TL;DR#
Large Language Models (LLMs) have shown great success, but their reasoning remains unexplored. This study uses Sparse Autoencoders (SAEs) to understand reasoning features in DeepSeek-R1 models. The method identifies features driving reasoning by learning sparse decompositions of latent representations. It introduces a way to extract candidate “reasoning features” from SAE, validated via analysis and interpretability methods, showing a direct link to reasoning. (499 char.)
The study introduces ReasonScore, an evaluation metric for detecting reasoning features from the SAE representations. Features are validated through interpretability and causal interventions, enhancing reasoning by steering these features, showcasing their impact. Systematic feature steering improves reasoning performance, marking the first mechanistic account of reasoning in LLMs. (488 char.)
Key Takeaways#
Why does it matter?#
This paper pioneers a mechanistic understanding of reasoning in LLMs by causally linking interpretable components to complex cognitive behaviors, potentially revolutionizing how we design and control AI reasoning.
Visual Insights#

🔼 This figure shows the impact of manipulating reasoning-related features within a large language model (LLM) during text generation. The control group (blue) demonstrates the model’s natural reasoning process, which may be less detailed or lack self-correction. In contrast, the experimental group (green) shows the effect of ‘steering’ or amplifying the identified reasoning features. Steering produces a more thorough reasoning process with evidence of self-correction and a more natural progression towards the final answer. This supports the claim that the identified features are directly responsible for the model’s reasoning capabilities.
read the caption
Figure 1: Illustration of steering (amplifying) reasoning-specific features during LLM generation. Default generation (blue) shows standard model reasoning, whereas steering (green) induces increased reasoning, self-correction, and graceful transition to the final answer—evidence that the identified features are responsible for the reasoning concept.
| Feature index | AIME 2024 | MATH-500 | GPQA | |||
|---|---|---|---|---|---|---|
| Diamond | ||||||
| pass@1 | # tokens | pass@1 | # tokens | pass@1 | # tokens | |
| No steering | 46.6 | 12.0k | 91.0 | 3.7k | 54.0 | 7.9k |
| 15136 | 60.0 | 13.8k | 89.6 | 4.3k | 50.5 | 8.9k |
| 17456 | 50.0 | 14.2k | 93.0 | 4.2k | 53.0 | 8.7k |
| 46379 | 53.3 | 15.5k | 92.4 | 4.4k | 55.5 | 9.0k |
| 62777 | 56.6 | 12.9k | 93.0 | 4.1k | 48.5 | 8.3k |
🔼 This table presents the performance of the DeepSeek-R1-Llama-8B large language model on three reasoning-related benchmarks: AIME-2024, MATH-500, and GPQA Diamond. The model’s performance is evaluated with and without ‘steering’—a technique that systematically modifies specific features identified as being related to reasoning within the model’s internal representation. The results show the model’s pass@1 accuracy (percentage of correctly answered problems) and the average number of output tokens generated in each experimental condition for different feature indices. This allows for an assessment of the impact of steering on both the quality and the length of model responses.
read the caption
Table 1: Performance and average number of output tokens for different steering experiments on reasoning-related benchmarks.
In-depth insights#
Reasoning’s SAEs#
Reasoning in LLMs through Sparse Autoencoders (SAEs) is a promising area for mechanistic interpretability. SAEs can disentangle complex activations into sparse, interpretable features, potentially revealing how LLMs encode reasoning steps like deduction, reflection, or uncertainty handling. The core idea is that reasoning isn’t a monolithic process but arises from interactions of simpler, disentangled features. ReasonScore helps to automatically identify SAE features relevant to reasoning, guiding the analysis and causal interventions. By steering these features, researchers can directly manipulate model behavior, strengthening or weakening reasoning abilities to confirm their causal role. Moreover, auto-interpretability and empirical evidence support the link. Overall, the SAE lens offers a unique way to dissect and understand the inner workings of reasoning in LLMs, moving beyond black-box observations towards a more mechanistic understanding of their capabilities. By revealing the features that drive reasoning, it may point towards directions for better control and enhancement of these abilities.
ReasonScore Metric#
The paper introduces ReasonScore, a novel metric designed to quantify the reasoning relevance of individual features learned by Sparse Autoencoders (SAEs) within Large Language Models (LLMs). This metric is crucial for identifying which features are most responsible for the model’s reasoning capabilities, such as reflection, uncertainty handling, and structured problem-solving. ReasonScore computes a score for each feature based on its activation patterns across a curated set of introspective vocabulary, penalizing features that activate uniformly across all reasoning tokens. The development of ReasonScore addresses a significant gap in understanding how reasoning is encoded within LLMs, offering a principled approach to disentangle activations and identify features causally linked to complex cognitive behaviors, marking a move toward interpretable AI.
Feature Steering#
Feature steering appears as a pivotal method to modulate LLM behavior. By systematically tweaking specific feature activations, researchers aim to discern the influence of these features on LLM outputs. This approach contrasts with holistic methods, as it allows targeted adjustments and measurement. The study analyzes how modulating the ‘reasoning’ features influences text coherence, logic, and argumentation, providing insights into internal mechanisms. Moreover, feature steering provides a way to manipulate the model’s cognitive processes. Amplifying certain features leads to improved step-by-step reasoning and self-correction, while suppressing features causes fragmented logic. This demonstrates the causal relationship of features and reasoning behaviors. This method offers a nuanced way to understand LLM reasoning.
Modulating Thought#
While the provided paper doesn’t explicitly have a section titled “Modulating Thought,” the research explores mechanisms that effectively modulate the reasoning processes within Large Language Models (LLMs). Feature steering, a key technique discussed, directly influences the model’s cognitive processes. Steering allows for amplifying or suppressing specific reasoning-related features, impacting text coherence and logical consistency. This highlights the potential for granular control over how LLMs approach problem-solving. The paper also investigates how the activations of identified reasoning features can be systematically altered to observe their causal impact on various reasoning benchmarks. This modulation through feature steering demonstrates that LLMs’ reasoning capabilities are not monolithic but can be shaped and guided by manipulating internal representations. Furthermore, the observed changes in the number of output tokens and the overall reasoning accuracy suggest that modulation affects the depth and thoroughness of the model’s thought process. This implies that by carefully selecting and modulating relevant features, it is possible to enhance desired reasoning characteristics, or even reduce unwanted ones.
Cognitive LLMs#
While the paper doesn’t explicitly use the heading “Cognitive LLMs,” the entire work orbits this concept. The core idea revolves around dissecting the reasoning mechanisms within LLMs, particularly DeepSeek-R1. This directly relates to the ‘cognitive’ aspect, as reasoning is a key component of cognition. The authors delve into how LLMs encode and execute processes mimicking human-like thought, such as reflection, uncertainty handling, and exploration. The application of Sparse Autoencoders (SAEs) is a method to ‘open the black box’ and identify specific features associated with these cognitive processes. The ReasonScore metric further quantifies the relevance of SAE features to reasoning. The experiments involving steering also demonstrate a causal link between these features and the model’s ability to solve complex problems. Ultimately, the study contributes to understanding the internal representations of knowledge and reasoning within LLMs, thus shedding light on their cognitive capabilities. The aim of this research is not to just improve performance, but to understand how these improvements are achieved. It would be interesting to see future work expanding upon the types of cognitive behaviors studied, as well as using their framework to compare and contrast various models of LLMs.
More visual insights#
More on figures

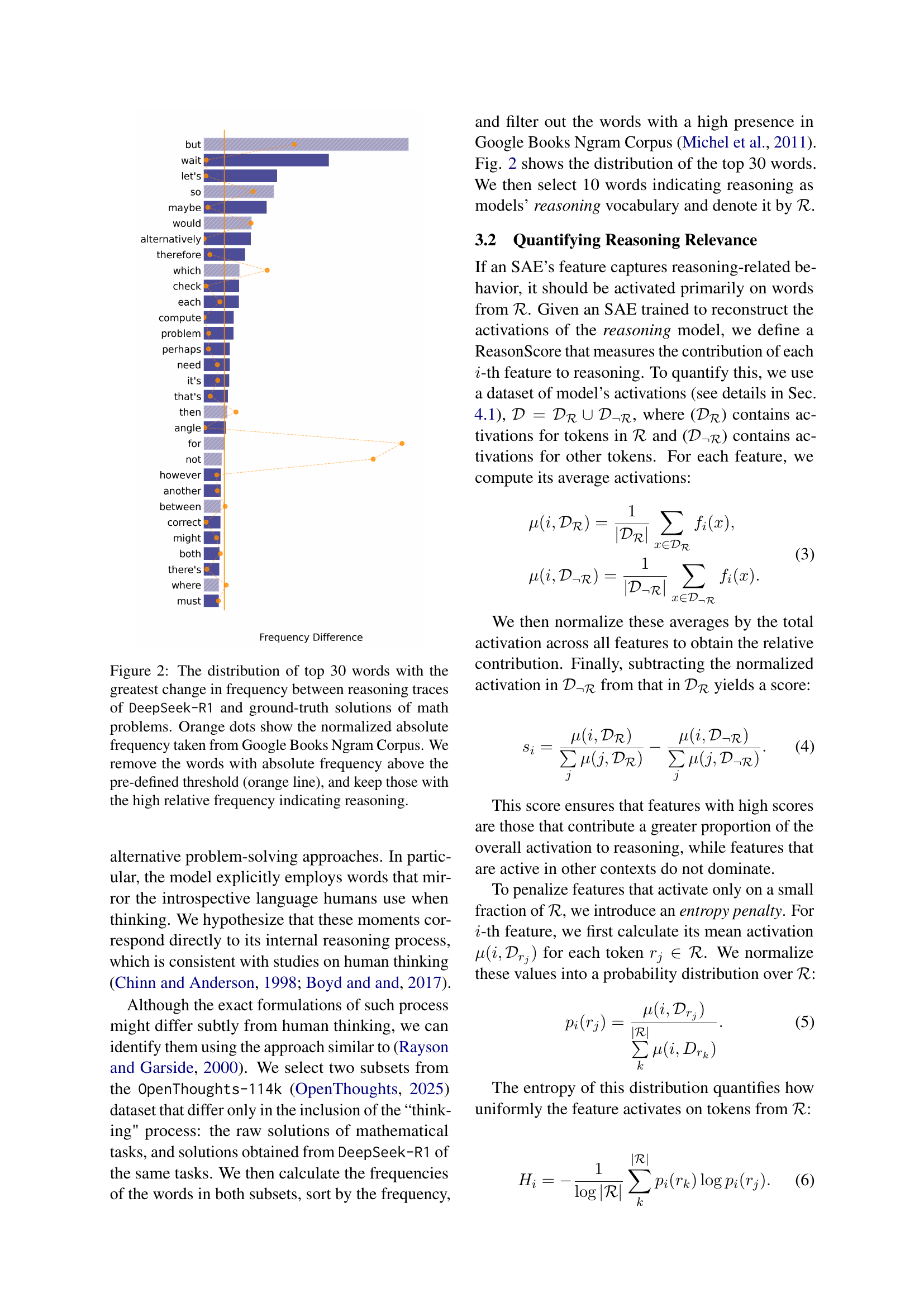
🔼 This figure shows the 30 words that most significantly changed in frequency between the reasoning traces generated by the DeepSeek-R1 model and the ground truth solutions for mathematical problems. The x-axis represents the difference in frequency between the model’s reasoning and the ground truth. Words to the right have a higher frequency in the model’s reasoning, suggesting their importance in the model’s reasoning process. The y-axis shows the words ranked by this frequency difference. The size of the orange dots indicates the normalized absolute frequency of each word in the Google Books Ngram Corpus. Words with a frequency above a certain threshold (represented by the orange line) were excluded, focusing on words with high relative frequency in the model’s reasoning output that are less common in general text.
read the caption
Figure 2: The distribution of top 30 words with the greatest change in frequency between reasoning traces of DeepSeek-R1 and ground-truth solutions of math problems. Orange dots show the normalized absolute frequency taken from Google Books Ngram Corpus. We remove the words with absolute frequency above the pre-defined threshold (orange line), and keep those with the high relative frequency indicating reasoning.

🔼 This figure shows the impact of a specific reasoning feature (identified using Sparse Autoencoders) on the model’s output logits. Panel (a) presents the top 10 negative and top 10 positive logits most strongly influenced by this feature. This highlights the feature’s effect on the model’s prediction probabilities for various tokens. Panel (b) displays the 20 contexts (inputs) where this feature exhibits the highest activation values. These contexts illustrate the types of situations or linguistic patterns that trigger the activation of this reasoning feature. The figure thus provides a detailed analysis of a single reasoning feature’s effects on model predictions and the conditions under which it becomes most active.
read the caption
(a) Top 10101010 negative and positive output logits of the feature

🔼 This figure visualizes the top 20 examples where a specific reasoning feature in a Sparse Autoencoder (SAE) model shows the highest activation. It demonstrates the contexts and phrases within the model’s activations that strongly correlate with the feature’s identification of reasoning processes like reflection, uncertainty, and exploration. Each example shows the input text where the feature is most active.
read the caption
(b) Top 20202020 max activating examples

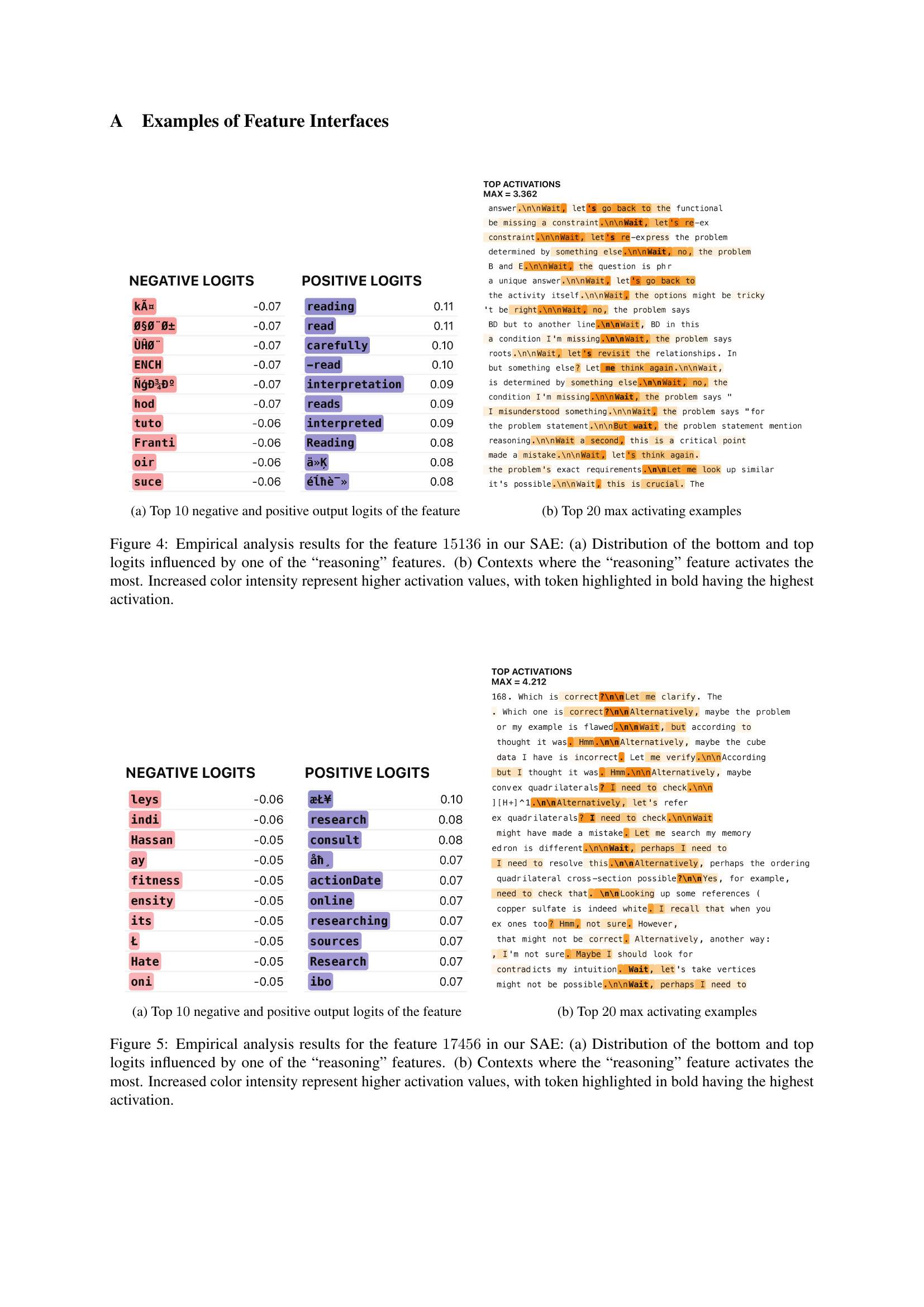
🔼 Figure 3 presents a detailed analysis of a specific reasoning feature (feature 17456) identified using Sparse Autoencoders (SAEs). Panel (a) displays the distribution of the lowest and highest logit values associated with this feature. Logits are scores assigned to tokens during language model prediction; higher values represent increased probability. This distribution shows which tokens are most affected by this feature. Panel (b) showcases various contexts in which feature 17456 demonstrates the highest activation level, providing illustrative examples of how this feature influences the model’s reasoning process. The color intensity in both panels correlates directly with the magnitude of activation values, enhancing the visualization of feature influence. Tokens appearing in bold represent the most significant activations within each context.
read the caption
Figure 3: Empirical analysis results for the feature 17456174561745617456 in our SAE: (a) Distribution of the bottom and top logits influenced by one of the “reasoning” features. (b) Contexts where the “reasoning” feature activates the most. Increased color intensity represent higher activation values, with token highlighted in bold having the highest activation.

🔼 This figure presents a detailed analysis of a specific feature (feature number 17456) within a Sparse Autoencoder (SAE). Panel (a) shows the top 10 most negative and top 10 most positive output logits influenced by this feature. Logits represent the model’s confidence in predicting specific tokens, with higher values indicating stronger confidence. This helps to understand the feature’s effect on the model’s output. Panel (b) displays the 20 contexts (input text snippets) where the feature exhibited the highest activation levels. These contexts provide insights into the specific situations that activate this particular feature, thus clarifying its function and semantics within the model’s reasoning process.
read the caption
(a) Top 10101010 negative and positive output logits of the feature

🔼 This figure visualizes the contexts where a specific reasoning feature in a Sparse Autoencoder (SAE) model exhibits the highest activation. The figure shows 20 examples of text segments from the model’s activations where this feature is most strongly activated, providing insights into the types of reasoning tasks or linguistic patterns that trigger this feature. This helps in understanding the feature’s role in the model’s overall reasoning process.
read the caption
(b) Top 20202020 max activating examples

🔼 Figure 4 presents a detailed analysis of a specific reasoning feature (feature 15136) identified using Sparse Autoencoders (SAEs) within a Large Language Model (LLM). Part (a) shows the distribution of the lowest and highest logit values (representing the model’s confidence in predictions) influenced by this feature. Part (b) illustrates the contexts within the LLM’s activations where this reasoning feature exhibits its strongest activation. The visualization uses color intensity to represent the magnitude of feature activation, highlighting tokens with the highest activation in bold.
read the caption
Figure 4: Empirical analysis results for the feature 15136151361513615136 in our SAE: (a) Distribution of the bottom and top logits influenced by one of the “reasoning” features. (b) Contexts where the “reasoning” feature activates the most. Increased color intensity represent higher activation values, with token highlighted in bold having the highest activation.

🔼 This figure shows the top 10 negative and positive output logits for a specific feature (identified using Sparse Autoencoders) in a large language model (LLM). The figure helps to illustrate the impact of this feature on the LLM’s output. Negative logits represent tokens that are less likely to be generated when the feature is active, while positive logits show tokens whose generation probability increases when the feature is active. This allows for analysis of how the activation of a single learned feature influences the LLM’s word choices.
read the caption
(a) Top 10101010 negative and positive output logits of the feature

🔼 This figure shows the top 20 examples where a specific reasoning feature in the Sparse Autoencoder (SAE) model exhibits its highest activation. It complements Figure 3a, which shows the distribution of activations. The contexts illustrated here provide insights into what kinds of situations or linguistic patterns trigger the activation of this particular reasoning feature, highlighting its role in the model’s reasoning process. Each example includes the model’s generated text showing the use of words and phrases related to reasoning and thought processes.
read the caption
(b) Top 20202020 max activating examples

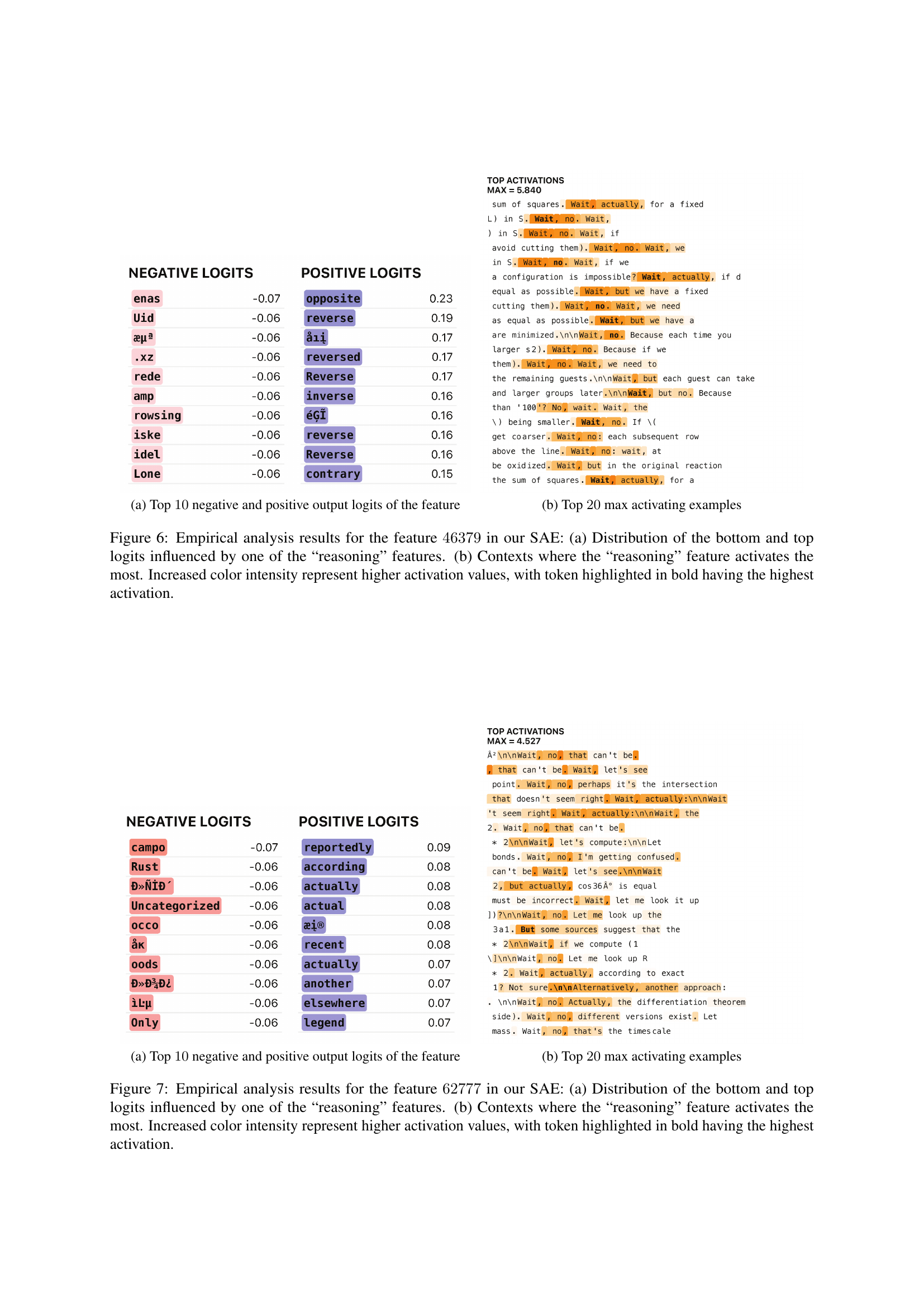
🔼 Figure 5 presents a detailed empirical analysis of a specific reasoning feature (feature ID: 17456) identified using Sparse Autoencoders (SAEs). Part (a) shows the distribution of low-activation (negative logits) and high-activation (positive logits) tokens influenced by this feature. This visualization helps understand the feature’s impact on the model’s output. Part (b) displays various contexts (text examples) where this feature exhibits the strongest activation, providing insights into the situations that trigger the feature. The use of color intensity further enhances the visualization by representing activation strength, with the boldest tokens carrying the highest activation levels. This detailed analysis provides evidence of how the identified feature contributes to the model’s reasoning capabilities.
read the caption
Figure 5: Empirical analysis results for the feature 17456174561745617456 in our SAE: (a) Distribution of the bottom and top logits influenced by one of the “reasoning” features. (b) Contexts where the “reasoning” feature activates the most. Increased color intensity represent higher activation values, with token highlighted in bold having the highest activation.
More on tables
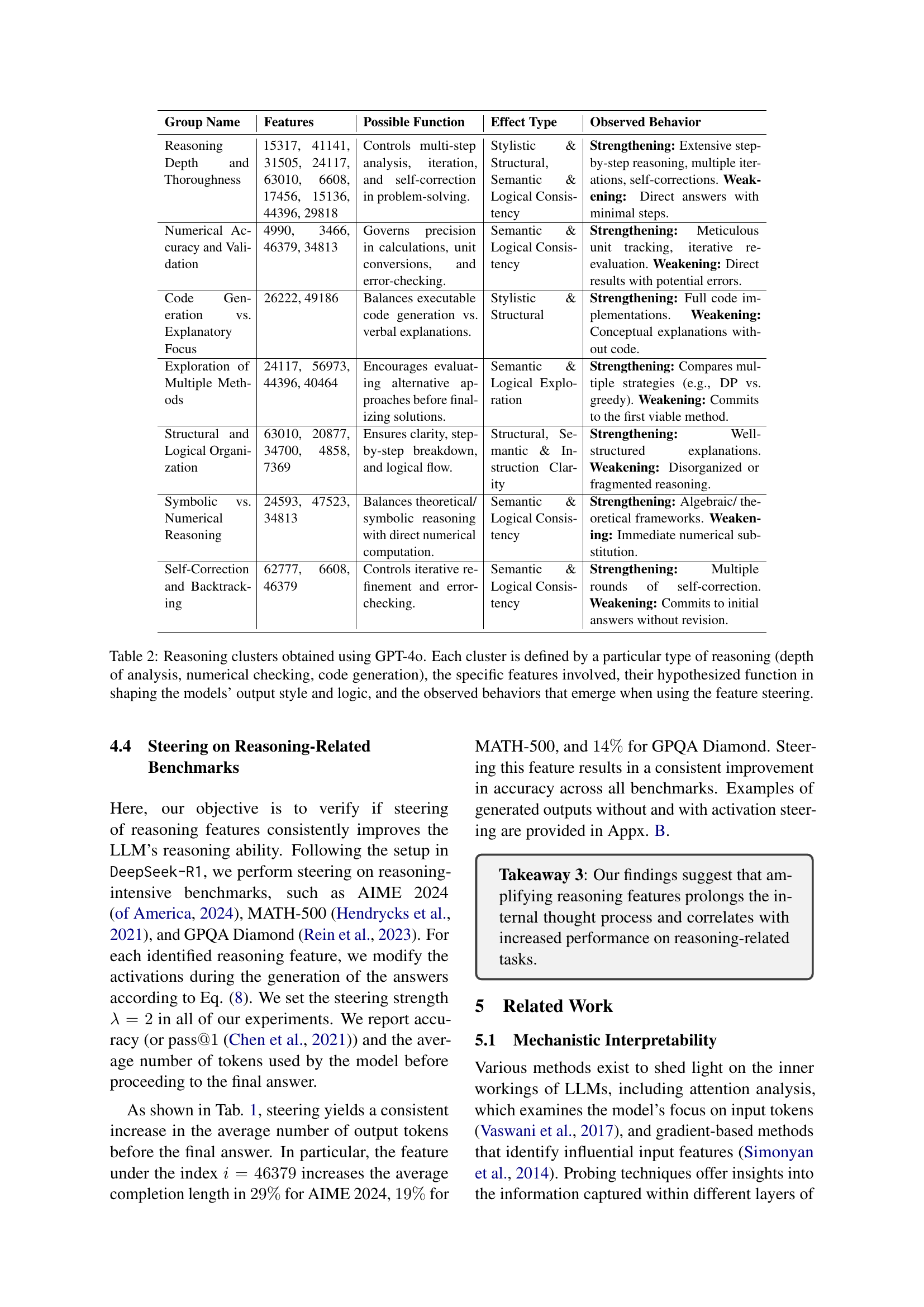
| Group Name | Features | Possible Function | Effect Type | Observed Behavior |
| Reasoning Depth and Thoroughness | 15317, 41141, 31505, 24117, 63010, 6608, 17456, 15136, 44396, 29818 | Controls multi-step analysis, iteration, and self-correction in problem-solving. | Stylistic & Structural, Semantic & Logical Consistency | Strengthening: Extensive step-by-step reasoning, multiple iterations, self-corrections. Weakening: Direct answers with minimal steps. |
| Numerical Accuracy and Validation | 4990, 3466, 46379, 34813 | Governs precision in calculations, unit conversions, and error-checking. | Semantic & Logical Consistency | Strengthening: Meticulous unit tracking, iterative re-evaluation. Weakening: Direct results with potential errors. |
| Code Generation vs. Explanatory Focus | 26222, 49186 | Balances executable code generation vs. verbal explanations. | Stylistic & Structural | Strengthening: Full code implementations. Weakening: Conceptual explanations without code. |
| Exploration of Multiple Methods | 24117, 56973, 44396, 40464 | Encourages evaluating alternative approaches before finalizing solutions. | Semantic & Logical Exploration | Strengthening: Compares multiple strategies (e.g., DP vs. greedy). Weakening: Commits to the first viable method. |
| Structural and Logical Organization | 63010, 20877, 34700, 4858, 7369 | Ensures clarity, step-by-step breakdown, and logical flow. | Structural, Semantic & Instruction Clarity | Strengthening: Well-structured explanations. Weakening: Disorganized or fragmented reasoning. |
| Symbolic vs. Numerical Reasoning | 24593, 47523, 34813 | Balances theoretical/ symbolic reasoning with direct numerical computation. | Semantic & Logical Consistency | Strengthening: Algebraic/ theoretical frameworks. Weakening: Immediate numerical substitution. |
| Self-Correction and Backtracking | 62777, 6608, 46379 | Controls iterative refinement and error-checking. | Semantic & Logical Consistency | Strengthening: Multiple rounds of self-correction. Weakening: Commits to initial answers without revision. |
🔼 Table 2 presents a detailed analysis of reasoning features identified using GPT-4. It categorizes features into clusters based on the type of reasoning they appear to influence (e.g., depth of analysis, numerical accuracy, code generation). For each cluster, the table lists the specific features involved, a description of their hypothesized role in shaping the model’s reasoning process, and the observed changes in model behavior (e.g., increased or decreased reasoning depth, logical consistency) when these features are manipulated during text generation via ‘feature steering’.
read the caption
Table 2: Reasoning clusters obtained using GPT-4o. Each cluster is defined by a particular type of reasoning (depth of analysis, numerical checking, code generation), the specific features involved, their hypothesized function in shaping the models’ output style and logic, and the observed behaviors that emerge when using the feature steering.
| Feature Number | Observed Behavior |
|---|---|
| 15136 | Affects: Reasoning Depth and Thoroughness, Self-Correction Weakening (-4.0): "To solve the problem, apply dynamic programming using a DP table where dp[i][j] stores the maximum coins collected up to (i,j). Compute dp[N][N] and return it if >= C, else return -1." (Short, direct response with no reasoning) Strengthening (4.0): "Okay, let me carefully analyze the problem. The participant starts at (1,1) and must reach (N,N). Each move is either right or down. To ensure an optimal path, we must track accumulated coins at each step. The best approach appears to be dynamic programming. Let’s define dp[i][j] as the maximum coins collected at (i,j). But wait—what if we consider another approach? Perhaps a graph-based shortest path algorithm? No, because the constraint is maximizing coins, so DP makes sense. Now, let’s check boundary conditions…" (Extensive, iterative reasoning with multiple reconsiderations before formulating the solution) |
| 17456 | Affects: Reasoning Depth and Thoroughness, Self-Correction Weakening (-4.0): "Use DP to compute the max coins. Return dp[N][N]." (Direct, without intermediate considerations) Strengthening (4.0): "Let’s carefully check all possible paths. We start by defining dp[i][j] to store max coins up to (i,j). However, we should verify if a greedy approach works. Let’s compare outputs from both strategies before concluding…" (Persistent, multi-step reasoning) |
| 46379 | Affects: Numerical Accuracy and Validation Weakening (-4.0): "Apply standard DP with dp[i][j] transition. Compute final result." (Straightforward, minimal reasoning) Strengthening (4.0): "Before solving, let’s analyze constraints. The participant moves through a grid and must maximize coins. Should we use a DP approach or consider a graph-based traversal? Let’s derive the recurrence relation first…" (Detailed breakdown of reasoning) |
| 62777 | Affects: Self-Correction and Backtracking Weakening (-4.0 to -2.5): "We assume the input is valid and proceed with computation." Strengthening (+2.5 to +4.0): "We must ensure that when n=2, the grid still allows a valid path." |
🔼 This table presents a detailed analysis of how manipulating specific features identified by the ReasonScore impacts the LLM’s reasoning process. For each selected feature, it shows the observed effects of both strengthening (positive steering) and weakening (negative steering) its activation. The observed changes are categorized into four key aspects of reasoning: depth, thoroughness, self-correction, and numerical accuracy. By examining contrasting responses under different steering conditions, the table demonstrates how these features causally influence various facets of the model’s reasoning behavior.
read the caption
Table 3: Observed effects of specific feature steering on the model reasoning behavior. Each feature is associated with changes in reasoning depth, thoroughness, self-correction, and numerical accuracy, as demonstrated by contrasting responses with negative and positive steering strengths.
Full paper#