TL;DR#
Flow models are powerful for generative tasks but lack the inference-time scaling capabilities of diffusion models, which leverage stochasticity for better reward alignment. This paper addresses this gap by proposing a novel approach to scale flow models effectively. Traditional flow models rely on deterministic processes, limiting their ability to incorporate particle sampling, a key technique for enhancing sample quality during inference. This limitation hinders their ability to effectively align outputs with user preferences or other reward signals, making them less adaptable compared to diffusion models in certain applications.
To solve this, the paper introduces three key innovations: (1) SDE-based generation to enable particle sampling in flow models, (2) Interpolant conversion, using Variance Preserving (VP) to broaden the search space and enhance sample diversity, and (3) Rollover Budget Forcing (RBF), which adaptively allocates computational resources across timesteps to maximize budget utilization. Results show SDE-based generation and VP interpolant improve particle sampling in flow models. Furthermore, RBF with VP-SDE achieves the best performance, outperforming previous inference-time scaling approaches, and better align images with complex user prompts.
Key Takeaways#
Why does it matter?#
This paper introduces a novel inference-time scaling method for flow models, enhancing their ability to align with user preferences and compositional structures. This work paves the way for future research in leveraging flow models for complex text-to-image generation tasks.
Visual Insights#

🔼 Figure 1 demonstrates the versatility of the proposed inference-time scaling method applied to a pretrained flow model. The top row showcases how increased computational resources during inference (measured by Number of Function Evaluations, NFEs) lead to improved image generation more closely matching user preferences, as quantified by a reduction in Residual Sum of Squares (RSS). The top-right panel highlights the superiority of the flow-based approach over diffusion models, achieving comparable results with significantly fewer NFEs. The remaining panels illustrate applications to diverse tasks: compositional text-to-image generation (using VQAScore for reward), counting (using object detection scores), aesthetic image generation (using aesthetic scores), and concept erasure (using VLM to quantify removed concepts). The red boxes indicate results produced using the novel method.
read the caption
Figure 1: Diverse applications of our inference-time scaling method. Our inference-time scaling method extends the capabilities of a pretrained flow model [25] to generate images that more precisely align with user preferences. More computation during inference improves alignment, reducing Residual Sum of Squares (RSS) over time (top row). Our flow-based method outperforms diffusion models, even with five times fewer number of function evaluations (NFEs) (top-right). For compositional text-to-image generation applications (“logical”, “comparison”, “spatial relation”), we use the reward from VQAScore [28] to ensure precise alignment with the input text, where the description is particularly challenging for typical text-to-image generative models to satisfy (see the results on the left side of each case). We use the object detection score [31] for the 'counting' application and the aesthetic score [44] for the 'aesthetic' application. For “concept erasure”, the reward is the number of removed concepts computed using VLM [3] queries. The red box denotes the results of our method.
 |  |  |
| (a) Linear-ODE | (b) Linear-SDE | (c) VP-SDE |
🔼 Table 1 presents a quantitative comparison of different inference-time scaling methods for compositional image generation. It shows the performance using various metrics (VQAScore, InstructBLIP, and aesthetic score) for different methods: Linear-ODE (baseline), Linear-SDE, and VP-SDE (the proposed approach). Improvements for particle-based sampling methods are calculated relative to the Linear-ODE baseline. The best and second-best results for each reward (given and held-out) are highlighted in bold and underlined, respectively. Results are shown for both default settings and with 50 denoising steps.
read the caption
Table 1: Quantitative results of compositional image generation. † denotes the given reward used in inference-time scaling. For particle-based sampling methods, the relative improvement in each cell is computed with respect to the Linear-ODE case. The best result in the given and held-out reward is highlighted by bold, and the runner-up is underlined. L.O., L.S., and V.S. indicate Linear-ODE, Linear-SDE, and VP-SDE, respectively. * denotes results with 50505050 denoising steps.
In-depth insights#
Flow SDE Scaling#
The paper addresses the challenge of scaling flow-based generative models, which, unlike diffusion models, have a deterministic nature, hindering the direct application of particle sampling techniques for inference-time scaling. To overcome this, the authors propose converting the deterministic flow into a stochastic differential equation (SDE), enabling particle sampling. A key insight is the importance of interpolant choice; replacing the typical linear interpolant with a Variance Preserving (VP) interpolant significantly broadens the search space and enhances sample diversity, leading to higher-reward samples. This conversion and interpolant choice allow models better results than traditional diffusion models. The paper includes a novel strategy for Rollover Budget Forcing (RBF), that adaptively allocates computational resources across timesteps, maximizing budget utilization and further improving performance. Experiments demonstrate the effectiveness of the approach across tasks like compositional text-to-image generation and quantity-aware image generation.
VP Trajectory++#
While ‘VP Trajectory++’ isn’t explicitly present, we can infer its essence from the context of flow models and diffusion model alignment. It likely refers to enhancing the Variance Preserving (VP) trajectory used in diffusion models, perhaps moving beyond standard VP SDEs. The ‘++’ suggests further improvements. This could involve adaptive trajectory shaping during inference, dynamically adjusting the noise schedule or interpolant based on reward signals. Perhaps the approach further increases sample diversity by modifying velocity fields or by adjusting timestep size to better fit with the few-step generation abilities. Ultimately, the aim would be to guide the flow model’s trajectory towards higher-reward regions more efficiently than existing inference-time scaling methods.
Rollover Forcing#
Rollover Budget Forcing (RBF) is presented as an adaptive strategy for distributing a computational budget across timesteps during inference. It addresses the inefficiency of uniformly allocating resources, recognizing that the effort to find better samples varies. RBF dynamically reallocates resources; if a higher-rewarding particle is found, remaining resources are used. Otherwise, the method proceeds using existing methods, selecting the particle with the best expected future reward. RBF improves performance, as demonstrated in experiments, showing gains and exceeding prior methods. The adaptive nature ensures resources are concentrated where they provide the most benefit during the search for superior results. The pseudocode shows RBF’s effectiveness when added with conversion and interpolant.
Comp. Generation#
In compositional generation, the paper addresses the challenge of creating images that accurately reflect complex text descriptions, focusing on attributes, relationships, and object quantities. The primary goal is to enhance alignment between the generated image and the user’s textual input. The paper uses metrics such as VQAScore to measure this alignment, indicating the probability that a given attribute or object is present in the generated image. A key finding is that flow models, enhanced with SDE conversion and interpolant conversion, significantly improve performance on compositional tasks. The use of a Variance Preserving (VP) interpolant, rather than a linear one, expands the search space and facilitates the discovery of high-reward samples that better match the text description. The qualitative results demonstrate that these techniques enable the generation of more faithful and accurate images, capturing intricate details and relationships specified in the text prompt. The work highlights the importance of modifying the generative process to improve alignment with user preferences.
Quant. Control#
In research concerning “Quantitative Control,” one might expect investigations into methods that precisely regulate generated content according to numerical constraints. This could involve scenarios where the objective is to accurately render specific quantities of objects within an image, aligning visual outputs with precise numerical targets. The work would probably leverage object detection to first establish how many objects are already present, and then modify generation to reach the target count. Moreover, novel loss functions might be used that strictly penalize deviations from requested object counts, driving the generative model to adhere to strict numerical benchmarks. Also the researchers might investigate the performance of diffrent existing model to effectively use for image manipulation by adding or removing objects and also compare these models against the custom models by ablative studies to confirm performance.
More visual insights#
More on tables
| L.O. | L.S. | V.S. |
| “A mouse pad has two pencils on it, the shorter pencil is green and the longer one is not” | ||
 |  |  |
| “Eight chairs” | ||
 |  |  |
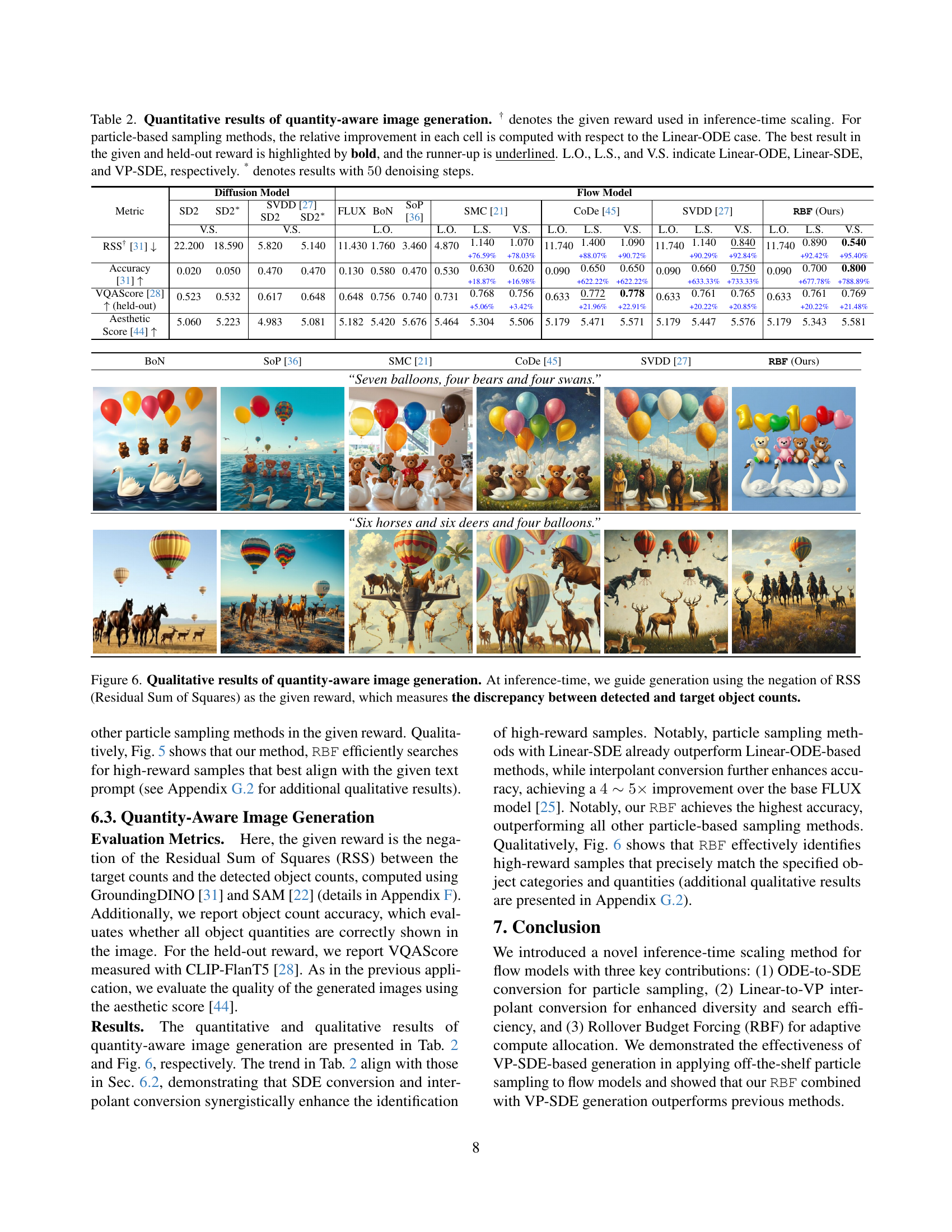
🔼 Table 2 presents a quantitative comparison of different inference-time scaling methods for quantity-aware image generation. The key metrics evaluated are Residual Sum of Squares (RSS), accuracy, held-out VQAScore, and aesthetic score. The table shows results for several baselines (BoN, SoP, SMC, CoDe, SVDD) and the proposed RBF method, all applied to the FLUX flow model. The performance of each method is analyzed under various conditions (Linear-ODE, Linear-SDE, and VP-SDE) and with different numbers of denoising steps. Relative improvements are calculated concerning the Linear-ODE baseline for particle-based methods. The best and second-best results for each metric are highlighted in bold and underlined, respectively.
read the caption
Table 2: Quantitative results of quantity-aware image generation. † denotes the given reward used in inference-time scaling. For particle-based sampling methods, the relative improvement in each cell is computed with respect to the Linear-ODE case. The best result in the given and held-out reward is highlighted by bold, and the runner-up is underlined. L.O., L.S., and V.S. indicate Linear-ODE, Linear-SDE, and VP-SDE, respectively. * denotes results with 50505050 denoising steps.
| Metric | Diffusion Model | Flow Model | |||||||||||||||||
| SD2 | SVDD [27] | FLUX | BoN | SoP [36] | SMC [21] | CoDe [45] | SVDD [27] | RBF (Ours) | |||||||||||
| SD2 | SD2∗ | ||||||||||||||||||
| V.S. | V.S. | L.O. | L.O. | L.S. | V.S. | L.O. | L.S. | V.S. | L.O. | L.S. | V.S. | L.O. | L.S. | V.S. | |||||
| VQAScore† [28] | 0.671 | 0.647 | 0.867 | 0.886 | 0.726 | 0.879 | 0.844 | 0.841 | 0.862 +2.50% | 0.877 +4.28% | 0.788 | 0.887 +12.56% | 0.914 +15.99% | 0.788 | 0.893 +13.32% | 0.915 +16.12% | 0.788 | 0.900 +14.21% | 0.925 +17.39% |
| Inst. BLIP [10] (held-out) | 0.741 | 0.739 | 0.790 | 0.799 | 0.775 | 0.820 | 0.799 | 0.815 | 0.811 –0.49% | 0.836 +2.58% | 0.786 | 0.815 +3.69% | 0.839 +6.74% | 0.789 | 0.813 +3.04% | 0.847 +7.35% | 0.789 | 0.813 +3.04% | 0.843 +6.84% |
| Aesthetic Score [44] | 5.107 | 5.115 | 5.181 | 5.213 | 5.338 | 5.162 | 5.254 | 5.233 | 5.016 | 5.156 | 5.190 | 5.023 | 5.177 | 5.200 | 5.052 | 5.249 | 5.200 | 5.072 | 5.237 |
🔼 This table presents a quantitative comparison of different inference-time scaling methods on the task of aesthetic image generation. The methods are evaluated based on two metrics: the aesthetic score (a measure of image quality) and the ImageReward score (a held-out reward that assesses alignment with user preferences). The table shows the performance of four methods: a baseline method (FLUX), a gradient-based method (DPS), a particle sampling method (SVDD), and the proposed Rollover Budget Forcing method (RBF). Each method’s performance is reported in terms of absolute score and relative improvement compared to the baseline method. The best-performing method for each metric is highlighted in bold.
read the caption
Table 3: Quantitative results of aesthetic image generation. † denotes the given reward used in inference time. The relative improvement in each cell is computed with respect to the base model. The best result in each row is highlighted in bold.
| BoN | SoP [36] | SMC [21] | CoDe [45] | SVDD [27] | RBF (Ours) |
| “Three mugs are placed side by side; the two closest to the faucet each contain a toothbrush, while the one furthest away is empty.” | |||||
 |  |  |  |  |  |
| “Five ants are carrying biscuits, and an ant that is not carrying biscuits is standing on a green leaf directing them.” | |||||
 |  |  |  |  |  |
🔼 Table 4 presents a quantitative analysis of quantity-aware image generation. It compares different inference-time scaling methods using varying numbers of function evaluations (NFEs). The experiment uses 100 prompts from the T2I-CompBench dataset [18] for quantity-aware image generation. The table shows the performance (measured by RSS, accuracy, VQAScore [28], and aesthetic score [44]) achieved by each method across different NFEs. The ‘†’ symbol indicates the reward metric used for each method during inference.
read the caption
Table 4: Quantitative results of quantity-aware image generation in NFE scaling expriment. We use the same 100100100100 prompts from T2I-CompBench [18] as in the quantity-aware image generation task. † denotes the given reward used in the inference-time.
Full paper#