TL;DR#
Video diffusion models have shown great progress in video generation, but they are slow because they need many steps to remove noise. Existing methods to speed up this process have problems with mismatching data and unreliable guidance. Therefore, this paper proposes AccVideo to solve this problem.
AccVideo reduces the inference steps by using a synthetic dataset and trajectory-based learning. The method includes SynVid, a synthetic dataset with 110K denoising trajectories, and a trajectory-based approach that selects key data points. AccVideo also uses adversarial training to enhance video quality, achieving an 8.5x speed improvement while maintaining comparable video quality and enabling higher resolutions.
Key Takeaways#
Why does it matter?#
This paper is important for researchers as it introduces an innovative method to accelerate video diffusion models, which are essential for many applications. By addressing the limitations of current distillation methods and providing a new dataset, this work opens new avenues for creating high-quality videos with greater efficiency.
Visual Insights#

🔼 This figure demonstrates the speed improvement achieved by the proposed AccVideo method. HunyuanVideo, a state-of-the-art video diffusion model, takes a considerable amount of time (3234 seconds) to generate a short (5-second), high-resolution (720x1280) video. AccVideo, using a knowledge distillation approach, significantly reduces the generation time, achieving an 8.5x speedup while maintaining comparable video quality. The figure visually compares the generation time difference with side-by-side video examples.
read the caption
Figure 1: Video diffusion models can generate high-quality videos, but they require dozens of inference steps, resulting in slow generation process. For instance, HunyuanVideo [23] takes 3234 seconds to generate a 5-seconds, 720×\times×1280, 24fps video on a single A100 GPU. In contrast, our method accelerates video diffusion models through distillation, achieving 8.5×\times× improvements in generation speed while maintaining comparable quality.
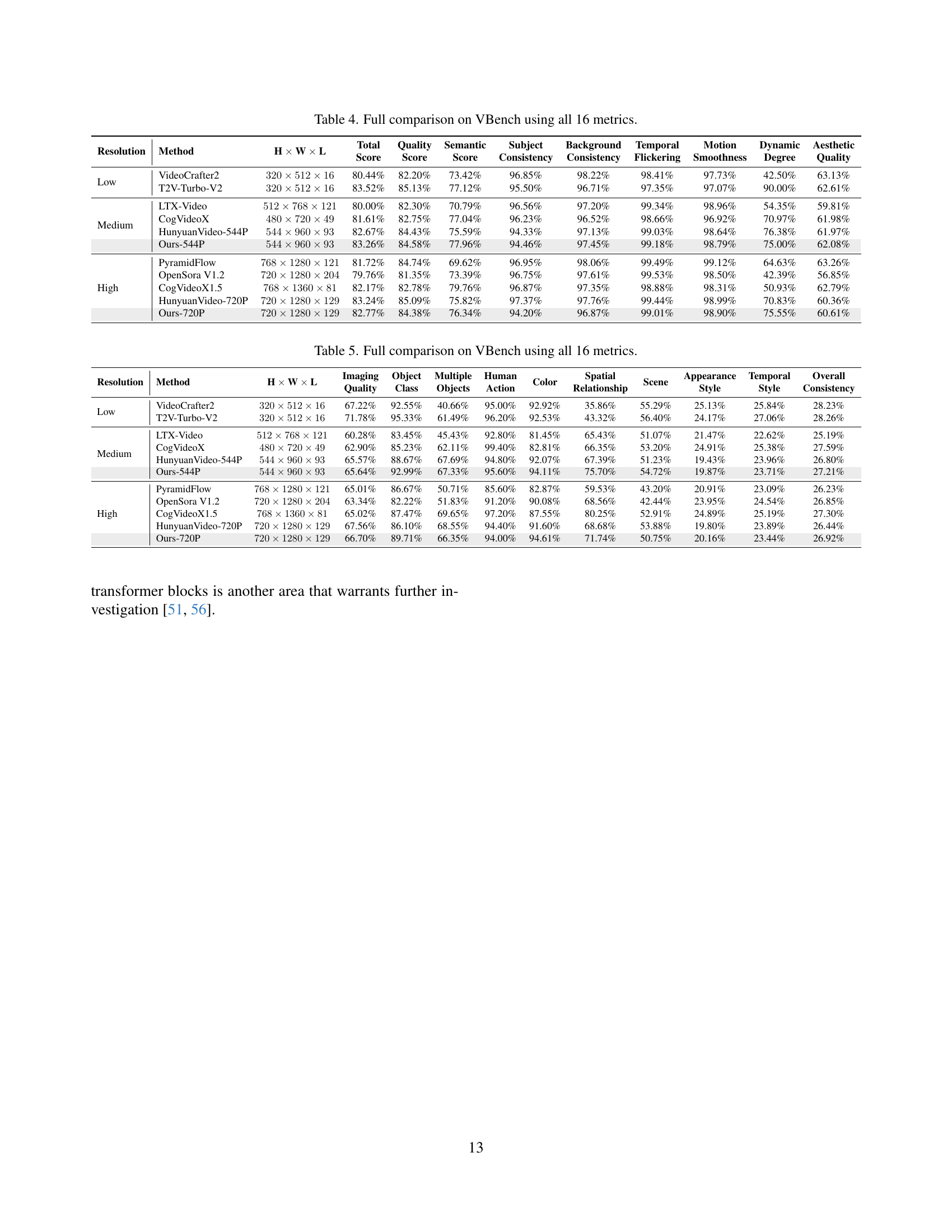
| Resolution | Method | Inference Time (s) | |
| Medium | CogVideoX-5B | 219 | |
| HunyuanVideo-544P | 704 | ||
| Ours-544P | 91 | ||
| High | CogVideoX1.5-5B | 926 | |
| HunyuanVideo-720P | 3234 | ||
| Ours-720P | 380 |
🔼 This table compares the inference time for generating videos across different models using a single NVIDIA A100 GPU. The inference time includes the time taken for text encoding (processing the text prompt), VAE decoding (converting the latent representation back to a video), and the diffusion process (generating the video frames from noise). The models are compared at different resolutions (medium and high), providing a comprehensive overview of their computational efficiency.
read the caption
Table 1: Comparison of inference time. Here, we use a single A100 GPU to measure the time required for generating a video, which includes text encoding, VAE decoding, and diffusion time.
In-depth insights#
AccVideo Intro#
The introduction to AccVideo likely addresses the increasing prominence of video generation alongside its computational demands. Diffusion models, while powerful for video creation, are iterative and require numerous steps, leading to slow generation speeds. AccVideo likely positions itself as a solution to this inefficiency, potentially by reducing the required inference steps. This involves a focus on novel distillation methods or synthetic datasets to train student models, accelerating the generation process while maintaining quality. The intro probably outlines the paper’s core contributions: a novel method, analysis of challenges in diffusion distillation, and high-quality video generation with higher resolution.
Dataset Distills#
Dataset distillation is a technique that aims to create a smaller, more manageable dataset from a larger one, while still retaining most of the original dataset’s information and performance. The core idea is to identify the most important or representative samples in the original dataset and use them to train a model that performs similarly to a model trained on the full dataset. This can be achieved through various methods, such as selecting diverse samples, identifying key data points, or generating synthetic data. The main benefits of dataset distillation are reduced training time, lower memory requirements, and improved generalization performance. However, it’s important to note that the effectiveness of dataset distillation depends heavily on the quality of the distillation method and the characteristics of the original dataset. If the distilled dataset does not accurately represent the original dataset, the model trained on the distilled dataset may perform poorly.
Few-Step Guidance#
The paper introduces a novel approach to accelerate video diffusion models called AccVideo, focusing on synthetic data to improve efficiency. A key aspect is the trajectory-based few-step guidance, which selects crucial data points from denoising trajectories, constructing a shorter noise-to-video mapping path. This allows a student model to generate videos in fewer steps, addressing the computational intensity of traditional diffusion models. By strategically picking key latents, the method aims to reduce the need for numerous inference steps, streamlining video generation. Moreover, this strategic data selection ensures that the student model receives precise guidance, enhancing training efficiency and overall video quality. It’s a contrast with existing methods that require many steps.
GAN Improves Vid#
While I can’t directly analyze a section titled “GAN Improves Vid” from the provided paper (as I don’t have real-time access to external files or the internet), I can offer some general insights about how Generative Adversarial Networks (GANs) can be leveraged to improve video processing. Specifically, GANs offer several potential benefits for tasks like video generation, super-resolution, and frame interpolation. In video generation, GANs can be trained to produce realistic and coherent video sequences from noise or textual descriptions. In super-resolution, they can hallucinate high-resolution details from low-resolution input videos, leading to improved visual quality. For frame interpolation, GANs can generate intermediate frames between existing ones, increasing the frame rate and creating smoother motion. The adversarial training process, where a generator network tries to fool a discriminator network, encourages the generator to produce more realistic and high-quality results. The use of time-aware projection heads to maintain visual quality is also key here. Overall, integrating GANs into video processing pipelines represents a powerful approach for enhancing various aspects of video quality and realism.
Future Work: VAE#
In future work, enhancing Video Diffusion Models, VAE plays a vital role in encoding/decoding videos. Further acceleration can stem from VAE improvements. Efficient VAE architecture could drastically reduce computation. DiT, containing many transformer blocks, offers another avenue.
More visual insights#
More on figures

🔼 This figure presents a 1D toy experiment to illustrate the challenges in existing diffusion distillation methods. It uses Flow Matching to train a teacher model that maps a Gaussian distribution to a data distribution with two data points. Panel (a) shows knowledge distillation, where a student model mimics the teacher’s denoising process. Panel (b) highlights issues caused by dataset or Gaussian noise mismatching, leading to unreliable guidance. Panel (c) shows distribution matching methods aiming to align the student’s and teacher’s output distributions. Panel (d) emphasizes problems with distribution matching, potentially leading to inaccurate guidance. Panel (e) shows the frequency of useless data points relative to a mismatching factor (M). Finally, panel (f) displays the distillation results for various values of M.
read the caption
Figure 2: 1D Toy Experiment. We employ Flow Matching objective [31] to train the teacher model, which learns the ODE that maps Gaussian distribution to the data distribution. The data distribution consists of two data points. a) illustrates the knowledge distillation methods, where a student model is trained to mimic the teacher model’s denoising process. b) highlights the challenges posed by dataset or Gaussian noise mismatching in knowledge distillation, which can lead to unreliable guidance. c) demonstrates the distribution matching methods, which aims to align the output distribution of the student model with that of the teacher model. d) emphasizes the issue in distribution matching, which can result in inaccurate guidance. e) illustrates the frequency of useless data points in relation to M𝑀Mitalic_M. f) shows the distillation results at various values of M𝑀Mitalic_M.

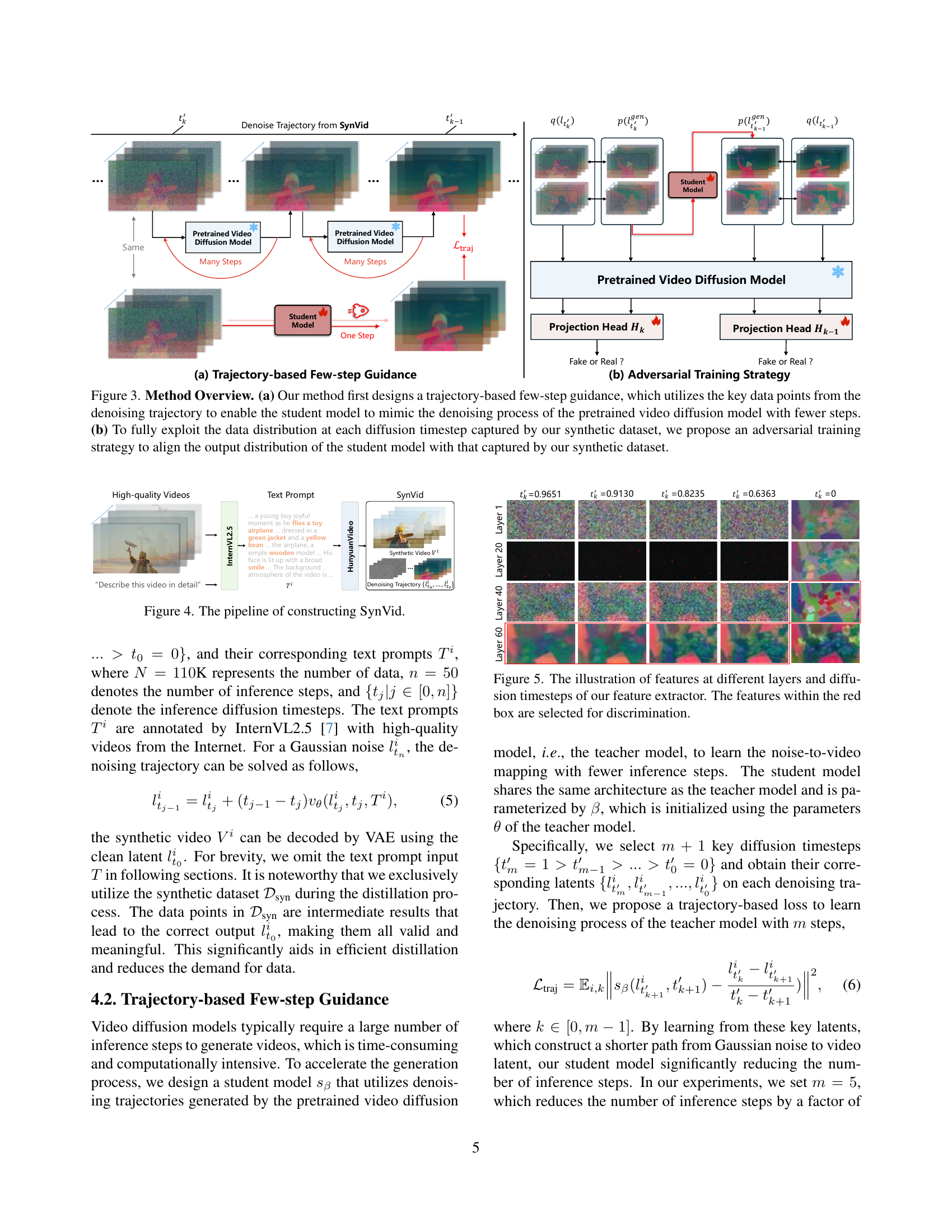
🔼 Figure 3 illustrates the key components of the proposed AccVideo method. Panel (a) shows the ’trajectory-based few-step guidance’ approach. This technique leverages key data points extracted from the denoising trajectories of a pre-trained video diffusion model to train a smaller, faster (‘student’) model. By focusing on these key points, the student model learns to effectively mimic the denoising process of the larger model, but with significantly fewer computational steps, thereby speeding up video generation. Panel (b) details the ‘adversarial training strategy’. A synthetic dataset is generated, capturing the data distribution at each step of the diffusion process. An adversarial approach is used to ensure that the output distribution of the student model closely matches that of the synthetic dataset, leading to higher-quality generated videos.
read the caption
Figure 3: Method Overview. (a) Our method first designs a trajectory-based few-step guidance, which utilizes the key data points from the denoising trajectory to enable the student model to mimic the denoising process of the pretrained video diffusion model with fewer steps. (b) To fully exploit the data distribution at each diffusion timestep captured by our synthetic dataset, we propose an adversarial training strategy to align the output distribution of the student model with that captured by our synthetic dataset.

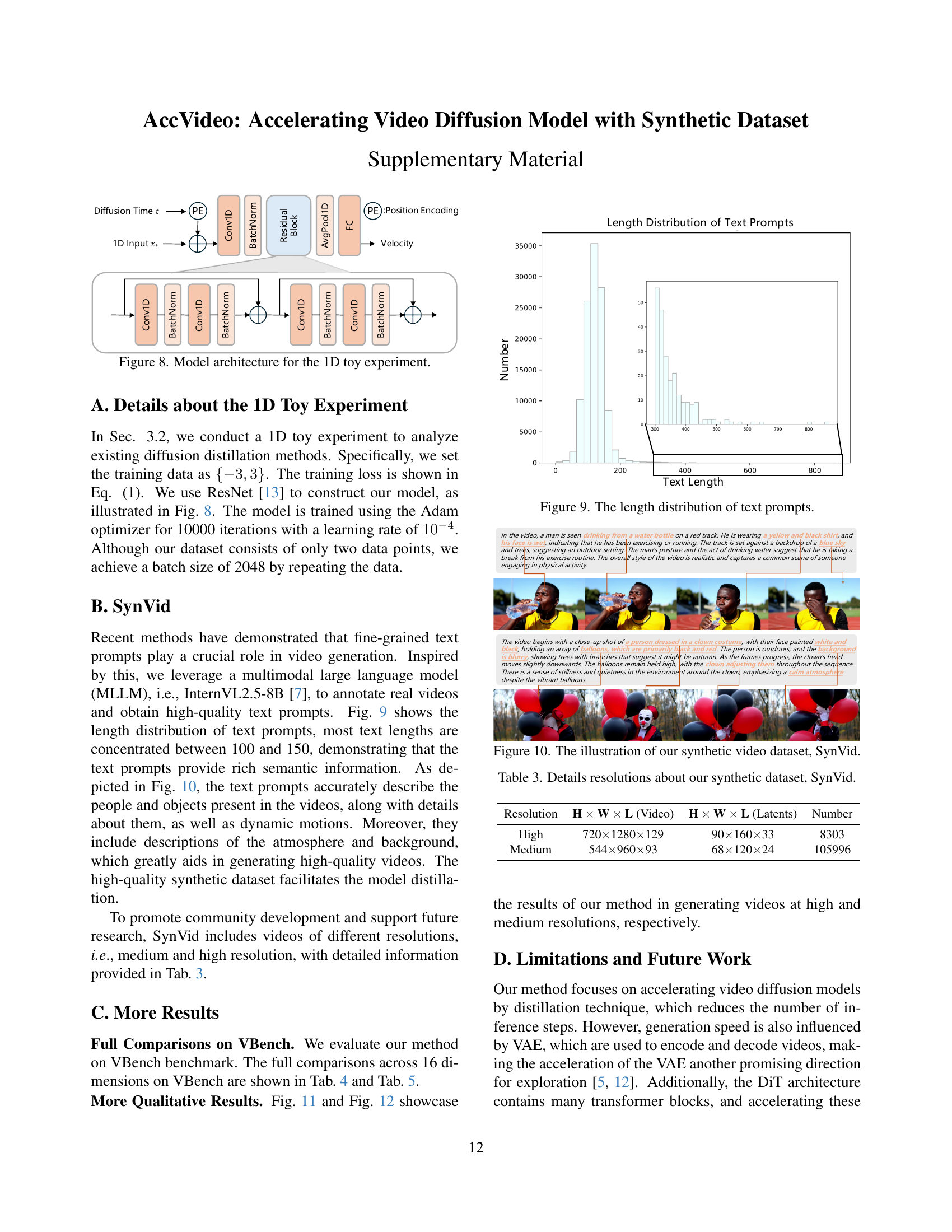
🔼 This figure illustrates the process of creating the SynVid dataset. It starts with text prompts, which are fed into the HunyuanVideo model. HunyuanVideo then generates high-quality videos. From these videos, denoising trajectories in latent space are extracted. These videos, trajectories, and their corresponding text prompts constitute the final SynVid dataset.
read the caption
Figure 4: The pipeline of constructing SynVid.

🔼 This figure shows a visualization of feature maps from different layers of the video diffusion model at various diffusion timesteps. The feature extractor processes video data, and different layers capture varying levels of detail and abstraction. Early layers might focus on low-level features like edges and textures, while deeper layers represent higher-level semantic information about the objects and scenes. The colored boxes highlight specific features within the feature maps which are later used in the adversarial training stage for discrimination between real and fake video latents.
read the caption
Figure 5: The illustration of features at different layers and diffusion timesteps of our feature extractor. The features within the red box are selected for discrimination.

🔼 This figure showcases two example videos generated by the AccVideo model. The left image depicts a girl playfully covering her mouth with her hand, showcasing the model’s ability to generate fine-grained details and realistic facial expressions. The right image shows a white vintage SUV with a black roof rack driving up a steep and winding mountain road. This example demonstrates the model’s ability to capture movement, depth, and scenic backgrounds.
read the caption
Figure 6: Qualitative results on text-to-video. Left: a girl raises her left hand to cover her smiling mouth. Right: the camera follows behind a white vintage SUV with a black roof rack as it speeds up a steep dirt road surrounded by pine trees on a steep mountain slope.

🔼 This figure presents a qualitative ablation study comparing different components of the proposed AccVideo model. It shows the results of generating a video based on the prompt: ‘a toy robot wearing purple overalls and cowboy boots taking a pleasant stroll in Johannesburg South Africa during a beautiful sunset’. Four different model variations are shown: (a) the results using only the teacher model with 5 inference steps; (b) using the teacher model with the proposed trajectory-based few-step guidance; (c) with both the trajectory-based few-step guidance and the adversarial training strategy; and (d) the final, full model incorporating all aspects of the AccVideo method. The differences highlight the effects of each component on the quality and coherence of the generated video.
read the caption
Figure 7: Qualitative ablation study results. Please zoom in for details. Prompt: a toy robot wearing purple overalls and cowboy boots taking a pleasant stroll in Johannesburg South Africa during a beautiful sunset.

🔼 This figure shows the model architecture used in the 1D toy experiment. The input is a 1D vector, representing a single data point from the simplified data distribution. This input then passes through several convolutional layers (Conv1D), each followed by batch normalization (BatchNorm). A residual block is included to improve training stability. Finally, the output is a velocity vector that represents the learned relationship between the Gaussian noise and the data point in the simplified distribution. This velocity is then used to update the model’s parameters during the training process.
read the caption
Figure 8: Model architecture for the 1D toy experiment.

🔼 This histogram illustrates the distribution of the lengths of text prompts used in the SynVid dataset. The x-axis represents the length of the text prompt (in number of words or tokens), and the y-axis represents the frequency or count of prompts with that particular length. The distribution appears to be unimodal, centered around a length of approximately 100-150 words, suggesting that most prompts are of moderate length. This information is crucial because it indicates the level of detail and specificity provided in the prompts used to generate the synthetic videos within the dataset. The use of relatively detailed descriptions in the prompts allows the model to learn detailed relationships between video content and natural language descriptions.
read the caption
Figure 9: The length distribution of text prompts.

🔼 Figure 10 presents two example video clips from the SynVid dataset. The SynVid dataset is a synthetic dataset generated by the HunyuanVideo model, containing high-quality videos paired with fine-grained text prompts. The examples demonstrate the quality of the videos generated by the model and the diversity of the scenes they encompass. These examples highlight the success of leveraging the pretrained model to create a synthetic dataset that faithfully captures the data distribution needed for distillation.
read the caption
Figure 10: The illustration of our synthetic video dataset, SynVid.

🔼 This figure showcases several example videos generated by the AccVideo model. Each video is accompanied by a short textual description explaining the visual content. The videos are all generated at a high resolution of 720x1280 pixels with a frame rate of 129 frames per second. The purpose of this figure is to demonstrate the high-quality video generation capabilities of the proposed model.
read the caption
Figure 11: Qualitative results on text-to-video with high resolution, i.e., 720×\times×1280×\times×129.
Full paper#