TL;DR#
Generating high-quality videos remains challenging due to the need for temporal coherence and capturing complex dynamics. Scaling video generation methods in training is costly and resource-intensive. To address this, the paper investigates test-time scaling (TTS) in video generation, asking how much it can improve generation quality for challenging text prompts. This explores enhancing video generation without retraining or enlarging models.
This paper introduces Video-T1, a framework that reinterprets TTS as a search problem for better video trajectories. It uses test-time verifiers and heuristic algorithms to guide the search. A linear search strategy increases noise candidates, while Tree-of-Frames (ToF) efficiently expands and prunes video branches. Experiments show that increasing test-time compute significantly improves video quality, offering a way to achieve superior results in computer vision.
Key Takeaways#
Why does it matter?#
This work introduces Video-T1, a novel test-time scaling framework that significantly enhances video generation quality by treating it as a search problem. It is important for showing how to achieve improved performance without expensive retraining, paving the way for more efficient video generation techniques and further exploration in this area.
Visual Insights#

🔼 This figure demonstrates the impact of Test-Time Scaling (TTS) on video generation quality. The top row showcases videos generated without TTS, while the bottom row shows videos generated using TTS. The differences highlight how TTS leads to videos that are more faithful to the text prompt and exhibit improved visual coherence and overall quality. Specific examples include clearer image generation, more accurate object representation, and better adherence to the described actions.
read the caption
Figure 1: Video-T1: We present the generative effects and performance improvements of video generation under Test-Time Scaling (TTS) settings. The videos generated with TTS are of higher quality and more consistent with the prompt than those generated without TTS.
| Methods | Linear Search | ToF Search |
|---|---|---|
| Pyramid-Flow(FLUX) | ||
| Pyramid-Flow(SD3) | ||
| NOVA |
🔼 This table presents a comparison of the computational cost, measured in GFLOPs (floating-point operations), for inference-time scaling using two different search methods: Linear Search and Tree-of-Frames (ToF) Search. It shows the GFLOPs required for each method across three different video generation models: Pyramid-Flow (FLUX), Pyramid-Flow (SD3), and NOVA. This allows for a quantitative assessment of the efficiency gains achieved by the ToF Search method compared to the more straightforward Linear Search method.
read the caption
Table 1: Inference-time scaling cost comparison on GFLOPs.
In-depth insights#
TTS for Video#
Test-Time Scaling (TTS) for video generation presents a promising avenue for enhancing video quality without the intensive costs associated with retraining or scaling model size. The core idea involves reinterpreting video generation as a search problem, navigating the latent space of Gaussian noise to identify trajectories that yield high-quality, text-aligned videos. This involves techniques such as random linear search and Tree-of-Frames (ToF) search, which adaptively expands and prunes video branches to balance computational cost and generation quality. The process utilizes test-time verifiers to assess the quality of intermediate results and guide the search process. By scaling the search space during inference, the method aims to uncover a broader range of potential solutions, leading to significant improvements in the quality and human preference alignment of generated videos. This offers a path to achieve superior results by leveraging inference-time computation effectively.
Searching Trajectory#
Searching trajectory can be conceptualized as finding an optimal path in a high-dimensional space to generate desired outputs. It involves navigating through possible solutions, improving the results at each step. In video generation, this means that starting from random noise, trajectories are denoised to the target video according to text prompts. The key to successful trajectory searching includes a strong evaluator and search methods. Test-Time Scaling (TTS) amplifies this process by increasing computational budget. This enables more samples and diverse trajectories to be explored, making it more likely to find a better result. Heuristic search algorithms, that use feedback from the verifier can efficiently explore the space, improving the qualities of videos.
Tree-of-Frames#
The Tree-of-Frames (ToF) approach addresses computational inefficiencies in test-time scaling for video generation. Unlike methods that process all frames simultaneously, ToF operates autoregressively, building a tree-like structure where video frames are nodes. This allows for adaptive expansion and pruning of video branches using feedback from test-time verifiers. ToF seeks to balance computation with generation quality. It starts with an initial frame and generates subsequent frames based on verifier feedback, which guides the search process. This includes image-level alignment (ensuring initial frame quality), hierarchical prompting (dynamically adjusting prompts for different stages of video creation), and heuristic pruning (eliminating unpromising branches to reduce computational cost). By structuring the generation process as a tree search, ToF can efficiently explore the space of possible video trajectories, achieving performance comparable to less efficient methods with significantly reduced computational overhead.
Multi-Verifiers#
Multi-verifier systems in video generation can potentially enhance performance significantly by mitigating biases inherent in single verifiers. These systems leverage a mixture of different evaluation models, allowing for a more robust assessment of generated video quality. By ensembling multiple verifiers, the system can better identify and select the highest-quality videos from a set of candidates, resulting in improved overall performance and a more reliable evaluation process. This approach can lead to more consistent and trustworthy results in video generation tasks.
Improve VBench#
While the paper doesn’t explicitly detail improvements to the VBench benchmark itself, the research intrinsically contributes to its enhanced utility. By demonstrating the effectiveness of Test-Time Scaling (TTS) in video generation, the study provides insights into evaluating video models more comprehensively. The consistent performance gains achieved through TTS, as measured by VBench across various models and dimensions, validate VBench’s ability to capture nuanced improvements in video quality and text alignment. The use of multiple verifiers within the TTS framework highlights the need for multi-faceted evaluation metrics, a concept directly applicable to refining VBench. The observation that different verifiers emphasize different aspects of video quality suggests that VBench could benefit from a more granular weighting of its sub-dimensions. Moreover, the failure cases identified in the experiments underscore the importance of VBench’s capacity to discern subtle yet critical aspects of video generation, such as realistic hand movements. Overall, the research implicitly strengthens VBench by validating its role in assessing video generation models and indicating areas for further development, such as incorporating diverse evaluation metrics and increasing sensitivity to fine-grained details.
More visual insights#
More on figures

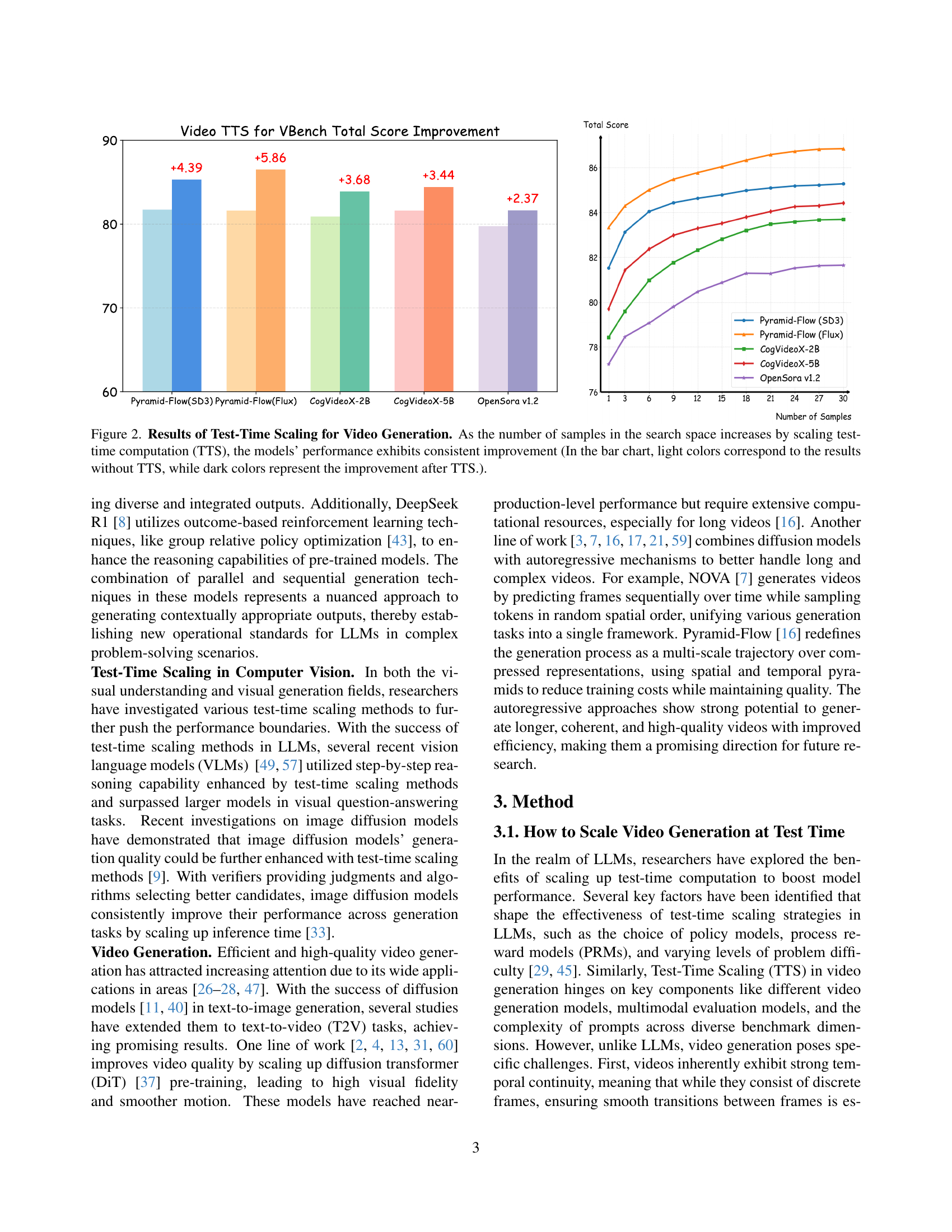
🔼 This figure displays the results of applying test-time scaling (TTS) to video generation. The bar chart shows the total score improvement across different video generation models (Pyramid-Flow (SD3), Pyramid-Flow (Flux), CogVideoX-2B, CogVideoX-5B, and OpenSora v1.2) as the number of samples in the search space increases. The light colored bars represent the model performance without TTS, and the dark colored bars show the improvement in total score achieved with TTS. This visually demonstrates the consistent performance gains obtained by increasing the computation during the testing phase, enhancing the quality of the generated videos.
read the caption
Figure 2: Results of Test-Time Scaling for Video Generation. As the number of samples in the search space increases by scaling test-time computation (TTS), the models’ performance exhibits consistent improvement (In the bar chart, light colors correspond to the results without TTS, while dark colors represent the improvement after TTS.).

🔼 This figure illustrates the pipeline of Test-Time Scaling (TTS) for video generation. The top part depicts the Random Linear Search method, where Gaussian noise is sampled, fed into a video generator for step-by-step denoising, and the resulting video is evaluated by verifiers. The highest-scoring video is chosen. The bottom half shows the Tree-of-Frames (ToF) Search method which involves three stages. Stage 1: Initial image-level alignment, influencing subsequent frames. Stage 2: Dynamic prompt is applied, focusing on motion stability and physical plausibility within the test verifiers. The resulting feedback guides the search process. Stage 3: Final evaluation of video quality, selecting the video with the highest text-prompt alignment.
read the caption
Figure 3: Pipeline of Tes-Time Scaling for Video Generation. Top: Random Linear Search for TTS video generation is to randomly sample Gaussian noises, prompt the video generator to generate sequential of video clips through step-by-step denoising in a linear manner, and select the highest score form the test verifiers. Bottom: Tree of Frames (ToF) Search for TTS video generation is to divide the video generation process into three stages: (a) the first stage performs image-level alignment that influences the later frames; (b) the second stage is to apply dynamic prompt in test verifiers 𝒱𝒱\mathcal{V}caligraphic_V to focus on motion stability, physical plausibility to provide feedback that guides heuristic searching process; (c) the last stage assesses the overall quality of the video and select the video with highest alignment with text prompts.

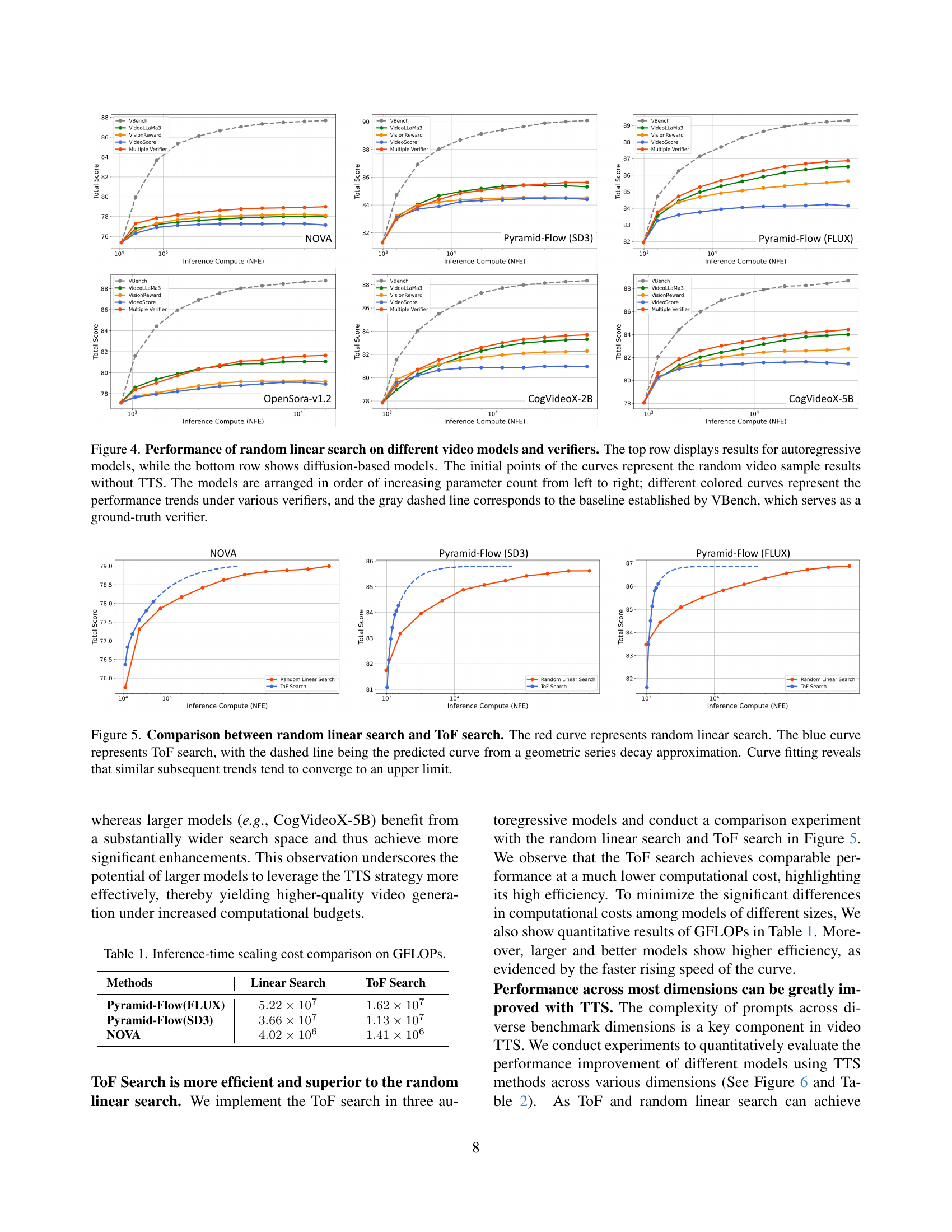
🔼 This figure showcases the results of applying a random linear search method for test-time scaling (TTS) on six different video generation models. The models are categorized into autoregressive (top row) and diffusion-based (bottom row) models, and are presented in ascending order of their parameter size. Each model’s performance is evaluated using four different verifiers (represented by distinct colored lines). The gray dashed line signifies the performance baseline set by VBench, a ground-truth verifier that serves as a point of comparison. The starting point of each colored line indicates the quality of videos generated without TTS (test-time scaling). The subsequent points illustrate the performance improvement as the TTS computation budget (and therefore the number of samples explored) increases.
read the caption
Figure 4: Performance of random linear search on different video models and verifiers. The top row displays results for autoregressive models, while the bottom row shows diffusion-based models. The initial points of the curves represent the random video sample results without TTS. The models are arranged in order of increasing parameter count from left to right; different colored curves represent the performance trends under various verifiers, and the gray dashed line corresponds to the baseline established by VBench, which serves as a ground-truth verifier.

🔼 Figure 5 compares the performance of two test-time scaling (TTS) search algorithms: random linear search and Tree-of-Frames (ToF) search. The graph plots the total VBench score (a metric for video quality) against the amount of computational resources used (NFE). The red curve shows the performance of random linear search, where increasing computation leads to incremental improvements in video quality but at a diminishing rate of return. The blue curve illustrates the performance of ToF search, which demonstrates significantly better efficiency. The dashed blue line represents a geometric series decay approximation fitted to the ToF search curve. This highlights that the ToF search converges to a maximum quality score more efficiently, indicating better resource utilization. The convergence suggests that beyond a certain computational budget, additional resources offer minimal quality improvement.
read the caption
Figure 5: Comparison between random linear search and ToF search. The red curve represents random linear search. The blue curve represents ToF search, with the dashed line being the predicted curve from a geometric series decay approximation. Curve fitting reveals that similar subsequent trends tend to converge to an upper limit.
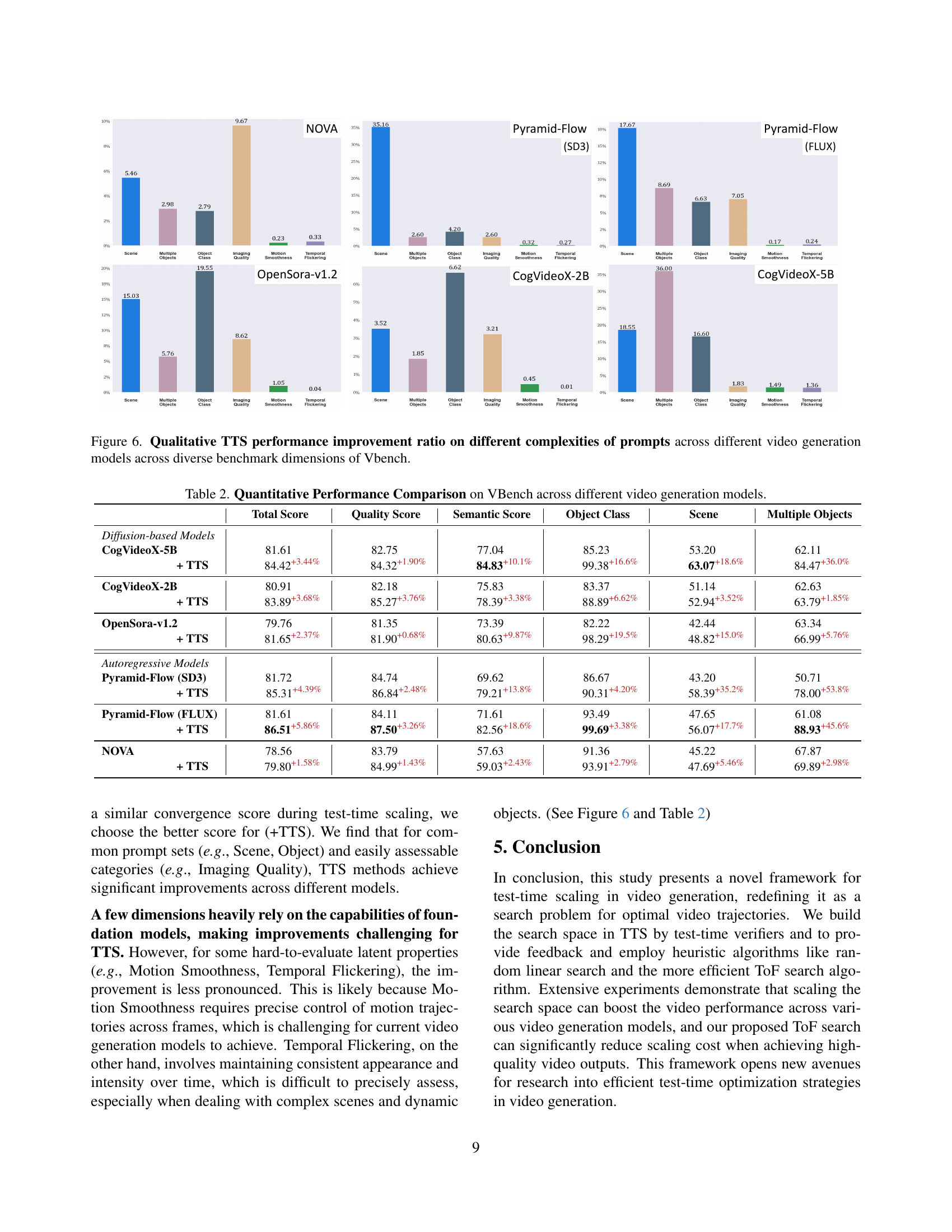
🔼 This figure displays a bar chart visualizing the percentage improvement in video generation quality achieved by Test-Time Scaling (TTS) across various model complexities and benchmark dimensions. Each bar represents a specific model (e.g., NOVA, Pyramid-Flow) and benchmark dimension (e.g., scene, object class, motion), showing the percentage increase in the VBench score after applying TTS. The various colors within each bar indicate the use of different verifiers. The figure highlights how TTS enhances performance differently across various video generation models and benchmark dimensions, providing insights into the effectiveness of TTS in different scenarios.
read the caption
Figure 6: Qualitative TTS performance improvement ratio on different complexities of prompts across different video generation models across diverse benchmark dimensions of Vbench.

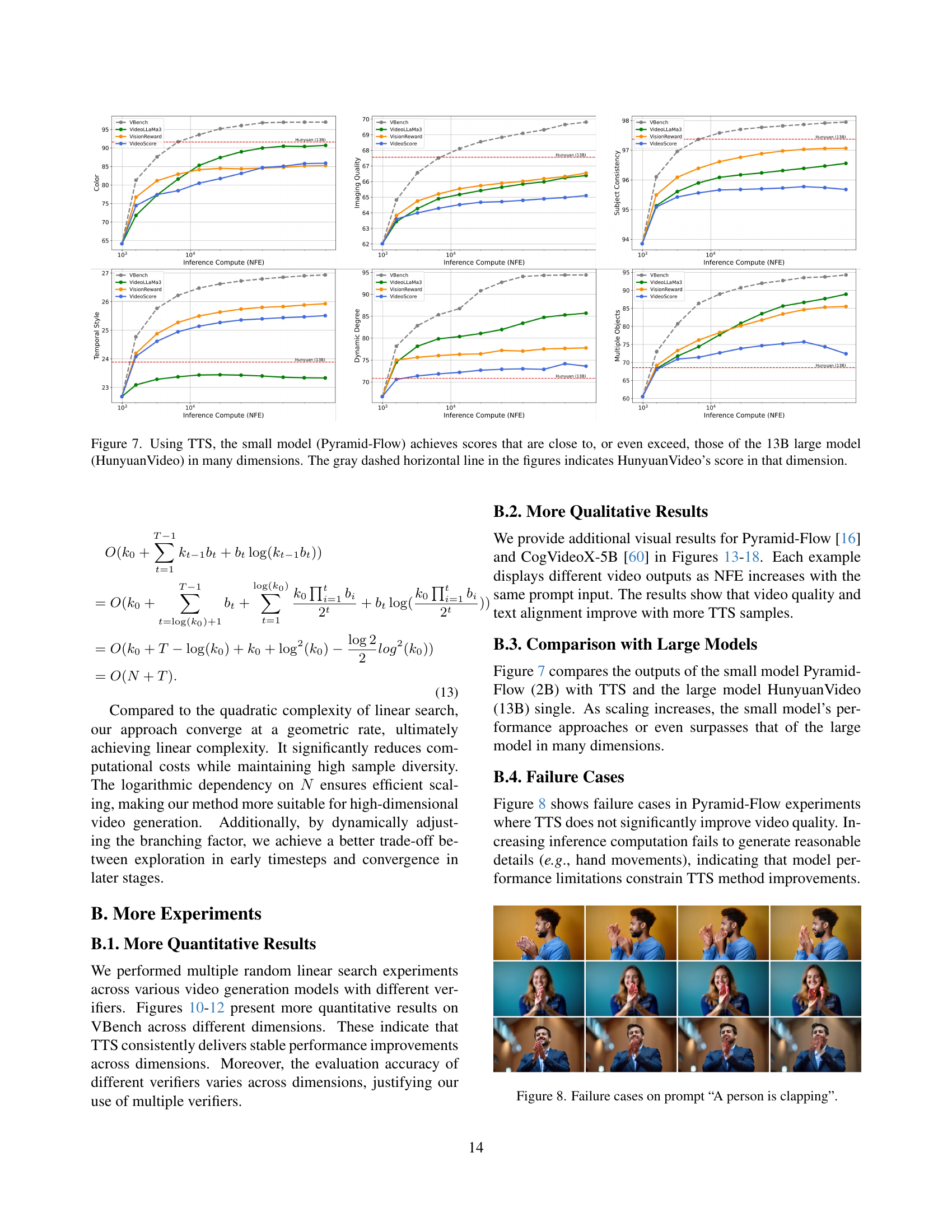
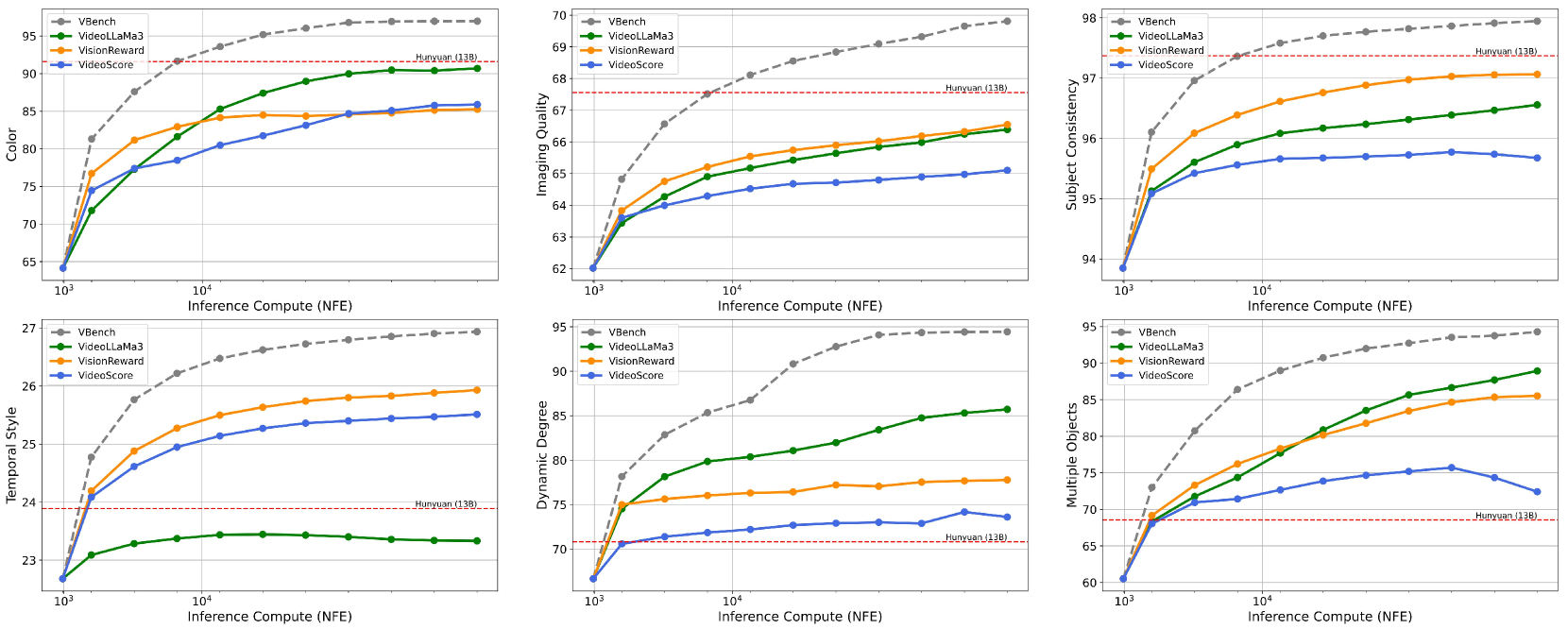
🔼 Figure 7 presents a comparison of performance between a smaller video generation model (Pyramid-Flow) and a significantly larger model (HunyuanVideo) when using test-time scaling (TTS). The figure shows that with increased computational resources allocated during inference (via TTS), the smaller Pyramid-Flow model achieves results comparable to or even surpassing those of the much larger 13B parameter HunyuanVideo model across multiple evaluation metrics. The gray dashed lines in each subplot represent the baseline performance of the HunyuanVideo model on that specific dimension, providing a clear visual comparison to the performance of the smaller model when utilizing TTS.
read the caption
Figure 7: Using TTS, the small model (Pyramid-Flow) achieves scores that are close to, or even exceed, those of the 13B large model (HunyuanVideo) in many dimensions. The gray dashed horizontal line in the figures indicates HunyuanVideo’s score in that dimension.

🔼 Figure 8 shows examples where the test-time scaling (TTS) method does not improve video generation quality. The figure displays several video frames generated from the prompt “A person is clapping.” Even with increased inference-time computation, the model struggles to generate realistic hand movements. This illustrates that model limitations can constrain the effectiveness of the TTS method, particularly for complex actions.
read the caption
Figure 8: Failure cases on prompt “A person is clapping”.

🔼 This figure illustrates the hierarchical verification process within the Tree-of-Frames (ToF) search algorithm during test-time scaling (TTS). The example shows a video generation task prompted by the text ‘a bear climbing a tree.’ The ToF approach breaks down the video generation into three stages: (1) generation of the initial frame, (2) generation of intermediate frames, and (3) generation of the final frame. At each stage, a verifier assesses the generated frames against the corresponding portion of the prompt. The verifier output, either ‘Yes’ (successful) or ‘No’ (unsuccessful), guides the progress of the search process. The flow demonstrates that the ToF method provides feedback in a step-wise manner during the video generation, refining the output to align with the prompt by verifying each stage sequentially.
read the caption
Figure 9: Verifications during TTS process.

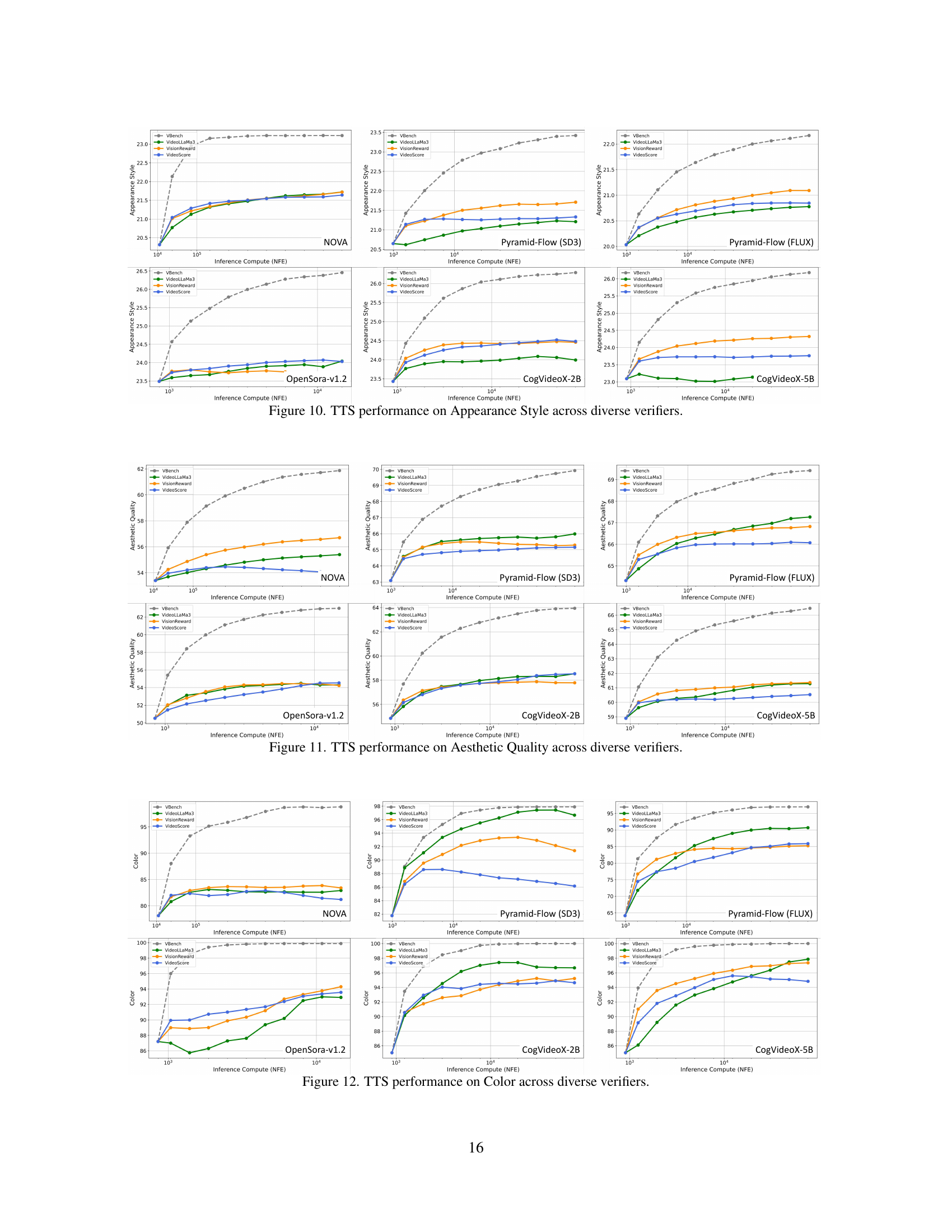
🔼 Figure 10 presents the results of applying test-time scaling (TTS) to improve the ‘Appearance Style’ aspect of video generation. It shows how different video generation models perform across various evaluation metrics (verifiers) as the amount of computation allocated at test time increases. The graphs illustrate the consistent improvement in appearance quality achieved by increasing the computational budget, highlighting the effectiveness of TTS for enhancing this specific visual attribute.
read the caption
Figure 10: TTS performance on Appearance Style across diverse verifiers.

🔼 This figure displays the results of test-time scaling (TTS) on the aesthetic quality of videos generated by six different video generation models. Each model is evaluated using four different verifiers (VBench, VideoLLaMa3, VisionReward, and VideoScore), which assess the videos’ quality from different perspectives. The x-axis represents the increasing computational cost (measured in NFE, number of function evaluations) during inference as the TTS is applied. The y-axis shows the corresponding aesthetic quality scores. The graphs illustrate how the aesthetic quality of the videos improves consistently as more computational resources are allocated during the test phase (increased NFE). The different verifiers show varying degrees of improvement, highlighting the diverse aspects of video quality assessment.
read the caption
Figure 11: TTS performance on Aesthetic Quality across diverse verifiers.

🔼 Figure 12 presents the results of applying Test-Time Scaling (TTS) to enhance color generation in videos. It displays the performance of different video generation models (NOVA, OpenSora v1.2, Pyramid-Flow (SD3), Pyramid-Flow (Flux), CogVideoX-2B, and CogVideoX-5B) across various verifiers (VBench, VideoLLaMa3, VisionReward, and VideoScore). The x-axis represents the computational cost (NFE), and the y-axis shows the performance score on the ‘Color’ dimension of the VBench benchmark. Each line represents a different video generation model, with different colors representing the different verifiers used to evaluate model performance. The figure demonstrates how increasing test-time computation generally improves the quality of color generation across various models and verifiers.
read the caption
Figure 12: TTS performance on Color across diverse verifiers.

🔼 This figure shows the results of applying Test-Time Scaling (TTS) to video generation using the Pyramid-Flow model. Each set of images represents a short video clip, with each row representing a different number of samples used during the TTS process. As the number of samples increases (from top to bottom), the quality and coherence of the generated videos improves. This demonstrates the effectiveness of TTS in enhancing the quality of video generation.
read the caption
Figure 13: More visual results during TTS process on Pyramid-Flow. From left to right, each row of frames are extracted from a video sequence. From top to bottom, each row represents the output video results of TTS with an increasing number of samples.

🔼 This figure showcases several video sequences generated using the Pyramid-Flow model with the Test-Time Scaling (TTS) technique. Each row presents a different number of samples used during the TTS process, illustrating how increased computation at inference time enhances the video generation. The videos in the figure demonstrate improvements in the overall quality, especially in handling complex movements and human motion, which are often challenging aspects of video generation. The results illustrate how TTS helps to effectively address common issues encountered when generating videos, resulting in smoother and more realistic movement.
read the caption
Figure 14: More visual results during TTS process on Pyramid-Flow. The TTS method can effectively alleviate common issues in video generation, such as those related to human motion and complex movements.

🔼 This figure displays several example videos generated using the CogVideoX-5B model with the Test-Time Scaling (TTS) method. Each set of images shows a sequence of frames from a single video, progressing from left to right. Multiple rows show the same video generated with increasing computational resources allocated at inference time. The differences in quality and consistency demonstrate the impact of TTS on the overall video generation quality.
read the caption
Figure 15: More visual results during TTS process on CogVideoX-5B.

🔼 This figure showcases additional visual results obtained from employing the Test-Time Scaling (TTS) method on the CogVideoX-5B model. The images demonstrate the enhanced video generation quality achieved through TTS by displaying multiple frames extracted from videos generated with increasing computational budget. Each row represents a separate video and shows the progression of generation quality as more computational resources are used during inference.
read the caption
Figure 16: More visual results during TTS process on CogVideoX-5B.

🔼 This figure showcases the improved multi-object spatial perception achieved by applying Test-Time Scaling (TTS) to the CogVideoX-2B model. It presents several example video generations, each showing an increase in the quality and accuracy of the scene’s spatial arrangement as the computational resources allocated to TTS are increased. The images illustrate that with more compute at inference time, the model more accurately represents the relationships between objects specified in the text prompt (e.g., an apple correctly positioned on a sandwich). This demonstrates the effectiveness of TTS in refining detailed aspects of video generation, beyond just overall visual quality.
read the caption
Figure 17: More visual results during TTS process on CogVideoX-2B. The TTS method can help to enhance multi-object spatial perception.
Full paper#