TL;DR#
Classifier-Free Guidance (CFG) is a widely used technique in diffusion and flow models to enhance image quality and controllability. However, it has limitations in flow matching models, especially during early training stages when flow estimation is inaccurate. In such cases, CFG can lead samples toward incorrect trajectories, affecting the quality of generated images. The paper hypothesizes that the mismatch arises from dataset limitations and learning limitations.
To address these issues, the paper introduces CFG-Zero*, which includes (a) an optimized scale, where a scalar is optimized to correct for inaccuracies in the estimated velocity; and (b) zero-init, which involves zeroing out the first few steps of the ODE solver. Through experiments in text-to-image and video generation, CFG-Zero* is proven to outperform CFG. The study also provides insights into error sources in flow-matching models.
Key Takeaways#
Why does it matter?#
This paper is important for researchers because it improves flow matching models which are now becoming more common in text-to-image generation. By providing a more effective and stable guidance method, this research can push the boundaries of generative modeling and its applications, also providing a clearer picture of the issues with current methods.
Visual Insights#

🔼 Figure 1 shows a comparison of images generated from the text prompt: ‘A dense winter forest with snow-covered branches, the golden light of dawn filtering through the trees, and a lone fox leaving delicate paw prints in the fresh snow.’ The comparison highlights the difference in image quality and detail between using the standard Classifier-Free Guidance (CFG) method and the improved CFG-Zero* method proposed in the paper. The images were generated using Stable Diffusion 3.5 (SD3.5). The CFG-Zero* method demonstrates improved image fidelity and adherence to the prompt’s description.
read the caption
Figure 1: Comparison for the prompt: “A dense winter forest with snow-covered branches, the golden light of dawn filtering through the trees, and a lone fox leaving delicate paw prints in the fresh snow.” Images generated using SD3.5 [5] with CFG and CFG-Zero⋆ (Ours).
 |  |
| (a) | (b) |
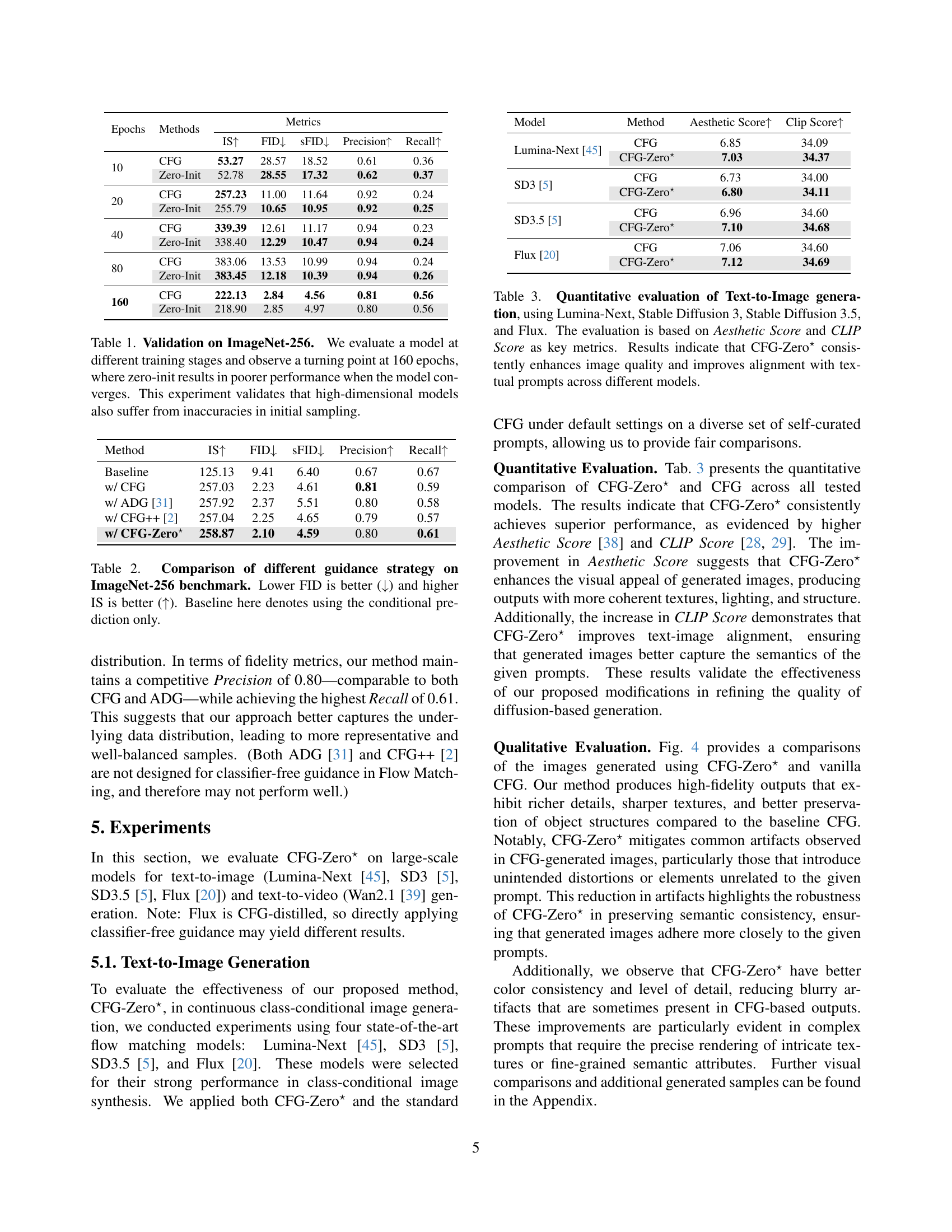
🔼 This table presents the results of an experiment evaluating the impact of the proposed CFG-Zero* method on the ImageNet-256 dataset. The experiment uses a class-conditional flow model and measures the model’s performance at various training epochs using metrics such as Inception Score (IS), Fréchet Inception Distance (FID), and others. It reveals a ’turning point’ at 160 epochs, where the benefits of the zero-initialization technique diminish as the model’s training progresses and improves. The study’s finding suggests that the limitations of the initial sampling process are persistent, particularly in high-dimensional models, emphasizing the need for CFG-Zero* particularly in early phases of training.
read the caption
Table 1: Validation on ImageNet-256. We evaluate a model at different training stages and observe a turning point at 160 epochs, where zero-init results in poorer performance when the model converges. This experiment validates that high-dimensional models also suffer from inaccuracies in initial sampling.
In-depth insights#
CFG Error Source#
Considering ‘CFG Error Source,’ a likely issue stems from inaccuracies when velocity is underfitted. CFG relies on conditional/unconditional prediction differences; if the learned velocity poorly captures data distribution, CFG can misguide samples. Early training stages are particularly vulnerable, with initial velocity estimates causing deviations from optimal trajectories. Dataset limitations or learning inadequacies contribute. Mismatch between user text prompt interpretation and the dataset, alongside imperfect learning, exacerbate this. Effectively, CFG amplifies initial errors, steering generation awry. Improved techniques must address these sources of error to enhance guidance.
Optimized Scaling#
Optimized scaling is a crucial aspect of enhancing the performance of models, particularly in scenarios where the learned velocity may be underfitted or inaccurate. By introducing a learnable scalar parameter, the model can dynamically adjust the influence of the unconditional and conditional predictions, allowing for a more precise approximation of the ground-truth flow. This approach aims to mitigate the mismatch between the intended conditional distribution and the learned conditional velocity, which can arise due to dataset limitations or learning constraints. Optimizing this scale involves minimizing the discrepancy between the guided velocity field and the ideal flow. By projecting the conditional velocity onto the unconditional velocity, the optimized scale can effectively correct for inaccuracies in the estimated velocity, leading to improved sample quality and more accurate guidance during the generation process.
Zero-Init Improves#
The ‘Zero-Init Improves’ concept suggests a novel way to refine generative models, specifically in flow matching. It likely involves initializing a portion of the generative process, perhaps the initial steps of ODE solvers, with zero values. This could act as a regularization technique, preventing early, inaccurate velocity estimations from steering the generation process down incorrect paths. By effectively skipping the problematic initial phase, the model can avoid accumulating errors arising from an underfitted state. Zero-init might be particularly beneficial in the early stages of training, where velocity predictions are less reliable, promoting stability. Later stages may see diminishing benefits as model accuracy increases, suggesting an adaptive application of zero-init.
Quality & Alignment#
In generative models, quality pertains to the visual fidelity and coherence of generated outputs. High-quality images exhibit sharp details, realistic textures, and structural integrity, minimizing artifacts and distortions. Alignment, on the other hand, refers to the consistency between the generated output and the intended semantics, especially in conditional generation tasks like text-to-image synthesis. Strong alignment means that the generated image accurately reflects the input text prompt, capturing its key elements and relationships. Achieving both high quality and strong alignment is crucial for the practical utility of generative models, ensuring outputs are not only visually pleasing but also semantically meaningful. Methods like classifier-free guidance (CFG) aim to improve this balance, but can introduce artifacts if not carefully tuned. The need for balancing is especially important for Flow Matching methods.
CFG-Zero* Works#
While the document doesn’t explicitly have a section titled “CFG-Zero* Works,” the core innovation revolves around enhancing Classifier-Free Guidance (CFG) for flow-matching models. The research tackles the issue of inaccurate velocity estimation during the early stages of training. The success stems from two key contributions: (1) optimized scale, dynamically adjusting the unconditional output to compensate for inaccuracies, acting like a learned correction, and (2) zero-init, strategically zeroing out the initial steps of the ODE solver, effectively bypassing flawed early velocity predictions. The study uses analysis of gaussian mixtures for data distribution and establishes how the traditional CFG is not optimal. This insight led to the development of a CFG-Zero*. The resulting approach shows how high-fidelity outputs are generated using CFG-Zero*.
More visual insights#
More on figures

🔼 This figure compares the results of image generation with and without classifier-free guidance (CFG). The prompt used was: “A mysterious underwater city with bioluminescent corals and towering glass domes.” The image on the left shows a sample generated using standard conditional generation, lacking the detail and coherence found in the image on the right, which is generated using CFG. CFG helps align the generated image more closely with the user’s specified prompt by guiding the sampling process towards a more appropriate output based on the user’s condition. The difference showcases CFG’s effectiveness in enhancing image quality and aligning generated images with given text prompts.
read the caption
Figure 2: (Left) Conditional generation. (Right) CFG generation. (Prompt: “A mysterious underwater city with bioluminescent corals and towering glass domes.”)

🔼 Figure 3 presents a comparative analysis of the performance of a flow matching model trained on a 2D Gaussian mixture. The left panel displays the Jensen-Shannon (JS) divergence between the model’s generated sample distribution and the true target distribution over training epochs. This metric quantifies the difference between the model’s output and the desired outcome. The right panel shows the Euclidean norm (magnitude) of the difference between the model’s initial velocity estimate (v
0θ) and the true optimal velocity (v0∗) for each epoch. This error norm highlights how accurately the model predicts the optimal trajectory at the beginning of the sampling process. A gray line in the right panel represents the magnitude of the ground truth velocity, providing a visual reference for the scale of the error.read the caption
Figure 3: Results on mixture of Gaussians in ℝ2superscriptℝ2{\mathbb{R}}^{2}blackboard_R start_POSTSUPERSCRIPT 2 end_POSTSUPERSCRIPT. Left: The Jensen–Shannon divergence between the model’s final flow sample distribution and the target distribution v.s. training epoch. Right: The velocity error norm ‖𝒗~0θ−𝒗~0∗‖normsubscriptsuperscript~𝒗𝜃0subscriptsuperscript~𝒗∗0\|\tilde{{\bm{v}}}^{\theta}_{0}-\tilde{{\bm{v}}}^{\ast}_{0}\|∥ over~ start_ARG bold_italic_v end_ARG start_POSTSUPERSCRIPT italic_θ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT - over~ start_ARG bold_italic_v end_ARG start_POSTSUPERSCRIPT ∗ end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 0 end_POSTSUBSCRIPT ∥, with the ground truth norm shown in gray v.s. training epoch.

🔼 Figure 4 presents a qualitative comparison of image generation results using standard Classifier-Free Guidance (CFG) and the improved method CFG-Zero*. Three different state-of-the-art models were used: Lumina-Next, Stable Diffusion 3, and Stable Diffusion 3.5. Each model used its optimal settings for sampling steps and guidance scale. The images generated with CFG are shown in orange, while those generated with CFG-Zero* are highlighted in green boxes, allowing for a direct visual comparison of the quality and fidelity of the generated images.
read the caption
Figure 4: Qualitative comparisons between CFG and CFG-Zero⋆. Experiments are conducted using Lumina-Next, Stable Diffusion 3, and Stable Diffusion 3.5, with each model evaluated under its recommended optimal sampling steps and guidance scale settings. CFG results are shown in orange and Ours are highlighted in green boxes.

🔼 This figure displays the results of a user study comparing the performance of CFG-Zero* against the standard CFG method across four different text-to-image models: Lumina-Next, Stable Diffusion 3, Stable Diffusion 3.5, and Flux. For each model, the chart shows the percentage of times users preferred images generated by CFG-Zero* over those generated by CFG. This provides a clear visual representation of CFG-Zero*’s relative effectiveness in generating higher-quality images compared to CFG across multiple leading models.
read the caption
Figure 5: User study on Lumina-Next, Stable Diffusion 3, Stable Diffusion 3.5, and Flux. The win rate of our method compared to CFG is presented.

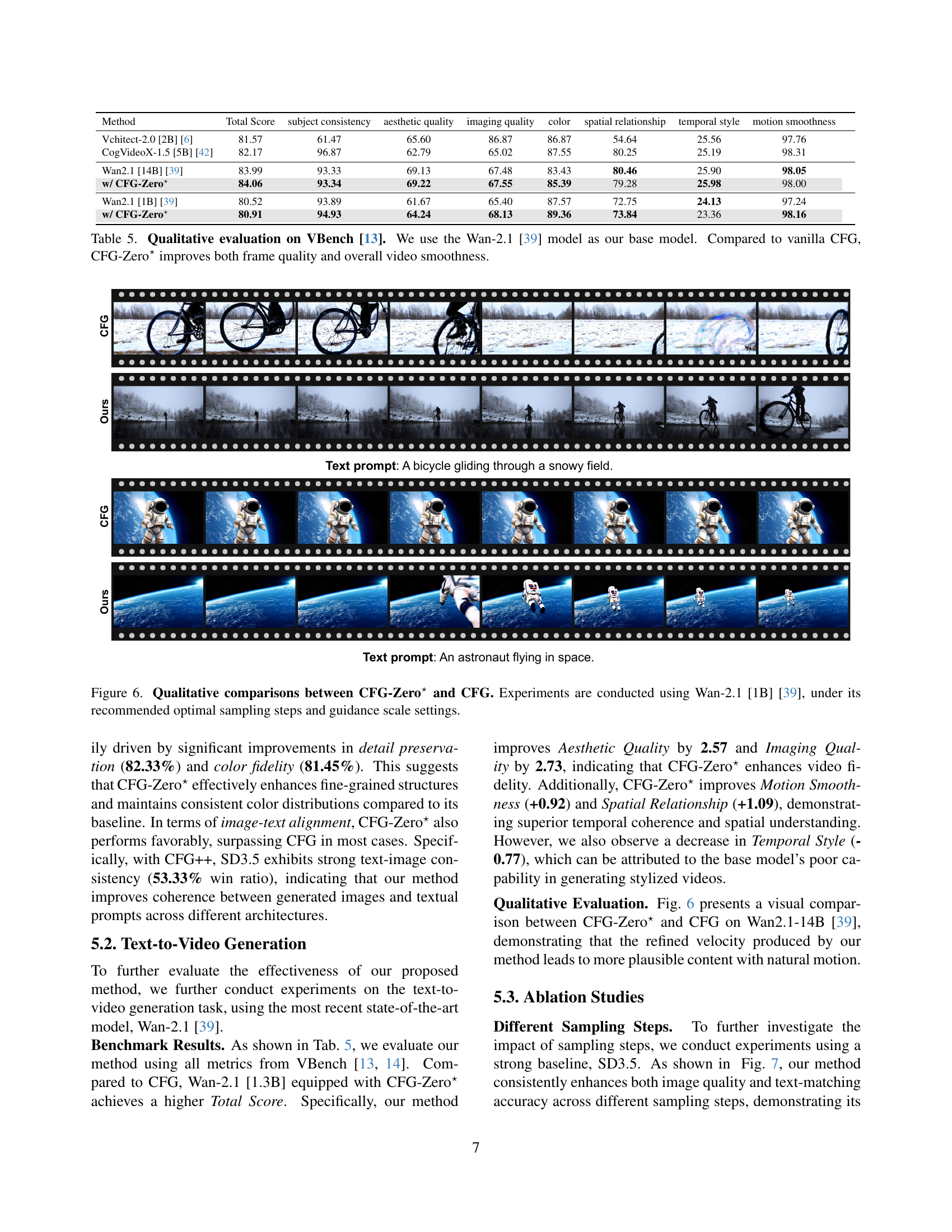
🔼 Figure 6 showcases a qualitative comparison of video generation results using the Wan-2.1 [1B] model, with and without the CFG-Zero* method. The experiments were conducted using the model’s recommended parameters for optimal sampling steps and guidance scale. The figure directly compares the visual quality of videos generated by CFG-Zero* and standard CFG, allowing for a visual assessment of the improvements achieved by CFG-Zero* in terms of detail, color, and overall smoothness of the generated videos. Two example video prompts are shown: ‘A bicycle gliding through a snowy field’ and ‘An astronaut flying in space.’
read the caption
Figure 6: Qualitative comparisons between CFG-Zero⋆ and CFG. Experiments are conducted using Wan-2.1 [1B] [39], under its recommended optimal sampling steps and guidance scale settings.

🔼 This ablation study investigates the effect of varying the number of sampling steps on the performance of CFG-Zero* and standard CFG. Two key metrics are compared across different step counts: CLIP Score (measuring image-text alignment) and Aesthetic Score (measuring visual appeal). The graphs visualize how these scores change for both methods as the number of sampling steps increases, allowing for a direct comparison of the impact of the proposed CFG-Zero* improvements on image quality and alignment with text prompts, across various sampling steps.
read the caption
Figure 7: Abalation study on different sampling steps. Comparison of CLIP Score and Aesthetic Score between our method and CFG across different sampling steps.

🔼 This ablation study investigates the effect of varying the guidance scale on the performance of both the standard CFG method and the proposed CFG-Zero* method. Two metrics are used to evaluate performance: the CLIP Score, which measures the alignment between generated images and text prompts, and the Aesthetic Score, which assesses the visual quality of the generated images. The figure shows how these two scores change for CFG and CFG-Zero* as the guidance scale is varied. This allows for an analysis of which method is more robust and performs better across a range of guidance scales, demonstrating the effectiveness of CFG-Zero* in improving both image-text alignment and visual quality compared to the baseline CFG.
read the caption
Figure 8: Abalation study on different guidance scale. Comparison of CLIP Score and Aesthetic Score between our method and CFG across different guidance scale.

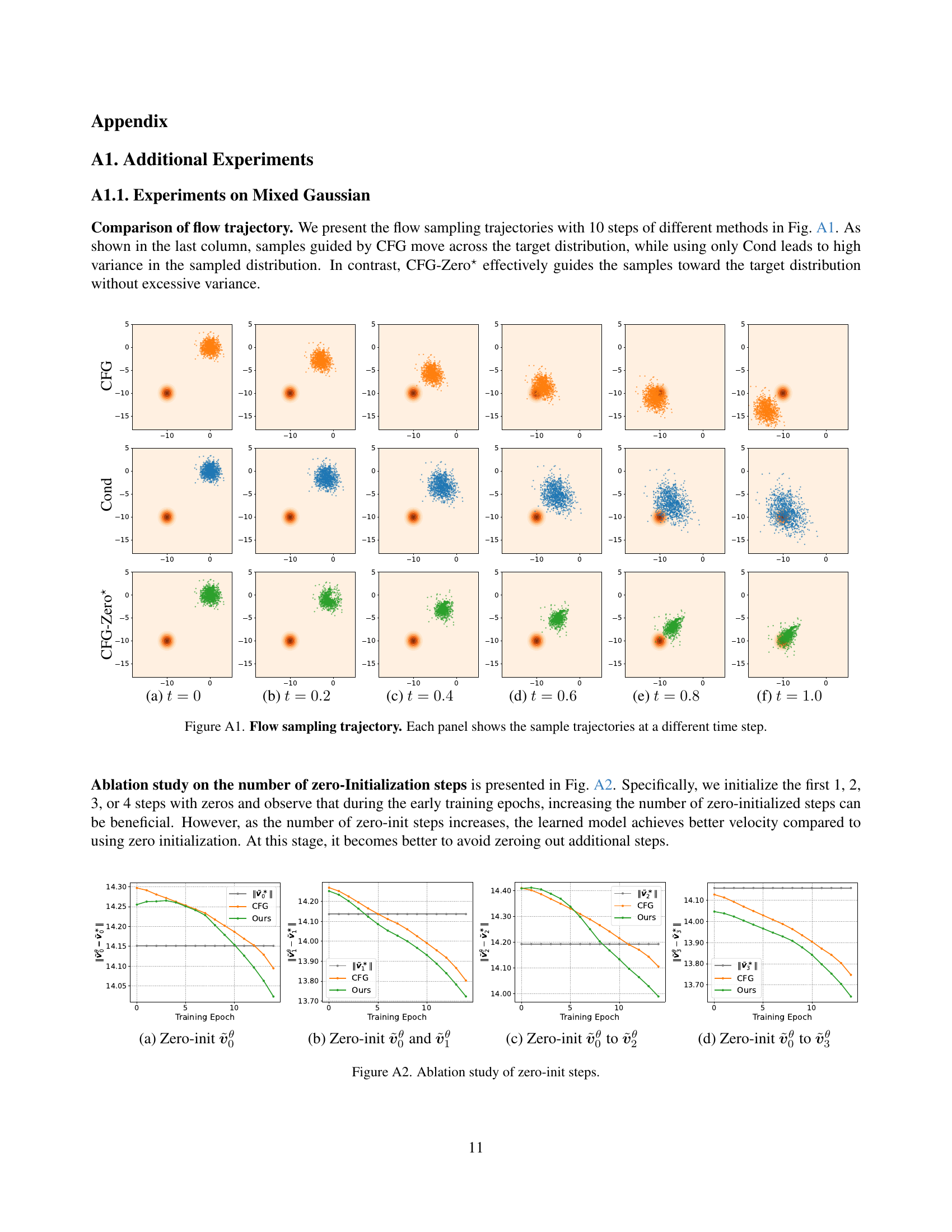
🔼 Figure A1 visualizes the sampling trajectories of a flow matching model for different time steps (t=0, 0.2, 0.4, 0.6, 0.8, 1.0). Each panel displays the sample trajectories generated using three different guidance methods: CFG (Classifier-Free Guidance), ‘Cond’ (conditional generation without guidance), and the proposed CFG-Zero*. The figure demonstrates how CFG-Zero* effectively guides the samples toward the target distribution, unlike CFG which causes the samples to deviate significantly, and Cond which results in high variance.
read the caption
Figure A1: Flow sampling trajectory. Each panel shows the sample trajectories at a different time step.

🔼 This ablation study investigates the impact of the ‘zero-init’ technique on model performance. The technique involves setting the initial velocity to zero for a specified number of steps in the ordinary differential equation (ODE) solver used during sample generation. The figure likely shows how different numbers of zero-initialized steps affect key performance metrics, possibly including image quality scores and the alignment between generated images and text prompts (measured by metrics like FID or CLIP score). The results would demonstrate whether zeroing out early ODE steps leads to improved or worse outcomes.
read the caption
Figure A2: Ablation study of zero-init steps.
More on tables
| Epochs | Methods | Metrics | ||||
|---|---|---|---|---|---|---|
| IS | FID | sFID | Precision | Recall | ||
| 10 | CFG | 53.27 | 28.57 | 18.52 | 0.61 | 0.36 |
| Zero-Init | 52.78 | 28.55 | 17.32 | 0.62 | 0.37 | |
| 20 | CFG | 257.23 | 11.00 | 11.64 | 0.92 | 0.24 |
| Zero-Init | 255.79 | 10.65 | 10.95 | 0.92 | 0.25 | |
| 40 | CFG | 339.39 | 12.61 | 11.17 | 0.94 | 0.23 |
| Zero-Init | 338.40 | 12.29 | 10.47 | 0.94 | 0.24 | |
| 80 | CFG | 383.06 | 13.53 | 10.99 | 0.94 | 0.24 |
| Zero-Init | 383.45 | 12.18 | 10.39 | 0.94 | 0.26 | |
| 160 | CFG | 222.13 | 2.84 | 4.56 | 0.81 | 0.56 |
| Zero-Init | 218.90 | 2.85 | 4.97 | 0.80 | 0.56 | |
🔼 This table presents a quantitative comparison of different guidance strategies used in generating images from the ImageNet-256 dataset. It compares the performance of standard conditional generation (baseline), classifier-free guidance (CFG), adaptive guidance (ADG), CFG++, and the proposed CFG-Zero*. The comparison is based on several metrics including the Inception Score (IS), which measures the quality and diversity of generated images (higher IS is better), and the Fréchet Inception Distance (FID), which measures the similarity between generated images and real images from the dataset (lower FID is better). Precision and Recall metrics assess the model’s ability to accurately generate images for a given class. The results show how each method affects the generated images’ quality and alignment with the ground truth.
read the caption
Table 2: Comparison of different guidance strategy on ImageNet-256 benchmark. Lower FID is better (↓↓\downarrow↓) and higher IS is better (↑↑\uparrow↑). Baseline here denotes using the conditional prediction only.
| Method | IS | FID | sFID | Precision | Recall |
|---|---|---|---|---|---|
| Baseline | 125.13 | 9.41 | 6.40 | 0.67 | 0.67 |
| w/ CFG | 257.03 | 2.23 | 4.61 | 0.81 | 0.59 |
| w/ ADG [31] | 257.92 | 2.37 | 5.51 | 0.80 | 0.58 |
| w/ CFG++ [2] | 257.04 | 2.25 | 4.65 | 0.79 | 0.57 |
| w/ CFG-Zero⋆ | 258.87 | 2.10 | 4.59 | 0.80 | 0.61 |
🔼 This table presents a quantitative comparison of image generation results using four different models (Lumina-Next, Stable Diffusion 3, Stable Diffusion 3.5, and Flux) and two guidance methods (CFG and CFG-Zero*). The comparison is based on two key metrics: Aesthetic Score, which measures the overall visual appeal of the generated images, and CLIP Score, which assesses how well the generated images align with the given text prompts. The results demonstrate that CFG-Zero* consistently produces higher scores on both metrics across all four models, indicating that it improves both the visual quality and the alignment of generated images with text prompts.
read the caption
Table 3: Quantitative evaluation of Text-to-Image generation, using Lumina-Next, Stable Diffusion 3, Stable Diffusion 3.5, and Flux. The evaluation is based on Aesthetic Score and CLIP Score as key metrics. Results indicate that CFG-Zero⋆ consistently enhances image quality and improves alignment with textual prompts across different models.
| Model | Method | Aesthetic Score | Clip Score |
|---|---|---|---|
| Lumina-Next [45] | CFG | 6.85 | 34.09 |
| CFG-Zero⋆ | 7.03 | 34.37 | |
| SD3 [5] | CFG | 6.73 | 34.00 |
| CFG-Zero⋆ | 6.80 | 34.11 | |
| SD3.5 [5] | CFG | 6.96 | 34.60 |
| CFG-Zero⋆ | 7.10 | 34.68 | |
| Flux [20] | CFG | 7.06 | 34.60 |
| CFG-Zero⋆ | 7.12 | 34.69 |
🔼 This table presents a quantitative comparison of the performance of CFG-Zero* and the standard CFG method on the T2I-CompBench benchmark dataset. The evaluation was performed using three different state-of-the-art text-to-image models: Lumina-Next, Stable Diffusion 3, and Stable Diffusion 3.5. The results demonstrate that CFG-Zero* consistently outperforms CFG across various metrics, showcasing improvements in the quality and details of generated images.
read the caption
Table 4: Quantitative evaluation on T2I-CompBench [12], using Lumina-Next, Stable Diffusion 3, and Stable Diffusion 3.5. Compared to CFG, CFG-Zero⋆ demonstrates consistent improvements across all evaluated aspects.
| Method | Color | Shape | Texture | Spatial |
|---|---|---|---|---|
| Lumina-Next [45] | 0.51 | 0.34 | 0.41 | 0.19 |
| + CFG-Zero⋆ | 0.52 | 0.36 | 0.45 | 0.29 |
| SD3 [5] | 0.81 | 0.57 | 0.71 | 0.31 |
| + CFG-Zero⋆ | 0.83 | 0.58 | 0.72 | 0.31 |
| SD3.5 [5] | 0.76 | 0.59 | 0.70 | 0.27 |
| + CFG-Zero⋆ | 0.78 | 0.60 | 0.71 | 0.28 |
🔼 This table presents a quantitative evaluation of the CFG-Zero* method on the VBench benchmark, specifically using the Wan-2.1 video generation model. The metrics assessed include Total Score, Subject Consistency, Aesthetic Quality, Imaging Quality, Color, Spatial Relationship, Temporal Style, and Motion Smoothness. The results show the performance of both the baseline Wan-2.1 model and the model enhanced with CFG-Zero*, demonstrating improvements in frame quality and overall video smoothness compared to the standard CFG approach.
read the caption
Table 5: Qualitative evaluation on VBench [13]. We use the Wan-2.1 [39] model as our base model. Compared to vanilla CFG, CFG-Zero⋆ improves both frame quality and overall video smoothness.
| Method | Total Score | subject consistency | aesthetic quality | imaging quality | color | spatial relationship | temporal style | motion smoothness | |
|---|---|---|---|---|---|---|---|---|---|
| Vchitect-2.0 [2B] [6] | 81.57 | 61.47 | 65.60 | 86.87 | 86.87 | 54.64 | 25.56 | 97.76 | |
| CogVideoX-1.5 [5B] [42] | 82.17 | 96.87 | 62.79 | 65.02 | 87.55 | 80.25 | 25.19 | 98.31 | |
| Wan2.1 [14B] [39] | 83.99 | 93.33 | 69.13 | 67.48 | 83.43 | 80.46 | 25.90 | 98.05 | |
| w/ CFG-Zero⋆ | 84.06 | 93.34 | 69.22 | 67.55 | 85.39 | 79.28 | 25.98 | 98.00 | |
| Wan2.1 [1B] [39] | 80.52 | 93.89 | 61.67 | 65.40 | 87.57 | 72.75 | 24.13 | 97.24 | |
| w/ CFG-Zero⋆ | 80.91 | 94.93 | 64.24 | 68.13 | 89.36 | 73.84 | 23.36 | 98.16 |
🔼 This table presents a quantitative comparison of four different methods for classifier-free guidance (CFG) in diffusion models: vanilla CFG, CFG with zero initialization (zero-init), CFG with dynamic scaling, and the proposed CFG-Zero*. The results highlight the individual and combined contributions of zero-init and dynamic scaling to the overall performance, measured by aesthetic score and CLIP score. It demonstrates how these modifications improve the quality and alignment of generated images by mitigating inaccuracies in the early stages of the generation process.
read the caption
Table 6: Effectiveness of CFG-Zero⋆. Comparison of vanilla CFG, CFG with zero-init, dynamic scaling, and CFG-Zero⋆, highlighting the impact of zero-init and dynamic scaling in improving performance.
 |  |
| (a) | (b) |
🔼 This ablation study investigates the impact of the ‘zero-init’ technique, which involves setting the initial steps of the ODE solver to zero, on the performance of different flow matching models. The experiment focuses on varying the number of initial steps set to zero and measures the resulting Aesthetic Score and CLIP Score. The results show a model-specific optimal number of zero-out steps. For SD3.5, increasing the number of zero-out steps beyond a certain point negatively impacts performance. Conversely, for Lumina-Next and SD3, utilizing approximately the first 7% of steps as zero-init steps yields the highest aesthetic and CLIP scores.
read the caption
Table 7: Ablation study on zero-out steps. For SD3.5 [5], more initial zero-out steps lead to worse performance, while Lumina-Next [45] and SD3 [5] achieve the highest Aesthetic Score and Clip Score with first 7% zero out.
 |  |
| (a) | (b) |
🔼 This table presents the computational resource requirements for generating 5-second videos using two different models: Wan2.1 and SD3. It details the FLOPs (floating-point operations) and GPU memory usage needed to produce videos at various resolutions (720p/480p for Wan2.1 and 1024x1024/512x512 for SD3). This information is crucial for understanding the efficiency and scalability of the proposed CFG-Zero* method.
read the caption
Table 8: Computational costs. FLOPs [15] and GPU memory usage of our method for 5-second video generation at 720p/480p using Wan2.1 [39], and at 1024/512 resolution using SD3 [5].
Full paper#