TL;DR#
Recent methods lack user control in 3D face editing due to pre-trained masks requiring extensive datasets, hindering applications like personalized medical imaging. Current Neural Radiance Fields(NeRF)-based face editing faces challenges in user control because it relies on pre-trained segmentation masks with fixed layouts. Gathering diverse datasets for varying mask layouts is difficult. This limits the ability to edit specific facial regions effectively for different applications.
This paper introduces FFaceNeRF, which uses a geometry adapter with feature injection and LMTA for mask adaptation, enabling effective manipulation with as few as 10 samples. This enables training on adapted mask layouts. In addition, the method utilizes an overlap-based optimization process for precise editing of small regions. Experiments demonstrate improved flexibility, control, and image quality compared to existing mask-based methods.
Key Takeaways#
Why does it matter?#
This paper is important for researchers as it advances 3D face editing by enhancing user control and image quality. The novel method addresses limitations in existing techniques, paving the way for more flexible and personalized applications in VR/AR, medical imaging, and creative design.
Visual Insights#

🔼 Figure 1 showcases the results produced by the FFaceNeRF model. It demonstrates the model’s ability to perform few-shot 3D face editing. The figure shows a source image with a typical mask overlayed. Next to it are examples of ‘desired layouts’, which represent the user-specified edits to be made to the facial features. Then, an ’edited mask’ shows the refined mask created by the model to guide the editing process. Finally, the ‘fine-edit results’ images display the final edited images produced by FFaceNeRF, reflecting the changes based on the ‘desired layouts’. This illustrates how the model effectively incorporates user input to produce high-quality, 3D-aware face edits.
read the caption
Figure 1: Results of FFaceNeRF. With few-shot training, our method can edit 3D-aware images from desired layouts.
![[Uncaptioned image]](extracted/6299363/figures/new_teaser2.png) |
🔼 This table presents the results of a user study comparing the performance of FFaceNeRF against two baseline methods (NeRFFaceEditing and IDE-3D) in 3D face editing tasks. Participants were shown edited images generated by each method and asked to rate them based on three criteria: faithfulness to the edited regions, retention of unchanged regions, and overall visual quality. The numbers in the table represent the percentage of times participants preferred FFaceNeRF over each of the baseline methods for each criterion.
read the caption
Table 1: Perceptual study results on face editing. The number indicates the percentage of selections for our methods over competitors.
In-depth insights#
Few-shot Editing#
Few-shot editing in the context of neural radiance fields (NeRFs) presents a significant challenge due to the data-hungry nature of NeRF models. Traditional NeRF training requires numerous images to accurately represent a 3D scene. Few-shot editing aims to enable meaningful and controllable modifications to NeRF-based representations using only a handful of input images or examples. This is crucial for applications where acquiring large datasets is impractical or impossible, such as personalized avatar creation or medical imaging. Methods for few-shot editing often involve techniques like meta-learning, transfer learning, or regularization to constrain the solution space and prevent overfitting. Geometry adaptation and latent space manipulation will be key to achieving precise control with limited data. Careful consideration must be given to preserving identity and minimizing artifacts.
Geometry Adapter#
The geometry adapter is a crucial component, enabling the model to adapt to new mask layouts with minimal training data. It functions by modulating the output of the geometry decoder, ( \Psi_{geo} ), which initially produces a fixed segmentation volume based on pre-trained knowledge. This modulation allows the model to generate customized masks corresponding to the desired layouts. A lightweight MLP, ( \Phi_{geo} ), facilitates rapid training and inference. To preserve crucial geometric information, the adapter injects tri-plane features ( F_{tri} ) and view direction ( v_d ), providing contextual cues for accurate mask generation. This injection addresses the limitation of discarding geometric information during pre-training, ensuring that the adapter effectively incorporates fine geometric details. By combining the pre-trained geometric knowledge with injected features and a modulating MLP, the geometry adapter enables few-shot adaptation to diverse mask layouts, a key contribution to the method’s flexibility and control.
LMTA Augmentation#
Latent Mixing for Triplane Augmentation (LMTA) is a technique designed to enhance the versatility of face editing with a small number of training samples. It addresses the crucial consideration of avoiding overfitting by maintaining semantic information while increasing the diversity of the original triplane features. The method leverages the architecture of style-based generators, known for their coarse-to-fine information structure across layers. LMTA blends latent codes from different layers, allowing modifications to details that don’t affect semantic information. The early layers are responsible for the coarse features and the later layers with fine details. This allows control over geometric attributes with few training samples. This augmentation results in high quality results of the edited images.
Overlap Optimize#
The concept of “Overlap Optimize” likely refers to a method that refines the boundaries or regions of interest in a model. Instead of treating distinct entities, it iteratively adjusts their spatial relationships. This is particularly relevant in image segmentation or 3D reconstruction tasks where objects might not have clear, defined edges. The optimization could involve metrics focused on minimizing boundary discrepancies, maximizing the intersection-over-union (IoU) between predicted and ground truth regions, or ensuring smoothness in transitions between regions. Furthermore, the method might use techniques like graph cuts or energy minimization to find the optimal overlap configuration. Regularization terms may be incorporated to prevent excessive or unrealistic overlaps, thereby promoting more physically plausible object arrangements.
Style Transfer#
Style transfer, particularly partial style transfer leveraging disentangled representations and custom masks, is highlighted as a key application within the broader context of facial editing. The method involves extracting style statistics (mean and variance) from target style images and applying them to the normalized source tri-plane, enabling the transfer of stylistic elements while preserving geometric fidelity. A customized mask then permits selective blending of the styled regions with the original face, allowing for precise control over which areas undergo style transformation. This approach ensures a seamless transition by employing linear blending at the edges, effectively tailoring the style transfer to specific facial features or regions of interest. The ability to perform partial style transfer offers granular control and creative flexibility in facial image manipulation.
More visual insights#
More on figures

🔼 This figure illustrates the pretraining phase of the FFaceNeRF model. It details how the model leverages the EG3D and NeRFFaceEditing architectures to achieve disentangled representations of face appearance and geometry. The process begins with an appearance decoder (Ψapp) generating a face volume from a latent code. This face volume is then rendered into an image. Simultaneously, a geometry decoder (Ψgeo) using a pre-trained segmentation network processes a normalized tri-plane feature (F’tri) to output a corresponding segmentation mask volume. The combination of these two networks allows for the generation of a face image and its associated segmentation mask. Importantly, the method allows adaptation of the geometry decoder to work with customized segmentation mask layouts rather than being limited to fixed layouts.
read the caption
Figure 2: Pretraining stage of FFaceNeRF following EG3D [4] and NeRFFaceEditing [18] for disentangled representation.

🔼 Figure 3 illustrates the architecture of FFaceNeRF, focusing on the geometry adapter (Φgeo). The adapter receives the concatenated inputs of the normalized tri-plane feature (F’tri), view direction (vd), and outputs from the geometry decoder (Ψgeo), which include segmentation labels (Seg) and density (σ). The density (σ) is directly used from the Ψgeo output without additional training of Φgeo. Notably, the Latent Mixing for Triplane Augmentation (LMTA) is applied during the training of Φgeo to enhance the model’s adaptability to varied segmentation masks.
read the caption
Figure 3: Overview of FFaceNeRF. LMTA is conducted during the training of ΦgeosubscriptΦ𝑔𝑒𝑜\Phi_{geo}roman_Φ start_POSTSUBSCRIPT italic_g italic_e italic_o end_POSTSUBSCRIPT. ΦgeosubscriptΦ𝑔𝑒𝑜\Phi_{geo}roman_Φ start_POSTSUBSCRIPT italic_g italic_e italic_o end_POSTSUBSCRIPT takes as input the concatenation of normalized tri-plane feature F′^trisubscript^superscript𝐹′𝑡𝑟𝑖\hat{F^{\prime}}_{tri}over^ start_ARG italic_F start_POSTSUPERSCRIPT ′ end_POSTSUPERSCRIPT end_ARG start_POSTSUBSCRIPT italic_t italic_r italic_i end_POSTSUBSCRIPT (yellow box), view direction vdsubscript𝑣𝑑v_{d}italic_v start_POSTSUBSCRIPT italic_d end_POSTSUBSCRIPT (white box), outputs of ΨgeosubscriptΨ𝑔𝑒𝑜\Psi_{geo}roman_Ψ start_POSTSUBSCRIPT italic_g italic_e italic_o end_POSTSUBSCRIPT, which are segmentation labels Seg𝑆𝑒𝑔Segitalic_S italic_e italic_g (blue box), and density σ𝜎\sigmaitalic_σ (red box). Density σ𝜎\sigmaitalic_σ is directly used from the output of ΨgeosubscriptΨ𝑔𝑒𝑜\Psi_{geo}roman_Ψ start_POSTSUBSCRIPT italic_g italic_e italic_o end_POSTSUBSCRIPT, without further training using ΦgeosubscriptΦ𝑔𝑒𝑜\Phi_{geo}roman_Φ start_POSTSUBSCRIPT italic_g italic_e italic_o end_POSTSUBSCRIPT.

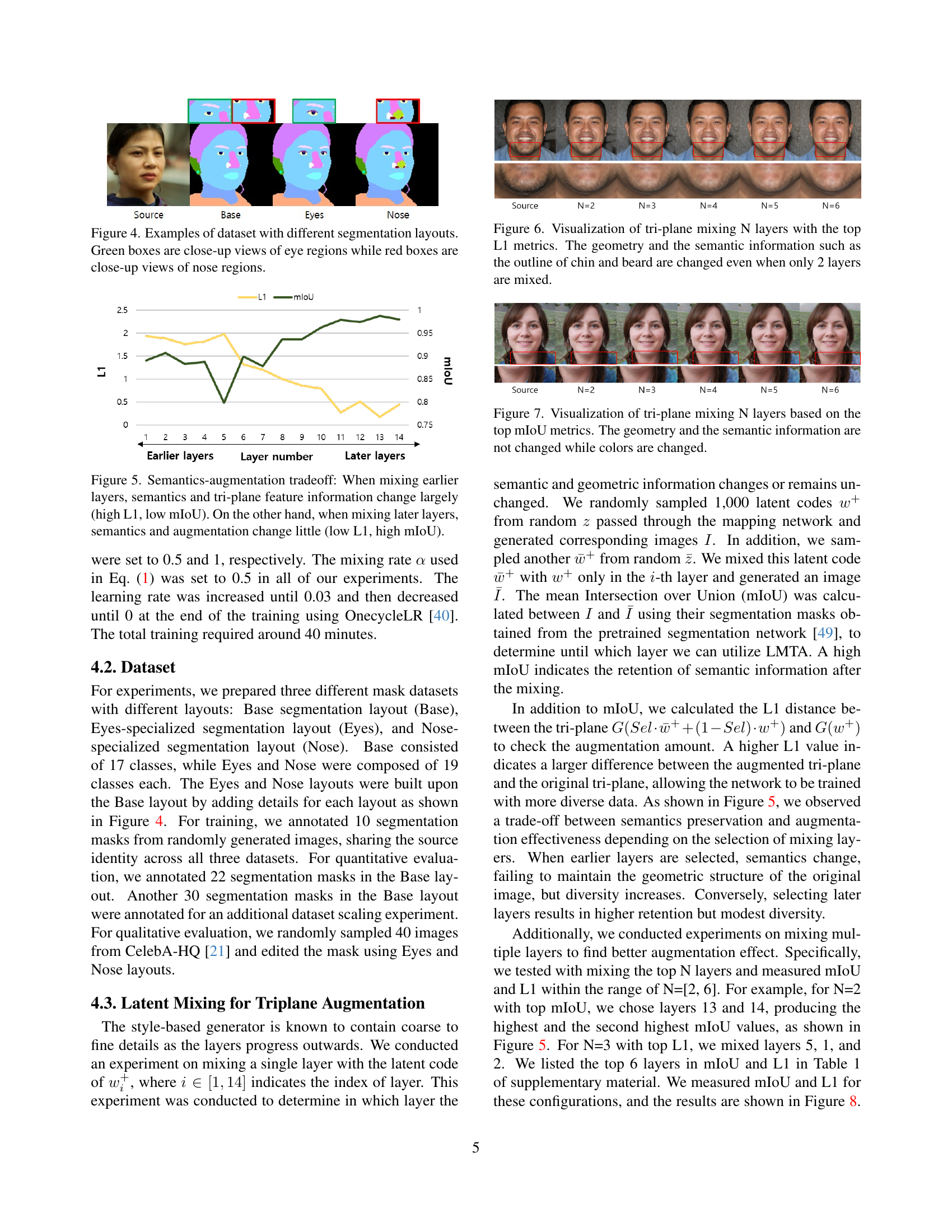
🔼 Figure 4 shows examples from the dataset used in the FFaceNeRF model training. The dataset includes images with three different segmentation mask layouts: Base, Eyes, and Nose. The Base layout provides a general segmentation of facial features. The Eyes and Nose layouts offer more detailed segmentations focusing on eye and nose areas respectively. The figure highlights these differences by displaying example images from each layout type. Green boxes show zoomed-in views of the eye region, while red boxes focus on the nose area.
read the caption
Figure 4: Examples of dataset with different segmentation layouts. Green boxes are close-up views of eye regions while red boxes are close-up views of nose regions.

🔼 This figure illustrates the effect of latent mixing on the balance between preserving semantic information and introducing diversity during training. The x-axis represents the layer number in a style-based generator, where earlier layers contain more coarse geometric information and later layers contain finer details. The y-axis shows two metrics: L1 distance (measuring the change in tri-plane features after mixing) and mIoU (measuring the similarity of segmentation masks before and after mixing). The plot shows that mixing earlier layers leads to large changes in both semantics and tri-plane features (high L1, low mIoU), indicating significant augmentation but potential loss of semantic consistency. Conversely, mixing later layers results in smaller changes (low L1, high mIoU), suggesting less augmentation but better preservation of original semantic information.
read the caption
Figure 5: Semantics-augmentation tradeoff: When mixing earlier layers, semantics and tri-plane feature information change largely (high L1, low mIoU). On the other hand, when mixing later layers, semantics and augmentation change little (low L1, high mIoU).

🔼 This figure visualizes the effects of latent mixing on tri-plane features during training. Latent mixing involves blending different latent codes at specific layers to create augmented tri-plane features. The experiment shows that even when mixing only two layers (N=2), selected based on having the highest L1 metric (which measures the magnitude of change), both geometry and semantic information such as the chin and beard outlines are visibly altered in the generated face images. This demonstrates the ability of latent mixing to successfully introduce changes across different levels of detail in the generated output.
read the caption
Figure 6: Visualization of tri-plane mixing N layers with the top L1 metrics. The geometry and the semantic information such as the outline of chin and beard are changed even when only 2 layers are mixed.

🔼 This figure visualizes the results of applying latent mixing to the tri-plane features in a neural radiance field (NeRF)-based face editing model. Latent mixing combines different latent codes from a style-based generator, affecting the color and texture information in the generated image. The ’top mIoU metrics’ selection criteria indicate that the layers were chosen to maximize the intersection over union (IoU) between the generated and ground truth segmentation masks. The experiment aims to demonstrate that latent mixing primarily affects the color information (such as changing hair color or skin tone), while maintaining the geometry and semantic features (such as facial shape and structure) of the face. The different images shown in the figure represent variations with different numbers (N) of layers undergoing latent mixing.
read the caption
Figure 7: Visualization of tri-plane mixing N layers based on the top mIoU metrics. The geometry and the semantic information are not changed while colors are changed.

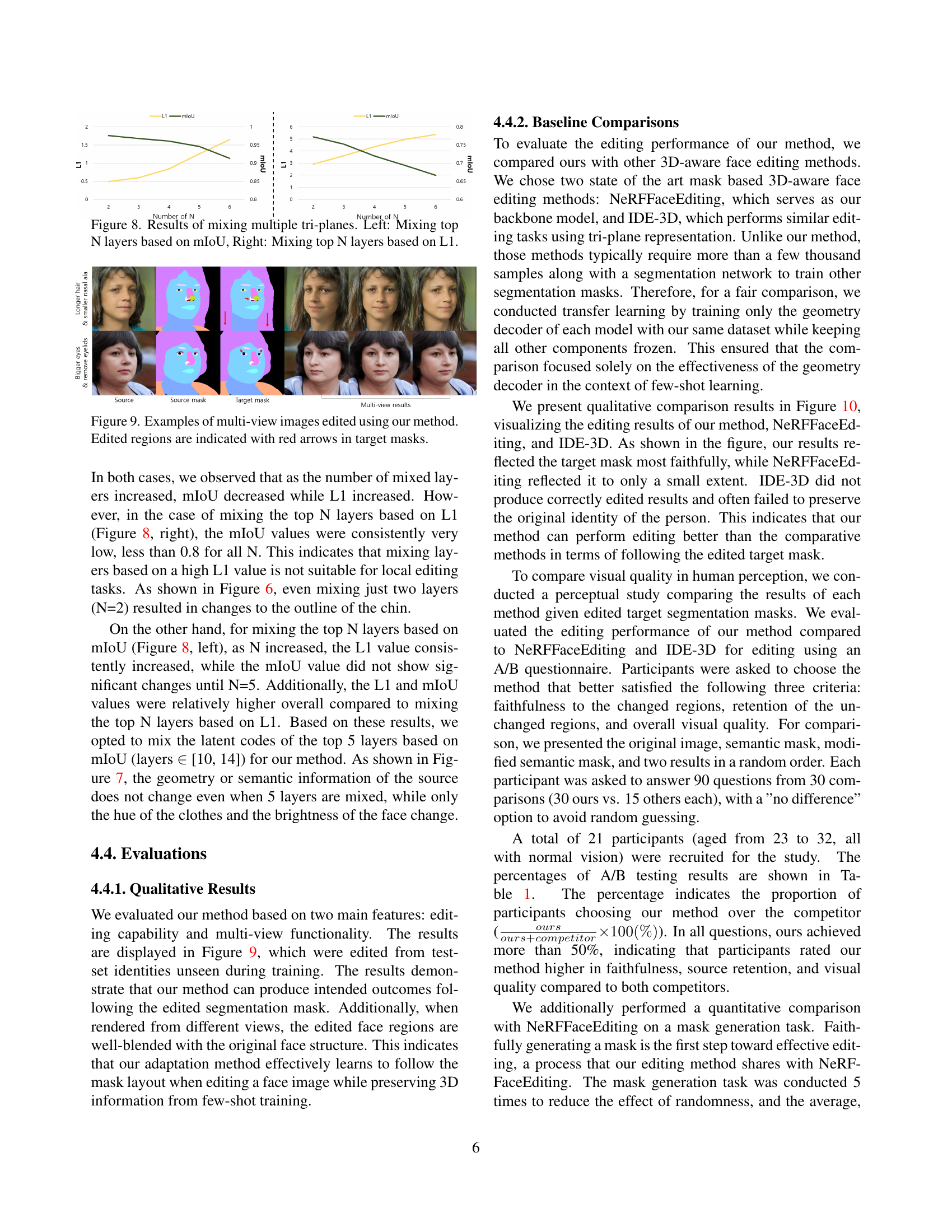
🔼 This figure visualizes the effects of mixing multiple tri-plane layers in the FFaceNeRF model during training. The left panel shows the results when selecting the top N layers based on the mean Intersection over Union (mIoU) metric, focusing on preserving semantic consistency. The right panel shows the results when selecting the top N layers based on the L1 distance metric, emphasizing the amount of change introduced by the augmentation. Both panels illustrate a trade-off between preserving semantic information (mIoU) and introducing diversity in the training data (L1). The graphs plot mIoU and L1 values against the number of layers (N) to show this relationship.
read the caption
Figure 8: Results of mixing multiple tri-planes. Left: Mixing top N layers based on mIoU, Right: Mixing top N layers based on L1.

🔼 This figure showcases the results of FFaceNeRF’s ability to perform multi-view face editing. It presents three columns: the original source image with its initial mask, the corresponding target mask indicating the desired edits (with red arrows highlighting the specific regions to be modified), and the final edited images viewed from multiple angles. This demonstrates the model’s capacity to consistently apply edits across different viewpoints, maintaining a realistic and coherent 3D representation of the edited face.
read the caption
Figure 9: Examples of multi-view images edited using our method. Edited regions are indicated with red arrows in target masks.

🔼 Figure 10 presents a qualitative comparison of face editing results between the proposed FFaceNeRF model and two baseline methods: NeRFFaceEditing and IDE-3D. Each row shows the source image, the source mask, the target mask (indicating the desired edits), and the edited results from each of the three methods. The figure highlights that FFaceNeRF achieves the most accurate and faithful editing results, closely reflecting the edits specified in the target mask, while the baseline methods show less accurate editing and sometimes fail to preserve the original facial identity.
read the caption
Figure 10: Examples of our results and those of baseline methods in editing tasks. The results of our method faithfully reflect the edited regions.

🔼 Figure 11 displays a comparison of face editing results using FFaceNeRF with different components removed to show their individual contributions. The top row shows the original source images and the target masks, which specify the desired edits. The subsequent rows show results from models trained without feature injection, without latent mixing for triplane augmentation (LMTA), and with all layers mixed during training, along with the results from the complete FFaceNeRF model. The complete model shows accurate reproduction of the target mask while maintaining the source face’s identity. Removing components led to problems such as color shifts (without feature injection), inaccurate hair generation (without LMTA), and alterations to the underlying facial features (mixing all layers).
read the caption
Figure 11: Ablation study results. Our full model best followed the target masks while preserving the original identity. The color shifted when trained without feature injection, hair was not faithfully generated when trained without LMTA, and the source identity changed when trained with mixing all layers.

🔼 Figure 12 shows a comparison between FFaceNeRF’s overlap-based optimization and a traditional percentage-based approach for eye enlargement. The image demonstrates that FFaceNeRF more accurately reflects the desired changes in eye size specified by the user’s edited mask, achieving more faithful results compared to the percentage-based method.
read the caption
Figure 12: Comparisons with percentage-based optimization on enlarging eyes show that our method more faithfully follows the desired eye size modifications.
More on tables
| Comparison | Faithfulness(%) | Retention(%) | Quality(%) |
|---|---|---|---|
| vs NeRFFaceEditing | 72.29 | 67.83 | 68.68 |
| vs IDE-3D | 79.65 | 80.17 | 81.22 |
🔼 This table presents a quantitative comparison of mask generation performance between the proposed FFaceNeRF method and the baseline NeRFFaceEditing method. The comparison focuses on the mean Intersection over Union (mIoU) metric, a measure of the overlap between the generated mask and the ground truth mask. The table shows the average mIoU, minimum mIoU, and maximum mIoU across five trials for each method. The highest mIoU scores, indicating better mask generation accuracy, are highlighted in bold. This comparison helps to demonstrate the improvement achieved by FFaceNeRF in generating accurate segmentation masks.
read the caption
Table 2: Quantitative results of our method and NeRFFaceEditing on mask generation. Highest scores are denoted in bold.
| Methods | Average mIoU [min, max] (%) |
|---|---|
| Ours | 85.33 [84.8, 85.7] |
| NeRFFaceEditing | 81.37 [81.2, 81.5] |
🔼 This table presents the quantitative results of an ablation study conducted to evaluate the impact of different components of the FFaceNeRF model on mask generation performance. The study varied the number of training data samples (1, 5, 10, 20, and 30) and compared the performance of the full FFaceNeRF model against versions without feature injection, without latent mixing tri-plane augmentation (LMTA), and using all layers for mixing. The metric used for evaluation is the mean Intersection over Union (mIoU), which quantifies the overlap between the generated mask and the ground truth mask. Higher mIoU values indicate better performance. The highest mIoU score achieved for each data sample size is highlighted in bold.
read the caption
Table 3: Quantitative results of ablation study on mask generation with a different number of training data. The highest scores are denoted in bold.
Full paper#