TL;DR#
Creating realistic 3D talking avatars is crucial for AR/VR applications. Existing methods struggle with fine-grained control of facial expressions and body movements, lack sufficient detail, and can’t run in real-time on mobile devices. Current solutions are also depend on high-precision scans and manual effort.
This paper presents TaoAvatar, a new method using 3D Gaussian Splatting for high-fidelity, lightweight full-body talking avatars. It employs a teacher-student framework for non-rigid deformation baking and introduces lightweight blend shapes for efficient rendering on mobile devices. The authors also introduce TalkBody4D, a new dataset for full-body talking scenarios.
Key Takeaways#
Why does it matter?#
This paper is important for researchers as it presents a novel method for creating high-fidelity, real-time full-body talking avatars, addressing the limitations of existing methods. The new dataset will help advance research, and the potential applications, especially in AR, are significant. This work opens avenues for future research in efficient avatar rendering and animation.
Visual Insights#

🔼 This figure demonstrates the TaoAvatar system’s pipeline. (a) shows the input: multiple views of a person captured from different angles. (b) shows the output: a photorealistic, full-body, 3D avatar that can be manipulated in real-time, featuring realistic facial expressions and body movements. This avatar is topologically consistent, meaning its 3D structure is accurate and reliable. Finally, (c) shows that this avatar is runnable on various AR devices such as Apple Vision Pro, making it highly portable and accessible. The system achieves high-quality rendering at real-time speeds with low storage needs.
read the caption
Figure 1: TaoAvatar generates photorealistic, topology-consistent 3D full-body avatars from multi-view sequences. It provides high-quality, real-time rendering with low storage requirements, compatible across various mobile and AR devices like the Apple Vision Pro.
| Novel View | Novel Gestures and Expression | Speed | |||||
| Model | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | FPS |
| GaussianAvatar[20] | 26.58 (23.57) | .9313 (.8159) | .10577 (.25242) | 25.99 (23.15) | .9232 (.8092) | .12265 (.26207) | 54 |
| 3DGS-Avatar[46] | 28.91 (23.95) | .9411 (.8303) | .07984 (.20450) | 26.46 (23.32) | .9157 (.8184) | .11804 (.21632) | 55 |
| MeshAvatar[10] | 28.53 (24.55) | .9360 (.8083) | .09470 (.25572) | 27.08 (23.58) | .9229 (.7965) | .10783 (.24947) | 22 |
| AnimatableGS[34] | 32.50 (26.42) | .9599 (.8587) | .06695 (.19535) | 28.05 (23.68) | .9328 (.8142) | .09191 (.22673) | 16 |
| Ours (Teacher) | 33.45 (27.01) | .9649 (.8741) | .04986 (.15613) | 28.28 (24.28) | .9336 (.8291) | .07385 (.18176) | 16 |
| Ours (Student) | 33.81 (27.80) | .9689 (.8975) | .06437 (.14218) | 28.38 (24.99) | .9389 (.8525) | .08874 (.13364) | 156 |
🔼 This table presents a quantitative comparison of different methods for generating full-body talking avatars. Metrics include PSNR, SSIM, and LPIPS, evaluating both overall image quality and the quality of the facial region specifically. Inference speed (frames per second, or FPS) is also reported, using an Nvidia RTX4090 GPU at a rendering resolution of 1500x2000 pixels.
read the caption
Table 1: Quantitative comparisons on full-body talking task. The results inside the parentheses are evaluated for the face area, and the inference speed is evaluated on Nvidia RTX4090 when rendering images at a resolution of 1500 × 2000.
In-depth insights#
Lifelike Avatars#
Lifelike avatars represent a significant pursuit in computer graphics and AR/VR, aiming to create digital representations that closely mimic real humans. This involves capturing realistic appearance, motion, and behavior. Challenges include achieving high fidelity in rendering, accurately capturing subtle facial expressions and body language, and ensuring real-time performance, especially on mobile devices. Advances in 3D scanning, neural rendering (NeRFs), and 3D Gaussian Splatting (3DGS) are driving progress. Key considerations are topology consistency, detail preservation, and computational efficiency for seamless integration into interactive applications. The creation of such avatars also brings ethical concerns around identity and authenticity.
3DGS & SMPLX++#
Combining 3D Gaussian Splatting (3DGS) and SMPLX++ models for realistic avatar creation is a smart move. 3DGS excels at high-quality rendering and real-time performance, while SMPLX++ provides a parametric human model with clothes and hair. This pairing can result in detailed and animatable avatars. The challenge lies in efficiently integrating these two different representations. One way to integrate them would be using 3DGS to enhance the visual realism of SMPLX++ avatars. Another approach would be to use SMPLX++ to guide the placement and deformation of Gaussians in the 3DGS scene. Another major issue is optimizing the model for real-time performance on mobile devices. Efficient data structures and rendering techniques are essential. Also, the model needs to be robust to varying lighting conditions and viewpoints. Addressing these challenges could lead to significant advancements in avatar technology.
Distill Deform#
The concept of ‘Distill Deform,’ likely refers to a process where a complex deformation field or model is simplified into a more manageable representation, often for efficiency. This distillation could involve transferring knowledge from a larger, high-capacity model (teacher) to a smaller, more efficient model (student). The deformation itself might be represented initially by a neural network with many layers, and the distillation step aims to compress this representation. Another part may involve extracting the most salient features and discarding less important information. This could involve techniques like parameter pruning, knowledge distillation, or even approximating the deformation with a simpler functional form. The goal here is to achieve a balance between accuracy and computational efficiency, making the model more suitable for real-time applications or deployment on resource-constrained devices. The ‘Distill Deform’ process is crucial for creating practical solutions that can perform well without being overly complex.
AR on Mobile#
While the provided document doesn’t explicitly discuss “AR on Mobile,” its content strongly implies the challenges and advancements in enabling augmented reality experiences on mobile devices. Key considerations revolve around computational constraints. Mobile AR demands lightweight algorithms and efficient rendering techniques like 3D Gaussian Splatting, essential for real-time performance. High-fidelity avatars, as presented in the paper, require intricate detail, making optimization crucial for mobile deployment. The method of teacher-student learning is an intelligent way to distill complex models into smaller networks. These networks will not be computationally expensive, making them easier to deploy for AR in mobile. Another important aspect is sensor input.
TalkingBody4D#
TalkBody4D represents a novel dataset tailored for full-body talking avatar research. It seems to address the limitations of existing datasets by focusing on realistic, everyday talking scenarios. A key strength lies in capturing rich mouth movements and diverse gestures synchronized with audio, crucial for lifelike avatar behavior. This contrasts with datasets emphasizing general motion, potentially lacking the nuances of conversational body language. The dataset’s multi-view nature (60 views) and high resolution (4K) are significant, allowing for detailed model training and evaluation. The inclusion of both full-body and face-region views suggests an understanding of the importance of both global body pose and fine-grained facial expressions in communication. The provision of SMPLX registrations is beneficial, streamlining the process of integrating the dataset with parametric avatar models. However, its composition (4 identities, 2 outfits each) might be a limiting factor; expanded diversity could enhance the generalizability of models trained on it. Future research could explore using this dataset to investigate the relationship between speech, gesture, and body pose in creating more believable and engaging talking avatars.
More visual insights#
More on figures

🔼 This figure illustrates the three main stages of the TaoAvatar method. (a) shows the creation of a personalized clothed human model (SMPLX++) with Gaussian textures bound to its surface. (b) details the training of a StyleUnet (teacher network) to learn complex, pose-dependent non-rigid deformations. These deformations are then distilled into a simpler MLP (student network) for efficient real-time processing. (c) shows how learnable Gaussian blend shapes are added to further refine the avatar’s appearance, resulting in high-fidelity rendering.
read the caption
Figure 2: Illustration of our Method. Our pipeline begins by reconstructing (a) a cloth-extended SMPLX mesh with aligned Gaussian textures. To address complex dynamic non-rigid deformations, (b) we employ a teacher StyleUnet to learn pose-dependent non-rigid maps, which are then baked into a lightweight student MLP to infer non-rigid deformations of our template mesh. For high-fidelity rendering, (c) we introduce learnable Gaussian blend shapes to enhance appearance details.

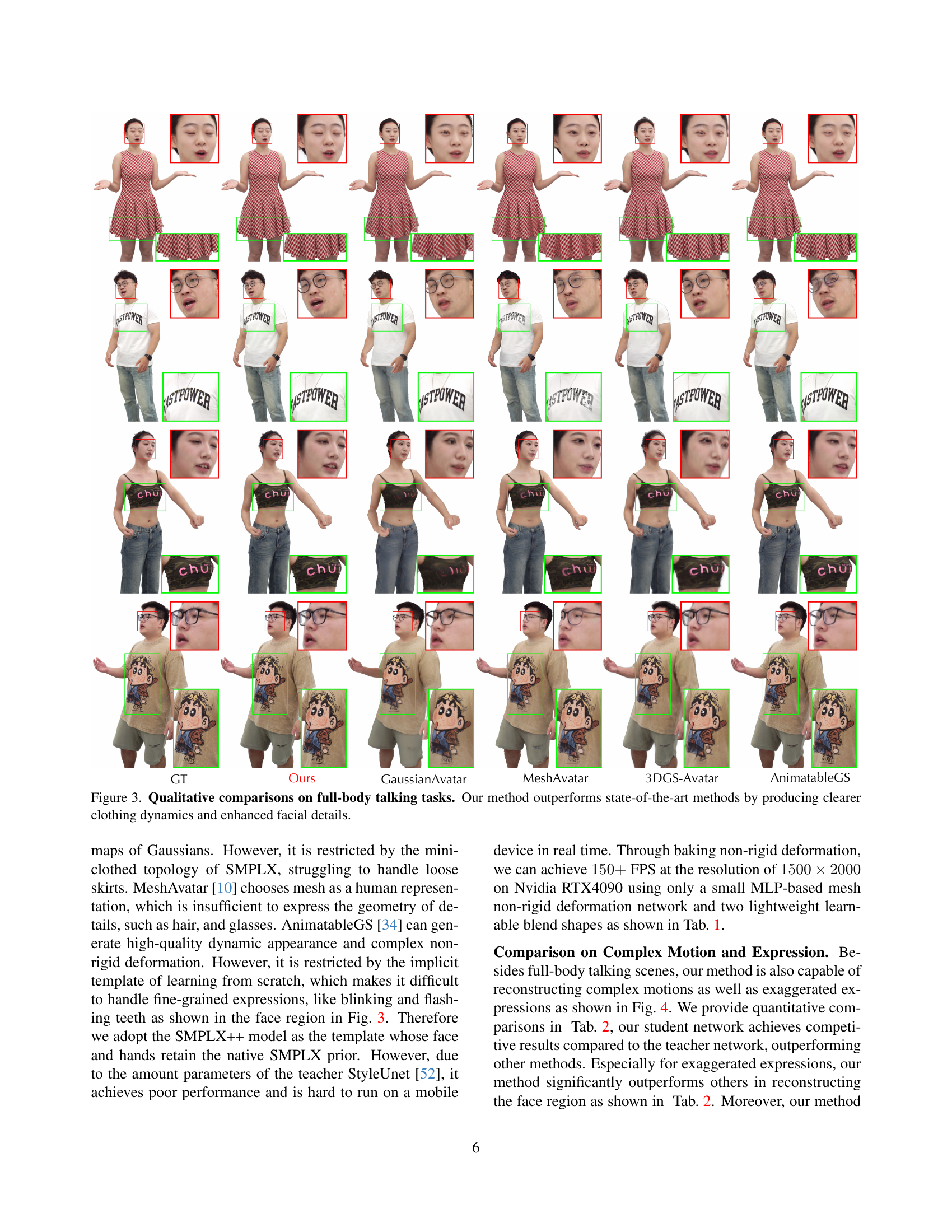
🔼 This figure presents a qualitative comparison of full-body talking avatar generation results across different methods, including the authors’ proposed method (Ours) and several state-of-the-art baselines. Each row represents a different pose and expression from a single video sequence, showcasing the performance of each approach. The comparison highlights the superiority of the authors’ method in capturing the fine details of the clothing, including natural folds and wrinkles, and in rendering more realistic and expressive facial features. This visual comparison underscores the effectiveness of the proposed approach in achieving high-fidelity, real-time avatar generation.
read the caption
Figure 3: Qualitative comparisons on full-body talking tasks. Our method outperforms state-of-the-art methods by producing clearer clothing dynamics and enhanced facial details.

🔼 Figure 4 showcases the robustness of the proposed method in handling challenging scenarios. It presents several examples of avatar reconstructions under extreme poses and exaggerated facial expressions, highlighting the method’s ability to maintain high-quality rendering even in these difficult conditions. The images visually demonstrate the superior performance of the TaoAvatar model compared to existing techniques in accurately representing detailed facial features and clothing dynamics, irrespective of complex body movements.
read the caption
Figure 4: Results in challenging scenarios. Our method can obtain high-quality reconstruction even for challenging pose and expressions.

🔼 This figure showcases TaoAvatar’s capability to generate realistic animations using only skeleton and expression parameters. Different individuals are shown performing the same actions, highlighting the model’s ability to capture and reproduce nuanced movements and expressions consistently across various subjects.
read the caption
Figure 5: Novel pose and expression animation. TaoAvatar can be driven by the same skeleton and expression parameters vividly.

🔼 This ablation study visualizes the impact of different components of the proposed method on the final avatar quality. By comparing the results with and without certain modules (like mesh non-rigid deformation or Gaussian non-rigid deformation), the figure highlights their individual contributions to generating high-fidelity avatars. Red and green boxes specifically point out artifacts present in the results and how these artifacts are addressed in the improved versions, providing a clear visual demonstration of the effectiveness of each component.
read the caption
Figure 6: Ablation Study. Red and Green boxes show artifacts and their improved counterparts.

🔼 This figure illustrates the process of reconstructing a personalized clothed human model, called SMPLX++, which serves as the foundation for creating the 3D avatar. The pipeline begins with multi-view images of a person. These images are used to reconstruct a 3D mesh using NeuS2, a neural radiance field method. Next, the non-body components (like clothing and hair) are segmented and separated from the body mesh. The SMPLX model (a parametric human body model) parameters are estimated for a reference frame (usually a T-pose) and the skinning weights are propagated from the body mesh to the non-body components. Inverse skinning is then applied to transform the non-body components back to the reference pose. Finally, the body mesh and non-body components are combined to create the complete clothed parametric model SMPLX++.
read the caption
Figure 7: The Pipeline of the Template SMPLX++ Reconstruction.
🔼 Figure 8 displays a comparison of different template meshes used to represent human avatars. It showcases the original SMPL-X model, the MeshAvatar template, the AnimatableGS template, and the novel SMPLX++ template developed by the authors. The visual differences highlight the improvements in detail and clothing representation achieved by the SMPLX++ template, which forms the foundation of the authors’ proposed method for creating high-fidelity, real-time avatars.
read the caption
Figure 8: Template Comparison.

🔼 This figure shows the relighting visualization process. The input is a raw rendered image, and the method uses the rendered normal map and an environment map to perform image-based relighting. The resulting image is more realistic and integrates better with the surrounding environment.
read the caption
Figure 9: Relighting Visualisation.

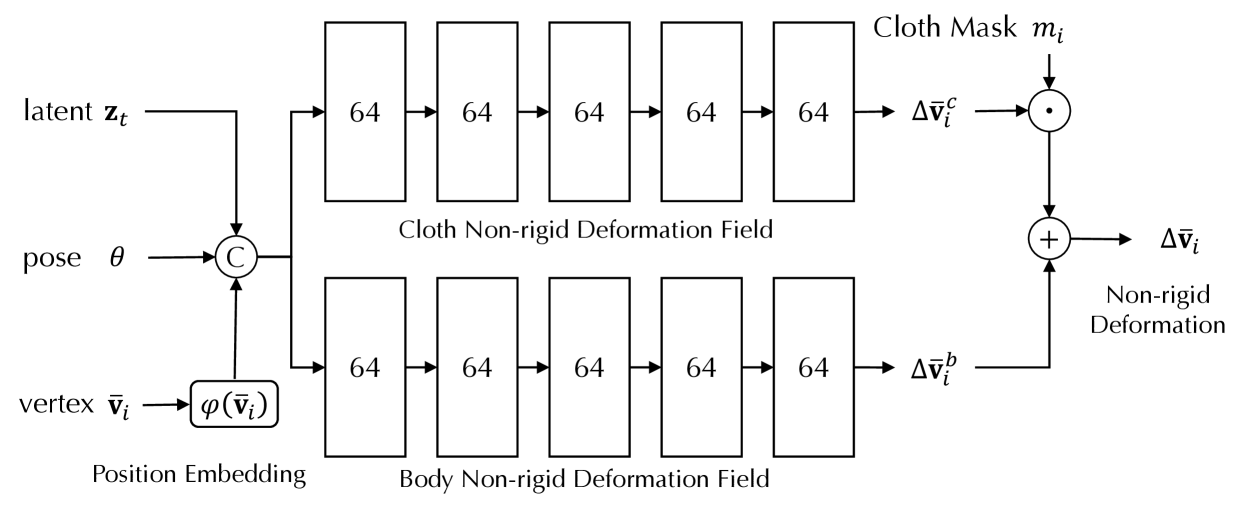
🔼 This figure details the architecture of the mesh non-rigid deformation field, a key component in TaoAvatar’s system for creating lifelike full-body avatars. It showcases the network’s input (pose and vertex coordinates), the processing steps involving two separate MLPs (Multilayer Perceptrons) to handle body and clothing deformations separately and the final output (the non-rigid deformation). The inclusion of a ‘cloth mask’ highlights the method’s ability to specifically apply clothing deformation where needed.
read the caption
Figure 10: Network Architecture of Mesh Nonrigid Deformation Field.

🔼 This figure shows an ablation study on the effect of adding a normal loss during the training process. The normal loss helps to improve the accuracy of the rendered normal maps by promoting smoother and more realistic-looking normal vectors. The comparison shows a significant improvement in the quality of the normals when the normal loss is included, resulting in better rendering quality and realism.
read the caption
Figure 11: The Impact of Normal Loss.

🔼 This figure shows a qualitative comparison of the results obtained from the teacher and student networks during the ‘baking’ process. The images compare the ground truth, the teacher network output, and the student network output. It visually demonstrates how the student network, a lightweight model, effectively learns and reproduces the complex non-rigid deformations initially learned by the more computationally expensive teacher network. The comparison shows the accuracy of the student network in approximating the deformations from the teacher network across different poses and includes a detailed look at the generated semantic maps (Sem. Et, Sem. Es) and Gaussian non-rigid deformation maps (Gau. Non. ∆Uf, Mesh Non. ∆V).
read the caption
Figure 12: Qualitative Visualization of Baking.

🔼 This figure illustrates the complete pipeline for creating a 3D digital human agent that can interact in real time on Apple Vision Pro. It shows how user audio input is processed through Automatic Speech Recognition (ASR), converted into text, and then interpreted by a large language model (LLM). The LLM’s response generates text, which is then converted to speech via Text-to-Speech (TTS) and finally used to drive the facial expressions and body movements of the 3D avatar using a Body Motion Library and Audio2BS.
read the caption
Figure 13: 3D Digital Human Agent Pipeline.

🔼 This ablation study visualizes the effect of including the semantic loss (Lsem) during the baking process of the neural network. It shows a comparison of the rendered images with and without the semantic loss. The images demonstrate the improvements in detail and accuracy achieved by incorporating Lsem, particularly in areas where clothing and body intersect. The results highlight the importance of Lsem for resolving inconsistencies in the Gaussian splatting representation.
read the caption
Figure 14: Ablation Study on Semantic Loss during Baking.

🔼 This figure provides a detailed qualitative comparison of the results produced by different methods for generating talking avatars. It showcases the level of detail achieved in face regions by comparing the results of the teacher model, the student model, and other state-of-the-art methods such as GaussianAvatar, MeshAvatar, 3DGS-Avatar, and AnimatableGS against the ground truth. This visual comparison highlights the superior detail achieved by the proposed model, especially in terms of facial expressions and textural details.
read the caption
Figure 15: Qualitative Comparison of Details.
More on tables
| Model | PSNR | SSIM | LPIPS |
|---|---|---|---|
| GaussianAvatar[20] | 25.94 (24.33) | .9294 (.8251) | .10478 (.24179) |
| 3DGS-Avatar[46] | 30.04 (25.08) | .9403 (.8458) | .08471 (.18044) |
| MeshAvatar[10] | 28.51 (24.94) | .9334 (.8100) | .08846 (.23517) |
| AnimatableGS[34] | 31.81 (26.79) | .9493 (.8608) | .07586 (.19521) |
| Ours (Teacher) | 32.80 (27.40) | .9533 (.8768) | .05581 (.14996) |
| Ours (Student) | 32.72 (27.35) | .9579 (.8836) | .07326 (.13914) |
🔼 This table presents a quantitative comparison of different methods for reconstructing human avatars performing complex motions and exaggerated expressions. The metrics used are PSNR, SSIM, and LPIPS, evaluating the quality of the rendered images. Results are shown for the full body and, separately, for the face (particularly focusing on exaggerated expressions). Higher PSNR and SSIM values and lower LPIPS values indicate better reconstruction quality.
read the caption
Table 2: Quantitative comparisons about complex motions and expressions reconstruction. The results inside the parentheses are evaluated for face regions with exaggerated expressions.
| Model | PSNR | SSIM | LPIPS | P2S | Chamfer |
|---|---|---|---|---|---|
| w SMPLX | 28.47 | .9476 | .07899 | .7690 | .9995 |
| w/o Mesh Non. | 32.10 | .9734 | .03814 | .4877 | .5007 |
| w/o Gau Non. | 31.16 | .9686 | .03932 | .2968 | .3068 |
| w/o Teacher | 32.67 | .9751 | .03769 | .5236 | .5359 |
| Full | 33.29 | .9772 | .03464 | .2953 | .3052 |
🔼 This table presents the results of an ablation study conducted to analyze the impact of different components on the overall performance of the proposed method. The study focuses on evaluating the quality of the reconstructed mesh geometry by comparing it to a pseudo-ground truth mesh generated using NeuS2 [54]. Different configurations are tested, systematically removing or modifying certain elements to assess their contribution to the final output. The results highlight the importance of each component, helping determine the effectiveness and robustness of the approach.
read the caption
Table 3: Ablation Study. We use the mesh reconstructed by NeuS2 [54] as a pseudo-truth for geometry evaluation.
| Model | Template | Non-rigid | Gaussian/Face Num. | Quality | Controllability | Speed | |||
| Head | Body | Head | Body | Head | Body | (Inference) | |||
| 3DGS-Avatar [46] | SMPLX | MLP | 19k | 181k | low | low | low | low | 54 |
| GaussianAvatar [20] | SMPLX | Unet | 45k | 146k | low | low | low | medium | 55 |
| MeshAvatar [10] | Mesh (Implicit) | StyleUnet | 5k | 50k | low | medium | low | medium | 22 |
| AnimatableGS [34] | Mesh (Implicit) | StyleUnet | 18k | 246k | low | high | low | high | 16 |
| Ours (Teacher) | SMPLX++ | StyleUnet | 19k | 250k | medium | high | medium | high | 16 |
| Ours (Student) | SMPLX++ | MLP+BS | 70k | 200k | high | high | high | high | 156 |
🔼 Table 4 provides a comparison of several state-of-the-art methods for generating full-body avatars. It contrasts different aspects of each method, including the type of template used (SMPLX or a customized version), the method used for non-rigid deformation modeling (MLP, StyleUnet), the number of Gaussians or parameters used, the overall quality of the resulting avatar, the level of controllability afforded to the user, the complexity of the body representation, and the speed of inference. This allows for a quantitative assessment of the trade-offs between accuracy, controllability, realism, and computational efficiency in different approaches.
read the caption
Table 4: Summary about these State-of-the-art Methods of Full-body Avatars.
Full paper#