TL;DR#
Existing Omnimatte methods for video layer decomposition require extensive training or optimization, leading to high computational costs and long processing times. Current video inpainting techniques, when applied to object removal, often fail to preserve background fidelity or introduce temporal inconsistencies across frames. This limits their practicality for real-time applications.
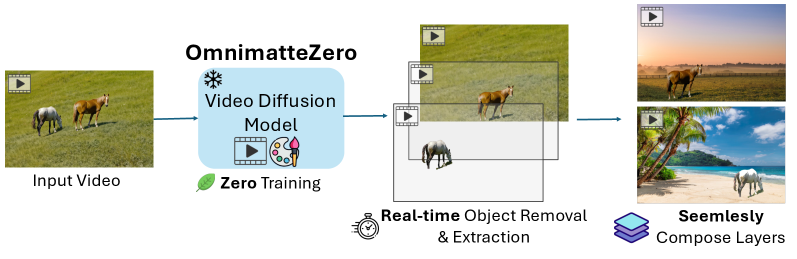
This paper introduces OmnimatteZero, a novel training-free approach that leverages pre-trained video diffusion models for real-time omnimatte. It adapts image inpainting techniques for video object removal, using self-attention maps to capture and inpaint object effects. This approach enables the extraction of clean background layers and object layers, which can be seamlessly recomposed onto new videos. OmnimatteZero achieves state-of-the-art performance in background reconstruction and runs in real-time.
Key Takeaways#
Why does it matter?#
This research enables real-time video editing and opens doors for new creative tools. The method’s efficiency and accessibility can facilitate broader adoption and exploration in video manipulation and content creation.
Visual Insights#
🔼 OmnimatteZero processes video by first encoding it and its corresponding mask into latent space. The object’s spatiotemporal footprint is identified and extracted from the encoding, using self-attention maps to incorporate associated effects (like reflections). Two inpainting methods are applied: one preserving background details (potentially leaving object traces), and one removing the object (possibly distorting the background). These results are blended using attention-based latent blending. Finally, denoising steps in a video diffusion model refine the result, yielding a high-quality reconstruction with the object removed and background preserved (high PSNR).
read the caption
Figure 1: Overview of OmnimatteZero-From left to right: The video and its corresponding object-masked version are encoded into the latent space. The spatio-temporal footprint of the target object is then identified and extracted from this encoding. Self-attention maps are leveraged to recognize effects associated with the object (such as a cat’s reflection), which are incorporated into both the object mask and the latent encoding. Using this mask, we apply two imperfect video inpainting methods: (a) Background-Preserving Inpainting, which retains background details but may leave behind traces of the object, and (b) Object-Removing Inpainting, which eliminates the object but might introduce background distortions. We refine the results through Attention-based Latent Blending, selectively combining the strengths of each inpainting method. Finally, few denoising steps of the video diffusion model enhances the blended output, producing a high-quality reconstruction with the object removed and the background well-preserved, as indicated by high PSNR values.
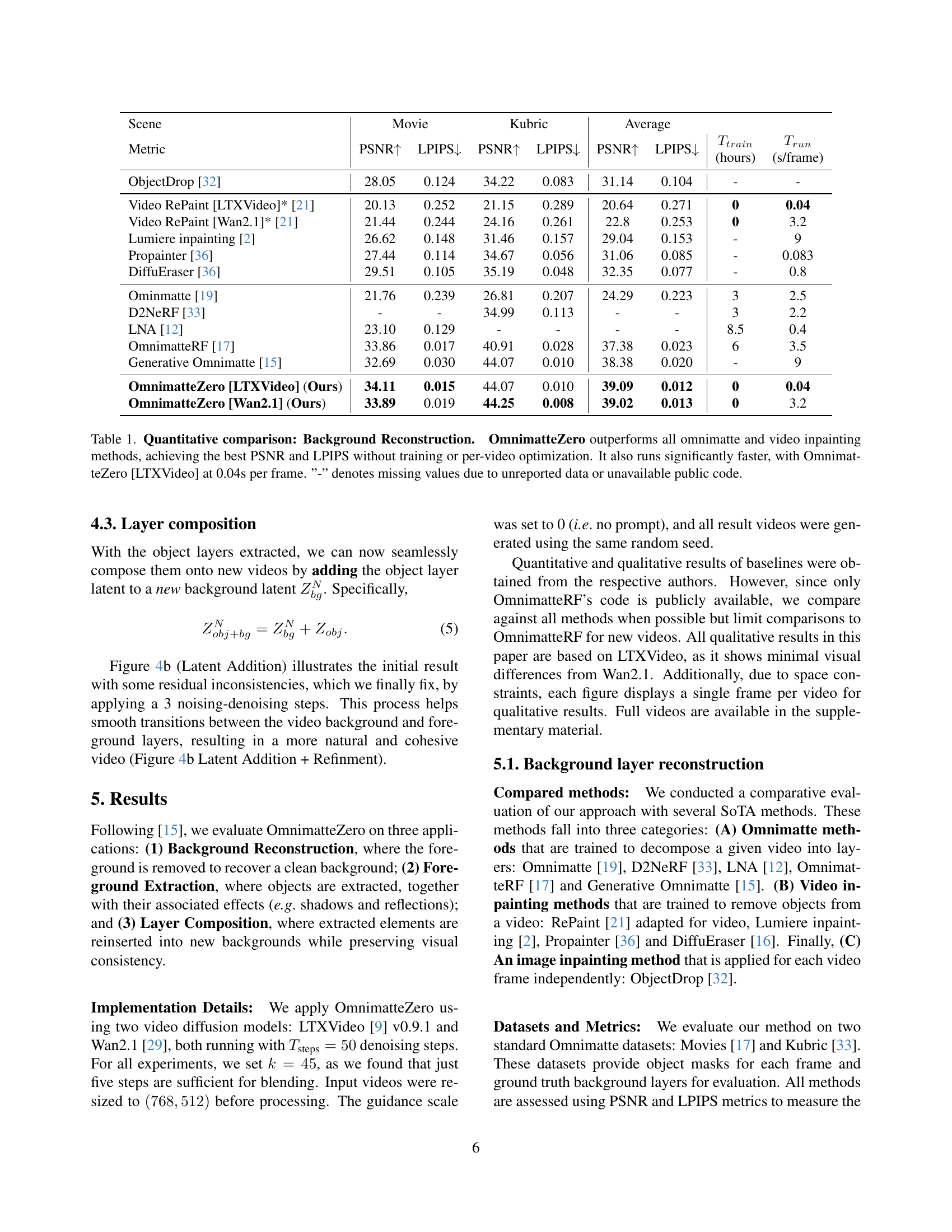
| Scene | Movie | Kubric | Average | |||||||||
| Metric | PSNR | LPIPS | PSNR | LPIPS | PSNR | LPIPS |
|
| ||||
| ObjectDrop [32] | 28.05 | 0.124 | 34.22 | 0.083 | 31.14 | 0.104 | - | - | ||||
| Video RePaint [LTXVideo]* [21] | 20.13 | 0.252 | 21.15 | 0.289 | 20.64 | 0.271 | 0 | 0.04 | ||||
| Video RePaint [Wan2.1]* [21] | 21.44 | 0.244 | 24.16 | 0.261 | 22.8 | 0.253 | 0 | 3.2 | ||||
| Lumiere inpainting [2] | 26.62 | 0.148 | 31.46 | 0.157 | 29.04 | 0.153 | - | 9 | ||||
| Propainter [36] | 27.44 | 0.114 | 34.67 | 0.056 | 31.06 | 0.085 | - | 0.083 | ||||
| DiffuEraser [36] | 29.51 | 0.105 | 35.19 | 0.048 | 32.35 | 0.077 | - | 0.8 | ||||
| Ominmatte [19] | 21.76 | 0.239 | 26.81 | 0.207 | 24.29 | 0.223 | 3 | 2.5 | ||||
| D2NeRF [33] | - | - | 34.99 | 0.113 | - | - | 3 | 2.2 | ||||
| LNA [12] | 23.10 | 0.129 | - | - | - | - | 8.5 | 0.4 | ||||
| OmnimatteRF [17] | 33.86 | 0.017 | 40.91 | 0.028 | 37.38 | 0.023 | 6 | 3.5 | ||||
| Generative Omnimatte [15] | 32.69 | 0.030 | 44.07 | 0.010 | 38.38 | 0.020 | - | 9 | ||||
| OmnimatteZero [LTXVideo] (Ours) | 34.11 | 0.015 | 44.07 | 0.010 | 39.09 | 0.012 | 0 | 0.04 | ||||
| OmnimatteZero [Wan2.1] (Ours) | 33.89 | 0.019 | 44.25 | 0.008 | 39.02 | 0.013 | 0 | 3.2 | ||||
🔼 Table 1 presents a quantitative comparison of OmnimatteZero against state-of-the-art (SoTA) omnimatte and video inpainting methods on the task of background reconstruction. The comparison is based on PSNR (Peak Signal-to-Noise Ratio) and LPIPS (Learned Perceptual Image Patch Similarity) metrics, which evaluate the quality of the reconstructed background. The results show that OmnimatteZero significantly outperforms all other methods in terms of both PSNR and LPIPS scores, indicating superior background reconstruction quality. Importantly, OmnimatteZero achieves this superior performance without requiring any model training or per-video optimization, unlike many of the other compared techniques. Furthermore, the table highlights the significant speed advantage of OmnimatteZero, with its LTXVideo implementation achieving a frame rate of 0.04 seconds per frame. Missing values in the table are denoted with a hyphen (-) and are due to either unreported data or unavailable public code from the respective authors.
read the caption
Table 1: Quantitative comparison: Background Reconstruction. OmnimatteZero outperforms all omnimatte and video inpainting methods, achieving the best PSNR and LPIPS without training or per-video optimization. It also runs significantly faster, with OmnimatteZero [LTXVideo] at 0.04s per frame. ”-” denotes missing values due to unreported data or unavailable public code.
In-depth insights#
Training-Free Edit#
Training-free editing represents a paradigm shift in media manipulation, circumventing the need for extensive model training or per-instance optimization. This approach is particularly valuable because traditional methods often demand significant computational resources and time, hindering real-time or rapid iteration workflows. By leveraging pre-trained models, such as video diffusion models, training-free techniques enable object removal, extraction, and seamless layer composition with remarkable efficiency. The core benefit is the ability to perform complex video edits, like omnimatte, without any model training or optimization, greatly improving efficiency and accessibility. Methods adapting zero-shot image inpainting are vital, as they handle video object removal, using self-attention maps to capture object information and its effects, achieving clean backgrounds and seamless object integration into new scenes. This promises unprecedented flexibility.
Attention Insight#
Attention mechanisms are pivotal in OmnimatteZero, offering insights beyond mere object recognition. Self-attention maps reveal not only the object’s location but also its contextual relationships, capturing associated effects like shadows and reflections. This is achieved by analyzing the interactions between query and key tokens, extracting a soft mask to identify object-related areas. The innovation lies in leveraging pre-trained video diffusion models without additional training, efficiently masking object effects and extracting object layers. This contrasts with image models which struggle to grasp such contextual nuances. By using attention, the system can discern and isolate elements related to an object (shadows etc). This enables more precise manipulation and recomposition of video layers which leads to realistic layer integration, ensuring visual coherence across diverse scenes. Therefore, attention is key in the model.
Real-time Latent#
Real-time latent space manipulation is a promising research area. It focuses on achieving fast video editing leveraging the latent space of pre-trained video diffusion models. Methods operating in the latent space offer computational advantages by manipulating compressed representations. Real-time performance requires efficient VAE encoders/decoders for fast conversion between pixel and latent spaces, also enabling faster video editing applications. Challenges include preserving video fidelity, avoiding artifacts, and maintaining temporal consistency across frames. Future research should explore new architectures and training techniques to improve the quality and efficiency of real-time latent space video editing.
Effect Extraction#
While the paper does not explicitly use the heading “Effect Extraction,” it implicitly addresses this concept through its techniques for omnimatte. The key idea is to isolate not only the object itself but also its associated visual effects, such as shadows, reflections, and subtle lighting interactions within the video scene. Traditional methods struggle to separate these effects from the object or the background, often leading to incomplete or unrealistic results. This paper addresses this limitation by leveraging self-attention mechanisms within pre-trained video diffusion models to identify and mask these effects. The method identifies that video diffusion models capture these effects due to their spatio-temporal context awareness, unlike image diffusion models. By accurately extracting these effects, the method enables more realistic object removal, manipulation, and composition into new scenes, significantly enhancing the realism and visual quality of video editing.
VAE Limits#
While VAEs are powerful tools for representation learning and generative modeling, they do have limitations. One key challenge is the trade-off between reconstruction accuracy and latent space disentanglement. Achieving a highly disentangled latent space, where each dimension controls a specific factor of variation, often comes at the cost of poorer reconstruction quality. Another limitation is the blurriness often observed in generated samples, particularly when using simple decoders. This is due to the loss function used during training, which encourages the model to average over possible outputs, leading to blurry results. Furthermore, VAEs can struggle with modeling complex, high-dimensional data distributions effectively, particularly when the underlying data manifold is highly non-linear. This can result in the latent space not accurately capturing the true structure of the data, leading to suboptimal generation and representation learning. In the context of video, it is also hard to maintain temporal consistency.
More visual insights#
More on figures

🔼 This figure demonstrates the key difference in how video diffusion models and image diffusion models process and understand contextual information, specifically focusing on ‘object-associated effects’. Panel (a) shows self-attention maps from the LTX Video diffusion model; these maps highlight the model’s ability to connect an object not only to its immediate visual features but also to related contextual elements like shadows and reflections. This demonstrates the model’s comprehension of spatio-temporal relationships. In contrast, panel (b) presents self-attention maps from a Stable Diffusion image model, showcasing its inability to make these same object-context connections. The image model focuses only on the object itself, lacking the understanding of the surrounding effects crucial for realistic video editing. This difference underscores the challenges of directly applying image inpainting techniques to video, motivating the development of a dedicated video-centric approach.
read the caption
Figure 2: Self-attention maps from (a) LTX Video diffusion model and (b) Image based Stable Diffusion. The spatio-temporal video latent ”attends to object associated effects” (e.g., shadow, reflection) where, image models struggles to capture these associations.

🔼 Figure 3 illustrates the process of foreground extraction and layer composition using latent video representations. (a) Foreground Extraction: First, the object’s latent representation is obtained by subtracting the background’s latent representation from the combined latent representation of the object and background. This produces an initial object extraction, but with some distortions. These distortions are corrected by replacing the distorted pixel values with those from the original video based on a mask, leading to a refined object layer. (b) Layer Composition: The refined object layer is added to the latent representation of a new background. To enhance the seamless blending of the object into the new background, several steps of SDEdit are performed, producing a more natural-looking result.
read the caption
Figure 3: (a) Foreground Extraction: The target object is extracted by latent code arithmetic, subtracting the background video encoding from the object+background latent (Latent Diff). This initially results in distortions, which are later corrected by replacing pixel values using the original video and a user-provided mask (Latent Diff + Refinement). (b) Layer Composition: The extracted object layer is added to a new background latent (Latent Addition). To improve blending, a few steps of SDEdit are applied, yielding a more natural integration of the object into the new scene (Latent Addition + SDEdit).

🔼 This figure showcases qualitative results of object removal and background reconstruction. The top row displays input video frames overlaid with object masks, highlighting the areas targeted for removal. The bottom row shows the resulting reconstructed backgrounds after applying the OmnimatteZero method. The results demonstrate the method’s effectiveness in removing objects while preserving fine details such as reflections, shadows, and textures, even across diverse scenes. Specific examples highlighted include the successful removal of a cat’s reflection in a mirror and water, a dog’s shadow, and the subtle bending of a trampoline caused by jumpers, all of which are faithfully maintained in the reconstructed background.
read the caption
Figure 4: Qualitative Results: Object removal and background reconstruction. The first row shows input video frames with object masks, while the second row presents the reconstructed backgrounds. Our approach effectively removes objects while preserving fine details, reflections, and textures, demonstrating robustness across diverse scenes. Notice the removal of the cat’s reflection in the mirror and water, the shadow of the dog and bicycle (with the rider), and the bending of the trampoline when removing the jumpers.

🔼 Figure 5 presents a qualitative comparison of OmnimatteZero’s object removal and background reconstruction capabilities against three state-of-the-art methods: Generative Omnimatte, DiffuEraser, and ProPainter. The figure showcases several examples where input videos (with object masks) are processed by each method. OmnimatteZero consistently produces cleaner background reconstructions with fewer artifacts than the other methods. Generative Omnimatte leaves some residual traces, while DiffuEraser and ProPainter struggle to completely remove objects and leave noticeable artifacts (highlighted in red). Notably, the bottom two rows highlight OmnimatteZero’s superior ability to remove not only objects but also associated effects such as shadows and reflections, which the other methods fail to achieve.
read the caption
Figure 5: Qualitative Comparison: Object removal and background reconstruction. Our approach achieves cleaner background reconstructions with fewer artifacts while Generative Omnimatte [15] leaves some residuals, DiffuEraser [16] and ProPainter [36] struggle with noticeable traces (highlighted in red). The last two rows show that OmnimatteZero successfully removes effects where others fail.

🔼 This figure compares the foreground extraction capabilities of OmnimatteZero and OmnimatteRF. It demonstrates that OmnimatteZero more accurately captures objects and their associated effects (shadows and reflections). OmnimatteRF, in contrast, frequently misses or distorts these effects, as shown in rows 2 and 3 of the figure which highlight examples of shadow and reflection inaccuracies.
read the caption
Figure 6: Qualitative Comparison: Foreground Extraction. Foreground extraction comparison between OmnimatteZero and OmnimatteRF [17]. Our method accurately captures both the object and its associated effects, such as shadows and reflections, in contrast to OmnimatteRF, often missing or distorting shadows (row 2) and reflections (row 3).

🔼 This figure demonstrates the ability of the OmnimatteZero method to seamlessly integrate extracted foreground objects (along with their associated shadows and reflections) into various background videos. It showcases the visual coherence and realism achieved by the approach, highlighting its ability to maintain visual consistency across diverse scenes, even when objects and effects are complex and interact with the background in non-trivial ways.
read the caption
Figure 7: Qualitative Comparison: Layer Composition. The extracted foreground objects, along with their shadows and reflections, are seamlessly integrated into diverse backgrounds, demonstrating the effectiveness of our approach in preserving visual coherence and realism across different scenes.
Full paper#