TL;DR#
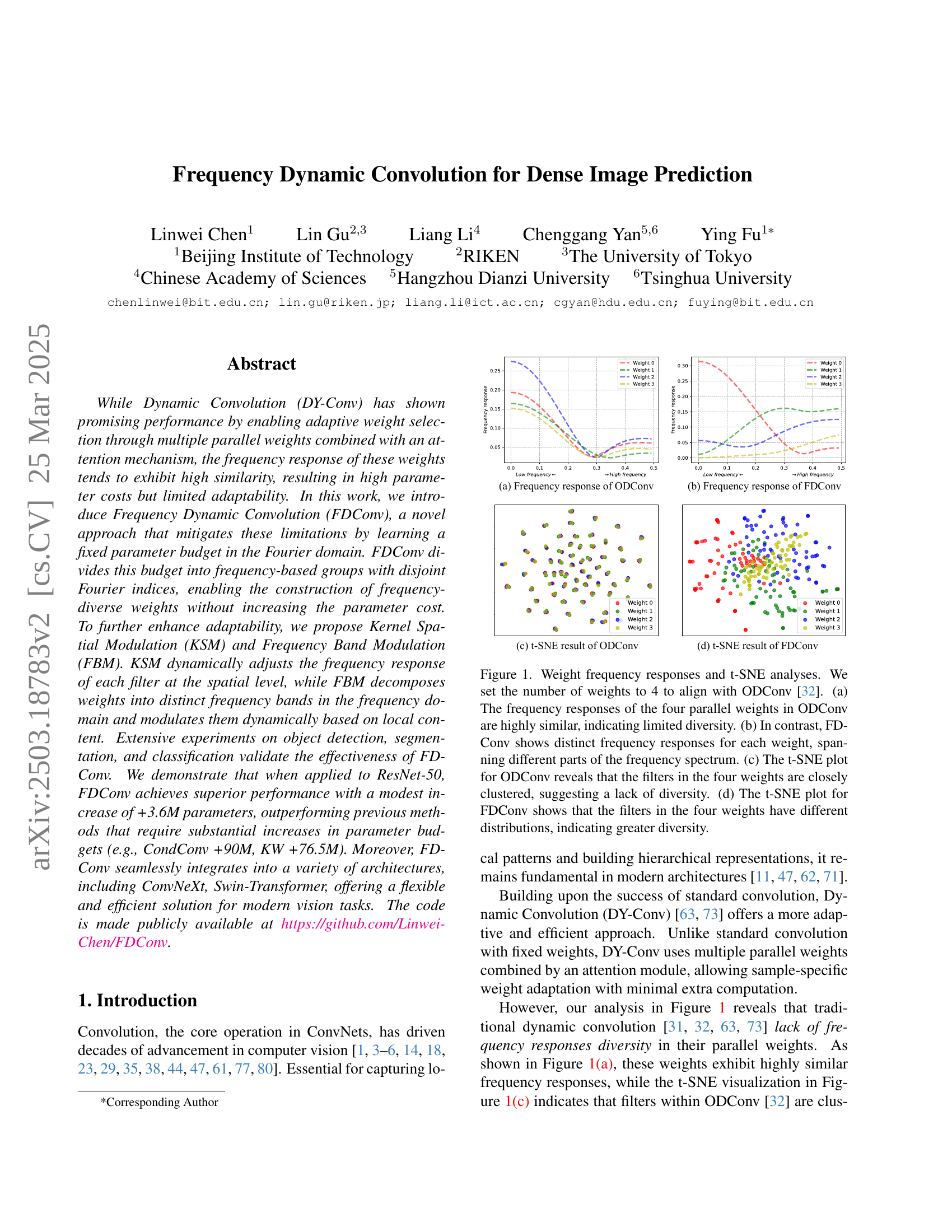
Dynamic Convolution (DY-Conv) enhances adaptive weight selection but suffers from limited adaptability and high parameter costs due to similarity in frequency responses. Existing dynamic convolution lacks the ability to adaptively capture features across different frequency bands. This limitation reduces the flexibility of dynamic convolution.
This paper introduces Frequency Dynamic Convolution (FDConv), learning in the Fourier domain with a fixed parameter budget. It divides this budget into frequency-based groups with disjoint Fourier indices. FDConv constructs multiple weights with diversified frequency responses. It includes Kernel Spatial Modulation (KSM) and Frequency Band Modulation (FBM) to enhance flexibility and improve convolution.
Key Takeaways#
Why does it matter?#
This paper introduces a novel convolution method using frequency analysis which could inspire new network designs. The method achieves SOTA results on various vision tasks. It provides an efficient and versatile solution that researchers could leverage across diverse applications.
Visual Insights#
 |
🔼 Table 1 presents a comparison of the performance of various object detection models on the COCO validation dataset. The models compared include several versions of Dynamic Convolution approaches (CondConv, DY-Conv, DCD, ODConv) and the proposed FDConv model. The table shows the number of parameters (in millions), floating point operations (in billions), and mean Average Precision (AP) scores for both bounding boxes (APbox) and masks (Apmask). For each dynamic convolution method, the table specifies how many times larger its convolutional parameter budget is compared to a standard convolution in the base model (e.g., 4x means four times the parameters). This allows for a direct comparison of efficiency and performance gains of different dynamic convolution techniques against standard convolutions.
read the caption
Table 1: Results comparison on the COCO validation set [42]. The numbers in brackets indicate the parameters of the backbone. Additionally, the notation n×n\timesitalic_n × denotes the convolutional parameter budget of each dynamic convolution relative to the standard convolution in the backbone.
In-depth insights#
Freq. Adaptability#
Frequency adaptability in neural networks refers to the ability of a network to dynamically adjust its sensitivity to different frequency components of the input data. This is crucial because real-world signals often contain information distributed across a wide spectrum of frequencies, and the importance of each frequency band can vary depending on the task. Networks with high frequency adaptability can selectively emphasize or suppress certain frequencies, allowing them to focus on the most relevant information and filter out noise. This can lead to improved performance, especially in tasks involving complex or noisy data. Methods for achieving frequency adaptability often involve learning mechanisms that modulate the network’s response to different frequency bands, such as adaptive filters or attention mechanisms. Such adaptability enhances the network’s robustness and generalization capabilities. It leads to efficient representation learning, as the network can allocate resources to capture the most informative frequency components while ignoring irrelevant ones.
Fourier Weights#
Analyzing “Fourier Weights,” it is evident that this concept likely pertains to manipulating image data in the frequency domain. This suggests leveraging the Fourier transform to decompose images into their constituent frequencies, enabling targeted modifications such as noise reduction via low-frequency filtering or edge enhancement through high-frequency emphasis. A core challenge lies in designing effective weighting schemes that selectively amplify or attenuate specific frequency components without introducing artifacts. The success of “Fourier Weights” hinges on understanding the interplay between spatial and frequency representations, and how manipulating one affects the other. This necessitates careful consideration of windowing functions to mitigate spectral leakage and efficient algorithms for computing the Fourier transform, particularly in the context of large images. Furthermore, adaptive strategies that dynamically adjust weights based on image content could significantly enhance performance.
Spatial Modulate#
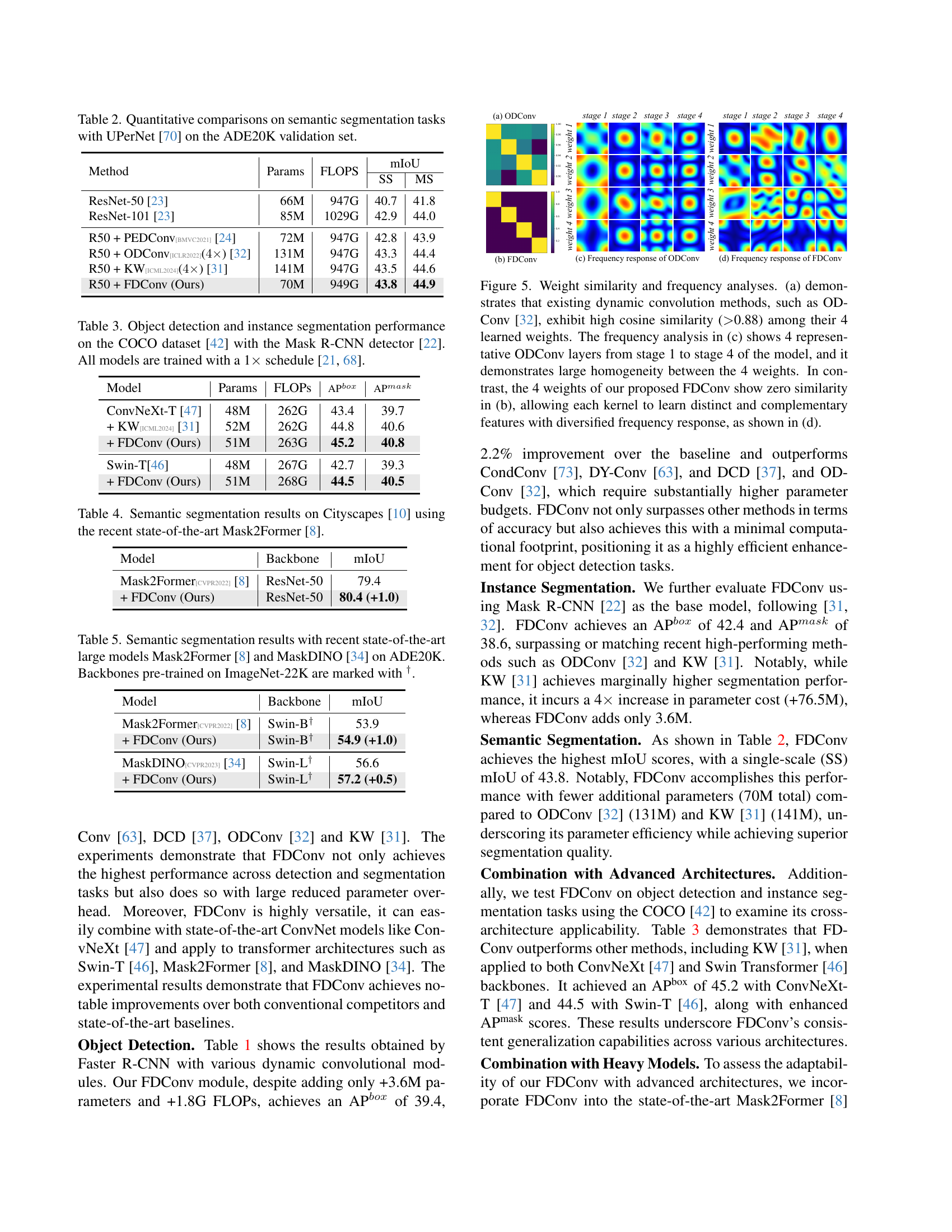
Spatial modulation techniques, particularly Kernel Spatial Modulation (KSM) and Frequency Band Modulation (FBM), represent a shift towards spatially adaptive convolutional operations. KSM enhances flexibility by adjusting the frequency response of each filter at the spatial level, combining local and global channel information to create a dense matrix of modulation values. FBM, on the other hand, decomposes weights into distinct frequency bands, enabling spatially variant frequency modulation. This allows each frequency band to be adjusted independently across spatial locations, deviating from traditional dynamic convolutions with fixed frequency responses. The essence of spatial modulation lies in enabling location-specific adjustments of convolutional filters, leading to more adaptable and context-aware feature extraction. This helps the model in suppressing feature noise while also capturing boundary details to improve the model’s performance.
FBM Analysis#
While there’s no explicit “FBM Analysis” section in the provided paper, we can infer insights based on the Frequency Band Modulation (FBM) discussion. The core idea revolves around adapting convolutional kernels to spatially varying content by decomposing them into frequency bands. The paper visualizes modulation maps, showing how higher frequency bands emphasize object boundaries, while lower frequencies highlight internal object regions. This selective modulation aids in suppressing background noise and enhancing foreground features. Thus, it leads to more precise representations beneficial for dense prediction tasks. The FBM technique effectively bridges the gap between frequency-adaptive weight decomposition and multi-band feature processing, offering implementation flexibility. The approach allows for either weight or feature manipulation based on computational constraints, maintaining mathematical equivalence via Fourier duality.
ConvNet Enhance#
ConvNet Enhancement techniques are pivotal for advancing deep learning in computer vision. These methods aim to improve the performance, efficiency, and robustness of Convolutional Neural Networks (CNNs). Key areas of focus include architectural innovations like residual connections and dense connections, which address the vanishing gradient problem and enable the training of deeper networks. Attention mechanisms, such as Squeeze-and-Excitation networks and transformers, allow CNNs to focus on the most relevant features in an image, enhancing representational power. Another enhancement strategy involves exploring different convolution operations, such as dilated convolutions and deformable convolutions, to better capture spatial relationships and handle variations in object scale and shape. Additionally, network pruning and quantization techniques are employed to reduce the computational cost and memory footprint of CNNs, making them more suitable for deployment on resource-constrained devices. Data augmentation and regularization methods are crucial for preventing overfitting and improving the generalization ability of CNNs. Furthermore, transfer learning and fine-tuning pre-trained CNNs on new datasets can significantly accelerate training and improve performance, especially when dealing with limited data. These various enhancement techniques collectively contribute to the ongoing evolution and widespread adoption of ConvNets in a wide range of computer vision applications.
More visual insights#
More on tables
 |
🔼 Table 2 presents a quantitative comparison of different methods for semantic segmentation on the ADE20K dataset. The comparison focuses on models using the UPerNet architecture [70] and evaluates their performance on the validation set of ADE20K. Metrics reported include the mean Intersection over Union (mIoU) for both single-scale (SS) and multi-scale (MS) predictions, along with the number of model parameters (Params) and floating point operations (FLOPs). This allows for a direct comparison of accuracy and efficiency between different approaches.
read the caption
Table 2: Quantitative comparisons on semantic segmentation tasks with UPerNet [70] on the ADE20K validation set.
 |
🔼 This table presents a comparison of object detection and instance segmentation performance on the COCO dataset using the Mask R-CNN detector. The results showcase the performance of several models, including a baseline ConvNeXt-T model and variants incorporating the proposed FDConv module. The models are trained using a standard 1x schedule for fair comparison, and the table lists the number of parameters, FLOPS (floating-point operations per second), APbox (average precision for bounding boxes), and Apmask (average precision for masks) for each model. The data provides insights into the efficiency and accuracy gains achieved by integrating FDConv into various architectures.
read the caption
Table 3: Object detection and instance segmentation performance on the COCO dataset [42] with the Mask R-CNN detector [22]. All models are trained with a 1×\times× schedule [21, 68].
 |
🔼 This table presents a comparison of semantic segmentation performance on the Cityscapes dataset [10] using the Mask2Former model [8]. It shows the mIoU (mean Intersection over Union) scores achieved by the Mask2Former model with a ResNet-50 backbone and the same model enhanced with the proposed FDConv method. The table highlights the improvement in mIoU resulting from the addition of FDConv.
read the caption
Table 4: Semantic segmentation results on Cityscapes [10] using the recent state-of-the-art Mask2Former [8].
| Models | Params | FLOPs | APbox | APmask |
| Faster R-CNN | 43.80(23.5)M | 207.1G | 37.2 | |
| + CondConv[NIPS2019] (8) [73] | +90.0M | +0.01G | 38.1 | - |
| + DY-Conv[ICLR2022] (4) [63] | +75.3M | +0.16G | 38.3 | - |
| + DCD[ICLR2021] [37] | +4.3M | +0.13G | 38.1 | |
| + ODConv[ICLR2022] (4) [32] | +65.1M | +0.35G | 39.2 | - |
| + FDConv (Ours) | +3.6M | +1.8G | 39.4 | |
| Mask R-CNN | 46.5(23.5)M | 260.1 | 39.6 | 36.4 |
| + DY-Conv[CVPR2020] (4) [63] | +75.3M | +0.16G | 39.6 | 36.6 |
| + ODConv[ICLR2022] (4) [32] | +65.1M | +0.35G | 42.1 | 38.6 |
| + KW[ICML2024] (1) [31] | +2.5M | - | 41.8 | 38.4 |
| + KW[ICML2024] (4) [31] | +76.5M | - | 42.4 | 38.9 |
| + FDConv (Ours) | +3.6M | +1.8G | 42.4 | 38.6 |
🔼 Table 5 presents the results of semantic segmentation experiments using two state-of-the-art large models, Mask2Former and MaskDINO, on the ADE20K dataset. The table shows the mean Intersection over Union (mIoU) achieved by each model on the ADE20K validation set. Results are shown for both models using Swin-B and Swin-L backbones. The Swin-L backbones were pre-trained on the larger ImageNet-22K dataset, which is indicated by a † symbol. The table highlights the performance improvement obtained by adding the proposed FDConv module to each model and backbone combination.
read the caption
Table 5: Semantic segmentation results with recent state-of-the-art large models Mask2Former [8] and MaskDINO [34] on ADE20K. Backbones pre-trained on ImageNet-22K are marked with †.
Full paper#