TL;DR#
Large Language Models (LLMs) can generate creative writing, but post-training often sacrifices output diversity for quality. This is problematic, as creative tasks benefit from varied, valid responses. Low diversity leads to homogenous content and biased outputs. Prior work focused on prompting or adjusting sampling temperatures, but these can trade off quality for diversity. This paper tackles this issue by diversifying training to improve creative writing quality.
The paper introduces diversified versions of Direct Preference Optimization (DPO) and Odds Ratio Preference Optimization (ORPO). The core idea is to incorporate deviation—the difference between a training sample and others with the same prompt—into the training objective. This helps models learn from rare, high-quality instances. By weighting training objectives with deviation, the model can enhance output diversity without significantly compromising quality. The proposed models can match human diversity.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the critical issue of diversity in LLM outputs for creative tasks, providing practical methods for enhancing both output quality and diversity. The demonstrated success of deviation-factored DPO and ORPO opens new avenues for tuning LLMs and impacts creative AI writing assistant tools and applications.
Visual Insights#

🔼 This figure illustrates a post-training approach for enhancing the diversity of creative writing generated by large language models (LLMs) while preserving output quality. The process starts with a prompt, which receives multiple responses. A deviation score is calculated for each response, measuring its difference from other responses to the same prompt. The responses are then fed into either Direct Preference Optimization (DPO) or Odds Ratio Preference Optimization (ORPO), with the loss for each response pair weighted by the winning response’s deviation score. This weighting emphasizes learning from rare, high-quality responses, thus promoting both diversity and quality in the final LLM output.
read the caption
Figure 1: Our post-training approach to diversify creative writing generation while maintaining quality.
| Writing Prompt: "Why are you shaking, my love? You are king now." King can be metaphorical or literal. | ||
| GPT-4o | Llama-3.1-8B DPO | Llama-3.1-8B DDPO-both |
| A newly promoted manager struggles with imposter syndrome while his wife offers unwavering support. | A divine ruler must abandon his throne to protect his daughter’s reign after revealing a dark secret. | A president grapples with moral conflict over inability to take a life despite leadership expectations. |
| A newly crowned king struggles with self-doubt while his beloved offers reassurance. | A king murders his wife due to a prophecy, while their son watches the tragic sacrifice. | A couple seeks refuge during a storm, harboring dark secrets and contemplating future redemption. |
| A newly crowned king grapples with self-doubt while his beloved offers reassurance. | A reluctant new king grapples with the overwhelming burden and fear of leadership. | A child’s supernatural encounters while diving reveal a dark family tradition of hunting marine spirits. |
| A reluctant heir grapples with the weight of unexpected kingship and fear of failure. | A royal heir struggles with leadership responsibilities while finding strength in romantic love. | A young bear prince assumes his role as King while facing an arranged marriage in a dark fantasy setting. |
🔼 This table displays topic sentences from creative writing examples generated by different LLMs under various conditions. Each row represents a different model (GPT-40, Llama-3.1-8B DPO, Llama-3.1-8B DDPO) and prompt, showcasing the diverse outputs produced by each model. Note that the ‘writing prompt’ does not always encompass the complete set of instructions provided to the LLMs; some implicit instructions or contextual information may be omitted for brevity.
read the caption
Table 1: Topic sentences of generated examples. Note that “writing prompt” is not necessarily a full instruction prompt given to LLMs.
In-depth insights#
Diversity Tuning#
Diversity tuning in LLMs for creative writing is crucial due to the non-unique nature of creative tasks. LLMs should generate diverse, valid outputs, but post-training often prioritizes quality over diversity, leading to homogenous content. The research explores post-training approaches to promote both diversity and quality, introducing the concept of ‘deviation’—the difference between a training sample and others with the same prompt—into the objective function. This helps the model learn from rare, high-quality instances. Diversified DPO and ORPO are implemented to increase semantic and style diversity with minimal quality decrease. The best model matches human-created diversity with GPT-4 quality. Further analysis includes human evaluation and a comparison with DivPO. The idea is to balance the need to learn from frequent and rare instances.
Deviation Weighting#
Deviation weighting emerges as a pivotal technique to diversify LLM outputs in creative tasks. By emphasizing rare, high-quality instances, this method addresses the tendency of post-training to prioritize average quality, inadvertently reducing diversity. The core idea involves incorporating a ‘deviation’ factor, quantifying how much a sample differs from others with the same prompt, directly into the training objective. This approach, implemented via methods like diversified DPO and ORPO, prioritizes learning from less frequent but valuable examples. The use of semantic and style deviations captures multifaceted aspects of diversity. By strategically weighting these deviations, the model is incentivized to explore less common pathways, fostering a richer variety of creative outputs. This results in a more nuanced and expressive generation process, without sacrificing overall quality.
DPO/ORPO + Div#
The paper introduces an innovative strategy that combines Direct Preference Optimization (DPO) and Odds Ratio Preference Optimization (ORPO) with a deviation-based diversity metric. This approach aims to enhance both the quality and diversity of generated content from Large Language Models (LLMs), which is particularly useful in creative writing tasks. The core concept involves integrating the degree of difference (deviation) between a training sample and other samples with the same prompt into the training objective. This method facilitates learning from rare, high-quality instances that might otherwise be overshadowed. The diversified DPO and ORPO approaches promote both semantic and stylistic variety in the model’s output, ensuring that while the quality is maintained, the range of different valid writings expands to achieve on par diversity as human created content. By using deviation as a weighting factor, rare and unique instances get greater emphasis during training, leading to a more balanced and diverse generation process.
Human Parity#
While the paper doesn’t explicitly address ‘Human Parity’, the evaluation metrics and results suggest an implicit pursuit of it. The authors use human-created dataset as a benchmark, implying a desire to reach parity in quality and diversity. The models strive to generate creative writing that is indistinguishable from human-authored content in terms of validity, quality and creative diversity. DDPO based models demonstrated better diversity than existing instruction-tuned models, and human evaluations suggest that DDPO approaches can sometimes even be preferred to GPT-40 in terms of quality, achieving parity or even surpassing it.
Data Is Needed#
The paper emphasizes the critical role of data in training and evaluating creative writing generation models. It uses the r/writingPrompts dataset, highlighting the importance of diverse writings for a single prompt to enhance model diversity. Data filtering is crucial, with the removal of excessively long and non-creative instances. Transforming score data into paired preferences for DPO/ORPO models is essential, avoiding repetition and prioritizing clear winning/losing responses. Details include training and test set sizes, prompt/response lengths, and the distribution of responses per prompt. The thoroughness in data processing underscores its direct impact on the model’s quality and diversity.
More visual insights#
More on figures

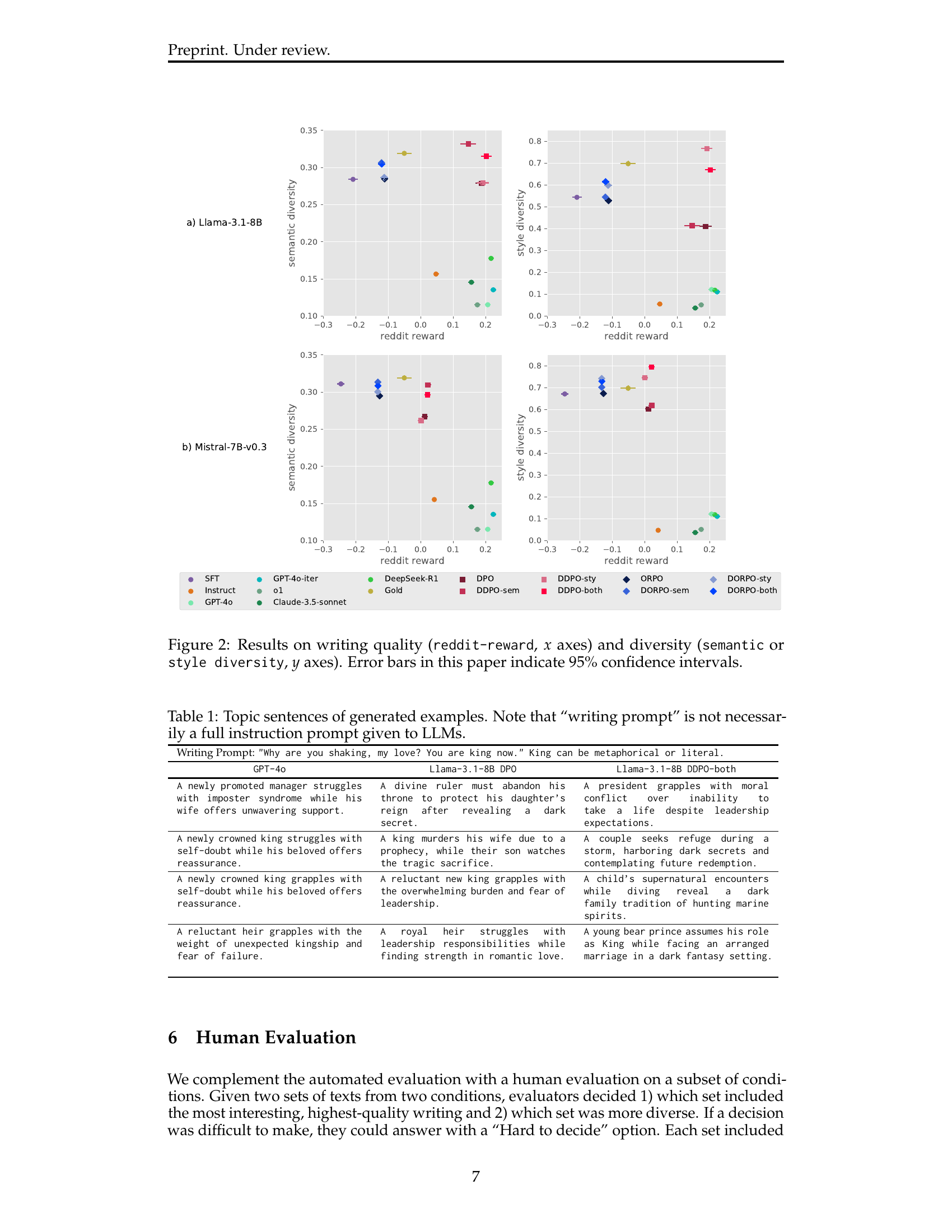
🔼 Figure 2 presents a comparative analysis of various large language model (LLM) training methods in terms of writing quality and diversity. The x-axis represents the writing quality measured using a reddit-reward model, indicating higher scores for better quality writing. The y-axis represents the diversity of the generated writing samples, categorized into semantic and style diversity. Each point represents the performance of a specific model (e.g. DPO, DDPO, and ORPO) trained using different approaches. The error bars indicate the 95% confidence intervals, showing the uncertainty in the measurements. This figure helps understand the trade-offs between writing quality and diversity achieved by different model training methods. The results demonstrate the effectiveness of the diversified optimization methods (DDPO and DORPO) in improving diversity without significantly reducing quality.
read the caption
Figure 2: Results on writing quality (reddit-reward, x𝑥xitalic_x axes) and diversity (semantic or style diversity, y𝑦yitalic_y axes). Error bars in this paper indicate 95% confidence intervals.

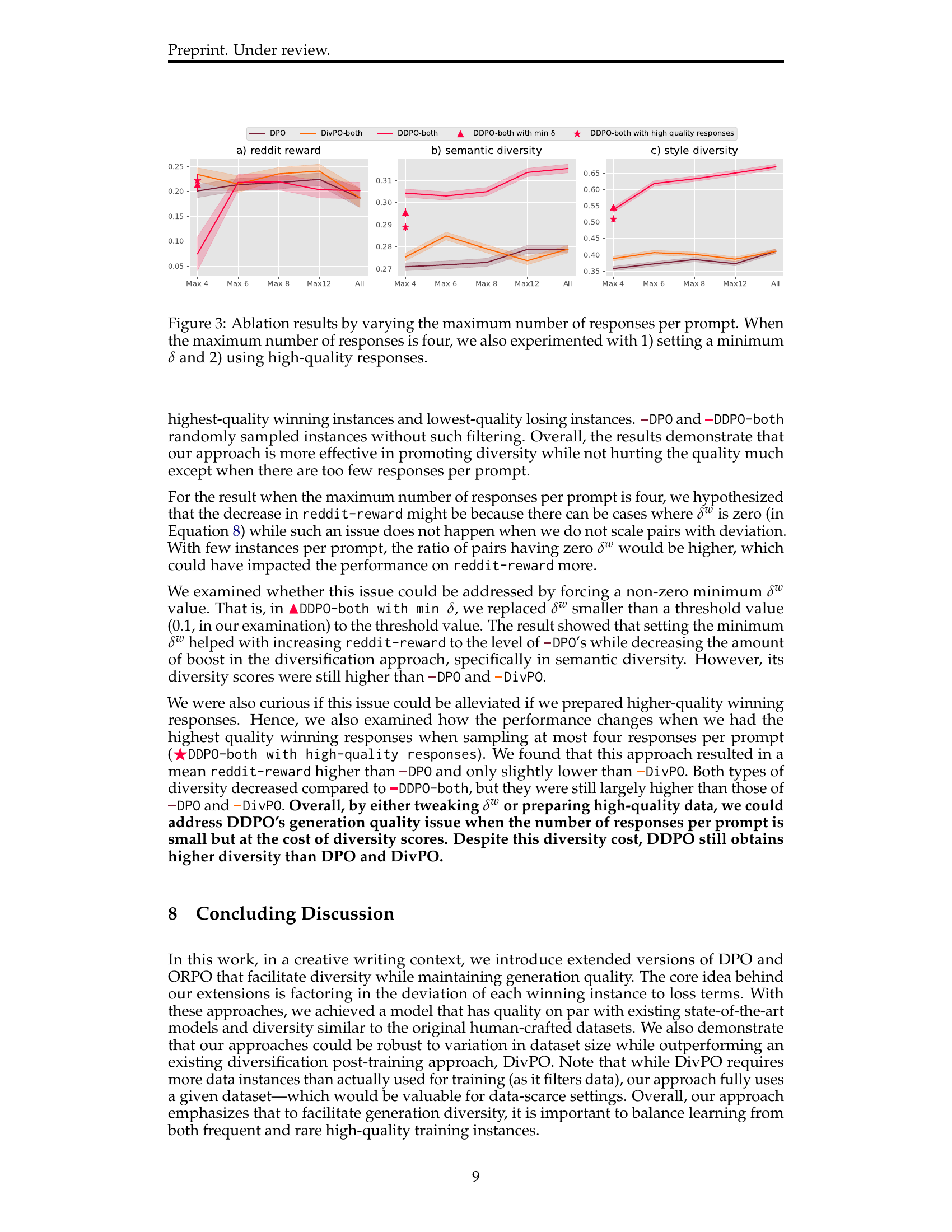
🔼 This figure displays the results of an ablation study that investigates the impact of varying the maximum number of responses per prompt on the performance of the proposed diversified DPO and ORPO models. The x-axis represents the maximum number of responses considered per prompt (4, 6, 8, 12, or all). Three separate y-axes show the model’s performance in terms of: (1) Reddit reward (quality), (2) Semantic diversity, and (3) Style diversity. The figure reveals the robustness of the proposed approach across different numbers of responses per prompt. Importantly, it also shows additional experiments performed when the maximum number of responses per prompt is four. These supplemental experiments involve (1) enforcing a minimum deviation threshold and (2) using only high-quality training responses to analyze their effect on the quality and diversity of the outputs.
read the caption
Figure 3: Ablation results by varying the maximum number of responses per prompt. When the maximum number of responses is four, we also experimented with 1) setting a minimum δ𝛿\deltaitalic_δ and 2) using high-quality responses.

🔼 This figure displays the results obtained using Llama-3.1-8B model, focusing on three distinct metrics: compression ratio, homogenization score, and n-gram diversity score. Each metric provides a unique perspective on the diversity and quality of text generated by the model. The compression ratio indicates how well the generated text can be compressed, with lower scores suggesting higher diversity. The homogenization score measures the similarity between generated text samples, and lower scores imply higher diversity. Finally, the n-gram diversity score assesses the diversity at the n-gram level. The plot visually compares the performance of several model variants and baselines across these three metrics.
read the caption
Figure 4: Llama-3.1-8B results on compression ratio, homogenization score, and n-gram diversity score.

🔼 This figure presents the results of evaluating Mistral-7B-v0.3, a large language model, across three different diversity metrics: compression ratio, homogenization score, and n-gram diversity score. The compression ratio measures the effectiveness of compression algorithms on the generated text, indicating the level of redundancy or repetitiveness. A lower score suggests higher diversity. The homogenization score quantifies the similarity between text sequences within the generated outputs; a lower score implies more diverse outputs. Finally, n-gram diversity score assesses the variety of n-grams (sequences of n words) in the generated text. Higher score indicates higher diversity. The figure likely displays these scores for various model settings or conditions, allowing for a comparison of their impact on text diversity.
read the caption
Figure 5: Mistral-7B-v0.3 results on compression ratio, homogenization score, and n-gram diversity score.

🔼 The figure shows the interface used for human evaluation in the study. It presents two sets of story summaries, labeled Set A and Set B, each containing four summaries. Evaluators were asked to choose which set contained the most interesting/high-quality story, which set had more diverse stories, and could optionally provide comments. The interface was designed to simplify the evaluation process by showing concise information.
read the caption
Figure 6: Human evaluation interface.
More on tables
| DDPO-both | vs. | GPT-4o | DDPO-both | vs. | DPO | |
| Has the highest-quality story | 68% | 24% | 50% | 34% | ||
| More diverse | 100% | 0% | 62% | 26% | ||
🔼 This table presents the results of a human evaluation comparing the quality and diversity of text generated by different models. The win rates represent the percentage of times each model was judged superior in terms of either the quality of the generated story or the diversity of the stories generated. Significant differences between models are highlighted in bold. The comparisons made were: DDPO-both vs. DPO, and DDPO-both vs. GPT-40. The evaluation involved human judges rating sets of four generated text samples.
read the caption
Table 2: Win rates(%) from human evaluation. Significant differences are bolded.
| Total P | Total R | P len | R len | Mean | Min | Max | Median | 25th | 75th | |
| Train | 95805 | 421330 | 31.87 | 502.21 | 4.40 | 2 | 500 | 2 | 2 | 4 |
| Test | 10606 | 45868 | 32.00 | 499.87 | 4.32 | 2 | 244 | 2 | 2 | 4 |
🔼 Table 3 presents a statistical overview of the dataset used for post-training the language model. It details the total number of prompts and responses, average lengths of prompts and responses (in words), and the distribution of the number of responses per prompt (minimum, maximum, median, and 25th and 75th percentiles). This information provides insights into the size and characteristics of the dataset, which are crucial for understanding the model’s training process and evaluating the results.
read the caption
Table 3: Post-training data characteristic. “Total P” and “Total R” stand for the number of all prompts and all responses in the dataset, respectively. “P len” and “R len” indicate the average number of words for prompts and responses, respectively. Other columns show statistics regarding the number of responses per prompt.
| Max | Min | Mean | Std | Median | 25th percentile | 75th percentile | |
| Raw | 23079 | 1 | 26.05 | 195.24 | 2 | 1 | 6 |
| Transformed | 1.0 | -1.0 | -0.07 | 0.58 | -0.05 | -0.31 | 0.40 |
🔼 This table presents a comparison of the original reddit-reward scores and their transformed versions used for training the reward model. The ‘Raw’ column displays the original score distribution, showing the minimum, maximum, mean, median, standard deviation, and 25th and 75th percentiles of the dataset’s scores. The ‘Transformed’ column shows the distribution of scores after applying a transformation to improve model training stability, indicating the minimum, maximum, mean, median, standard deviation, and 25th and 75th percentiles of the transformed scores.
read the caption
Table 4: The dataset’s score distribution on reddit-reward. “Raw” is for the original scores, and “transformed” indicates the version of scores transformed from the raw ones for reward model training.
| # from Step 1 | # from Step 2 | ||||
| 6 | 25 | 4 | 2 | 4 () | 4 () |
| 6 | 25 | 8 | 4 | 6 () | 6 () |
| 6 | 25 | 12 | 6 | 6 () | 6 () |
| 6 | 25 | 16 | 8 | 8 () | 6 () |
🔼 This table illustrates how the DivPO (Diverse Preference Optimization) method filters data. DivPO requires a specific filtering process to select the most and least diverse instances for training. This example showcases how the number of selected samples adapts depending on the initial number of responses per prompt and the DivPO parameter (ρ, representing the percentage of top and bottom responses to consider). It highlights the method’s dynamic sample size adjustment to ensure a consistent number of training instances, even when the initial data is limited.
read the caption
Table 5: Filtering example for DivPO experiments. # from Step 2 indicates the final number of filtered samples.
Full paper#