TL;DR#
Large Language Models (LLMs) heavily depend on GPU systems, but CPUs are becoming a more flexible and cost-effective alternative, especially for inference and reasoning tasks. RISC-V is gaining popularity due to its open and vendor-neutral Instruction Set Architecture (ISA). However, RISC-V hardware and software ecosystems for LLMs still require specific tuning. To address this, this paper focuses on optimizing LLM inference on Sophon SG2042, a commercially available many-core RISC-V CPU with vector processing.
This paper introduces V-SEEK and optimizes LLM inference by developing optimized kernels, selecting suitable compilation toolchains, and optimizing model mapping to address the memory hierarchy. The approach is evaluated on two open-source LLMs, DeepSeek R1 Distill Llama 8B and DeepSeek R1 Distill QWEN 14B. The results show speedups of up to 3.0x in token generation and 2.8x in prompt processing, reaching a throughput of 4.32/2.29 and 6.54/3.68 tok/s, respectively. This demonstrates the potential of RISC-V for LLM inference, achieving competitive performance and energy efficiency.
Key Takeaways#
Why does it matter?#
This paper presents a practical approach to accelerate LLM reasoning on RISC-V platforms, offering insights into optimizing performance and energy efficiency. It opens avenues for further research in hardware-aware LLM optimization and exploring the potential of RISC-V in AI.
Visual Insights#

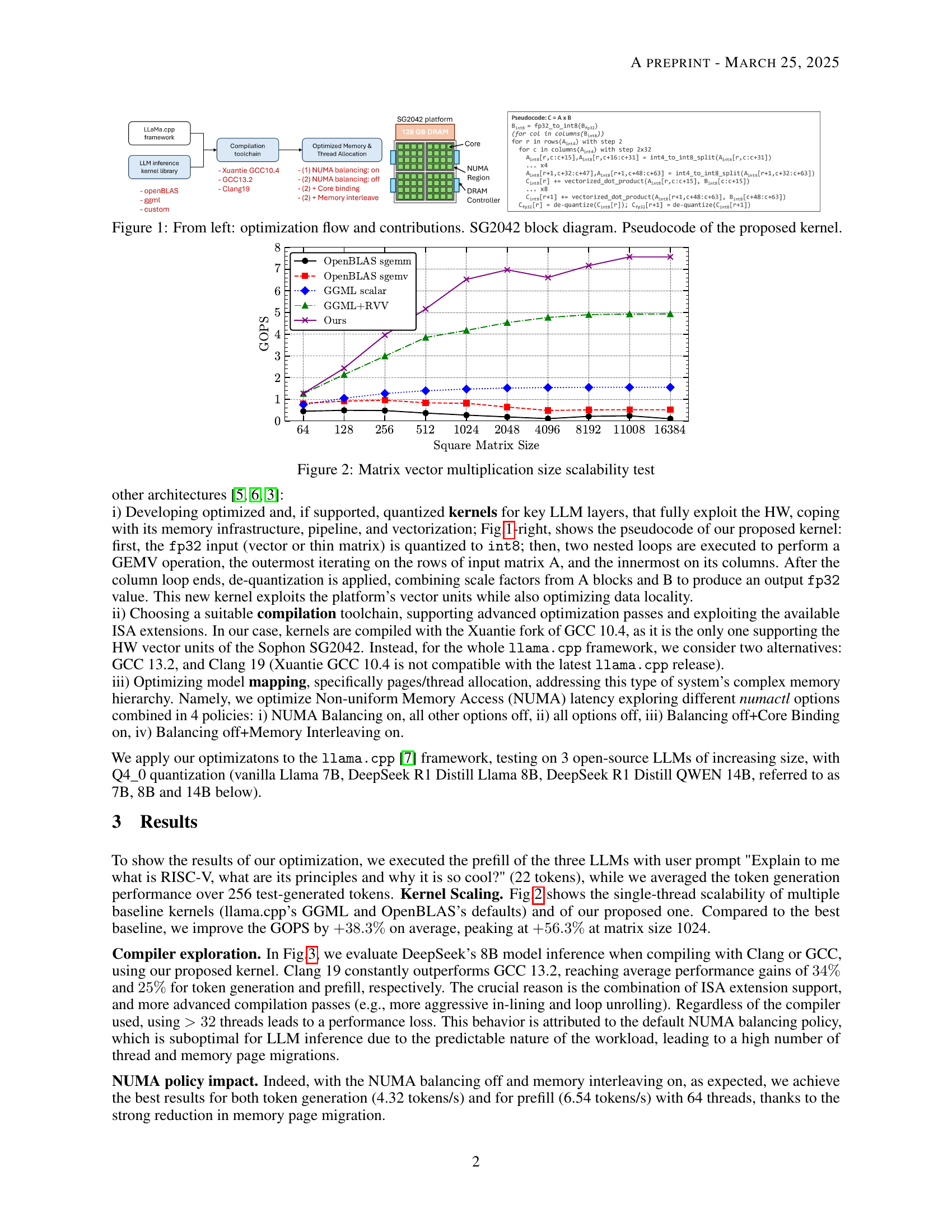
🔼 This figure provides a comprehensive overview of the optimization process and its components. The leftmost panel illustrates the optimization flow, detailing the steps involved in accelerating LLM reasoning on RISC-V platforms. This includes kernel optimization, compilation toolchain selection, and memory allocation strategies. The central panel presents a block diagram of the Sophon SG2042, a many-core RISC-V CPU, highlighting its key architectural features. Finally, the rightmost panel shows the pseudocode of the optimized kernel developed for this work, which is central to improving the performance of LLM inference on this platform.
read the caption
Figure 1: From left: optimization flow and contributions. SG2042 block diagram. Pseudocode of the proposed kernel.
In-depth insights#
RISC-V for LLMs#
RISC-V is emerging as a compelling alternative to GPUs and x86 CPUs for LLM inference, particularly due to its open-source nature and vendor neutrality. This allows for greater flexibility and customization. The paper addresses the gap in mature RISC-V hardware and software ecosystems for LLMs, optimizing inference on the Sophon SG2042, a many-core RISC-V CPU with vector processing. They achieved significant speedups on DeepSeek models. Key optimizations include developing quantized kernels, selecting a suitable compiler toolchain (Clang outperforms GCC), and optimizing model mapping with NUMA-aware thread allocation, reducing memory page migration. It is shown that a carefully optimized RISC-V platform can be competitive with incumbent architectures for specific LLM workloads. The research highlights the potential of RISC-V in democratizing access to LLM inference capabilities and paving the way for tailored hardware solutions.
SG2042 Optimizing#
Based on the paper, optimizing for the Sophon SG2042 involves a multi-faceted approach. Exploiting the RISC-V vector extensions (RVV) through custom kernel development is crucial for performance. The paper highlights the importance of choosing the right compiler toolchain, with Clang demonstrating superior performance over GCC due to better ISA extension support and advanced optimization passes. Careful model mapping and thread allocation are essential to mitigate NUMA effects and memory bottlenecks. Specifically, disabling NUMA balancing and enabling memory interleaving are key strategies to reduce memory page migrations and improve throughput. Ultimately, achieving optimal performance on the SG2042 requires a holistic approach encompassing kernel optimization, compiler selection, and memory management.
Compiler Impact#
The research indicates a significant impact of the compiler choice on LLM inference performance. Specifically, Clang 19 demonstrates superior performance compared to GCC 13.2, with average performance gains of 34% for token generation and 25% for prefill in the DeepSeek 8B model when using the proposed kernel. The primary reason is attributed to the combination of ISA extension support and more advanced compilation passes, such as more aggressive in-lining and loop unrolling. The study also reveals that using more than 32 threads leads to performance degradation, potentially due to a suboptimal NUMA balancing policy that causes excessive thread and memory page migrations. This highlight the importance of compiler selection and optimization techniques in maximizing the performance of LLM inference on RISC-V platforms and to avoid performance bottleneck.
NUMA Scaling#
NUMA (Non-Uniform Memory Access) scaling is a crucial aspect when optimizing LLM inference on multi-core systems, especially those with complex memory hierarchies. The key challenge is to minimize the latency associated with accessing memory that is not local to the processor core, as this can significantly impact performance. The paper explores different numactl options, which are essentially policies governing how memory is allocated and accessed across NUMA nodes. These policies include balancing memory access, disabling balancing altogether, binding cores to specific NUMA nodes, and interleaving memory across nodes. The effectiveness of each policy depends on the workload characteristics and the system architecture. Disabling NUMA balancing and enabling memory interleaving are found to be particularly effective for LLM inference, likely due to the predictable nature of the workload and the reduction in memory page migrations, resulting in improved token generation and prefill performance. The optimal NUMA configuration can significantly reduce memory access latency, resulting in considerable speedups for LLM tasks.
Open Source LLMs#
The paper highlights the importance of open-source LLMs as key drivers for innovation and accessibility in the field. It emphasizes the need for optimization on RISC-V platforms, a rapidly emerging architecture with its open and vendor-neutral ISA. By focusing on the Sophon SG2042, the first commercial many-core RISC-V CPU with vector processing capabilities, the research addresses the limitations of current software ecosystems optimized for x86 or ARM architectures. It emphasizes bridging the gap for LLM workloads, indicating the potential for lower hardware costs and enhanced flexibility. Performance results with DeepSeek R1 Distill Llama 8B and DeepSeek R1 Distill QWEN 14B highlight performance improvements in token generation and prompt processing, making them competitive with incumbent architectures. This work also shows improvements in efficiency by leveraging the available ISA extensions.
More visual insights#
More on figures
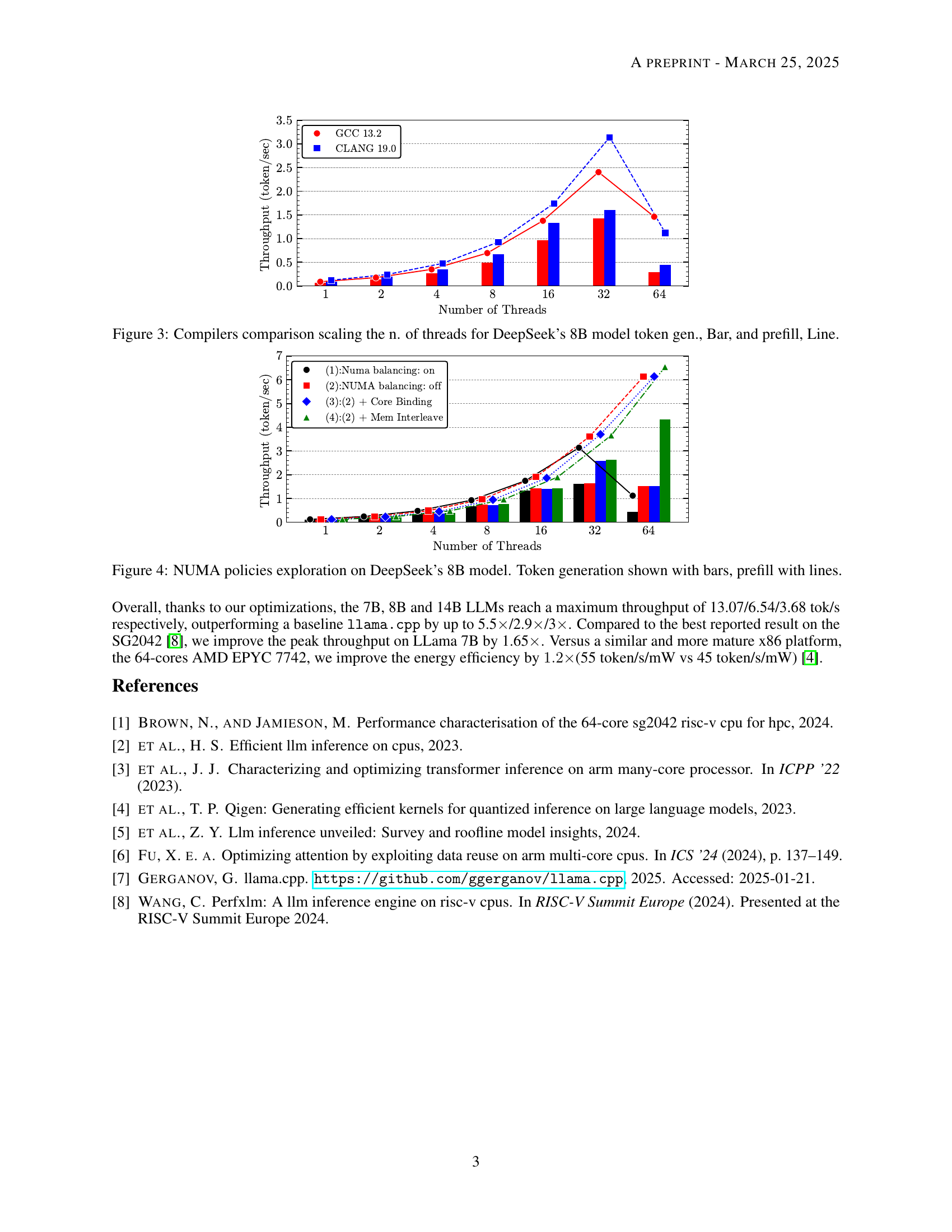
🔼 This figure shows the scalability of matrix-vector multiplication performance as the size of the square matrix increases. Different methods are compared, including OpenBLAS’s sgemm (general matrix multiplication) and sgemv (matrix-vector multiplication), a scalar GGML implementation, a GGML implementation using RISC-V vector instructions (RVV), and the authors’ optimized approach. The x-axis represents the size of the square matrix, and the y-axis represents the GOPS (gigaflops per second), a measure of computational performance. The graph illustrates how the performance of each method scales with the matrix size, highlighting the efficiency gains achieved by the authors’ optimized kernel.
read the caption
Figure 2: Matrix vector multiplication size scalability test
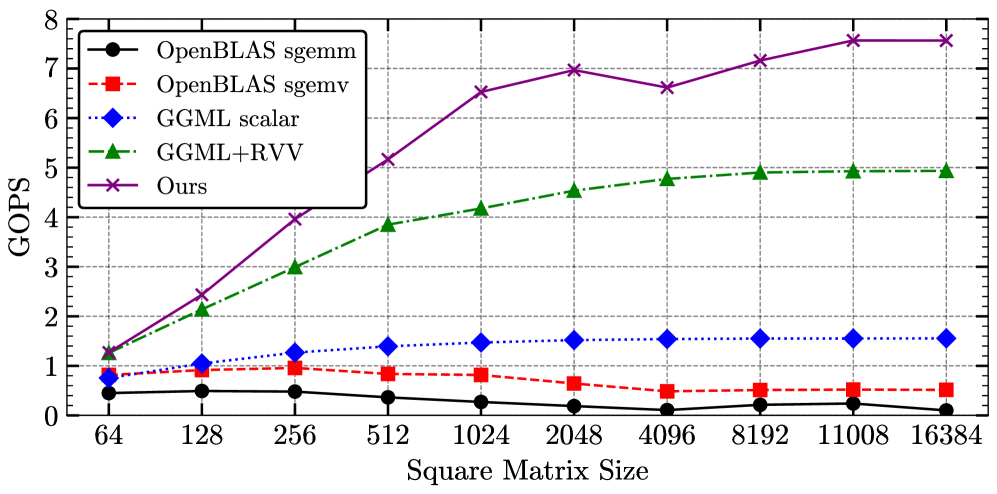
🔼 This figure compares the performance of two different compilers, GCC 13.2 and Clang 19.0, when compiling the code for DeepSeek’s 8B model on the Sophon SG2042. The x-axis represents the number of threads used, and the y-axis shows the throughput in tokens per second. Two sets of data are displayed. Bars represent the token generation throughput, while the line shows the prefill throughput. The results indicate that Clang 19.0 consistently outperforms GCC 13.2 across various thread counts, highlighting its advantage in optimizing the code for this particular model and hardware.
read the caption
Figure 3: Compilers comparison scaling the n. of threads for DeepSeek’s 8B model token gen., Bar, and prefill, Line.
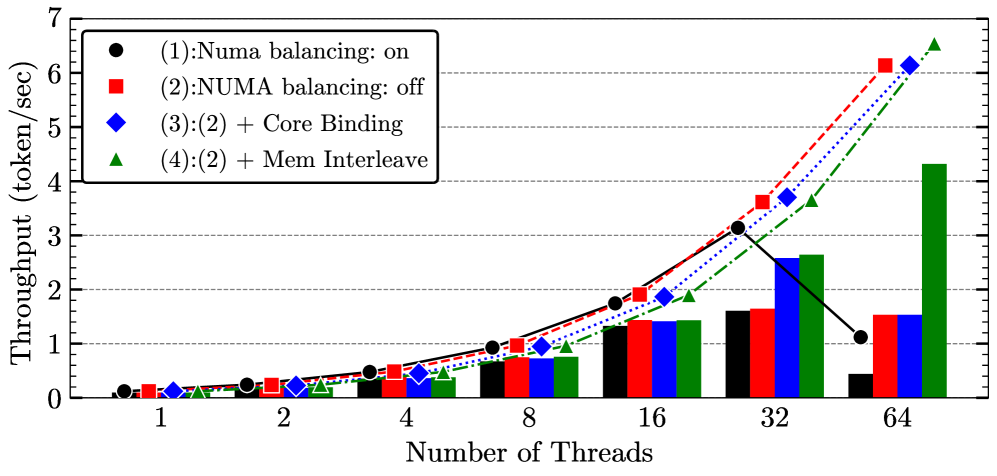
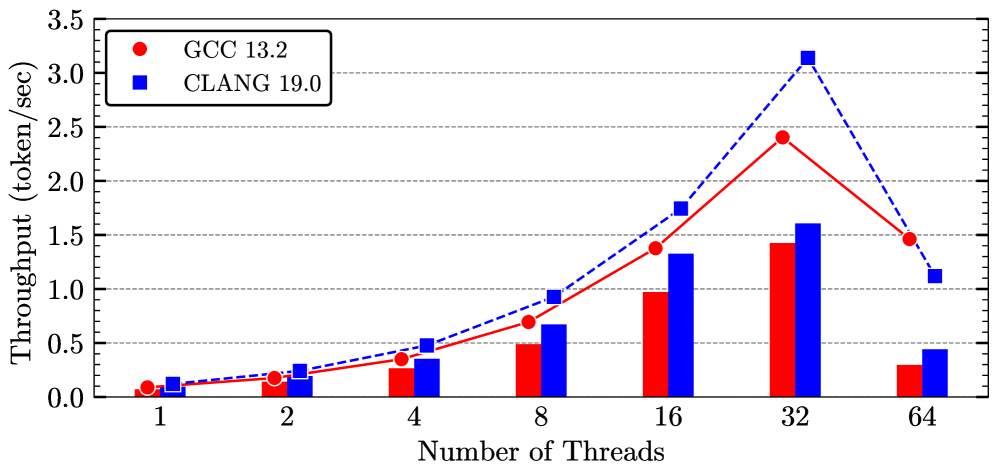
🔼 This figure shows the impact of different NUMA (Non-Uniform Memory Access) policies on the performance of DeepSeek’s 8B model. It compares four different NUMA configuration strategies: NUMA balancing enabled, NUMA balancing disabled, NUMA balancing disabled with core binding, and NUMA balancing disabled with memory interleaving. The performance is measured in terms of token generation (bars) and prefill (lines) throughput in tokens per second across different numbers of threads. This illustrates how different NUMA policies affect parallel processing efficiency and the resulting impact on speed of processing tokens during model operation.
read the caption
Figure 4: NUMA policies exploration on DeepSeek’s 8B model. Token generation shown with bars, prefill with lines.
Full paper#