TL;DR#
Current Vision-Language Models(VLMs) struggle with 3D spatial reasoning, hindering their ability to generate realistic and coherent 3D scenes for applications like metaverse. Supervised fine-tuning(SFT) is limited as there is no single correct layout and existing methods often require extensive post-processing to ensure physical plausibility, coherence and structural consistency. Therefore, there is a need to enhance VLM with 3D spatial reasoning for real-time 3D scene generation, eliminating hard-coded optimization.
To address these issues, MetaSpatial, a reinforcement learning(RL) framework, enhances 3D spatial reasoning in VLMs. This approach involves a multi-turn RL-based optimization mechanism integrating physics-aware constraints and rendered image evaluations. It introduces an adaptive, iterative reasoning process, enabling VLMs to refine spatial arrangements over multiple turns by analyzing rendered outputs, ensuring generated 3D layouts are coherent, physically plausible, and aesthetically consistent.
Key Takeaways#
Why does it matter?#
This paper introduces a novel RL approach to enhance 3D spatial reasoning in VLMs, a critical area for metaverse, AR/VR, and digital twin development. It offers practical solutions to overcome the limitations of current VLM technologies and sets new directions for future research in AI-driven 3D content creation, offering generalizable methods for creating intelligent systems.
Visual Insights#

🔼 MetaSpatial is a reinforcement learning framework that enhances 3D spatial reasoning in vision-language models (VLMs). The figure illustrates its process: given a room image, user preferences, and object information, the VLM generates a JSON layout with precise (x,y,z) coordinates and a reasoning trace explaining its decisions. This layout is then evaluated by three reward signals: Format Detection (correct JSON structure), Physical Detection (physical plausibility, no collisions), and Rendering-based Evaluation (aesthetic quality, judged by a language model). The RL algorithm uses multiple multi-turn refinement trajectories (iterative improvements to the layout), optimized with Group Relative Policy Optimization (GRPO) to learn better spatial reasoning from various outcomes.
read the caption
Figure 1: Overview of MetaSpatial framework. Given room images, user preferences, and object status, the model generates a JSON-formatted object layout with precise (x, y, z) coordinates and a reasoning process. It evaluates the layout using three reward signals: Format Detection, Physical Detection, and Rendering-based Evaluation. The RL updates are based on multiple multi-turn refinement trajectories, optimizing a grouped policy via Group Relative Policy Optimization (GRPO) to enable the VLM to learn deeper spatial reasoning from diverse refinement outcomes.
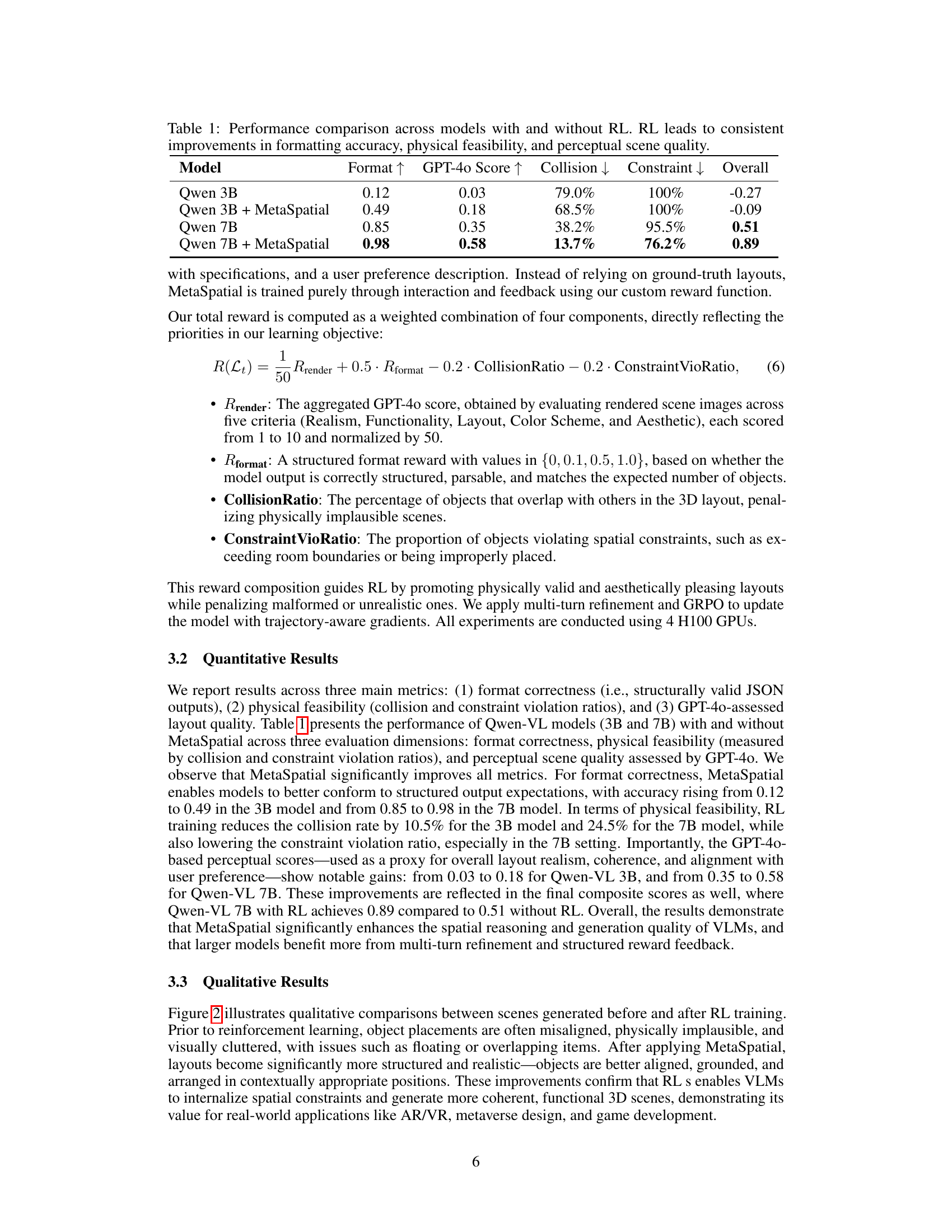
| Model | Format | GPT-4o Score | Collision | Constraint | Overall |
|---|---|---|---|---|---|
| Qwen 3B | 0.12 | 0.03 | 79.0% | 100% | -0.27 |
| Qwen 3B + MetaSpatial | 0.49 | 0.18 | 68.5% | 100% | -0.09 |
| Qwen 7B | 0.85 | 0.35 | 38.2% | 95.5% | 0.51 |
| Qwen 7B + MetaSpatial | 0.98 | 0.58 | 13.7% | 76.2% | 0.89 |
🔼 This table compares the performance of vision-language models (VLMs) with and without reinforcement learning (RL) enabled by the proposed MetaSpatial framework. It shows consistent improvements across three key metrics when RL is applied: formatting accuracy (how well the generated layout adheres to the expected JSON format), physical feasibility (how often generated object placements are physically plausible, without collisions or impossible placements), and perceptual scene quality (as assessed by a GPT-40 language model evaluating the realism and overall aesthetic quality of the rendered 3D scene). The results highlight the benefits of using RL to enhance 3D scene generation in VLMs.
read the caption
Table 1: Performance comparison across models with and without RL. RL leads to consistent improvements in formatting accuracy, physical feasibility, and perceptual scene quality.
In-depth insights#
RL 4 3D Layout#
Reinforcement Learning (RL) offers a compelling paradigm for 3D layout tasks, addressing limitations of supervised learning. Unlike fixed datasets, RL enables dynamic adaptation to varying spatial constraints and design goals. This is especially relevant in 3D layout, where numerous valid configurations exist for a given scene. RL facilitates learning from interactive feedback, optimizing for physical plausibility and aesthetic coherence. By defining appropriate reward functions (e.g., collision avoidance, user preference alignment), an agent can iteratively refine object placements, achieving realistic and functional layouts. The exploration inherent in RL can also lead to novel and creative arrangements beyond those present in training data. However, designing effective reward functions is crucial; they must be carefully crafted to guide the agent towards desired outcomes without over-constraining the solution space. Challenges include balancing competing objectives (e.g., realism vs. aesthetics) and ensuring efficient exploration to avoid local optima. Despite these challenges, RL holds significant promise for automated 3D layout generation, especially when integrated with other techniques like generative models or constraint programming to enhance its capabilities and improve solution quality.
MetaSpatial VLM#
The concept of “MetaSpatial VLM” suggests a novel approach to integrating spatial reasoning capabilities within Vision-Language Models, potentially revolutionizing how VLMs interact with and understand 3D environments. The “MetaSpatial” aspect likely refers to imbuing the VLM with an awareness of spatial relationships, object arrangements, and physical constraints inherent in real-world or simulated 3D spaces. This could involve new architectures, training methodologies, or data representations that allow the VLM to process and generate information grounded in a 3D context. A key challenge lies in effectively encoding and representing spatial information in a way that VLMs can readily learn and utilize. This may also involve using reinforcement learning to guide spatial layout refinement. The ultimate goal would be to enable VLMs to generate realistic and coherent 3D scenes from textual descriptions or visual cues, paving the way for advancements in metaverse creation, AR/VR applications, and robotics. **Enhancements in spatial understanding, including physical plausibility and coherence, mark a significant step forward.
GRPO Refinement#
The paper introduces Group Relative Policy Optimization (GRPO) as a crucial element for training VLMs in 3D spatial reasoning, addressing the limitations of traditional methods. GRPO optimizes spatial understanding by leveraging grouped refinement trajectories and relative reward comparisons. This eliminates the need for ground truth labels, relying on constraint-driven and evaluative feedback, fostering adaptable spatial reasoning. Key benefits include encouraging high-quality layouts in early refinement steps, eliminating the need for ground truth labels, and facilitating stable, group-wise updates, enhancing generalization. GRPO is designed to promote diverse exploration of the state space, leading to more robust and generalizable policies, making the training process more efficient.
Adaptive Spatial#
While the exact phrase “Adaptive Spatial” isn’t present, the research points towards that direction. The core of the idea would revolve around creating systems that can dynamically adjust their understanding and manipulation of space. This might involve adapting to different scales, recognizing objects under varying conditions, and maintaining spatial consistency even with noisy or incomplete data. Adaptive spatial reasoning would require robust perception, allowing models to interpret visual inputs from different viewpoints and lighting conditions. Furthermore, it needs sophisticated memory to track objects and their relationships over time. The system should be able to handle uncertainty, updating its spatial understanding as new information becomes available. This adaptability will be crucial for deploying these models in real-world scenarios, where the environment is constantly changing and the unexpected is common. Crucially, adaptation isn’t just about correcting errors but about proactively refining spatial understanding based on prior experience, creating a positive feedback loop that enhances performance over time. The ultimate goal would be to create AI agents that can interact with the physical world in a safe, reliable, and intelligent manner.
Towards AR/VR#
The paper’s exploration of reinforcement learning (RL) to enhance 3D spatial reasoning in VLMs has significant implications for AR/VR applications. MetaSpatial’s ability to generate coherent and physically plausible 3D scenes in real-time addresses a key challenge in creating immersive AR/VR experiences. By internalizing spatial constraints through RL, the system reduces the reliance on manual design or extensive post-processing, making it more scalable for dynamic virtual environments. The multi-turn refinement strategy allows for iterative improvements in scene quality, crucial for AR/VR where user interaction demands responsive and realistic environments. The focus on perceptual coherence and alignment with user preferences ensures that generated scenes are aesthetically pleasing and functional, contributing to user engagement and usability. Furthermore, the research suggests a move towards more interactive and adaptive AR/VR systems that respond dynamically to user input and changing environmental conditions. This will be crucial in creating highly responsive and personalized experiences.
More visual insights#
More on tables
| Reward Setting | Format | GPT-4o Score | Collision | Constraint |
|---|---|---|---|---|
| Full Reward (Ours) | 0.98 | 0.58 | 13.7% | 76.2% |
| w/o Rendering () | 0.96 | 0.45 | 17.5% | 80.5% |
| w/o Physics () | 0.97 | 0.40 | 35.0% | 89.6% |
| w/o Format () | 0.72 | 0.41 | 16.3% | 84.8% |
🔼 This ablation study investigates the impact of each reward component (format, rendering, and physics) on the overall performance of the MetaSpatial model using the Qwen2.5-VL 7B. By removing one component at a time, it shows how each reward type contributes to the model’s ability to generate high-quality 3D layouts. The results demonstrate the relative importance of each reward component in terms of format accuracy, GPT-40 score, collision rate, and constraint violation rate.
read the caption
Table 2: Ablation study of reward components on Qwen2.5-VL 7B.
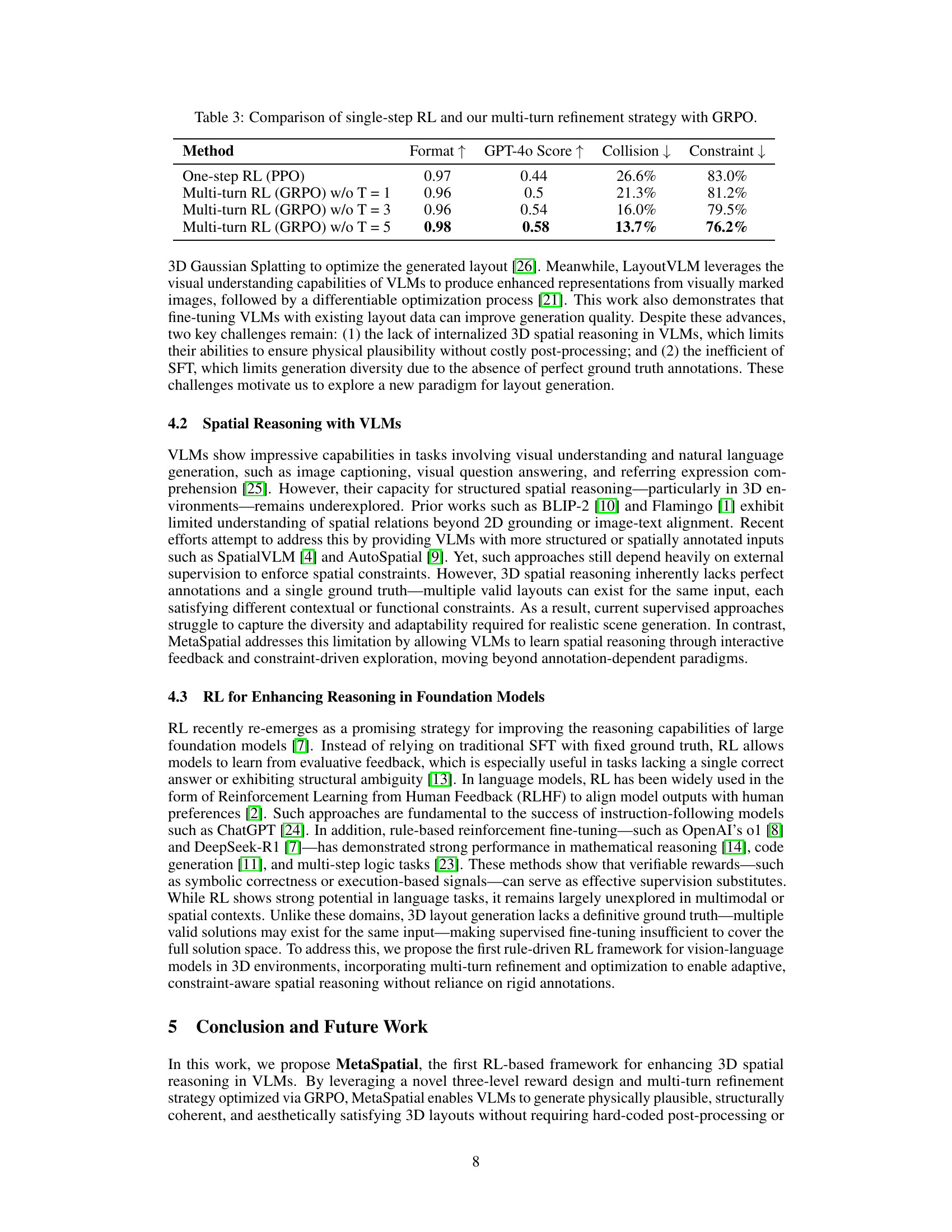
| Method | Format | GPT-4o Score | Collision | Constraint |
|---|---|---|---|---|
| One-step RL (PPO) | 0.97 | 0.44 | 26.6% | 83.0% |
| Multi-turn RL (GRPO) w/o T = 1 | 0.96 | 0.5 | 21.3% | 81.2% |
| Multi-turn RL (GRPO) w/o T = 3 | 0.96 | 0.54 | 16.0% | 79.5% |
| Multi-turn RL (GRPO) w/o T = 5 | 0.98 | 0.58 | 13.7% | 76.2% |
🔼 This table compares the performance of single-step reinforcement learning (RL) using Proximal Policy Optimization (PPO) with MetaSpatial’s multi-turn refinement strategy using Group Relative Policy Optimization (GRPO). It shows the impact of the multi-turn approach on several key metrics: format accuracy (how well the model generates correctly structured JSON outputs), GPT-40 score (a measure of the overall quality and realism of the 3D scene as evaluated by a large language model), collision ratio (the percentage of objects that overlap unnaturally), and constraint violation ratio (the percentage of objects violating spatial constraints). Different numbers of refinement turns (T) are compared for the GRPO method to demonstrate the effect of increasing the number of iterative improvements on model performance.
read the caption
Table 3: Comparison of single-step RL and our multi-turn refinement strategy with GRPO.
Full paper#