TL;DR#
Integrating geometric understanding with generative models is key for human-like AI, but it’s challenging. Existing methods struggle with real-world data and lack unified approaches for reconstruction, prediction, and planning. There is a need for more scalable and generalizable solutions that can bridge the gap between synthetic training and real-world application.
This paper introduces AETHER, a framework trained on synthetic 4D data, achieving zero-shot generalization to real-world tasks. AETHER jointly optimizes 4D reconstruction, action-conditioned prediction, and visual planning. A robust pipeline annotates synthetic data. This enables accuracy comparable to SOTA while enabling planning.
Key Takeaways#
Why does it matter?#
AETHER’s synthetic data approach offers a scalable solution to bridge the gap between geometric reasoning and generative modeling, enabling robust zero-shot transfer to real-world tasks. This can inspire new research in physically-plausible world modeling for AI systems.
Visual Insights#

🔼 Figure 1 provides a visual overview of the Aether model, showcasing its core functionalities trained exclusively on synthetic data. It demonstrates the model’s ability to perform 4D reconstruction (using data from MovieGen [48] and Veo 2 [62]), action-conditioned 4D prediction (with input from a university classroom), and goal-conditioned visual planning (with data from an office environment). Notably, these capabilities are shown applied to real-world data never seen during the training process, highlighting the model’s impressive generalization abilities. The image is best viewed at a larger scale for better detail.
read the caption
Figure 1: An overview of Aether, trained entirely on synthetic data. The figure highlights its three key capabilities: 4D reconstruction, action-conditioned 4D prediction, and visual planning, all demonstrated on unseen real-world data. The 4D reconstruction examples are derived from MovieGen [48] and Veo 2 [62] generated videos, while the action-conditioned prediction uses an observation image from a university classroom. The visual planning example utilizes observation and goal images from an office building. Better viewed when zoomed in. Additional visualizations can be found in our website.
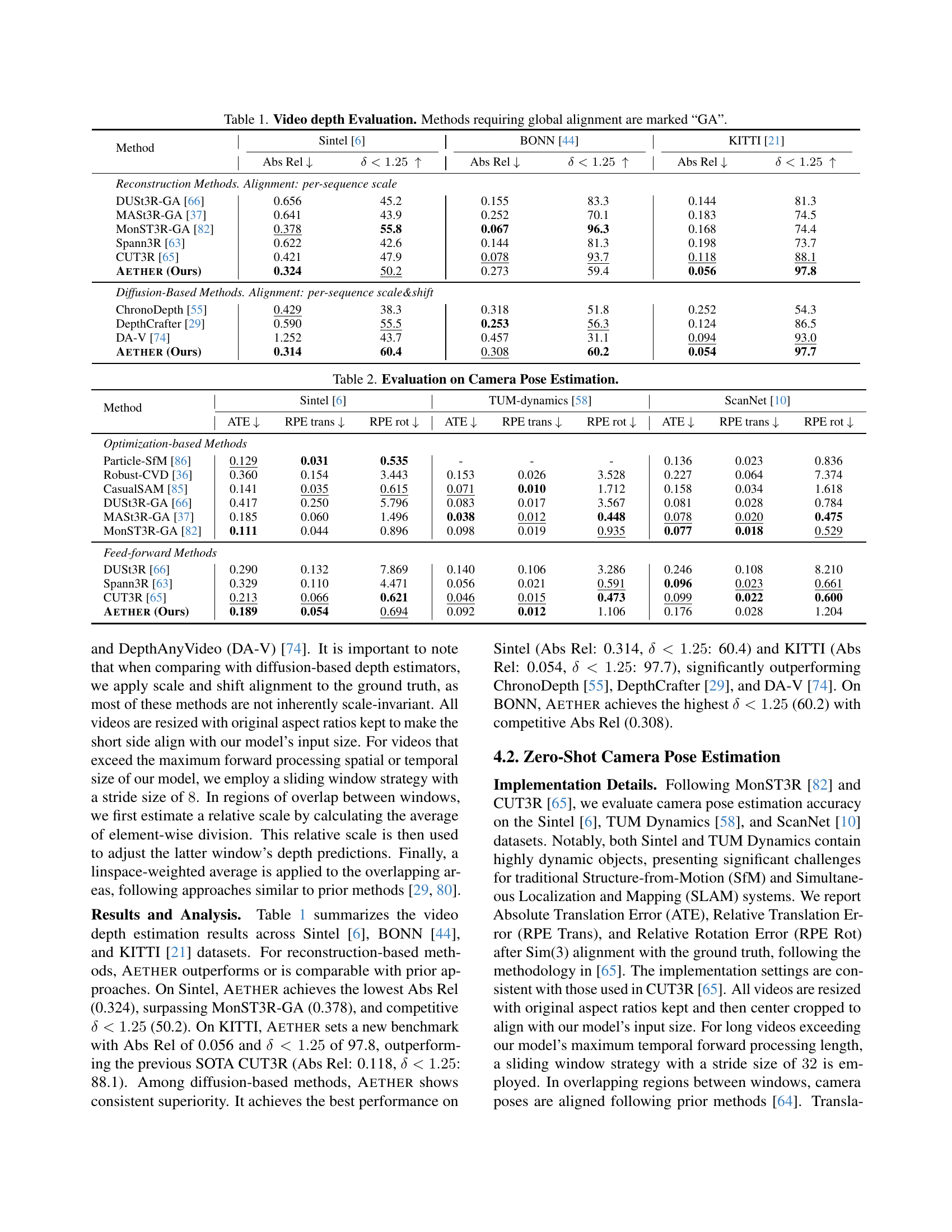
| Method | Sintel [6] | BONN [44] | KITTI [21] | |||
|---|---|---|---|---|---|---|
| Abs Rel | Abs Rel | Abs Rel | ||||
| Reconstruction Methods. Alignment: per-sequence scale | ||||||
| DUSt3R-GA [66] | 0.656 | 45.2 | 0.155 | 83.3 | 0.144 | 81.3 |
| MASt3R-GA [37] | 0.641 | 43.9 | 0.252 | 70.1 | 0.183 | 74.5 |
| MonST3R-GA [82] | 0.378 | 55.8 | 0.067 | 96.3 | 0.168 | 74.4 |
| Spann3R [63] | 0.622 | 42.6 | 0.144 | 81.3 | 0.198 | 73.7 |
| CUT3R [65] | 0.421 | 47.9 | 0.078 | 93.7 | 0.118 | 88.1 |
| Aether (Ours) | 0.324 | 50.2 | 0.273 | 59.4 | 0.056 | 97.8 |
| Diffusion-Based Methods. Alignment: per-sequence scale&shift | ||||||
| ChronoDepth [55] | 0.429 | 38.3 | 0.318 | 51.8 | 0.252 | 54.3 |
| DepthCrafter [29] | 0.590 | 55.5 | 0.253 | 56.3 | 0.124 | 86.5 |
| DA-V [74] | 1.252 | 43.7 | 0.457 | 31.1 | 0.094 | 93.0 |
| Aether (Ours) | 0.314 | 60.4 | 0.308 | 60.2 | 0.054 | 97.7 |
🔼 Table 1 presents a quantitative evaluation of video depth estimation methods. The table compares several reconstruction-based and diffusion-based methods on three benchmark datasets (Sintel, BONN, and KITTI). Performance is measured using two key metrics: Absolute Relative Error (Abs Rel), which quantifies the average difference between predicted and ground truth depths, and the percentage of predicted depths within a 1.25 factor of the ground truth depths (δ < 1.25). Methods marked with ‘GA’ require global alignment, indicating an additional processing step to align the predicted depths with the ground truth. The table showcases the performance of AETHER in comparison to other state-of-the-art methods.
read the caption
Table 1: Video depth Evaluation. Methods requiring global alignment are marked “GA”.
In-depth insights#
Geometric-Aware#
Geometric-awareness in AI signifies endowing models with an understanding of spatial relationships, shapes, and structures. This is crucial for tasks requiring spatial reasoning, like 3D reconstruction, navigation, and physical interaction. A geometrically-aware model can better interpret scenes, predict object behavior, and plan actions within an environment. This understanding can be achieved through various techniques, including incorporating geometric priors into the model architecture, training on data with explicit geometric annotations (e.g., depth maps, camera poses), and using losses that encourage geometric consistency. The benefit is improved generalization, robustness to noise, and the ability to handle novel viewpoints and object configurations. Over all its about representing and processing spatial information effectively which is a corner stone for the development of intelligent systems that can seamlessly interact with world.
Synthetic 4D Data#
Synthetic 4D data is a crucial element for training models that aim to understand and interact with the world. The lack of real-world 4D datasets, which capture dynamic 3D scenes over time, makes synthetic data a valuable substitute. High-quality synthetic data allows researchers to generate precisely annotated sequences, providing ground truth information for depth, segmentation, and object tracking. Furthermore, using synthetic environments enables the creation of diverse scenarios and the precise control over scene properties such as lighting and camera movement. The synthetic data generation also facilitates generating corner cases and failures which enhances the robustness of the trained model. However, the domain gap between synthetic and real-world data remains a challenge, necessitating techniques such as domain adaptation and data augmentation to bridge this gap and ensure effective model generalization. Synthetic data provides means to develop and evaluate novel algorithms and techniques.
Zero-Shot Transfer#
Zero-shot transfer is a compelling area in machine learning, aiming to apply a model trained on one dataset to a completely unseen target domain without any further training. This ability is particularly valuable when target domain data is scarce or expensive to acquire. Effective zero-shot transfer often hinges on shared underlying structures or representations between the source and target domains. For instance, if a model learns robust geometric principles from synthetic data, it might generalize surprisingly well to real-world images despite the visual differences. Success depends on several factors, including the similarity of feature distributions, the robustness of the learned representations, and the absence of negative transfer, where knowledge from the source domain actually hinders performance in the target domain. Geometric awareness and robust, disentangled representations are key.
Multi-Task Synergy#
Multi-task synergy, in the context of AI models, suggests a mutually beneficial relationship where training a model on multiple tasks simultaneously improves performance on each individual task. This occurs through shared learning of underlying representations and features that are relevant across tasks, leading to better generalization and efficiency. A key benefit is improved generalization, allowing models to perform better on unseen data or novel situations. Further, multi-task learning can act as a form of regularization, preventing overfitting by constraining the model to learn more robust and general features. Successfully implementing requires careful selection of tasks that complement each other, as well as balancing the influence of each task during training to prevent negative transfer, where one task hinders performance on another. The end result is a world model that is more capable and robust.
Actionable World#
The concept of an “Actionable World” signifies a paradigm shift in AI, moving beyond passive observation to active engagement with the environment. This involves endowing AI agents with the capacity to not only perceive and understand their surroundings but also to reason about actions, predict their consequences, and strategically plan to achieve specific goals. Key to this is the development of world models that incorporate both geometric and semantic understanding, allowing agents to simulate the effects of their actions in a virtual environment before executing them in the real world. The ability to learn from interaction and adapt to changing circumstances is also crucial. This entails designing AI systems that can refine their understanding of the world based on the feedback they receive from their actions, continuously improving their ability to predict and control their environment. Furthermore, an actionable world requires AI agents to have access to a repertoire of actions, ranging from simple motor commands to high-level strategic decisions. These actions must be grounded in the agent’s perception of the world and aligned with its goals. The ultimate aim is to create AI systems that can seamlessly navigate and manipulate their environment, solving complex problems and achieving ambitious objectives in a safe and reliable manner. This necessitates addressing challenges related to uncertainty, robustness, and scalability, ensuring that AI agents can operate effectively in a wide range of real-world scenarios.
More visual insights#
More on figures

🔼 Figure 2 presents visualization results from the automatic camera annotation pipeline. The pipeline processes synthetic RGB-D videos to generate accurate camera pose annotations. The images show examples of various scenes (indoor/outdoor, static/dynamic) and demonstrate the pipeline’s ability to accurately annotate camera parameters and dynamic masks, even in challenging conditions. Zooming in is recommended for a clearer view of the details.
read the caption
Figure 2: Some visualization results of data annotated through our pipeline. Better viewed when zoomed in.

🔼 This figure illustrates the four-stage pipeline used for automatically annotating camera parameters (both intrinsic and extrinsic) from synthetic RGB-D videos. Stage 1, Object-Level Dynamic Masking, utilizes semantic segmentation to identify and separate dynamic regions from static ones, crucial for accurate camera estimation. This is followed by Video Slicing (Stage 2), which segments long videos into shorter, temporally consistent clips to improve efficiency and robustness. Stage 3, Coarse Camera Estimation, employs DroidCalib to provide an initial estimation of camera parameters. Finally, Stage 4, Tracking-Based Camera Refinement with Bundle Adjustment, refines the initial estimate using CoTracker3 for long-term correspondence and bundle adjustment techniques to minimize reprojection errors. The resulting output is a fully annotated dataset with precise camera parameters for each frame.
read the caption
Figure 3: Our robust automatic camera annotation pipeline.
More on tables
| Method | Sintel [6] | TUM-dynamics [58] | ScanNet [10] | ||||||
|---|---|---|---|---|---|---|---|---|---|
| ATE | RPE trans | RPE rot | ATE | RPE trans | RPE rot | ATE | RPE trans | RPE rot | |
| Optimization-based Methods | |||||||||
| Particle-SfM [86] | 0.129 | 0.031 | 0.535 | - | - | - | 0.136 | 0.023 | 0.836 |
| Robust-CVD [36] | 0.360 | 0.154 | 3.443 | 0.153 | 0.026 | 3.528 | 0.227 | 0.064 | 7.374 |
| CasualSAM [85] | 0.141 | 0.035 | 0.615 | 0.071 | 0.010 | 1.712 | 0.158 | 0.034 | 1.618 |
| DUSt3R-GA [66] | 0.417 | 0.250 | 5.796 | 0.083 | 0.017 | 3.567 | 0.081 | 0.028 | 0.784 |
| MASt3R-GA [37] | 0.185 | 0.060 | 1.496 | 0.038 | 0.012 | 0.448 | 0.078 | 0.020 | 0.475 |
| MonST3R-GA [82] | 0.111 | 0.044 | 0.896 | 0.098 | 0.019 | 0.935 | 0.077 | 0.018 | 0.529 |
| Feed-forward Methods | |||||||||
| DUSt3R [66] | 0.290 | 0.132 | 7.869 | 0.140 | 0.106 | 3.286 | 0.246 | 0.108 | 8.210 |
| Spann3R [63] | 0.329 | 0.110 | 4.471 | 0.056 | 0.021 | 0.591 | 0.096 | 0.023 | 0.661 |
| CUT3R [65] | 0.213 | 0.066 | 0.621 | 0.046 | 0.015 | 0.473 | 0.099 | 0.022 | 0.600 |
| Aether (Ours) | 0.189 | 0.054 | 0.694 | 0.092 | 0.012 | 1.106 | 0.176 | 0.028 | 1.204 |
🔼 This table presents a quantitative evaluation of camera pose estimation methods across three datasets: Sintel, TUM-dynamics, and ScanNet. The datasets vary in terms of scene dynamics and complexity, providing a comprehensive assessment. For each dataset, the table displays several key metrics including Absolute Translation Error (ATE), which measures the overall accuracy of camera position estimation; and Relative Pose Errors (RPE), both translational (RPE trans) and rotational (RPE rot), reflecting the consistency of pose estimation over time. The results allow for a comparison of different methods’ performance in different scenarios.
read the caption
Table 2: Evaluation on Camera Pose Estimation.
| subject consistency | b.g. consistency | motion smoothness | dynamic degree | aesthetic quality | imaging quality | weighted average | |
| CogVideoX | 89.36/84.61/87.77 | 92.72/91.43/92.29 | 98.24/96.93/97.81 | 88.75/95.00/90.83 | 54.49/53.58/54.18 | 55.38/52.29/54.35 | 79.01/77.52/78.51 |
| Aether | 91.50/87.55/90.18 | 94.29/93.62/94.07 | 98.54/98.19/98.42 | 96.25/100.00/97.50 | 54.36/52.58/53.77 | 55.08/54.88/55.01 | 80.34/79.42/80.04 |
🔼 This table presents a comparison of video prediction performance between two models, CogVideoX and Aether, evaluated using VBench metrics. The comparison considers three scenarios: in-domain, out-domain, and overall performance, reflecting the models’ ability to generalize to unseen data. VBench assesses multiple aspects of video quality, including subject consistency, background consistency, motion smoothness, dynamic degree, aesthetic quality, and imaging quality. The best performance for each metric in each scenario is highlighted in bold.
read the caption
Table 3: VBench [30] Metrics of Video Prediction without Action Conditions. Comparison between CogVideoX and Aether (Ours) on in-domain/out-domain/overall performance on the validation set. For each group, the better performance is highlighted in bold.
| subject consistency | b.g. consistency | motion smoothness | dynamic degree | aesthetic quality | imaging quality | weighted average | |
|---|---|---|---|---|---|---|---|
| CogVideoX | 91.56/88.23/90.51 | 92.98/92.29/92.77 | 98.44/97.81/98.24 | 83.87/93.02/86.76 | 56.19/57.43/56.58 | 56.48/61.60/58.10 | 79.56/80.70/79.92 |
| Aether | 90.73/93.27/91.54 | 93.61/95.03/94.06 | 98.53/98.62/98.56 | 100.00/83.72/94.85 | 55.04/56.50/55.50 | 53.89/63.23/56.84 | 80.33/81.55/80.71 |
🔼 This table presents a quantitative comparison of action-conditioned video prediction performance between the CogVideoX model and the Aether model. The comparison is conducted across six key metrics from the VBench evaluation protocol: subject consistency, background consistency, motion smoothness, dynamic degree, aesthetic quality, and imaging quality. Results are shown for both in-domain and out-domain validation sets, and an overall average. The metrics assess various aspects of the generated videos, including the consistency of subjects and background elements, the smoothness and naturalness of motion, the level of dynamic activity, and the overall visual and aesthetic quality. The table highlights the better performance (CogVideoX or Aether) for each metric in bold font. This allows for a comprehensive evaluation of the two models’ performance on this specific video generation task.
read the caption
Table 4: VBench [30] Metrics of Action-Conditioned Video Prediction. Comparison between CogVideoX and Aether (Ours) on in-domain/out-domain/overall performance on the validation set. For each metric group, the better performance is highlighted in bold.
| PSNR | SSIM | MS-SSIM | LPIPS | |
| Aether-no-depth | 19.13/18.67/18.97 | 0.5630/0.4830/0.5353 | 0.5467/0.5204/0.5376 | 0.3116/0.2995/0.3074 |
| Aether | 19.87/19.37/19.70 | 0.5803/0.5058/0.5545 | 0.5830/0.5627/0.5760 | 0.2691/0.2599/0.2659 |
🔼 This table presents a comparison of the performance of two models, Aether and Aether-no-depth, on the task of action-conditioned navigation. The comparison is broken down by three categories: in-domain performance (data similar to the training data), out-of-domain performance (data different from the training data), and overall performance across both domains. Pixel-wise metrics (PSNR, SSIM, MS-SSIM, and LPIPS) are used to evaluate the quality of the generated navigation videos. The best performing model in each category is highlighted in bold.
read the caption
Table 5: Pixel-wise Metrics of Action-Conditioned Navigation. Comparison of performance between Aether-no-depth and Aether on in-domain/out-domain/overall performance. For each metric group, the better performance is highlighted in bold.
| subject consistency | b.g. consistency | motion smoothness | dynamic degree | aesthetic quality | imaging quality | weighted average | |
| Aether-no-depth | 88.68/89.61/88.61 | 93.62/93.92/93.66 | 98.37/98.31/98.32 | 97.06/91.67/96.15 | 54.12/56.26/54.78 | 51.77/58.46/54.29 | 79.11/80.43/79.59 |
| Aether (Ours) | 89.69/91.61/90.36 | 93.88/94.58/94.13 | 98.50/98.40/98.46 | 97.06/91.67/95.19 | 55.83/56.87/56.19 | 54.71/61.13/56.93 | 80.21/81.53/80.67 |
🔼 This table presents a quantitative comparison of the performance of two models, Aether and Aether-no-depth, on the task of action-free visual path planning. The models are evaluated across several metrics, including subject consistency, background consistency, motion smoothness, dynamic degree, aesthetic quality, and imaging quality, both for in-domain and out-of-domain data, as well as overall performance. The metrics assess the quality of the generated video sequences, focusing on the coherence of the subjects and background, smoothness of motion, level of dynamism, visual appeal, and technical aspects of the image quality. The best performing model for each metric is highlighted in bold, enabling easy identification of superior performance.
read the caption
Table 6: Quantitative Results of Action-Free Visual Path Planning. Comparison of performance between Aether and Aether-no-depth on in-domain/out-domain/overall performance. For each metric group, the better performance is highlighted in bold.
Full paper#