TL;DR#
Video generation models have made remarkable strides, but applying them to downstream tasks with limited resources remains challenging. Parameter-efficient tuning methods on pre-trained models can fall short due to poor fitting ability and deviation from the target domain. Training smaller models from scratch, despite requiring effective data use and strategic learning, can be an alternative. This approach reduces dependence on source domain knowledge, focusing on adapting to the specifics of downstream application.
To address these issues, this paper introduces a resource-efficient dual-mask training framework (RDTF) for multi-frame animated sticker generation (ASG). RDTF constructs a discrete frame generation network and uses a dual-mask data utilization strategy to improve data availability and diversity. A difficulty-adaptive curriculum learning method is proposed to smooth convergence. Experiments show RDTF quantitatively and qualitatively outperforms efficient-parameter tuning methods.
Key Takeaways#
Why does it matter?#
This paper presents a novel and efficient method to overcome the resource limitations when training video generation models, making it highly relevant for researchers working on resource-constrained applications. It also highlights the importance of effective data utilization and curriculum learning.
Visual Insights#

🔼 This figure illustrates the resource-efficient dual-mask training framework (RDTF) for animated sticker generation. It highlights three key components: 1) A discrete frame generation network, designed to handle the unique characteristics of animated stickers (low frame rates and discrete frames). 2) Dual masks (condition and loss masks) which improve data utilization by selectively focusing on certain parts of the data during training, increasing the effective data size and diversity. 3) A difficulty-adaptive curriculum learning strategy, which gradually increases the difficulty of training data to enhance model convergence and performance. This framework allows for training smaller, more efficient video generation models, suitable for resource-constrained environments.
read the caption
Figure 1: An overview of resource-efficient dual-mask training framework. We propose a discrete frame generation network to model the discreteness between animated sticker frames. Furthermore, the dual masks, i.e.formulae-sequence𝑖𝑒i.e.italic_i . italic_e ., condition mask and loss mask, are designed to improve the availability and expand the diversity of limited data. The difficulty-adaptive curriculum learning is applied to facilitate convergence.
| Indicator | Customize-A-Video | I2V-Adapter | SimDA | Ours |
|---|---|---|---|---|
| FVD | 451.83 | 456.24 | 448.36 | 442.18 |
| VQA | 0.479 | 0.476 | 0.462 | 0.502 |
| CLIP | 0.377 | 0.367 | 0.372 | 0.376 |
🔼 This table presents a quantitative comparison of various video generation methods on the image and text to video (I&T→V) task, performed under constrained computational resources. The metrics used for comparison include Fréchet Video Distance (FVD), Video Quality Assessment (VQA), and CLIP similarity. Lower FVD scores indicate better temporal consistency, higher VQA scores reflect improved video quality, and higher CLIP similarity scores signify stronger semantic alignment between the generated video and the input text and image. The ‘best’ and ‘second-best’ results for each metric are highlighted in bold and underlined, respectively, allowing for easy identification of top-performing models within the resource constraints.
read the caption
Table 1: Quantitative comparison of different methods on I&T→→\rightarrow→V task under constrained resources. Bold and underline indicate the best and the second-best, respectively.
In-depth insights#
Data-Efficient ASG#
Data-efficient animated sticker generation (ASG) tackles the challenge of creating diverse and high-quality stickers with limited training data. This is crucial because acquiring large, labeled datasets for ASG can be expensive and time-consuming. Techniques like transfer learning from related domains (e.g., image or video generation) and few-shot learning methods can be leveraged to adapt pre-trained models to the ASG task using only a small amount of sticker data. Furthermore, data augmentation strategies specifically tailored for stickers, such as applying style transfer or creating variations of existing stickers, can artificially increase the size and diversity of the training set. Meta-learning approaches, where the model learns to learn from limited data, are also promising for data-efficient ASG. Additionally, generative models like GANs or VAEs can be trained on a small sticker dataset and then used to generate synthetic stickers to augment the training data, further improving the diversity and quality of the generated stickers. Effective use of unlabelled data or weak supervision is also beneficial.
Dual-Mask Training#
Dual-mask training appears to be a technique designed to enhance data utilization and diversity within a limited dataset, likely in the context of training a generative model. It probably uses two masks, potentially a condition mask and a loss mask, to selectively guide the training process. The condition mask might be used to switch between different training tasks like interpolation, prediction, and generation by masking out specific input components. The loss mask likely focuses the learning signal on specific regions or frames, perhaps to address long-tail distributions or improve information density. By carefully crafting these masks, the method aims to improve the availability and variability of the data, effectively augmenting the dataset and leading to better model generalization, especially in resource-constrained settings.
Adaptive Learning#
Adaptive learning is a crucial aspect of modern AI, especially in dynamic environments. It involves creating systems that can adjust their behavior and parameters based on real-time feedback and data. This adaptability is essential for handling variability and uncertainty. In the context of machine learning, this could mean adjusting the learning rate, model complexity, or feature selection process based on the observed performance during training. Curriculum learning, where the model is gradually exposed to increasingly complex examples, is one strategy. Another approach is to use reinforcement learning, where the system learns by interacting with its environment and receiving rewards or penalties. Efficient adaptive learning necessitates robust mechanisms for monitoring performance and identifying areas for improvement. Real-time adaptability improves not just the model’s accuracy but also its resilience and practical applicability.
Resource Limits#
The research confronts resource limitations head-on, a crucial consideration for real-world deployment. Balancing model size, training data, and computational power is paramount. The paper showcases a method effective with million-level samples, a significant reduction compared to many resource-intensive approaches. This is vital for democratizing AI, allowing development on more accessible hardware. The study tackles memory constraints (32G V100) head-on. Model efficiency becomes a core objective. While parameter-efficient tuning offers a path, the work argues that strategic data utilization and curriculum learning can enable smaller models trained from scratch to surpass fine-tuned behemoths in certain scenarios. There’s a trade-off though – increased training time compared to parameter-efficient tuning. Ultimately, the research pioneers a resource-conscious paradigm.
Future ASG Tasks#
Future advancements in Animated Sticker Generation (ASG) hinge on tackling key challenges. Scaling data and leveraging self/supervised learning for pre-trained models is crucial for capturing common sticker features and accelerating downstream task iteration. Addressing the unique characteristics of cartoon stickers, particularly the contrast between simple lines/color blocks and complex natural scenes, necessitates exploring disassembly/reconstruction techniques in the frequency domain. Modeling the creation process by emulating sketching and coloring offers a promising avenue for reducing complexity and improving sample quality. Finally, achieving detailed control over subject characterization and action modeling remains a vital, yet challenging, aspect of intelligent sticker creation, essential for generating high-quality and personalized content.
More visual insights#
More on figures

🔼 This figure shows the distribution of frame counts across the collected animated sticker dataset. The distribution is skewed towards shorter videos; there are significantly more stickers with a small number of frames than stickers with a large number of frames. This long-tail distribution is a key characteristic of the dataset used and influences the methods for training and data utilization described in the paper.
read the caption
Figure 2: Frame distribution in collected sticker dataset, which follows the long-tail distribution, i.e.formulae-sequence𝑖𝑒i.e.italic_i . italic_e ., more short frames and fewer long frames.

🔼 This figure illustrates a data augmentation technique used to improve the performance of the animated sticker generation model. The method involves clustering the frames of animated stickers into k groups based on their visual features. This clustering step aims to increase the information density of the dataset by highlighting common patterns within each cluster. By randomly selecting clusters during the model training process, the model is exposed to a wider range of visual patterns, thus potentially enhancing its learning and generalization capabilities. The original caption only briefly describes the clustering step; this expanded description provides a more comprehensive understanding of its purpose and effect within the training process.
read the caption
Figure 3: Frame extraction algorithm based on feature clustering. During training, data are clustered into k𝑘kitalic_k clusters randomly to increase the information density.

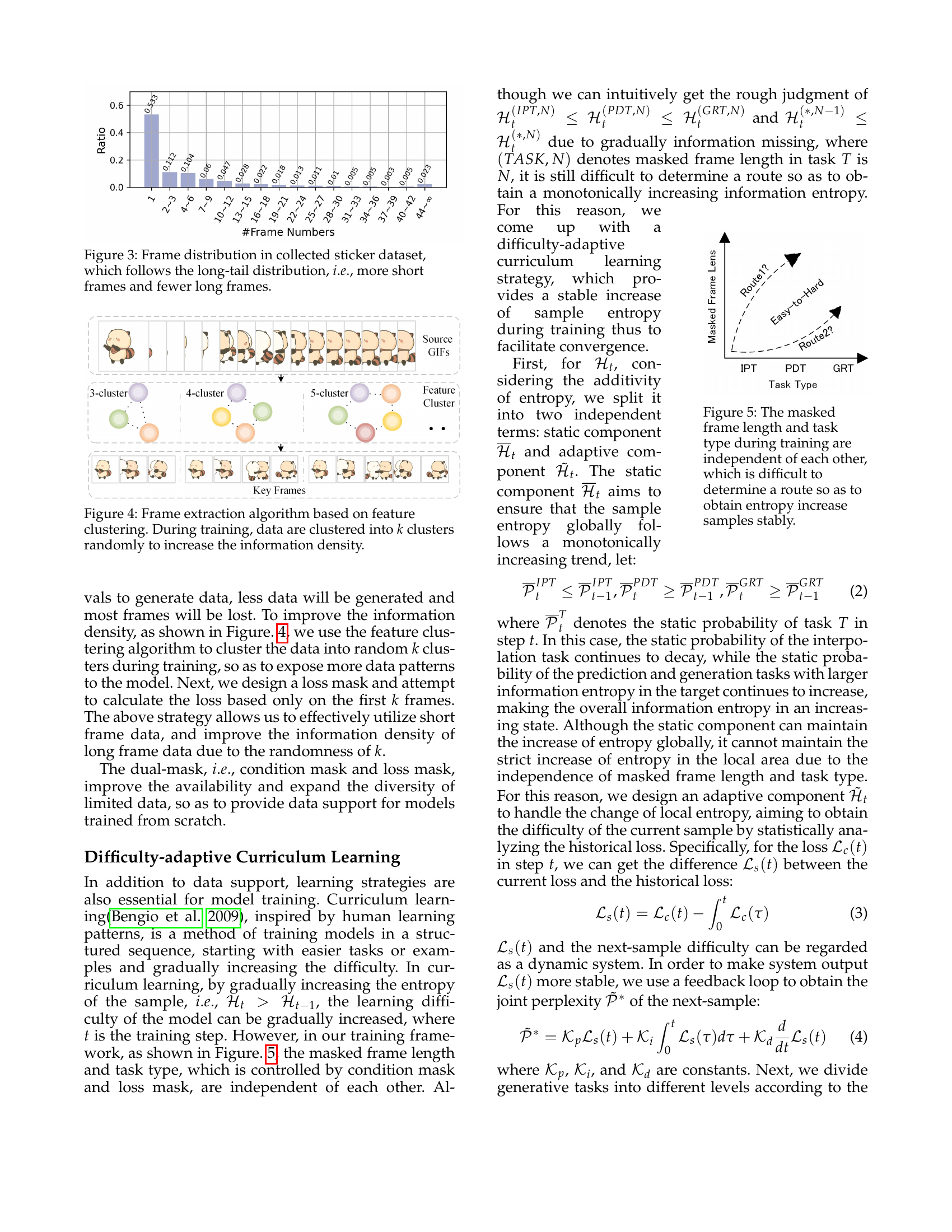
🔼 This figure illustrates the challenge in designing a curriculum learning strategy for animated sticker generation. The training process involves two independent factors: the length of the masked frames and the type of task being performed (interpolation, prediction, or generation). These factors are not directly correlated, making it difficult to create a curriculum that consistently increases the complexity of the training samples over time to facilitate stable model convergence. A suitable curriculum should smoothly increase the information entropy of the training data, gradually moving from simpler to more complex tasks. However, the independence of frame length and task type makes it difficult to create a curriculum that consistently increases entropy.
read the caption
Figure 4: The masked frame length and task type during training are independent of each other, which is difficult to determine a route so as to obtain entropy increase samples stably.

🔼 This figure displays a visual comparison of animated sticker generation results using four different methods: Customize-A-Video, I2V-Adapter, SimDA, and RDTF (the authors’ proposed method). Each method is applied to the same input (image and text), and the resulting animated stickers are shown. The comparison highlights the smoother and clearer motion achieved by the RDTF method compared to the other three. The caption encourages viewers to click to see dynamic results, suggesting the animation quality is a key aspect of the comparison.
read the caption
Figure 5: Visual comparison for animated sticker generation on I&T→→\rightarrow→V task between Customize-A-Video, I2V-Adapter, SimDA and RDTF. Compared with other methods, the motion obtained by RDTF method is smoother and clearer than others. Click here to see dynamic results.

🔼 Figure 6 presents a visual comparison of the interpolation and prediction capabilities of two video generation models: SimDA and the proposed RDTF (Resource-efficient Dual-mask Training Framework). The figure showcases example results for both tasks, highlighting the differences in generated video quality and detail. Grey boxes in the figure indicate where visual guidance was provided as input to the model. This comparison demonstrates RDTF’s superior performance in generating smoother and more visually appealing results compared to SimDA.
read the caption
Figure 6: Visual comparison for interpolation and prediction tasks between SimDA and RDTF. Gray boxes indicate visual guidance.
More on tables
| Method | FVD | VQA |
|---|---|---|
| I2V-Adapter | 213.71 | 0.517 |
| SimDA | 198.49 | 0.509 |
| Ours | 192.62 | 0.536 |
🔼 This table presents a quantitative comparison of different video generation methods for two specific tasks: interpolation and prediction. The comparison is performed under constrained computational resources. The methods are evaluated using two metrics: FVD (Fréchet Video Distance), a measure of video quality, and VQA (Video Quality Assessment), which assesses the video’s semantic coherence. Lower FVD scores and higher VQA scores indicate better performance. The table highlights the best-performing method for each task and metric by bolding and underlining the top two scores. This allows for a direct comparison of the efficiency and effectiveness of different approaches in generating high-quality videos within limited resource constraints.
read the caption
Table 2: Quantitative comparison of different methods for (left) interpolation and (right) prediction task under constrained resources. Bold and underline indicate the best and the second-best, respectively.
| Method | FVD | VQA |
|---|---|---|
| I2V-Adapter | 79.34 | 0.526 |
| SimDA | 74.68 | 0.521 |
| Ours | 67.92 | 0.539 |
🔼 This table presents the results of an ablation study evaluating the impact of different modules on the performance of the proposed model, RDTF, for animated sticker generation. The experiment systematically removes or changes components of the model architecture to analyze their individual contributions. The table compares the Fréchet Video Distance (FVD) and Video Quality Assessment (VQA) scores, two metrics for assessing video generation quality. Lower FVD indicates better similarity between generated and real videos and higher VQA indicates better perceived visual quality. The baseline model, DFGN, utilizes a 3D convolution as the temporal layer. Subsequent rows progressively add the dual-mask-based data utilization (DDU) strategy and the difficulty-adaptive curriculum learning (DCL) strategy. This demonstrates the individual and combined effects of these crucial components in achieving optimal performance.
read the caption
Table 3: Module ablation results. DFGN(3D-Conv) represents DFGN using 3D convolution as the temporal layer. DDU stands for dual-mask based data utilization strategy and DCL stands for difficulty-adaptive curriculum learning.
| Method (I&TV) | FVD | VQA |
|---|---|---|
| DFGN(3D-Conv) | 492.31 | 0.397 |
| DFGN | 478.47 | 0.435 |
| DFGN (w/ DDU) | 459.21 | 0.476 |
| DFGN (w/ DDU & w/ DCL) | 442.18 | 0.502 |
🔼 Table 4 presents a comparison of three different curriculum learning strategies used in training a model for animated sticker generation: no curriculum learning (W/o CL), monotonous curriculum learning (LCL), and difficulty-adaptive curriculum learning (DCL). The left side shows a quantitative comparison of these methods based on FVD (Fréchet Video Distance) and VQA (Video Quality Assessment) scores, demonstrating the impact of each learning strategy on the model’s performance. The right side visually demonstrates how task weights change over time during linear curriculum learning, illustrating the progression of training difficulty.
read the caption
Table 4: (Left) Quantitative comparison when using different curriculum learning strategies. W/o CL, LCL, and DCL denote without curriculum learning, monotonous curriculum learning, and difficulty-adaptive curriculum learning, respectively. (Right) Demonstration of task weight changes in linear curriculum learning.
| Method (I&TV) | FVD | VQA |
|---|---|---|
| RDTF (w/o CL) | 459.21 | 0.476 |
| RDTF (w/ LCL) | 451.65 | 0.484 |
| RDTF (w/ DCL) | 442.18 | 0.502 |
🔼 This table presents the results of a user study comparing different methods for animated sticker generation. Users ranked the stickers generated by each method based on three criteria: text alignment, interest, and motion smoothness. Higher scores indicate better performance. The best and second-best performing methods for each criteria are highlighted in bold and underlined, respectively. This allows for a qualitative comparison of the different models beyond the quantitative metrics presented earlier in the paper.
read the caption
Table 5: User study results. A higher score indicates superior performance. Bold and underline indicate the best and the second-best, respectively.
| Method (I&TV) | Text. | Interest. | Motion. |
|---|---|---|---|
| Customize-A-Video | 2.10 | 1.87 | 1.94 |
| I2V-Adapter | 1.90 | 1.73 | 1.71 |
| SimDA | 1.97 | 2.06 | 2.03 |
| RDTF | 2.03 | 2.34 | 2.31 |
🔼 Table 6 provides a comprehensive overview of the hyperparameters used in the Resource-efficient Dual-mask Training Framework (RDTF) for animated sticker generation. It details settings for various components of the model architecture, including spatial layers, STI (Spatial Temporal Interaction) layers, the diffusion process, and the dual-mask-based data utilization strategy and difficulty-adaptive curriculum learning. This table is crucial for understanding and replicating the experiments conducted in the paper.
read the caption
Table 6: Hyperparameters for our RDTF.
| Hyperparameter | RDTF |
| Spatial Layers | |
| Architecture | |
| LDM | ✓ |
| 8 | |
| Latent shape | 32 32 4 |
| Input channels | 8 |
| Output channels | 4 |
| Layers per block | 2 |
| Head channels | 64 |
| Condition | |
| Embedding dimension | 1024 |
| Text sequence length | 77 |
| STI Layers | |
| Architecture | |
| Convolution kernel size | 3,1,1 |
| Convolution layers | 2 |
| Num attention layers | 1 |
| Num attention heads | 8 |
| Attention head dim | 32 |
| Dual-mask based Data Utilization Strategy | |
| range of | 3-8 |
| Difficulty-adaptive Curriculum Learning | |
| 5.0 | |
| 3.0 | |
| 1.3 | |
| Training | |
| Parameterization | |
| Learnable para. | Full |
| # train steps | 50K |
| Learning rate | 1e-5 |
| Batch size per GPU | 1 |
| # GPUs | 16 |
| GPU-type | A100-40GB |
| Diffusion Setup | |
| Diffusion steps | 1000 |
| Noise schedule | Linear |
| 0.00085 | |
| 0.0120 | |
| Sampling Parameters | |
| Sampler | DDIM |
| Steps | 50 |
| 1.0 | |
| Text guidance scale | 7.5 |
| Img guidance scale | 7.5 |
🔼 This table details the different conditional masks used in the dual-mask training framework. Each row represents a different task (Interpolation, Prediction, Generation), and the columns show whether text guidance and/or visual (image) guidance are used for each task. The binary values in the ‘Visual Condition Mask’ column represent which frames are used as visual guidance in the corresponding task.
read the caption
Table 7: Different conditional mask definitions.
| Task | Text Guidance | Visual Condition mask |
| Interpolation | ✓ | [0 1 0 1 0 1 0 1] |
| ✓ | [1 0 1 0 1 0 1 0] | |
| ✓ | [1 0 0 1 0 0 1 0] | |
| … | ||
| Prediction | ✓ | [1 1 1 1 1 0 0 0] |
| ✓ | [0 0 1 1 1 1 1 1] | |
| … | ||
| Generation | ✓ | [1 0 0 0 0 0 0 0] |
| ✓ | [0 0 1 0 0 0 0 0] | |
| ✗ | [0 0 1 0 0 0 0 0] | |
| ✗ | [1 0 0 0 0 0 0 0] | |
| … | ||
🔼 This table compares the computational resource requirements and inference speeds of different video generation methods. It shows the number of parameters (in billions) and the average inference time (in seconds) for each method. The evaluation was performed using a single V100 GPU on input video clips with dimensions 1x8x256x256 (1 video, 8 frames, 256x256 pixels).
read the caption
Table 8: Parameters and inference costs comparison of different methods, which is evaluated on inputs of shape 1×8×256×256182562561\times 8\times 256\times 2561 × 8 × 256 × 256 with a single V100.
| Customize-A-Video | I2V-Adapter | SimDA | Ours | |
|---|---|---|---|---|
| (Ren et al. 2024) | (Guo et al. 2024a) | (Xing et al. 2024) | ||
| Param. (B) | 1.19 | 1.21 | 1.32 | 0.96 |
| Infer Time (s) | 0.42 | 0.42 | 0.43 | 0.39 |
🔼 This table presents a quantitative comparison of different video generation models’ performance on the OphNet2024 dataset, specifically focusing on the medical video generation task. The models are evaluated using two metrics: FVD (Fréchet Video Distance), which measures the discrepancy between generated videos and real videos, and VQA (Video Quality Assessment), which assesses the overall quality of the generated videos. Lower FVD scores and higher VQA scores indicate better performance. The table helps demonstrate the relative strengths of different models in generating high-quality medical videos, considering aspects such as visual fidelity and overall quality.
read the caption
Table 9: Comparison of different model test results on OphNet2024 dataset (Hu et al. 2024) in medical video generation task.
| Indicator | Customize-A-Video | I2V-Adapter | SimDA | Ours |
|---|---|---|---|---|
| FVD | 296.2 | 304.7 | 291.7 | 273.1 |
| VQA | 0.584 | 0.571 | 0.596 | 0.612 |
🔼 Table 10 presents a quantitative comparison of different video generation models’ performance on the unScene dataset (Wen et al., 2024), focusing on the autonomous driving video generation task. The table shows the Frechet Video Distance (FVD) and Video Quality Assessment (VQA) scores achieved by Customize-A-Video, I2V-Adapter, SimDA, and the authors’ proposed RDTF method. Lower FVD scores indicate better video quality, while higher VQA scores represent better overall perceptual quality. This comparison helps to evaluate the effectiveness of different models in generating realistic and high-quality videos for autonomous driving applications, considering factors such as visual fidelity and perceptual alignment with the intended content.
read the caption
Table 10: Comparison of different model test results on unScene dataset (Wen et al. 2024) in autonomous driving video generation task.
Full paper#