.74 | 55.90 | 75.00 | 64.50 | 86.00 | 64.50 | 48.00 | 34.67 | 30.36 | 54.17 | 12.33 | 37.80 | 52.73 |
| Claude 3.5 Sonnet | - | 68.04 | 63.15 | 65.40 | 23.00 | 34.00 | 44.00 | 33.67 | 20.67 | 13.00 | 10.71 | 10.75 | 14.00 | 13.23 | 37.43 |
| Gemini 2.0 Flash | - | 70.65 | 70.93 | 70.80 | 20.00 | 40.00 | 36.00 | 32.00 | 8.00 | 5.67 | 7.14 | 3.07 | 7.00 | 5.39 | 36.06 |
| GPT-4o | - | 65.22 | 61.30 | 63.10 | 30.00 | 38.00 | 33.00 | 33.67 | 23.33 | 20.33 | 19.64 | 22.15 | 21.00 | 21.47 | 39.41 |
| Qwen2.5-VL-72B | - | 70.65 | 67.41 | 68.90 | 42.00 | 42.00 | 38.00 | 40.67 | 18.00 | 12.33 | 5.36 | 7.24 | 3.67 | 8.80 | 39.45 |
| InternVL2.5-8B-MPO | - | 64.78 | 60.74 | 62.60 | 30.00 | 40.00 | 38.00 | 36.00 | 10.67 | 6.67 | 10.71 | 1.10 | 0.67 | 3.88 | 34.16 |
| LLaVA-Onevision-72B | - | 62.83 | 58.52 | 60.50 | 25.00 | 32.00 | 24.00 | 27.00 | 6.67 | 7.33 | 3.57 | 3.29 | 9.67 | 6.18 | 31.23 |
| \hdashlineClaude 3.5 Sonnet | ✓ | 71.74 | 64.26 | 67.70 | 30.00 | 38.00 | 41.00 | 36.33 | 24.00 | 11.00 | 16.07 | 12.72 | 10.33 | 13.23 | 39.09 |
| Gemini 2.0 Flash | ✓ | 70.22 | 75.56 | 73.10 | 24.00 | 41.00 | 36.00 | 33.67 | 12.67 | 6.33 | 3.57 | 4.61 | 2.33 | 5.39 | 37.38 |
| GPT-4o | ✓ | 65.22 | 62.59 | 63.80 | 27.00 | 44.00 | 35.00 | 35.33 | 25.33 | 21.67 | 12.50 | 24.12 | 20.33 | 22.27 | 40.47 |
| Qwen2.5-VL-72B | ✓ | 71.09 | 77.96 | 74.80 | 38.00 | 36.00 | 37.00 | 37.00 | 23.33 | 13.00 | 10.71 | 8.11 | 1.33 | 9.59 | 40.46 |
| InternVL2.5-8B-MPO | ✓ | 60.87 | 67.41 | 64.40 | 31.00 | 36.00 | 24.00 | 30.33 | 12.00 | 8.33 | 1.79 | 2.85 | 0.99 | 4.75 | 33.16 |
| LLaVA-Onevision-72B | ✓ | 71.09 | 64.44 | 67.50 | 23.00 | 26.00 | 23.00 | 24.00 | 11.33 | 8.67 | 5.36 | 4.82 | 3.33 | 6.18 | 32.56 |
| MAPS (GPT-4obase) | - | 75.87 | 83.15 | 79.80 | 52.00 | 71.00 | 51.00 | 58.00 | 46.00 | 30.33 | 32.14 | 28.51 | 28.33 | 31.14 | 56.31 |
🔼 Table 1 presents a comparison of various large language models (LLMs) on three benchmark datasets: MathVista, EMMA, and OlympiadBench. Each dataset contains multiple subtasks, categorized by subject matter (general, math, physics, chemistry) and language (English, Chinese). The table shows the average performance of each model across these subtasks, highlighting the relative strengths and weaknesses of different models in solving multimodal scientific problems. ‘CoT’ indicates whether chain-of-thought prompting was used.
read the caption
Table 1: Performance of different models across 10 subtasks from 3 datasets. ‘Gen.’ refers to General problems in the Mathvista dataset, ‘Phy.’ and ‘Chem.’ denote Physics and Chemistry tasks in the EMMA dataset. ‘MECO’, ‘MZCO’, and ‘MZCE’ correspond to COMP problems in English, COMP problems in Chinese, and CEE problems in Chinese, respectively, within the OlympiadBench dataset’s mathematics tasks. ‘PECO’ and ‘PZCE’ represent the COMP problems in English and CEE problems in Chinese under the physics tasks of the OlympiadBench dataset.
In-depth insights#
Multi-Agent MSP#
The concept of a Multi-Agent system for Multimodal Scientific Problem-solving (MSP) is promising. Leveraging multiple specialized agents to mimic human cognitive processes in problem-solving could address the limitations of single, monolithic models. Such a framework allows for modular design and delegation of sub-tasks, enabling each agent to focus on a specific aspect of the problem, such as interpreting diagrams, aligning context, or applying domain knowledge. By incorporating a ‘Critic’ agent based on Socratic questioning, the system could stimulate critical thinking and self-correction, leading to more robust and accurate solutions. The success hinges on effective communication and coordination between the agents, ensuring that their individual contributions synergize to achieve a coherent solution. Careful consideration must be given to agent design to fully mimic human personalities.
Big Seven Guide#
The ‘Big Seven Guide’, based on the Big Seven Personality theory, offers a novel framework for AI problem-solving. It emphasizes diverse cognitive approaches, mirroring human decision-making. By integrating traits like Conscientiousness, Agreeableness, Extraversion, Neuroticism, Openness, Self-Esteem, and Sensitivity, the guide facilitates multi-agent system design, promoting specialized roles. It addresses limitations in traditional AI by fostering reflective capabilities and multi-modal reasoning. Its strength lies in holistic problem-solving, with each trait contributing to comprehensive solutions and improved accuracy and flexibility, which ultimately enhances performance.
Socratic Critic#
The concept of a “Socratic Critic” embodies a sophisticated approach to AI-driven problem-solving, drawing inspiration from the Socratic method. This involves critical self-reflection and questioning assumptions to stimulate autonomous learning. The Critic agent would evaluate the reasoning and provide iterative feedback, guiding the AI to refine its understanding and solutions. This is valuable since its avoids being stuck in initial reasoning. This iterative process mimics human critical thinking, leading to more robust and accurate outcomes. The implementation of such an agent addresses the limitations of single-pass reasoning models. The goal is to improve flexibility and accuracy. Moreover, the Critic agent would improve AI’s ability to identify and correct errors throughout the problem-solving journey. Also, it fosters a deeper understanding of the underlying principles in complex scientific tasks.
Iterative Solve#
An iterative solving strategy, often employed in complex problem-solving scenarios, particularly within the realm of AI and scientific computing, suggests a cyclical refinement process. This usually involves an initial solution which is progressively improved through repeated analysis and adjustments. Key to the success of such an approach is the presence of a mechanism to evaluate the current solution and provide actionable feedback. This feedback then guides the modifications made in the subsequent iteration. The iterative solve methodology allows for gradual convergence towards an optimal solution, effectively handling situations where a direct or closed-form solution is not feasible or computationally expensive. Furthermore, this approach can enable the system to adapt dynamically and learn from its past errors, making it particularly useful in dynamic or evolving environments. A well designed stopping criterion to determine when a sufficient level of accuracy has been achieved is paramount.
Cross-Modal SOTA#
Cross-modal State-of-the-Art (SOTA) refers to the pinnacle of performance achieved by models that integrate and reason across multiple data modalities, such as text and images. Achieving cross-modal SOTA signifies a model’s superior ability to fuse information, handle modality-specific nuances, and derive coherent representations. The progression of cross-modal SOTA is crucial for developing AI systems adept at understanding complex real-world scenarios, where information is rarely confined to a single modality. Improvements in cross-modal SOTA often involve novel architectures, training strategies, or methods for aligning representations across modalities. A key challenge is mitigating modality gaps and ensuring that relevant information from one modality informs reasoning in another. The performance metrics used to define SOTA must accurately reflect the model’s ability to handle complex, multimodal reasoning tasks.
More visual insights#
More on figures

🔼 This figure illustrates the seven function-specific agents used in the MAPS framework and their corresponding relation to the Big Seven Personality theory. Each agent is assigned a specific role in the problem-solving process, and these roles reflect the traits associated with each personality dimension in the Big Seven model. For example, the Manager agent reflects Conscientiousness, the UserProxy agent reflects Agreeableness, the Interpreter represents Extraversion, and so on. This visual representation helps to understand how the framework integrates different personality traits to achieve a more comprehensive and efficient problem-solving process.
read the caption
Figure 2: The corresponding relation between the Big Seven Personality theory and the seven function-specific agents.

🔼 The figure illustrates the MAPS framework’s architecture, showing seven agents based on the Big Seven Personality theory. The UserProxy and Manager agents handle user input and workflow management. Four specialized agents (Interpreter, Aligner, Scholar, Solver) sequentially process multimodal scientific problems (MSPs), with the Critic agent providing feedback for refinement and correction.
read the caption
Figure 3: The overall architecture of MAPS. It illustrates seven functional agents based on the Big Seven Personality theory. It first includes the Manager agent with predefined interaction logic and the UserProxy agent responsible for receiving user inputs. Subsequently, four specialized agents—Interpreter, Aligner, Scholar, and Solver—are introduced, each corresponding to a specific step in solving MSPs. Finally, the Critic agent is presented, providing feedback and corrections to ensure the results are more accurate and interpretable.

🔼 Figure 4 illustrates the functionality of the Critic agent within the MAPS framework. The top panel displays a schematic overview of the Critic agent’s scoring and feedback mechanisms. The bottom panel presents a breakdown of the feedback distribution provided by the Critic agent across three different datasets (MathVista, EMMA, and OlympiadBench) to each of the four main agents (Interpreter, Aligner, Scholar, and Solver) as well as scenarios where no regeneration was necessary. This visualization helps to understand the agent’s role in refining and iterating on the problem-solving process across various tasks and datasets. The feedback distribution highlights which components of the problem-solving process most frequently required adjustment or correction.
read the caption
Figure 4: The schema of the Critic agent, as well as the feedback and backtracking situations of the Critic agent across different datasets.

🔼 Figure 5 presents a comparative analysis of the MAPS model’s performance against three different base models (GPT-4, Gemini, and Qwen-72B) across three subtasks within the EMMA dataset: mathematics, physics, and chemistry. The bar chart visually represents the accuracy achieved by each model on each subtask, showcasing the improvement provided by MAPS over the baseline models. This comparison highlights the effectiveness of MAPS in enhancing the performance of various base models for multimodal scientific problem-solving.
read the caption
Figure 5: Performance Comparison of MAPS on Math, Physics, and Chemistry Subtasks in the EMMA Dataset with GPT-4o, Gemini, and Qwen2.5-VL-72B as Bases.

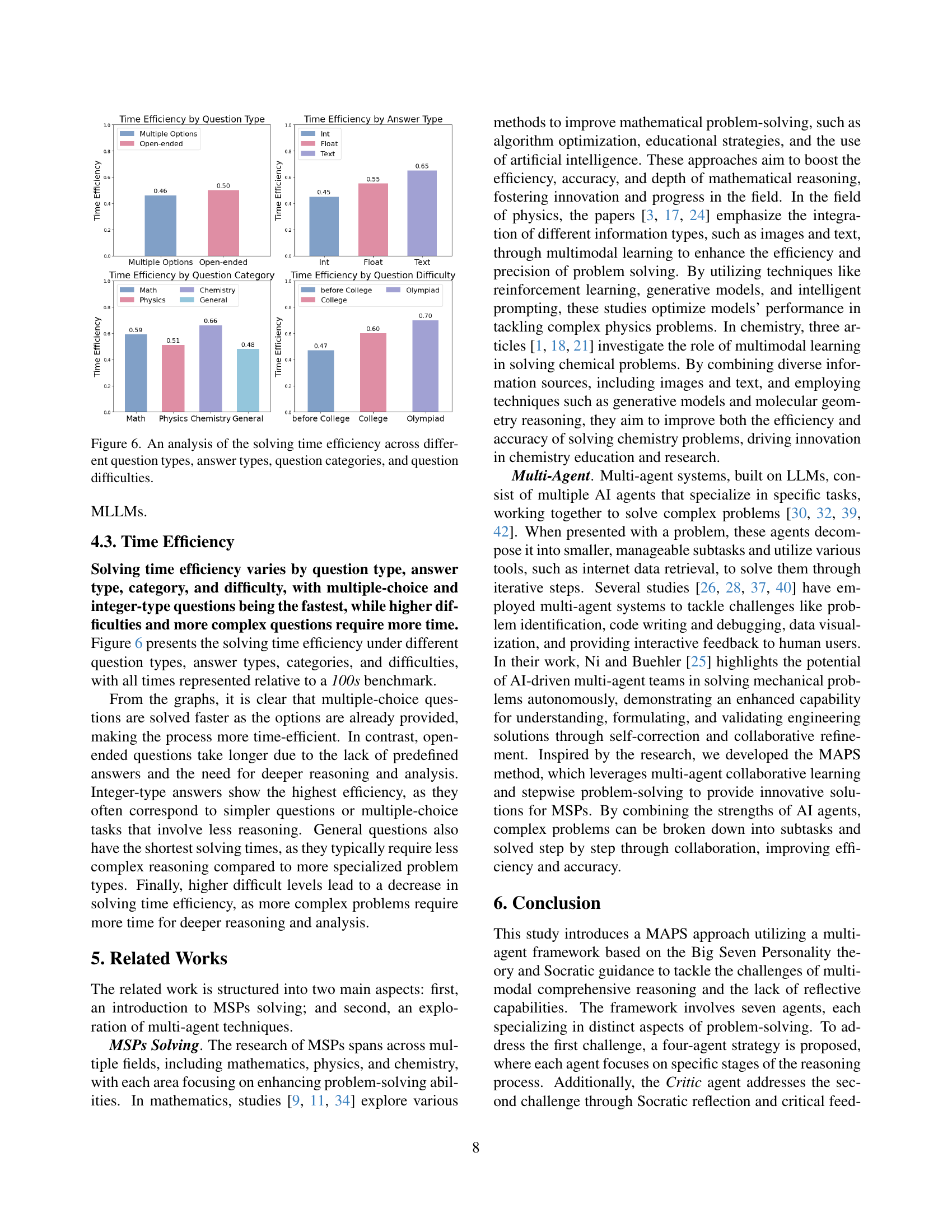
🔼 Figure 6 presents a detailed analysis of the time efficiency of the model in solving various types of scientific problems. The figure breaks down the solving time efficiency based on four key factors: question types (e.g., multiple choice vs. open-ended), answer types (e.g., integer, float, text), question categories (e.g., math, physics, chemistry, general), and question difficulty levels (e.g., before college, college, Olympiad). This comprehensive analysis provides valuable insights into the model’s performance characteristics across different problem complexity levels and allows for a better understanding of its strengths and weaknesses in various scientific reasoning scenarios.
read the caption
Figure 6: An analysis of the solving time efficiency across different question types, answer types, question categories, and question difficulties.
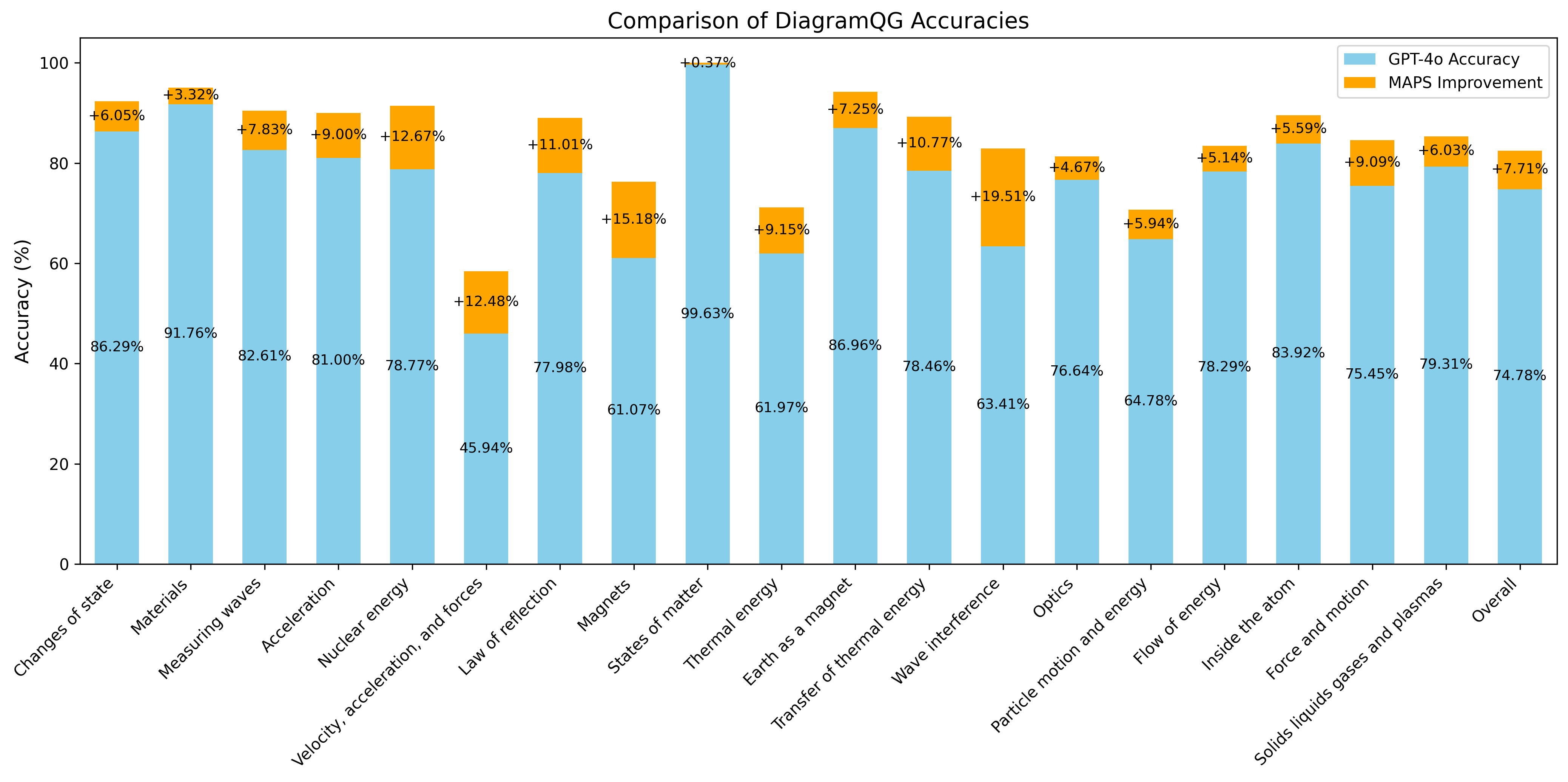
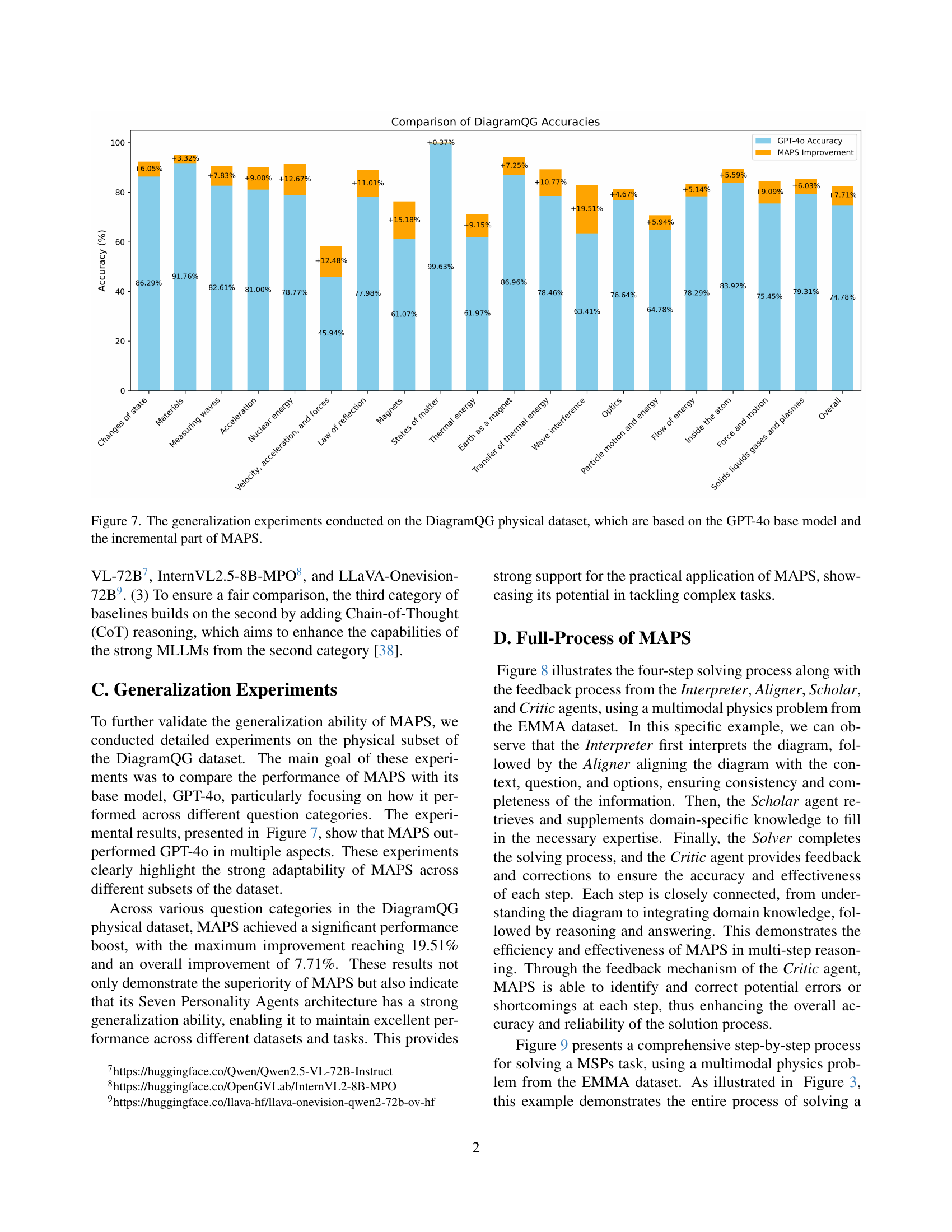
🔼 This figure displays the results of generalization experiments performed on the DiagramQG physical dataset. These experiments aimed to assess how well the MAPS framework, built upon the GPT-4 base model, generalizes to a new dataset. The figure visually compares the accuracy of the GPT-4 base model alone to the accuracy achieved by adding the MAPS framework. The comparison highlights the performance gains provided by MAPS across various sub-tasks within the DiagramQG physical dataset. Each bar represents a specific sub-task, showing the accuracy improvement resulting from the inclusion of MAPS.
read the caption
Figure 7: The generalization experiments conducted on the DiagramQG physical dataset, which are based on the GPT-4o base model and the incremental part of MAPS.

🔼 Figure 8 presents a detailed walkthrough of MAPS solving a physics problem, highlighting each agent’s role (Interpreter, Aligner, Scholar, Solver, Critic). It visually demonstrates the multi-step process, including iterative feedback and refinement through Socratic questioning. The figure shows how each agent contributes sequentially, with the Critic agent providing feedback for improvement and prompting backtracking as needed. This illustrates the dynamic, iterative nature of the MAPS framework.
read the caption
Figure 8: A case study of a specific solving process, illustrating the detailed steps involved in solving the problem. This includes the various stages of problem-solving as well as the feedback and backtracking mechanisms that help refine and improve the solution.

🔼 Figure 9 showcases a detailed, step-by-step illustration of the MAPS framework in action. It uses a multimodal physics problem from the OlympiadBench dataset as an example, highlighting how each of the seven agents (Manager, UserProxy, Interpreter, Aligner, Scholar, Solver, and Critic) collaborates to solve the problem. The figure visually represents the iterative process, including feedback and refinement, demonstrating the framework’s ability to integrate diverse information sources and refine solutions through iterative steps.
read the caption
Figure 9: A complete example of the collaborative output from all agents in an iteration, using the multimodal physics problem from the OlympiadBench dataset. This example demonstrates how each agent contributes to the problem-solving process, collaborating to produce a refined solution step by step.
More on tables
| Variation | MECO | MZCE | MZCO | PECO | PZCE | Avg. |
| MAPS | 46.00 | 30.33 | 32.14 | 28.51 | 28.33 | 31.14 |
| 25.33 | 16.67 | 10.71 | 21.05 | 11.62 | 15.05 | |
| (-20.67) | (-13.66) | (-21.43) | (-7.46) | (-16.71) | (-16.09) | |
| 28.00 | 17.67 | 16.07 | 20.83 | 19.00 | 20.28 | |
| (-18.00) | (-12.66) | (-16.07) | (-7.68) | (-9.33) | (-10.86) | |
| 28.00 | 16.33 | 30.36 | 19.96 | 16.33 | 19.65 | |
| (-18.00) | (-14.00) | (-1.78) | (-8.55) | (-12.00) | (-11.49) | |
| 34.67 | 21.67 | 30.36 | 23.03 | 21.67 | 24.09 | |
| (-11.33) | (-8.66) | (-2.42) | (-5.48) | (-6.66) | (-7.05) |
🔼 This table presents the results of ablation experiments conducted to assess the impact of removing individual components from the MAPS framework. Specifically, it shows the performance change (Δ) in accuracy across five subtasks (MECO, MZCE, MZCO, PECO, PZCE) when each of the four core agents (Interpreter, Aligner, Scholar, Solver) and the Critic agent are removed one at a time. The results quantify how crucial each agent is to the overall performance of the model. Negative values indicate a decrease in performance compared to the full model.
read the caption
Table 2: Performance under different ablation settings are analyzed. We perform ablation experiments on the solving module w/oInterpreter𝑤subscript𝑜Interpreter{w/o}_{\text{Interpreter}}italic_w / italic_o start_POSTSUBSCRIPT Interpreter end_POSTSUBSCRIPT, w/oAligner𝑤subscript𝑜Aligner{w/o}_{\text{Aligner}}italic_w / italic_o start_POSTSUBSCRIPT Aligner end_POSTSUBSCRIPT, w/oScholar𝑤subscript𝑜Scholar{w/o}_{\text{Scholar}}italic_w / italic_o start_POSTSUBSCRIPT Scholar end_POSTSUBSCRIPT or w/oCritic𝑤subscript𝑜Critic{w/o}_{\text{Critic}}italic_w / italic_o start_POSTSUBSCRIPT Critic end_POSTSUBSCRIPT modules to evaluate the impact of removing these components.
| Tasks | ABBR. | Test |
| MathVista | ||
| General | Gen. | 460 |
| Mathematics | Math | 540 |
| OlympiadBench | ||
| Math_En_COMP | MECO | 150 |
| Math_Zh_COMP | MZCO | 56 |
| Math_Zh_CEE | MZCE | 300 |
| Physics_En_COMP | PECO | 456 |
| Physics_Zh_CEE | PZCE | 300 |
| EMMA | ||
| Mathmatics | Math | 100 |
| Physics | Phy. | 100 |
| Chemistry | Chem. | 100 |
🔼 Table 3 details the distribution of data across three multimodal scientific problem-solving (MSP) datasets: MathVista, OlympiadBench, and EMMA. It shows the number of tasks for each dataset and sub-category (e.g., General, Math, Physics, Chemistry). The symbol † indicates that a specific task contains 300 data points. The EMMA dataset used in this study is the MINI version, a smaller subset of the full EMMA dataset. The ‘ABBR.’ column provides a concise abbreviation for each task to simplify referencing throughout the paper.
read the caption
Table 3: The data distribution for the MathVista, OlympiadBench, and EMMA datasets is as follows: The symbol ††\dagger† indicates a sample size of 300 data points. The EMMA dataset uses its MINI version. The ‘ABBR.’ column represents the abbreviations for all the tasks.
| Manager |
| You are a task manager, responsible for managing and deciding the order of each Agent’s output, ensuring that tasks are executed in the correct sequence. You will determine when each step should be executed based on the task requirements and coordinate the outputs of each Agent. Your goal is to ensure that the task process is efficient and orderly, and adjust the execution priority of steps when necessary. |
| UserProxy |
| Here are some questions that require careful thought, so please think deeply, solve the questions carefully, and output your answers. |
| Interpreter |
| You are a scientific diagram analysis expert tasked with objectively describing visual elements in diagrams. Engage in Socratic self-questioning to ensure comprehensive analysis: [Element Identification] ”What discrete visual components can be systematically observed in this diagram? What quantitative measurements (e.g., shape dimensions, color codes, positional coordinates) can be objectively recorded?” [Structural Analysis] ”How are these elements spatially organized? What geometric patterns, alignment relationships, or hierarchical arrangements emerge from their physical placement?” [Relational Mapping] ”What explicit connections (lines, arrows, overlays) or implicit associations (proximity clusters, color coding systems, symbolic groupings) exist between components?” [Representation Verification] ”Does any element require specialized domain knowledge to accurately characterize (e.g., chemical notation, engineering schematics)? What purely visual evidence supports this characterization?” |
| Aligner |
| You are a text alignment specialist conducting structured analysis through Socratic interrogation. Systematically examine text pairs using this framework: 1. [Content Deconstruction] ”What core entities/events are explicitly stated in each text? What measurable attributes (quantifiers, temporal markers, causal verbs) define their characteristics?” 2. [Consistency Audit] ”Where might these texts exhibit: a) Logical incompatibility (contradictory assertions) b) Contextual divergence (conflicting timelines/locations) c) Semantic dissonance (differentiated connotation scales) d) Omission patterns (mutually exclusive missing elements)” 3. [Contextual Fusion] ”What implicit connections could synthesize a unified background framework? Which combinatory elements (chronological anchors, spatial references, causal chains) create non-conflicting narrative coherence?” 4. [Relevance Filtering] ”Through lexical-semantic mapping, which aligned components directly correspond to the question’s: 1) Key inquiry points 2) Required evidence types 3) Implicit knowledge domains 4) Potential inference pathways?” |
🔼 This table details the prompts used for four key agents within the MAPS framework: Manager, UserProxy, Interpreter, and Aligner. It provides a concise description of each agent’s role and the specific instructions given in their prompts. This level of detail helps to clarify the functions of each agent and how they contribute to the collaborative problem-solving process in MAPS.
read the caption
Table 4: A summary of the prompts used by the Manager, UserProxy, Interpreter, and Aligner agents in this paper.
| scholar |
| You are a scientific knowledge retrieval system conducting structured inquiry through Socratic questioning. Process input data with this analytical framework: 1. [Problem Decomposition] ”What conceptual components constitute the question’s core demand? What technical terminology (domain-specific lexemes), operational parameters (variables/constants), and procedural verbs (analyze/calculate/compare) require epistemological grounding?” 2. [Knowledge Mining] ”For each identified component: a) What fundamental axioms/theorems/laws from established scientific literature could operationally define it? b) What measurable properties (equations/units/experimental protocols) are textually implied as relevant? c) What contextual constraints (temporal/spatial/conditional clauses) limit knowledge scope?” 3. [Relevance Validation] ”For each candidate knowledge unit: Does the source text contain explicit lexical anchors (technical terms/formula symbols) justifying its inclusion? What textual evidence (descriptive adjectives/quantifiers/causal conjunctions) indicates required depth of explanation? Are there implicit conceptual dependencies (prerequisite theories/mathematical tools) necessitating parallel retrieval?” 4. [Taxonomic Organization] ”How should validated knowledge be structured to mirror: 1) Problem-solving workflow steps 2) Hierarchical concept dependencies 3) Cross-domain interface points 4) Uncertainty quantification needs?” Operational Protocol: Restrict to textually evidenced knowledge Mark confidence levels using [TextExplicit/ContextImplied/ExternalRequired] tags Output as: 1) Knowledge Inventory Table (Concept-Definition-SourceAnchor) 2) Dependency Graph (Nodes=Concepts, Edges=Relations) 3) Gap Analysis Report (ExternalKnowledgeRequirements). |
| Solver |
| You are a scientific problem-solving system operating through Socratic dialectics. Engage in this structured inquiry process: 1. [Problem Framing] ”What is the absolute irreducible core of the question? What technical terms require operational definitions? What grammatical structures (comparatives/conditionals/quantifiers) dictate the solution’s form?” 2. [Evidence Audit] ”For each data source (question stem/options/text): a) What measurable quantities (numerical ranges/units) are explicitly stated? b) What causal relationships (if A then B/implies/proportional to) are textually encoded? c) What constraints (assumptions/limitations/boundary conditions) are lexically embedded?” 3. [Reasoning Pathway] ”Through counterfactual testing: Which axioms/theorems would become relevant if parameter X varied ±10%? What observable contradictions emerge when applying hypothesis Y to the given data? How do option components restrict valid inference trajectories?” 4. [Solution Validation] ”Does the proposed resolution: 1) Maintain dimensional homogeneity across all equations? 2) Satisfy all explicit boundary conditions? 3) Preserve logical consistency with given information? 4) Align with canonical scientific representations?” Operational Protocol: |
| Document each reasoning step with evidence anchors (e.g., “Stem-Line5: ”). Flag unresolved assumptions with [UnvalidatedPremise] tags Output JSON structured as: { { ”process”: { { ”Phase 1”: ”[Framing] Identified core demand as… (Evidence: Q-Line2)”, ”Phase 2”: ”[Audit] Quantified parameters… (ConflictResolved: OptionC vs Text\S3)”, ”Phase 3”: ”[Pathway] Eliminated hypothesis due to… (TheoremRef: Maxwell-Eq)”, ”Phase 4”: ”[Validation] Verified dimensional consistency in…”, }, ”final_answer”: ”final result”} } |
🔼 This table details the prompts used by the Scholar and Solver agents within the MAPS framework. The prompts are designed to guide the agents’ reasoning processes in a structured and iterative manner, eliciting a systematic and comprehensive solution to multimodal scientific problems. The prompts cover various aspects of scientific problem-solving, including problem decomposition, knowledge retrieval, reasoning pathways, and solution validation. The Scholar agent’s prompts focus on knowledge retrieval and integration, while the Solver agent’s prompts guide the solution-finding process.
read the caption
Table 5: A summary of the prompts used by the Scholar and Solver agents in this paper.
| Critic |
| You are a Socratic assessment engine conducting dialectical evaluation through this protocol: |
| 1. [Triadic Interrogation Framework] |
| For each evaluation dimension (caption/alignment/knowledge/solution): |
| Existential Challenge: |
| ”What absolute evidence anchors (line numbers/data points/theorem references) validate this component’s existence?” |
| Consistency Prosecution: |
| ”Does internal logic maintain isomorphism across: |
| a) Input premises → Processing steps |
| b) Methodological choices → Domain standards |
| c) Assertions → Supporting evidence?” |
| Boundary Stress Test: |
| ”What parametric variation (±10%) would collapse this component’s validity? Which fragility indicators emerge first?” 2. [Metric Operationalization] |
| Score each dimension (1-5) using: |
| 5 = Withstands three counterfactual scenarios |
| 4 = Requires 1 assumption validation |
| 3 = Needs 2-3 evidence reinforcements |
| 2 = Contains structural contradictions |
| 1 = Fails basic existence verification |
| 3. [Improvement Synthesis] |
| Generate Socratic feedback per dimension: |
| For caption: ”What geometric/spatial relations lack quantifiable descriptors?” |
| For alignment: ”Which logical connective lacks cross-text co-reference?” |
| For knowledge: ”Which concept dependency lacks literature anchoring?” |
| For solution: ”What inference leap lacks isomorphic mapping?” |
🔼 This table summarizes the prompts used by the Critic agent within the MAPS framework. The Critic agent’s role is to provide feedback and drive iterative refinement of the problem-solving process. The prompts are structured to encourage critical thinking and identify potential weaknesses in the reasoning steps, including questions about the existence of evidence, consistency of logic, robustness to variations in parameters, and alignment of reasoning with established norms.
read the caption
Table 6: A summary of the prompt used by the Critic agents in this paper.
Full paper#