TL;DR#
Large language models (LLMs) are now used as AI agents, which have significantly advanced code generation. However, even with test-time reasoning, these systems struggle with complex software tasks. Current methods also rely on static datasets, limiting the model’s capacity to dynamically refine outputs. To address this, the paper introduces a new approach to enhance code generation capabilities and reasoning in AI agents.
This paper introduces a code generation and reasoning agent based on LLMs (CURA), enhanced by a novel verbal process supervision (VPS). The CURA improves code understanding and reasoning through iterative feedback at each step. Results show that CURA achieves better performance on challenging benchmarks. The VPS guides the reasoning process, enabling the agent to generate better code. This integrated approach improves performance by combining feedback and supervision throughout the reasoning pipeline.
Key Takeaways#
Why does it matter?#
This paper introduces CURA, a novel code generation framework enhanced by verbal process supervision(VPS), leading to performance improvements. Researchers can leverage the VPS technique to improve code generation capabilities for existing reasoning and chat models. This work opens avenues for integrating reasoning-driven architectures with LLM-based code generation, enabling agents to tackle complex software engineering tasks more effectively.
Visual Insights#

🔼 The CURA architecture is an iterative process-supervised reasoning framework for code generation. It starts with understanding the problem, generating test cases, and then generating code through solution reasoning. The generated code is executed in a sandbox to verify its correctness. At each step, a process reward model provides verbal reward signals, guiding the model towards better solutions. These signals refine the model’s behavior without the need for fine-tuning, enhancing its performance iteratively.
read the caption
Figure 1: The CURA architecture: a process-supervised reasoning framework incorporating verbal reward signals.
In-depth insights#
VPS for LLM Code#
Verbal Process Supervision (VPS) holds significant promise for enhancing Large Language Model (LLM) code generation. The core idea revolves around providing LLMs with step-by-step guidance through natural language feedback, rather than solely relying on final execution results. This is particularly beneficial because it addresses the inherent limitations of LLMs in complex, multi-step reasoning and debugging tasks. By incorporating VPS, LLMs can iteratively refine their code generation process, leading to more accurate and robust solutions. Furthermore, VPS enables a more transparent and interpretable reasoning process, as the model explicitly verbalizes its thought process at each stage. This can be valuable for understanding and diagnosing errors, as well as for improving the overall quality of the generated code. The use of reward model to reinforce correct behavior is key to enable fine-tuning-free improvements in problem-solving.
CURA: Code Agent#
While the exact phrase ‘CURA: Code Agent’ isn’t explicitly present, the paper introduces CURA (Code Understanding and Reasoning Agent) as a novel framework for code generation. CURA leverages a process-supervised reasoning architecture, guided by verbal process supervision (VPS), to improve code generation capabilities. This contrasts with traditional approaches relying solely on final execution results. The key innovation is the integration of VPS, which allows for step-level feedback and iterative refinement during the reasoning process. This focuses on understanding code and guiding through the reasoning.
Iterative Refinement#
Iterative refinement is a powerful paradigm prominently featured in the context. This technique is often employed to improve solutions gradually, addressing identified shortcomings or enhancing initial outputs based on feedback loops. The core idea is to cycle through stages of generating an initial solution, evaluating its quality or correctness, and then using that evaluation to refine the solution. These feedback mechanisms drive progressive improvement, allowing models to overcome limitations in initial generations by incorporating insights derived from execution, testing, or verification steps. This approach particularly beneficial when dealing with complex tasks, where a single pass often falls short of delivering satisfactory results.
Scaling VPS#
The document discusses challenges and opportunities related to scaling Verbal Process Supervision (VPS). While VPS enhances code generation by providing feedback at each reasoning stage, its fine-grained application introduces computational overhead, potentially limiting scalability. Future work should explore methods to balance supervision granularity with efficiency. Hierarchical reward structures or selective intervention strategies could be used to reduce computational costs while retaining VPS benefits. Adaptability across different domains requires exploration, as VPS’s effectiveness in other complex reasoning tasks, such as mathematical theorem proving, needs further investigation. Additionally, the performance of CURA depends on the underlying language model’s capabilities, while VPS helps refine reasoning, it does not fully mitigate the inherent limitations of pre-trained models. Further improvements in aligning VPS signals with human-expert feedback could enhance its effectiveness. Balancing immediate feedback with computational efficiency is a critical area for future research. The trade-offs between immediate and delayed feedback need to be carefully considered to optimize the reasoning process. Improving the balance between structured reasoning and unstructured exploration is another area for improvement to improve model performance in various tasks.
Temp Impacts Code#
While the actual heading is ‘Influence of Temperature Settings,’ the broader concept of ‘Temp Impacts Code’ is insightful. The paper indicates that deterministic decoding (low temperature) generally yields more reliable code outputs. Conversely, higher temperatures introduce randomness, degrading coherence and correctness. It seems structured code benefits from deterministic approaches that maintain stability, while higher temperatures are detrimental. This impacts the trade-offs between reliability and diversity, suggesting that adaptive temperature strategies might optimize the output generation across diverse coding scenarios. The models balance instruction following and coding generation by optimizing temperature. As temperature increases, code becomes more unreliable.
More visual insights#
More on figures

🔼 Figure 2 presents a comparison of the performance of two models on the BigCodeBench (Hard) dataset: the baseline o3-mini model and the o3-mini model enhanced with CURA and Verbal Process Supervision (VPS). The bar chart displays the scores (in percentages) achieved by each model across three evaluation categories: Complete, Instruct, and Average. The y-axis represents the scores, while the x-axis represents the evaluation categories. The results reveal that the o3-mini model with CURA and VPS demonstrates improved performance across all categories compared to the baseline, with the most significant improvement observed in the ‘Complete’ category.
read the caption
Figure 2: Comparison of o3-mini Baseline vs. o3-mini CURA with VPS on the BigCodeBench (Hard) dataset. The y-axis shows the score (in %), while the x-axis shows three different evaluation modes (Complete, Instruct, and the Average of all modes). Notice that o3-mini VPS shows an improvement in all categories, with the largest gain in the “Complete” mode.

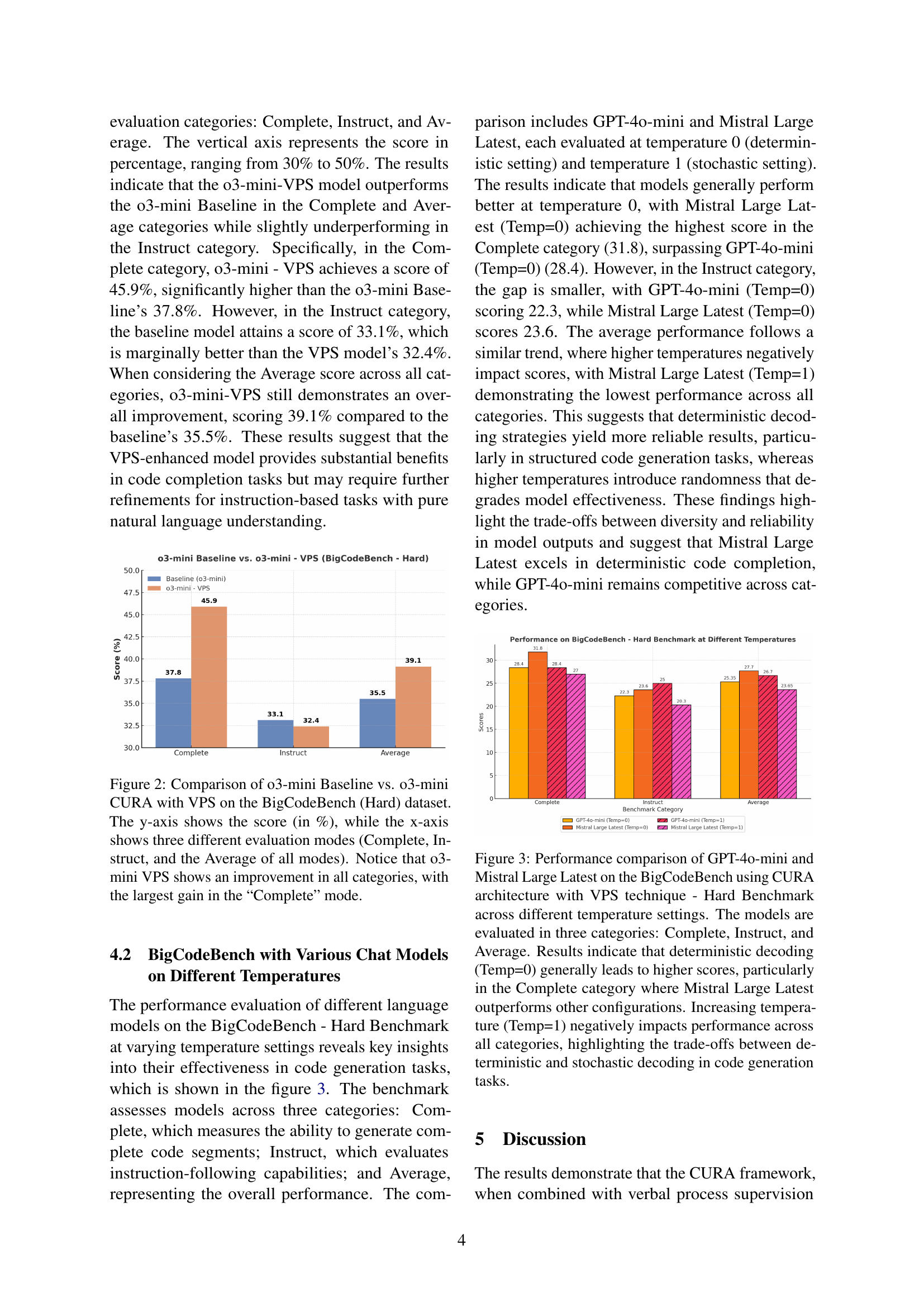
🔼 This figure displays a performance comparison between two large language models (LLMs), GPT-40-mini and Mistral Large Latest, on the BigCodeBench-Hard benchmark. The models were tested using the CURA architecture with Verbal Process Supervision (VPS) at two different temperature settings: 0 (deterministic) and 1 (stochastic). The performance is broken down into three categories: Complete (generating complete code), Instruct (following instructions), and Average (overall performance). The results show that deterministic decoding (Temp=0) generally leads to better scores, particularly in the Complete code generation category, where Mistral Large Latest outperforms GPT-40-mini. Increasing the temperature to 1 introduces more randomness which negatively affects performance across all categories, highlighting a trade-off between deterministic and stochastic code generation methods.
read the caption
Figure 3: Performance comparison of GPT-4o-mini and Mistral Large Latest on the BigCodeBench using CURA architecture with VPS technique - Hard Benchmark across different temperature settings. The models are evaluated in three categories: Complete, Instruct, and Average. Results indicate that deterministic decoding (Temp=0) generally leads to higher scores, particularly in the Complete category where Mistral Large Latest outperforms other configurations. Increasing temperature (Temp=1) negatively impacts performance across all categories, highlighting the trade-offs between deterministic and stochastic decoding in code generation tasks.
Full paper#